目录
- 前言
- 一、倍增思想
-
- [1.1 快速幂](#1.1 快速幂)
- [1.2 大整数乘法](#1.2 大整数乘法)
- 二、离散化
-
- [2.1 火烧赤壁](#2.1 火烧赤壁)
- [2.2 贴海报](#2.2 贴海报)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、倍增思想
倍增与其说是一种算法,不如说是一种思想。
倍增,顾名思义就是翻倍。它能够使线性的处理转化为对数级的处理,极大的优化时间复杂度
1.1 快速幂


一、题目分析
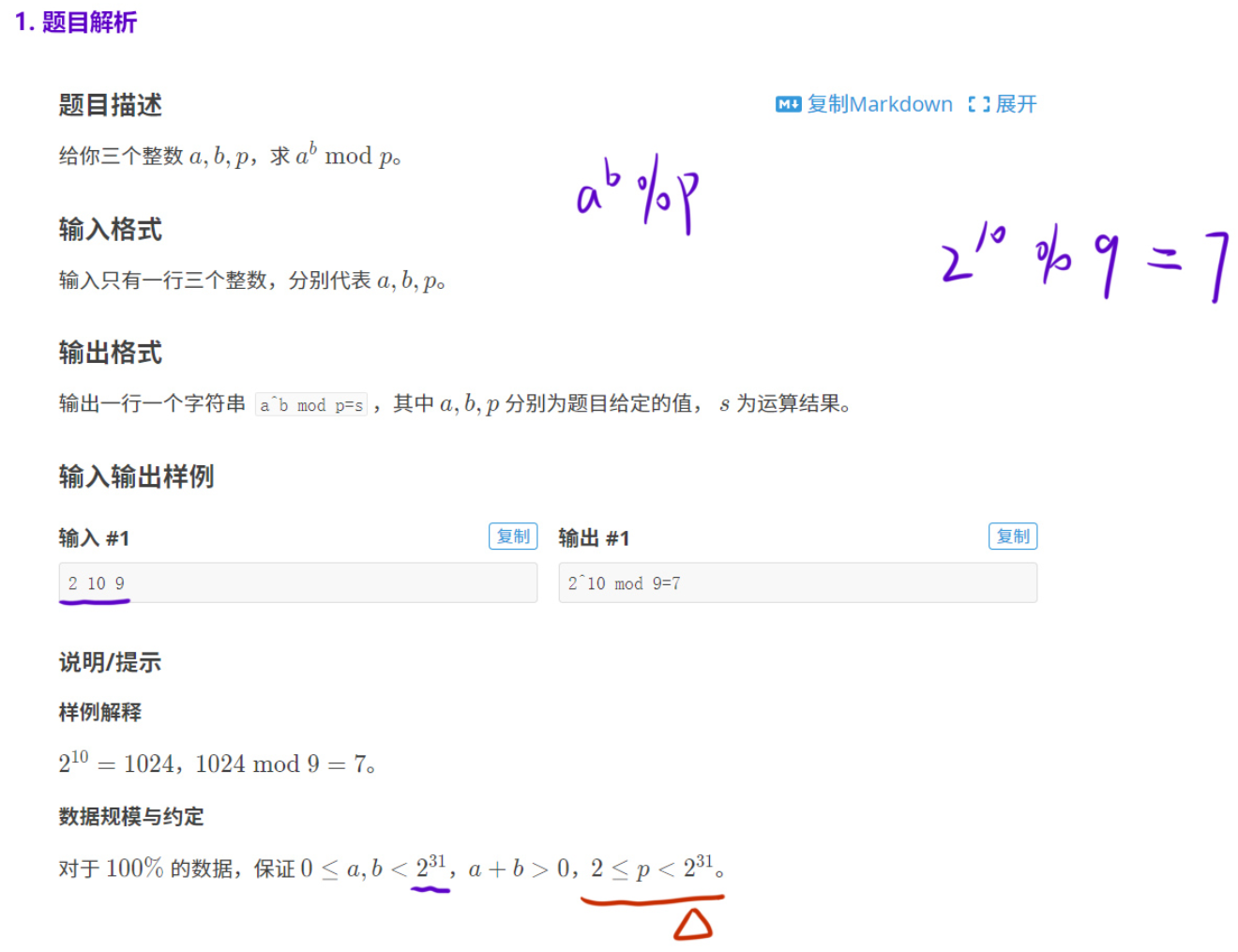
这道题的核心是计算 ab mod p(即 a 的 b 次方对 p 取余),但数据范围非常大:
- 0 ≤ a,b <231,2 ≤ p < 231
- 直接暴力循环 b 次计算 ab 会超时(时间复杂度 O(b),当 b=109 时根本跑不完),且直接计算会导致数值溢出(ab 会远超 64 位整数范围)。
所以必须用 快速幂算法 来优化时间和防止溢出。
- ret 是最终答案:初始值必须是 1(因为任何数的 0 次方是 1,乘法的 "单位元");
- 每一步都要 %p :不管是
ret*a还是a*a,都要取模 ------ 目的是防止数值太大溢出,记住 "取模就对了"; - b >>= 1 就是把 b 砍半:比如 b=10→5→2→1→0,循环到 b=0 就停。
cpp
#include <iostream>
using namespace std;
typedef long long LL; // 防止数值溢出,用64位整数
LL a, b, p;
// 快速幂函数:计算 (a^b) mod p
LL qpow(LL a, LL b, LL p)
{
LL ret = 1; // 结果初始值(任何数的0次方是1,相当于乘法的"单位元")
while(b) // 只要指数b还没拆完,就继续循环
{
// 第一步:判断当前b的最后一位二进制是不是1(是不是需要乘这个幂次)
if(b & 1) ret = ret * a % p;
// 第二步:把a翻倍(算下一个2的幂次),取模防止溢出
a = a * a % p;
// 第三步:把b右移一位(去掉最后一位二进制,拆剩下的指数)
b >>= 1;
}
return ret;
}
int main()
{
cin >> a >> b >> p; // 输入2 10 9
printf("%lld^%lld mod %lld=%lld",a, b, p, qpow(a, b, p));
return 0;
}说实话这道题原理很好懂,但是代码不太好懂,如果上面部分还看不懂的话,接下来我就以最简单的讲解方式将代码和原理结合起来,包你看懂:
我们就用最直观的例子:计算 210 mod 9(对应代码输入 a=2, b=10, p=9)。
核心原理的 3 个要点:
- 指数拆成二进制 :10 的二进制是 1010,也就是 8 + 2,所以 210 = 2(8+2) = 28 × 22(这一步是 "减少计算次数" 的关键);
- 倍增算幂次 :不用一个个算 21、22、23... 而是 "翻倍算":
21 = 2(初始的 a)
22 = (21) × (21)(a 平方)
24 = (22) × (22)(a 再平方)
28 = (24) × (24)(a 再平方)
这样算 28 只需要 3 次平方,而不是 8 次乘法; - 只乘需要的项 :二进制位是 1 的位置才需要乘到结果里(1010 的第 2 位和第 4 位是 1,对应 22 和 28),二进制位是 0 的跳过。
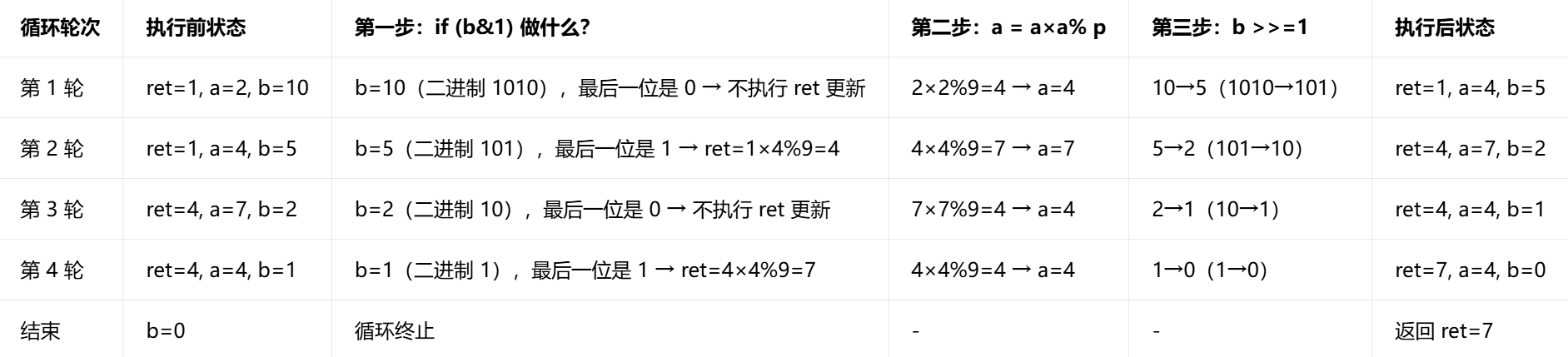
现在,我们模拟 qpow(2, 10, 9) 的执行全过程 :
初始化:ret=1,a=2,b=10(二进制 1010),p=9
把原理和代码的对应关系总结成 "一句话"

最后要点补充 :
原代码的输出行也可替换为cout
cpp
//printf 输出 long long 必须用 %lld(小写 L),写错会输出错误值;
printf("%lld^%lld mod %lld=%lld",a, b, p, qpow(a, b, p));替换成 cout 的写法:
cpp
cout << a << "^" << b << " mod " << p << "=" << qpow(a, b, p) << endl;1.2 大整数乘法
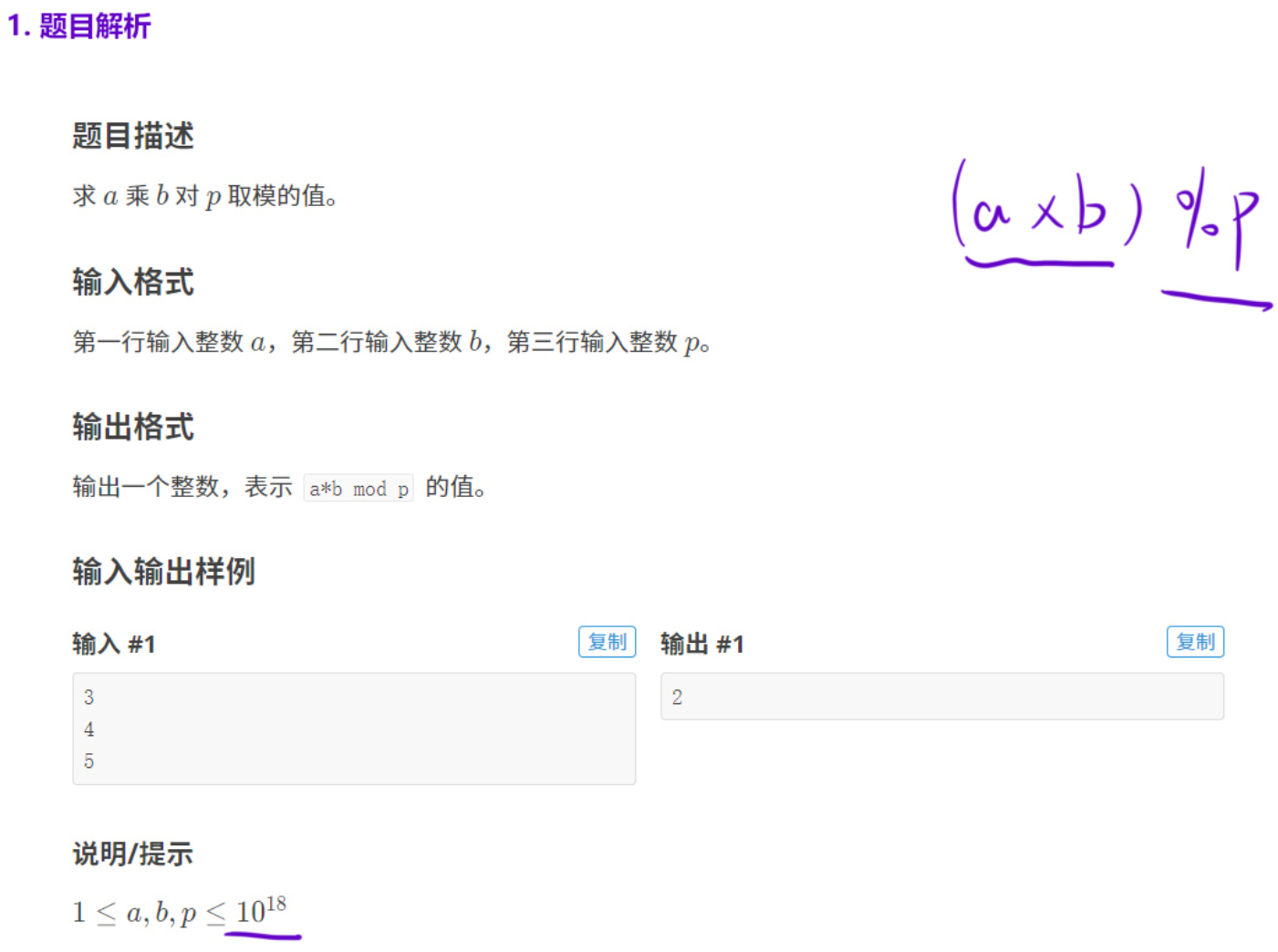
这道题的数据范围是1018,即使使用long long存a * b的值也是会溢出的,此时%p之后的结果也是不对的,所以还是要用倍增的思想来解决该问题
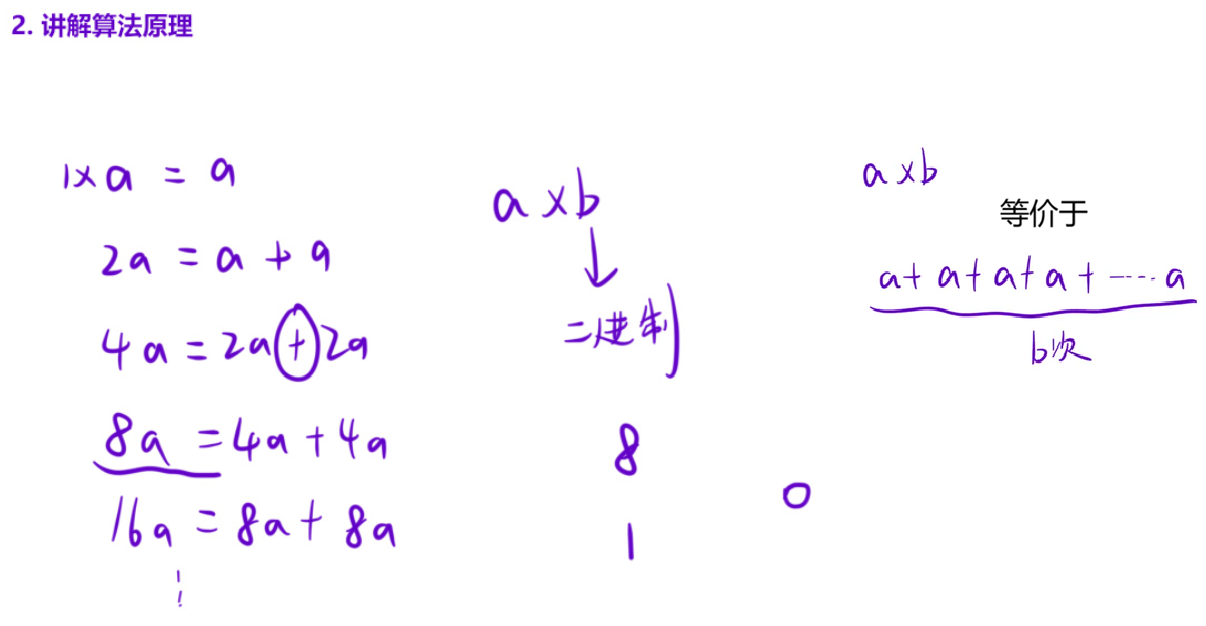
这道题也可以使用上道题的思想,先把b的二进制表示写出来,当二进制的某一位权值(比如说是8)所对应的数是1,就把8a的结果累加上,如果某一位的权值所对应的数是0的话跳过不累加即可,所以说该题目和上一道题目的解法是一摸一样的,只不过上一个是累乘,该题是累加
cpp
#include<iostream>
using namespace std;
typedef long long LL;
LL a, b, p;
LL qmul(LL a, LL b, LL p)
{
LL sum = 0;
while(b)
{
if(b & 1) sum = (sum + a) % p;
a = (a + a) % p;
b >>= 1;
}
return sum;
}
int main()
{
cin >> a >> b >> p;
cout << qmul(a, b, p) << endl;
return 0;
}二、离散化
当题目中数据的范围很大,但是数据的总量不是很大。此时如果需要用数据的值来映射数组的下标时,就可以用离散化的思想先预处理一下所有的数据,使得每一个数据都映射成一个较小的值。之后再用离散化之后的数去处理问题。
示例:99, 9, 9999, 999999 离散之后就变成 2, 1, 3, 4
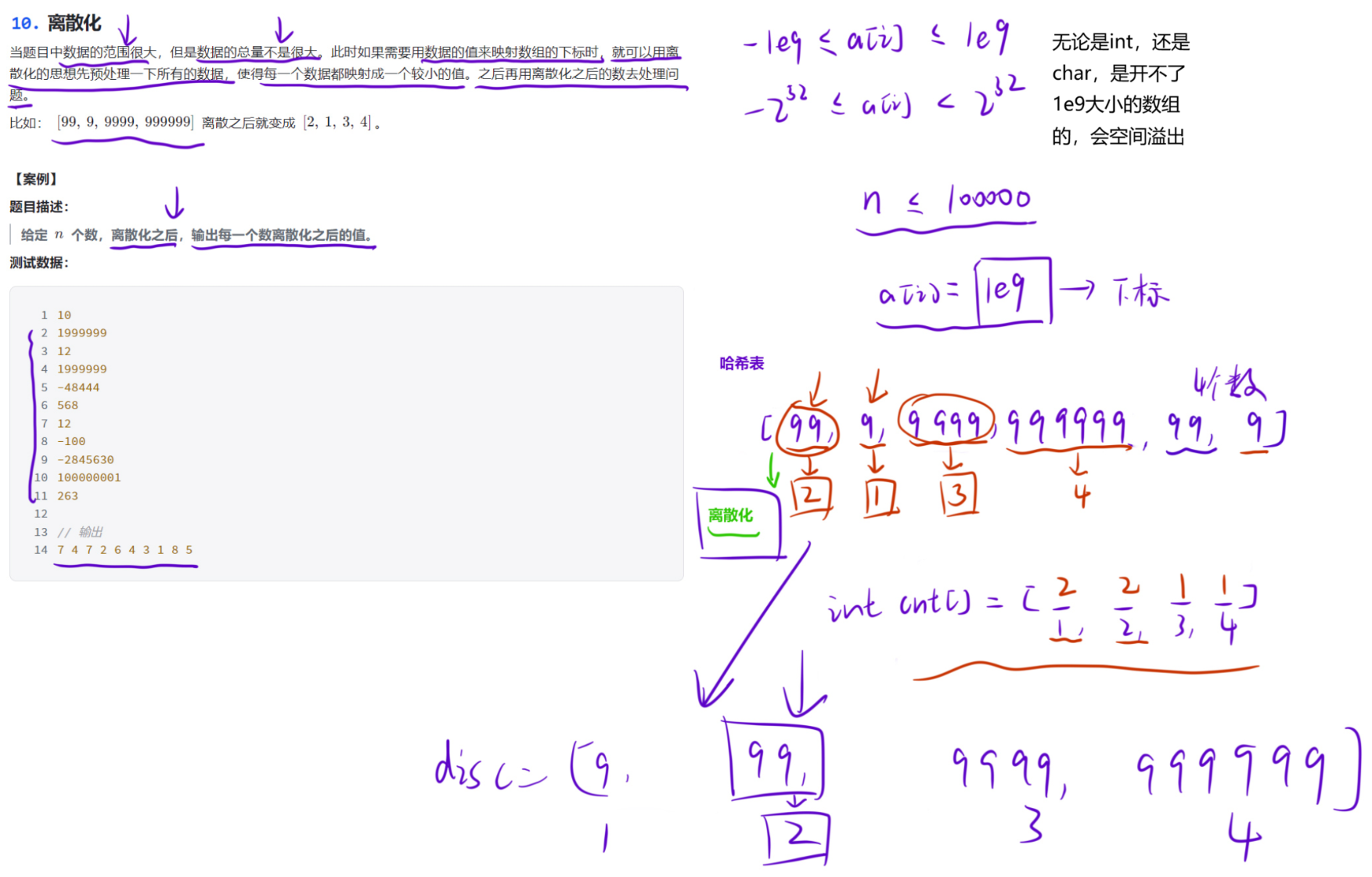
案例
题目描述
给定 n 个数,离散化之后,输出每一个数离散化之后的值。
cpp
10 数据个数 - n
1999999
12
1999999
-48444
568
12
-100
-2845630
100000001
263
共10个数
// 输出
7 4 7 2 6 4 3 1 8 5离散化模板一:排序 + 去重 + 二分查找离散之后的结果
cpp
#include<iostream>
//包含sort、unique等算法
#include<algorithm>
using namespace std;
const int N = 1e5 + 10;
typedef long long LL;
LL n, pos;
LL a[N];
//辅助数组:用来存放所有需要离散化的元素,后续排序去重
LL disc[N];
LL find(LL x)
{
LL l = 1, r = pos;
while(l < r)
{
LL mid = (l + r) / 2;
if(disc[mid] >= x) r = mid;
else l = mid + 1;
}
return l;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
disc[++pos] = a[i];
}
//步骤1:排序
sort(disc + 1, disc + 1 + pos);
//步骤2:去重
pos = unique(disc + 1, disc + 1 + pos) - (disc + 1);
//步骤3:遍历原始数组,输出每个元素的离散化结果
for(int i = 1; i <= n; i++)
{
cout << a[i] << "离散化之后" << find(a[i]) << endl;
}
return 0;
}这段代码核心完成 3 件事:
- 把原始数组的所有元素复制到辅助数组disc中;
- 对disc排序 + 去重,得到 "唯一且有序" 的离散化基准数组;
- 用二分查找,为原始数组每个元素找到其在基准数组中的位置/下标(这个位置就是离散化后的值)。
最终效果:把范围可能极大的原始数值(比如 - 2845630、100000001)映射成连续的小整数(比如 1、9),且保持数值的相对大小关系。
要点补充:
- unique的底层原理
unique是 C++ STL 中的算法,必须在「有序数组」上使用 ,否则无法正确去重。
核心逻辑:unique不是 "删除" 重复元素,而是将相邻的重复元素移动到数组末尾,返回「去重后最后一个有效元素的下一个位置」的指针 / 迭代器。
代码中pos的计算逻辑
cpp
pos = unique(disc + 1, disc + 1 + pos) - (disc + 1);- unique(disc+1, disc+1+pos):处理disc1~discpos,返回有效区域的下一个地址(比如有效元素有 8 个,返回disc+9);
- 减去disc+1:把地址差转换成元素个数(disc+9 - (disc+1) = 8),最终pos就是去重后的元素个数。
离散化模板二:排序 + 哈希表去重以及记录最终的位置
cpp
#include<iostream>
#include<algorithm>
#include<unordered_map>
using namespace std;
const int N = 1e5 + 10;
typedef long long LL;
LL n, pos;
LL a[N], disc[N];
unordered_map<LL, LL> id;
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
disc[++pos] = a[i];
}
sort(disc + 1, disc + 1 + pos);
LL cnt = 0;
//遍历排序后的disc数组,构建哈希映射
for(int i = 1; i <= pos; i++)
{
//取排序后的当前值
LL x = disc[i];
//关键:如果x已在哈希表中,跳过(去重)
if(id.count(x)) continue;
//编号+1(保证连续)
cnt++;
//存入映射:原始值x → 离散编号cnt
id[x] = cnt;
}
for(int i = 1; i <= n; i++)
{
cout << a[i] <<"离散化后:"<< id[a[i]] << endl;
}
return 0;
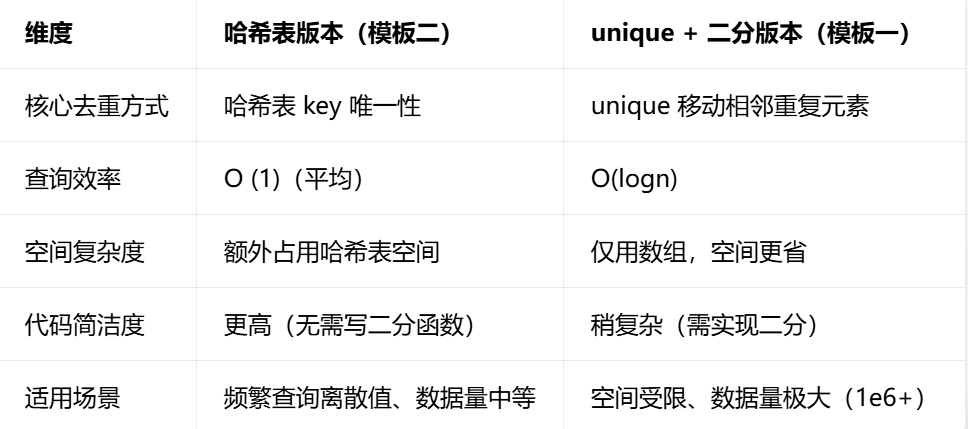
}这个模板是离散化的哈希表实现版本,核心逻辑和模板一(排序 + unique + 二分)一致 ------ 将大范围的原始值映射为连续的小整数,但用「哈希表」替代了「unique 去重 + 二分查找」
要点补充:
- unordered_map核心特性:
key唯一:同一个key只能存一个value,重复插入会覆盖,这是「去重」的关键 - id.count(x):检查哈希表中是否存在key=x,返回1表示存在,0表示不存在;
哈希版 vs 模板一(unique + 二分)对比
注意事项:
- 离散化是一种「思想」,模版其实不用背,根据算法思想就可以实现。而且实现离散化的方式也可以在上述模板的基础上「修改」,千万「不要生搬硬套」(大家也会看到有些题解里面是借助「结构体」离散化的,但是核心的思想都是不变的);
- 前期学习离散化的时候可能会被「绕」进去,会把「离散前」和「离散后」的值搞混,分不清楚是用离散前的值还是离散后的值。觉得迷惑是「很正常」,一定要根据最基础的模板画图分析整个流程,搞清楚每一个变量的作用,以及达到的目的。离散化「使用的多」了,慢慢的就不会迷了。
2.1 火烧赤壁
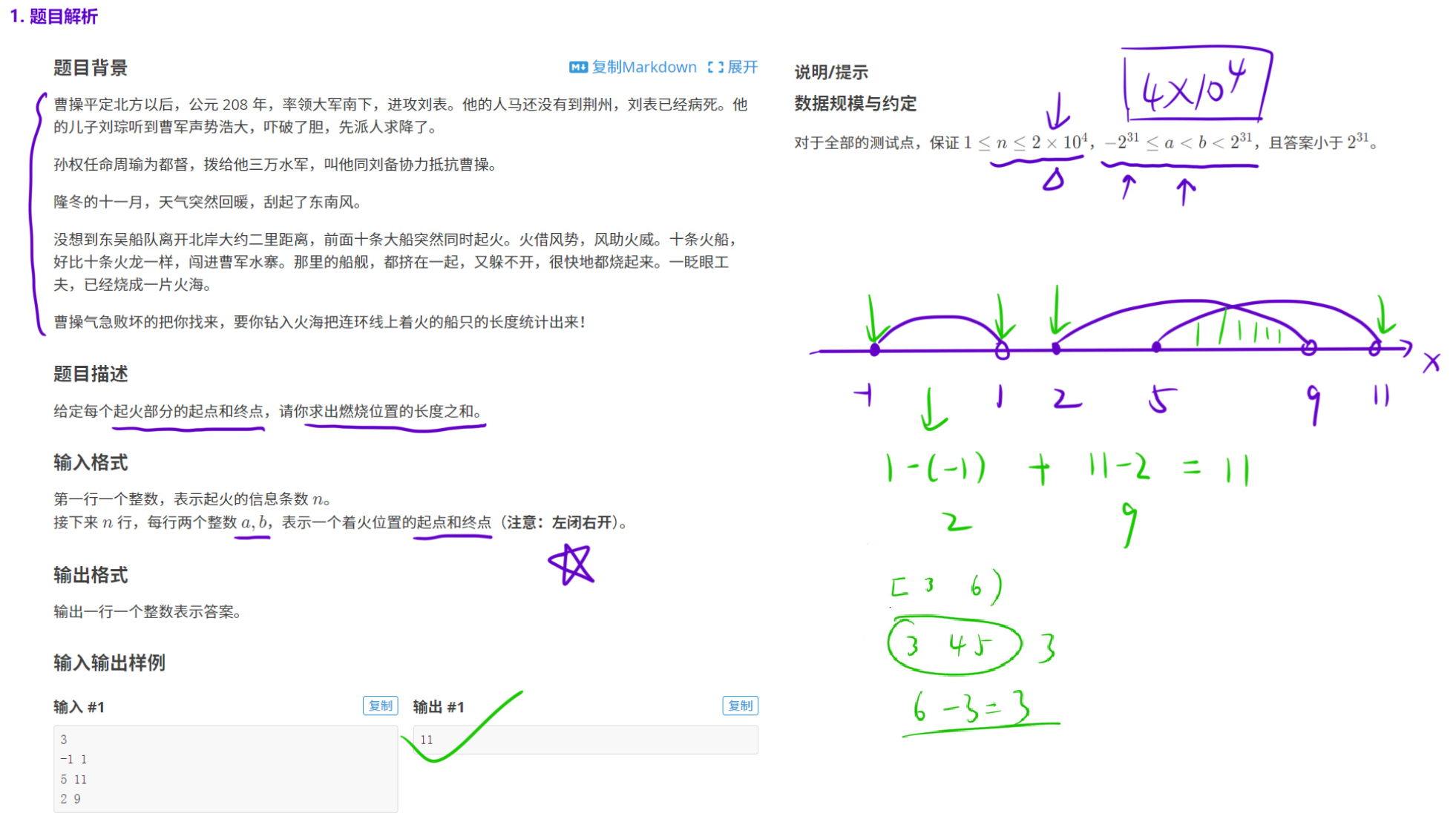
【解法】
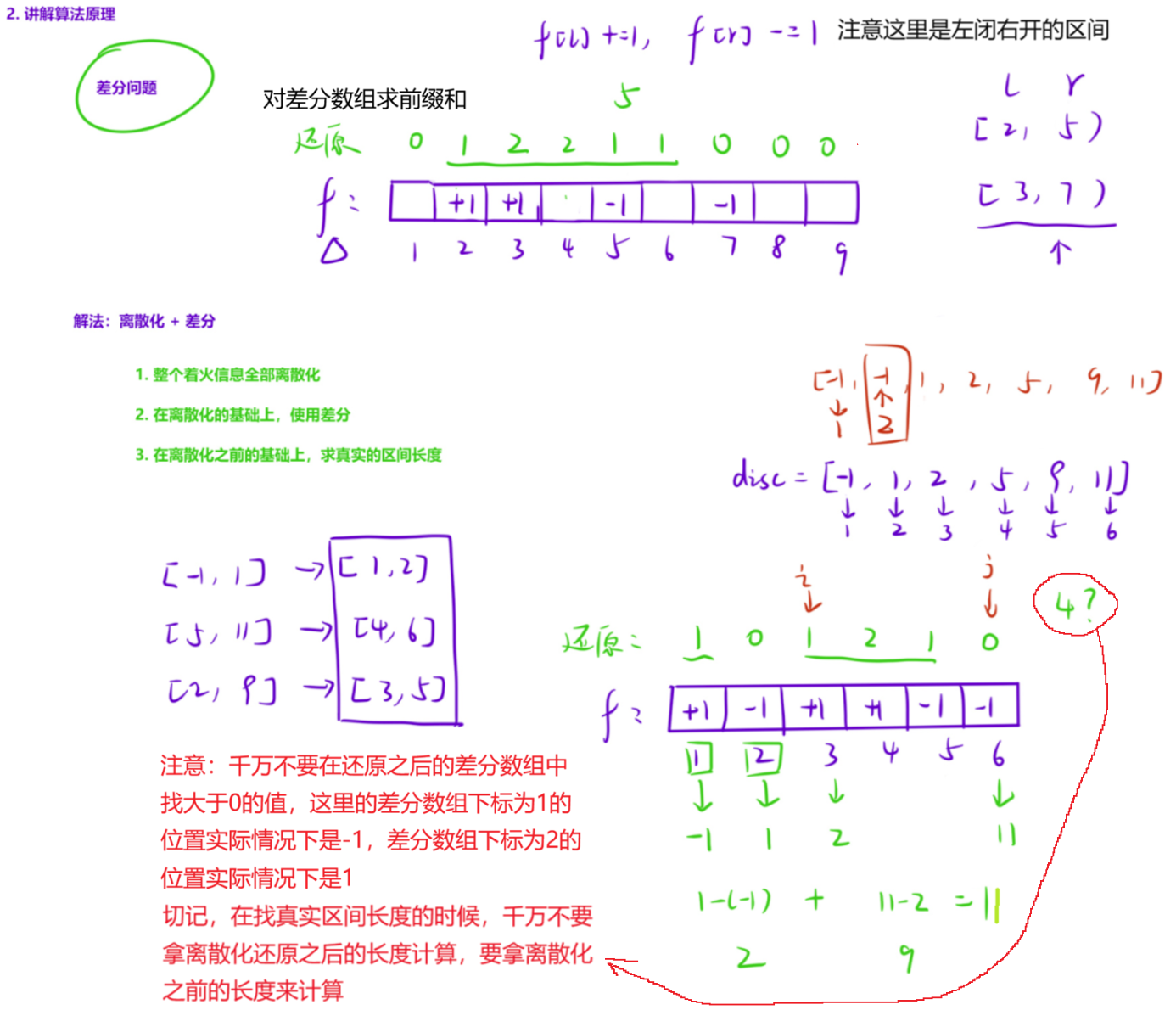
抛开数据范围不看,这就是一道「差分」题目:
- 给定一个区间,我们可以全部执行 +1 操作;
- 最后看看整个数组中,大于 0 的位置有多少个。
因此可以创建一个原数组的「差分」数组,然后执行完「区间修改」操作之后,还原原数组,「统计大于 0」的区间长度。
但是,这道题的「数据范围/区间长度」不允许我们直接差分,因为「开不了那么大」的数组;即使能开那么大的数组,「时间」也不够用,但是n的范围是2×104,区间的端点数最多是4×104。
我们发现,区间的范围虽然很大,区间的「个数」却只有 2×104 级别。此时我们就可以:
- 先将所有的「区间信息」离散化;
- 然后在「离散化的基础」上,处理所有的「区间修改」操作;
- 处理完之后找出「原始数组对应的区间端点」,计算相应的「长度」。
下面展示两种写法,第一种是直接套模板写出来的代码
cpp
#include<iostream>
#include<unordered_map>
#include<algorithm>
using namespace std;
const int N = 2e4 + 10;
typedef long long LL;
unordered_map<LL, LL> id;
int n;
int pos;
LL a[N], b[N];
LL disc[N * 2];
LL f[N * 2];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i] >> b[i];
disc[pos++] = a[i]; disc[pos++] = b[i];
}
//排序
sort(disc + 1, disc + pos + 1);
//离散化
LL cnt = 0;
for(int i = 1; i <= pos; i++)
{
LL x = disc[i];
//去重
if(id.count(x)) continue;
cnt++;
id[x] = cnt;
}
//离散化的基础上做差分
for(int i = 1; i <= n; i++)
{
//针对当前的着火信息找到离散化后对应的值
LL l = id[a[i]], r = id[b[i]];
f[l]++; f[r]--;
}
//还原数组,前缀和
for(int i = 1; i <= cnt; i++) f[i] += f[i - 1];
//统计结果
//记录着火区间的长度
LL ret = 0;
//遍历整个还原之后的数组
for(int i = 1; i <= cnt; i++)
{
int j = i;
while(j <= cnt && f[j] > 0) j++;
ret += disc[j] - disc[i];
i = j;
}
cout << ret << endl;
return 0;
}该代码是有bug的,这里排序的时候disc数组还是没有去重的,sort处没有给disc去重的话ret += disc[j] - disc[i];就会有bug,此时在第i个位置想找之前未离散化的值的时候就会出错,比如说disc数组中有两个-1,第一个-1对应映射的位置是1,第二个-1映射的位置就是2了,此时就会出错
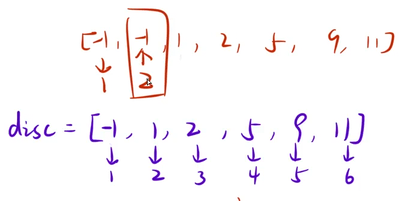
修改后的逻辑:
cpp
#include<iostream>
#include<algorithm>
#include<unordered_map>
using namespace std;
const int N = 2e4 + 10;
typedef long long LL;
unordered_map<LL, LL> id;
int n;
int pos;
LL a[N], b[N];
LL disc[N * 2];
LL f[N * 2];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i] >> b[i];
disc[++pos] = a[i]; disc[++pos] = b[i];
}
//排序
sort(disc + 1, disc + 1 + pos);
//去重
pos = unique(disc + 1, disc + 1 + pos) - (disc + 1);
//离散化
for(int i = 1; i <= pos; i++)
{
LL x = disc[i];
id[x] = i;
}
//离散化的基础上做差分
for(int i = 1; i <= n; i++)
{
LL l = id[a[i]], r = id[b[i]];
f[l]++; f[r]--;
}
//对差分数组做还原
for(int i = 1; i <= pos; i++) f[i] += f[i - 1];
//统计结果
LL ret = 0;
for(int i = 1; i <= pos; i++)
{
int j = i;
while(j <= pos && f[j] > 0) j++;
ret += disc[j] - disc[i];
i = j;
}
cout << ret << endl;
return 0;
}这里的要点分析就以我当时看到该题的疑惑来解答:
在离散化的基础上做差分这里的循环区间为什么是1 到 n?
差分操作的目的是:对每一个原始区间 a\[i, bi) 标记它的覆盖范围。
- 代码里 ai 和 bi 是第 i 个原始区间的起点和终点,所以必须遍历
i=1~n,才能拿到所有原始区间的起止点。 - 对每个原始区间,我们通过 ida\[i] 和 idb\[i] 映射到离散化后的索引 l 和 r,然后执行 fl++、fr--,完成一次差分标记。
为什么不能是 1~pos?
如果循环写成 1~pos,就会变成遍历离散化后的点,而不是原始区间:
- 此时 i 代表的是离散点的索引,没有对应的 ai 和 bi(a 和 b 数组只有 n 个元素),会直接数组越界或逻辑错误。
- 差分标记只需要对每个原始区间做一次,和离散点的数量 pos 完全无关。
为什么差分数组大小是 N*2?
离散化后,每个端点对应一个 1~pos 的索引(pos 是去重后的端点数量,最多为 2n)。 差分数组的大小必须匹配离散化后的索引范围
差分数组 f 是用来标记区间 a, b) 的:对离散化后的 l = id\[a、r = idb,执行 fl++、fr--。
由于离散化后的索引最大为 2n,所以差分数组 f 必须和 disc 数组一样开 N*2 的大小,才能覆盖所有可能的索引,避免数组越界访问(比如 n=2e4 时,2n=4e4,如果 f 只开 N 大小,就会超出范围)。
2.2 贴海报
贴海报

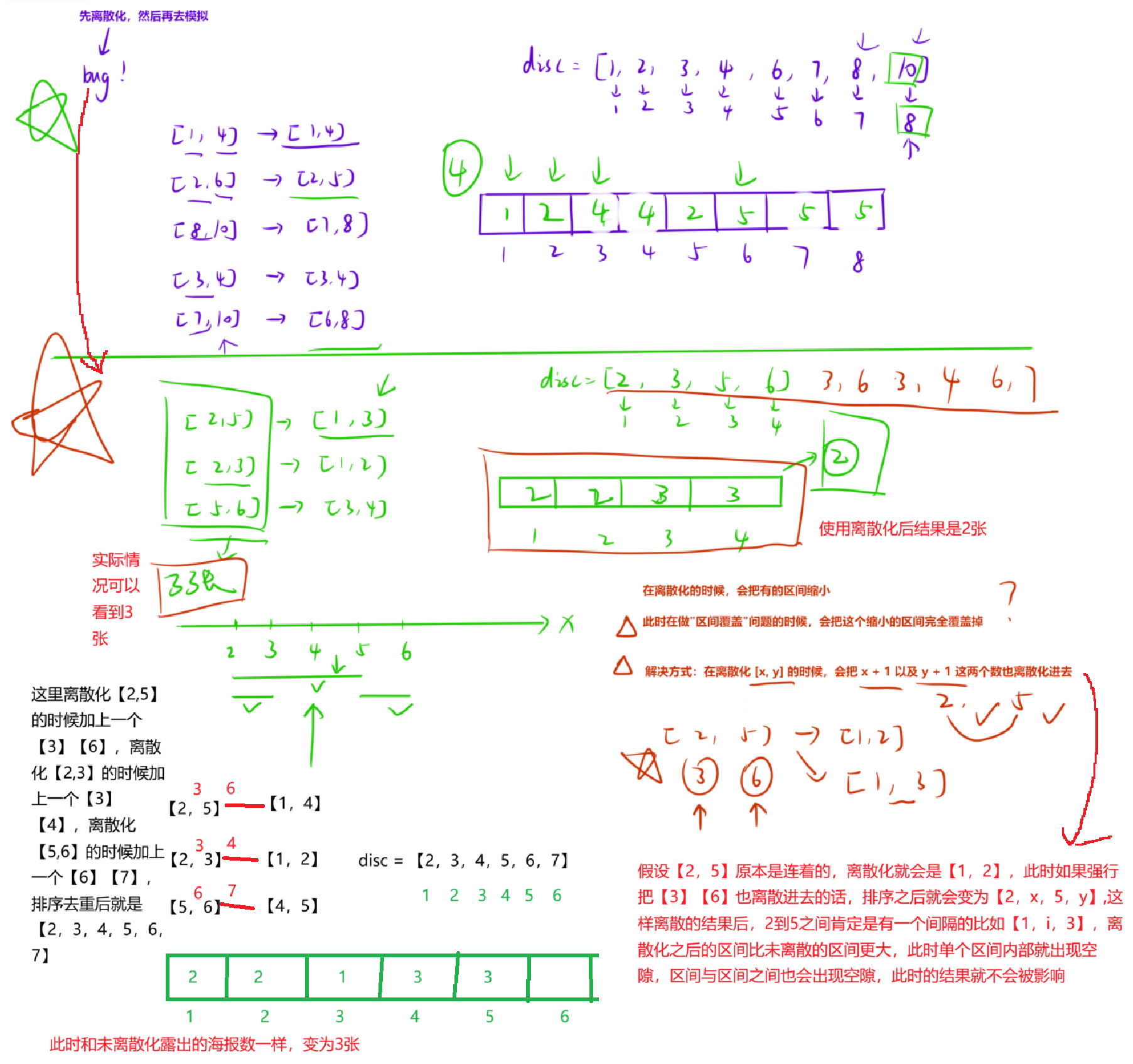
【解法】
根据题意「模拟」即可。
由于「区间的长度」很大,暴力模拟的时候会超时。但是我们发现,虽然区间长度很大,但是「区间的个数」是很少的,所以我们可以「离散化」处理一下区间的端点值,然后在「离散化的基础上」模拟覆盖情况。
注意注意注意,重要的注意说三遍 :
离散化在离散「区间问题」的时候一定要小心!因为我们离散化操作会把区间缩短,从而导致丢失一些点。在涉及「区间覆盖」问题上,离散化会导致「结果出错」。
比如我们这道题,如果有三个区间分别为:2,5、2,3、5,6,离散化之后为:1,3、1,2、3,4,区间覆盖如图所示:

为了避免出现上述情况,我们可以在离散化的区间 x,y 时,不仅考虑 x,y 这两个值,也把「x+1,y+1」也考虑进去。此时「单个区间内部」就出现空隙,「区间与区间之间」也会出现空隙。就可以避免上述情况出现。
可见,离散化之后可能会导致结果错误,使用的时候还是需要「谨慎」一点。
cpp
#include<iostream>
#include<algorithm>
#include<unordered_map>
using namespace std;
const int N = 1010;
unordered_map<int, int> id;
int n, m;
//海报的起始位置,终止位置
int a[N], b[N];
//记录离散化之后有多少数
int pos;
//不仅要离散化海报的左右端点
//还要离散化对应左右端点的值 + 1,大小要开4倍
int disc[N * 4];
//海报墙
int w[N * 4];
//全局bool类型数组,默认值为0->false
bool st[N * 4];//标记那些海报已经出现过
int main()
{
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> a[i] >> b[i];
disc[++pos] = a[i]; disc[++pos] = a[i] + 1;
disc[++pos] = b[i]; disc[++pos] = b[i] + 1;
}
//离散化
sort(disc + 1, disc + 1 + pos);
int cnt = 0;
for (int i = 1; i <= pos; i++)
{
int x = disc[i];
if (id.count(x)) continue;
cnt++;
id[x] = cnt;
}
//在离散化的基础上模拟贴海报的过程
for (int i = 1; i <= m; i++)
{
//针对当前海报找到离散化之后的值
int l = id[a[i]], r = id[b[i]];
for (int j = l; j <= r; j++)
{
w[j] = i;
}
}
int ret = 0;
//统计结果 - 数组中不同数的个数
for (int i = 1; i <= cnt; i++)
{
int x = w[i];
//格子为0,当前位置没有海报
//当前海报出现过,均continue
if (!x || st[x]) continue;
ret++;
st[x] = true;
}
cout << ret << endl;
return 0;
}要点补充:
代码中 const int N = 1010 表示:海报的最大数量 m 不超过 1010(题目约束)。
1. 离散化的「4 倍值」来源
代码中对每个海报,都往 disc 数组中存入了 4 个值:
cpp
// 每个海报i,存入4个值
disc[++pos] = a[i]; // 海报左端点
disc[++pos] = a[i] + 1; // 左端点+1
disc[++pos] = b[i]; // 海报右端点
disc[++pos] = b[i] + 1; // 右端点+11 张海报 → 4 个离散化候选值
m 张海报(最多 N 张)→ 最多 N * 4 个候选值
因此,disc 数组需要开 N * 4 来容纳所有候选值,这是「4 倍」的核心来源。
3. w 数组:必须开 N*4 的原因
w 数组的作用是:存储离散化后每个位置被哪张海报覆盖。
- 离散化后,所有候选值会被去重、排序,得到唯一的「离散化编号 cnt」(代码中 cnt 是离散化后的总位置数)。
- cnt 的最大值 = 所有候选值的数量上限 =
N * 4(极端情况下所有海报的 4 个值都不重复)。 - 为了让 w 数组能覆盖所有离散化后的位置 ,必须把大小设为
N * 4(否则会出现数组越界)。
4. st 数组:开 N*4 是「冗余但安全」的写法
st 数组的作用是:标记某张海报是否已经被统计过(避免重复计数)。 - 理论上,海报的编号 i 最大是 m <= N,所以 st 数组只需要开 N 就足够(比如 st1010 就能覆盖所有海报)。
- 代码中开
N * 4是「偷懒但安全」的写法:
-
- 不需要精确计算 st 的最小大小,直接复用
N*4的大小(和 w 保持一致);
- 不需要精确计算 st 的最小大小,直接复用
-
- 内存开销极小(bool st4040 仅占 4KB 左右),不会有性能问题;
-
- 避免因边界判断失误导致数组越界。
结语
