
🎈主页传送门:良木生香
🔥个人专栏:《C语言》 《数据结构-初阶》 《程序设计》《鼠鼠的C++学习之路》 《Linux系统编程》
🌟人为善,福随未至,祸已远行;人为恶,祸虽未至,福已远离

前言:在之前的学习中,我们已经将C++STL容器部分的String类进行了学习,知道了STL容器的基本用法以及常见接口。那么今天我们就来继续学习STL中容器中的Vector,看看它有哪些点是和string相似和不同点
一、基本接口的使用
1.1、定义:

从定义中我们可以看到,Vector与String相似,也是一个模板,毕竟是为了支持多种数据的插入
1.2、构造 && 析构
构造:
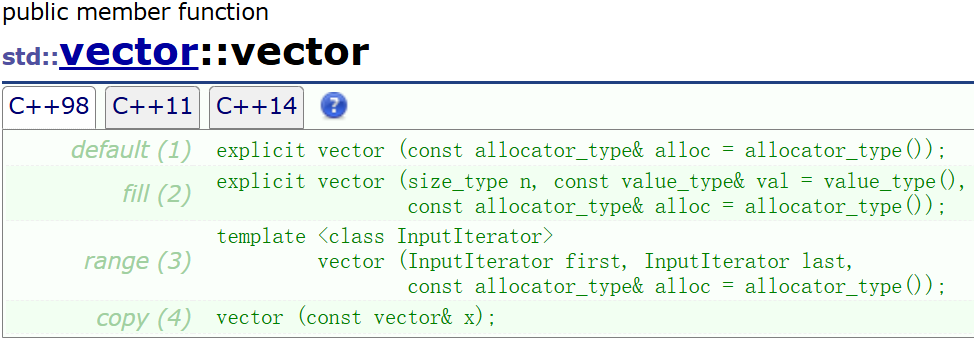
虽然Vector有多种构造方式,但是在日常使用中使用更多的还是默认构造和拷贝构造。
析构:

对于析构函数,如果不是自己写的话,就不用去关心这么多,因为在日常使用中Vector自带的析构函数已经非常完美了,但如果是自己写的构造函数,那就要自己手动写析构了。
1.3、流插入和流提取
Vector是不支持流插入和流提取的,即不能用cin和cout对其进行输入和输出。当我们想要对数据进行输入和输出时,可以用上我们的三种遍历方式:下标+ 、范围for 以及迭代器iterator
下面就进行小小的演示:
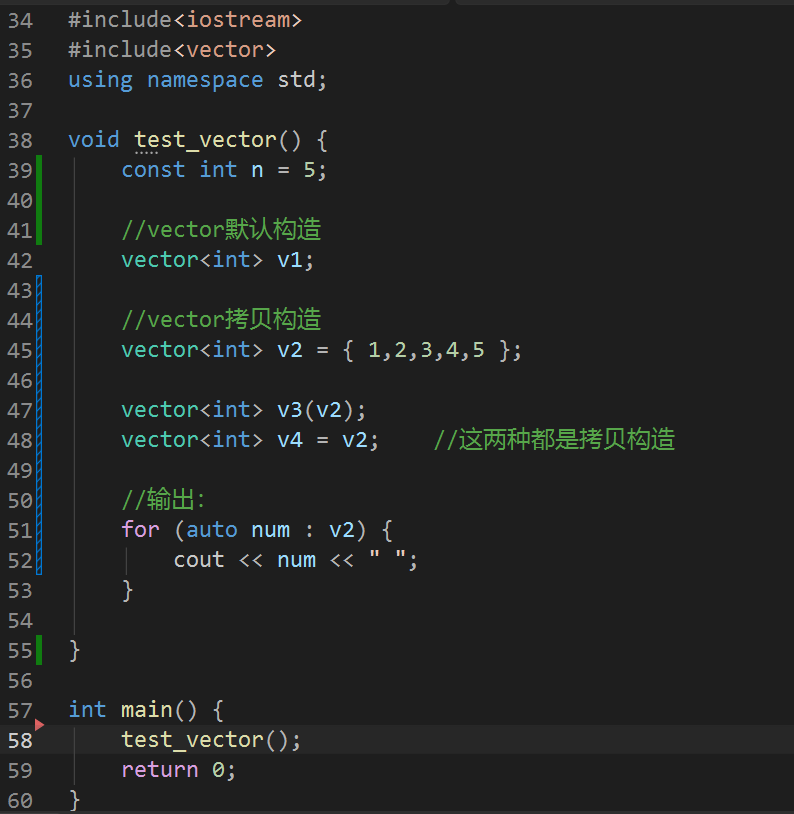
运行结果为:

在C++11中新增加了一个小特性:initializer_list,也就是允许用{元素}方式直接给vector进行初始化。还有一点就是:有迭代器就能使用范围for,这就是为什么string类和vector都能使用范围for的原因。
1.4、size && max_size && capacity
讲到容器,就不得不提它的容量大小了。
size()依旧计算的是元素的个数,max_size是计算当前环境下能存放的最大数量的元素个数,capacity()值得则是当前穷奇的容量,我们以v2为例子,看看数据是怎么样的:
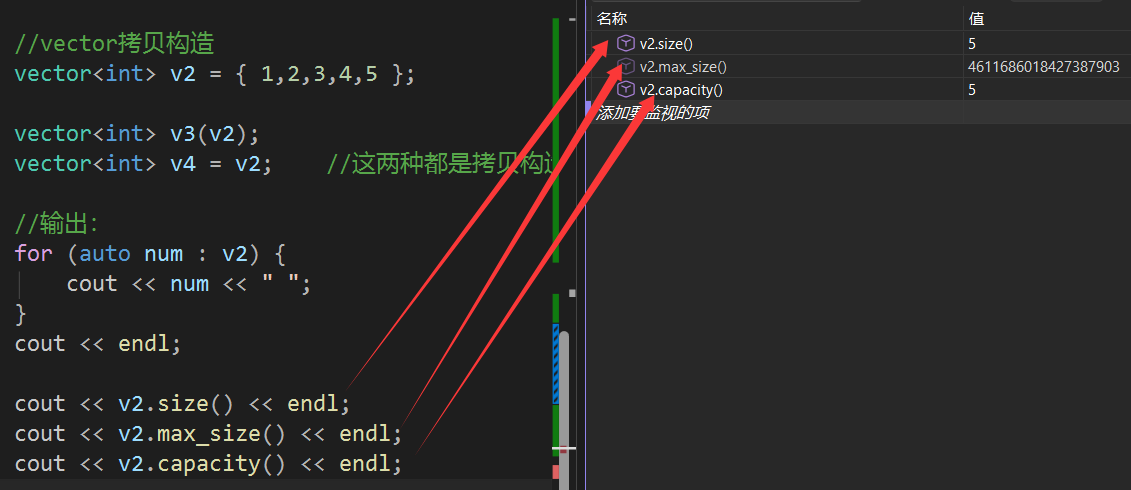
这里我们也能看一下windows和Linux在vector上的capacity扩容方式:
vs中的扩容方式是这样的:
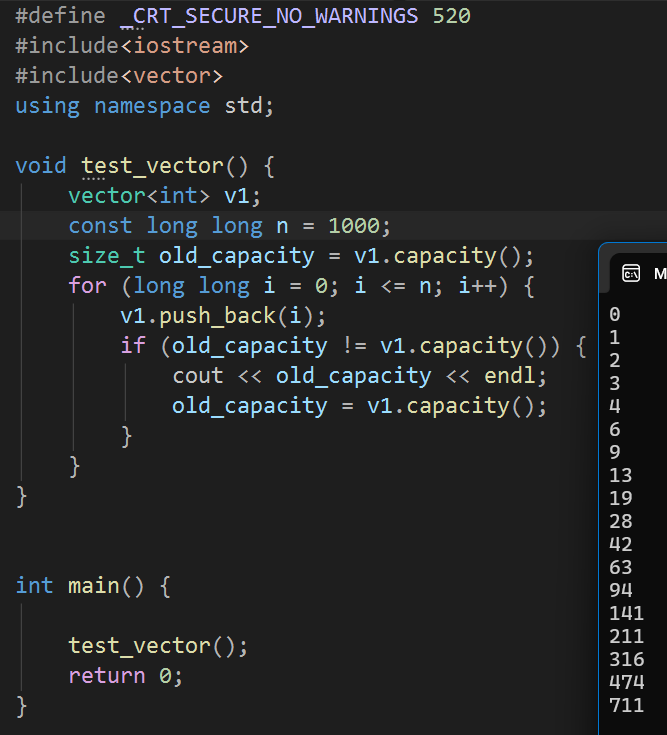
大概呈1.5倍的扩容方式,而Linux下的环境则是这样的:
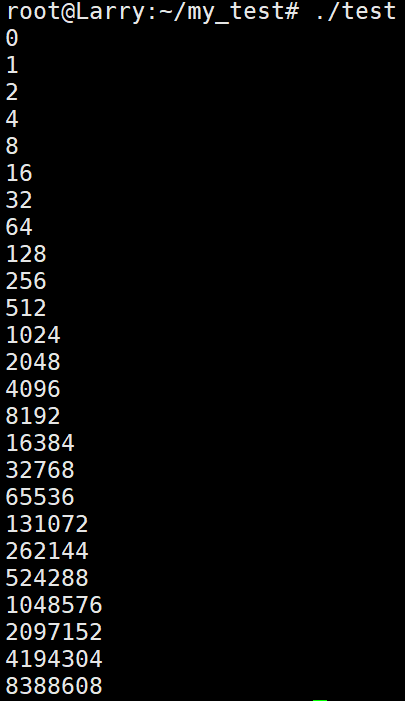
同样的代码,在Linux环境下则是标准的二倍扩容。
1.5、reserve
既然都讲到了空间扩容,我们就来看看reserve能为我们的程序提升多大的效率:
假设我们差如十亿个数据,下面是使用reserve的情况:
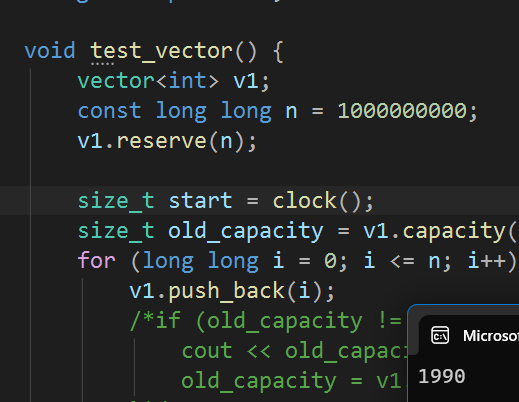
耗时在两秒左右,那不使用reserve有是多久呢?
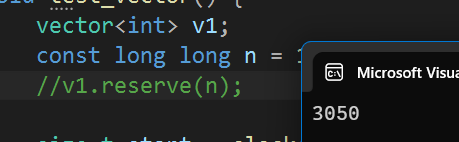
用了三秒左右,可见使用reserve之后程序运行的效率能大大提高啊。
既然扯到了reserve,那我们再来将他和resize对比一下:
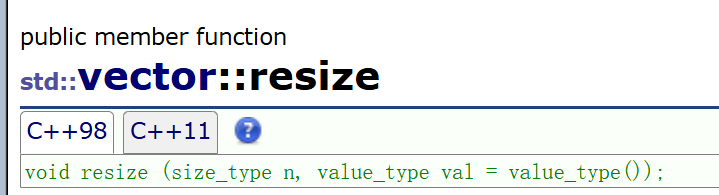
从定义中我们能看到,resize具有开空间的同时又能对空间进行初始化,但是reserve只能开空间,并不会赋值。
1.6、对元素的操作:
1.6.1、push_back && pop_back
这两个接口顾名思义就是尾插和尾删 ,两者的定义如下:
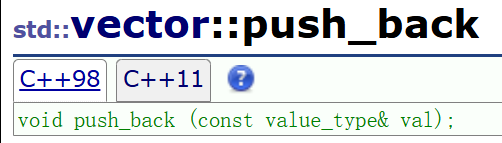

他们的具体使用方法如下:
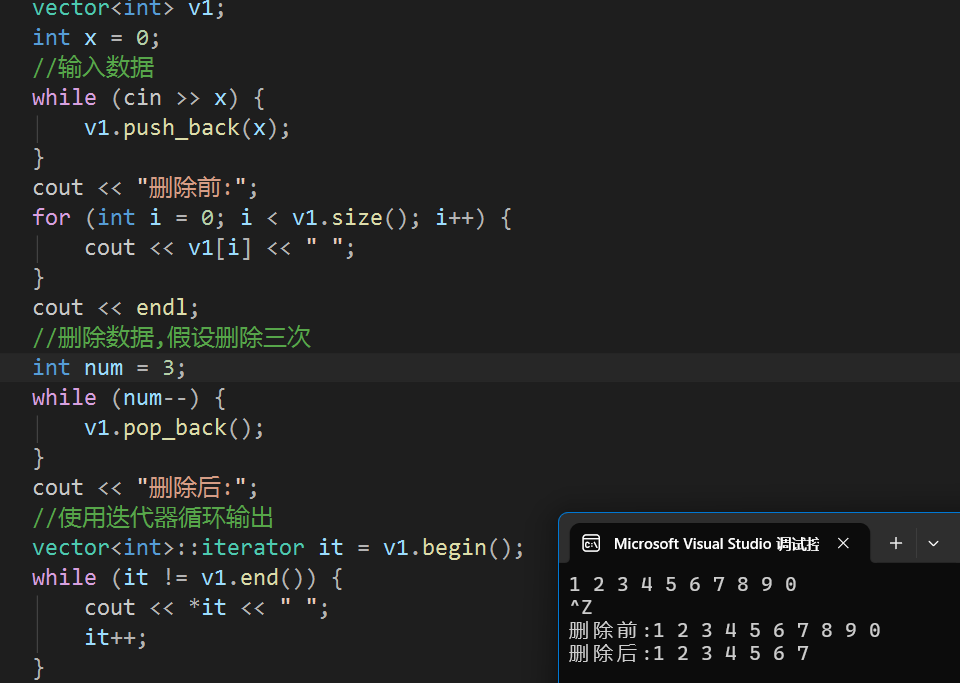
既然有了尾删和尾插,那有没有头删和头插呢?有的:
1.6.2、insert && erase
两者的定义如下:


其实他们实现的是在某个位置进行插入和删除,但是我们只用将位置设定在头部就能实现头删和头插了:
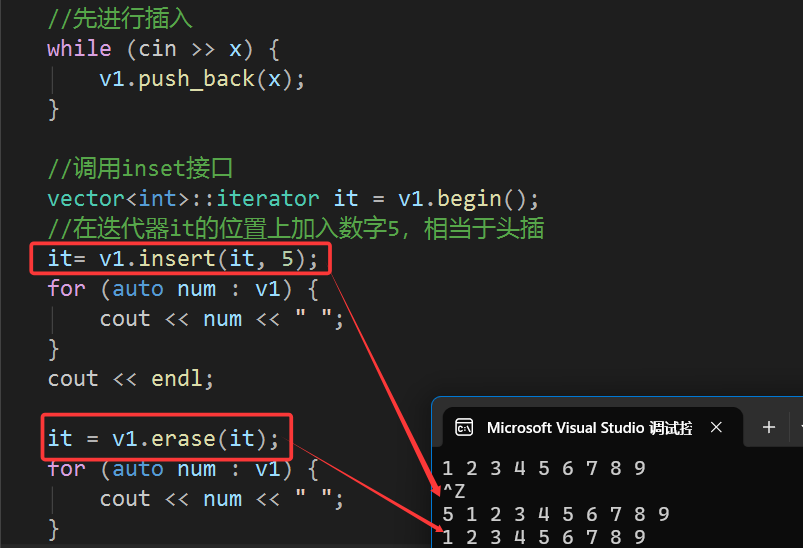
在实现的时候要注意,在调用一次insert或者erase之后都要将it(iterator)的指向进行修改,因为这两个操作可能会修改容器的起始指针。
1.6.3、swap && clear
这两者在平时中使用的场景并不是很多,但是还是要注意一下,先看定义:

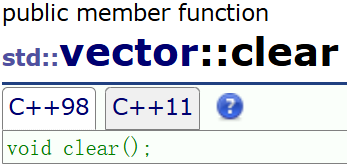
1.swap交换的其实并不是两个容器之间的数据,而是指向两个容器的指针,即容器A的指针指向容器B,容器B的指针指向容器A。
2.clear在被调用时只是清除数据,并不会起到释放空间的作用。
1.6.4、emplace_back && emplace
两者的定义如下:


这两者的区别就相当于inset和push_back的区别,但是emplace_back和push_back亦有差距,当vector中存放当元素是了结构体或者是类类型时,传进去的多个参数会触发多参数的隐式类型转换,即将多个参数自动构造成一个类类型对象或者是结构体对象并存入vector中。
但是:
1.push_back()在对多参数类型进行隐式类型转换的时候,会先用多参数创建一个临时对象,在对临时对象进行拷贝,最后才放进vecotr中。
2.emplace_back()则是直接在vector中直接用参数构造类类型对象或者是结构体对象。
综上,emplace_back()的效率会比push_back()要高一些。
既然emplace_back()的效率要比push_back()要高,那为什么还要保留push_back()?
就是因为当已经有现成对象的时候,使用push_back()的效率又会更高效,而emplace_back()则是将对象的参数拆分出来,这样就得不偿失了,所以两者在不同场景下都各有优点。
总结:
emplace_back():没有现成对象,只传参数的时候,效率更高;并且能传构造对象的参数,也能传对象(emplace_back(aa1)->对象 / emplace_back(1,2)->参数)
push_back():只能传对象(现有对象/临时对象),如果传参数也是先构造成临时对象,再将临时对象进行拷贝再传入vector,所以本实质上还是只能传对象。(push_back({1,2})->参数->临时对象(多参数的隐式类型转换))
二、简单练习
讲完了基本接口的使用,现在来做两道题练练手:
2.1、只出现一次的数字:
136. 只出现一次的数字 - 力扣(LeetCode)![]() https://leetcode.cn/problems/single-number/description/
https://leetcode.cn/problems/single-number/description/
题解很简单,使用异或对所有数字进行遍历即可,因为只有一个数字出现一次,那么其他数字就只可能多次重复出现或者都不出现,在异或运算之后,重复出现的数字会被异或成0,而0和任何数字异或还是那个数字(当然前提是每个数字出现的次数都是偶数次,如果是基数次的话那就要用到分组异或了)
2.2、杨辉三角
118. 杨辉三角 - 力扣(LeetCode)![]() https://leetcode.cn/problems/pascals-triangle/description/
https://leetcode.cn/problems/pascals-triangle/description/
这道题是挺有意思的,我么你可以将其分为C语言版的和C++版本的C++版本呢
先来看看C++版本的:
可以看到,你这个函数的接口非常的简单,只用我们返回一个二维vector的指针,那么我们先通过画图来理解一下这个二维的vector:
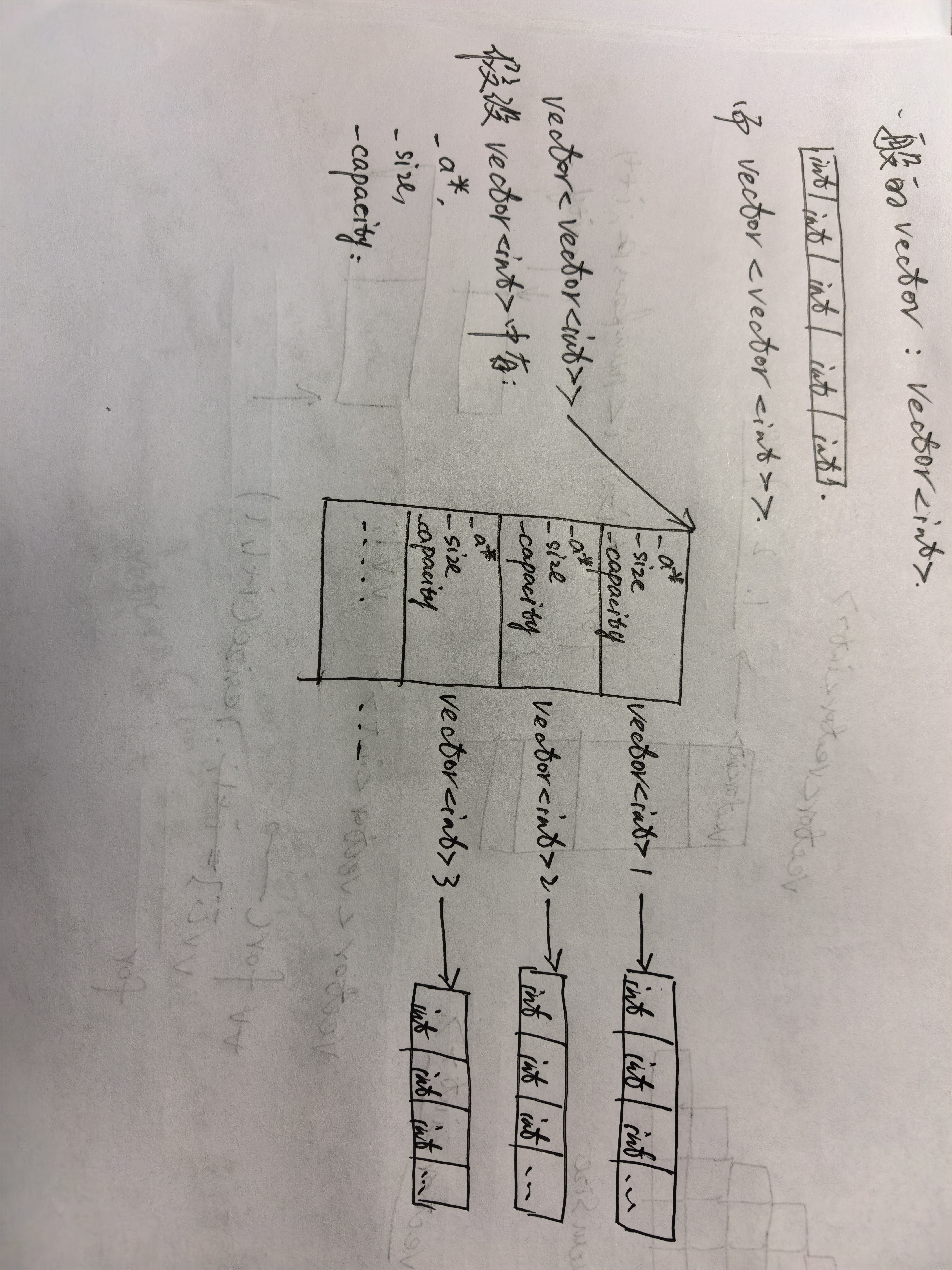
可以看到,二维的vector就是由一个一个vector拼接起来组成的,那么想要实现杨辉三角,我们就要先开numRows长的空间来存放vector<int>类型的数据,再对每个vector<int>放入int 类型的数据,那么具体的代码如下:
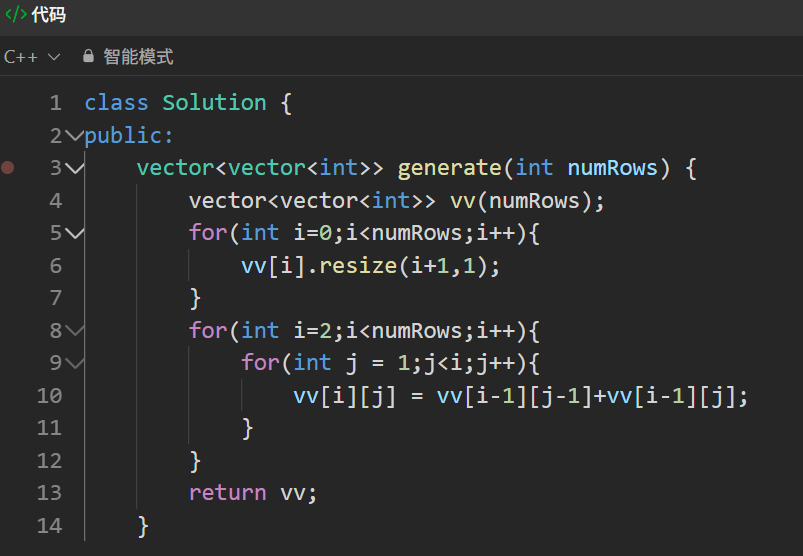
整个过程非常的简单,后面就是对杨辉三角进行一些元素的处理了。
现在我们再来看看C++版本的:
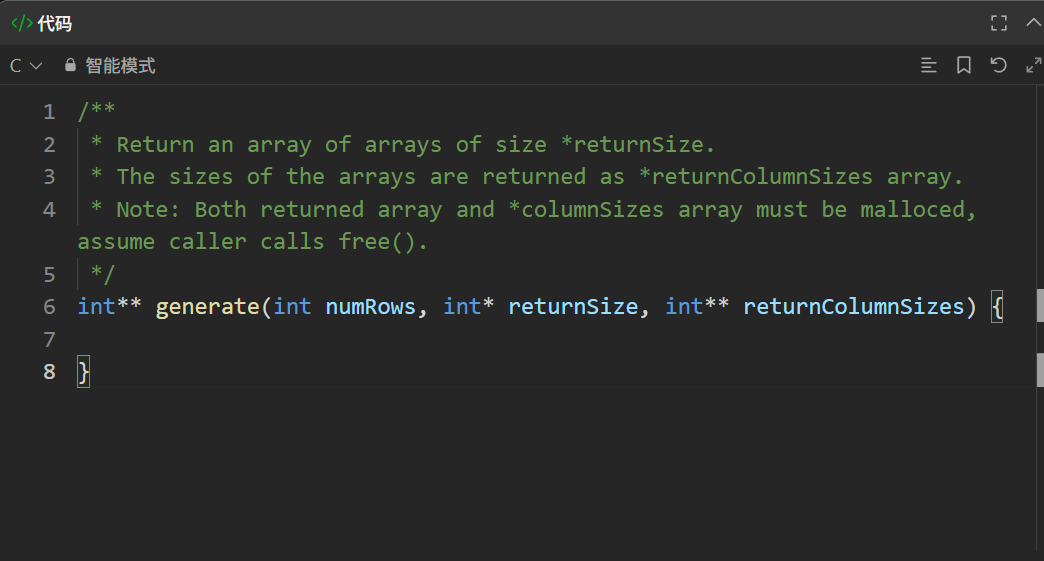
这里要传入的参数就比C++版本的多得多了,由图可见上面有一堆绿色的注释,简单来说就是:
returnSize是这个二维数组有几行,returnColumnSize是这个数组有几列,并且返回时的数组必须都是要由自己开空间得来的。
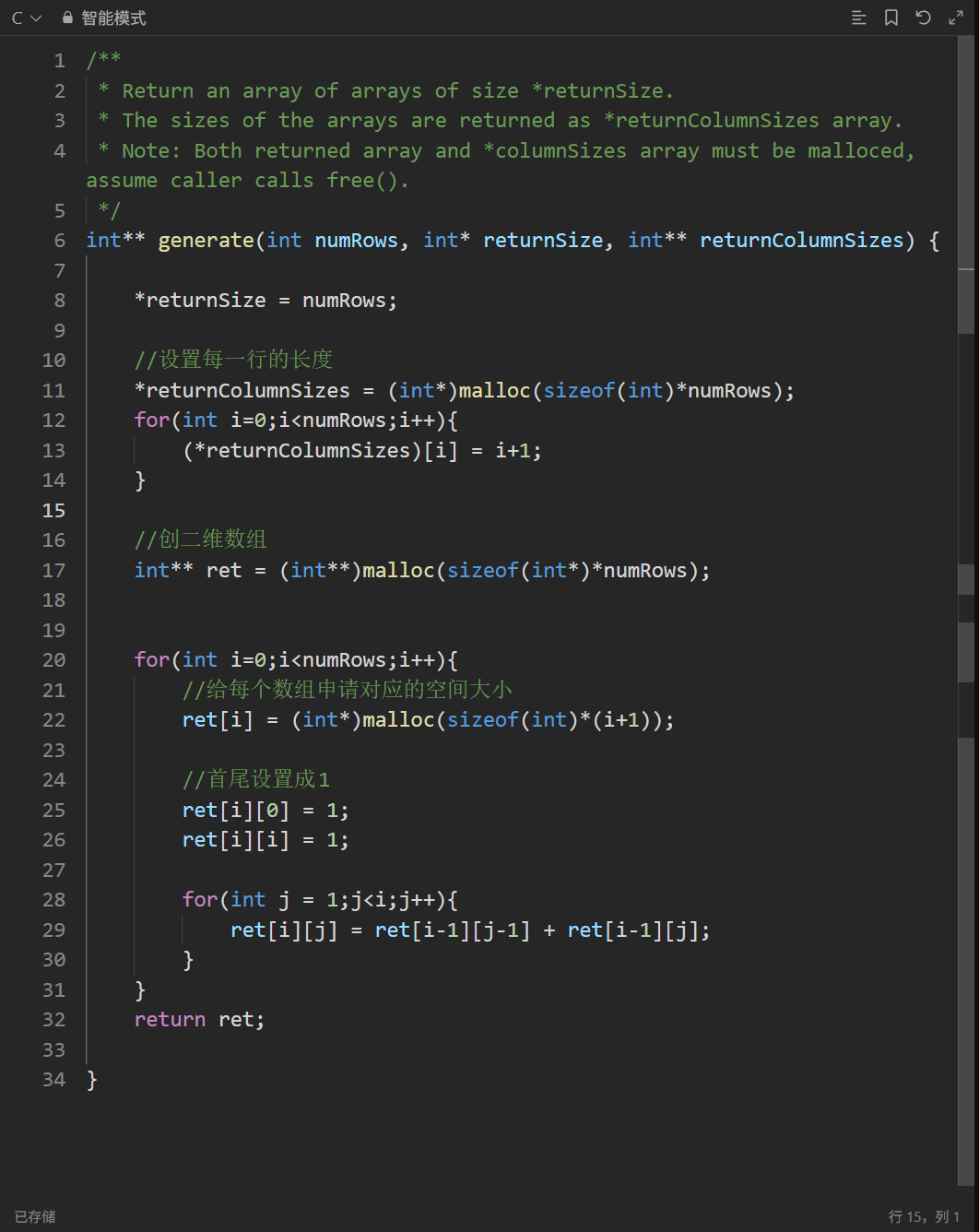
*returnColumnSize是一个指针数组的地址,而returnSize是int类型数组的地址想要实现二维数组,那就要先创建一个指针数组,存放每一个整型数组的指针,在对每一个整型数组的书v就进行处理,就得到了杨辉三角的C语言版本。
代码入下:
那么以上就是本次所有的内容了
文章是自己写的哈,有什么描述不对的、不恰当的地方,恳请大佬指正,看到后会第一时间修改,感谢您的阅读~~~~
博主笔记:


