论文:DOVER: A Method for Combining Diarization Outputs
作者:Andreas Stolcke, Takuya Yoshioka
单位:Microsoft Speech and Dialog Research Group
时间:2020 arXiv v2 / ASRU 2019 相关工作
arXiv:
1909.08090任务:Speaker Diarization Output Combination,把多个 diarization 系统或多个通道的输出融合成一个更好的 diarization 结果
前言
在 ASR 中,如果有多个识别系统,常见做法是用 ROVER 做投票融合。它会先把多个识别结果按词对齐,然后在每个位置选票数最高的词。
说话人日志的模型输出融合怎么做?
比如我们有 7 个麦克风通道,每个通道都跑了一遍 diarization:
text
channel 1 -> diarization hypothesis 1
channel 2 -> diarization hypothesis 2
...
channel 7 -> diarization hypothesis 7我们想输出融合得到一个更好的结果。
相比 ASR, diarization 的标签拥有排列不变性,即不同系统的 speaker_1 不一定是同一个人。
比如同一段音频,两个系统可能输出:
text
系统 A:
speaker_A1 -> 张三
speaker_A2 -> 李四
系统 B:
speaker_B1 -> 李四
speaker_B2 -> 张三这两个系统本质上可能都正确,但 label 编号相反。
并且 diarization 输出是连续时间轴上的分段,不是离散词序列。
论文提出了 DOVER(diarization output voting error reduction):先把不同系统的 speaker label 映射到同一个标签空间,再在每个时间区域做加权多数投票。
一、问题描述
论文把第 i i i 个 diarization 输出记为:
D i = ( L i , B i , E i ) D_i=(L_i,B_i,E_i) Di=(Li,Bi,Ei)
其中:
| 符号 | 含义 |
|---|---|
| L i = { l i j } j = 1 n i L_i=\{l_{ij}\}_{j=1}^{n_i} Li={lij}j=1ni | 第 i i i 个输出中的 speaker label 序列 |
| B i = { b i j } j = 1 n i B_i=\{b_{ij}\}_{j=1}^{n_i} Bi={bij}j=1ni | 每个 segment 的开始时间 |
| E i = { e i j } j = 1 n i E_i=\{e_{ij}\}_{j=1}^{n_i} Ei={eij}j=1ni | 每个 segment 的结束时间 |
| n i n_i ni | 第 i i i 个输出中的 segment 数 |
每个 segment 满足:
b i j < e i j b_{ij}<e_{ij} bij<eij
同一个 diarization 输出内部,segment 按时间排列:
e i j ≤ b i , j + 1 e_{ij}\le b_{i,j+1} eij≤bi,j+1
DOVER 的输入是 N N N 个 diarization 输出:
{ D 1 , D 2 , ... , D N } \{D_1,D_2,\ldots,D_N\} {D1,D2,...,DN}
同时可以给每个输出一个权重:
{ w 1 , w 2 , ... , w N } , w i ≥ 0 \{w_1,w_2,\ldots,w_N\},\quad w_i\ge 0 {w1,w2,...,wN},wi≥0
输出是一个共识结果(consensus diarization):
D ∗ D^* D∗
二、DOVER 算法流程
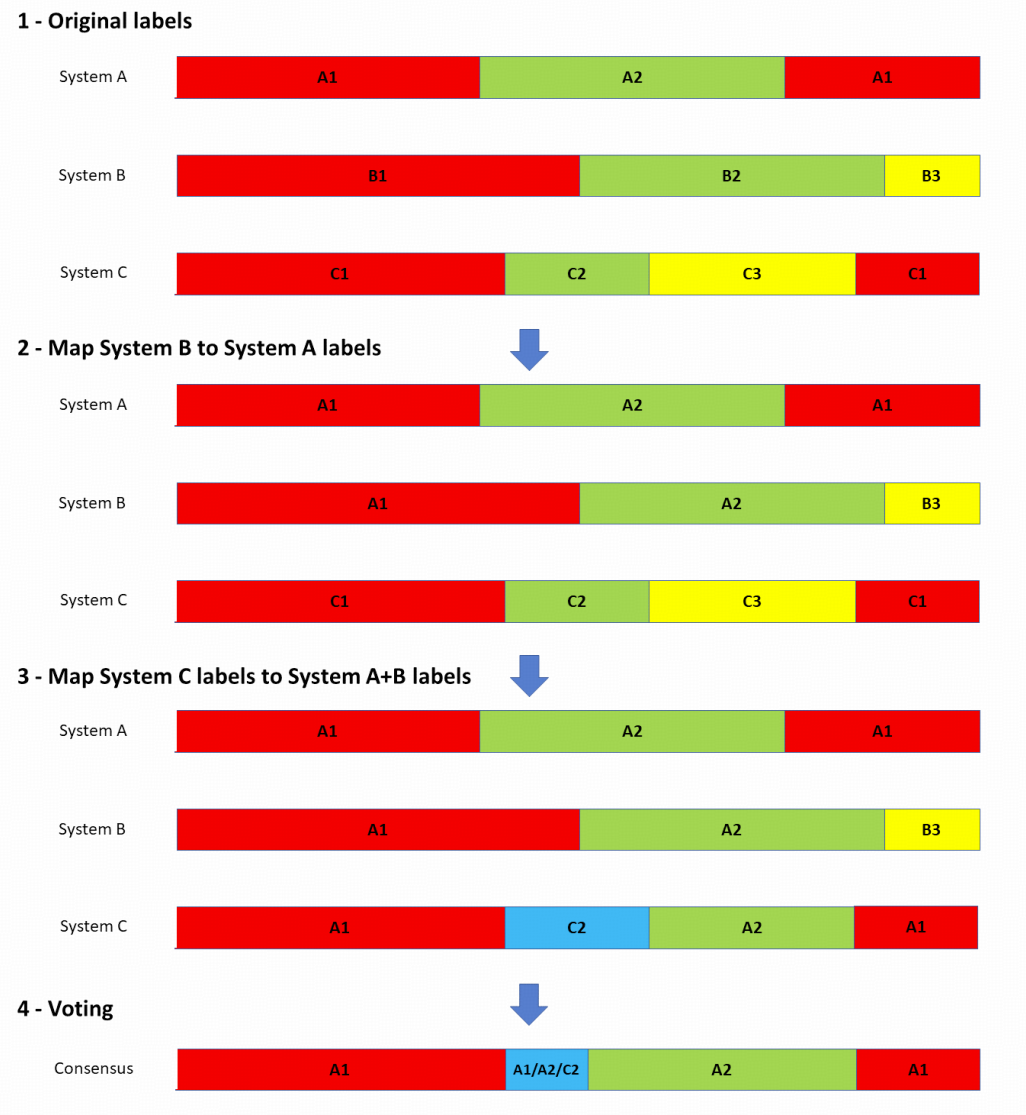
图1 3 套模型输出融合,B3 代表系统 B 的 speaker_3
DOVER 可以拆成两个阶段:
text
阶段一:speaker label mapping,将不同排列的标签映射到同一个空间
阶段二:region-wise label voting,切分细小区域进行投票2.1 speaker label mapping
假设有两个 diarization 输出
D A , D B D_A,\quad D_B DA,DB
它们的 speaker label 分别是
A 1 , A 2 , ... , A m A_1,A_2,\ldots,A_m A1,A2,...,Am
和
B 1 , B 2 , ... , B n B_1,B_2,\ldots,B_n B1,B2,...,Bn
DOVER 要找一个映射
M : A i → B j M:A_i\rightarrow B_j M:Ai→Bj
使得映射后的两个 diarization 输出之间 DER 最小。
换句话说,如果 A i A_i Ai 和 B j B_j Bj 在时间上高度重叠,它们就更可能是同一个真实 speaker。
可以用重叠时长定义匹配分数:
s ( A i , B j ) = d u r ( A i ∩ B j ) s(A_i,B_j)=\mathrm{dur}(A_i\cap B_j) s(Ai,Bj)=dur(Ai∩Bj)
其中 d u r ( ⋅ ) \mathrm{dur}(\cdot) dur(⋅) 表示时间长度。
于是 label mapping 可以看成一个二项匹配问题:
text
左边:系统 A 的 speaker labels
右边:系统 B 的 speaker labels
边权:两个 speaker label 的重叠时长目标是找到总重叠最大,或者等价地 DER 最小的匹配。
这个问题可以用 Hungarian algorithm 高效求解。
如果有 N > 2 N>2 N>2 个 diarization 输出,DOVER 采用增量映射,如图 1 1~3 步所示:
假设输入顺序是:
D 1 , D 2 , ... , D N D_1,D_2,\ldots,D_N D1,D2,...,DN
- 先把 D 2 D_2 D2 的标签映射到 D 1 D_1 D1 的标签空间;
- 再把 D 3 D_3 D3 映射到已经对齐的 D 1 , D 2 D_1,D_2 D1,D2 标签空间;
- 继续处理 D 4 , ... , D N D_4,\ldots,D_N D4,...,DN;
- 最终所有输出都使用统一 speaker label 空间。
2.2 冲突处理
在映射到同一个空间的过程中,可能存在第 i i i 个 diarization 输出在分别和前面 i − 1 i-1 i−1 个已对齐输出做 label mapping 时,得到的映射关系彼此矛盾。
比如前面两个系统已经对齐到了统一标签空间:
text
全局 speaker A
全局 speaker B现在要把第 3 个系统的输出映射进来。第 3 个系统自己的标签是:
text
C1
C2DOVER 会分别比较:
text
C 系统 vs 之前的系统 1
C 系统 vs 之前的系统 2每次比较都会产生一组建议映射。
比如一种冲突是:
text
C1 -> A
C2 -> A即第 3 个系统里的两个不同 speaker label C1 和 C2,都想映射到同一个全局 speaker A。
另一种冲突是:
text
C1 -> A
C1 -> B即同一个当前 speaker label C1,在和不同历史系统比较时,被建议映射成两个不同的全局 speaker。
论文的解决方式是如果多个映射建议冲突,就保留时间重叠最长的那一对。
设当前系统里的 speaker label 是 l l l,已有全局 speaker label 是 r r r,它们在时间轴上的总重叠时长为
d ( l , r ) = d u r ( l ∩ r ) d(l,r)=\mathrm{dur}(l\cap r) d(l,r)=dur(l∩r)
如果出现冲突,比如
text
C1 -> A,重叠 42 秒
C2 -> A,重叠 18 秒那就保留
text
C1 -> A丢掉
text
C2 -> A因为 C1 和 A 的共同说话时间更长,更可能是同一个真实 speaker。
这也是 DOVER 的一个局限:它是 greedy incremental mapping,映射结果依赖输入顺序。后来的 DOVER-Lap 用全局 cost tensor,就是为了缓解这种局部最优解问题。
2.3 输入顺序
DOVER 的 label mapping 是 greedy incremental 的。
这意味着第一个输入会成为锚点。
如果第一个系统很差,它的 speaker label 空间会影响后面所有 mapping。
论文提出用 centroid hypothesis 作为第一个输入。
具体做法是计算每个 hypothesis 到其他 hypothesis 的平均 DER
d ˉ i = 1 N − 1 ∑ j ≠ i D E R ( D i , D j ) \bar{d}i=\frac{1}{N-1}\sum{j\ne i}\mathrm{DER}(D_i,D_j) dˉi=N−11j=i∑DER(Di,Dj)
然后选择平均 DER 最小的那个作为锚点
i ∗ = arg min i d ˉ i i^*=\arg\min_i \bar{d}_i i∗=argimindˉi
直觉是和大家都比较接近的系统,更适合作为 label mapping 的参考。
论文实际使用的是类似思路:
把输入 hypothesis 按平均 DER 从小到大排序,centroid 放前面,outlier 放后面。
2.4 rank-based weighting
如果系统已经按质量排序,可以给排名靠前的系统更大权重。
论文使用的 rank-based 权重是:
w i = 1 i 0.1 w_i=\frac{1}{i^{0.1}} wi=i0.11
其中 i i i 是排序后的 rank。
说明一下这个权重。
i 0.1 = i 1 / 10 = i 10 i^{0.1}=i^{1/10}=\sqrt10{i} i0.1=i1/10=10i
| rank i i i | i 0.1 i^{0.1} i0.1 | w i = 1 i 0.1 w_i=\frac{1}{i^{0.1}} wi=i0.11 |
|---|---|---|
| 1 | 1.000 | 1.000 |
| 2 | 1.072 | 0.933 |
| 3 | 1.116 | 0.896 |
| 4 | 1.149 | 0.871 |
| 5 | 1.175 | 0.851 |
| 10 | 1.259 | 0.794 |
| 16 | 1.320 | 0.758 |
可以看到,衰减非常慢。
第 1 名权重是 1.0 1.0 1.0,第 10 名还有 0.794 0.794 0.794。
虽然 rank 1 系统更可靠,但 rank 2 和 rank 3 如果一致,仍然可以超过 rank 1。
所以作者设计这个权重的目的是
- 单个高质量系统有优势;
- 但两个低排名系统如果一致,仍然可以推翻一个高排名系统。
2.5 region-wise label voting
完成 label mapping 后,所有系统的 speaker label 已经统一。
然后把所有输入系统的 speaker boundary 收集起来,用这些边界切分时间轴。
例如三个系统的边界合起来是:
text
0.0, 1.2, 2.0, 3.5, 4.1, 5.0那么 region 就是:
text
[0.0,1.2]
[1.2,2.0]
[2.0,3.5]
[3.5,4.1]
[4.1,5.0]每个 region 内,每个输入系统的 label 都不会变化。
设时间点或 region 为 t t t。
第 i i i 个 diarization 输出在 t t t 上的 speaker label 是:
L a b e l ( D i , t ) \mathrm{Label}(D_i,t) Label(Di,t)
对每个候选 speaker label l l l,DOVER 累加投票:
T ( l , t ) = ∑ i = 1 N w i 1 ( L a b e l ( D i , t ) = l ) T(l,t)=\sum_{i=1}^{N}w_i\mathbb{1}(\mathrm{Label}(D_i,t)=l) T(l,t)=i=1∑Nwi1(Label(Di,t)=l)
其中:
| 符号 | 含义 |
|---|---|
| T ( l , t ) T(l,t) T(l,t) | speaker label l l l 在时间 t t t 的加权票数 |
| w i w_i wi | 第 i i i 个 diarization 输出的权重 |
| 1 ( ⋅ ) \mathbb{1}(\cdot) 1(⋅) | 示性函数,条件成立为 1,否则为 0 |
票数最高的 label 是:
l ∗ ( t ) = arg max l T ( l , t ) l^*(t)=\arg\max_l T(l,t) l∗(t)=arglmaxT(l,t)
这部分如图 1 第 4 步所示。
2.6 speech / nonspeech 判断
设总权重为:
W = ∑ i = 1 N w i W=\sum_{i=1}^{N}w_i W=i=1∑Nwi
如果最高 speaker 票数至少达到一半:
T ( l ∗ , t ) ≥ W 2 T(l^*,t)\ge \frac{W}{2} T(l∗,t)≥2W
则输出:
L a b e l ( D ∗ , t ) = l ∗ ( t ) \mathrm{Label}(D^*,t)=l^*(t) Label(D∗,t)=l∗(t)
否则该 region 输出为 nonspeech。
即只有多数系统认为这里有某个 speaker,DOVER 才输出 speech。
三、DOVER 算法流程
text
输入:
N 个 diarization outputs: D1, D2, ..., DN
N 个系统权重: w1, w2, ..., wN
阶段一:label mapping
1. 按平均 DER 给所有 hypothesis 排序
2. 以第一个 hypothesis 的 label 空间为锚点
3. 对 i = 2 到 N:
对当前 Di 和之前所有已对齐输出做 label mapping
用 DER-minimizing / maximum-overlap criterion 找映射
如果映射冲突,保留 overlap duration 最大的映射
把 Di relabel 到统一 label 空间
阶段二:label voting
1. 收集所有输入输出中的 speaker boundary
2. 把时间轴切成最小 regions
3. 对每个 region:
计算每个 speaker label 的加权票数
找到票数最高的 speaker
如果最高票数 >= 总权重的一半:
输出该 speaker
否则:
输出 nonspeech
输出:
consensus diarization D*四、实验结果
论文主要在两个多麦克风会议数据集上验证 DOVER。
4.1 RT-07 conference meeting
第一个数据集来自 NIST 2007 Rich Transcription evaluation。
特点:
- 8 场会议;
- 来自 4 个录制地点;
- 每场会议有 3 到 16 个麦克风;
- 每场会议有 4 到 6 个参会人;
- 总共 31 个不同 speaker;
- 每场会议评测一个约 22 分钟的 speaker-labeled excerpt。
4.2 Project Denmark
第二个数据集是 Microsoft 内部会议数据。
特点:
- 5 场真实工作会议;
- 每场 30 分钟到 1 小时;
- 每场 3 到 11 个参会人;
- 有的用 7 个独立消费级设备录制;
- 有的用 7 通道圆形麦克风阵列录制;
- 参会人熟悉彼此,会议不是脚本化或表演式对话。
4.3 输入 diarization 系统
论文使用的是 ICSI diarization algorithm 的重新实现。
基本流程是:
text
均匀切分音频
-> 每个初始 segment 作为一个 speaker cluster
-> 提取声学特征
-> 用 GMM 建模 speaker cluster
-> agglomerative clustering
-> 每次合并后用 Viterbi 做 resegmentation
-> 用 BIC-like criterion 决定什么时候停止speaker cluster 之间的距离来自
一个 speaker 模型和两个 speaker 模型的 log likelihood 差异。
需要注意
这篇 DOVER 原论文没有处理 overlapping speech。
因此它的 DER 有一个天然 floor:重叠语音会变成 missed speech 或 speaker error。
后来的 DOVER-Lap 是专门为 overlap-aware diarization output 设计的扩展。
4.4 RT-07 实验结果
RT-07 实验中,作者使用三种输入特征:
MFCC(raw audio):直接从原始通道提 MFCC;MFCC(BF audio):先 beamforming,再提 MFCC;MFCC + TDOA:beamformed MFCC 加上通道间到达时间差特征。
结果如下。
| 输入特征 | 单通道最差 SpkrErr | 单通道平均 SpkrErr | 单通道最好 SpkrErr | DOVER SpkrErr | DOVER DER |
|---|---|---|---|---|---|
| MFCC raw audio | 21.69 | 14.13 | 8.41 | 10.39 | 18.91 |
| MFCC BF audio | 16.80 | 9.43 | 5.48 | 7.04 | 15.58 |
| MFCC + TDOA | 12.79 | 5.30 | 2.16 | 2.38 | 10.93 |
结论
第一,单通道结果差异很大。
例如 MFCC raw audio 下,最差通道 speaker error 是 21.69 % 21.69\% 21.69%,最好通道是 8.41 % 8.41\% 8.41%。
这说明:
通道选择非常重要,但真实系统里通常不知道哪个通道最好。
第二,DOVER 显著好于单通道平均值。
例如 MFCC + TDOA:
5.30 % → 2.38 % 5.30\%\rightarrow 2.38\% 5.30%→2.38%
第三,DOVER 通常接近 oracle best channel,它避免了"选错通道"的风险。
4.5 Project Denmark 实验结果
Project Denmark 实验使用三种 diarization 特征配置,以及一种 speaker ID 输出。
| 输入特征 | 单通道最差 SpkrErr | 单通道平均 SpkrErr | 单通道最好 SpkrErr | DOVER SpkrErr | DOVER DER |
|---|---|---|---|---|---|
| MFCC | 34.56 | 24.23 | 15.56 | 15.00 | 26.98 |
| MFCC + d-vector | 13.94 | 11.06 | 8.82 | 8.70 | 20.65 |
| MFCC + 3 d-vectors | 11.38 | 6.07 | 3.00 | 3.10 | 14.97 |
| Speaker ID | 2.18 | 1.86 | 1.42 | 1.20 | 13.06 |
这里也能看到同样趋势:
- DOVER 明显优于单通道平均;
- DOVER 通常接近甚至超过 oracle best channel;
- 即使单通道已经很强,DOVER 仍然可能继续降低 speaker error。
特别是 Speaker ID 这一行:
1.42 % → 1.20 % 1.42\%\rightarrow 1.20\% 1.42%→1.20%
说明即使每个通道的 speaker labeling 已经非常准确,多通道投票仍然能带来额外收益。
五、总结
DOVER 显式解决了 speaker label 的对齐问题,它可以将多个通道/模型输出结果融合,降低偶然错误,是很好的后处理模块。
局限是不支持 overlap-aware 输出;label mapping 是 greedy incremental,会依赖输入顺序,虽然论文用 centroid 排序和 rank weighting 缓解了这个问题,但本质上它仍然不是全局最优。
后来的 DOVER-Lap 使用 cost tensor 和 greedy K K K-partite matching,就是为了解决这个问题。