- 我的问题是:从底层网络计算的机制来看,BiLSTM 和 BERT(也就是 Transformer 架构)在处理这种长文本的'长距离序列依赖'时,它们的核心工作方式有什么本质区别?为什么在这个任务上,BERT 获取全局语义的能力会碾压 BiLSTM?"
首先是 BiLSTM :它的本质依然是串行计算 。虽然它有输入、遗忘、输出三个门控机制,能极大地缓解梯度消失问题,但它依然需要'一个词一个词'地按顺序读。如果一篇文章有 500 个词,第 1 个词的信息要经过 500 步才能传递到最后。在这个漫长的传递过程中,信息必然会发生严重的衰减和丢失。
而 BERT(Transformer 架构)则完全不同 :它使用的是 Self-Attention(自注意力机制) 。它抛弃了按顺序读的模式,直接开启了**'上帝视角'。在计算时,句子里的 任意两个词**,无论隔得有多远,它们之间都能直接进行一次矩阵乘法(点积),距离瞬间缩短为 1 步(O(1) 的复杂度)。
所以,BERT 不仅自带强大的预训练迁移学习知识,更因为这种一步到位的全局注意力机制 ,让它在处理咱们项目里几百词的长文本时,能够完美捕捉首尾的语义关联,最终分类效果彻底碾压了受限于串行信息衰减的 BiLSTM。"
"老师,LSTM 就像串行传话,相隔 100 个词就需要 100 步的传递,极其容易造成长距离信息的遗忘。而 BERT 的 Self-Attention 相当于打破了时间序列的限制,让所有的词同时在一个全连接的图里进行矩阵点积打分。它使得任意两个词语的语义交互距离强制缩短为 1 步,这也是为什么在处理咱们天池那几十万条长文本新闻时,BERT 能一眼看穿全局语义,碾压了 BiLSTM。"

导师提问: "你的权重是怎么按 F1 分数分配的?具体的计算策略是什么?"


为什么你要费劲捕获这种长距离依赖?


你把 TextCNN、BiLSTM 和 BERT 这种异构网络强行集成在一起,理论上是不对的,它们提取特征的空间都不一样,你怎么能这样直接做模型预测呢?"

为什么一定要一样长?(显卡的"强迫症")

- 如果你在写代码时偷了个懒,没有用 pack_padded_sequence 把这些 0 给'压缩/屏蔽'掉,直接把带有大量 0 的矩阵强行喂给了 BiLSTM,这会对你的模型训练、以及最终算出来的特征向量,造成什么毁灭性的打击?"

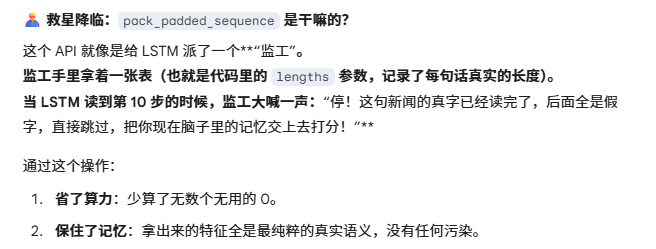



"混合精度 FP16 中,GradScaler 是干什么用的?没有它行不行?" (展示你的显存和精度管理能力) :"不行。FP16 虽然能让训练吞吐量翻倍并节省显存,但它的动态范围比 FP32 窄很多。在反向传播时,很多极其微小的梯度在 FP16 下会被直接截断为 0,引发'梯度下溢'。GradScaler 的作用是在反向传播前,将 Loss 乘上一个非常大的缩放因子把梯度放大,等权重更新前再缩放回来,从而完美兼顾了速度与精度。"
- 所谓的"加权软投票"到底怎么用代码实现?
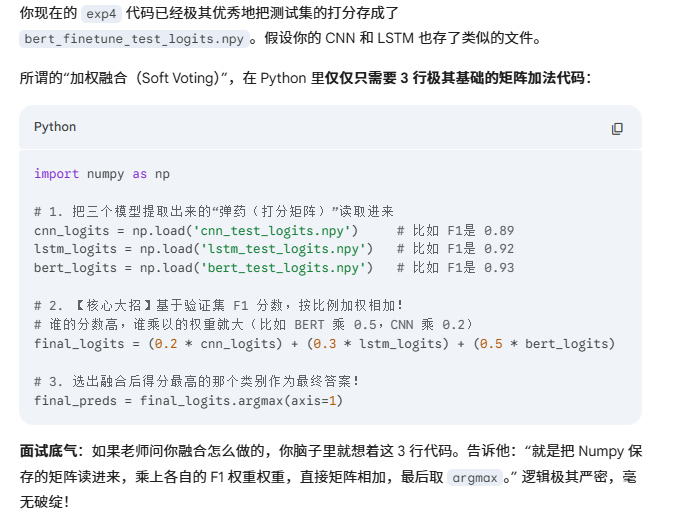
- 长尾优化与特征集成:设计类别加权交叉熵提升少数类敏感度;提取各模型在测试集输出的 Logits 矩阵,采用基于验证集 F1 分数的加权软投票(Soft Voting)策略实现降维融合。 做这个的意义是什么


- 同学,你已经有了很强的 BERT,为什么还要费力气把 CNN 和 RNN 融合进来?"


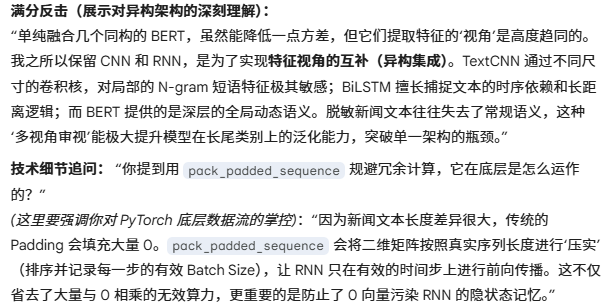
- "你提到用了 Soft Voting(软投票),它比普通的'少数服从多数'高级在哪里?"

- "为什么说硬投票会丢失置信度信息?你的加权软投票具体是怎么加权的?"

- 看你的代码只有单模型训练,你这个融合在工程上是怎么落地的?
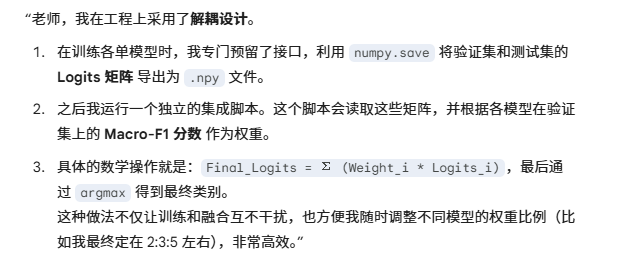
- 怎么 微调 的

- "你提到了用 Linear Warmup 保护底层预训练权重,为什么要保护?不加 Warmup 会发生什么?"
防止"新人的鲁莽"破坏"老兵的经验", BERT 微调属于迁移学习 ,我们需要在保护'预训练知识'和学习'新任务特征'之间做平衡。

- 你的数据既然是脱敏的数字 ID,那你后面用的 BERT 预训练模型,它自带的中文词表(Vocab)不就完全失效了吗?你是怎么解决这个冲突的?


- "CNN 通常用来处理二维图像(比如花卉),你是怎么用它来处理一维的文本数据的?你的卷积核大小 2, 3, 4 到底代表什么物理含义?"

卷积之后你接了一个 Max Pooling(最大池化),而且窗口大小等于整个句子的长度。为什么要这么做?这会不会丢掉很多信息?

BiLSTM + Attention 的时序魔法
新闻文本长短不一,你在 Batch 训练时肯定要做 Padding(补齐 0)。这些 0 会对 LSTM 造成什么影响?

为什么用了 BiLSTM 还要加 Attention?你的 Attention 在遇到刚才说的 Padding 0 时,是怎么处理的?"
因为bilstm认为每个词的贡献是极其不合理的,所以使用了注意力机制,做了mask操作,告诉模型哪些是真实词,哪些是0,送入softmax时候,把补齐的0的分数换成极小的负数

你说数据存在严重的'长尾类别不平衡',你是怎么解决的?为什么最后评估模型用的是 Macro-F1 而不是 Accuracy(准确率)?

pack__sequence与mask

你具体是怎么在代码里部署 GradScaler 的?加在哪个位置了?"
反向传播之前增大梯度,更新参数之前再缩回去


 也就是说,样本数越小,猜错的惩罚就越大,代价越高
也就是说,样本数越小,猜错的惩罚就越大,代价越高
不用过采样有两个原因 :
一是过采样少数类会引入重复样本,增加过拟合风险,尤其是在数据量已经有 20 万的情况下;二是加权损失在实现上更简洁,不改变数据分布,训练流程更稳定。两者本质上都是在调整类别的梯度贡献比例,但加权损失更优雅。
Label Smoothing 的原理是什么?在你的项目里解决了什么问题?
Label Smoothing 是把硬标签软化,正确类从 1 变成 0.9,其他类从 0 变成约 0.007。它在我的项目里解决两个问题:第一是防止过拟合,硬标签会驱动模型把 logit 推到极端值,softmax 输出趋近 one-hot,模型过度自信;第二是配合类别不平衡,少数类样本少,模型容易在这些类上过度拟合几个训练样本的模式,Label Smoothing 相当于正则化,让模型保持适度的不确定性。
考官心里很清楚:原生的 BERT 最多只能处理 512 个词。 而新闻类文本(尤其是咱们天池这个比赛)通常都很长,有的几千甚至上万个词。 他只要顺口问一句:"BERT 只能处理 512 个词,你的新闻那么长,剩下的词你直接扔掉了吗?"如果你答不上来,他就会怀疑你的 0.94 分是不是真的。

Logits(原始得分)直接相加 ,


你的硬件配置是怎样的?BERT 这么大,你是怎么跑通的?"

梯度累积解决了什么问题?和直接用大 batch 有什么区别?

"Transformer 为什么用 LayerNorm 而不是 BatchNorm?"

BERT 和 GPT 的本质区别是什么

CNN、RNN、Transformer 建模长距离依赖的能力有什么本质区别?

常用激活函数对比

注意力机制

soft(q*k的转置)*v

什么是 Embedding


数据集处理


