一、一段话总结
https://arxiv.org/abs/2505.18654
MTGR: Industrial-Scale Generative Recommendation Framework in Meituan
美团提出的MTGR(美团生成式推荐框架)是基于HSTU架构打造的工业级生成式推荐模型,核心解决了传统生成式推荐模型舍弃DLRM交叉特征导致性能下降的痛点,既保留了DLRM的全部特征(含交叉特征)又具备GRM的优秀可扩展性;该模型创新提出Group-Layer Normalization(GLN)和动态掩码策略优化模型性能、避免信息泄露,同时基于TorchRec对训练框架做了动态哈希表、嵌入查找优化等系统性改造,实现1.6x--2.4x的训练吞吐量提升;实验表明MTGR-large相比多年优化的DLRM基线,单样本前向推理实现65x FLOPs提升,线上CTR提升1.31%、转化量提升1.22%,推理成本降低12%,且已成功部署在美团外卖主流量推荐系统,支撑数亿用户规模,同时验证了其性能与计算复杂度间的幂律关系。
二、思维导图
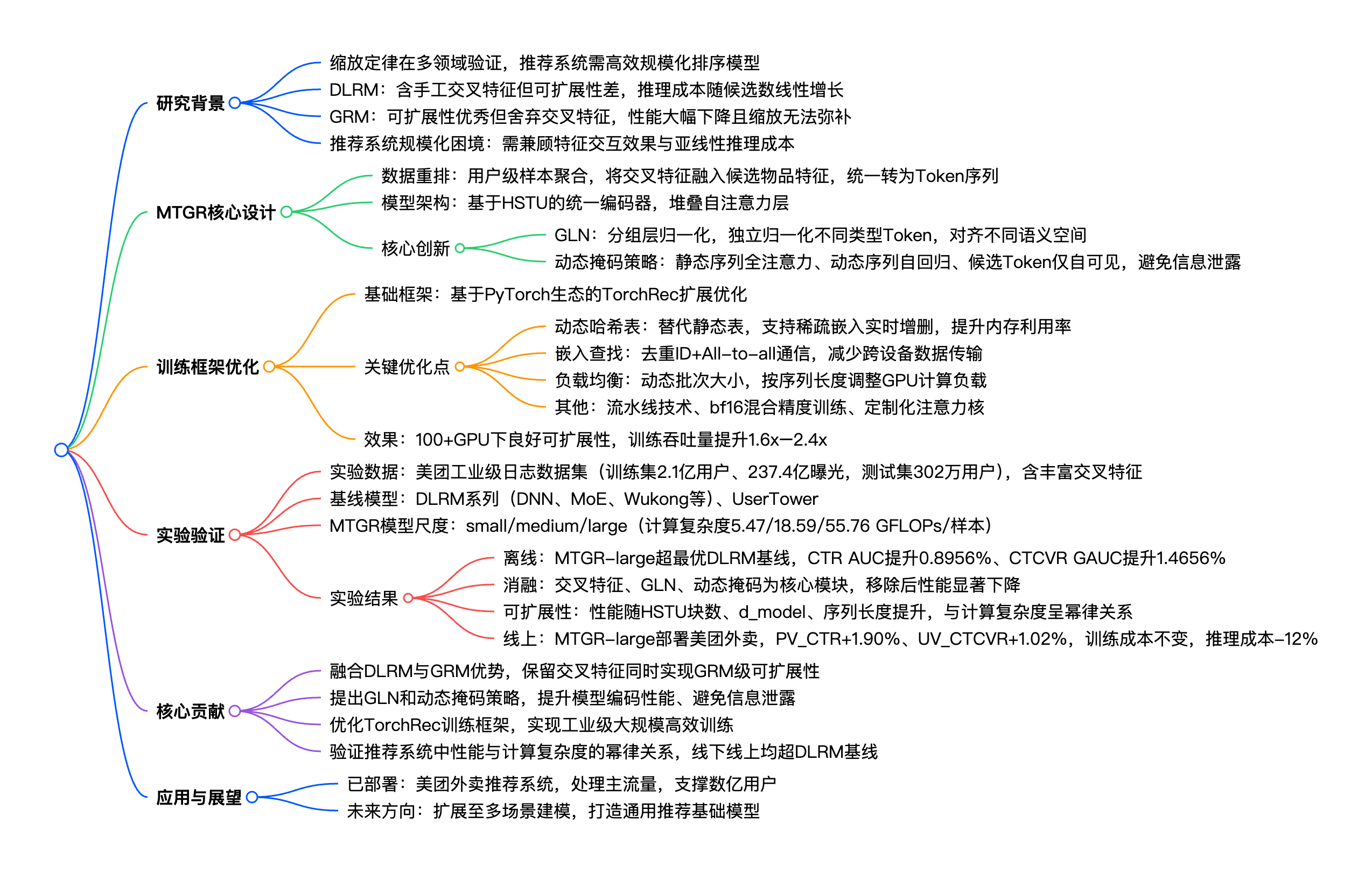
三、详细总结
本文是美团团队发表于CIKM '25的研究成果,提出MTGR(Meituan Generative Recommendation)工业级生成式推荐框架,解决了传统推荐模型规模化的核心矛盾,实现了性能与可扩展性的双重提升,并成功落地美团外卖推荐系统。以下是按研究脉络的详细总结:
(一)研究背景与问题提出
-
缩放定律的应用现状:缩放定律已在NLP、CV、信息检索等领域充分验证,工业推荐系统需在高QPS、低延迟要求下实现排序模型的高效规模化,现有研究分为DLRM(深度学习推荐模型)和GRM(生成式推荐模型)两类。
-
DLRM的痛点:沿用近十年,含精心设计的交叉特征(提升性能的核心),但存在两大问题:一是无法高效处理海量用户行为序列,学习能力受限;二是训练/推理成本随候选物品数量线性增长,规模化成本过高。
-
GRM的痛点:可扩展性优秀,通过Token化组织数据、Transformer架构实现高效注意力计算,但其基于下一个Token预测的建模方式需舍弃交叉特征,导致模型性能大幅下降,且单纯缩放模型无法弥补该损失。
-
核心研究问题:如何构建既能利用交叉特征保证性能,又具备GRM可扩展性的推荐排序模型,同时实现亚线性的推理成本。
(二)MTGR的核心设计
MTGR的核心思路是融合DLRM和GRM的优势,通过数据重排、架构创新、策略优化实现性能与可扩展性的平衡,基于HSTU(分层序列转导单元)架构建模。
1. 用户级样本聚合与数据重排
-
将交叉特征融入候选物品特征,按用户聚合候选样本,实现用户表示复用,大幅减少训练/推理的计算冗余;
-
将所有特征(用户、序列、实时行为、候选物品)统一转换为Token序列,统一输入维度为d_model,适配Transformer自注意力架构,形成公式Feat_D=Concat(Feat_U, Feat_Ṡ, Feat_Ṙ, Feat_I)。
2. 基于HSTU的统一编码器
-
采用编码器-only架构,堆叠自注意力层和MLP,对Token序列进行端到端编码;
-
自注意力块中引入残差连接,保证模型深度可扩展性。
3. 两大核心创新策略
-
Group-Layer Normalization(GLN,分组层归一化):对不同语义空间的Token(如用户特征、序列特征)独立归一化,保证不同域Token分布相似,提升异构信息建模能力;
-
动态掩码策略:为避免信息泄露,设置三类掩码规则:①用户/历史序列(静态序列)对所有Token可见;②实时行为序列(动态序列)遵循因果性,仅对后续Token可见;③候选物品Token仅对自身可见。
(三)MTGR训练框架的系统性优化
为支撑工业级大规模训练,美团放弃传统TensorFlow框架,基于PyTorch+TorchRec重构并深度优化,核心优化点如下,最终实现100+GPU下的良好可扩展性,训练吞吐量提升1.6x--2.4x:
-
动态哈希表:替代TorchRec的静态嵌入表,采用解耦的键/值存储架构,支持稀疏嵌入ID的实时增删,提升内存利用率,适配工业流式训练场景;
-
嵌入查找优化:通过ID去重+All-to-all跨设备通信,减少重复ID的传输开销,提升嵌入查找效率;
-
动态批次大小(BS):针对用户行为序列的长尾分布,按序列长度调整各GPU的本地批次大小,实现计算负载均衡,并优化梯度聚合策略保证计算逻辑一致性;
-
其他工程优化:①流水线技术(拷贝/分发/计算三流并行),减少I/O延迟;②bf16混合精度训练;③基于Cutlass设计定制化注意力核,加速训练。
(四)实验验证
实验基于美团工业级外卖推荐日志数据集开展(弥补公共数据集缺乏交叉特征的缺陷),设计离线、消融、可扩展性、线上四类实验,验证MTGR的有效性,核心实验配置与结果如下:
1. 实验基础配置
| 类别 | 关键信息 |
|---|---|
| 数据集规模 | 训练集:2.1亿用户、430万物品、237.4亿曝光、10.8亿点击、1.8亿下单;测试集:302万用户、314万物品、7.69亿曝光 |
| MTGR模型尺度 | small(3层、d_model=512、2头,5.47 GFLOPs/样本);medium(5层、d_model=768、3头,18.59 GFLOPs/样本);large(15层、d_model=768、3头,55.76 GFLOPs/样本) |
| 基线模型 | DLRM系列(DNN、MoE、Wukong、MultiEmbed)、UserTower(SIM/E2E),其中UserTower-SIM为最优DLRM基线 |
| 评估指标 | 离线:CTR/CTCVR的AUC、GAUC;线上:PV_CTR(单页浏览CTR)、UV_CTCVR(单用户浏览转化率) |
2. 核心实验结果
-
离线整体性能:MTGR-small已超越最优DLRM基线UserTower-SIM,MTGR-large实现CTR AUC提升0.8956%、CTR GAUC提升1.0748%、CTCVR AUC提升0.4990%、CTCVR GAUC提升1.4656%,且性能随模型尺度平滑提升;
-
消融实验:移除交叉特征、GLN、动态掩码任一模块,模型性能均显著下降,其中移除交叉特征会抵消MTGR-large相对DLRM的全部优势,验证了三大模块的核心作用;
-
可扩展性实验:MTGR的性能随HSTU块数、d_model、输入序列长度的增加而平滑提升,且性能与计算复杂度呈幂律关系,符合缩放定律;
-
线上实验:在美团外卖开展2%流量AB测试,MTGR-large相比迭代2年的最优DLRM基线,实现PV_CTR+1.90%、UV_CTCVR+1.02%,训练成本不变,推理成本降低12%,且推理成本随候选物品数量呈亚线性增长。
(五)核心贡献与应用
1. 核心贡献
-
首次融合DLRM和GRM的优势,在保留DLRM全部特征(含交叉特征)的前提下,实现了GRM级的优秀可扩展性;
-
提出GLN和动态掩码策略,分别提升了异构语义空间的编码性能、避免了建模中的信息泄露;
-
基于TorchRec完成工业级训练框架的系统性优化,实现100+GPU的高效训练,吞吐量提升1.6x--2.4x;
-
首次在工业级推荐系统中验证了性能与计算复杂度的幂律关系,线下线上实验均显著超越DLRM基线。
2. 实际应用
MTGR-large已成功部署在美团外卖推荐系统,处理主流量,支撑数亿用户的推荐服务,是近两年来美团推荐系统线下线上性能提升最大的模型。
3. 未来展望
将MTGR扩展至多场景建模,借鉴大语言模型的思路,打造具备通用知识的推荐基础模型。
(六)关键性能数字
-
单样本前向推理65x FLOPs提升(相比多年优化的DLRM基线);
-
线上转化量提升1.22%、CTR提升1.31%;
-
训练吞吐量提升1.6x--2.4x,推理成本降低12%;
-
MTGR-large的UV_CTCVR(核心商业指标)提升1.02%。
四、关键问题与答案
问题1(模型设计层面):MTGR如何解决传统GRM舍弃交叉特征导致的性能下降问题,核心设计思路是什么?
答案:MTGR并未沿用GRM舍弃交叉特征的建模方式,而是通过数据重排+特征融合的核心思路保留交叉特征:①将交叉特征作为候选物品特征的一部分,融入候选Token的构建中,而非单独剥离;②按用户聚合所有候选样本,复用用户表示,同时将用户、历史序列、实时行为、带交叉特征的候选物品全部统一转换为Token序列,适配生成式架构的同时保留DLRM的全部特征(含交叉特征);③结合判别式损失进行训练,而非单纯依赖GRM的下一个Token预测,最终实现既保留交叉特征保证性能,又具备GRM可扩展性的目标。
问题2(工程实现层面):MTGR基于TorchRec的训练框架做了哪些核心优化,为何这些优化能适配美团的工业级流式训练场景?
答案:MTGR对TorchRec的核心优化包括动态哈希表、嵌入查找优化、动态批次大小、流水线技术等,适配工业流式训练的关键原因:①动态哈希表替代静态嵌入表,支持稀疏ID的实时增删,解决了工业场景中用户/物品不断新增导致的ID溢出问题,同时提升内存利用率;②动态批次大小针对用户行为序列的长尾分布实现GPU负载均衡,避免了工业级海量数据中长序列导致的计算拥堵;③嵌入查找优化和流水线技术分别减少了跨设备数据传输开销和I/O延迟,适配工业级高吞吐、低延迟的训练要求;④所有优化均支持100+GPU的分布式训练,满足美团超大规模数据的训练需求。
问题3(实际应用层面):MTGR相比传统DLRM,在推理成本和可扩展性上的核心优势是什么,为何能成功落地美团外卖主流量推荐系统?
答案:1. 核心优势:①推理成本方面,MTGR通过用户级样本聚合,对一个请求中的所有候选物品仅做一次推理,替代了DLRM对每个候选物品单独推理的方式,使推理成本随候选物品数量呈亚线性增长,而非DLRM的线性增长,最终实现推理成本降低12%;②可扩展性方面,MTGR基于Transformer架构和HSTU编码器,结合GLN、动态掩码等策略,实现了性能与计算复杂度的幂律关系,模型尺度提升时性能平滑增长,且训练框架支持100+GPU的大规模训练,训练成本未随复杂度提升而增加。
- 成功落地的原因:①性能层面,线下线上均显著超越迭代2年的最优DLRM基线,核心商业指标(UV_CTCVR、PV_CTR)大幅提升,带来实际商业价值;②成本层面,训练成本保持不变,推理成本下降,适配美团外卖高QPS、低延迟的工业级要求;③工程层面,训练框架的优化适配了美团的流式训练场景,支持海量用户/物品的实时更新,且模型已完成工业级部署验证,能支撑数亿用户的主流量推荐。