一.索引
1.1聚簇索引
既是索引目录,也是真实数据。聚簇索引不用自己创建,每创建的每一张表都自动创建唯一的聚簇索引。
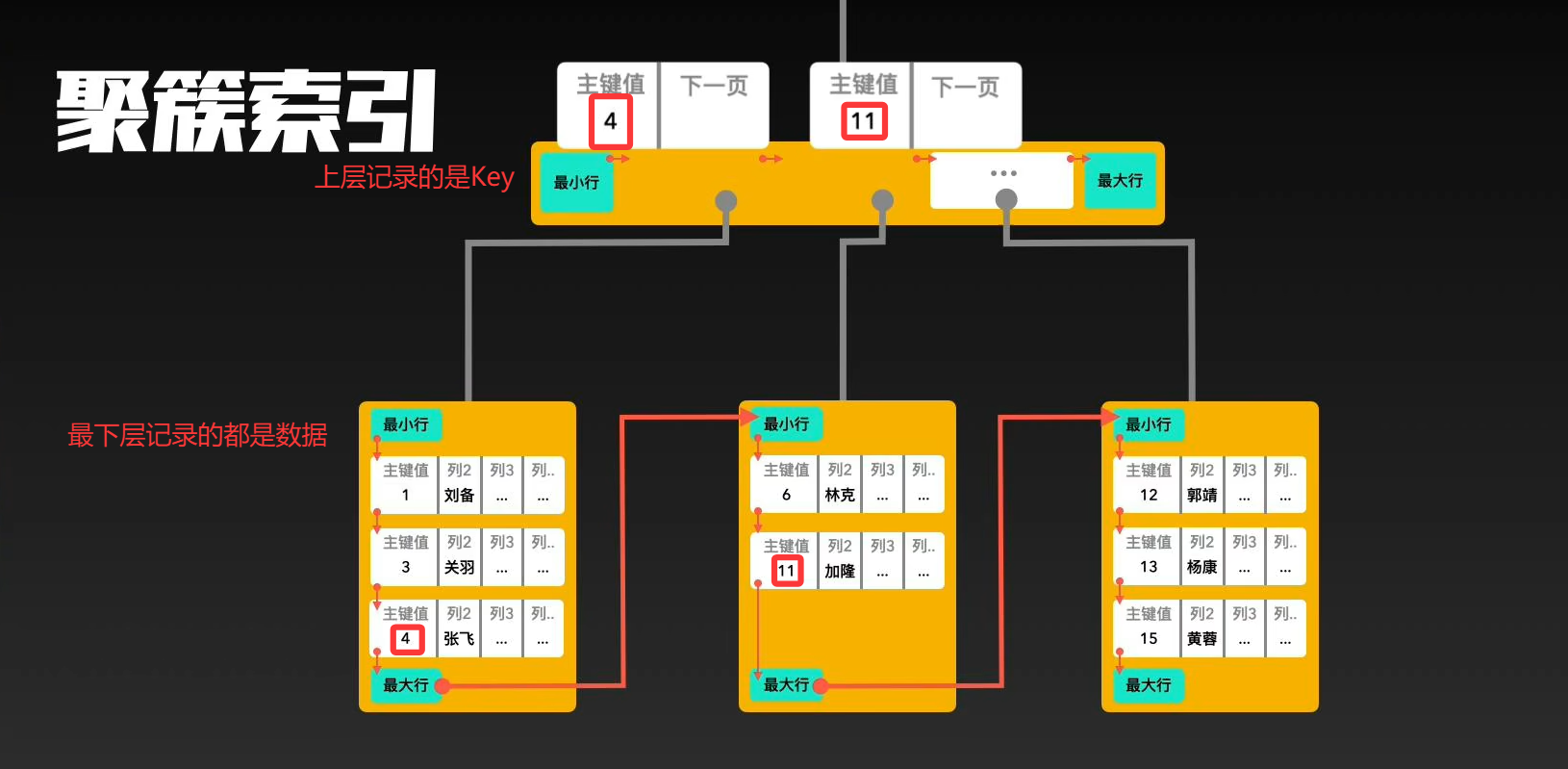
InnoDB 中主键索引(聚簇索引)的 B + 树,叶子节点直接存储完整的数据记录,这是聚簇索引的核心特征。
1.2非聚簇索引
也叫二级索引,辅助索引。除了聚簇索引外的其它每一个索引都会构成自己的非聚簇索引树。树的key就是这些索引树对应的列。树的非叶子节点与聚簇索引一样,只记录行里的这个索引值,作为目录存在。而树底层的叶子节点,记录改行的聚簇索引的Key(如果主键太长,那么非聚簇索引的叶子节点会占用更多的空间,索引不推荐使用太长的Key)
作用:
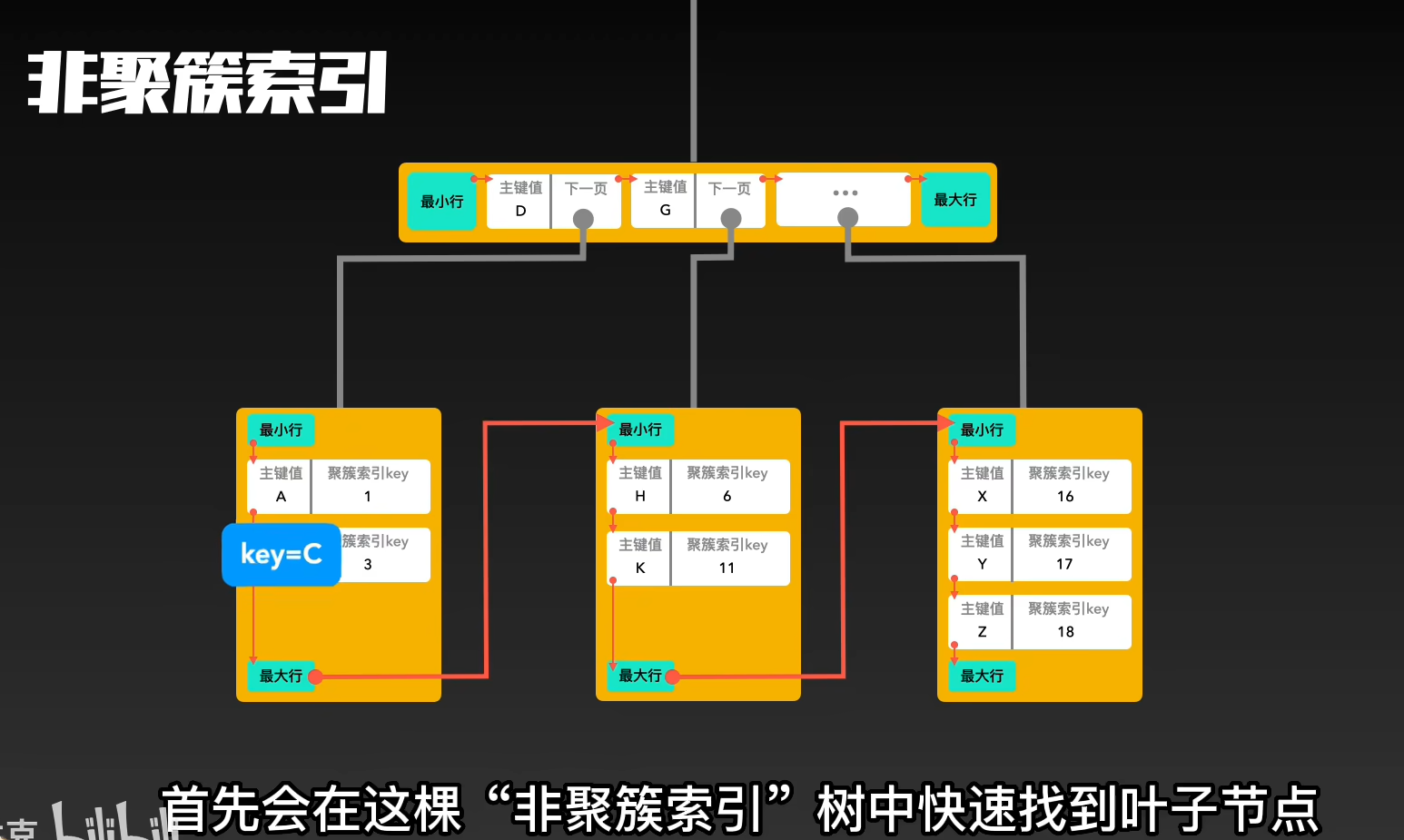
1.3区别
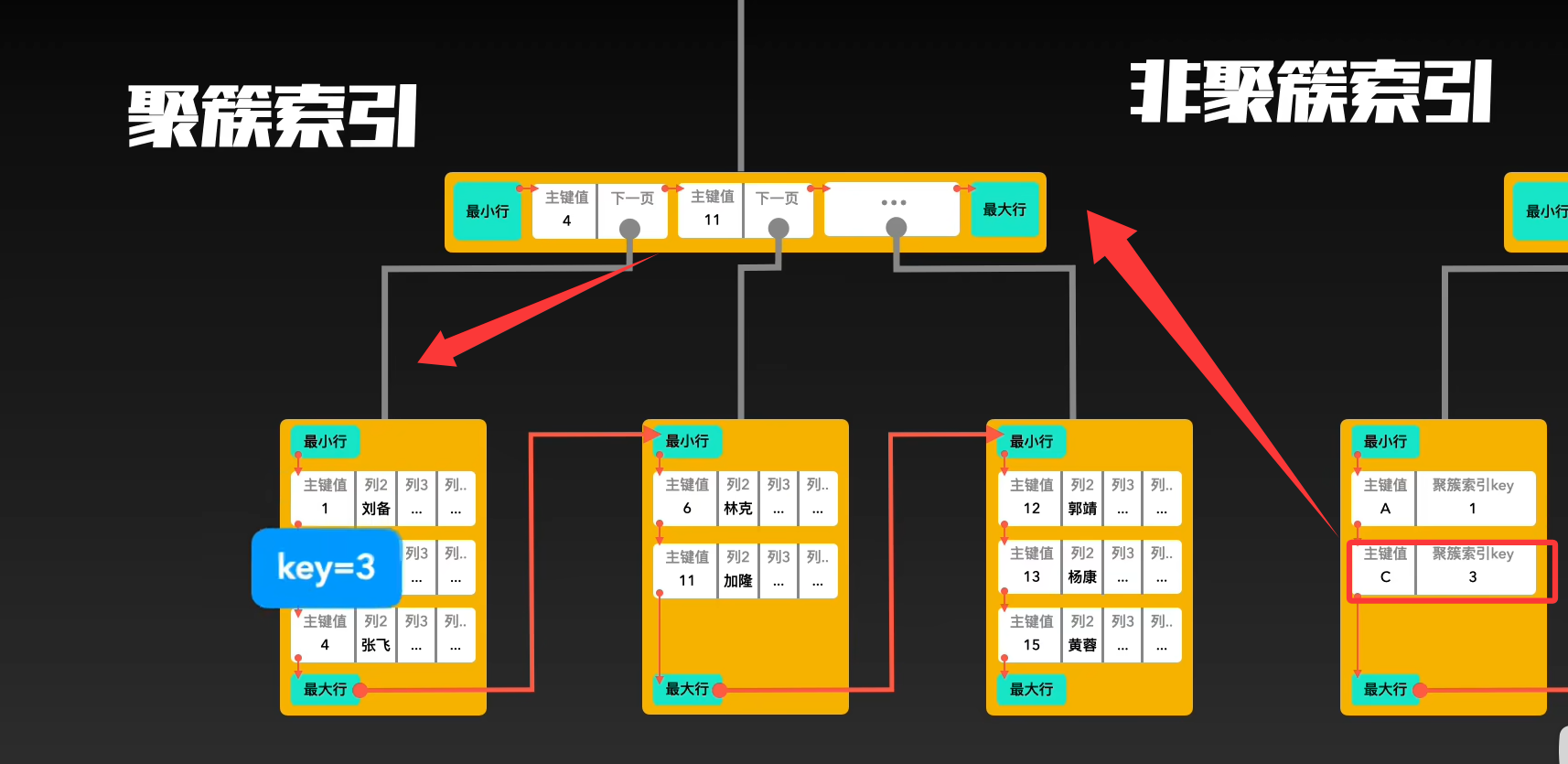
他们的目标都是提升查询速率的,而非聚簇索引是辅助进行查询的。聚簇索引存的是数据,非聚簇索引存的是聚簇索引。非聚簇索引要通过拿到聚簇索引,才可以取得具体数据(叫回表查询)。
二.回表与否分析
2.0什么时候需要回表
👉 结论:只要查询 / 过滤用到了不在当前索引里的列,就必须回表。
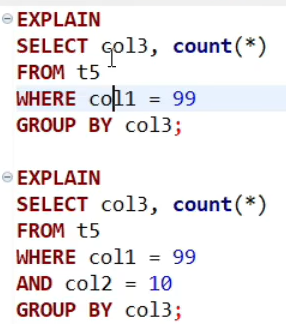
2.1上面的查询直接通过索引取数据
sql
INDEX idx_col1_col3 (col1, col3)
sql
SELECT col3, count(*)
FROM t5
WHERE col1 = 99
GROUP BY col3;- 过滤:
col1 = 99(符合联合索引最左前缀) - 查询列:
col3(在联合索引里) - 分组:
GROUP BY col3(也在联合索引里) - 所有需要的数据都在联合索引的叶子节点里 ,不需要回表,直接从索引取数 → 这叫覆盖索引。
完整执行步骤:
-
MySQL 看到 WHERE col1 = 99 发现 col1 是联合索引 (col1, col3) 的第一列→ 走 联合索引 B + 树
-
在联合索引 B + 树 查找 从根节点往下找,快速定位到所有 col1=99 的叶子节点
-
**重点来了:叶子节点里天然有 col3!**你找到的每条数据都是:
col1=99 | col3=? | id=?→ col3 直接就在索引里,不需要去表里拿!
-
直接在索引里完成 GROUP BY col3不需要回表不需要查主键索引不需要读真实数据
-
统计 count (*),返回结果
2.2下面的查询
sql
INDEX idx_col1_col3 (col1, col3)
sql
SELECT col3, count(*)
FROM t5
WHERE col1 = 99
AND col2 = 10 -- 关键:col2 不在联合索引 (col1, col3) 里
GROUP BY col3;- 过滤:
col1 = 99能走联合索引,但col2 = 10这个条件不在索引里 - 所以 MySQL 只能先通过联合索引找到所有
col1=99的行,拿到主键id - 再回表 (去主键索引 B + 树)查完整行,才能判断
col2是否等于 10 - 最后再对符合条件的行做
GROUP BY col3和count(*)
位置执行步骤:
-
**MySQL 依然走联合索引 (col1, col3)**因为 col1=99 能用上
-
找到所有 col1=99 的叶子节点拿到:
col1=99 | col3=X | id=123 -
关键问题:col2 不在联合索引里! MySQL 现在不知道 col2 是多少!索引里没有!
-
必须回表! 拿着主键 id=123去主键索引(聚簇索引) 查整行数据才能拿到 col2 的值
-
判断 col2 是否等于 10符合条件 → 保留不符合 → 丢弃
-
最后再分组、统计
2.3什么时候可以直接使用索引访问数据
核心条件:覆盖索引(Covering Index)
满足下面两点,就可以直接从索引叶子节点拿数据,不用回表:
- 查询的所有列(SELECT 里的列、WHERE/GROUP BY/ORDER BY 里的列)都包含在当前索引里
- 不需要访问主键索引之外的其他字段
2.4我的比喻
我拿快递驿站打比方:联合索引就像快递盒子挂的彩灯(一输入号码就会亮自己颜色的灯),MySQL拿到WHERE了,会看里面的变量有没有在联合索引的,只要符合最左匹配原则,那么就不论后面的变量是不是在联合索引中,都会走联合索引,让对应的快递盒子亮灯。我们把直接拿走比作查询的东西全在联合索引内,把需要查快递单号签收比作有数据不在联合索引内。那么只要我们查询的东西全在联合索引就不用回表,反之就需要回表。
三.判断什么SQL需要优化
3.1优化SQL语句
3.1.1含复关联子查询和复杂函数的
1)关联子查询
1>内部执行过程
sql
select *
from A
where id in (
select id
from B
where ...
)MySQL 内部执行是这样的:
- 先去 A 表查一条数据
- 跑到 B 表执行一下子查询
- 再回到 A 表查第二条数据
- 又跑到 B 表执行一下子查询
- 反复循环......
结果:
**A 表有 10000 条数据,子查询就执行 10000 次!**这叫 【嵌套循环】,性能爆炸!
2>原因
- 会循环嵌套执行(外表多少条,子查询就跑多少次)
sql
MySQL 内部执行是这样的:
先去 A 表查一条数据
跑到 B 表执行一下子查询
再回到 A 表查第二条数据
又跑到 B 表执行一下子查询
反复循环......
结果:
A 表有 10000 条数据,子查询就执行 10000 次!这叫 【嵌套循环】,性能爆炸!- 无法高效利用索引
sql
MySQL 对子查询的优化非常弱!很多时候:
子查询不能用索引
子查询会产生临时表
子查询会做全表扫描
结果:
明明能走索引变快的 SQL,一用子查询就变成慢查询!- 会产生临时表,消耗大量资源
sql
子查询执行时:
MySQL 会创建临时表
把数据放进去
再去外层查询
最后删除临时表
结果:
数据量大 → 临时表爆内存 → MySQL 卡死、CPU 100%!3>解决方法
使用 JOIN 替代关联子查询
- 使用 JOIN 完成多表关联查询,让 MySQL 优化器生成最优执行计划
- 利用索引完成高效关联,避免嵌套循环与临时表
- 保证关联字段建立索引,提升多表查询速度
3.1.2避免使用select *
为什么?
- 查询无用字段,浪费 IO
- 无法使用覆盖索引 ,一定会回表
- 网络传输数据变大
正确写法
sql
SELECT id,name,age FROM user WHERE id=13.1.3建立合适的索引
哪些字段要建索引?
- WHERE 里经常查询的字段
- JOIN 关联的字段
- ORDER BY / GROUP BY 字段
哪些字段不要建索引?
- 大量重复值(性别、状态)
- 小表(数据 < 2000 行)
- 经常修改的字段
3.1.4隐式类型转换
sql
where id = '123' → 索引失效3.1.5like不要以 % 开头,可以以%结尾
sql
where name like '%张三' → 索引失效3.1.6不可以违背最左匹配原则
联合索引必须从左往右用,跳过第一个,后面全部失效!
联合索引 (a, b, c)
- where a=1 → 索引有效 ✅
- where a=1 and b=2 → 索引有效 ✅
- where a=1 and b=2 and c=3 → 索引有效 ✅
- where b=2 → 索引失效 ❌
- where c=3 → 索引失效 ❌
- where a=1 and c=3 → 只用到 a,b、c 失效 ❌
3.1.7不要使用!= 、 <> 、is not null
MySQL 认为这些条件 "范围太大、不确定",干脆不走索引!
为什么?
!=/<>:不等于,范围太大is not null:不确定哪些不为空
3.1.8使用 OR 连接无关条件
OR 只要有一个条件没索引,整个索引全部失效!
例子:
索引 (name)
sql
where name = '张三' OR age = 18为什么?
- name 有索引
- age 没有索引
3.1.9避免频繁使用 DISTINCT、ORDER BY、GROUP BY
能不加就不加非常消耗 CPU 和内存
3.2分表
3.2.0为什么分表
3.2.1 单表数据量太大 → 查询 / 写入巨慢(最核心原因)
1)为什么分表反而不容易让B+树变深呢?
mysql的每张表其实都是一个B+树。
分表 = 把一棵巨大的 B + 树,切成很多棵小小的 B + 树每棵小树的数据量少 → 高度自然就变低 → 查询更快!
MySQL 的每张表在底层就是一棵 B + 树。分表就是把一棵大数据量的大树,拆成多棵小数据量的小树,让每棵树的高度变低,查询更快。
2)什么时候分?
- 单表 超过 1000 万行
- 单表大小 超过 10GB
- 查询变慢、索引变大、CPU 飙升
3)为什么要分?
B+ 树深度变高 → 磁盘 IO 变多 → 查询慢到爆炸不分表,你的项目早晚崩!
3.2.2 单表写入 QPS 太高 → 数据库扛不住
1)什么时候分?
- 写入并发高(下单、日志、消息、操作记录)
- 单表每秒几百上千次写入
- 锁竞争严重、出现死锁、慢查询
2)为什么分?
分表后,压力分摊到多张表一张表扛不住 → 10 张表一起扛
3.2.3 历史数据没人查,但占空间巨大
比如:订单表 3 年前的数据、操作日志、历史监控数据
1)为什么分?
- 热数据(最近 3 个月)放一张表
- 冷数据(历史)放归档表让热表变小、变快!
这叫 冷热数据分离(水平分表)
3.2.4业务增长快,必须提前扩容
电商、支付、用户量大的系统数据会爆发式增长不分表,后面重构成本极高
总结:
数据量未来会爆炸 → 提前分表!
四.怎么查慢SQL
4.1开启MySQL的慢查询日志记录,得到慢查询日志

4.2分析慢查询日志