一、文献基本信息
| 项目 | 内容 |
|---|---|
| 期刊 | Science China Information Sciences (SCIS) |
| 发表时间 | 2025年1月, Vol. 68, Iss. 1, 111102:1-88 |
| DOI | https://doi.org/10.1007/s11432-023-4127-5 |
| 作者单位 | 北京大学、浙江大学、中山大学、大连理工大学、南京大学、北京航空航天大学、复旦大学、华为等 |
| 论文数量 | 调研了601篇相关论文 |
| 关键词 | 深度学习、软件工程、软件基准测试、软件制品表示、综述 |
二、全面摘要总结
本文是首个面向任务的深度学习驱动软件工程综述,系统性地调研了601篇相关论文,覆盖了软件开发生命周期中的12个核心软件工程任务。文章从技术进展、数据集、深度学习模型、挑战与机遇四个维度,全面剖析了深度学习技术在软件工程领域的应用现状。
综述涵盖的12个软件工程任务及论文数量如下:
| 序号 | 软件工程任务 | 论文数量 |
|---|---|---|
| 1 | 需求工程 (Requirements Engineering) | 28 |
| 2 | 代码生成 (Code Generation) | 46 |
| 3 | 代码搜索 (Code Search) | 40 |
| 4 | 代码摘要 (Code Summarization) | 55 |
| 5 | 软件重构 (Software Refactoring) | 19 |
| 6 | 代码克隆检测 (Code Clone Detection) | 53 |
| 7 | 软件缺陷预测 (Software Defect Prediction) | 32 |
| 8 | Bug查找 (Bug Finding) | 114 |
| 9 | 故障定位 (Fault Localization) | 42 |
| 10 | 程序修复 (Program Repair) | 64 |
| 11 | Bug报告管理 (Bug Report Management) | 51 |
| 12 | 开发者协作 (Developer Collaboration) | 57 |
| 总计 | 601 |
核心贡献:
- 提供了深度学习在软件工程各任务中的技术全景图
- 系统总结了各任务的常用数据集和模型架构
- 深入分析了各领域面临的技术挑战与未来机遇
- 为研究者提供了明确的研究方向指引
三、研究背景
3.1 深度学习与软件工程的融合趋势
近年来,深度学习技术的飞速发展为软件工程领域带来了革命性的变革。传统软件工程方法在处理大规模、复杂的软件系统时面临诸多挑战,而深度学习凭借其强大的特征学习和模式识别能力,为解决这些挑战提供了新的途径。
驱动因素:
- 大规模代码库的涌现:GitHub等开源平台积累了海量代码资源,为深度学习模型训练提供了丰富的数据基础
- 计算能力的提升:GPU/TPU等硬件的发展使得训练大规模深度神经网络成为可能
- 预训练模型的成功:CodeBERT、CodeT5等代码预训练模型在多个软件工程任务上取得了突破性进展
- 工业界的强烈需求:软件开发效率提升、代码质量保障等实际需求推动了AI辅助开发工具的快速发展
3.2 研究现状的空白
尽管已有一些关于深度学习与软件工程结合的综述研究,但现有综述存在以下局限:
- 多聚焦于特定技术(如预训练模型)或特定任务
- 缺乏对软件工程全生命周期任务的系统性覆盖
- 未能全面揭示各任务的技术进展、挑战与机遇
本文正是填补这一空白,首次提供面向任务的深度学习软件工程全景综述。
四、当前研究现状
4.1 需求工程 (Requirements Engineering)
主要任务:
- 需求获取 (Requirements Elicitation) - 9篇论文
- 需求追踪 (Requirements Traceability) - 7篇论文
- 需求缺陷检测 (Smelly Requirements Detection) - 5篇论文
- 需求分类 (Requirements Classification) - 5篇论文
常用模型:
- Transformer模型:11篇论文
- 神经网络模型:13篇论文
- 预训练模型占比:36%
性能表现:
- 精确率(Precision)和召回率(Recall)通常超过80%
- F1分数通常超过75%
4.2 代码生成 (Code Generation)
主要贡献方向:
- 增强代码结构信息
- 特殊代码生成(SQL、汇编语言等)
- 多模态代码生成
- 可编译性保证
- 双学习框架
- 基于现有代码的生成
- 上下文感知生成
- 实用性提升
- 长依赖问题处理
常用数据集:
| 数据集 | 编程语言 | 规模 |
|---|---|---|
| CONCODE | Java | - |
| Lyra | Python | - |
| APPS | Python | - |
| CodeXGLUE | 多语言 | - |
4.3 代码搜索 (Code Search)
两种主要范式:
- 自然语言驱动的代码搜索
- 代码到代码搜索
常用数据集:
| 数据集 | 语言 | 规模 | 来源 |
|---|---|---|---|
| StaQC | Python, SQL | 267k | Stack Overflow |
| CoNaLa | Python | 2.8k | Stack Overflow |
| CodeSearchNet | 多语言 | 2M | GitHub |
| CoSQA | Python | 20k | Bing搜索日志 |
| xCodeEval | 多语言 | 11k | Codeforces |
4.4 代码摘要 (Code Summarization)
技术路线:
- 基于源代码序列的方法
- 基于抽象语法树(AST)的方法
- 基于控制流图(CFG)的方法
- 基于数据流图的方法
常用数据集:
| 数据集 | 语言 | 规模 |
|---|---|---|
| TL-CodeSum | Java | 87,136 |
| Deepcom | Java | 588,108 |
| Funcom | Java | 2.1M |
| CodeSearchNet | 6种语言 | 2M |
4.5 Bug查找与程序修复
Bug查找是研究最多的领域,共有114篇论文,涵盖:
- 静态缺陷检测
- 代码漏洞识别
- 安全漏洞发现
程序修复共有64篇论文,主要技术路线包括:
- 基于神经网络的补丁生成
- 基于预训练模型的修复
- 结合程序分析的混合方法
故障定位共有42篇论文,主要方法:
- 基于频谱的方法与深度学习结合
- 基于图神经网络的定位方法
五、主要图表分析
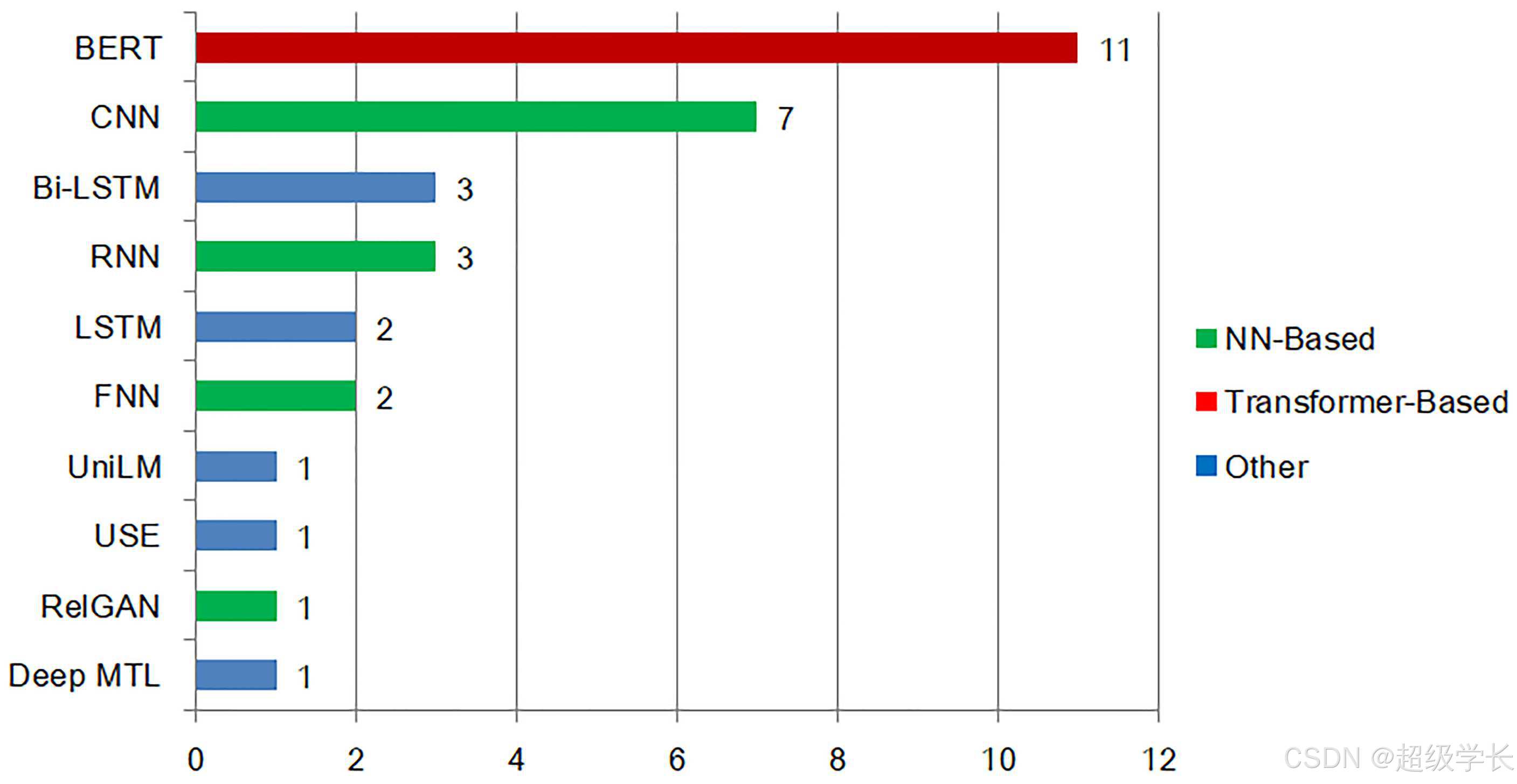
Figure 1: 深度学习模型在需求工程中的应用
图表说明: 该图展示了在需求工程研究中使用的各种深度学习模型分布,包括Transformer、神经网络(NN)、RNN、CNN、GNN等超过10种模型类型。
重要性: 揭示了Transformer和传统神经网络模型在需求工程领域具有竞争性和互补性,研究者需要根据具体任务选择或设计合适的深度学习模型。
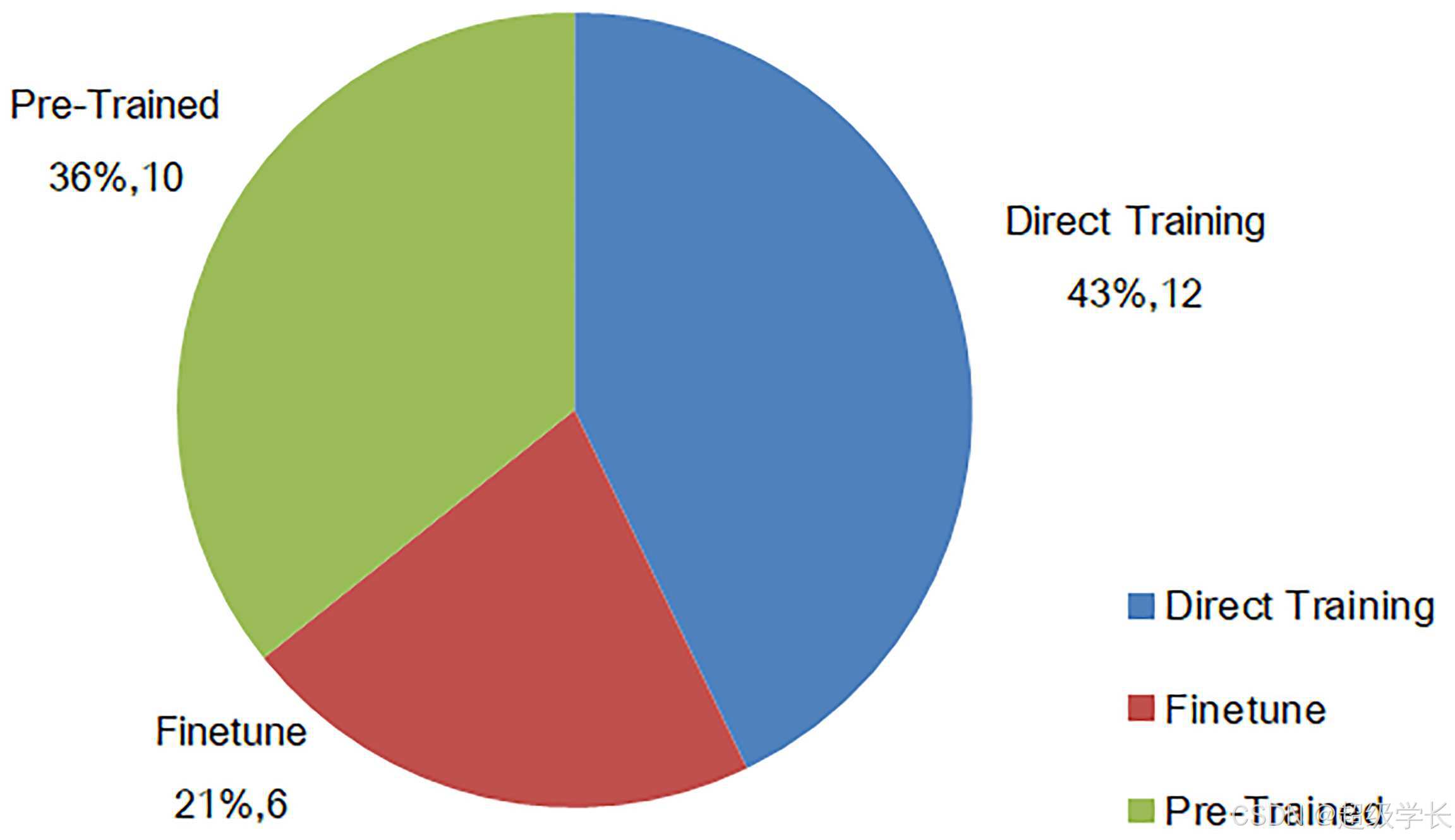
Figure 2: 深度学习模型使用比例
图表说明: 展示了预训练模型与从零训练模型的使用比例。研究表明36%的研究使用预训练模型。
重要性: 预训练模型可以节省时间和计算资源,但如果预训练数据集与目标任务不够相似,效果可能不理想。
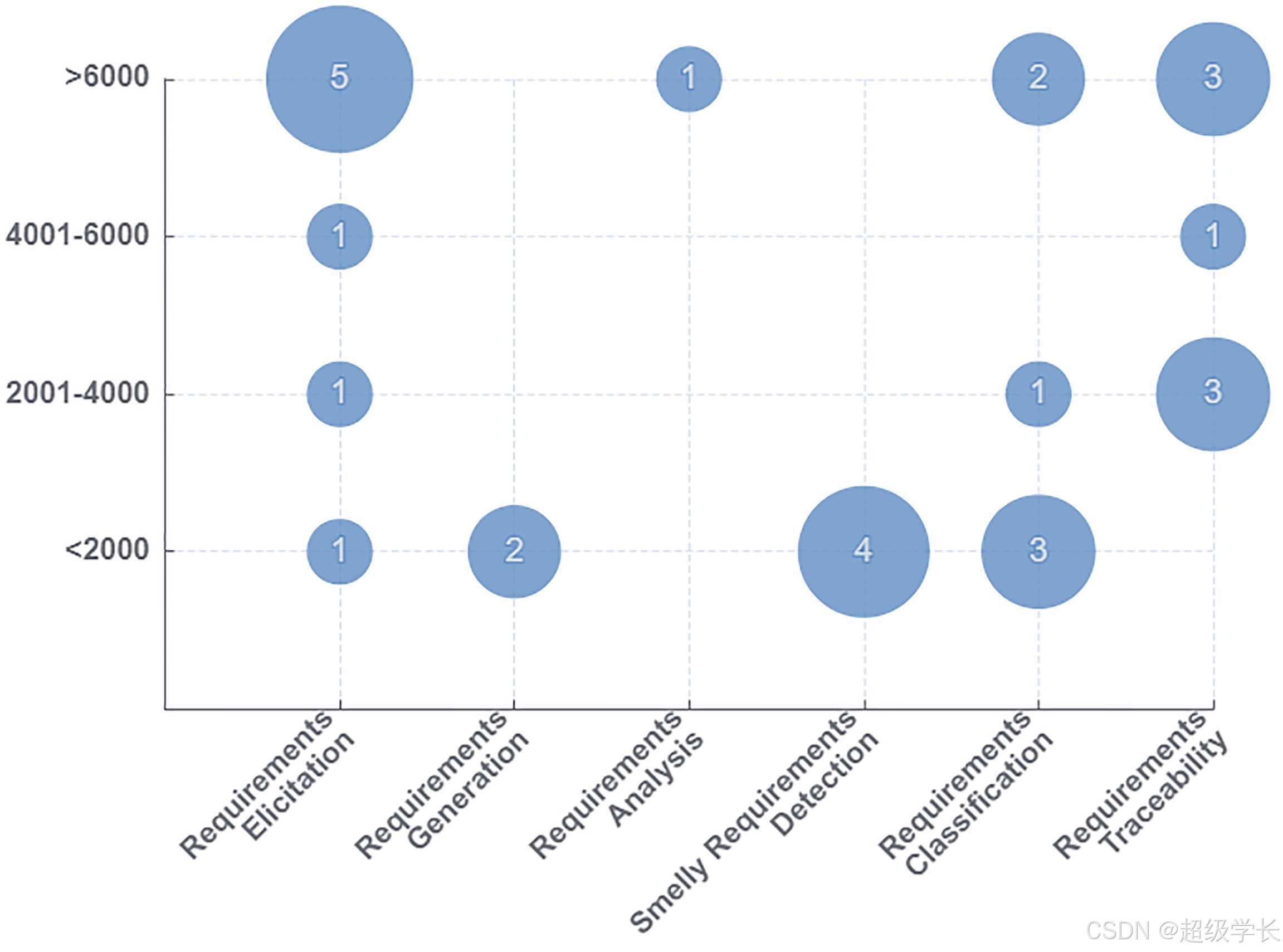
Figure 3: 需求工程研究数据集规模分布
图表说明: 展示了DL4RE研究中涉及的数据集规模分布情况。
重要性: 揭示了当前需求工程领域数据集规模偏小的现状,无法与GitHub上的开源代码规模相比,这是制约研究发展的重要因素。
六、挑战与机遇
6.1 共性挑战
数据层面:
- 高质量数据集匮乏,尤其是需求工程领域
- 现有数据集与实际项目场景差距较大
- 数据标注成本高、质量参差不齐
模型层面:
- 大语言模型(LLM)的幻觉问题
- 生成代码的安全性和正确性保障
- 模型可解释性不足
应用层面:
- 研究成果向工业实践转化困难
- 开发者对AI工具的信任度有待提高
- 长尾问题的处理能力不足
6.2 各领域特定挑战
需求工程:
- 公开需求的透明度低
- 缺乏项目级别的需求信息
代码生成:
- 不安全代码生成问题
- 基准测试与真实项目的差距
- LLM幻觉现象
代码搜索:
- 搜索结果质量保障
- 搜索意图歧义处理
- 效率与效果的权衡
代码摘要:
- 高质量数据集构建
- 多语言适应性
6.3 未来发展机遇
技术层面:
- 知识增强的代码生成:整合项目信息、相似代码片段等知识,提升LLM在特定领域的代码生成能力
- 数据集即软件:将数据集管理提升到软件工程层面,提高数据集的生产力、质量和安全性
- LLM增强的代码搜索:利用LLM的自然语言理解和代码语义理解能力提升搜索效果
- 多模态方法融合:结合源代码、字节码、API文档、设计文档等多源信息
应用层面:
- 工业场景落地:探索AI方法在真实工业环境中的可行性和可用性
- 开发者协作增强:利用深度学习优化开发者协作流程
- 全生命周期覆盖:实现从需求到部署的智能化辅助
七、未来发展趋势
7.1 技术演进方向
1. 大语言模型的深度应用
- GPT-4、CodeLlama等大模型在代码理解和生成方面的能力将持续提升
- 代码专用大模型将成为各软件工程任务的统一解决方案
2. 多模态深度融合
- 代码、自然语言、图表、视频等多种模态的联合理解
- 跨模态的软件制品生成与转换
3. 知识图谱与深度学习的结合
- 将领域知识、API知识等融入深度学习模型
- 提升模型的领域适应性和可解释性
7.2 应用发展趋势
1. 智能开发环境的普及
- AI辅助编程工具(如GitHub Copilot)将成为开发者的标配
- IDE深度集成AI能力,实现实时智能辅助
2. 软件质量的智能化保障
- 自动化的代码审查、缺陷检测和安全扫描
- 智能化的代码修复和优化建议
3. 软件工程流程的智能化
- 从需求到测试的全流程AI辅助
- 智能化的项目管理和协作支持
7.3 研究热点预测
- 低代码/无代码平台的智能化增强
- 软件供应链安全的AI检测与防护
- 遗留系统现代化的智能重构
- DevOps智能化(AIOps)
- 软件工程伦理与安全研究
八、研究价值与启示
8.1 学术价值
本综述为学术界提供了:
- 深度学习软件工程研究的全景图
- 各任务的技术路线和数据资源索引
- 未来研究的方向指引
8.2 实践价值
为工业界提供了:
- AI辅助开发工具的技术选型参考
- 深度学习技术在软件工程中的应用指南
- 技术落地面临的挑战预判
8.3 个人启示
作为首个面向任务的深度学习软件工程综述,本文具有里程碑意义。研究者可以:
- 选择具有研究潜力的任务深入探索
- 关注跨任务的通用技术和方法
- 注重学术研究与工业实践的结合
九、总结
本文是深度学习与软件工程交叉领域的重要综述,系统性地梳理了601篇论文在12个软件工程任务中的应用。文章不仅总结了技术进展,更深入分析了挑战与机遇,为该领域的未来发展指明了方向。
核心观点:
- 深度学习已深入软件工程全生命周期
- 大语言模型正在重塑软件开发范式
- 数据集质量和模型可解释性是当前主要瓶颈
- 学术研究与工业实践的结合是未来关键