一、定义与核心特征
机器学习作为人工智能的核心分支,其本质是通过设计高效算法,使计算机系统无需显式编程指令,即可从数据中自主挖掘内在规律与关联关系,并基于习得的模式完成预测、分类、决策等各类任务的技术体系。与传统编程的"指令驱动"模式不同,机器学习采用"数据驱动"的学习范式,可实现模型的自主迭代与性能优化。
💡 核心区分:传统编程"指令驱动"(固定逻辑)vs 机器学习"数据驱动"(自主学习),核心优势在于自适应数据变化、泛化能力更强。
传统编程依赖开发者预设的固定逻辑规则实现特定功能,当应用场景或数据分布发生变化时,需人工修改代码逻辑,灵活性较差;而机器学习模型通过对海量数据的统计分析与特征学习,能够自适应数据分布的动态变化,具备更强的泛化能力,可有效应对复杂场景下的任务需求。
机器学习的核心特征主要体现在三个方面:
-
数据依赖性:模型性能直接取决于数据的质量、规模及代表性,高质量数据是模型发挥作用的基础;
-
自主学习性:模型可通过持续迭代优化,逐步提升任务处理性能;
-
泛化性:能够将训练过程中习得的规律迁移至未见过的新数据,实现有效预测与决策。
其学习逻辑与人类归纳学习具有一致性,模型通过对样本数据的特征提取与模式识别,构建输入与输出之间的映射关系,无需人工干预即可完成复杂任务。本质而言,机器学习的过程就是通过算法不断调整模型参数,最小化预测值与真实值之间的误差,进而优化映射关系的过程。
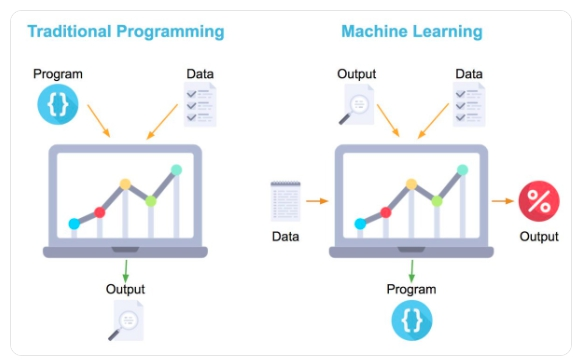 图1:机器学习与传统编程的核心逻辑对比
图1:机器学习与传统编程的核心逻辑对比
二、核心思想与理论基础
机器学习的核心思想根植于统计学习理论(Statistical Learning Theory, SLT),其本质是通过构建可解释、可优化的数学模型,拟合数据的真实分布,挖掘数据背后隐藏的潜在规律与内在关联,进而实现对未知数据的精准预测、科学决策与高效分类。与传统统计学仅注重数据描述与推断不同,机器学习更强调"自主学习"与"泛化能力",核心目标是让模型在未见过的新数据上依然能保持稳定的性能,这也是其区别于传统数据分析的核心特质。
其理论基础并非单一学科,而是多学科交叉融合的产物,核心涵盖四大领域,各领域在机器学习流程中承担着不同的支撑作用,缺一不可:
-
统计学:提供数据分布、概率推断、假设检验等核心逻辑,如极大似然估计用于参数求解;
-
线性代数:支撑高维数据处理、特征变换,如矩阵运算用于神经网络正向传播;
-
微积分:核心支撑参数优化,如梯度下降依赖求导找到损失函数最小值;
-
信息论:量化数据不确定性,如交叉熵作为分类任务损失函数。
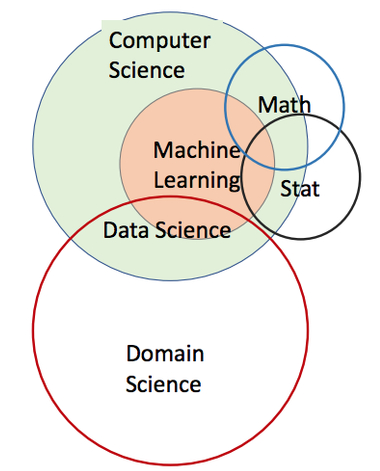 图2:机器学习的多学科理论基础
图2:机器学习的多学科理论基础
模型的学习过程本质上是从预设的假设空间(所有可能的映射关系集合)中,筛选出最贴合数据真实分布的最优假设,这一过程需严格兼顾两个核心目标:对训练数据的拟合度与对未知数据的泛化能力,二者的平衡是机器学习模型设计的核心难点,也是避免两类典型问题的关键:
💡 过拟合:模型过度贴合训练数据噪声,训练集性能优、测试集泛化差(常见于模型复杂、数据量不足);
💡 欠拟合:模型未学会数据核心规律,训练集与测试集性能均较差(常见于模型简单、特征工程不到位)。
为实现拟合度与泛化能力的平衡,实际训练中常采用正则化(L1正则、L2正则)、早停(Early Stopping)、数据增强、集成学习等策略:正则化通过对模型参数施加惩罚,降低模型复杂度,避免过拟合;早停通过监控验证集性能,在模型出现过拟合趋势时及时停止训练;数据增强通过扩充训练数据量、丰富数据分布,提升模型泛化能力;集成学习通过融合多个基础模型的预测结果,降低单一模型的过拟合风险,提升模型稳定性。
数据作为机器学习的核心输入,其质量与分布直接决定模型的最终性能,是模型发挥作用的前提与基础,高质量的数据需同时满足完整性、准确性、一致性与代表性四大核心要求,四者缺一不可。
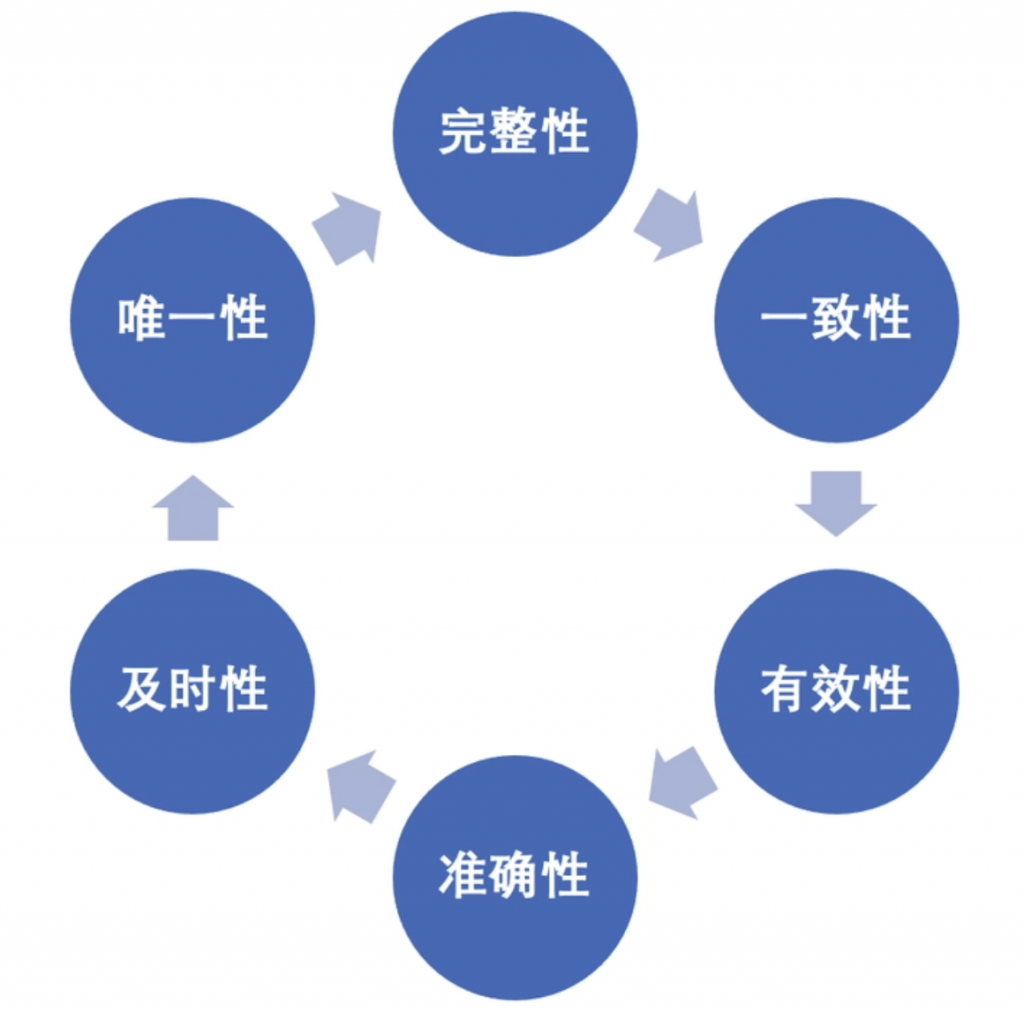 图3:机器学习高质量数据的四大核心要求
图3:机器学习高质量数据的四大核心要求
值得注意的是,数据规模与模型性能并非简单的正相关关系:在数据质量有保障的前提下,合理提升数据规模通常能增强模型的泛化能力,因为更多的数据能让模型更全面地学习数据规律;但如果数据质量低下(如存在大量异常值、缺失值),即使数据规模再大,也会导致模型训练偏差,甚至出现"垃圾进、垃圾出"的情况。此外,数据规模的提升也需要配套的高效算法与充足算力支撑,否则会导致模型训练效率极低,无法落地应用。
以图像分类(猫与狗区分)任务为例,进一步拆解理论在实践中的应用:模型首先通过卷积神经网络(CNN)提取图像的底层特征(像素值、边缘)、中层特征(纹理、轮廓)与高层特征(面部特征、肢体特征),这一过程本质是通过线性代数的矩阵运算实现特征变换;随后通过交叉熵损失函数,计算模型预测结果与真实标签的差异,这一过程依托信息论的交叉熵概念;最后通过梯度下降算法,对模型参数进行迭代更新,最小化损失函数,这一过程依赖微积分的求导原理。
此外,机器学习的理论基础还包含PAC学习(Probably Approximately Correct Learning)理论,其核心是量化模型的泛化能力,给出模型在未知数据上达到预设准确率的概率保证,为模型的性能评估提供了严格的理论支撑。
三、常见类型与适用场景
机器学习的类型划分核心取决于学习方式、数据标签的有无以及学习过程中的反馈机制,其中最主流、最具实用性的分类为监督学习、无监督学习与强化学习三大类。三类学习范式基于截然不同的核心逻辑,在数据需求、算法设计、优化目标上存在显著差异,适配的业务场景也各有侧重。
 图4:监督学习、无监督学习、强化学习核心对比
图4:监督学习、无监督学习、强化学习核心对比
不同学习类型的核心区别在于"是否存在监督信号""是否存在环境交互反馈",这也决定了其各自的技术路径与落地边界:监督学习依赖标注数据提供明确的学习目标,无监督学习依赖数据自身的内在结构挖掘规律,强化学习则依赖智能体与环境的交互反馈实现策略优化,三者相辅相成,共同覆盖了绝大多数机器学习的应用场景。
监督学习:基于标注数据(输入与对应标签的映射样本)开展学习,核心是构建输入特征到标签的映射函数。标注数据作为"监督信号",可引导模型学习正确的映射关系,其核心任务分为分类与回归两大类。
分类任务适用于离散标签的预测,如图像识别、垃圾邮件过滤、客户流失预测等,常用算法包括逻辑回归、决策树、支持向量机(SVM)、卷积神经网络(CNN)等;回归任务适用于连续值的预测,如房价预测、销量预测、股价预测等,常用算法包括线性回归、岭回归、随机森林回归等。
典型应用场景包括电商平台用户画像分类、金融领域风险评估、医疗领域疾病诊断等,其核心优势是预测准确率高,适用于有明确标签数据的场景。
无监督学习:基于未标注数据开展学习,核心是挖掘数据自身的内在结构、聚类模式与关联关系,无需人工提供监督信号。其核心任务包括聚类、降维、异常检测等,核心逻辑是基于数据相似性进行分组或特征提取。
聚类算法(如K-Means、DBSCAN、层次聚类)适用于客户分群、用户行为聚类、数据异常识别等场景,可在无标签情况下将相似样本归为一类;降维算法(如PCA、t-SNE)适用于高维数据处理,通过保留核心特征、降低数据维度,提升模型训练效率与可解释性。
典型应用场景包括新闻聚类、用户兴趣分群、工业数据异常检测等,其优势是无需标注数据,适用于数据标签难以获取、需挖掘数据潜在规律的场景。
强化学习:基于"智能体-环境"的交互反馈开展学习,核心是通过试错机制优化智能体的行为策略,使智能体在与环境的持续交互中最大化累积奖励。其核心要素包括智能体、环境、状态、动作、奖励函数与策略函数。
智能体通过执行动作与环境交互,获取环境反馈的正奖励或负惩罚,逐步调整行为策略,实现长期奖励最大化。常用算法包括Q-Learning、SARSA、深度强化学习(DQN、PPO)等。
典型应用场景包括自动驾驶、机器人控制、游戏AI、推荐系统动态优化等,其优势是能够适应动态变化的环境,具备自主决策与持续优化的能力。
四、实际应用与技术落地
机器学习已广泛渗透于金融、医疗、工业、互联网等多个领域,其核心价值在于通过数据驱动的方式,解决传统方法难以处理的复杂问题,进而提升业务效率、降低运营成本、优化决策质量。以下结合各领域核心场景,梳理其技术落地要点:
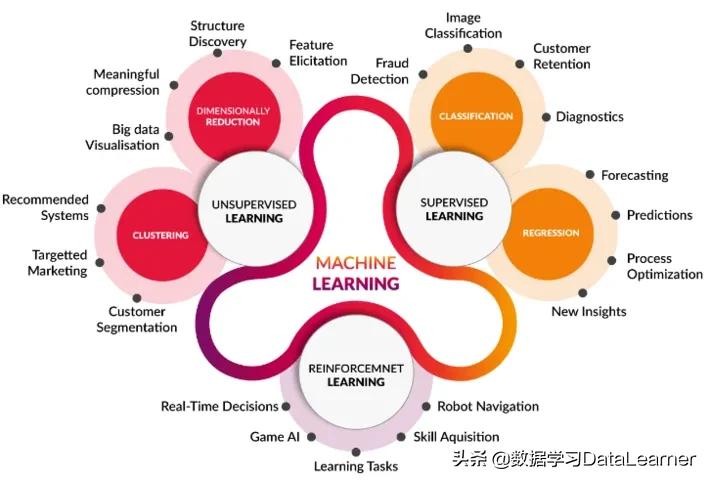 图5:机器学习在各行业的核心应用场景
图5:机器学习在各行业的核心应用场景
推荐系统:核心是基于用户行为数据(浏览、购买、收藏、停留时长等)与物品特征数据,构建用户-物品的兴趣映射模型,实现个性化推荐。其核心技术包括协同过滤、内容推荐、深度学习推荐(如Wide&Deep、DeepFM)等。
落地核心要点在于用户行为数据的精准采集、特征工程优化(如用户画像构建、物品特征提取)、模型实时更新及冷启动问题的有效解决。典型应用包括电商平台商品推荐、视频平台内容推荐、音乐平台歌曲推荐等,可显著提升用户粘性与转化效率。
计算机视觉(图像识别):基于图像的像素特征、纹理特征、形状特征等,实现图像分类、目标检测、语义分割、人脸识别等任务,核心技术包括CNN、R-CNN系列、YOLO系列、Transformer-based视觉模型等。
典型应用场景包括人脸识别(身份验证、门禁系统)、交通监控(违章检测、车辆识别)、工业质检(产品瑕疵检测)、医疗影像诊断(病灶识别、影像分割)等。落地过程中需重点解决数据标注成本高、复杂场景(如光照变化、遮挡)下泛化能力不足等问题。
自然语言处理(NLP):核心是实现计算机对人类语言的理解与生成,涵盖文本分类、情感分析、机器翻译、问答系统、文本生成等任务,核心技术包括词嵌入(Word2Vec、BERT)、Transformer模型、预训练语言模型(GPT系列、BERT系列)等。
典型应用场景包括智能客服(自动应答、问题解决)、机器翻译(跨语言沟通)、文本审核(违规内容检测)、智能写作(文案生成、报告撰写)等。落地要点在于高质量语料库的构建、语义理解的准确性及多场景适配性。
医疗诊断:基于医疗影像数据(CT、X光、核磁共振)、患者病历数据、基因数据等,实现疾病诊断、风险预测、个性化治疗方案制定等任务,核心技术包括图像识别、回归分析、聚类分析等。
其核心价值在于提升诊断效率与准确率,尤其是早期疾病(如肺癌、乳腺癌)的筛查,可有效弥补人工诊断的局限性。落地过程中需注重数据隐私保护、医疗数据标准化及模型可解释性,确保符合医疗行业规范。
五、标准流程与技术要点
机器学习的落地并非简单的"数据输入-模型输出",而是一套标准化、系统化的流程,涵盖数据处理、模型构建、训练优化、评估部署等多个关键环节,每个环节的技术细节直接决定模型的性能与落地效果。
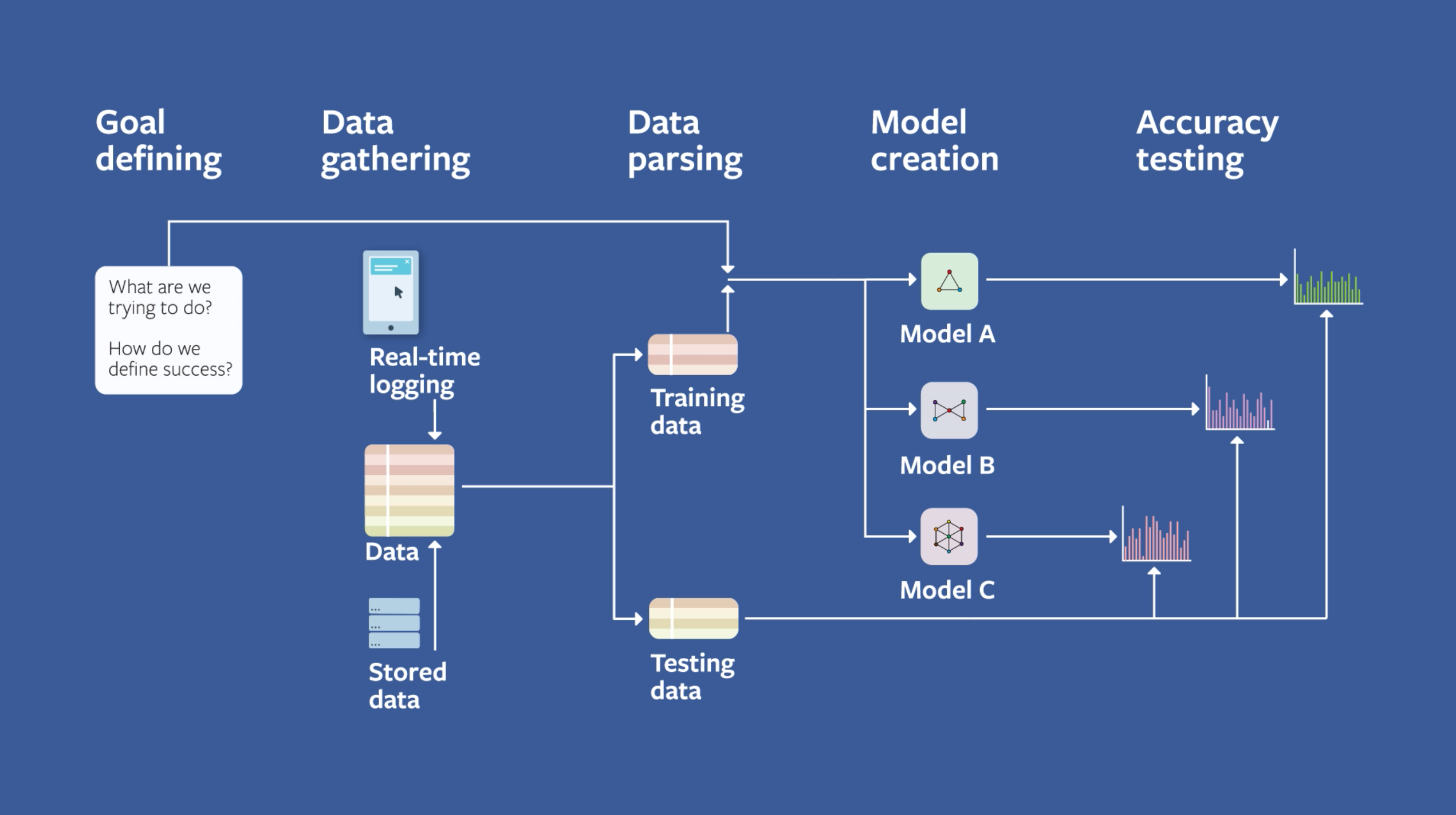 图6:机器学习端到端标准流程
图6:机器学习端到端标准流程
以下是机器学习一般的标准流程:
-
数据收集与需求分析:作为流程的基础环节,核心是明确业务需求与模型目标(分类、回归、聚类等),并收集与任务高度相关的高质量数据。数据来源包括公开数据集、业务数据库、爬虫采集、传感器采集等,需确保数据的代表性与完整性。
-
需求分析需明确模型的核心性能指标(准确率、召回率、F1值、MSE等)、应用场景(离线预测、实时推理)及算力约束,为后续模型选择与参数优化提供明确依据。同时,数据收集过程中需严格遵循合规性要求,注重数据隐私保护,避免数据泄露。
-
数据预处理:原始数据通常存在缺失值、异常值、重复值、数据格式不统一等问题,需通过一系列标准化处理,将其转化为适合模型训练的结构化数据,核心步骤包括数据清洗、特征工程、数据划分。
-
数据清洗:删除重复数据、基于3σ原则或IQR方法修正异常值、通过均值填充、中位数填充或模型预测填充等方式处理缺失值;特征工程:涵盖特征提取、特征转换(归一化、标准化、编码)、特征选择(过滤法、包裹法、嵌入法),核心目标是提升特征的区分度与代表性,降低模型训练复杂度。
-
数据划分:将预处理后的数据集划分为训练集(用于模型训练)、验证集(用于参数调优)、测试集(用于模型评估),常用划分比例为7:2:1,需确保划分后的数据分布一致,避免数据泄露影响模型泛化能力。
-
模型选择与训练:需根据任务类型(分类、回归、聚类)、数据特征(高维/低维、结构化/非结构化)及性能需求,选择适配的算法模型,核心是实现模型复杂度与泛化能力的平衡。
-
模型选择需结合算法适用场景:结构化数据分类可优先选择逻辑回归、随机森林;高维数据分类可选择SVM、神经网络;图像数据可选择CNN;文本数据可选择Transformer模型。训练过程中需合理设置超参数(学习率、迭代次数、正则化系数等),通过梯度下降、Adam等优化算法,最小化模型损失函数,提升模型拟合效果。
-
模型评估与调优:模型训练完成后,需通过测试集开展性能评估,核心是基于预设的性能指标,判断模型的拟合效果与泛化能力,精准识别过拟合、欠拟合等问题,并进行针对性调优。
-
分类任务常用评估指标包括准确率、召回率、F1值、ROC曲线、AUC值;回归任务常用指标包括均方误差(MSE)、平均绝对误差(MAE)、决定系数(R²)。调优手段包括超参数调优(网格搜索、随机搜索、贝叶斯优化)、特征优化、模型融合(集成学习)等,直至模型性能达到预设目标。
-
模型部署与监控迭代:模型评估通过后,需部署至实际业务场景,实现从模型到应用的落地,部署方式包括离线部署、实时部署(API接口调用)、边缘部署等,需结合业务场景的响应速度需求合理选择。
-
模型部署后并非一劳永逸,需建立完善的监控体系,持续监测模型运行效果及数据分布变化(模型漂移),当模型性能出现下降时,需重新收集数据、开展预处理、训练模型,实现模型的持续迭代优化,确保模型始终适配业务场景的动态变化。
六、进阶路径与技术提升方向
对于非初学者而言,机器学习的进阶核心的是实现从"会用模型"向"懂原理、能优化、可落地"的转变,需兼顾理论深度与实践能力,重点从以下几个方面提升技术水平:
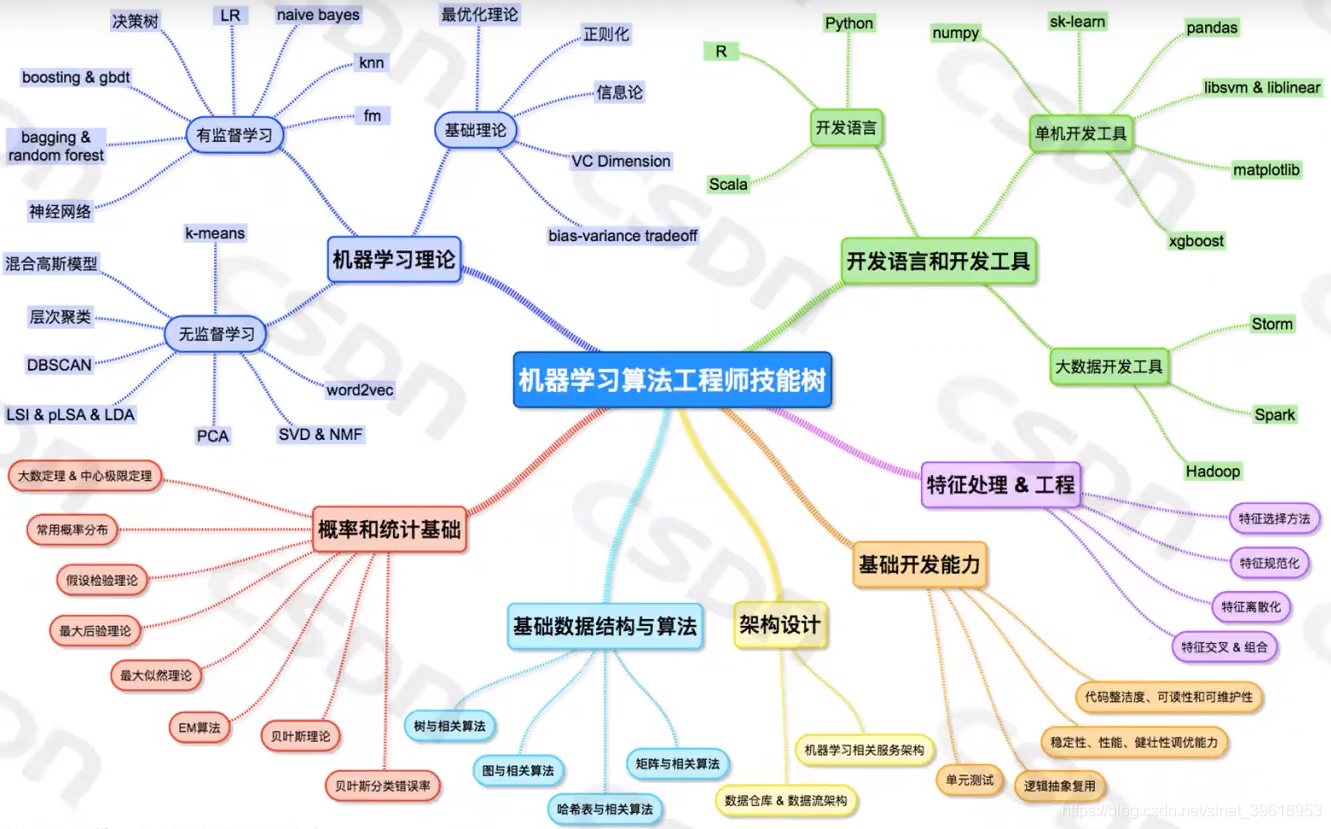 图7:非初学者机器学习进阶路径
图7:非初学者机器学习进阶路径
理论基础深化:深入掌握机器学习的核心理论,包括统计学习理论、线性代数(矩阵运算、向量空间)、微积分(导数、梯度下降)、概率论与数理统计(概率分布、期望、极大似然估计)、信息论(熵、交叉熵)等,深刻理解各类算法的底层原理与数学推导过程。
重点突破各类算法的核心逻辑,如梯度下降的优化原理、正则化的作用机制、神经网络的反向传播过程、集成学习的融合策略等,能够从理论层面解释模型行为与性能瓶颈,为模型优化提供理论支撑。
编程与工具精通:熟练掌握Python编程语言,精通机器学习常用库的底层逻辑与高级用法,包括NumPy(数值计算)、Pandas(数据处理)、Scikit-learn(传统机器学习算法)、TensorFlow/PyTorch(深度学习框架)等。
能够基于库函数实现自定义模型,优化模型结构与参数,解决实际业务中的复杂问题;同时熟练掌握Matplotlib、Seaborn等数据可视化工具,通过可视化分析数据分布、模型性能及误差原因,为模型调优提供依据。
实战项目深耕:脱离基础demo练习,聚焦实际业务场景的复杂项目,如高维数据异常检测、实时推荐系统构建、医疗影像精准诊断、强化学习在机器人控制中的应用等,积累端到端的项目落地经验。
实战过程中重点关注数据预处理细节、特征工程优化、模型调优策略及部署落地难点,能够有效解决数据缺失、模型漂移、算力不足等实际问题,形成完整的项目解决方案。
前沿技术跟踪与实践:持续关注机器学习的前沿方向,如深度学习与传统机器学习的融合、预训练模型的微调与应用、联邦学习(隐私保护)、强化学习的工业化落地、大模型与机器学习的结合等,通过实践探索前沿技术的应用场景与落地价值。
同时,密切关注行业动态与业务需求,将技术与业务深度融合,理解机器学习在不同行业的落地逻辑,提升技术选型与问题解决能力,实现技术价值向业务价值的转化。
七、常见误区与规避策略
在机器学习的理论学习与实践落地过程中,非初学者也易陷入各类误区,导致模型性能不佳、落地失败等问题。以下梳理常见误区及对应的规避策略,助力高效开展机器学习相关工作:
❌ 核心提醒:规避误区的关键的是"贴合业务、注重基础",拒绝盲目追求复杂、忽视核心环节(数据质量、模型监控等)。
误区一:过度追求复杂模型,忽视简单模型的适用性。部分学习者存在"模型越复杂,性能越好"的认知,过度青睐深度神经网络、复杂集成模型,忽视逻辑回归、决策树等简单模型的优势,导致模型训练成本高、可解释性差、泛化能力不足。
规避策略:模型选择需结合数据特征与业务需求,优先选择简单、可解释性强的模型,若简单模型无法满足性能需求,再逐步引入复杂模型;同时注重模型复杂度与泛化能力的平衡,通过正则化等手段避免过拟合。
误区二:忽视数据质量,过度依赖模型调优。错误认为"只要模型足够好,再差的数据也能得到好结果",忽视数据的完整性、准确性与代表性,导致模型训练出现偏差,即使经过大量调优,也无法达到预期性能。
规避策略:将数据预处理置于核心位置,投入充足的时间与精力开展数据清洗、特征工程优化,确保数据质量;同时注重数据的代表性,避免数据分布偏差,为模型训练提供可靠基础。
误区三:忽视模型可解释性,盲目追求预测准确率。在金融、医疗等对可解释性要求较高的领域,过度追求模型准确率,选择可解释性差的复杂模型(如深度神经网络),导致模型无法通过行业合规审核,难以落地应用。
规避策略:结合业务场景的可解释性需求选择模型,如金融风控场景优先选择逻辑回归、决策树等可解释性强的模型;若需使用复杂模型,需通过SHAP、LIME等方法提升模型可解释性,确保模型行为可追溯、可解释。
误区四:模型部署后缺乏监控,忽视模型漂移。认为模型训练完成、部署落地后即可一劳永逸,忽视数据分布的动态变化(概念漂移、数据漂移),导致模型性能随时间推移逐步下降,无法适应业务场景的变化。
规避策略:建立完善的模型监控体系,实时监测模型运行性能与数据分布变化,设置性能预警机制;定期收集新数据,对模型进行重新训练与迭代,确保模型始终适配业务场景的动态变化。
误区五:混淆"理论性能"与"落地性能"。模型在测试集上表现出优异的理论性能,但部署到实际业务场景中,由于数据分布差异、算力约束、业务逻辑适配性等问题,导致落地性能不佳,无法发挥实际价值。
规避策略:模型训练过程中,尽可能模拟实际业务场景的数据分布与约束条件;部署前开展充分的场景测试,验证模型在实际业务中的适配性;结合业务需求调整模型性能指标,平衡预测准确率与响应速度、算力成本等实际因素。
综上,机器学习是一门理论与实践深度融合的技术,其核心价值在于通过数据驱动的方式解决实际业务问题。对于非初学者而言,需跳出"基础应用"的局限,深化理论基础、精通工具用法、积累实战经验,规避各类常见误区,实现技术与业务的深度融合,充分发挥机器学习的价值。随着技术的持续迭代,机器学习与深度学习、大模型、联邦学习等前沿技术的融合,将为各行业带来更多创新可能,同时也对学习者的技术能力提出了更高要求。