继续跟进【文档智能】解析进展。之前的一些多模态OCR(MOCR)方案主要关注文本识别(表格、文字、公式等),图表、UI组件等视觉图形截图保留 ,不进行解析(图到SVG代码等,如下图),本文介绍的工作提到:图形中蕴含的结构语义信息,不进行解析会导致文档解析存在固有信息损失了;同时,现有方法无法挖掘文本与图形之间的语义关联,也无法将图形转化为可复用的监督信号用于多模态模型训练。
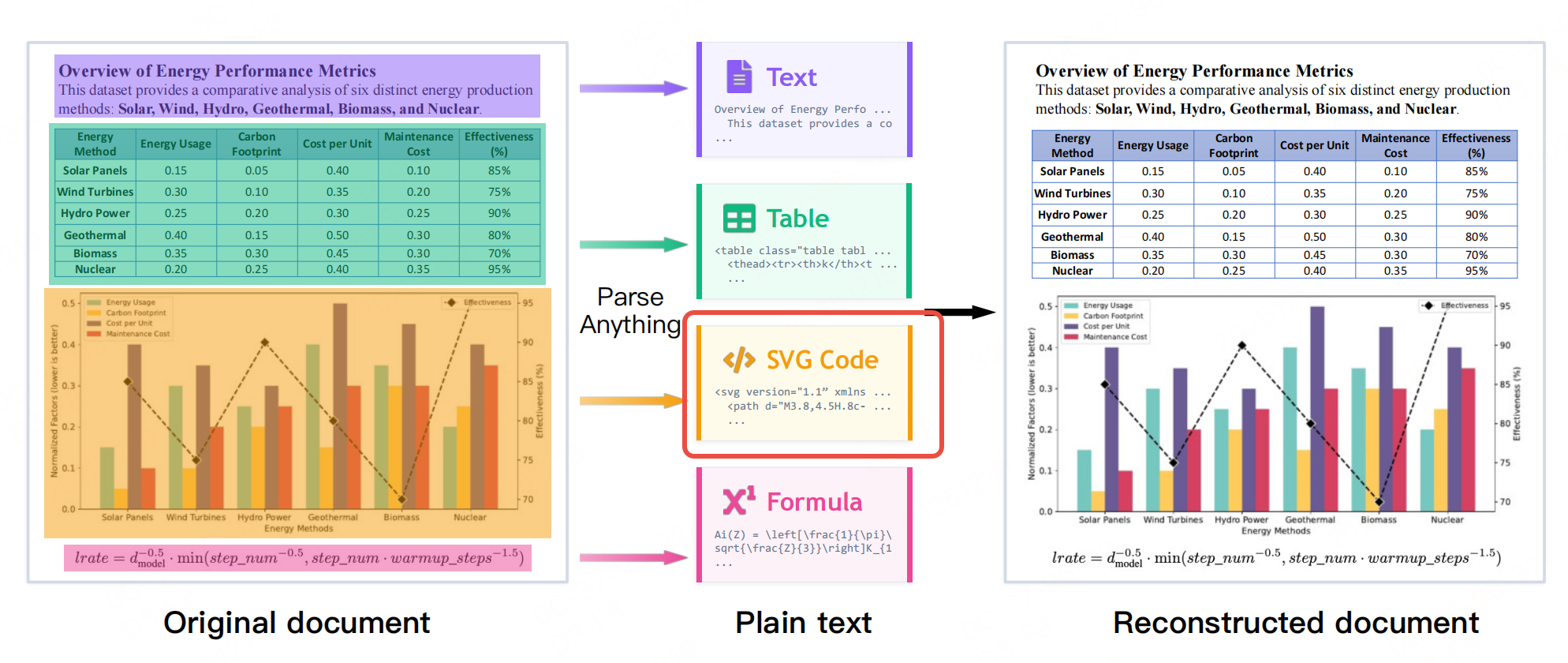
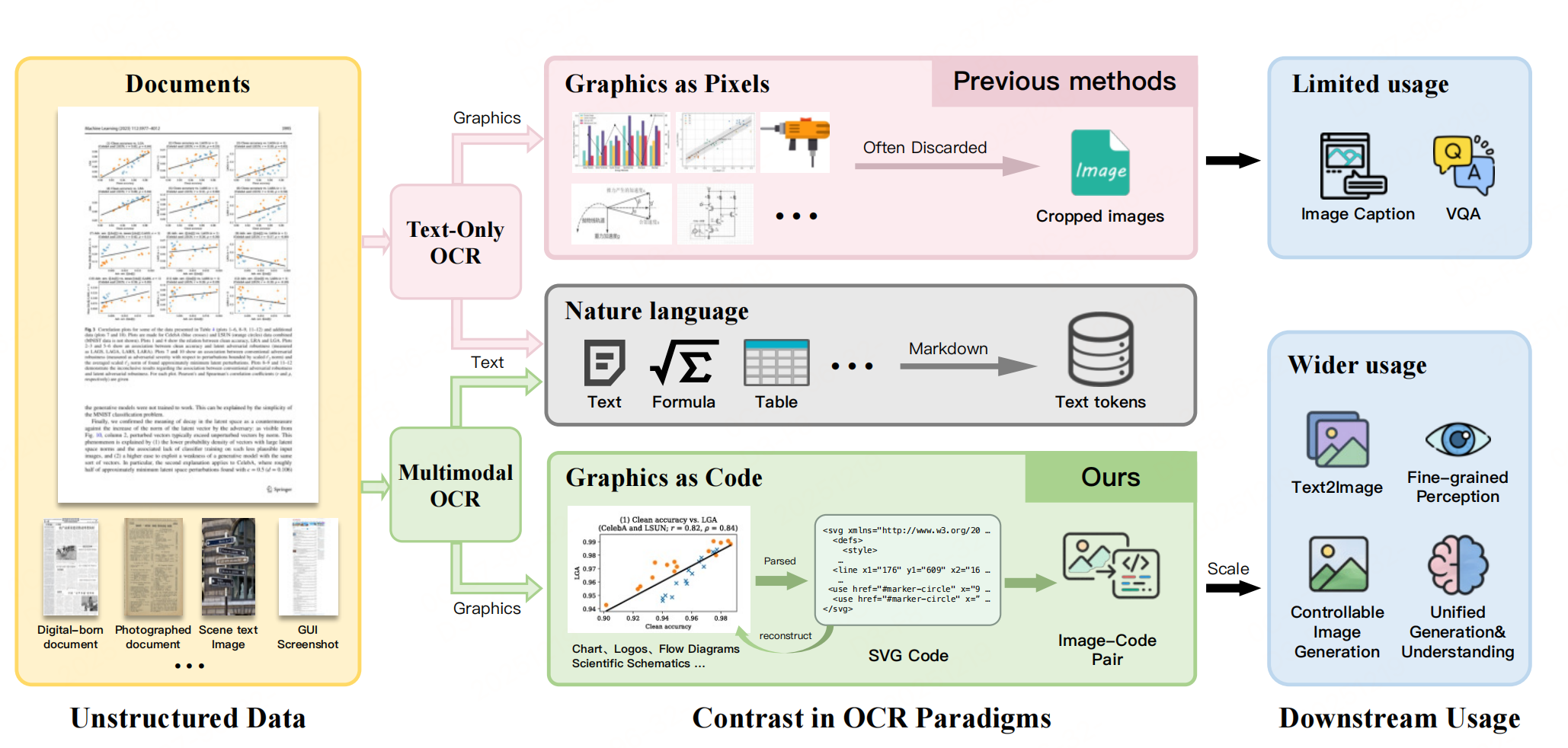
MOCR范式的定义 :将文档中所有信息元素 (文本、布局、表格、公式、图表、图标、UI组件等)均视为解析目标,通过视觉-语言联合建模 ,将文本转化为符号化标记(纯文本/Markdown/LaTeX),将可程序化描述的图形转化为可渲染、可编辑的结构化代码 (核心为SVG,可扩展至TikZ/D3.js等),最终输出统一的有序结构化序列。
- 输入 :任意文档图像 I I I(涵盖PDF渲染图、数字扫描件、网页截图、场景文本图像);
- 输出 :按人类阅读顺序 排列的解析元素序列 S S S:
S = ( B 1 , c 1 , p 1 ) , . . . , ( B K , c K , p K ) S=\left\\left(\\mathcal{B}_{1}, c_{1}, p_{1}\\right), ...,\\left(\\mathcal{B}_{K}, c_{K}, p_{K}\\right)\\right S=(B1,c1,p1),...,(BK,cK,pK)
其中每个元素包含三个核心部分:- B k \mathcal{B}_k Bk:元素的空间边界框,表征其在图像中的位置;
- c k c_k ck:元素的语义类别(如文本行、表格、公式、柱状图、图标等);
- p k p_k pk:元素的各类别的输出对应的格式【文本类元素 (文本行/块、表格、公式): p k p_k pk为符号化转录结果,如纯文本、Markdown表格、LaTeX公式,图形类元素 (图表、图标、UI组件、化学结构式): p k p_k pk为可渲染的结构化代码(核心为SVG)】。
模型架构:dots.mocr的统一视觉-语言架构
架构和doc.ocr一致,总参数量为3B(1.2B视觉编码器+1.5B语言解码器+连接器)。
训练方法
MOCR的训练目标是让模型同时掌握文本解析 和图形-to-SVG 生成,属于典型的多任务联合训练 ,且面临图形监督稀缺、SVG代码非唯一的痛点。整个训练分三阶段预训练+指令调优。
预训练的核心是从简单的视觉-语言对齐,逐步过渡到MOCR专属的多模态解析 ,同时逐步提升输入分辨率 ,匹配任务难度的增加,还通过混合重加权、课程调度控制优化稳定性。
阶段1:通用视觉-语言对齐
通用视觉数据集(如COCO、ImageNet)+ 简单OCR数据;低分辨率训练,让语言解码器学会可靠地消费视觉token,实现基础的视觉-语言接地(Grounding)
阶段2:文本解析基础构建
通用视觉数据 + 纯文本文档解析监督 (PDF/网页的文本+布局解析),按比例混合;
中分辨率(适配常规文档)训练,让模型掌握传统OCR的核心能力------文本识别、布局分析、表格/公式的符号化解析,同时保持通用视觉鲁棒性;
阶段3:MOCR多模态解析强化
大幅降低通用视觉数据比例,增加MOCR监督数据 (多模态文档+图像-to-SVG数据);
高分辨率(适配11M像素的超高清文档)训练,让模型学会挖掘文本与图形的语义关联,掌握图形-to-SVG的结构化代码生成能力;
SFT
核心是提升监督可靠性、对齐输出规范、优化端到端解析保真度,针对实际应用场景做精细化调整。
关键步骤
- 高质量数据集构建:从数据引擎中筛选、精炼样本,修正系统错误,对齐文本/图形的输出格式(如SVG的编码规范、Markdown的表格格式);
- SVG专属优化 :对图形解析做规范化处理(如SVG的viewBox归一化、代码复杂度降低、canonicalization),解决SVG代码"非唯一"(不同代码生成相同视觉效果)的问题;
- 多任务混合训练:将文本解析、图形-to-SVG生成的高质量样本混合,进行端到端指令调优。
两个发布版本的差异化训练
基于同一预训练权重,通过调整指令调优的数据比例,得到两个侧重不同的模型版本,共享3B参数量:
- dots.mocr:基础版本,文本解析与图形解析均衡;
- dots.mocr-svg :图形解析强化版本,增加SVG数据的占比,并对高难度SVG程序做加权训练,重点优化图表、化学结构式等复杂图形的解析。
数据引擎
MOCR的最大的差异化特点是图像-SVG的生成,下面主要概述下这个数据的生成方法:
渲染网页(文本+图形的对齐数据)
- 数据用途 :提供复杂布局的文本解析监督,同时挖掘文本-图形的语义关联和原生SVG图形;
- 处理方法 :爬取网页并渲染为图像,结合网页的HTML/DOM结构化信号 ,生成文档解析标注;同时提取网页中原生的SVG图标、图表,得到图像-SVG对齐对;
- 核心优势:HTML/DOM提供了精准的结构化信号,大幅降低标注噪声。
原生SVG(图形解析数据)
- 数据用途 :提供大规模的图像-SVG对齐监督,让模型学会图形-to-SVG的生成;
- 处理流程 :
- 清洗 :用
svgo工具移除无关元数据、归一化数值精度、标准化代码结构; - 去重:通过文本匹配(代码级)和感知哈希(pHash,图像级)实现去重;
- 采样 :按领域平衡 (图标、图表、UI、科学绘图)和复杂度感知(简单/复杂SVG混合)采样,避免数据偏斜。
- 清洗 :用
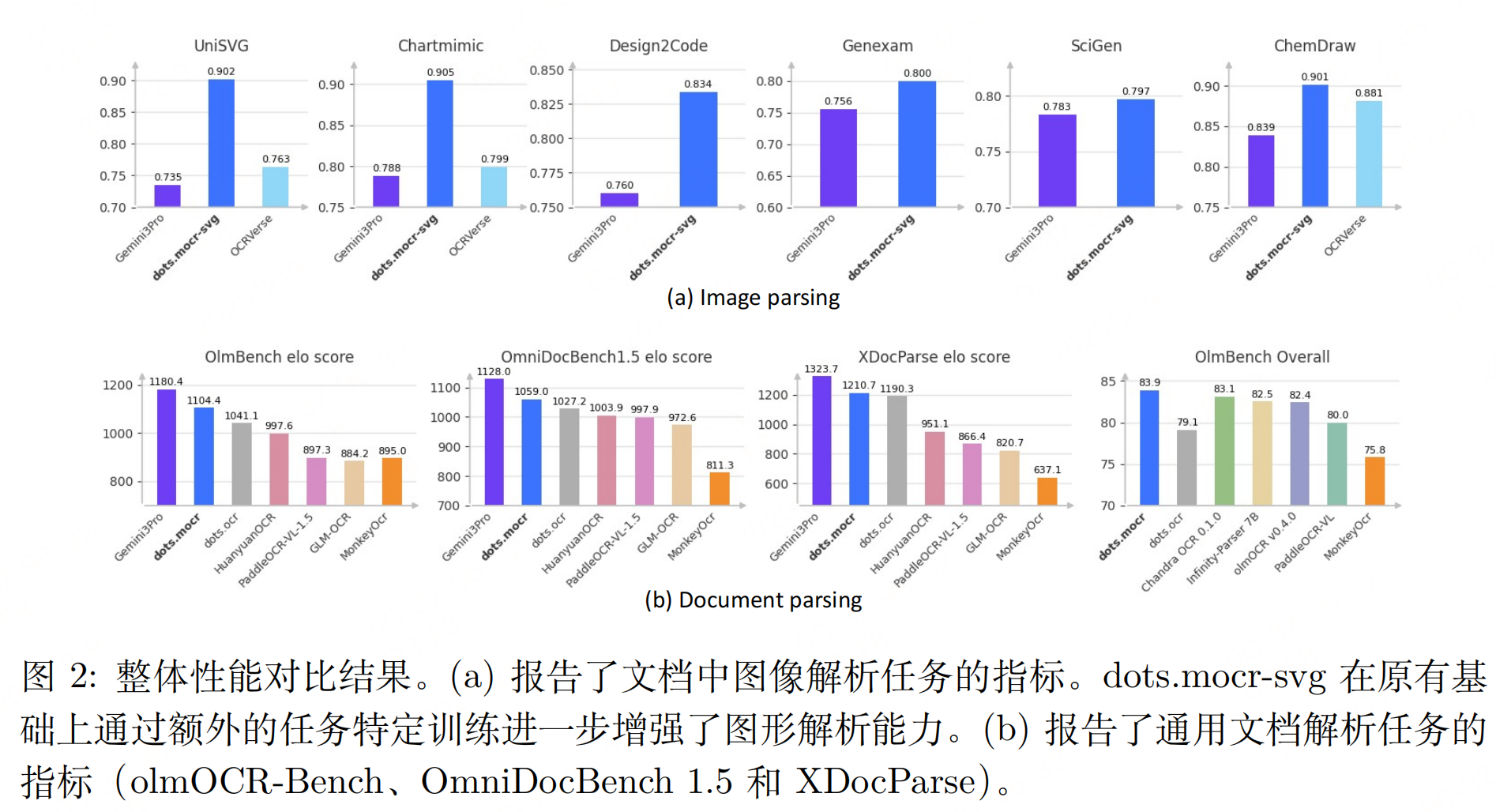
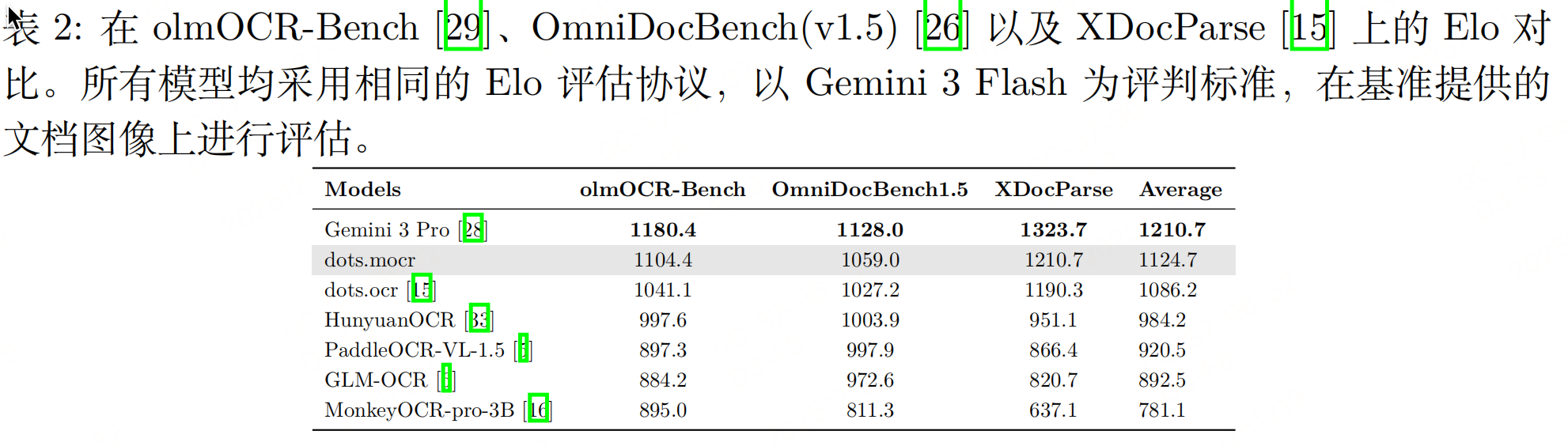
实验

参考文献
Multimodal OCR: Parse Anything from Documents,https://arxiv.org/pdf/2603.13032v1