RNN模型分类
从两个角度对RNN模型进行分类. 第一个角度是输入和输出的结构, 第二个角度是RNN的内部构造
N vs N - RNN:
它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
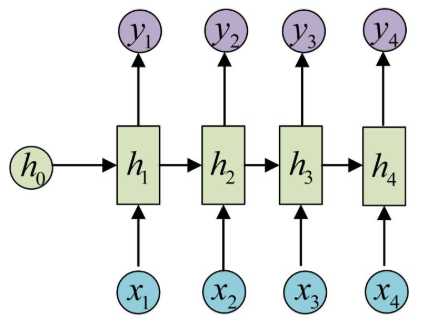
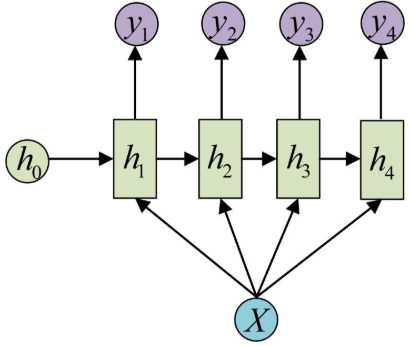
N vs 1 - RNN:
有时候我们要处理的问题输入是一个序列,而要求输出是一个单独的值而不是序列,应该怎样建模呢?我们只要在最后一个隐层输出h上进行线性变换就可以了,大部分情况下,为了更好的明确结果, 还要使用sigmoid或者softmax进行处理. 这种结构经常被应用在文本分类问题上.
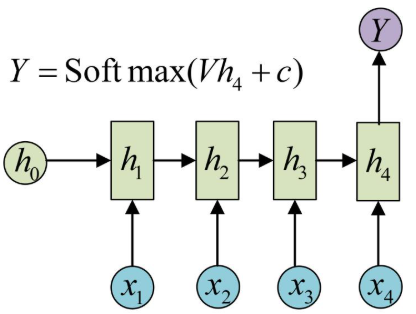
1 vs N - RNN:
如果输入不是序列而输出为序列的情况怎么处理呢?我们最常采用的一种方式就是使该输入作用于每次的输出之上. 这种结构可用于将图片生成文字任务等.
N vs M - RNN:
这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
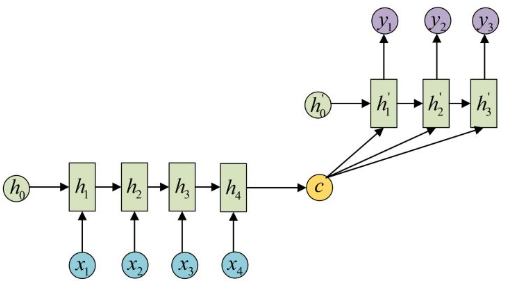
seq2seq架构最早被提出应用于机器翻译, 因为其输入输出不受限制,如今也是应用最广的RNN模型结构. 在机器翻译, 阅读理解, 文本摘要等众多领域都进行了非常多的应用实践.
关于RNN的内部构造进行分类的内容我们将在后面使用单独的小节详细讲解.
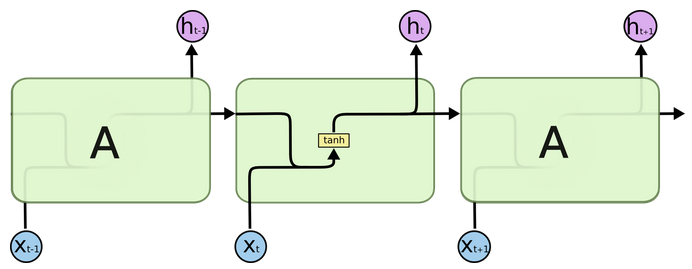
传统RNN
内部结构图
公式
h_t = \tanh(x_t W_{ih}^T + b_{ih} + h_{t-1}W_{hh}^T + b_{hh})其中,:math:h_t 是时间 t 的隐藏状态,:math:x_t 是时间 t 的输入,:math:h_{(t-1)} 是上一时刻 t-1 的隐藏状态,或者时间 0 的初始隐藏状态。如果 :attr:nonlinearity 是 'relu',则使用 :math:\text{ReLU} 函数代替 :math:\tanh。
nn.RNN使用示例1
python
import torch
import torch.nn as nn
def dm_rnn_for_base():
"""
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
"""
rnn = nn.RNN(5, 6, 1)
"""
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
"""
input = torch.randn(1, 3, 5)
"""
第一个参数:num_layer * num_directions(层数*网络方向),num_directions一般为1
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
"""
h0 = torch.randn(1, 3, 6)
# [1,3,5],[1,3,6] ---> [1,3,6],[1,3,6]
output, hn = rnn(input, h0)
print('output--->', output.shape, output)
print('hn--->', hn.shape, hn)
print('rnn模型--->', rnn)
dm_rnn_for_base()
python
output---> torch.Size([1, 3, 6]) tensor([[[ 0.4320, 0.3604, -0.3584, 0.3799, 0.2293, 0.2679],
[-0.2547, -0.5575, -0.6784, -0.4315, 0.5883, -0.1581],
[ 0.0080, 0.4830, 0.1754, -0.8194, 0.9422, -0.7051]]],
grad_fn=<StackBackward0>)
hn---> torch.Size([1, 3, 6]) tensor([[[ 0.4320, 0.3604, -0.3584, 0.3799, 0.2293, 0.2679],
[-0.2547, -0.5575, -0.6784, -0.4315, 0.5883, -0.1581],
[ 0.0080, 0.4830, 0.1754, -0.8194, 0.9422, -0.7051]]],
grad_fn=<StackBackward0>)
rnn模型---> RNN(5, 6)nn.RNN使用示例2
输入数据长度发生变化
python
import torch
def dm_rnn_for_sequence_len():
"""
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
"""
rnn = torch.nn.RNN(5, 6, 1)
"""
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
"""
input = torch.randn(20, 3, 5) # B
"""
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
"""
h0 = torch.randn(1, 3, 6) # C
# [20,3,5],[1,3,6] --->[20,3,6],[1,3,6]
output, hn = rnn(input, h0)
print('output--->', output.shape)
print('hn--->', hn.shape)
print('rnn模型--->', rnn)
dm_rnn_for_sequence_len()
python
output---> torch.Size([20, 3, 6])
hn---> torch.Size([1, 3, 6])
rnn模型---> RNN(5, 6)nn.RNN使用示例3
python
import torch
def dm_run_for_hidden_num():
"""
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
"""
rnn = torch.nn.RNN(5, 6, 2) # A 隐藏层个数从1-->2 下面程序需要修改的地方?
"""
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
"""
input = torch.randn(1, 3, 5) # B
"""
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
"""
h0 = torch.randn(2, 3, 6) # C
output, hn = rnn(input, h0) #
print('output-->', output.shape, output)
print('hn-->', hn.shape, hn)
print('rnn模型--->', rnn) # nn模型---> RNN(5, 6, num_layers=11)
dm_run_for_hidden_num()
python
output--> torch.Size([1, 3, 6]) tensor([[[ 0.2826, -0.1749, -0.7063, 0.4330, -0.7987, 0.5027],
[-0.6392, 0.2742, -0.1241, -0.3682, 0.1564, -0.1928],
[-0.5529, -0.0269, 0.9240, -0.6768, 0.4402, -0.1243]]],
grad_fn=<StackBackward0>)
hn--> torch.Size([2, 3, 6]) tensor([[[ 0.2711, 0.1775, -0.4353, 0.6829, -0.6478, -0.8098],
[-0.6810, 0.2980, 0.2135, 0.6189, -0.3950, 0.4263],
[-0.7016, -0.7970, 0.1254, -0.7231, -0.8568, 0.6428]],
[[ 0.2826, -0.1749, -0.7063, 0.4330, -0.7987, 0.5027],
[-0.6392, 0.2742, -0.1241, -0.3682, 0.1564, -0.1928],
[-0.5529, -0.0269, 0.9240, -0.6768, 0.4402, -0.1243]]],
grad_fn=<StackBackward0>)
rnn模型---> RNN(5, 6, num_layers=2)LSTM模型
内部结构图
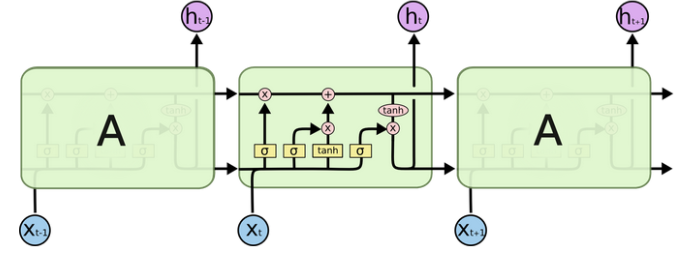
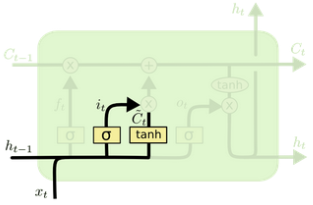
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
遗忘门(Forget Gate)------ "该忘掉什么?"
-
作用:决定上一时刻的细胞状态(长期记忆)里,哪些信息要丢掉。
-
通俗比喻:就像你在记日记,昨天写了"我今天要减肥",但今天吃了火锅,你就想把"减肥"这条记忆忘掉。
-
数学上:用 sigmoid 函数输出 0~1 的值,0 = 完全忘记,1 = 完全保留。
-
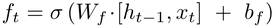
-
0~1 的遗忘权重 → 乘到旧细胞状态 C_{t-1} 上。
-
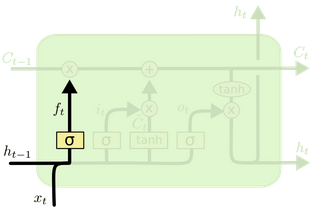
输入门(Input Gate)------ "该记住什么新东西?"
- 作用:决定当前输入的新信息,有多少要加到长期记忆里。
- 分两步:
- 第一步:用 sigmoid 决定"要不要记"(0~1)
- 第二步:用 tanh 算出"如果要记,具体记什么内容"(-1~1 的候选值)
- 通俗比喻:你今天吃了火锅,决定"火锅真香"这条信息要记下来,但不是全部情绪都要记,只记"辣度 8 分,很过瘾"这条精华。
- 公式:
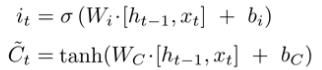
细胞状态(Cell State Update)------ "把新旧记忆融合"
- 作用:把"旧记忆(经过遗忘门过滤后的)" + "新记忆(经过输入门过滤后的)"加起来,形成新的长期记忆 C_t。
- 通俗比喻:昨天的日记(旧记忆)删掉"减肥"后,今天加上"火锅真香",合成新日记。
- 公式:
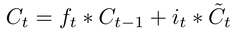
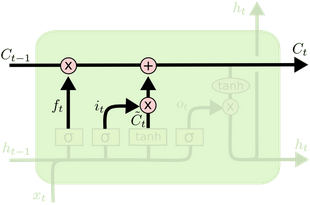
输出门(Output Gate)------ "该对外输出什么?"
- 作用:决定当前时刻要对外输出(给下一个 cell 或最终预测)哪些信息。
- 分两步:
- sigmoid 决定"要输出什么"(0~1)
- 把细胞状态 C_t 通过 tanh 变成 -1~1,再乘上输出权重,得到最终隐藏状态 h_t。
- 通俗比喻:你今天吃了火锅,决定对外说"今天很爽",但不说"我吃了三碗米饭"。
- 公式:
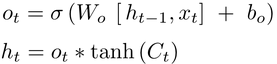
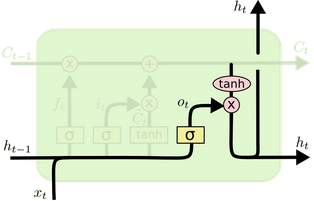
LSTM优缺点
-
LSTM优势:
LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
-
LSTM缺点:
由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
Bi-LSTM介绍
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出。
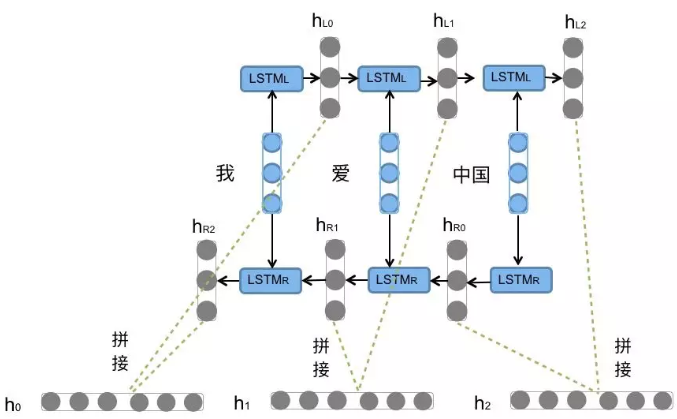
我们看到图中对"我爱中国"这句话或者叫这个输入序列, 进行了从左到右和从右到左两次LSTM处理, 将得到的结果张量进行了拼接作为最终输出. 这种结构能够捕捉语言语法中一些特定的前置或后置特征, 增强语义关联,但是模型参数和计算复杂度也随之增加了一倍, 一般需要对语料和计算资源进行评估后决定是否使用该结构。
python
import torch.nn as nn
import torch
def dm_lstm():
"""
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
"""
rnn = nn.LSTM(5, 6, 2)
"""
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
"""
input = torch.randn(1, 3, 5)
"""
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
"""
h0 = torch.randn(2, 3, 6)
c0 = torch.randn(2, 3, 6)
output, (hn, cn) = rnn(input, (h0, c0))
print('output-->', output.shape, output)
print('hn-->', hn.shape, hn)
print('cn-->', cn.shape, cn)
print('rnn模型--->', rnn)
dm_lstm()
python
output--> torch.Size([1, 3, 6]) tensor([[[-0.3224, 0.1985, -0.0751, 0.0005, 0.2105, -0.1516],
[ 0.1574, 0.0314, 0.2190, 0.0948, 0.2185, 0.0148],
[-0.0928, -0.0878, -0.0488, 0.2341, 0.3469, -0.1718]]],
grad_fn=<MkldnnRnnLayerBackward0>)
hn--> torch.Size([2, 3, 6]) tensor([[[-3.4701e-02, 2.0348e-01, -1.0518e-02, -2.4653e-02, -2.9480e-02,
4.3411e-02],
[ 1.4300e-02, -2.7515e-01, -2.1168e-01, 5.5081e-01, 2.5772e-01,
-9.0823e-02],
[-3.2285e-01, 1.3861e-01, 1.4773e-01, 2.6684e-01, 2.5339e-01,
-9.3171e-02]],
[[-3.2242e-01, 1.9848e-01, -7.5119e-02, 4.9545e-04, 2.1053e-01,
-1.5159e-01],
[ 1.5745e-01, 3.1420e-02, 2.1896e-01, 9.4843e-02, 2.1849e-01,
1.4844e-02],
[-9.2831e-02, -8.7809e-02, -4.8831e-02, 2.3410e-01, 3.4690e-01,
-1.7183e-01]]], grad_fn=<StackBackward0>)
cn--> torch.Size([2, 3, 6]) tensor([[[-0.1281, 0.8242, -0.0518, -0.0968, -0.0456, 0.1523],
[ 0.0270, -0.6408, -0.8990, 1.0246, 0.5178, -0.2018],
[-0.8174, 0.2502, 0.2077, 0.8208, 0.7850, -0.5001]],
[[-0.6332, 0.4563, -0.1930, 0.0016, 0.3750, -0.2496],
[ 0.2917, 0.0544, 0.3335, 0.2279, 0.5234, 0.0288],
[-0.2121, -0.1717, -0.0879, 1.1136, 1.2385, -0.2947]]],
grad_fn=<StackBackward0>)
rnn模型---> LSTM(5, 6, num_layers=2)GRU模型
GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象。同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
内部结构图
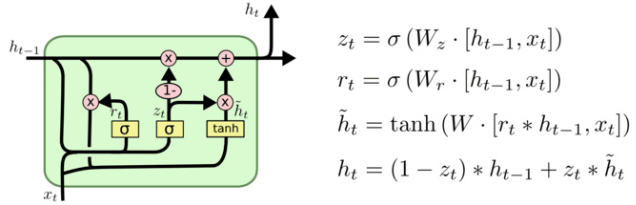
GRU的更新门和重置门结构图:
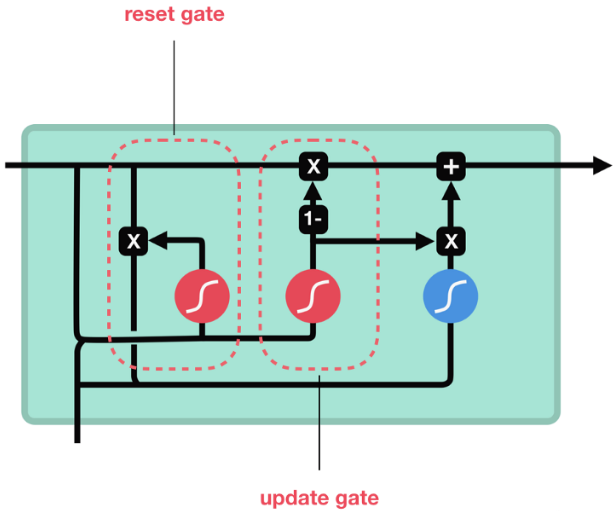
更新门(Update Gate)------ "这次要记住多少旧的、加多少新的?"
- 作用 :决定当前时刻的隐藏状态 h_t,要保留多少上一时刻的旧记忆(h_{t-1}),同时要加入多少当前输入的新信息。
- 一句话理解 :它控制"旧记忆"和"新记忆"的混合比例。
- 更新门值接近 1 → 几乎全保留旧记忆(适合长距离依赖)
- 更新门值接近 0 → 几乎全用新信息(适合短期变化)
- 通俗比喻:你在记日记,昨天写了"我要减肥",今天吃了火锅。 更新门值高 → 你就继续写"还是要减肥"(旧记忆占主导)。 更新门值低 → 你直接改成"火锅真香,减肥先放放"(新信息占主导)。
- 公式: z_t = σ(W_z · h_{t-1}, x_t + b_z) → z_t 是 0~1 的值,决定旧记忆和新记忆的加权比例。
重置门(Reset Gate)------ "旧记忆里哪些部分要先忘掉再算新内容?"
- 作用 :决定在计算当前候选新记忆时,要忽略(重置)多少上一时刻的隐藏状态 h_{t-1}。
- 一句话理解 :它控制"旧记忆对新记忆计算的影响程度"。
- 重置门值接近 1 → 保留旧记忆的影响(新内容和旧内容强相关)。
- 重置门值接近 0 → 几乎忽略旧记忆(当前输入几乎从零开始计算)。
- 通俗比喻:你今天想写"火锅真香",但昨天的"减肥"记忆会干扰你。 重置门值高 → 你会把"减肥"和"火锅"一起考虑(写成"虽然要减肥,但火锅真香")。 重置门值低 → 你直接忽略昨天的减肥,直接写"火锅超爽"(旧记忆不影响新内容)。
- 公式: r_t = σ(W_r · h_{t-1}, x_t + b_r) → r_t 是 0~1 的值,乘到 h_{t-1} 上,决定保留多少旧记忆去计算候选新记忆。
Bi-GRU介绍
Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, 而是将模型应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出. 具体参见上小节中的Bi-LSTM.
GRU优缺点¶
-
GRU的优势:
- GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
-
GRU的缺点:
- GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈.
python
import torch
def dm_gru():
"""
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
bidirectional=False, 是否是Bi-GRU
"""
rnn = torch.nn.GRU(5, 6, 2, bidirectional=False, )
"""
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
"""
input = torch.randn(1, 3, 5)
"""
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
"""
h0 = torch.randn(2, 3, 6)
output, hn = rnn(input, h0)
print('output-->', output.shape, output)
print('hn-->', hn.shape, hn)
print('rnn模型--->', rnn)
dm_gru()
python
output--> torch.Size([1, 3, 6]) tensor([[[ 0.1542, -0.1329, 0.7914, -0.3325, 0.1283, -0.1653],
[-0.1383, -0.8248, 0.6732, -0.2581, 0.8363, -0.9070],
[-0.0325, -0.8599, -0.5409, -0.1649, -0.1222, 0.7552]]],
grad_fn=<StackBackward0>)
hn--> torch.Size([2, 3, 6]) tensor([[[-0.2576, 0.1694, 0.5491, -0.1092, 0.2666, -0.3225],
[ 0.8471, 0.9595, -0.8849, -1.1791, 0.4446, -1.1334],
[-1.3785, 0.3195, 0.2242, 0.1168, -0.7916, 0.0907]],
[[ 0.1542, -0.1329, 0.7914, -0.3325, 0.1283, -0.1653],
[-0.1383, -0.8248, 0.6732, -0.2581, 0.8363, -0.9070],
[-0.0325, -0.8599, -0.5409, -0.1649, -0.1222, 0.7552]]],
grad_fn=<StackBackward0>)
rnn模型---> GRU(5, 6, num_layers=2)RNN,LSTM,GRU对比:
RNN(普通循环)是个金鱼脑子,句子一长它就忘了开头(梯度消失)。
LSTM(长短期记忆网络):给 AI 装了一个"日记本(细胞状态 Cell State)。
它多了三个保安(门控机制):
遗忘门:决定把日记本里哪些没用的废话擦掉。
输入门:决定把今天的新知识写进日记本。
输出门:决定今天跟别人聊天时,要用日记本里的哪些内容。
GRU:是 LSTM 的"缩水省钱版"。把三个保安精简成了两个(更新门、重置门),速度更快,效果差不多。