目录
[1. 导入依赖库](#1. 导入依赖库)
[2. 初始化配置](#2. 初始化配置)
[(1)MediaPipe 手部检测组件初始化](#(1)MediaPipe 手部检测组件初始化)
[3. 核心函数: collect_gesture_data()](#3. 核心函数: collect_gesture_data())
[1.模块 1:数据加载( load_gesture_data() )](#1.模块 1:数据加载( load_gesture_data() ))
[2.模块 2:模型训练与评估( train_and_evaluate_models() )](#2.模块 2:模型训练与评估( train_and_evaluate_models() ))
[3.模块 3:实时识别( real_time_recognition() )](#3.模块 3:实时识别( real_time_recognition() ))
简介
上一篇博客我们讲述了关于Mediapipe简介,以及讲述了手部识别与手势识别,今天我们就来看看我们自定义手势是如何完成的
一、收集数据代码实现
这段代码是一个 基于 MediaPipe 的手势数据采集工具,核心功能是通过摄像头实时检测手部关键点,并将不同手势(如拳头、张开手、剪刀手等)的 21 (这里我就用几个其他的可以自己自行添加)个手部三维关键点坐标保存为 JSON 文件,为后续的手势识别模型训练提供数据集。
1. 导入依赖库
python
import cv2
import mediapipe as mp
import numpy as np
import os
import jsoncv2(OpenCV):负责摄像头调用、图像格式转换、画面显示和键盘事件处理。mediapipe as mp:提供预训练的手部检测模型,用于实时提取 21 个手部关键点。numpy as np:用于生成时间戳(np.datetime64('now')),记录数据采集时间。os:用于创建文件夹(os.makedirs),管理数据存储路径。json:将手部关键点数据以 JSON 格式保存(可读性强,便于后续模型读取)
2. 初始化配置
(1)MediaPipe 手部检测组件初始化
python
mp_hands = mp.solutions.hands # 手部检测核心模块
mp_drawing = mp.solutions.drawing_utils # 手部关键点绘制工具mp_hands:提供Hands类,用于加载手部检测模型并处理图像。mp_drawing:提供draw_landmarks函数,将检测到的关键点和连接关系绘制在画面上
(2)定义手势类别与数据存储路径
python
# 手势类别:键为数字(对应键盘按键),值为手势名称
GESTURE_CLASSES = {
0: "fist", # 拳头
1: "open_hand", # 张开的手
2: "point", # 指向(单指)
3: "peace", # 剪刀手(双指)
4: "ok" # OK手势
}
DATA_DIR = "gesture_data" # 总数据目录名称(3)创建数据存储目录
python
for cls in GESTURE_CLASSES.values():
os.makedirs(os.path.join(DATA_DIR, cls), exist_ok=True)os.path.join(DATA_DIR, cls):拼接路径,例如gesture_data/fist、gesture_data/open_hand。exist_ok=True:如果目录已存在,不报错(避免重复创建导致的异常)。- 最终生成的目录结构:
python
gesture_data/
├─ fist/
├─ open_hand/
├─ point/
├─ peace/
└─ ok/3. 核心函数: collect_gesture_data()
该函数是代码的核心,包含 摄像头调用、手部检测、关键点提取、数据保存四大逻辑,我们逐块解析。
python
def collect_gesture_data():
"""采集手势数据,提取21个关键点的三维坐标"""
cap = cv2.VideoCapture(0) # 使用默认摄像头
# 显示手势类别说明
print("手势类别:")
for key, value in GESTURE_CLASSES.items():
print(f"{key}: {value}")
print("按对应的数字键收集数据,按q退出")
# 初始化计数器,记录每个类别的样本数量
counters = {cls: 0 for cls in GESTURE_CLASSES.values()}
with mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.7) as hands:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("无法获取摄像头画面")
break
# 转换为RGB并处理
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(image)
# 转换回BGR用于显示
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 检测到手部
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 绘制手部关键点
mp_drawing.draw_landmarks(
image, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# 提取21个关键点的三维坐标
landmarks = []
for lm in hand_landmarks.landmark:
# 存储x, y, z坐标
landmarks.append([lm.x, lm.y, lm.z])
# 显示当前各类别样本数量
info_text = " | ".join([f"{cls}: {count}" for cls, count in counters.items()])
cv2.putText(image, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# 显示画面
cv2.imshow('Gesture Collection (Press number key to save, q to exit)', image)
# 键盘事件处理
key = cv2.waitKey(5) & 0xFF
if key == ord('q'):
break
# 按数字键保存对应类别的数据
elif chr(key) in [str(k) for k in GESTURE_CLASSES.keys()]:
cls_idx = int(chr(key))
cls_name = GESTURE_CLASSES[cls_idx]
if results.multi_hand_landmarks and len(results.multi_hand_landmarks) > 0:
# 保存关键点数据
counters[cls_name] += 1
data = {
"class": cls_name,
"class_index": cls_idx,
"landmarks": landmarks,
"timestamp": str(np.datetime64('now'))
}
# 保存为JSON文件
filename = f"{cls_name}_{counters[cls_name]}.json"
filepath = os.path.join(DATA_DIR, cls_name, filename)
with open(filepath, 'w') as f:
json.dump(data, f, indent=2)
print(f"已保存 {cls_name} 样本 #{counters[cls_name]}")
else:
print("未检测到手部,请将手放在摄像头前")
cap.release()
cv2.destroyAllWindows()
# 打印最终收集的样本数量
print("\n数据收集完成!")
print("样本数量统计:")
for cls, count in counters.items():
print(f"{cls}: {count}个样本")
if __name__ == "__main__":
collect_gesture_data()这里我们要自己添加数据集进行训练、我们对着摄像头比划对应的手势,按住对应数字就可以自己添加数据集

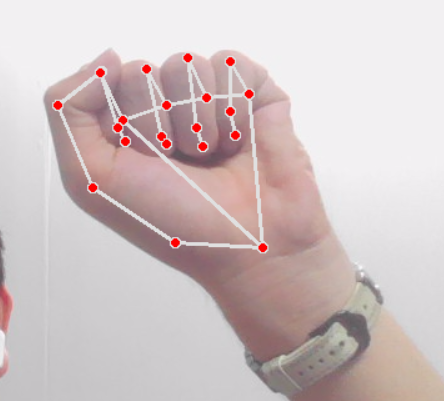

我们经过添加多中手势图片得到数据集,接下来我们就是训练然后进行预测。
二、训练预测代码实现
python
import os
import json
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import joblib
import seaborn as sns
# 数据目录和手势类别(需与采集程序一致)
DATA_DIR = "gesture_data"
GESTURE_CLASSES = {
0: "fist", # 拳头
1: "open_hand", # 张开的手
2: "point", # 指向
3: "peace", # 剪刀手
4: "ok" # OK手势
}
def load_gesture_data():
"""加载手势数据并转换为特征向量"""
X = [] # 特征向量
y = [] # 标签
# 遍历每个手势类别目录
for cls_idx, cls_name in GESTURE_CLASSES.items():
cls_dir = os.path.join(DATA_DIR, cls_name)
if not os.path.exists(cls_dir):
print(f"警告: 类别 {cls_name} 的数据目录不存在")
continue
# 加载该类别的所有样本
for filename in os.listdir(cls_dir):
if filename.endswith(".json"):
filepath = os.path.join(cls_dir, filename)
with open(filepath, 'r') as f:
data = json.load(f)
# 将21个关键点的3D坐标展平为一维向量 (21*3=63维)
landmarks = data["landmarks"]
feature_vector = []
for lm in landmarks:
feature_vector.extend(lm) # 添加x, y, z坐标
X.append(feature_vector)
y.append(cls_idx)
print(f"加载完成! 共 {len(X)} 个样本,每个样本 {len(X[0]) if X else 0} 维特征")
return np.array(X), np.array(y)
def train_and_evaluate_models():
"""训练多种传统机器学习模型并评估性能"""
# 加载数据
X, y = load_gesture_data()
if len(X) == 0:
print("没有数据可用于训练,请先采集数据")
return
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 保存标准化器
joblib.dump(scaler, "scaler.pkl")
# 定义要训练的模型
models = {
"K近邻分类器": KNeighborsClassifier(n_neighbors=5),
"支持向量机": SVC(kernel='rbf', gamma='scale'),
"决策树": DecisionTreeClassifier(max_depth=10),
"随机森林": RandomForestClassifier(n_estimators=100)
}
# 训练并评估每个模型
best_accuracy = 0
best_model = None
best_model_name = ""
print("\n模型训练和评估结果:")
for name, model in models.items():
# 训练模型
model.fit(X_train_scaled, y_train)
# 预测
y_pred = model.predict(X_test_scaled)
# 评估
accuracy = accuracy_score(y_test, y_pred)
print(f"\n{name} 准确率: {accuracy:.4f}")
print("分类报告:")
print(classification_report(
y_test, y_pred,
target_names=GESTURE_CLASSES.values()
))
# 保存表现最好的模型
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model = model
best_model_name = name
# 保存最佳模型
joblib.dump(best_model, "best_gesture_model.pkl")
print(f"\n最佳模型是: {best_model_name},准确率: {best_accuracy:.4f}")
print("最佳模型已保存为 best_gesture_model.pkl")
print("特征标准化器已保存为 scaler.pkl")
# 绘制最佳模型的混淆矩阵
y_pred_best = best_model.predict(X_test_scaled)
cm = confusion_matrix(y_test, y_pred_best)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=GESTURE_CLASSES.values(),
yticklabels=GESTURE_CLASSES.values())
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title(f'{best_model_name} 混淆矩阵 (准确率: {best_accuracy:.4f})')
plt.savefig('confusion_matrix.png')
print("混淆矩阵已保存为 confusion_matrix.png")
plt.close()
def real_time_recognition():
"""实时手势识别"""
import cv2
import mediapipe as mp
# 加载模型和标准化器
try:
model = joblib.load("best_gesture_model.pkl")
scaler = joblib.load("scaler.pkl")
except FileNotFoundError:
print("未找到模型文件,请先训练模型")
return
# 初始化MediaPipe手部检测
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
cap = cv2.VideoCapture(0)
with mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.7) as hands:
print("实时手势识别开始,按q退出")
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("无法获取摄像头画面")
break
# 转换为RGB并处理
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(image)
# 转换回BGR用于显示
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 检测到手部
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 绘制手部关键点
mp_drawing.draw_landmarks(
image, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# 提取21个关键点的三维坐标并转换为特征向量
landmarks = []
for lm in hand_landmarks.landmark:
landmarks.extend([lm.x, lm.y, lm.z])
# 标准化特征
landmarks_scaled = scaler.transform([landmarks])
# 预测手势
prediction = model.predict(landmarks_scaled)
predicted_class = GESTURE_CLASSES[prediction[0]]
# 获取预测概率
if hasattr(model, 'predict_proba'):
probabilities = model.predict_proba(landmarks_scaled)[0]
max_prob = max(probabilities) * 100
display_text = f"{predicted_class} ({max_prob:.1f}%)"
else:
display_text = predicted_class
# 在画面上显示结果
cv2.putText(image, display_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示画面
cv2.imshow('Real-time Gesture Recognition (q to exit)', image)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
print("实时识别结束")
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='手势识别程序')
parser.add_argument('--train', action='store_true', help='训练模型')
parser.add_argument('--recognize', action='store_true', help='实时识别')
args = parser.parse_args()
if args.train:
train_and_evaluate_models()
elif args.recognize:
real_time_recognition()
else:
print("请指定操作: --train 训练模型 或 --recognize 实时识别")代码分为 3 大核心模块,通过命令行参数( --train / --recognize )切换功能,逻辑链路清晰:
- 数据加载模块:读取上一阶段保存的 JSON 格式手势关键点数据,转换为模型可训练的特征向量。
- 模型训练与评估模块:加载数据后,划分训练 / 测试集、标准化特征,训练 4 种经典机器学习模型并评估性能,最终保存 "最佳模型" 和 "特征标准化器"。
- 实时识别模块:加载已保存的最佳模型和标准化器,通过摄像头实时检测手部关键点,预测手势并在画面上显示结果。
1.模块 1:数据加载( load_gesture_data() )
核心是将 "JSON 格式的 21 个 3D 关键点" 转换为 "模型可训练的一维特征向量",解决 "数据格式适配" 问题:
- 遍历数据目录 :按手势类别(如
gesture_data/fist、gesture_data/open_hand)遍历文件夹,读取每个 JSON 文件; - 特征向量转换 :每个手势样本包含 21 个关键点,每个关键点有(x,y,z)3 个坐标 → 展平为
21×3=63维的一维向量(如[x0,y0,z0,x1,y1,z1,...,x20,y20,z20]),这种 "展平" 是传统机器学习模型的输入要求(模型无法直接处理二维的关键点结构); - 标签匹配 :将每个特征向量与对应的手势标签(如 "fist" 对应标签 0)关联,最终输出
X(特征矩阵,形状为 样本数,63)和y(标签数组,形状为 样本数)。
2.模块 2:模型训练与评估( train_and_evaluate_models() )
这是 "离线训练" 核心,目标是找到 "分类效果最好的模型",关键步骤如下:
-
数据预处理:
- 划分训练集(80%)和测试集(20%):用
stratify=y确保训练 / 测试集中各手势的样本比例与原始数据一致,避免因样本分布不均导致评估偏差; - 特征标准化:用
StandardScaler将特征向量缩放到 "均值为 0、标准差为 1" 的范围 ------ 因为 KNN、SVM 等模型对特征尺度敏感(如 x/y/z 坐标均为 0~1 的归一化值,标准化后更易收敛,提升模型精度)。
- 划分训练集(80%)和测试集(20%):用
-
模型训练与评估:
- 定义 4 种经典模型:覆盖 "lazy learner"(KNN,无需训练仅靠邻居投票)、"核方法"(SVM,适合高维小样本)、"树模型"(决策树 / 随机森林,抗过拟合能力强),对比不同算法的性能;
- 逐模型训练与评估:对每个模型,先在训练集上训练,再在测试集上预测,输出 "准确率" 和 "分类报告"(包含精确率、召回率、F1 值,全面评估对每个手势的分类效果);
- 保存最佳模型:通过准确率对比,选择表现最好的模型,用
joblib.dump()保存为best_gesture_model.pkl,同时保存标准化器scaler.pkl(实时识别时需用同一标准化器处理新数据)。
-
结果可视化:
- 绘制最佳模型的混淆矩阵:用热力图展示 "真实标签" 与 "预测标签" 的对应关系,直观看到模型对哪些手势容易误判(如是否常把 "指向" 误判为 "OK"),并保存为
confusion_matrix.png。
- 绘制最佳模型的混淆矩阵:用热力图展示 "真实标签" 与 "预测标签" 的对应关系,直观看到模型对哪些手势容易误判(如是否常把 "指向" 误判为 "OK"),并保存为
3.模块 3:实时识别( real_time_recognition() )
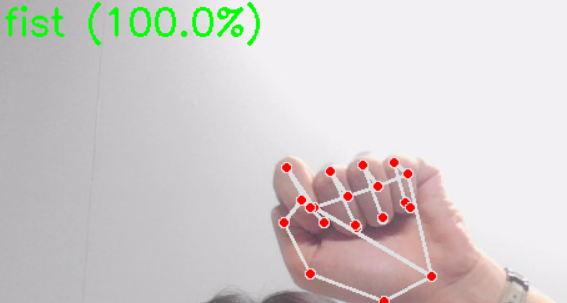
这是 "在线预测" 核心,基于训练好的模型实现实时手势判断,逻辑与 "数据采集" 强关联但目标不同(采集是 "存数据",识别是 "用模型判类别"):
- 模型加载 :先读取
best_gesture_model.pkl和scaler.pkl,若文件不存在则提示 "先训练模型"; - 实时关键点提取:用 MediaPipe 检测摄像头画面中的手部关键点,提取方式与 "数据采集" 完全一致(确保特征格式统一);
- 预测流程 :
- 特征处理:将实时提取的 21 个 3D 关键点展平为 63 维向量,用加载的
scaler标准化(必须与训练时的标准化规则一致,否则预测失效); - 模型预测:将标准化后的特征输入最佳模型,得到预测标签(如 0→"fist");
- 结果显示:在画面上绘制手部关键点,并显示 "预测手势 + 置信度"(若模型支持
predict_proba,则显示最大概率,如 "fist (98.5%)",增强结果可信度);
- 特征处理:将实时提取的 21 个 3D 关键点展平为 63 维向量,用加载的
- 退出逻辑 :按
q键释放摄像头资源,关闭窗口。