在大语言模型(LLM)如雨后春笋般涌现的今天,我们常常会看到各种复杂的模型名称,比如 Qwen3-4B-Instruct-2507、gemini-2.5-pro 或 DeepSeek-R1-GGUF。这些名字看似神秘,实则蕴含着丰富的信息。一个模型的名字,就是它的"简历"。从厂商到参数,从性能到部署,每一个细节都在告诉你:它是什么、能做什么、适合谁用。
本文将带你系统拆解大模型的命名规则与关键参数,从此不再困惑于"模型叫什么"、"它到底有多强"。
一、名称与版本:模型的身份标识
1. 厂商名称
-
定义:标识模型研发或出品的厂商/品牌。
-
示例:
-
qwen(通义千问厂商)
-
gemini(谷歌厂商)
-
✅ 这是模型的"姓氏",告诉你它是谁家的孩子。
2. 版本信息
-
定义:模型迭代更新的版本序列或代次。
-
示例:
-
qwen3(通义千问第3代)
-
deepseek V3.1(深度求索V3.1)
-
🔁 版本号反映技术演进路径,数字越大通常代表越新、越强。
3. 发布日期
-
定义:模型版本发布或更新的日期标识。
-
示例:Qwen3-4B-Instruct-2507(2025年7月发布)
📅 时间戳帮你判断模型是否"新鲜出炉",避免使用过时版本。
二、参数信息:模型的"大脑容量"
1. 绝对参数量
-
定义:模型所有可训练参数的总和(如权重、偏置),单位为B(十亿)或T(万亿)。
-
示例:Qwen3-235B(2350亿参数)
💡 参数越多,模型潜力越大,但训练成本也越高。
2. 相对参数量
-
定义:以相对尺度体现参数量级的标识,常用于区分大小模型。
-
示例:
-
gpt-4.1-mini(小量级参数)
-
mistral-medium(中量级)
-
📏 "mini"、"medium"、"large"等词帮助快速判断模型规模。
3. 激活参数量
-
定义:在动态架构(如MoE,混合专家模型)中,单次推理实际参与计算的参数子集。
-
示例:Qwen3-30B-A3B(总参300亿,激活30亿,占比10%)
⚙️ 激活参数量决定实时计算效率,是轻量化设计的关键指标。
三、性能分级:模型的能力标签
1. 响应速度
-
定义:模型生成回复的快慢程度。
-
示例:
-
gemini-2.5-flash(快速响应)
-
grok-4-fast(高速)
-
⏱️ "flash"、"fast"等关键词提示其适合低延迟场景,如实时对话。
2. 模型能力
-
定义:模型综合功能与性能的等级划分。
-
示例:
-
qwen3-plus(增强级)
-
gemini-2.5-pro(专业级)
-
🌟 "lite"、"pro"、"max"等后缀表示能力层级,越高级越全能。
四、量化部署:让模型跑得更快更省
1. 量化信息
-
定义:模型的量化精度和压缩方法。
-
示例:gemma-3-27b-it-q4_0(4bit量化)
📉 量化降低内存占用和计算开销,常见有4bit、8bit等,数值越小越轻量。
2. 部署框架
-
定义:模型适配的部署格式或框架。
-
示例:
-
Llama-2-7b-chat-mlx(MLX框架部署)
-
DeepSeek-R1-GGUF(llama.cpp、ollama部署)
-
🖥️ 不同框架适用于不同平台,GGUF适合本地运行,MLX适合苹果设备。
五、其他主题:更多隐藏细节
1. 开源信息
-
定义:模型是否开源及其属性。
-
示例:gpt-oss-20b(开源)、oss开源
🆓 开源意味着可自由下载、修改和部署,适合开发者和技术爱好者。
2. 专用场景
-
定义:模型针对特定任务优化的设计。
-
示例:datagemma-rag-27b-it(适配RAG检索增强场景)
🎯 专为某类任务打造,如RAG、代码生成、数学推理等。
3. 语言支持
-
定义:模型主要适配或优化的语言种类。
-
示例:Llama3-8B-Chinese-Chat(中文优化)
🌍 支持多语言还是专注某一语种?看这里就知道。
4. 上下文长度
-
定义:模型可处理的最大token数量。
-
示例:Phi-3-mini-128k(支持128K上下文)
📄 上下文越长,越能理解长文档、复杂逻辑,适合阅读分析类任务。
5. 全模态
-
定义:模型支持的多模态处理能力。
-
示例:gpt-4o-mini、o代表omni全模态
🖼️ 能看图、听音、读文本?全模态模型正在成为新一代AI标配。
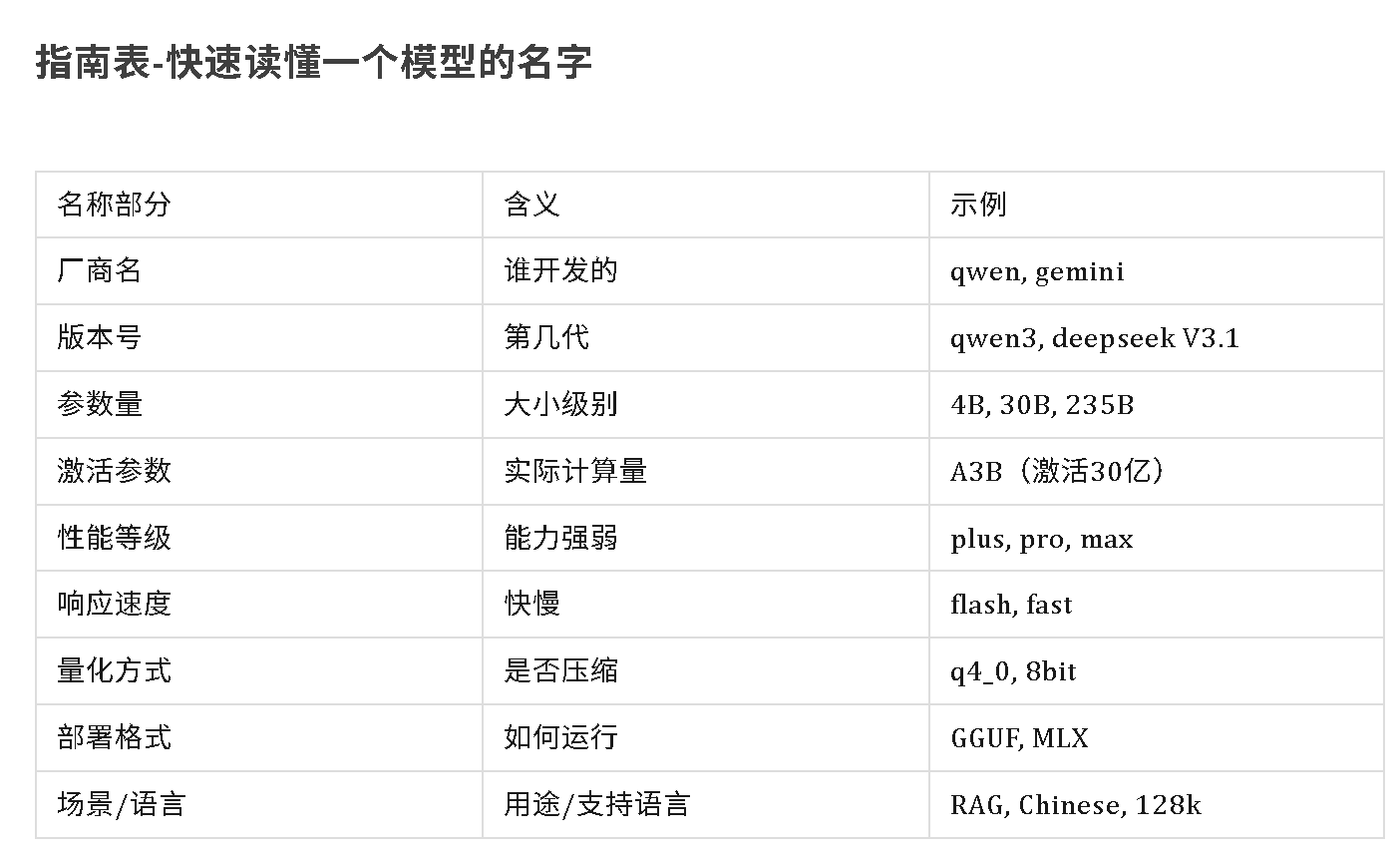
实例解析:
模型名称: Qwen3-4B-Instruct-2507-flash-q4_0,这是通义千问第三代、40亿参数、指令优化版、2025年7月发布、快速响应、4bit量化、适合本地部署的轻量级模型!
六、大模型分类
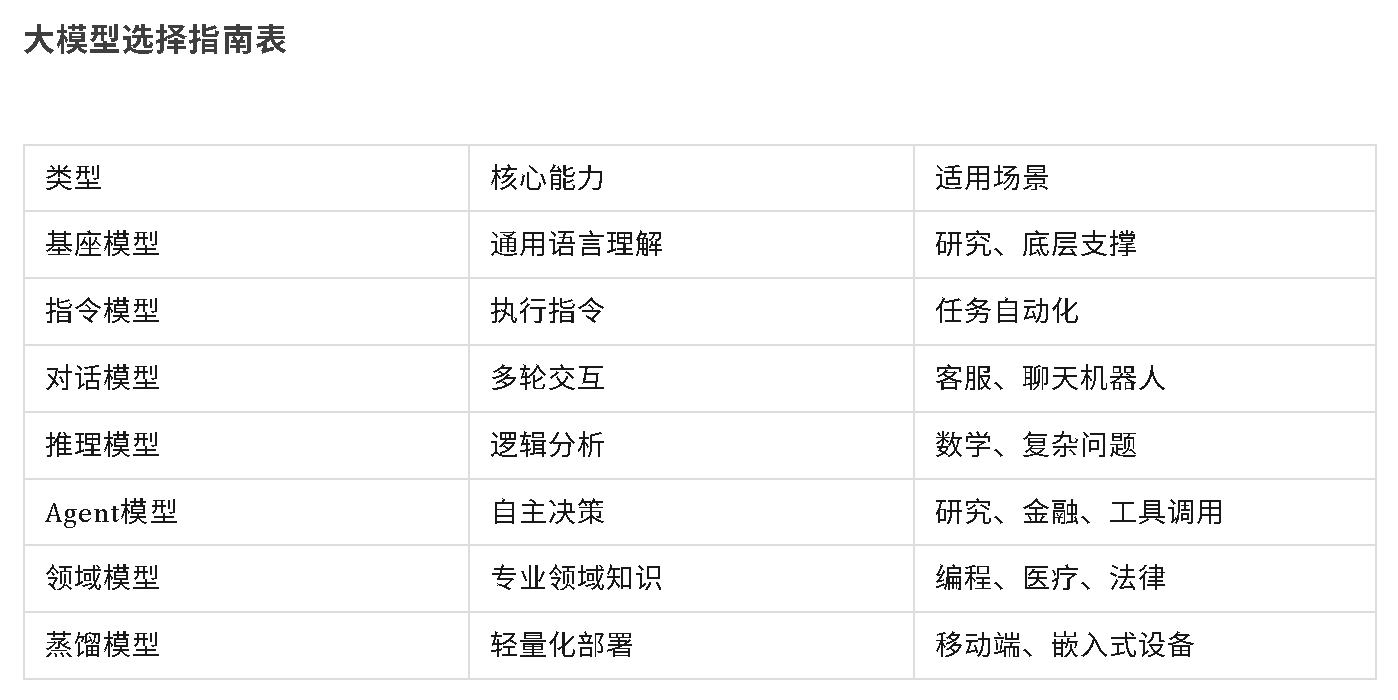
1. LLM(基座模型)
-
定义:未经任务微调的通用预训练语言模型,具备基础语言能力。
-
训练方式:大规模无监督预训练。
-
示例:GPT-3、Qwen-7B。
-
典型场景:模型预研、基础文本生成底座。
✅ 基座模型是所有其他模型的基础,相当于"原始语言能力"的载体。
2. LLM-Instruct(指令模型)
-
定义:擅长理解并执行自然语言指令的任务导向型模型。
-
训练方式:SFT(监督微调)+ RLHF(基于人类反馈的强化学习),结合对话数据增强。
-
示例:Kimi-K2-Instruct、Qwen3-4B-Instruct-2507。
-
典型场景:代码生成、信息提取、专项任务处理。
💡 指令模型让AI更"听话",能准确响应用户的明确需求。
3. LLM-Chat(对话模型)
-
定义:针对多轮对话优化,具备上下文感知能力的交互模型。
-
训练方式:SFT + RLHF,使用指令-响应数据进行增强。
-
示例:ChatGPT、Qwen-7B-Chat。
-
典型场景:智能客服、闲聊机器人、人机对话交互。
🗨️ 对话模型专注于流畅、连贯的交流体验,适合日常沟通场景。
4. LLM-Thinking(推理模型)
-
定义:具备逻辑推理能力,支持分步思考的高级模型。
-
训练方式:思维链微调(Chain-of-Thought)、RLHF等。
-
示例:LongCat-Flash-Thinking、Qwen3-4B-Thinking-2507。
-
典型场景:数学解题、逻辑分析、复杂问题拆解。
🔍 推理模型像"数学家"或"侦探",擅长一步步解决问题。
5. LLM-Agentic(Agent模型)
-
定义:强化自主决策、工具调用与多步推理的智能体模型。
-
训练方式:Agentic CPT、Agentic SFT、Agentic RL。
-
示例:Tongyi-DeepResearch-30B-A3B。
-
典型场景:复杂研究、金融分析、多工具协同等深度推理任务。
🤖 Agent模型是"超级助手",不仅能思考,还能主动行动和调用外部工具。
6. LLM-Domain(领域模型)
-
定义:针对特定领域知识优化的专业语言模型。
-
训练方式:领域知识CPT(持续预训练)、领域指令SFT。
-
示例:Qwen2.5-Coder-32B、medgemma-4b。
-
典型场景:代码编程、医疗辅助、法律解读、金融咨询等垂直领域。
🎯 领域模型专精于某一行业,提供精准且专业的服务。
7. LLM-Distill(蒸馏模型)
-
定义:将大模型的知识压缩至小模型的轻量化版本。
-
训练方式:KD(知识蒸馏)技术。
-
示例:DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B。
-
典型场景:边缘设备、移动端等低算力环境部署。
⚙️ 蒸馏模型兼顾性能与效率,是落地应用的关键桥梁。
七、大模型选择指南
参考文献: