LLM/MLLM RL微调的时大概率都踩过这个致命的坑:90%的GPU算力都花在了rollout采样上,可模型精度就是纹丝不动;训到后期看梯度,几乎全是接近0的无效值,烧了算力,全做了无用功。
Shuffle-R1没有卷更复杂的策略梯度算法,也没有堆更花哨的奖励函数设计,而是回归「数据」这个最本质的问题,用一套简单的方案提升RL训练效率。
一、根因:90%的RL算力浪费,都源于这两个被忽略的问题
在讲方法之前,先把「RL微调为什么效率低」这件事说透。
自从DeepSeek-R1把「结果可验证的RL」带火之后,行业里的优化方向基本都集中在两个维度:要么改策略梯度目标函数(PPO→GRPO→DAPO→GSPO),要么堆更高质量的训练数据、更复杂的奖励设计。但几乎所有人都默认了一个静态范式:
对每个query采样N条rollout→算奖励和优势→所有轨迹一视同仁,全部扔进模型做梯度更新→每条轨迹只用一次,下一轮重新采样。
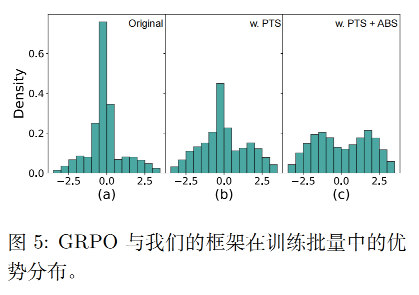
如下图:Advantage Collapsing(优势坍缩) 和 Rollout Silencing(滚动静默)。
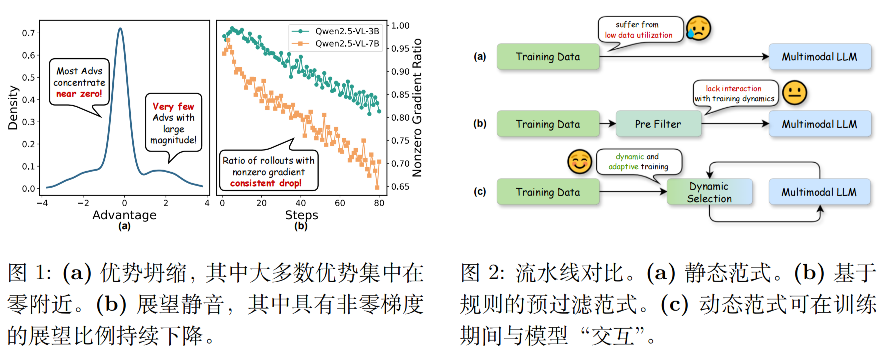
1. Advantage Collapsing(优势坍缩)
模型的梯度更新强度,和优势值(Advantage)的绝对值正相关。优势值是对「这条轨迹比平均水平好多少/差多少」的量化,只有绝对值足够大的优势,才能带来有效的梯度更新。
但论文通过探针实验发现了一个反常识的现象:在标准RL训练中,一个batch里超过80%的优势值,都会集中在0附近。
- 比如一个query采样16条rollout,可能只有2条的优势绝对值大于1,剩下14条全在±0.2以内;
- 这些近0优势的轨迹,带来的梯度信号可以忽略不计,却会占用绝大多数的更新带宽,直接把少数有效轨迹的梯度淹没了;
- 行业里常用的解法是「增加单query的rollout数量」,比如从8条加到32条,可这只会让采样算力翻4倍,完全没解决「有效信号占比极低」的根源问题。
这就是优势坍缩:你的梯度更新,从一开始就被绝大多数无意义的噪声轨迹绑架了。
2. Rollout Silencing(滚动静默)
比优势坍缩更致命的,是滚动静默 :随着训练推进,能为模型贡献非零梯度的rollout占比,会持续断崖式下跌。
论文里的实验显示,训到后期,超过70%的rollout完全无法带来任何有效梯度,算力直接被浪费。核心原因有三个:
- 简单query过早收敛,模型已经能100%答对,所有rollout的奖励都是1,归一化后的优势全是0,完全没有梯度;
- 困难query始终学不会,所有rollout的奖励都是0,优势也全是0,同样没有梯度;
- 标准范式里,每条rollout只被用一次,哪怕是极少数能带来强梯度的高价值轨迹,也只更新一次就被丢弃了,数据利用率低到极致。
这两个问题,才是RL微调「烧钱不出活」的根因。
二、Shuffle-R1方法
Shuffle-R1:模型在什么数据上更新,和模型怎么更新,同等重要。没有推翻现有的RL训练范式,而是在「rollout采样」和「梯度更新」之间,加了两个完全解耦、可插拔的模块,不改变损失函数、优化器、超参,就能直接带来效率和精度的提升。
整体流程一句话概括:先通过成对轨迹采样(PTS) 筛选出梯度最丰富的高对比度轨迹,解决优势坍缩;再通过基于优势的批次混洗(ABS) 放大高价值轨迹的曝光,解决滚动静默。
模块一:Pairwise Trajectory Sampling (PTS) 成对轨迹采样
核心目标:过滤噪声轨迹,把梯度信号的对比度拉满
先问大家一个问题:RL训练里,什么样的轨迹,能带来最有效的梯度更新?
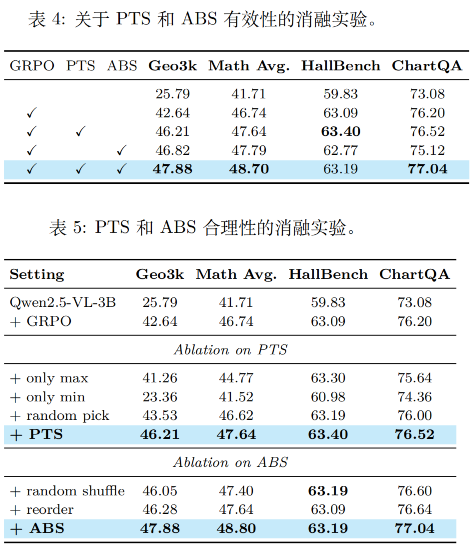
很多人的第一反应是「奖励最高的正样本」,但论文的消融实验直接推翻了这个认知:只选top-K的正样本,效果甚至比基线GRPO还差。
原因很简单:RL的策略学习,本质上是对比学习。模型只看「什么是对的」,根本学不到决策边界;只有同时知道「什么是对的、什么是错的」,形成强对比,梯度才会最锐,学习效率才最高。
这就是PTS的核心设计思路:不孤立评估单条轨迹,而是通过Max-Min双向配对,构建高对比度的正负轨迹对,只保留最有学习价值的样本。
具体执行步骤
- 扩展采样池 :对每个query,我们采样
2N条rollout(比如论文里N=8,就是16条),而不是传统的N条。这里的扩展,是为了获得更大的样本池,提升抓到高对比度轨迹的概率,后续我们会筛选掉一半,不会增加梯度计算的开销。 - 优势排序 :计算每条rollout的奖励和归一化优势值,把
2N条轨迹按优势值降序排序,从最高正优势,排到最低负优势。 - Max-Min双向配对 :用「最高-最低、第二高-第二低」的方式,把
2N条轨迹组成N个轨迹对。- 举个例子:16条轨迹排序后是A1>A2>...>A16,配对就是(A1,A16)、(A2,A15)...(A8,A9);
- 这样配对的好处是:top-rank的轨迹对,天然就是「高正优势+高负优势」的强对比正负样本,优势差拉到最大,梯度信号最丰富;而bottom-rank的轨迹对,两条的优势都接近0,完全没有学习价值。
- Top-K筛选 :设置采样比例
α(论文最优值α=0.5),只保留前M=α*N个高对比度轨迹对,剩下的直接过滤掉。比如N=8、α=0.5,就是从8个配对里保留前4个,最终8条轨迹进入后续更新,和传统范式的单query样本量完全一致。
为什么这个设计能打?
- 从根源解决优势坍缩:直接把近0优势的噪声轨迹全部过滤掉,梯度更新的带宽100%集中在高对比度的有效样本上,再也不会出现「噪声淹没信号」的问题;
- 梯度锐化效果拉满:正负样本的强对比,让模型能同时学习「正确的推理路径」和「错误的决策陷阱」,比只看正样本的学习效率高得多;
- 零额外梯度开销:虽然我们采样了2N条rollout,但最终进入梯度计算的只有N条,和传统范式的计算量完全一致,多出来的采样开销,在大模型训练里几乎可以忽略不计。
模块二:Advantage-based Batch Shuffle (ABS) 基于优势的批次混洗
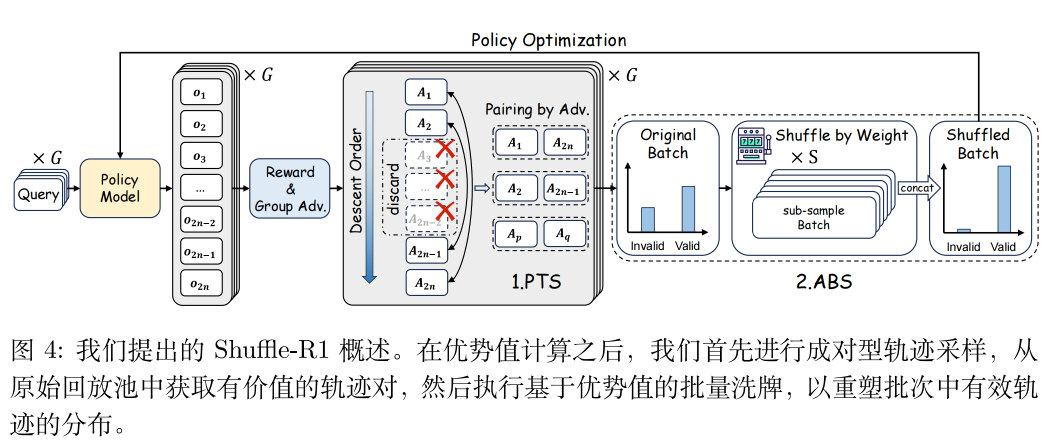
核心目标:提升高价值轨迹的利用率,解决滚动静默
PTS帮我们筛选出了高价值的轨迹对,但还有一个问题没解决:传统范式里,每条轨迹只用一次,哪怕是梯度最丰富的样本,也只更新一次就被丢弃了,完全浪费了它的学习价值。
很多人这里会想到「优先经验回放(PER)」:把高价值样本存起来,后续训练反复采样。但PER有个致命的缺陷:样本的优势值是基于旧策略计算的,模型更新之后,这个优势值就不准了,反复用旧样本训练,很容易导致过拟合、策略坍缩。
而ABS的设计,完美避开了这个坑,它的核心是:在线、同批次、基于当前策略的加权混洗,不存任何历史样本,只用当前batch里刚算出来的新鲜优势值,做动态调度。
具体执行步骤
- 权重计算 :对PTS输出的全局批次B里的每个轨迹对,我们给它分配一个重要性权重:权重等于该对里两条轨迹的绝对优势值之和,公式是:
W(pj)=∣A^j,1∣+∣A^j,2∣W(p_j)=|\hat{A}{j,1}|+|\hat{A}{j,2}|W(pj)=∣A^j,1∣+∣A^j,2∣
优势绝对值越大的轨迹对,权重越高,被采样的概率越大。 - 构建加权采样分布:把所有轨迹对的权重做归一化,形成整个批次上的采样分布Φ,确保高价值轨迹对有更高的采样概率。
- 带权子采样与批次重构 :基于分布Φ,做S次子采样,每次子采样取T个轨迹对,保证
S*T = 原批次大小,最终把所有子采样的批次拼接,形成和原批次大小完全一致的混洗批次B',用于梯度更新。- 论文里的最优设置S=8,也就是做8次子采样,高价值轨迹对大概率会被多次采样,低价值的可能一次都不会被选中;
- 细节:保证了混洗后的批次大小和原批次完全一致,所以原来的梯度更新、优化器、超参,一行都不用改。
设计思想
- 解决滚动静默:高价值轨迹会被多次采样,获得更多的更新机会,再也不会出现「有效样本只用一次就丢」的问题,数据利用率直接拉满;
- 避开PER的缺陷:所有采样都基于当前batch、当前策略刚算出来的优势值,没有任何历史 stale 样本,不会出现过拟合、策略偏移的问题;
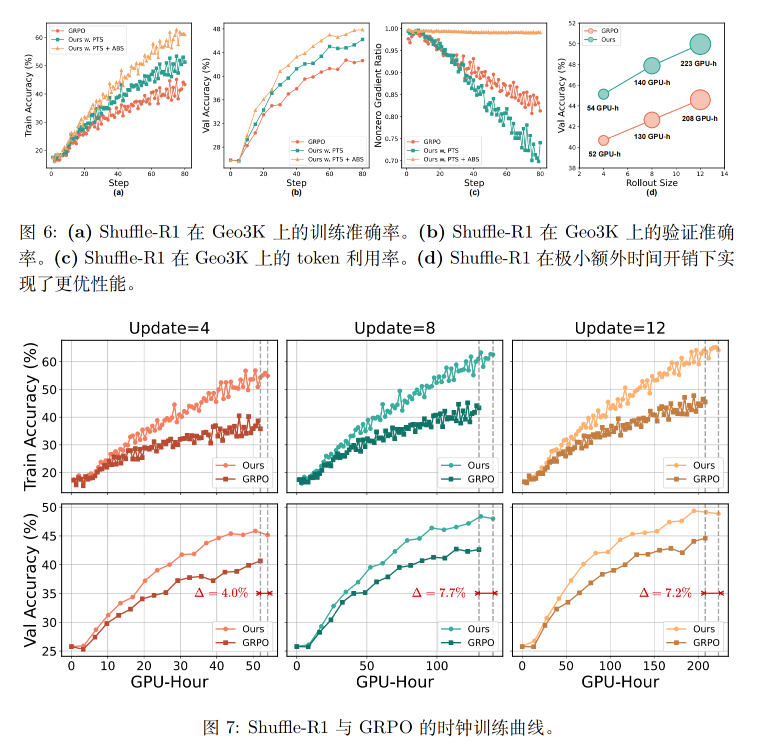
- 工程成本低:只是对批次内的样本做了一次加权重采样,计算开销可以忽略不计,论文里实测总GPU时间仅比基线增加4%~7.7%。
verl等后训练框架适配思路
原有流程:
1. 输入query,采样rollout
2. 计算奖励和优势值
3. 送入模型做梯度更新
Shuffle-R1改造后流程:
1. 输入query,采样2N条rollout
2. 计算奖励和优势值
3. 【新增PTS】Max-Min配对,筛选top-α*N个轨迹对,组成基础批次
4. 【新增ABS】基于优势加权,对批次做S次子采样混洗,重构最终批次
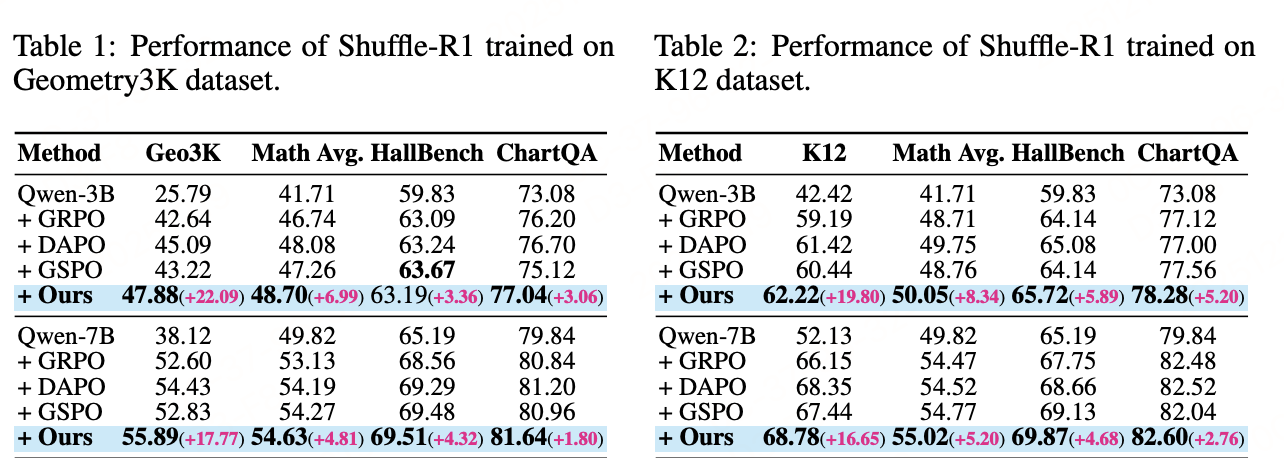
5. 送入模型做梯度更新实验
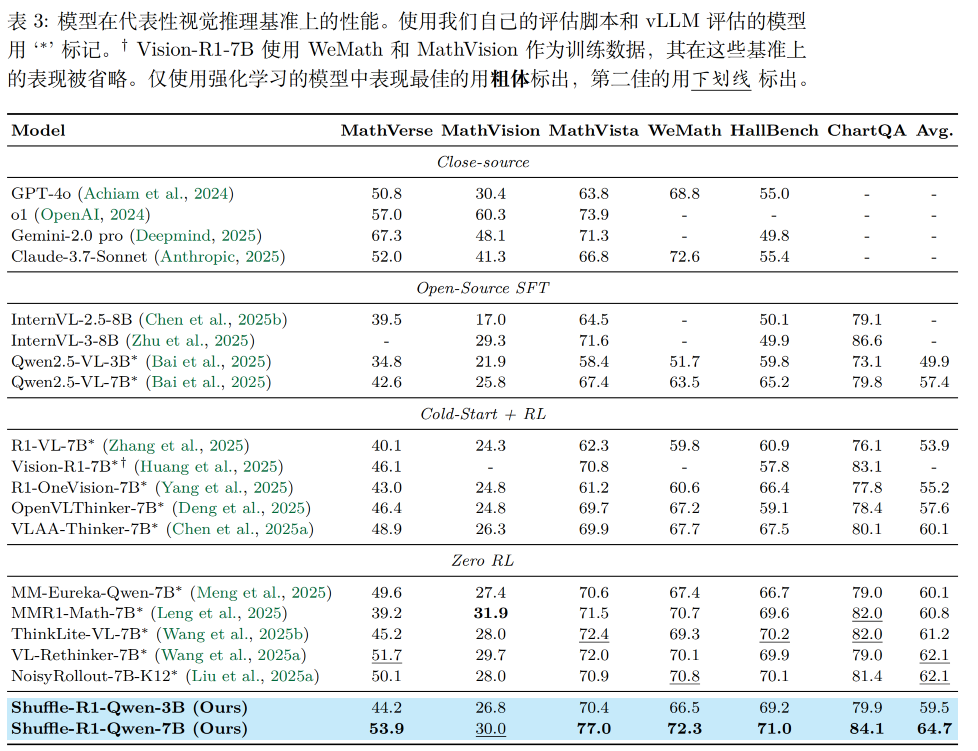
参考文献
SHUFFLE-R1: EFFICIENT RL FRAMEWORK FOR MULTIMODAL LARGE LANGUAGE MODELS VIA DATA-CENTRIC DYNAMIC SHUFFLE,https://arxiv.org/pdf/2508.05612v6