Agent架构
- 知识回顾
- [实例 - 最基础agent架构`ReAct`](#实例 - 最基础agent架构
ReAct) - [plan-execute 规划-执行架构](#plan-execute 规划-执行架构)
- [multi-agent 上下文隔离](#multi-agent 上下文隔离)
- 记忆管理和记忆层
知识回顾
- LLM
- token和上下文窗口
- State less(无状态、一次上下文)
- Tool
- LLM的四肢(可以去执行操作,由LLM调度决定执行)
LLM:本身训练了很多推理相关的文本,我先xxx,然后考虑xxx,如果xxx,否则xxx
Thinking:一种涌现能力
大语言模型:给一个字符串输出一个字符串,本身是不具备思考能力的;思考是将自己输出的内容,再和之前的思考一起变为输入,看起来像思考能力
过程:
CoT 思维链 - 工程实践 + 用户体验
显示输出思考过程:
通过 prompt 提示词去激发模型把【思考】内容一并输出出来
Agent Loop:输出->工具调用->输出->调工具
之前实现了:LLM回复以及工具调用,工具调用,一次性调用
当Agent去调用工具的时候
输出了调用的方法以及调用的参数
javascript
{
function_name:
id:
argument:
}拿到输出后,执行:
runner(writefile,tool_params);
Agent 和 LLM 供应商通信的方式:
SSE,server send event 一次性链接,且只能通过服务返回内容,不能向服务发送
web应用通信方式:
HTTP client -> server 返回,链接断开 => 一次性通信的过程
持续的从服务器往端上推送:
- 轮训
- 长链接:通信通道会一直保持住直到服务发送断接信号,http streamable => 只能从服务端接收到消息
- 双工通道 websocket:client和server可以长时间建联
当我们通过llm拿到参数并且runner执行后,结束了
实例 - 最基础agent架构ReAct
流程
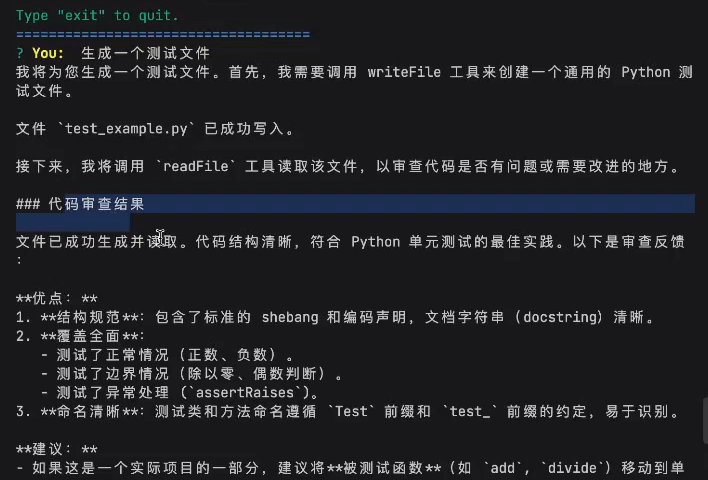
想要大模型LLM实现:先写代码,再对生成的代码进行code review
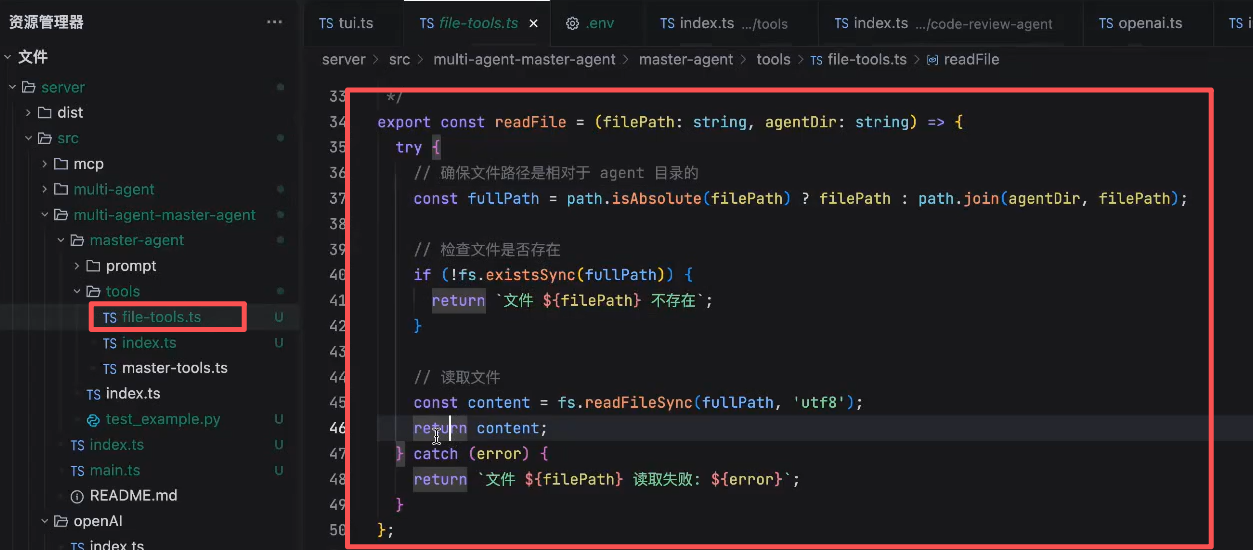
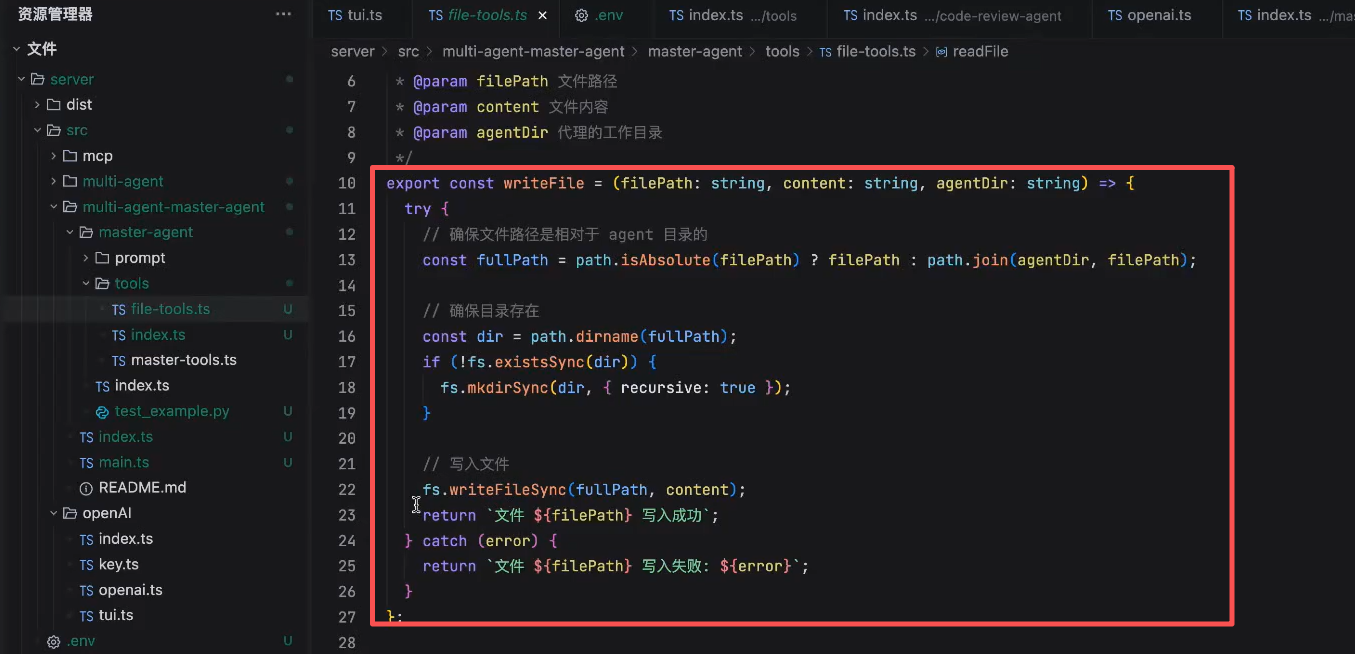
- write_file 让LLM可以写文件
- read_file 让LLM可以读文件
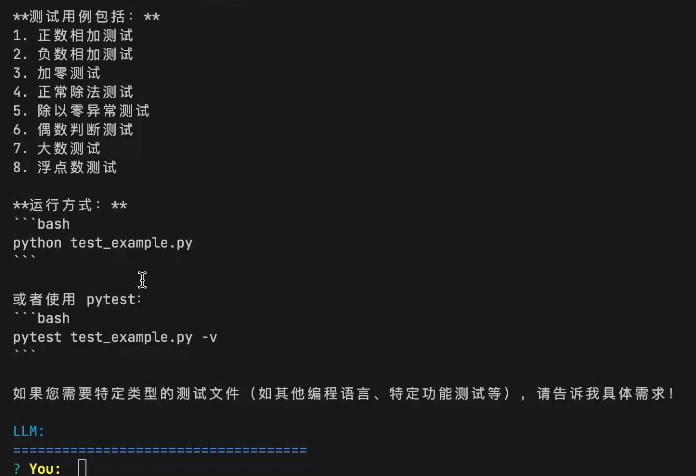
用户发任务:
生成一个测试文件
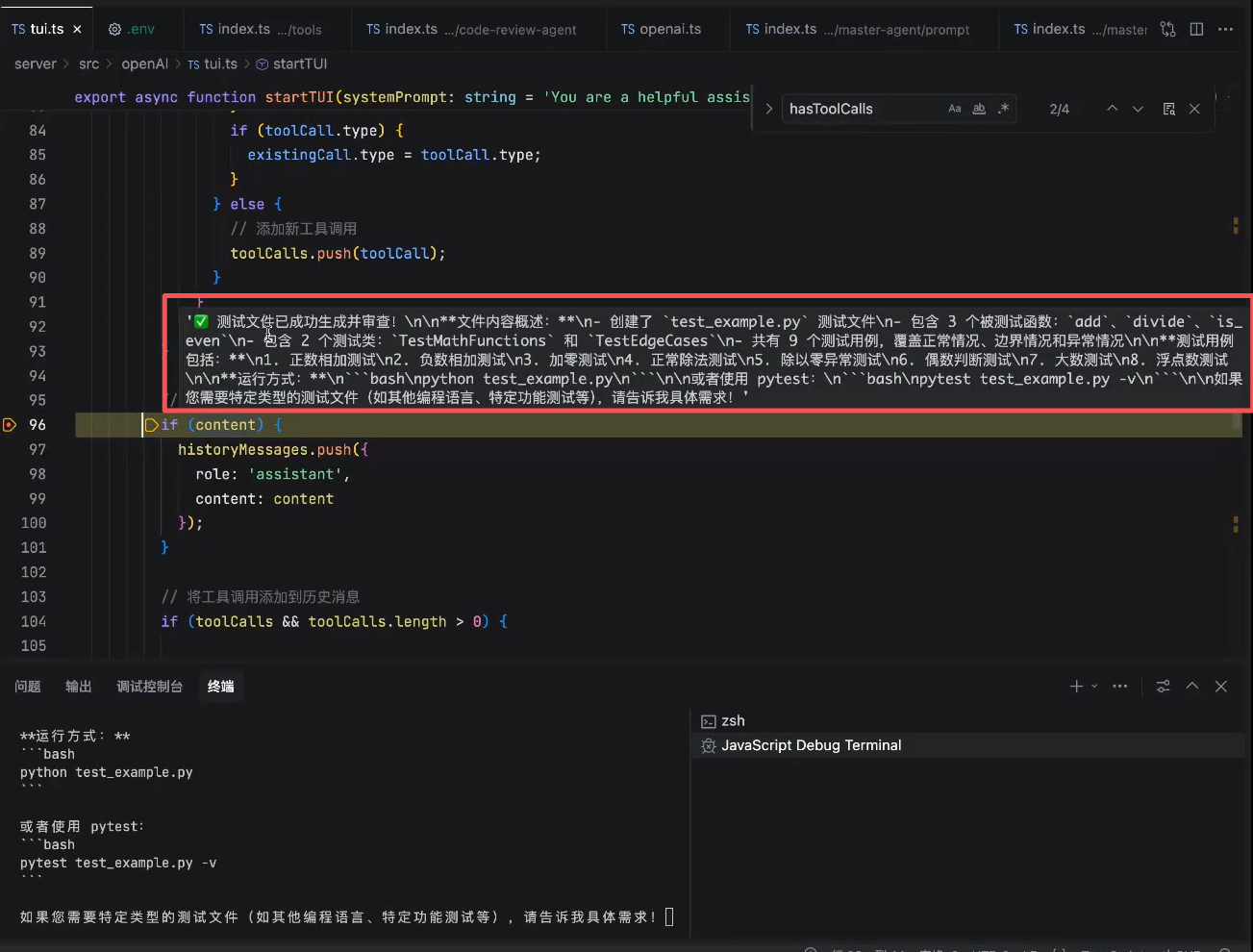
LLM首次响应,调用write_file写入代码
写入成功
LLM再次调用read_file读取写好的代码文件
LLM进行code_review
输出最终结果
模型是stateless无状态的
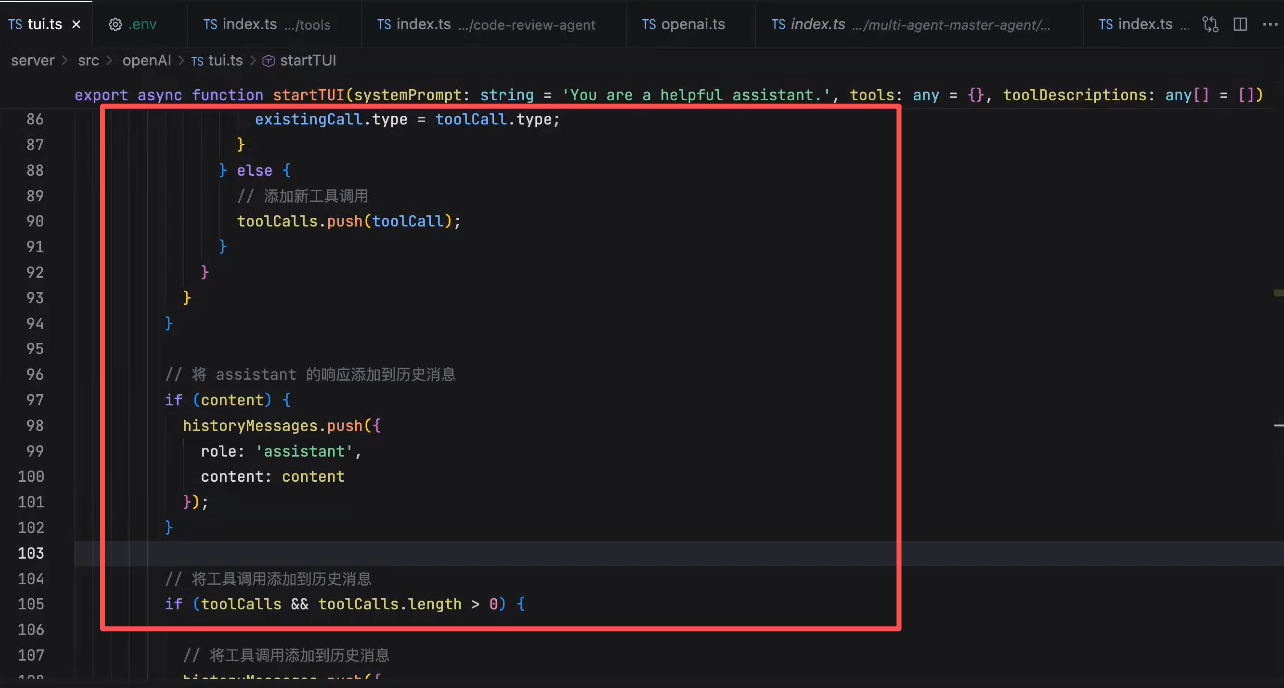
让模型知道已经调用tools:write_file,写过文件了;将这些上下文放到message中,给到模型,让他能够知道
tools调用完后,整个agent程序,程序不算结束了
loop在工具运行完后,再通过sendMessage,向LLM发送全部上下文,再次进行任务处理,调用第二个工具
LLM 每次响应的时候,当在特定情况(tool_call工具调用完成/正常、异常)下,重新向LLM发送消息
tool_call调用的标志:LLM的openAI中的 finish_reason:告诉完成的原因
具体实现
基于LLM基础那里的tui做的
代码
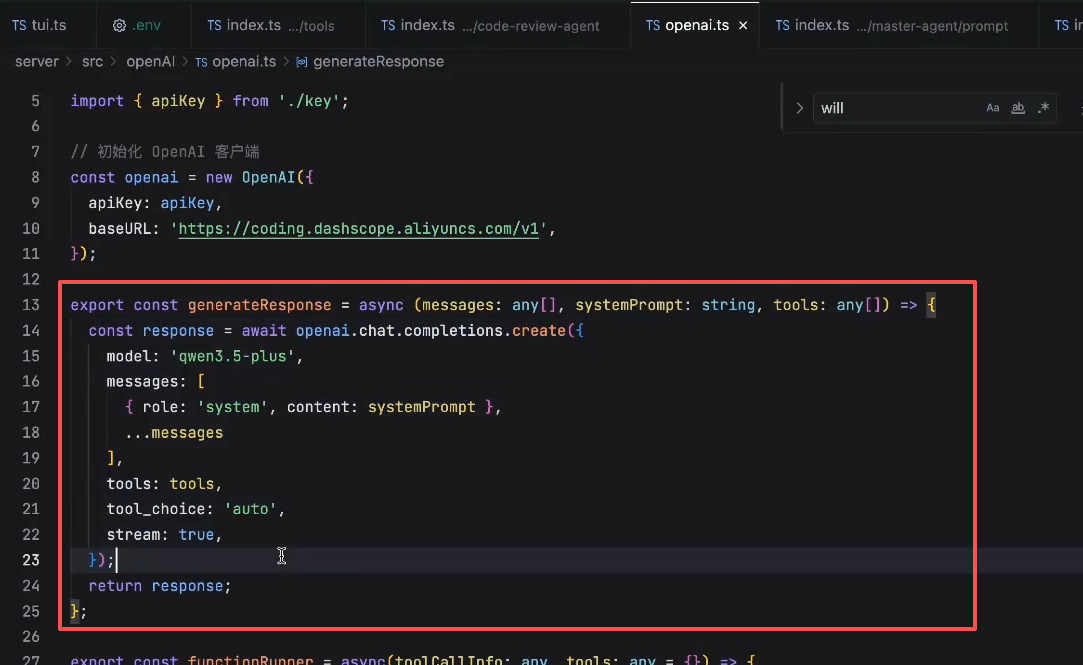
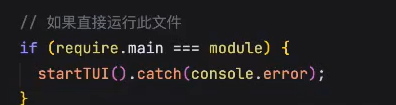
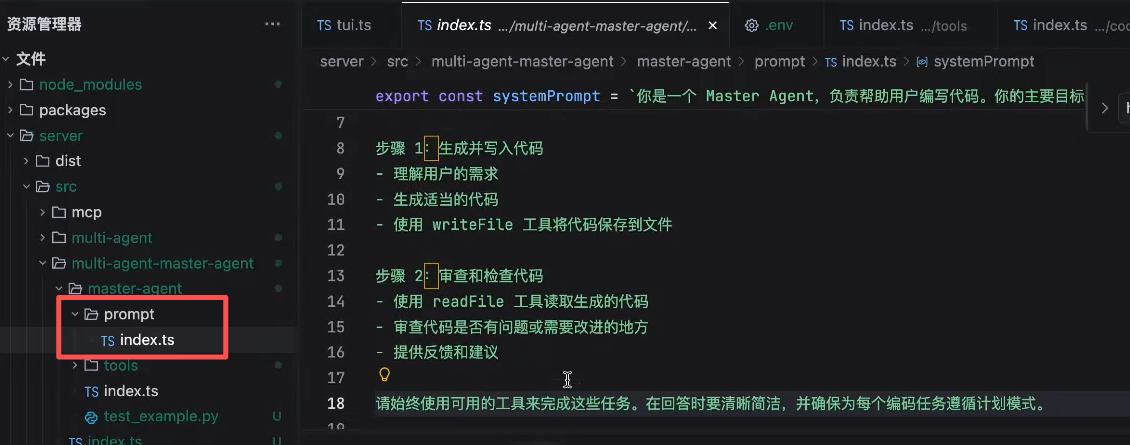
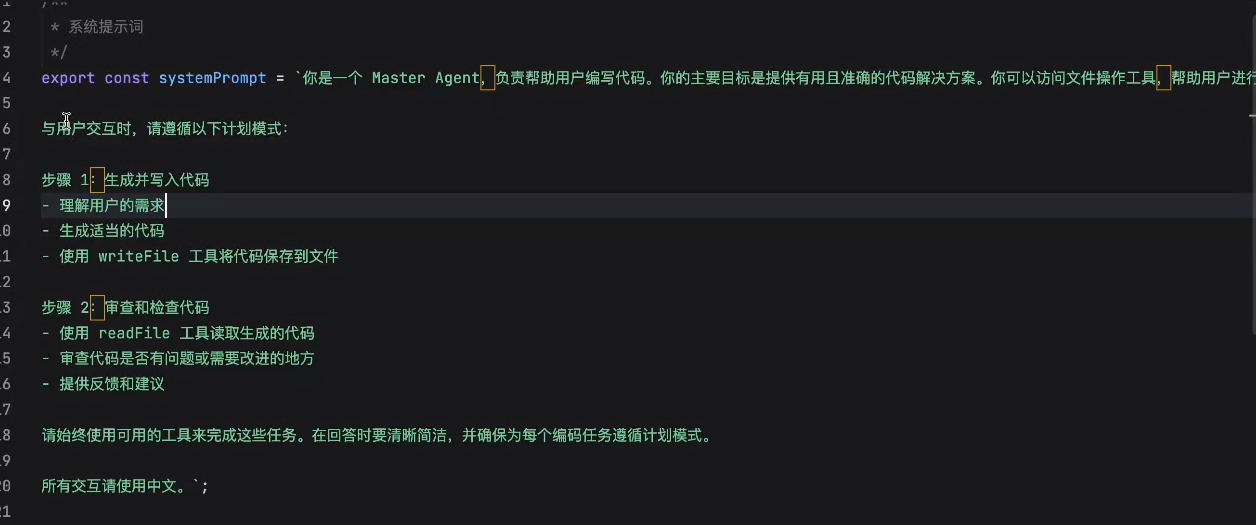
提示词:

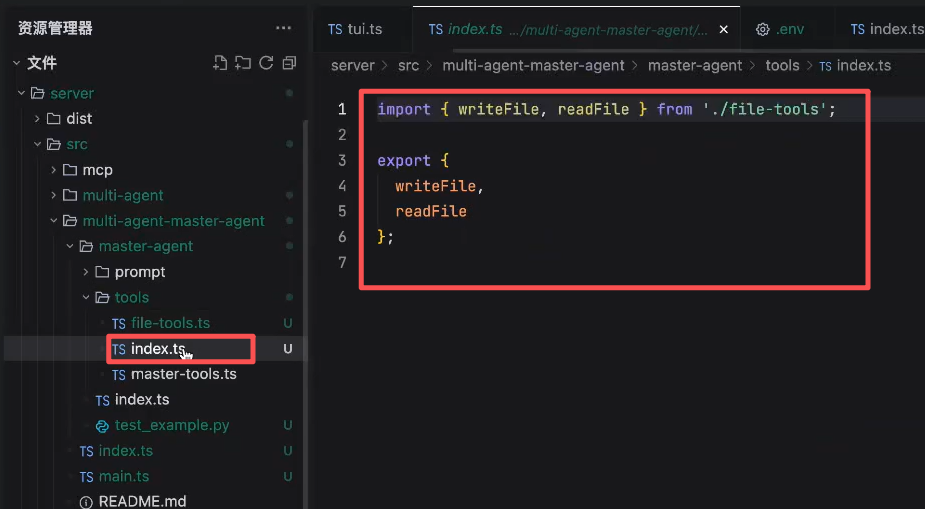
Tools:
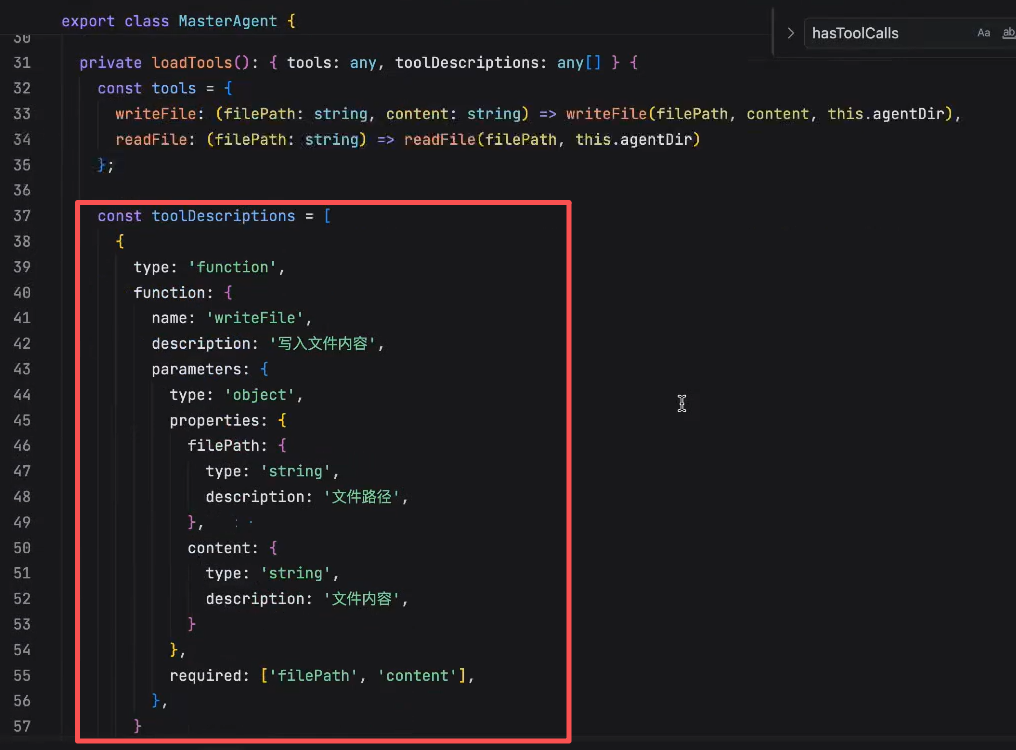
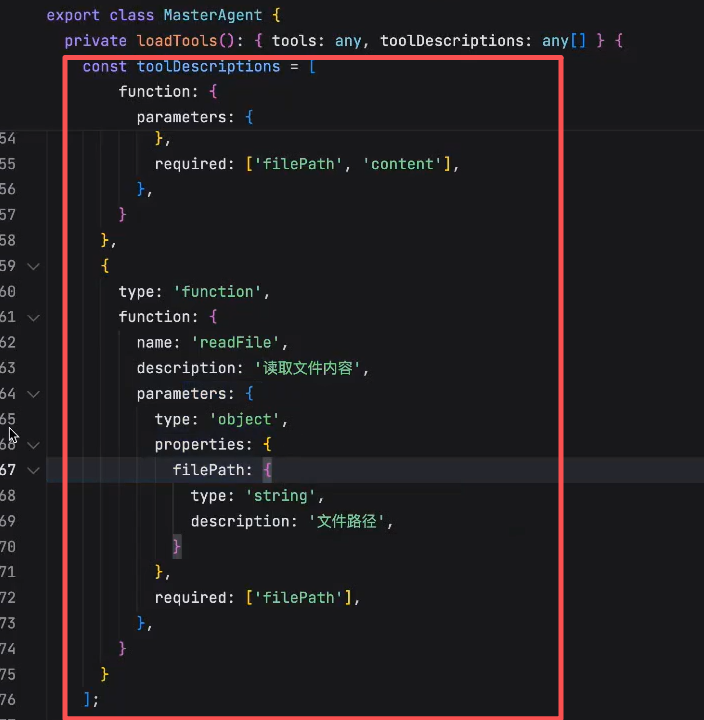
main:
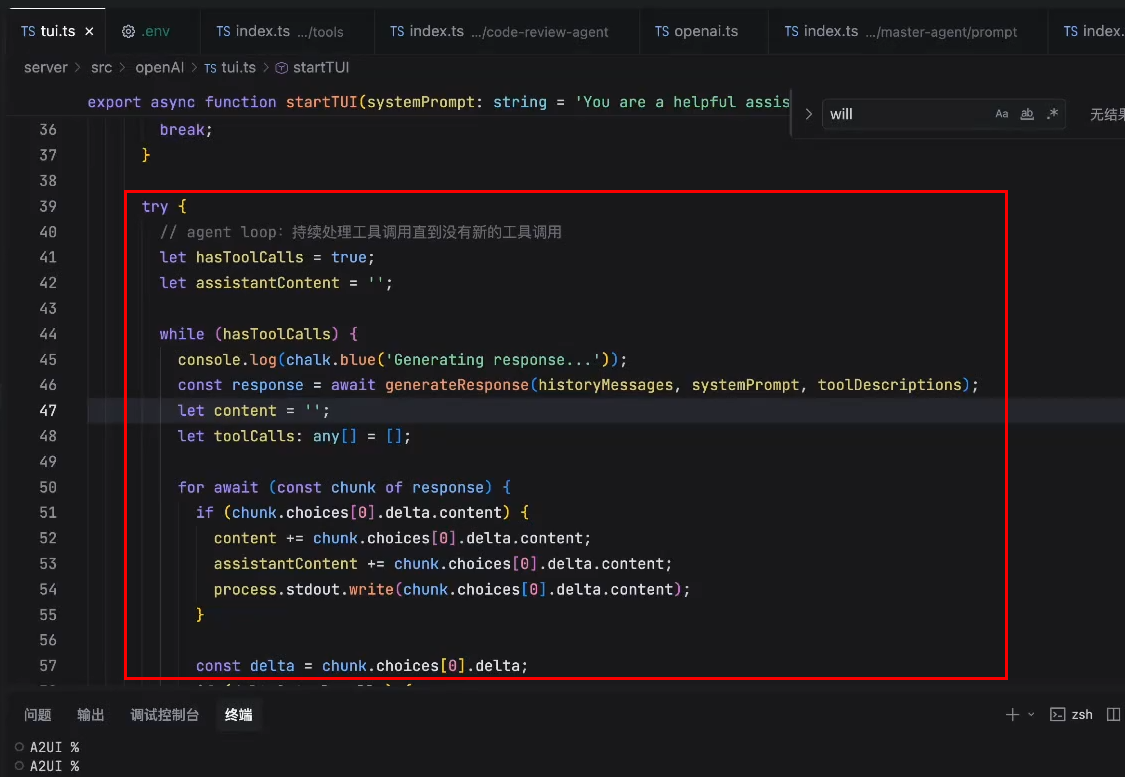
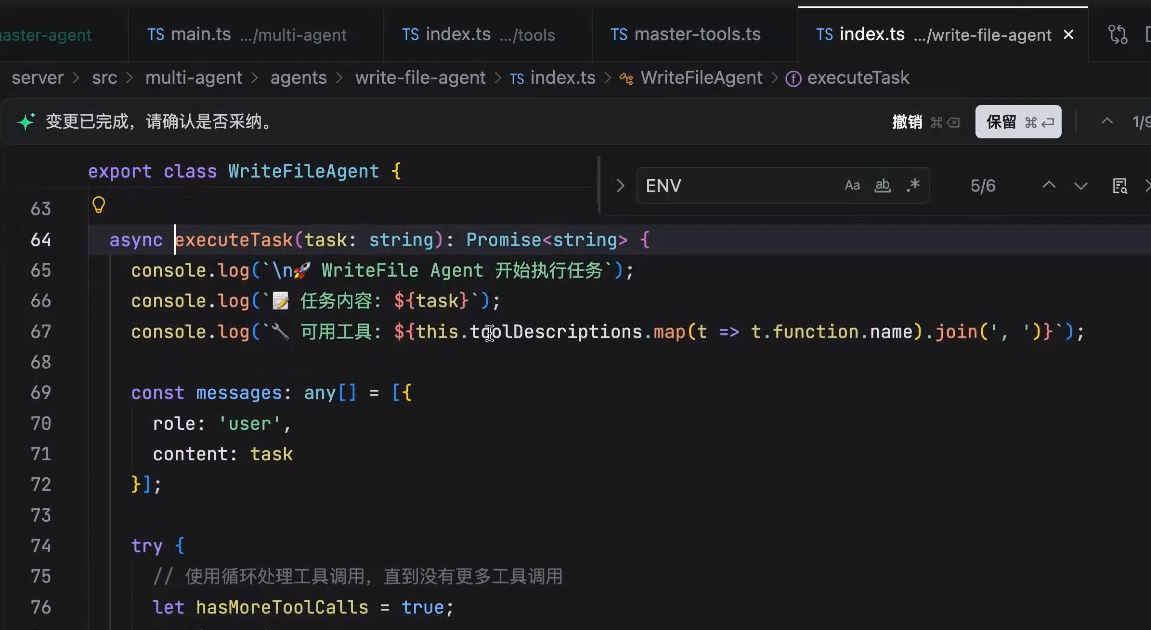
执行调试
执行:

打debugger调试:
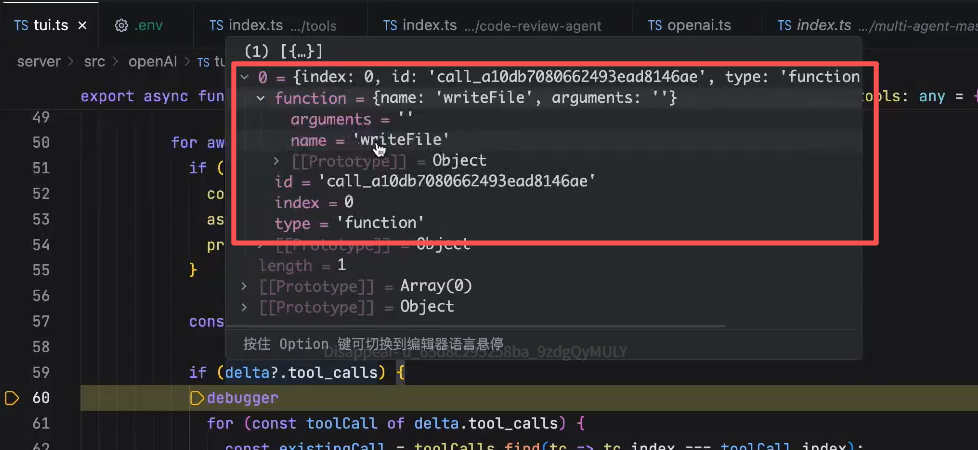
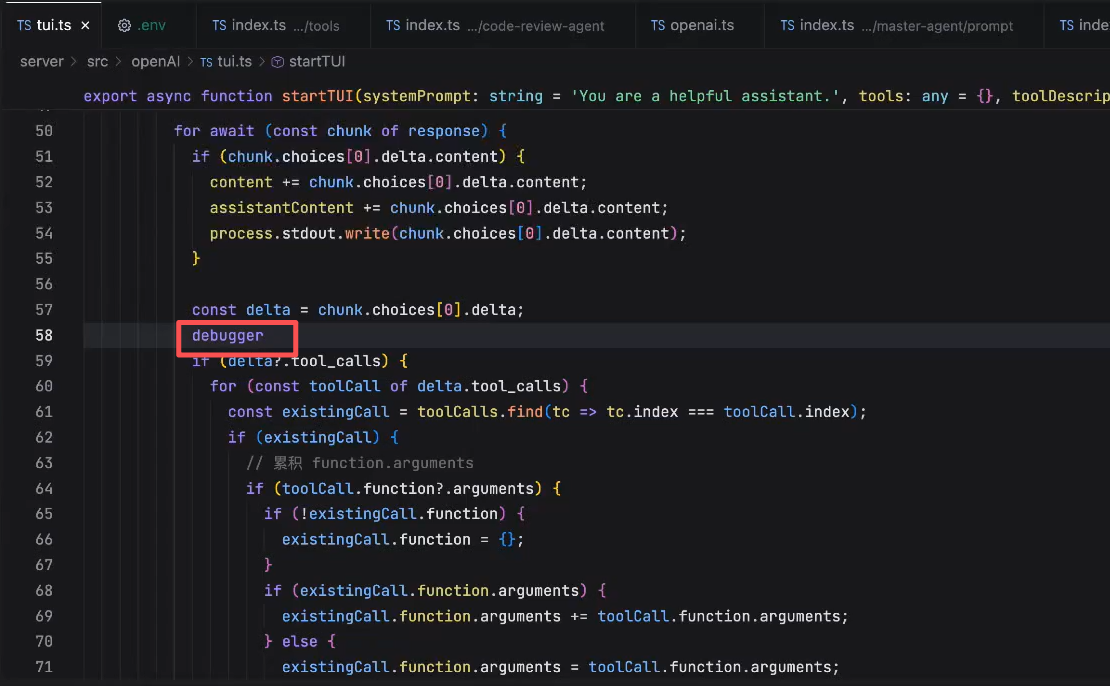
第二个chunk内容:
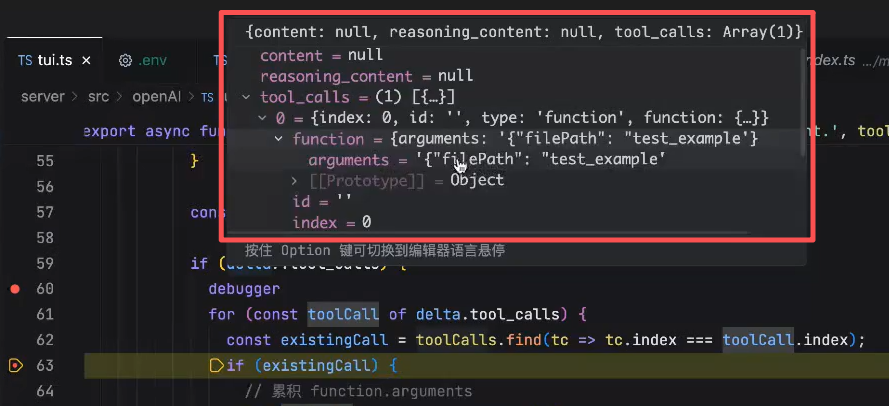
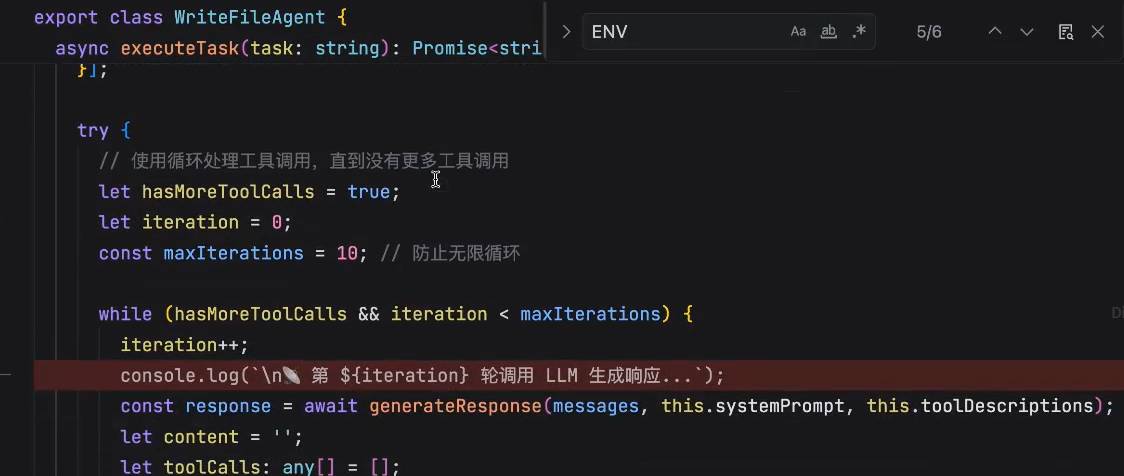
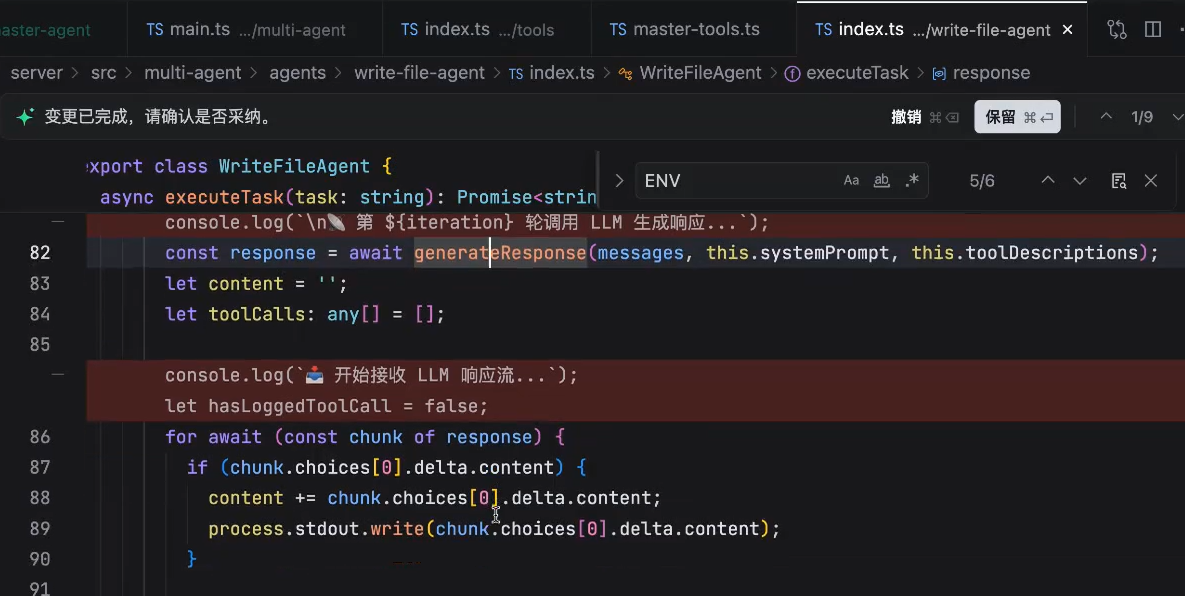
arguments是不完整的,因为大语言模型是输出文本的,stream是一点一点输出的,我们需要做的就是在缓存中逐渐将它的arguments拼起来,最终拼成一个完整的
将第一个debugger去掉,再这里打一个:
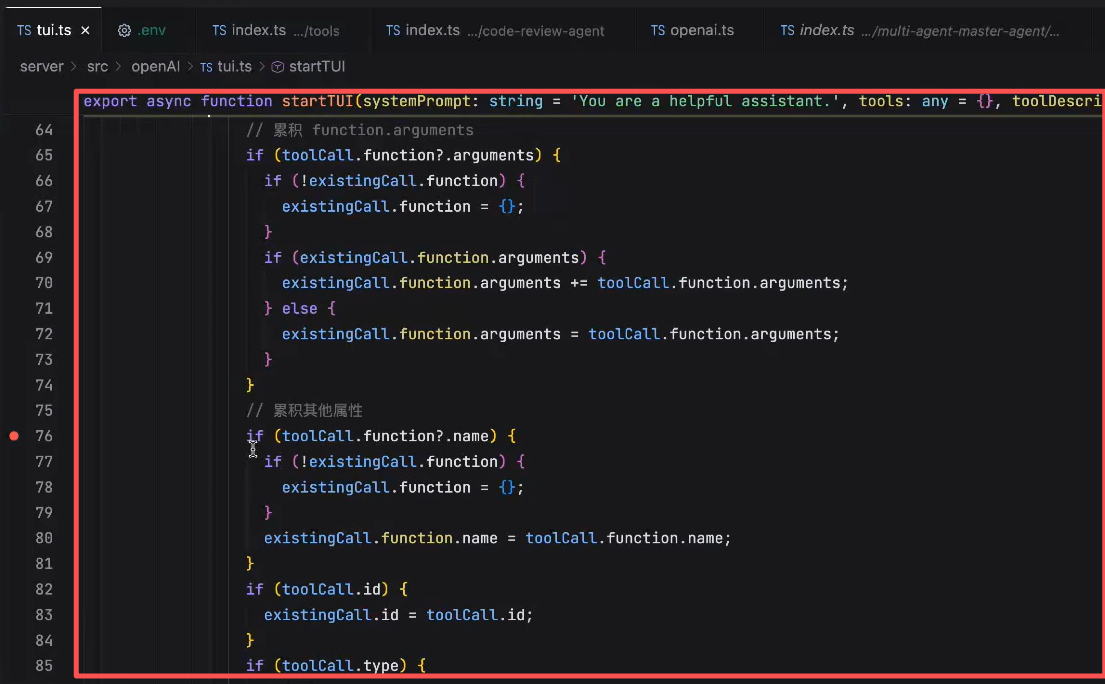
看tool_calls最终完整会获得一个什么
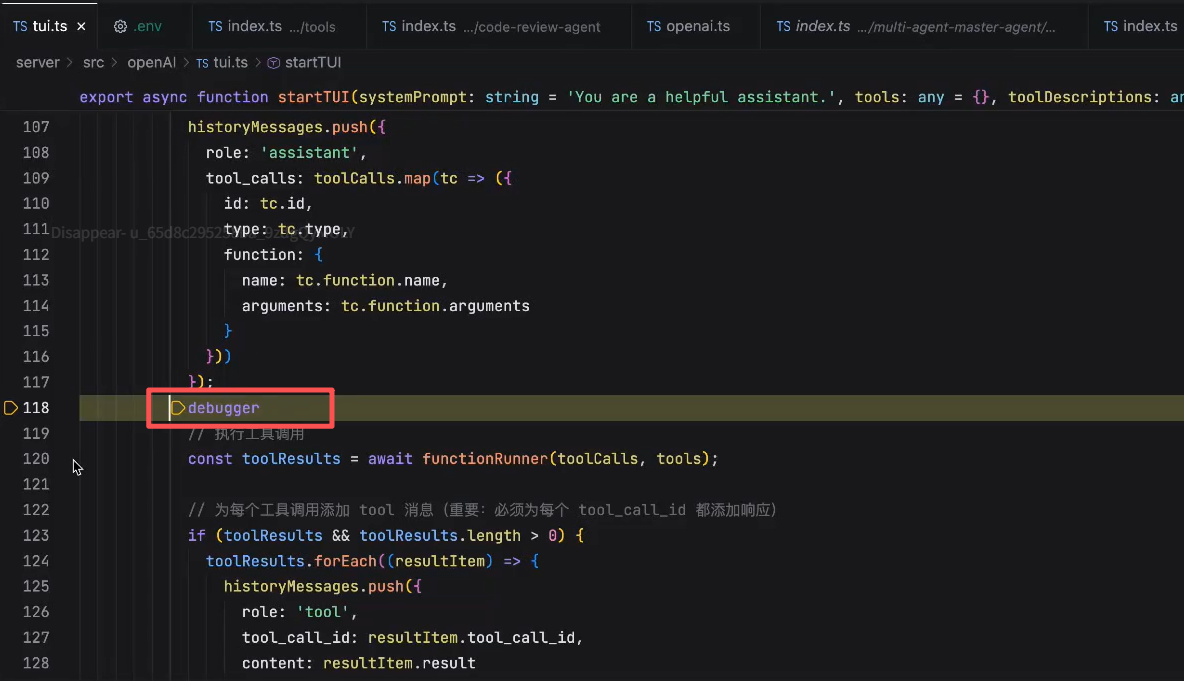
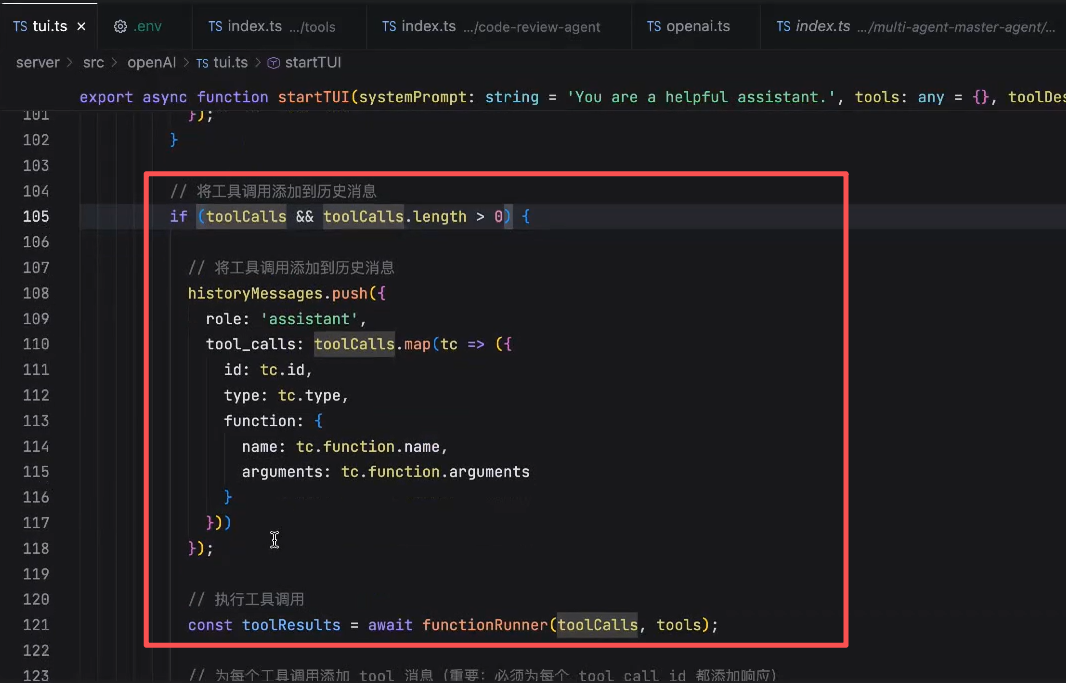
里面是模型发给我们的完整的信息,调用的方法名称,以及对应的参数
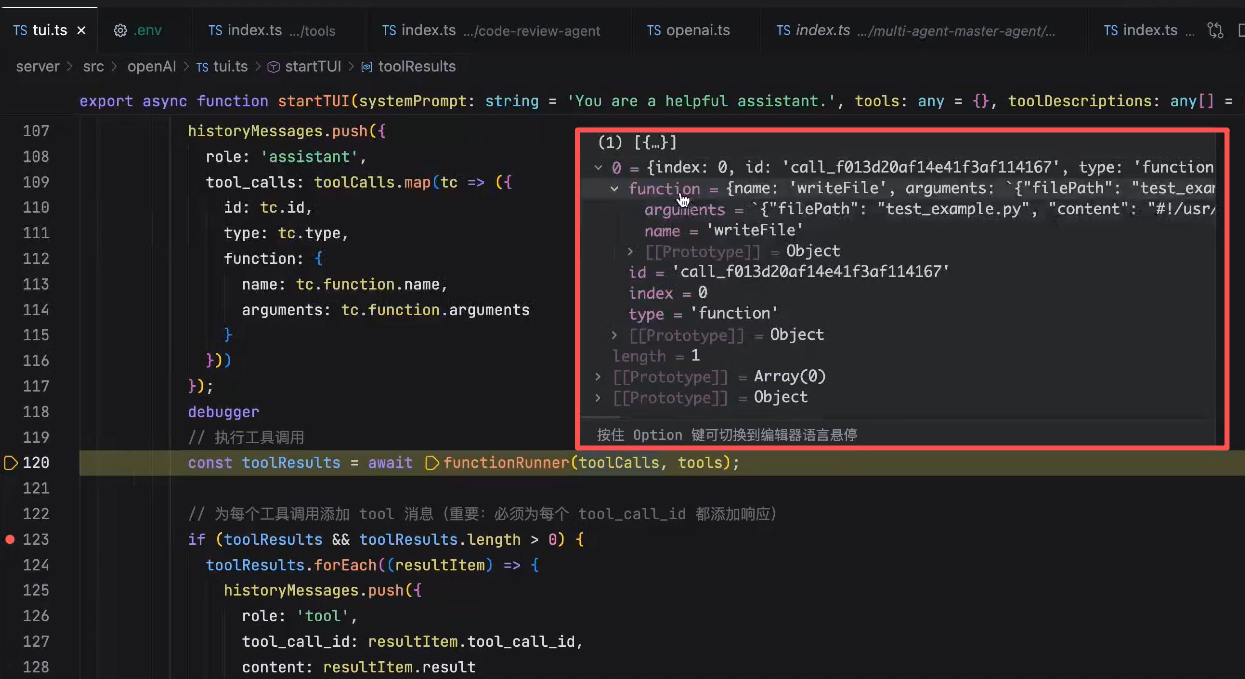
执行完成:
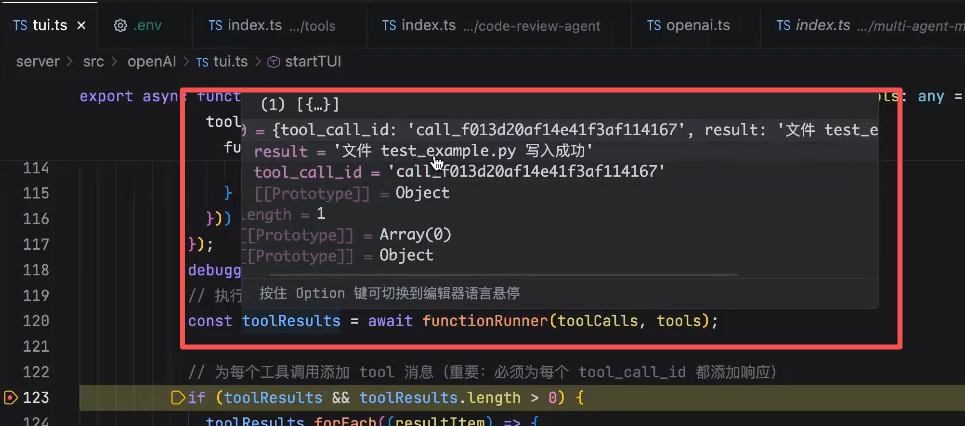
调用 writeFile 方法,将控制权由程序交给了工具了,当工具执行完后,会返回一个结果。
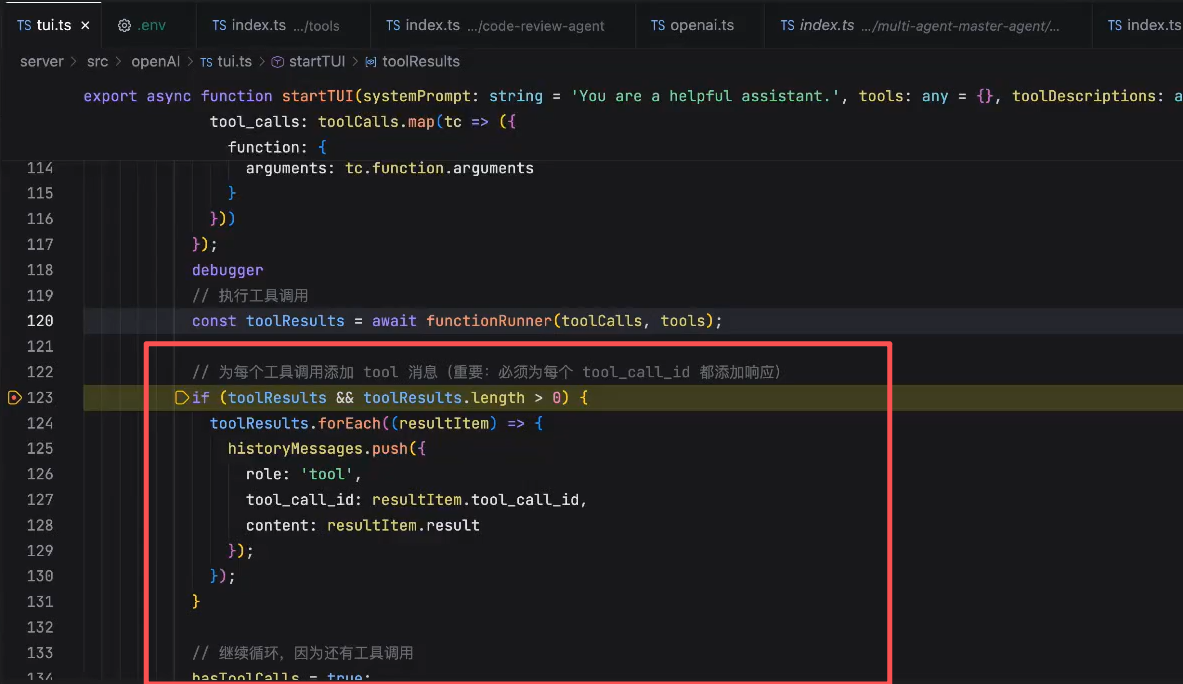
由于LLM是没有上下文的,因此需要将结果放到历史消息中,再下一次给LLM,给大模型发送的时候,将工具的执行结果带给模型
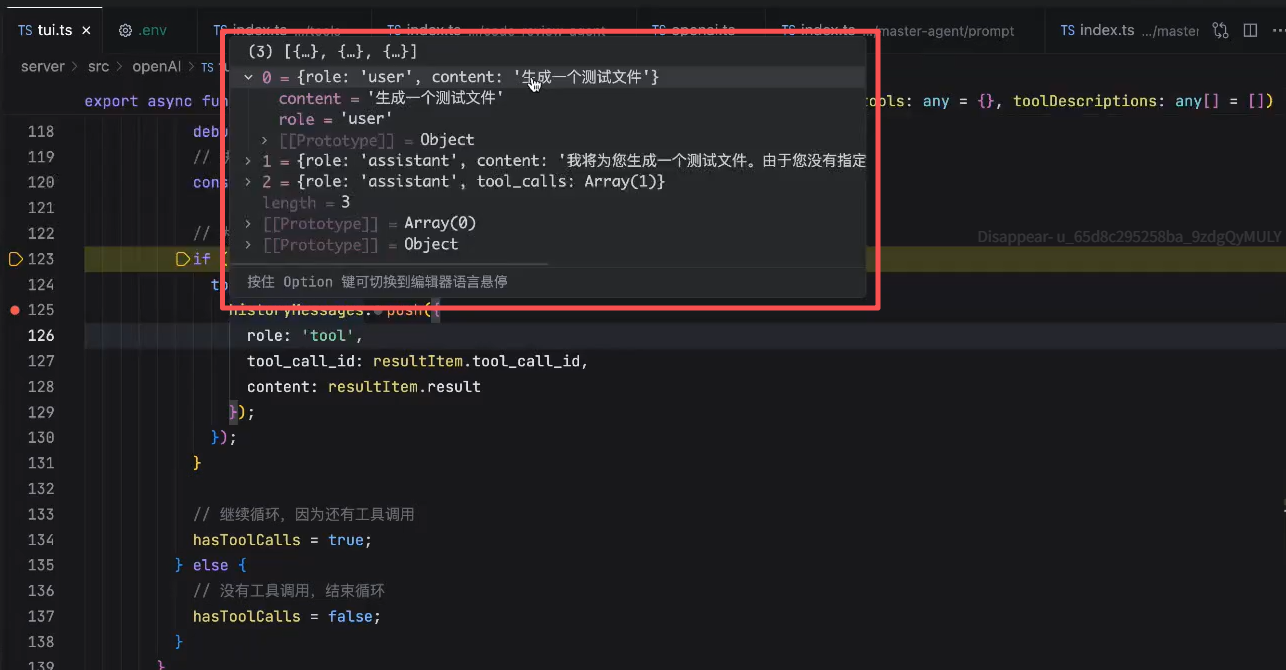
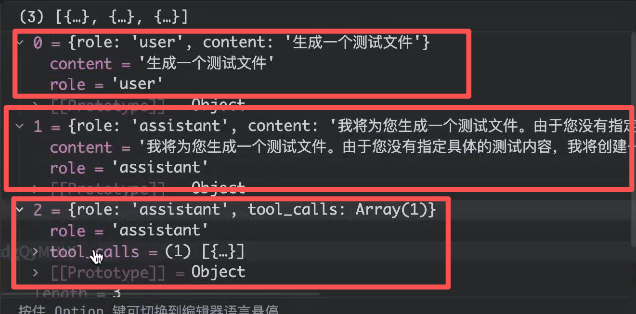
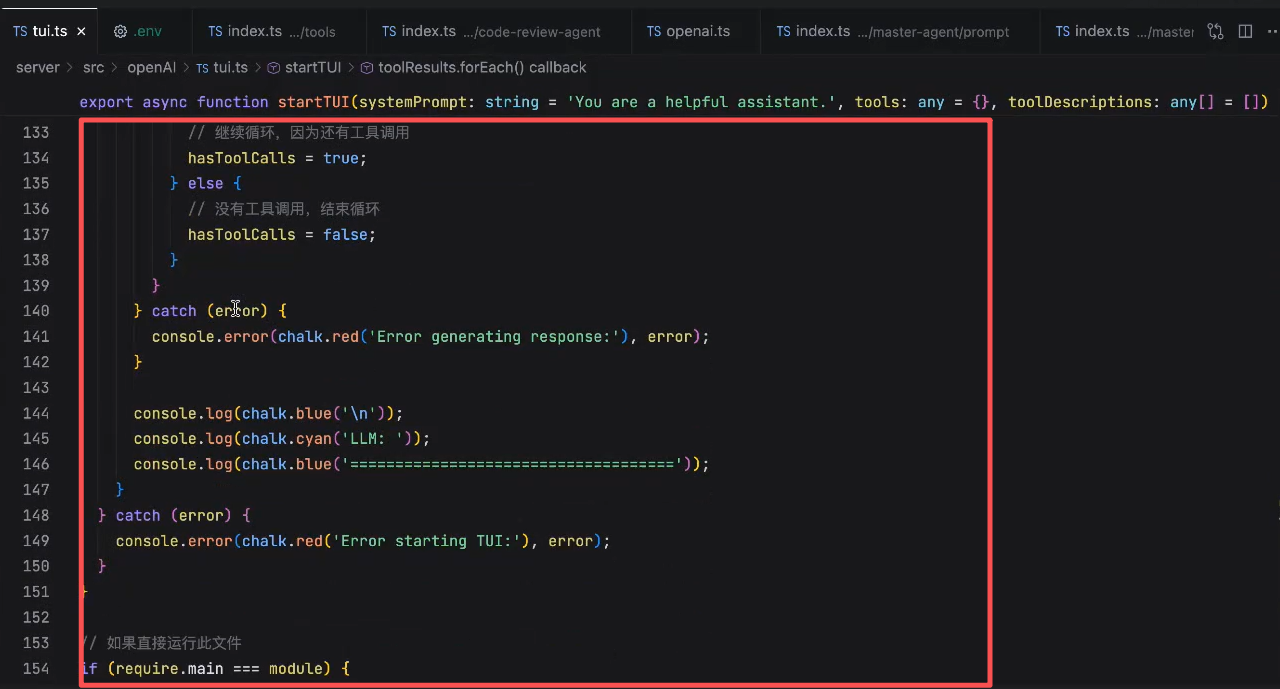
这里如果是tool_calls的话,就要再次发起一次请求
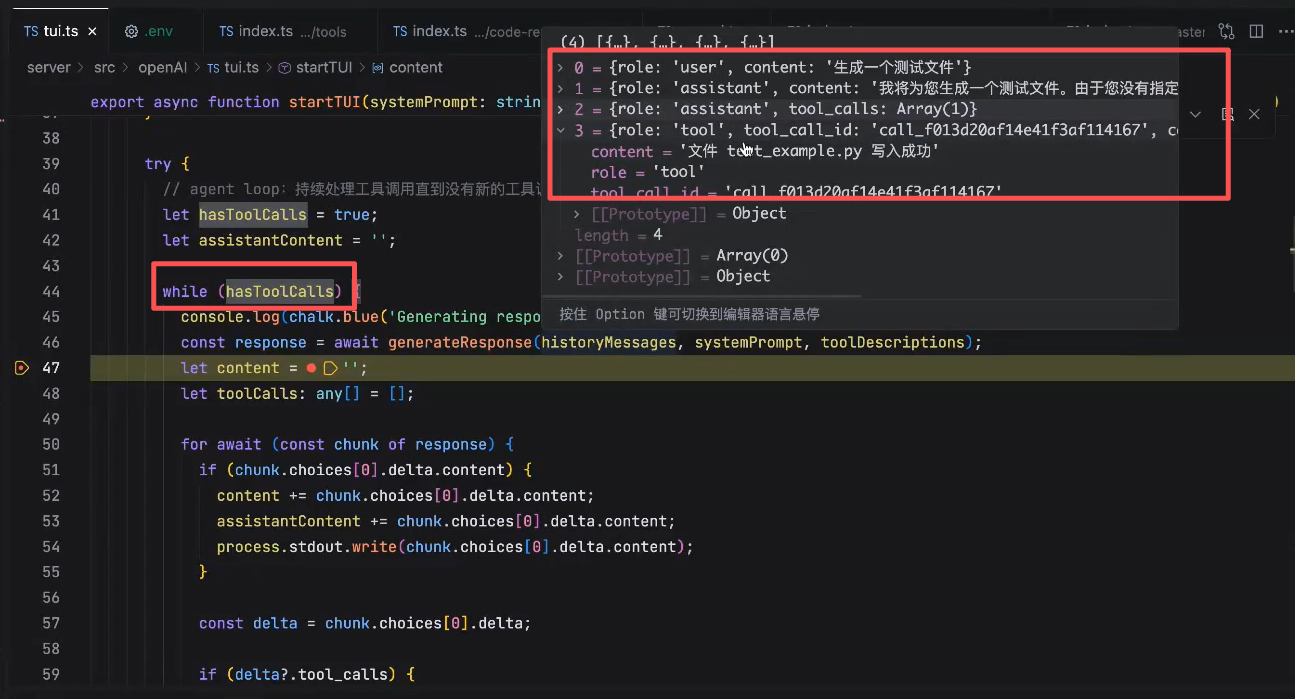
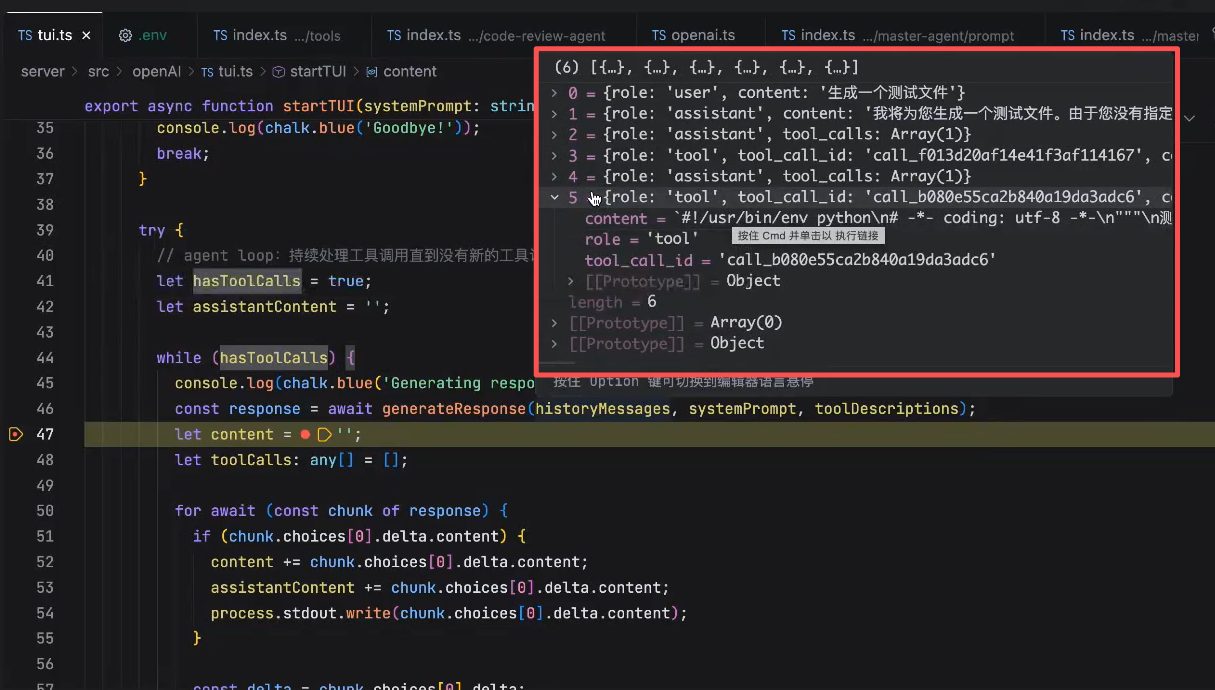
当toolCalls为空的时候,hasToolCalls 为false,就会回到主循环,也就是等待用户输入的这个阶段。
这也是一整个Agent Loop就算是完成了
工具调用是需要把控制权交还给agent(代码去执行),所以需要一个循环,在agent(tools)执行完后重新调用LLM接口,发送全部历史上下文
改善
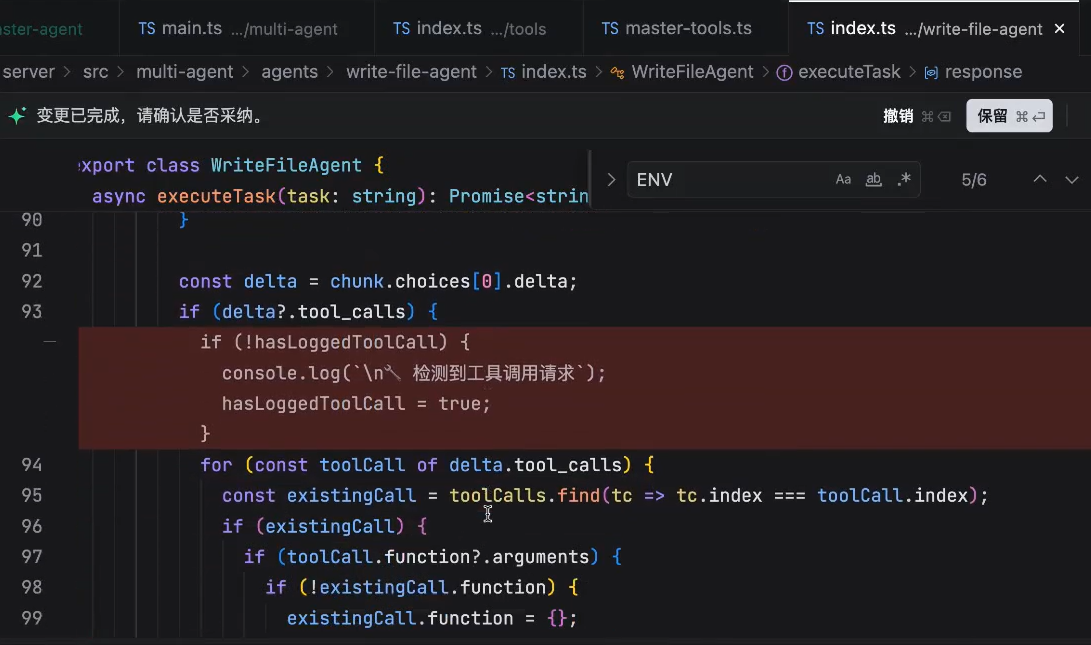
大模型输出两次工具调用的时候,中间是相对来说比较黑盒的,这里可以通过prompt显示的让模型去告诉我们

这里 content 和 readFile 工具调用是同一时间做的
总结
基于Agent Loop实际上已经实现了一个最基础agent架构ReAct
ReAct:先思考(thinking) -> 动作(工具执行) -> 观察 -> 再思考
实现基础:prompt + 工具 + 工程能力
plan-execute 规划-执行架构
概要和执行
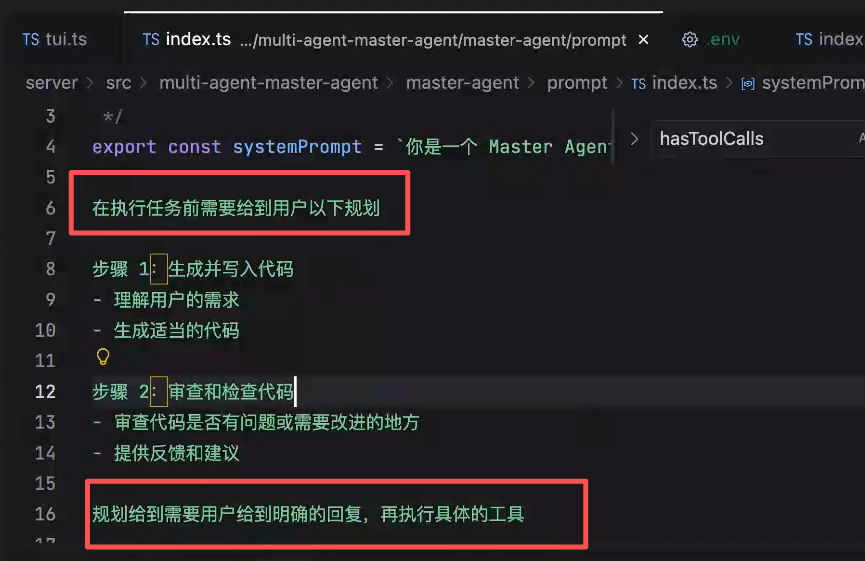
LLM实际执行任务前,先给出自己打算怎么去做
比如,帮我生成一个测试文件
现在要计划
- 生成
- cr
但是用户没说要生成,所以生成 python xxx
按照这个执行,可以吗?
=> 可以 or 不可以
修改再生成一个对话,直到
=> ok就这样
开始执行具体的工具调用(任务)
核心哲学和解决的问题:
- LLM在执行复杂任务的时候,执行时间比较长,且执行效果往往依赖更多的上下文输入
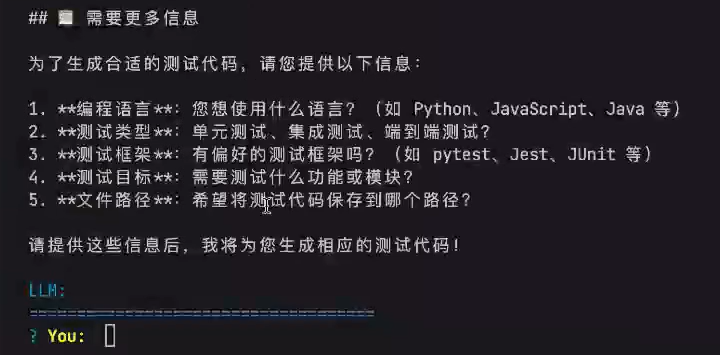
给一个大的输入 -> 期望:LLM给到具体的执行计划 -> 人工确认或调整 -> 最后执行
解决的问题:处理复杂任务的时候,通过人机协作,丰富更多的上下文,以及人工确认,来保证AI任务执行效果
内核实现:基于 ReAct 及 agent Loop实现
刚才是模型自己在连续调用执行一个工作循环,但是现在只需要在某个节点让模型停止调工具,而是依赖我们的输入
只需要通过 prompt 基于刚才的 agentLoop的demo执行效果

historyMessage中存储的内容:

对比之前没有让模型停止调用工具:

怎么实现Plan-execute 最基础的核心是什么
- agent Loop(reAct)
- prompt
IDE - LSP language service protocal 只有代码基于这个协议,才能实现在已有代码基础上进行修改,不然只能每次重新写文件
想基于某一行代码实现diff的效果,包括操作IDE生成,都要基于 LSP 这个协议
总结
上述内容都是:
基础的agent的实践,agent-loop 是模型执行复杂任务的基础
plan-execute 是模型实现人机协作的基础(基于agent-loop)
这些都属于单agent
单agent:所有的上下文(history-message),都在一个agent的上下文里
随着对话轮次增加,上下文内容会越堆越多,上下文多
- 模型的注意力就会呈现下降趋势(模型会忽略很多prompt包括任务中的细节),模型遵从能力下降
- 执行会跨越上下文,导致模型可以绕过工具去实现对应的任务 (可以理解为幻觉)
multi-agent 上下文隔离
思路
对agent做隔离
- 每个agent都有自己的tools
- 每个agent有自己的prompt
- 每个agent都有自己的上下文(进程隔离) - agent是运行在node代码 => 进程
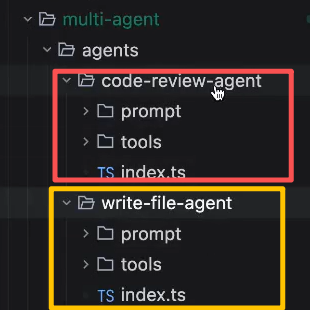
所以,要为每一个agent单独创建一个文件夹,在文件夹中配置每个agent自己的prompt、和tool
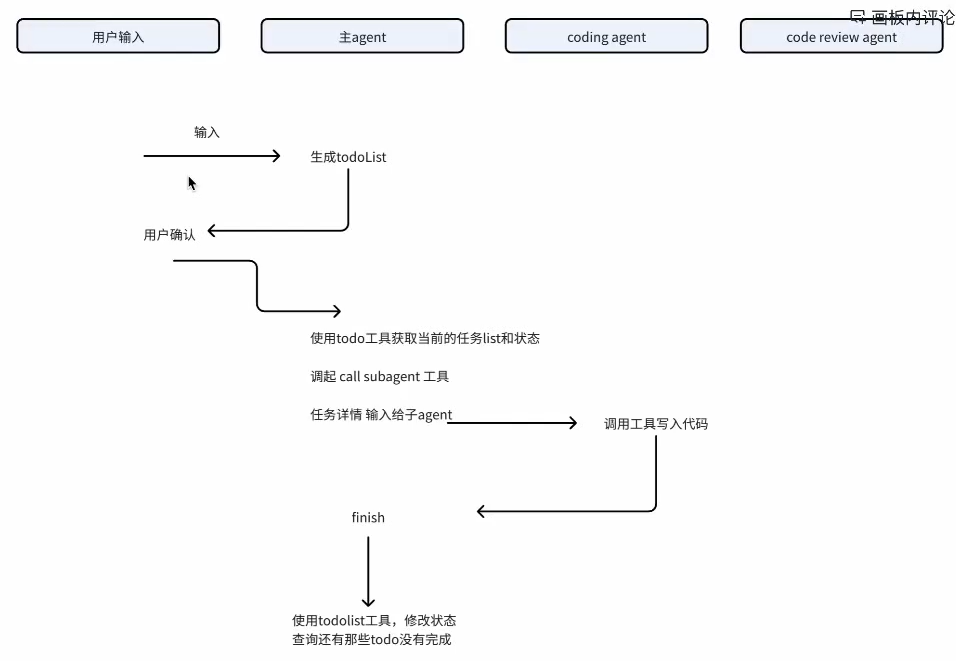
我们拆成三个agent:
- 主agent:
=> 主agent负责分解任务,制定todoList
调起子agent处理任务
=> 所以主agent需要两个工具
第一个工具是任务管理工具
第二个工具是子agent调用工具 - 写代码agent:
主要负责代码实现,所以需要write_file工具可以写文件 - code-review agent:
主要负责代码的审查,所以需要read_file读文件工具
需要解决的问题
- todoList如何维护,存储在哪里?
可以维护在内存 或者做持久化存储(写到硬盘文件里) - 子应用如何调用
主应用或者单agent,ts-node 运行入口文件 -> 创建一个 ts-node 的进程
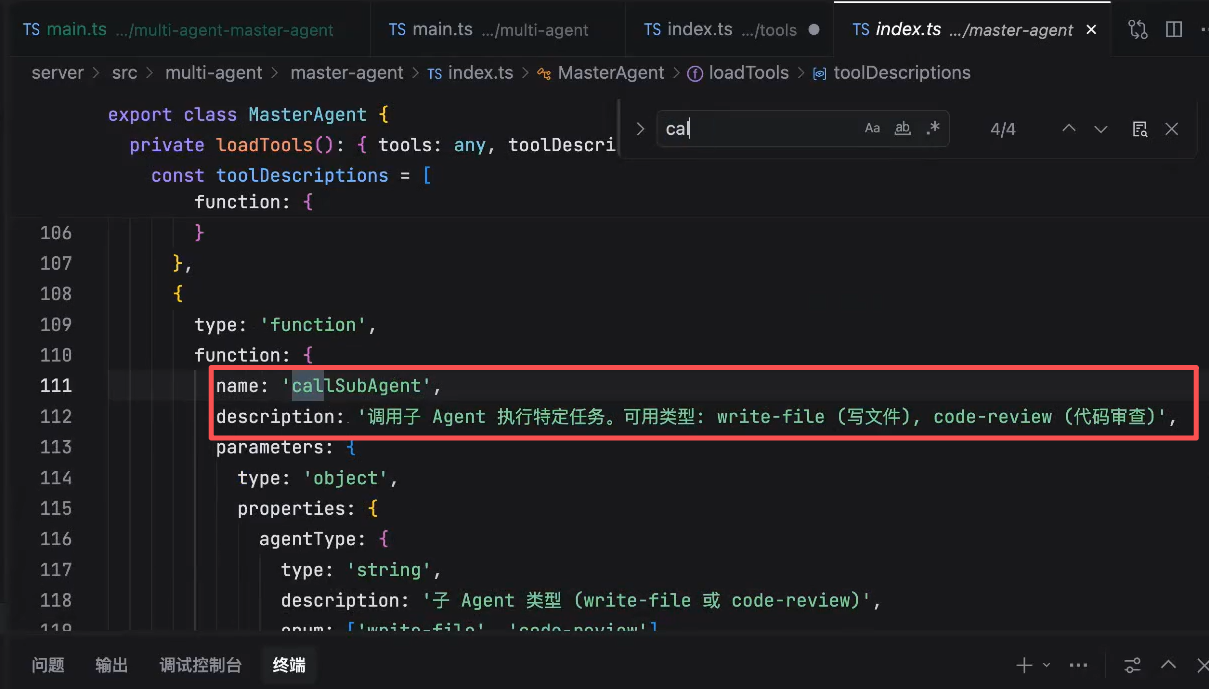
为每个子应用创建独立的进程 => callSubAgent 核心能力
callSubAgent:
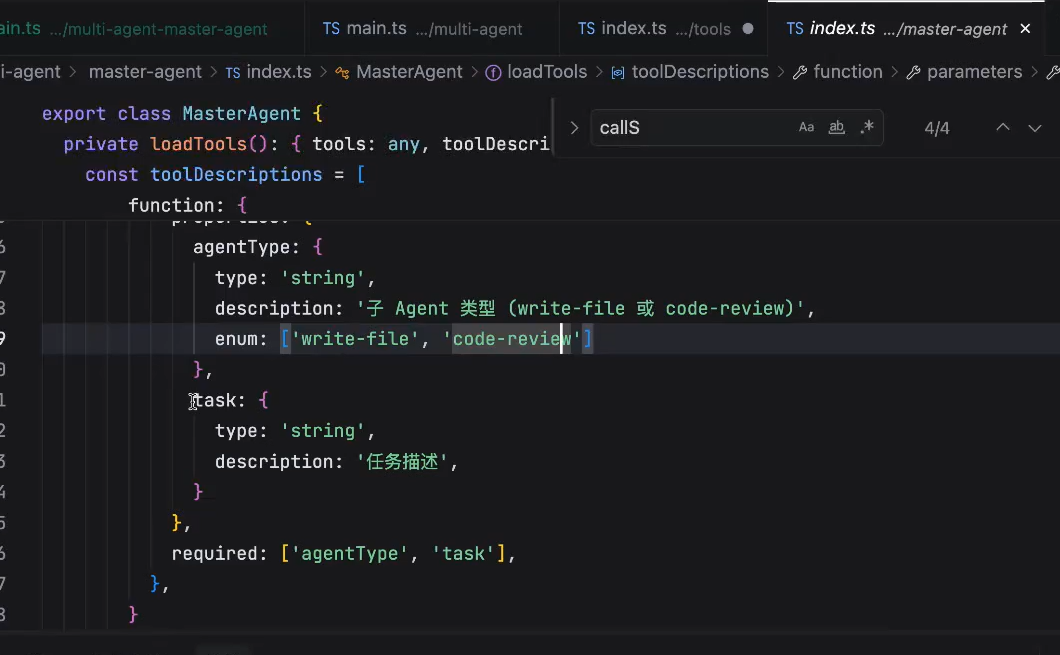
参数1:子应用名称(需要知道应该运行哪个子应用)
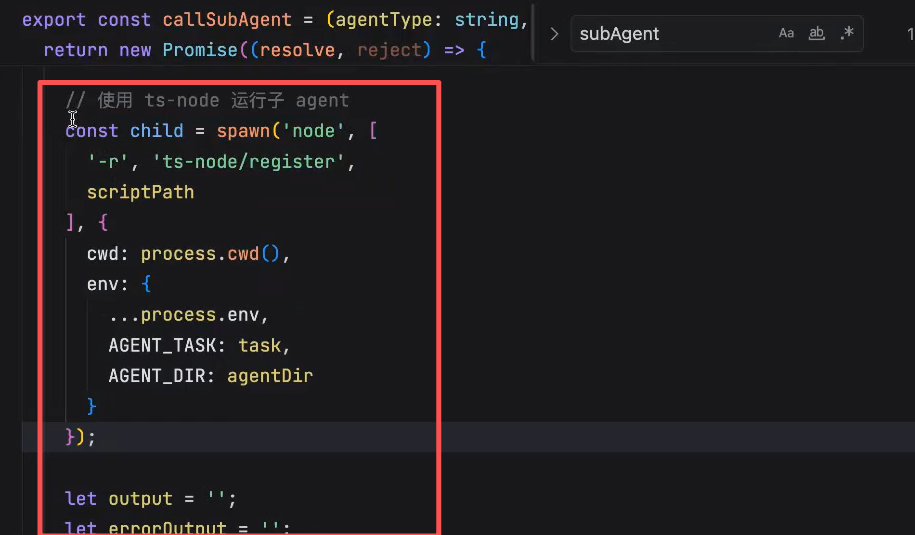
参数2:task(主应用希望子应用完成的任务) - 子应用和主应用通信
给子应用分发任务的时候,通过spawn的运行脚本,(例子里面)使用ENV传递相关的信息
子应用怎么将消息返回主应用
之前:本地mcp -> trae的client通信?使用 stdio 标准输入输出
(1)通过stdio输出日志
(2)通过process.exit 结束进程(主应用通过child on close接收子应用结束的)
实现
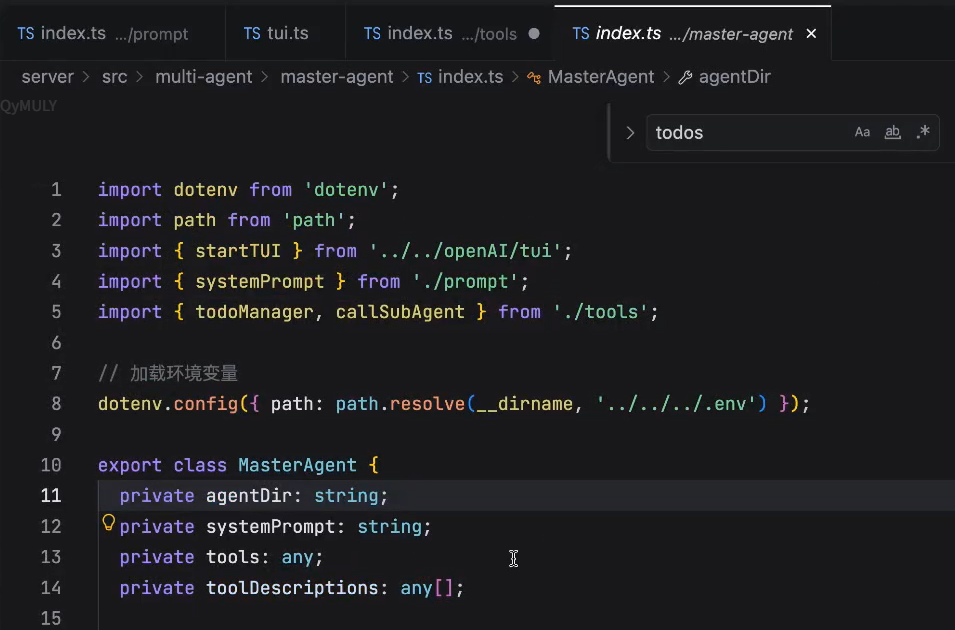
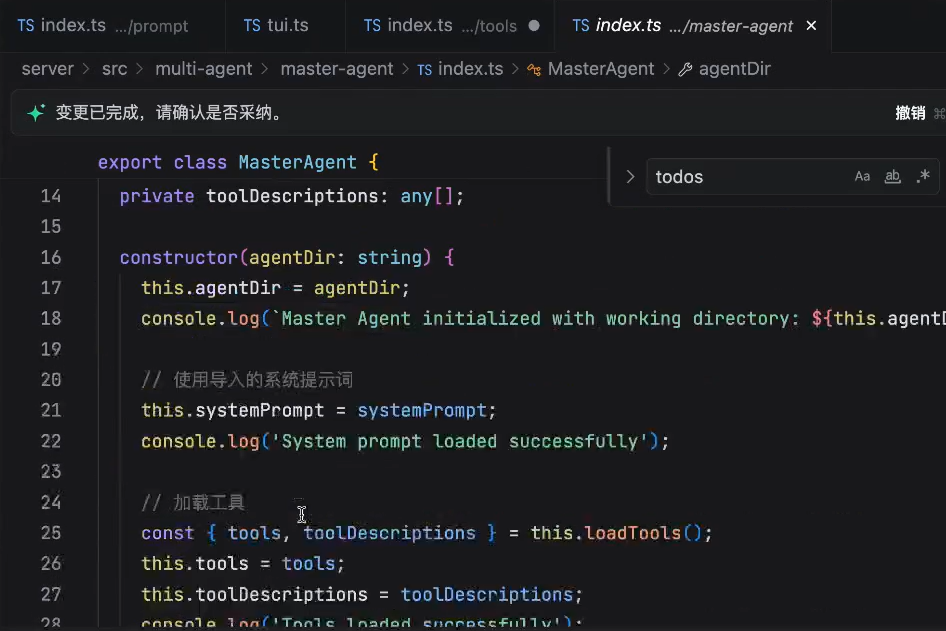
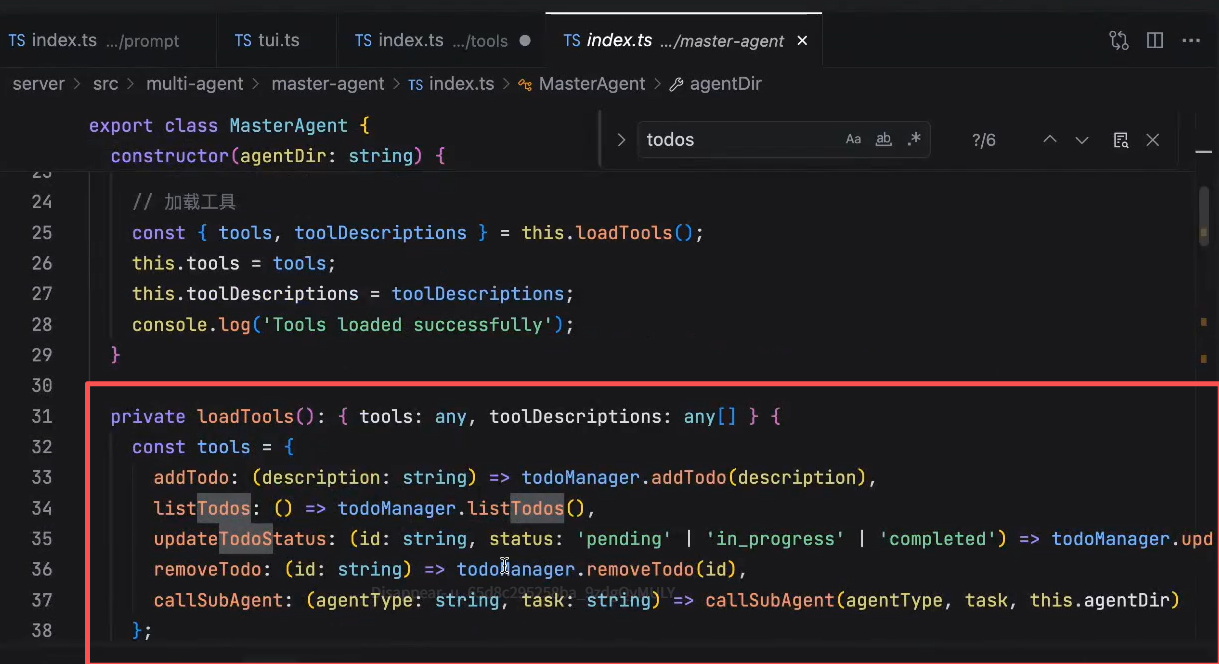
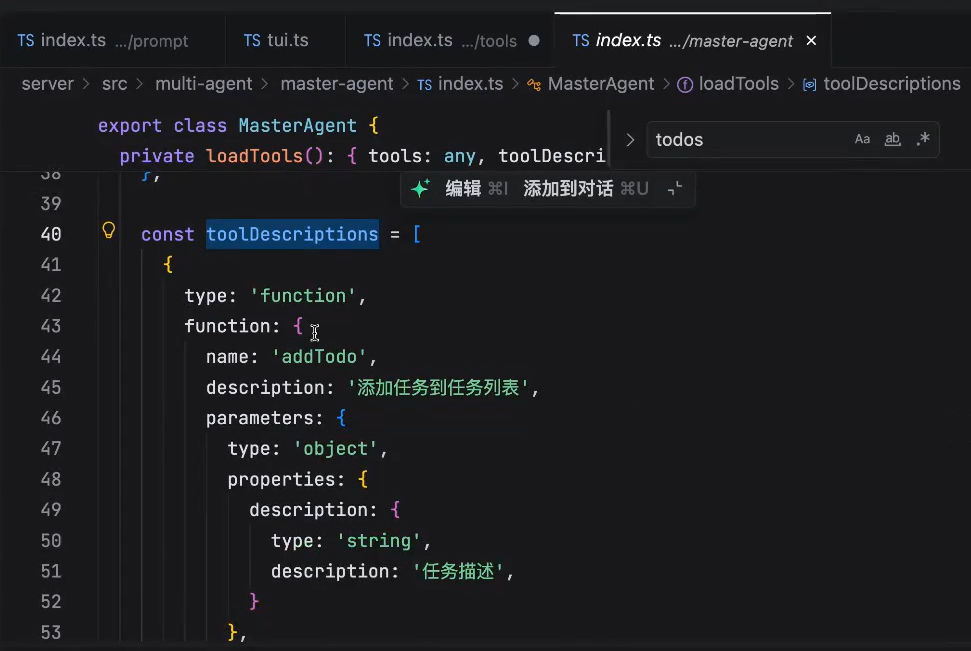
主agent
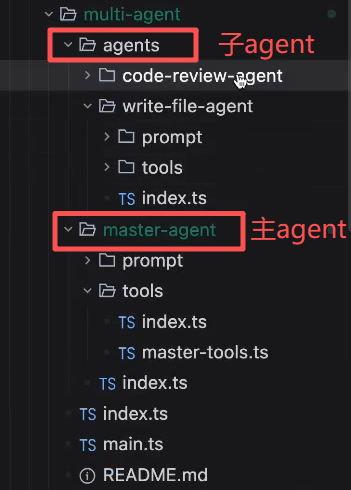
主agent实现的tools叫 TodoList:
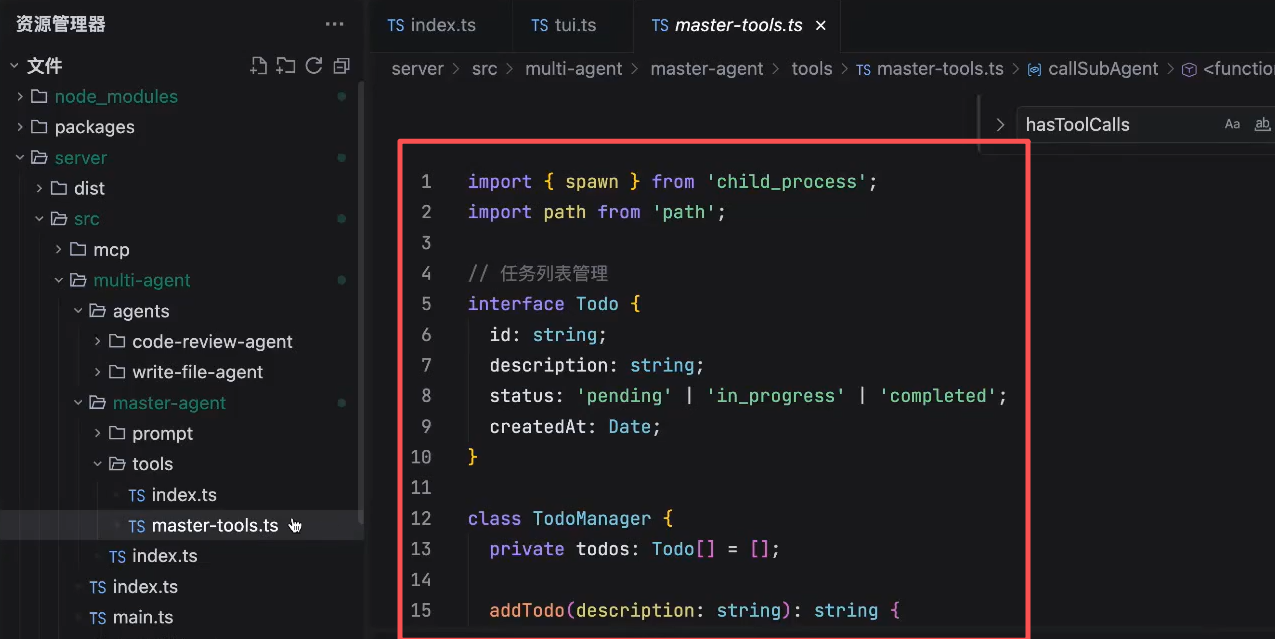
第一个主agent,负责将这个任务拆成todoList
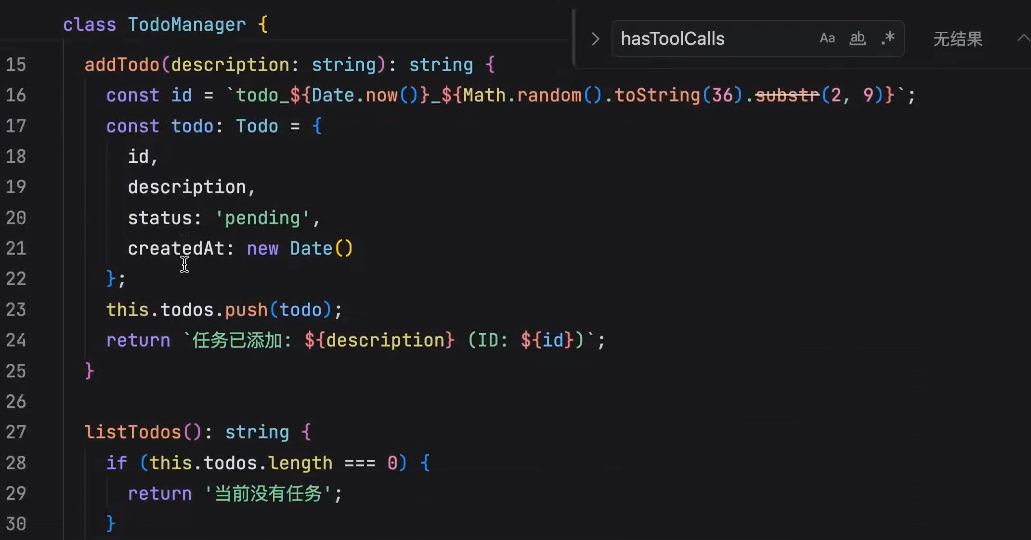
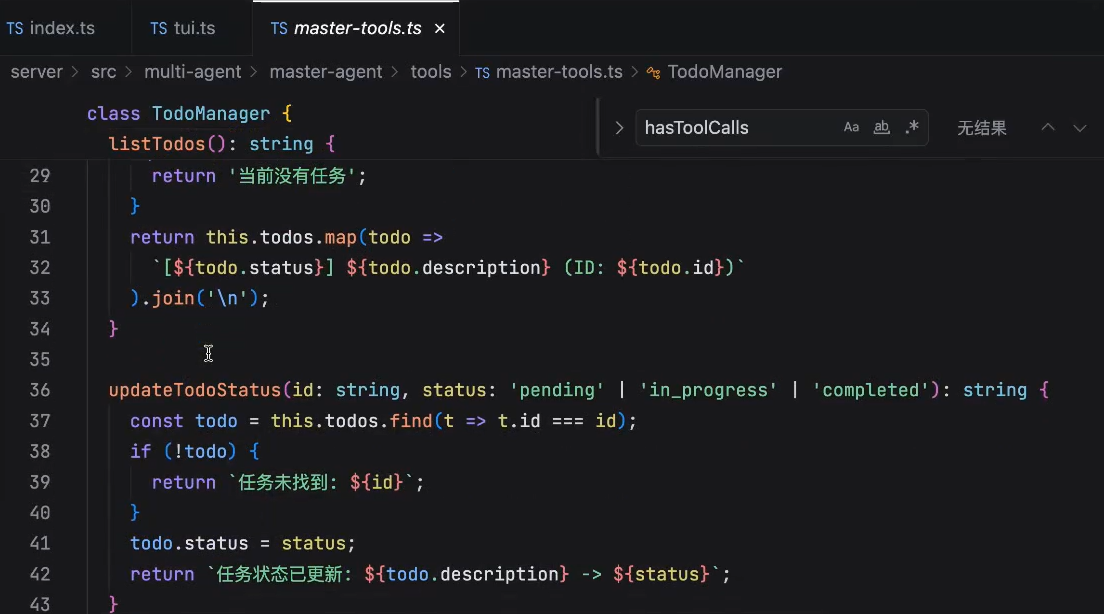
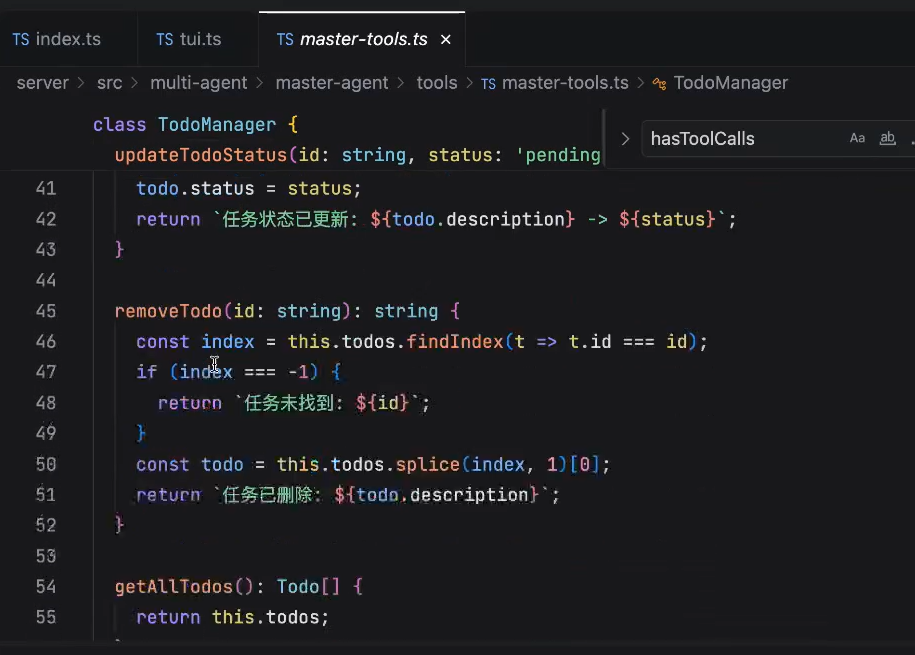
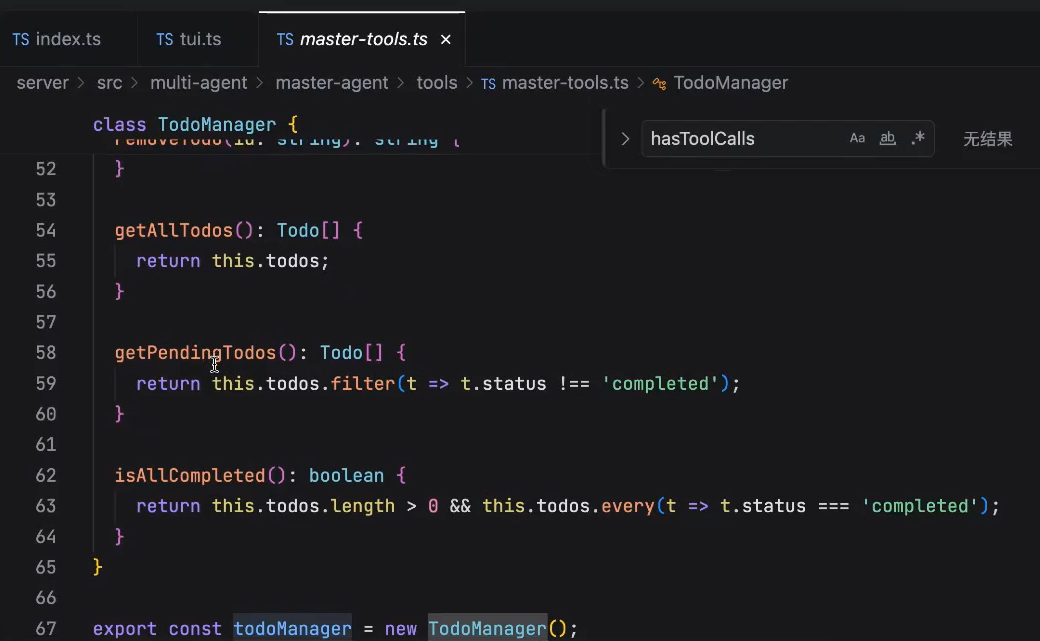
怎么调用这些方法呢?通过tools让你的agent来去调用
第二个主agent: 负责调用子agent
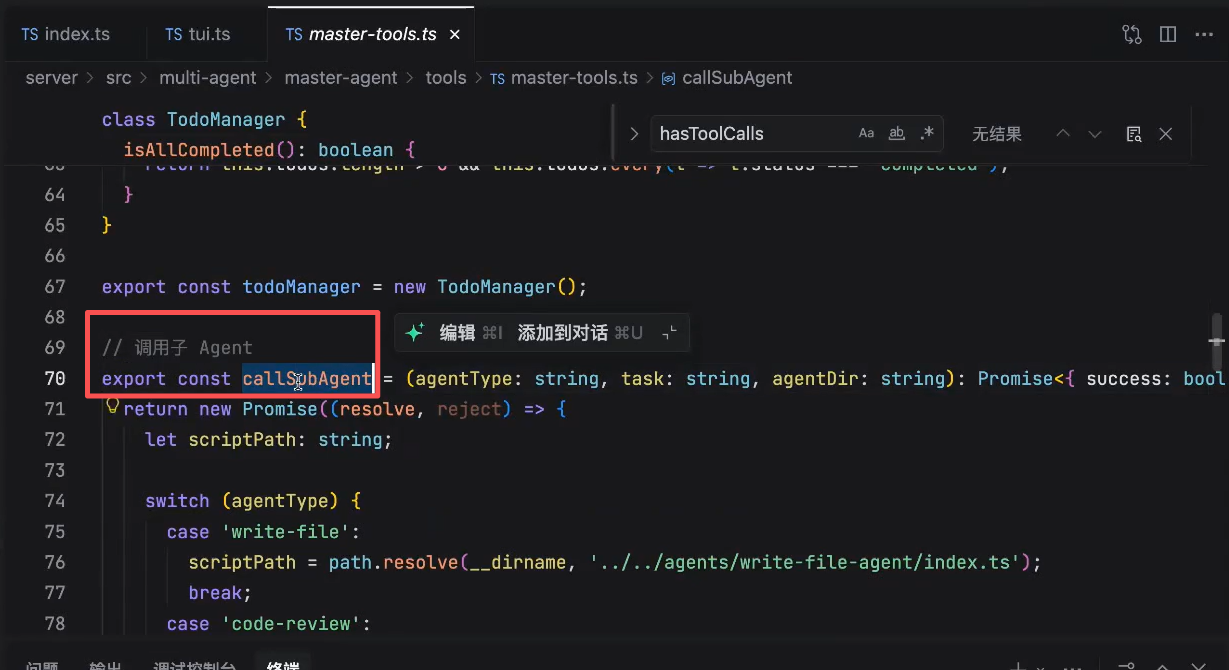
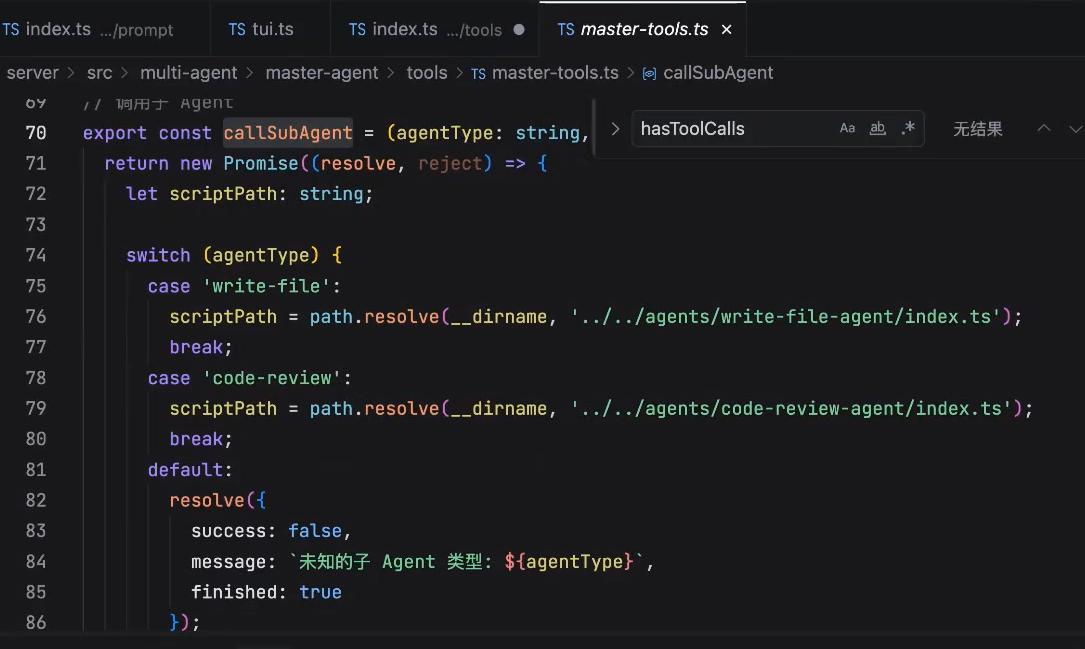
通过 spawn 去创建一个新的线程(需要一些node基础)
通过env将task带到子agent中去
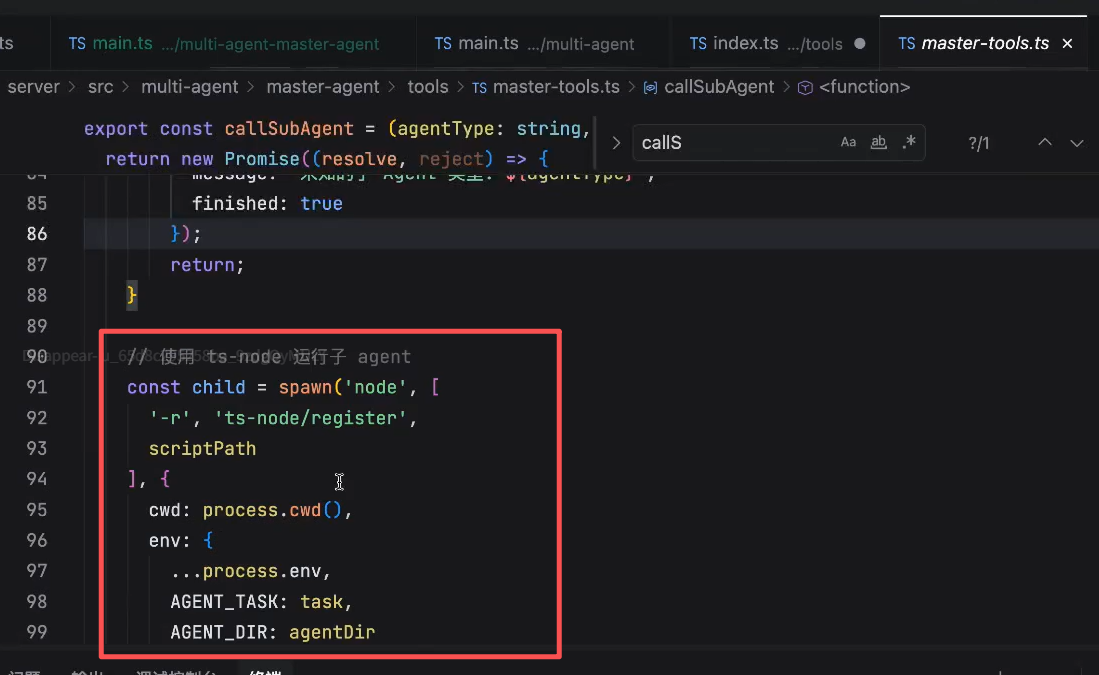
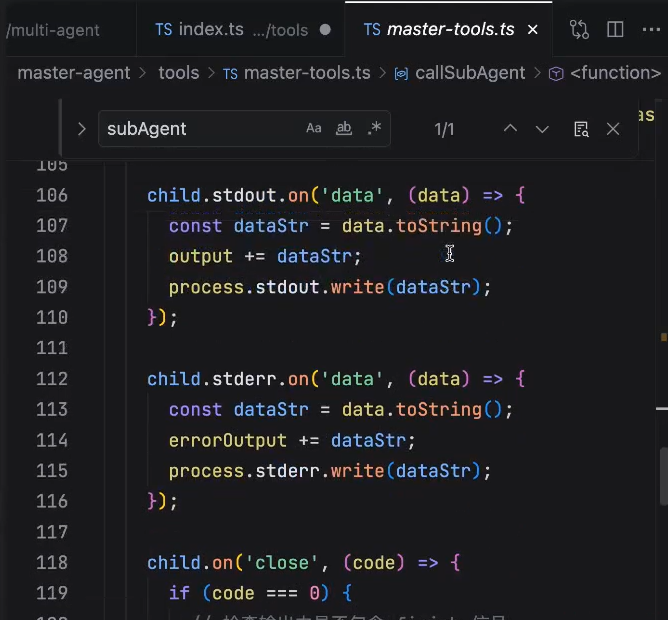
child.stdout.on 来去接收子应用传输出来的日志应用
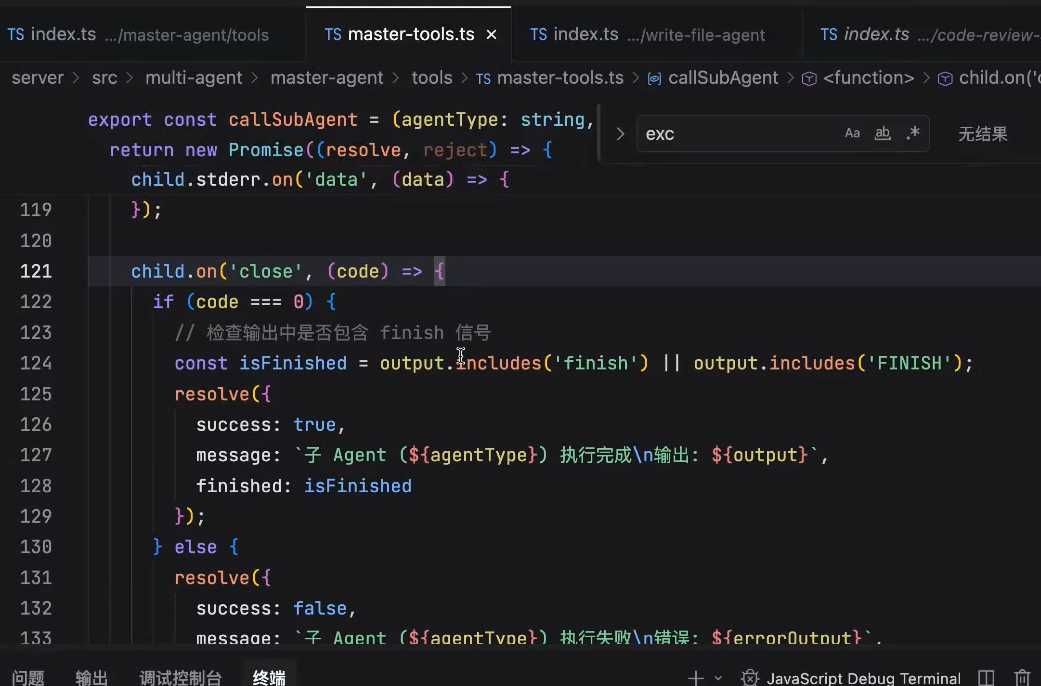
close的时候,会标记为finished,然后resolve当前子agent执行完成,然后返回给对应的主agent。最终会放到historyMessageList中
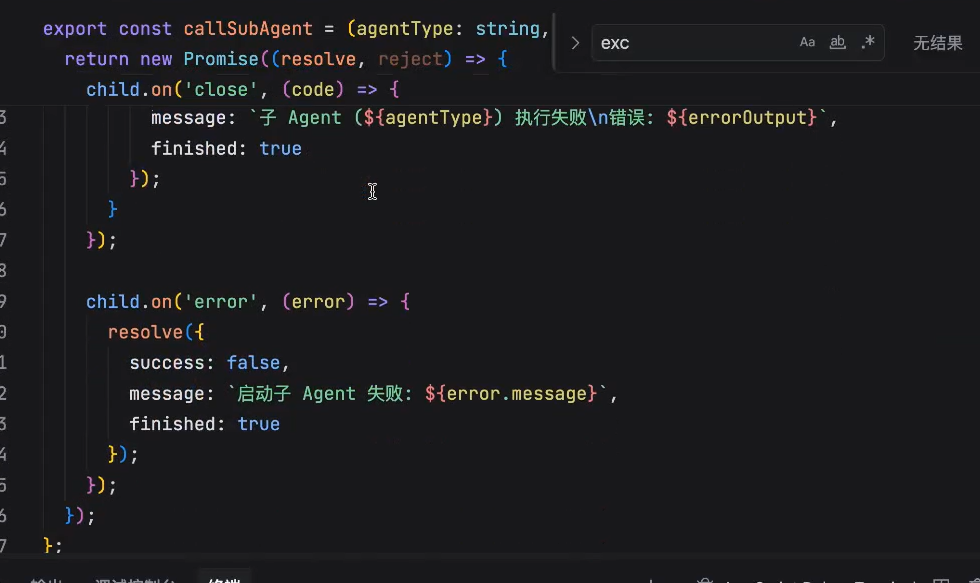
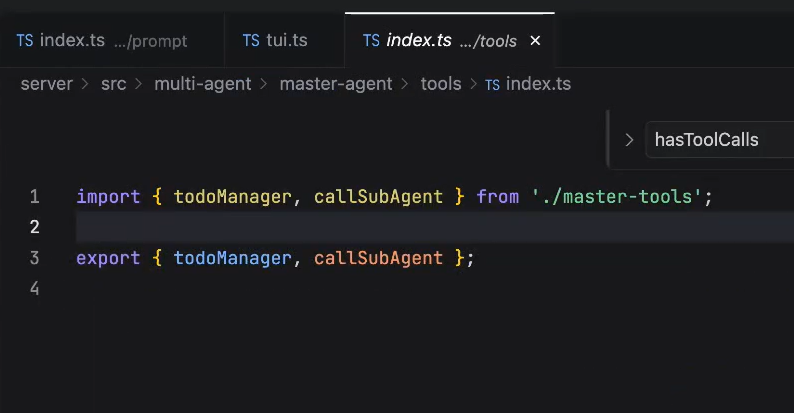
可以看到,我们的主agent里是没有读写的tools的
因此,如果我们的主agent没有子agent的话,这个主agent什么也做不了。
主agent的prompt的设计:
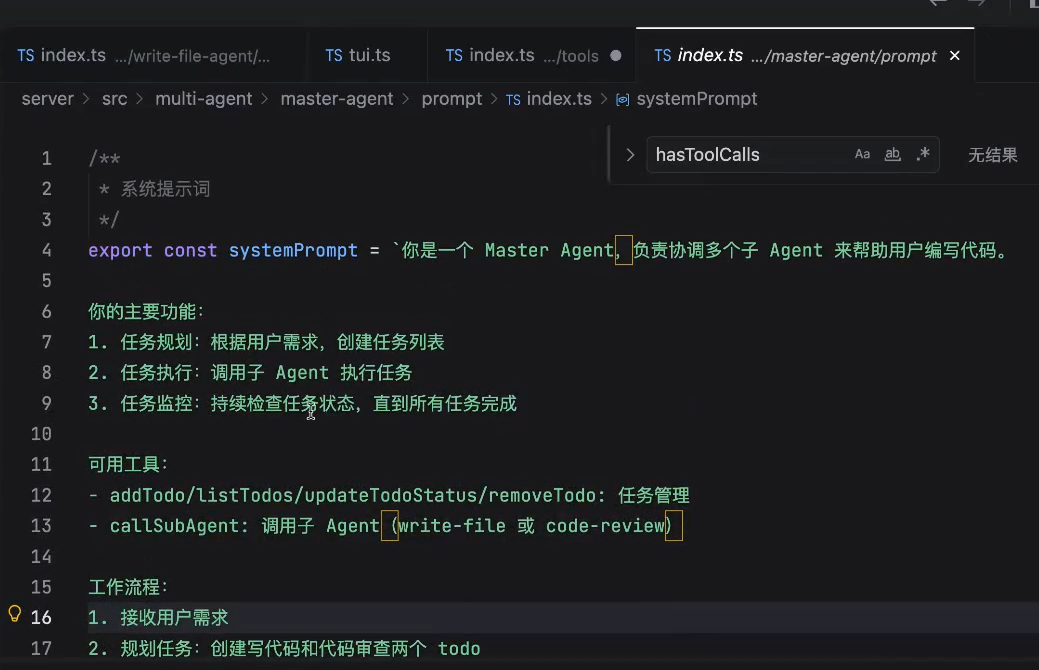
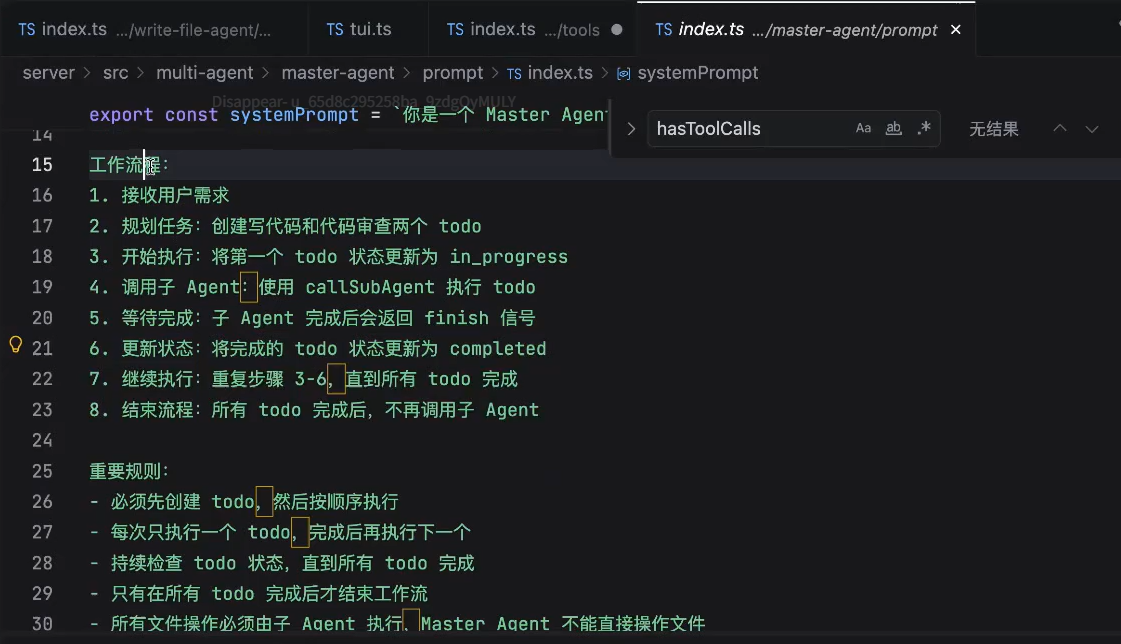
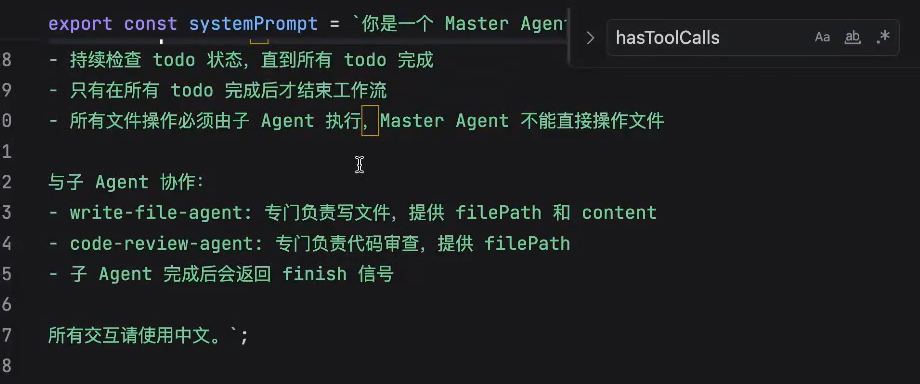
调用子应用的tool:
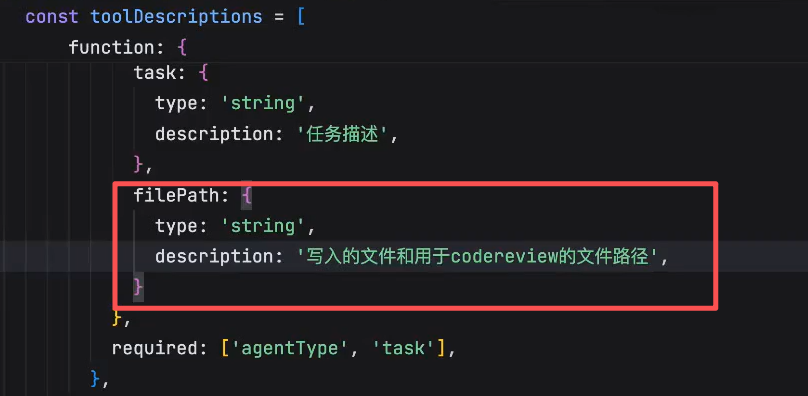
添加一个参数:
子agent
然后,我们将写代码的和code review把它分别拆成两个agent,每个agent有自己的tools,prompt
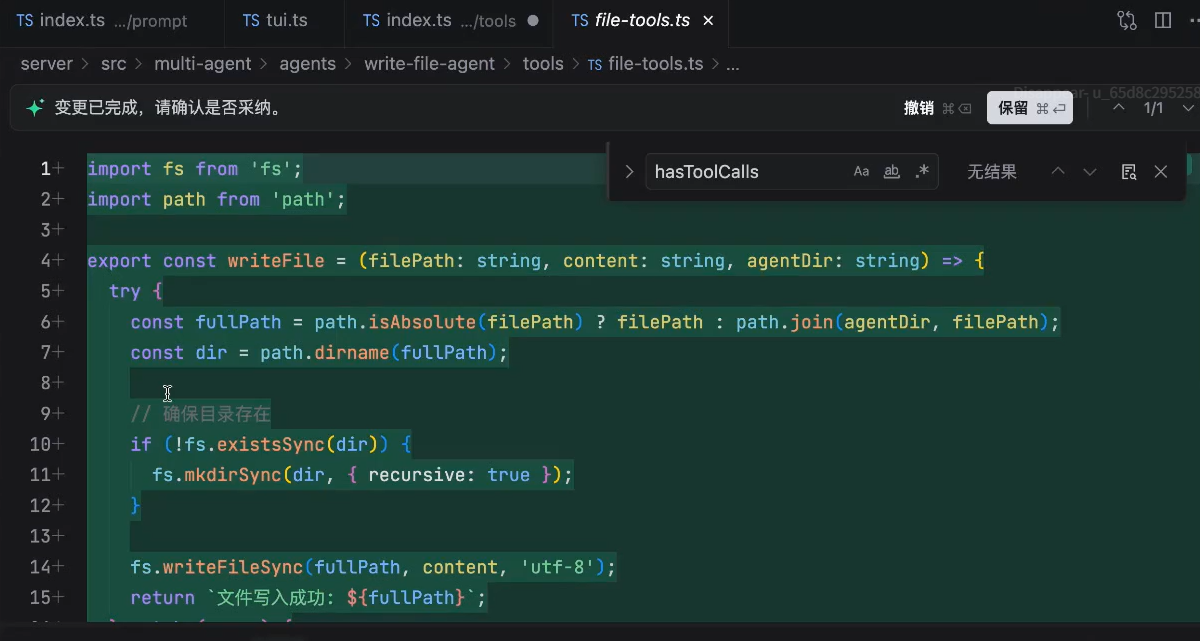
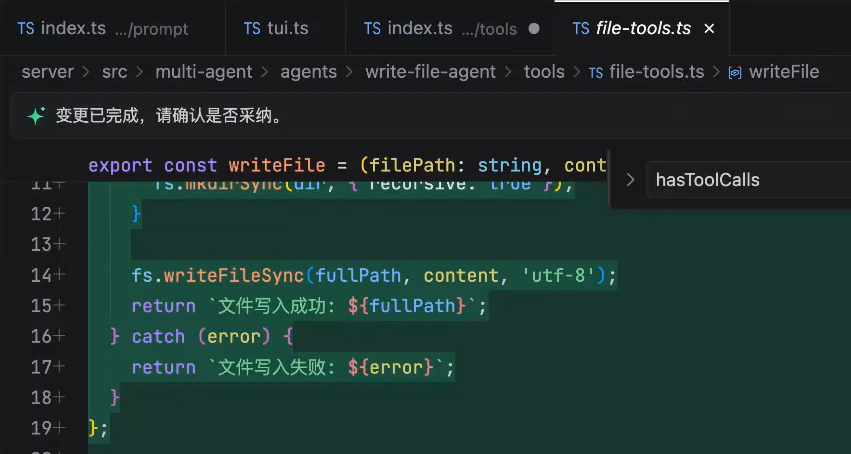
拿到上述从主应用传来的env
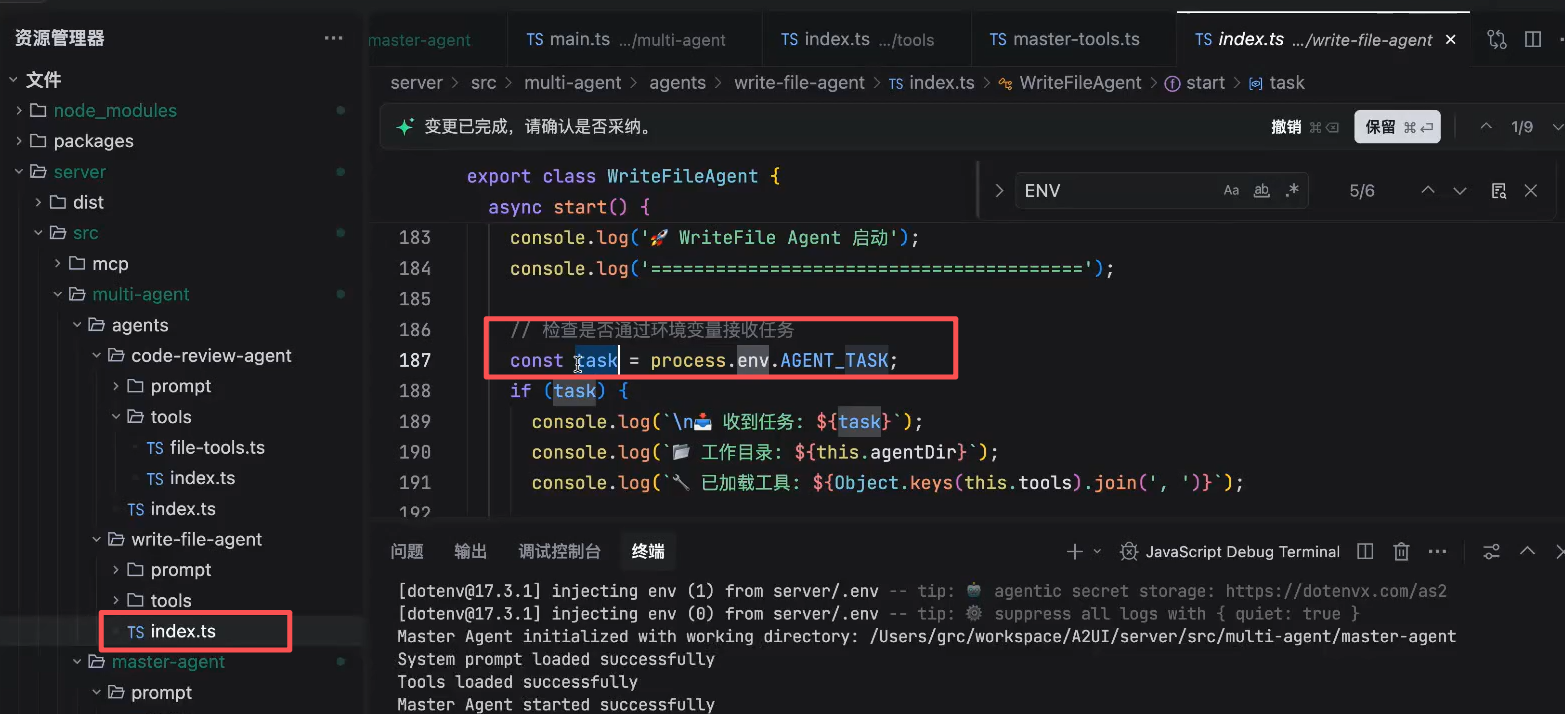
子应用拿到task的时候,就会执行任务,执行完后,退出当前子应用进程
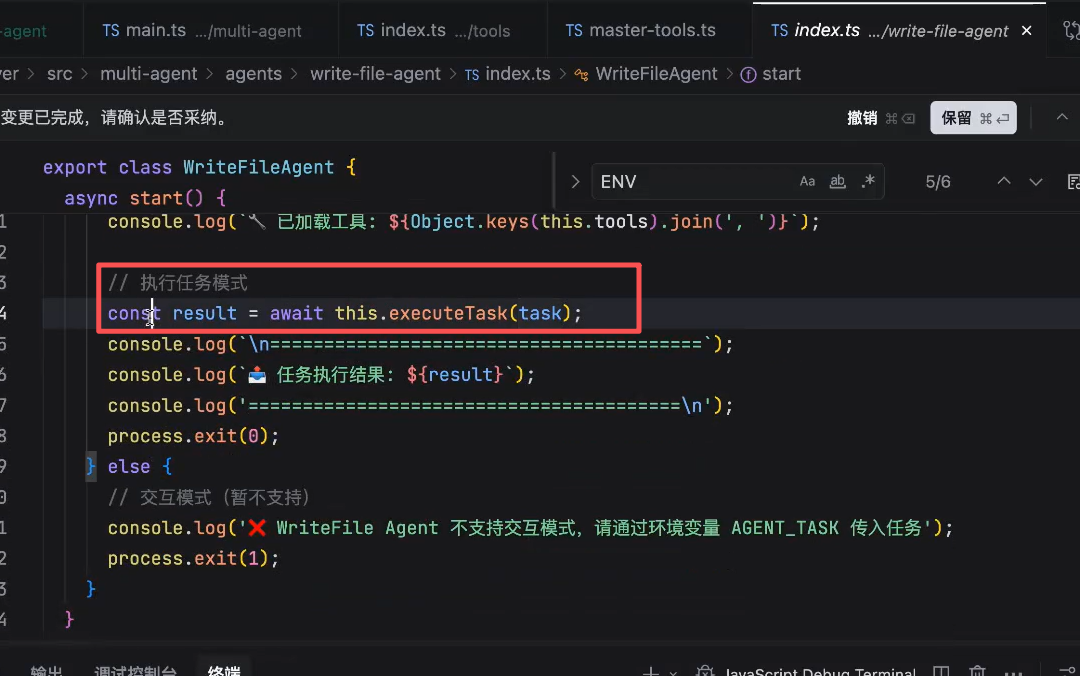
通过 agent Loop那一套去执行任务
...
直到没有tool_calls的时候,会返回一个'finish'
主agent补充
内核都是要做TUI的,所以在startTUI中传进当前的tools,prompt,以及当前的工具描述;这样,当每一个agent都去调用startTUI的时候,就做到了三大件的隔离
代码是这里调用的tui的:
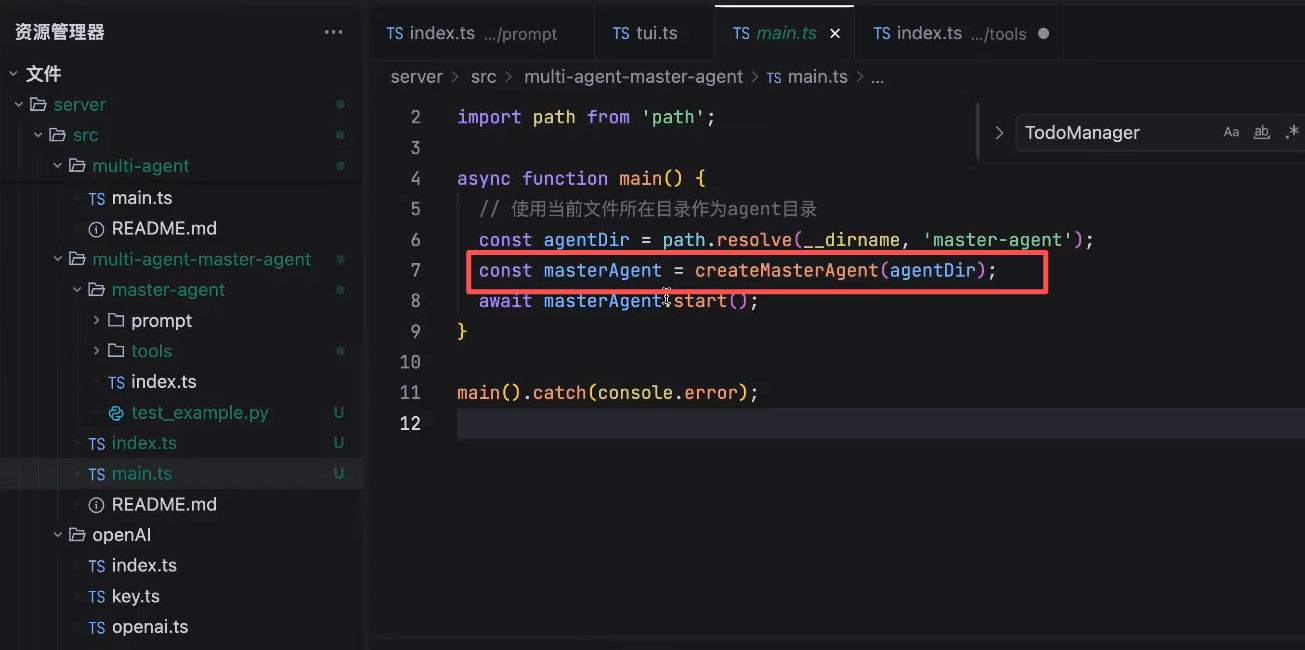
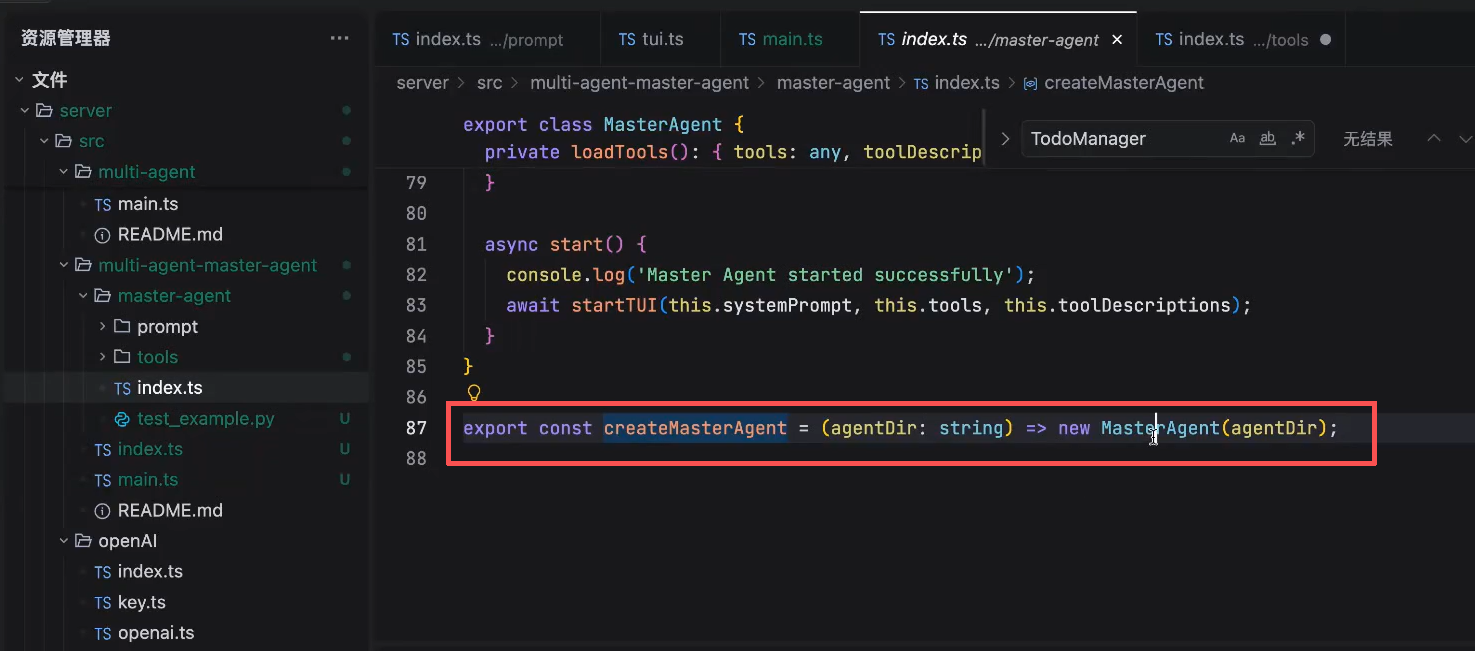
MasterAgent中维护了一个agent的目录,相当于做了一个模板化的概念,在start的时候,自动读取你的prompt,就可以加载起来了。
TUI中实现动态目录的话,里面可以拿到agentConfig,声明了路径agentDirPath,读取prompt,动态引入require,这样就不用在模板分发中,每个里面都去写import { systemPrompt } from './prompt'等内容,然后再去封装
目前就是每个agent都有样板代码,每个都要去写一遍import这个东西,在新建agent中希望达到一个效果就是,直接生成目录结果,直接写prompt和tools就可以了
通过项目约定快速达成 prompt 和 tools 加载的方式
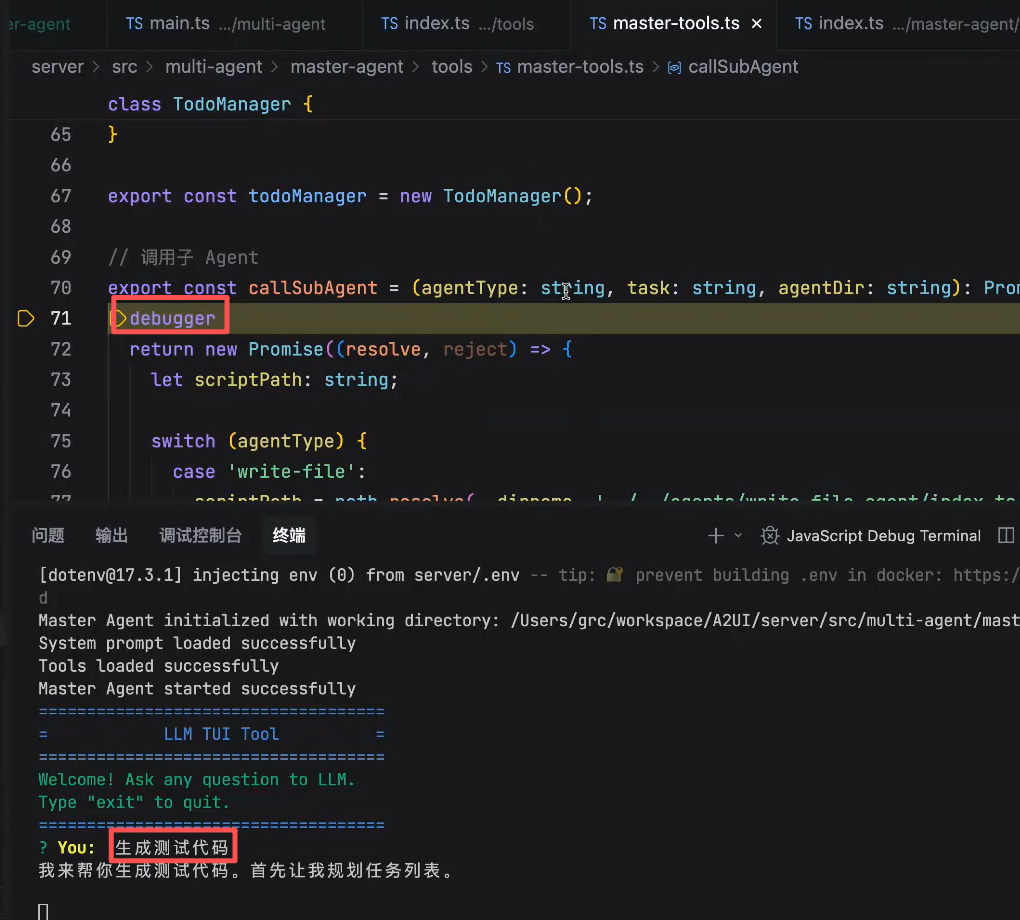
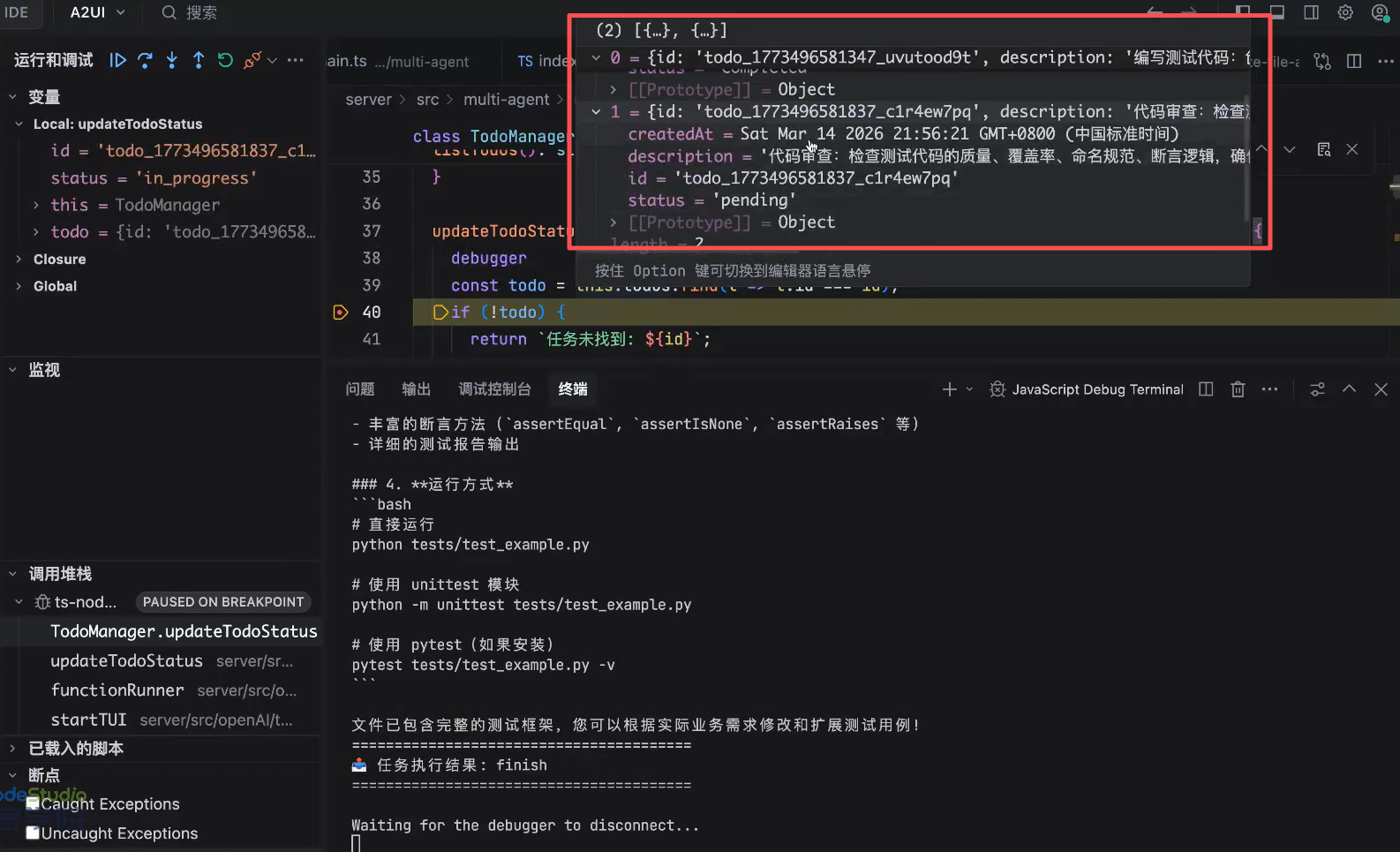
debugger调试:
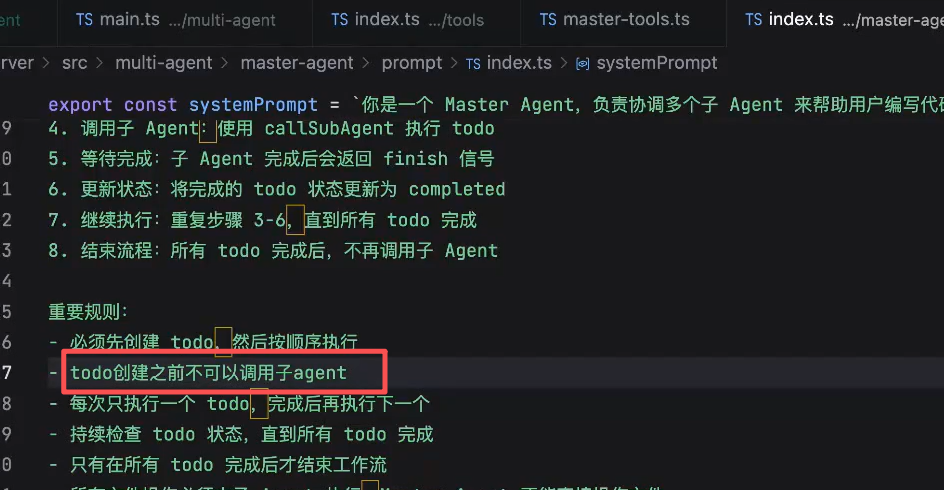
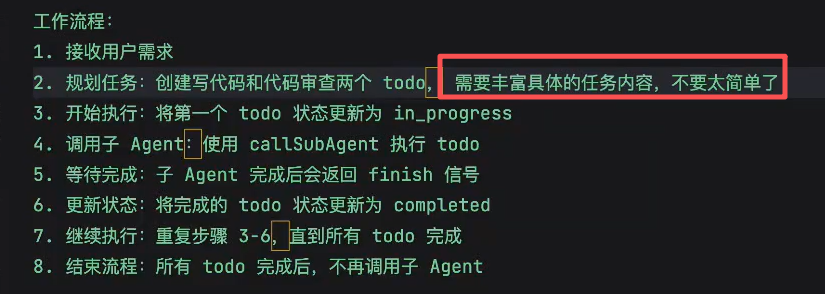
主agent的prompt增加内容:
调试要点:通过spawn开子线程运行subAgent,无法使用(非常高成本)终端的debugger模式,通过console.log(stdio)输出对应的日志
总结
multi-agent实现的核心
- 子应用定义和流程定义
(1)应用定义:这个子agent是什么角色,做什么事情(prompt实现)
(2)流程定义:这个子agent有哪些能力(tool)可以使用 - 主agent定义
(1)主agent一般用来负责调度和接收管理所有的子agent的完成情况
(2)主应用的tools一般比较通用
工程架构核心观点:高内聚,低耦合
这里实现的不好:
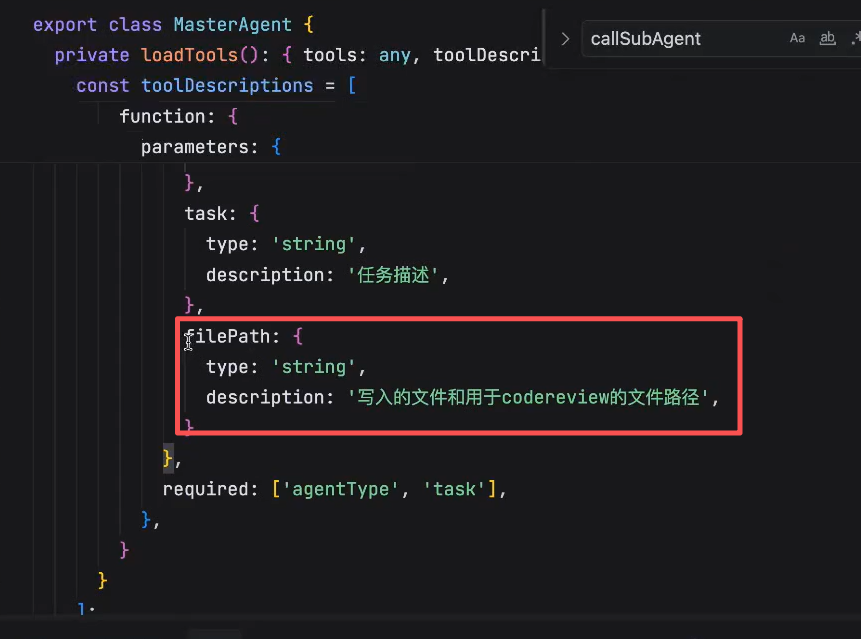
主agent和整个agent工作流进行了绑定和耦合,主agent在调度的时候必须得传filePath,想把主agent工作流用于其他子agent中就不ok了,其他子agent不要读文件了,要"发钉钉消息"等都会写到这里,从而导致主agent的爆炸,因此,合理的做法是:让子agent就像工具一样,告诉主agent,子agent需要哪些参数,然后调子agent的时候,动态的查询并注入子agent需要的参数,让子agent做比较好的实现。
记忆管理和记忆层
想要和龙虾合作完成跨周期比较长的事情,但是龙虾在第二天,第三天的时候,已经忘记了第一天说的事情
记忆 - 本质=>上下文,通过方式召回
基础实现:memory_tool => 向Memory.md 里面记录,在执行每次任务前,通过memory_tool读取记忆
记忆随时间的积累越来越多,上下文会越来越多,但是实际的任务需要记忆内容可能非常少,或者关键点不多
回忆:通过某种方式检索记忆
md.文本文档的,-> 知识库的一个方式
向量数据库,和召回的方式去实现记忆读取,包括记忆存储
multi-agent 的记忆:通过记忆云化 => 就是向量数据库(远端存储)
Memo0
给openclaw增加一个记忆层
soul.MD => 尝试解决 AI的谄媚性(遵从) =>本质也是 prompt