摘要:
该文提出了针对3D 医学图像分割的UNETR新型 Transformer 基架构,该架构将 3D 分割任务重构为序列到序列预测问题 ,突破了传统 FCNNs 卷积层局部性导致的长距离空间依赖学习局限;其以Transformer 作为主编码器 有效捕捉全局多尺度信息,搭配CNN 解码器捕捉局部空间信息,通过跨分辨率跳跃连接融合编码器不同层的特征,在BTCV(腹部 CT 多器官)和MSD(MRI 脑肿瘤、CT 脾脏)数据集上完成验证。
介绍:
U型的编码器解码器结构的网络在医学分割任务上取得了相当不错的效果,尤其是典型的U-Net结构,编码器负责通过逐渐对提取的特征进行下采样来学习全局上下文表示,而解码器对提取的表示进行上采样到输入分辨率以进行像素/体素的语义预测。此外,跳过连接以不同的分辨率将编码器和解码器的输出合并,从而允许恢复在下采样期间丢失的空间信息。
虽然基于卷积的方法效果不错,但是还是有很多问题,比如长距离建模能力被它们有限的感受野限制(这块原因和2d的没区别)。受到VIT的启发,该文提出了UNETR,简单来说,就是使用Transformer模型作为编码器提取特征,CNN模型作为解码器输出分割预测。
相关工作:
CNN
自经典的 U-Net 提出后,以 CNN 为基础的网络在各类 2D和 3D医学图像分割任务中,都取得了当前最优性能,成为该领域的主流方法。
纯 2D CNN 只能处理单张切片,丢失 3D 空间上下文信息;而早期纯 3D CNN 计算量极大,因此研究者提出2.5D 折中方案 :对 3D 体积中每个体素 ,提取其在三个视角下的 2D 切片特征,再将这些特征融合起来完成分割,既弥补了 2D 的 3D 上下文缺失,又降低了纯 3D 的计算成本。
纯 3D CNN 方法不做视角拆分 ,直接将由一系列 2D 切片 (如整卷 CT 的连续切片)或多模态数据 组成的完整 3D 体积图像作为输入,能直接捕捉体素间的 3D 空间依赖关系,分割的空间一致性更好,是 3D 体积分割的直接解决方案(缺点是对计算资源要求更高)。
虽然一些基于CNN的模型取得了不错的效果,但它们在学习全局背景和远程空间依赖方面的性能较差,这会严重影响具有挑战性任务的分割性能。
Transformer
为适配图像分类、检测等视觉任务的特性,研究者提出分层视觉 Transformer ,成为 ViT 的重要发展方向,其核心设计是模仿 CNN 的层级结构 :网络不同层的特征具备可变分辨率 ,浅层保留高分辨率细粒度特征,深层输出低分辨率全局特征;搭配空间嵌入 为序列特征补充空间位置信息,解决 Transformer 无空间感知的问题;采用逐步降低特征分辨率 + 下采样注意力模块 的方式,核心目的是降低 Transformer 自注意力的计算量(减少序列长度),兼顾特征的细节性和全局性。而 UNETR 编码器的所有 Transformer 层中,特征表示的尺寸 / 分辨率全程固定,无层内分辨率调整操作;
方法
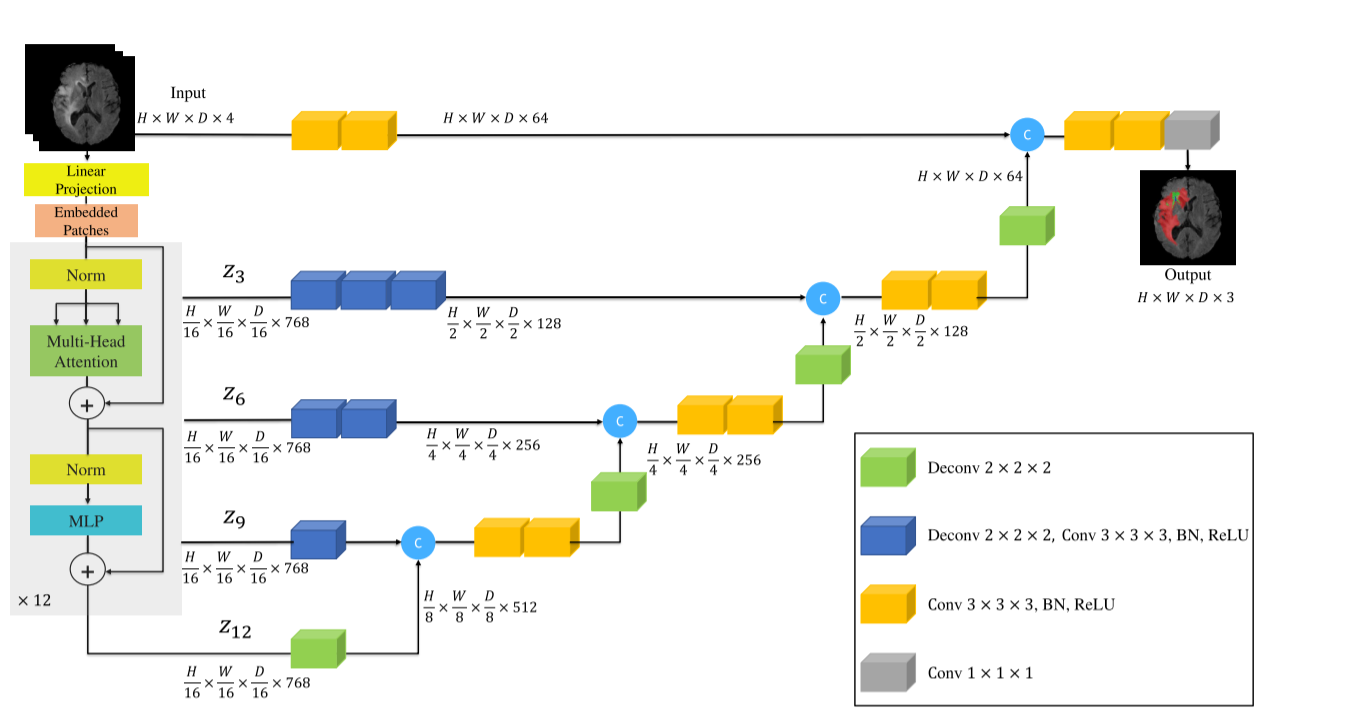
3D图像首先被切分为N个P×P×P的patch,然后加入一维位置向量后输入编码器,这部分全程固定分辨率,因为调整分辨率,会导致不同层的序列长度剧烈变化,3D 场景下的计算量和显存占用会直接超出硬件承载能力;也就是说Transformer 编码器只负责输出固定长度的 1D 序列,后续的 "降分辨率 / 升分辨率"(比如从 6×6×6→12×12×12→24×24×24),全部由 CNN 解码器的3D 卷积 / 反卷积完成 ------ 而卷积的计算量是线性的,哪怕 3D 卷积计算量比 2D 大,但线性增长的特性让硬件完全能承载。
提取 Transformer 多层序列特征,重塑为 3D 张量再通过卷积投影后,通过跳跃连接传给 CNN 解码器 ------ 这样就能让解码器获得 Transformer 不同层的全局特征,结合 CNN 的局部特征做密集分割。可以看到,这块从 Transformer提取出的张量维度都是相同的,使用的是反卷积和卷积来达到升降分辨率的效果,然后进行解码器的过程。
然后介绍损失函数部分:

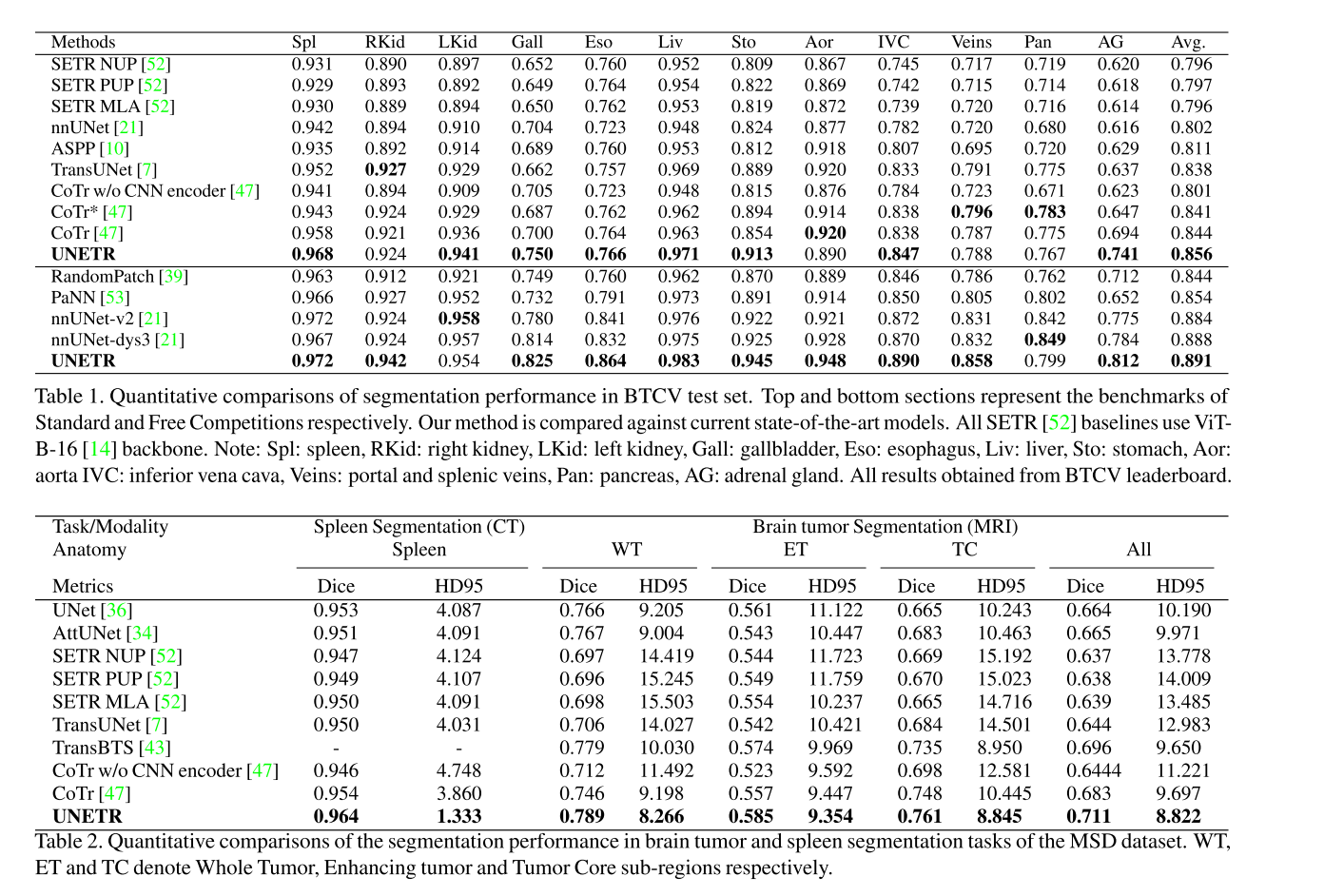
实验: