一、技术背景与目标
1.1 项目概述
ytb作为海外最大的视频社交媒体平台,其评论区蕴藏巨大挖掘价值。
本文介绍一种基于Python的视频评论数据采集技术方案。该方案通过调用网页接口实现数据抓取,无需模拟浏览器操作,具有较高的稳定性和采集效率。
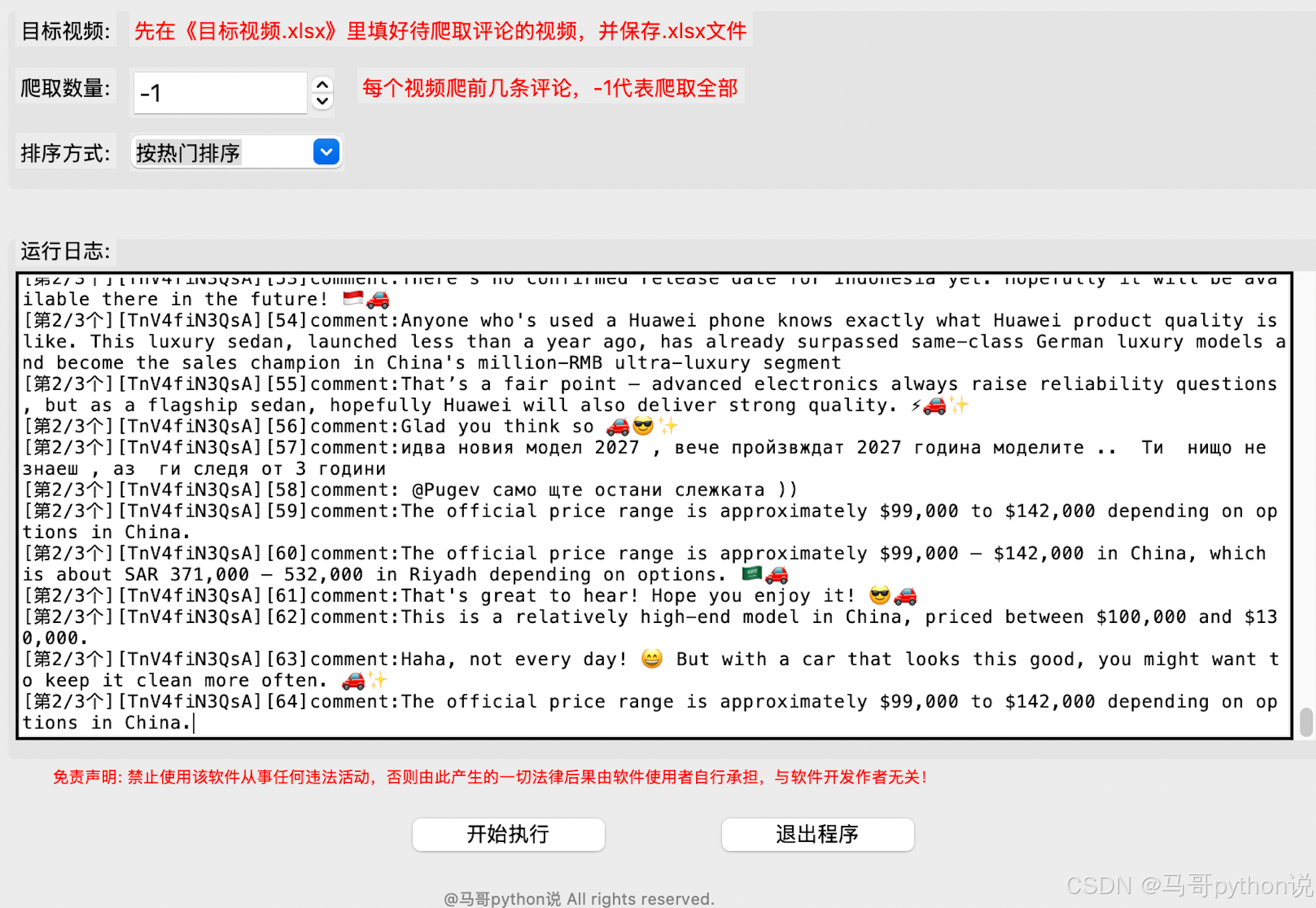
1.2 采集字段定义
采集的数据包含以下10个核心字段:
1. cid - 评论唯一标识符
2. text - 评论内容文本
3. time - 相对时间(如:2小时前)
4. author - 评论者昵称
5. channel - 评论者频道链接
6. votes - 评论点赞数
7. replies - 评论回复数
8. time_parsed - 解析后的时间对象
9. time2 - 绝对时间戳
10. video_id - 所属视频ID1.3 技术架构特点
- 接口调用模式:直接调用网页前端API,非浏览器自动化方案
- 数据持久化:增量式存储,每页数据实时写入,防止异常中断导致数据丢失
- 跨平台支持:基于Python Tkinter开发GUI,支持Windows/macOS系统
- 日志追踪:完整的运行日志记录,便于问题排查
二、核心实现原理
2.1 接口分析
评论数据通过其内部API接口返回JSON格式数据。关键接口参数包括:
videoId: 目标视频IDcontinuation: 分页令牌,用于获取更多评论clickTrackingParams: 追踪参数
请求响应结构示例:
json
{
"continuationContents": {
"itemSectionContinuation": {
"contents": [...],
"continuations": [...]
}
}
}2.2 数据解析逻辑
从JSON响应中提取评论数据的核心代码逻辑:
python
def parse_comment(item):
"""解析单条评论数据"""
comment = {}
renderer = item.get('commentRenderer', {})
# 提取评论ID
comment['cid'] = renderer.get('commentId', '')
# 提取评论内容
content_text = renderer.get('contentText', {})
comment['text'] = extract_text_runs(content_text)
# 提取作者信息
author_text = renderer.get('authorText', {})
comment['author'] = author_text.get('simpleText', '')
# 提取点赞数
vote_count = renderer.get('voteCount', {})
comment['votes'] = parse_vote_count(vote_count)
return comment2.3 分页处理机制
评论采用流式加载,通过continuation令牌实现分页:
python
class CommentCrawler:
def __init__(self):
self.session = requests.Session()
self.headers = self._build_headers()
def fetch_comments(self, video_id, limit=-1):
"""获取指定视频的评论"""
continuation = self._get_initial_continuation(video_id)
comments = []
while continuation and (limit == -1 or len(comments) < limit):
response = self._fetch_page(continuation)
page_data = self._parse_response(response)
# 提取评论
for item in page_data.get('comments', []):
comment = self._extract_comment(item)
comments.append(comment)
self._save_incremental(comment) # 增量保存
# 获取下一页令牌
continuation = page_data.get('next_continuation')
# 请求间隔,避免触发风控
time.sleep(random.uniform(1, 2))
return comments三、技术实现细节
3.1 反爬虫策略应对
网站具备完善的反爬机制,关键技术点:
| 策略类型 | 应对方案 |
|---|---|
| 请求频率限制 | 动态随机延时(1-3秒) |
| User-Agent检测 | 使用真实浏览器UA |
| Cookie验证 | 维护会话状态 |
| IP限制 | 配合网络环境配置 |
3.2 数据存储方案
采用CSV格式进行增量存储,防止程序异常中断导致数据丢失:
python
def save_incremental(self, comment, video_id):
"""增量保存单条评论"""
file_path = f'./results/{video_id}.csv'
# 检查文件是否存在,写入表头
file_exists = os.path.exists(file_path)
with open(file_path, 'a+', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(f, fieldnames=self.fieldnames)
if not file_exists:
writer.writeheader()
writer.writerow(comment)3.3 图形界面设计
基于Tkinter构建简单GUI,便于非技术人员使用:
python
import tkinter as tk
from tkinter import ttk, messagebox
class CommentCrawlerGUI:
def __init__(self, root):
self.root = root
self.root.title('ytb评论采集工具')
self.root.geometry('850x650')
self._create_widgets()
def _create_widgets(self):
# 视频链接输入区
tk.Label(self.root, text='目标视频:').place(x=30, y=30)
self.video_entry = tk.Entry(self.root, width=60)
self.video_entry.place(x=120, y=30)
# 采集数量设置
tk.Label(self.root, text='采集数量:').place(x=30, y=70)
self.limit_spin = tk.Spinbox(
self.root, from_=-1, to=9999999,
width=10, font=('微软雅黑', 12)
)
self.limit_spin.place(x=120, y=70)
tk.Label(self.root, fg='gray',
text='-1表示采集全部评论').place(x=240, y=70)
# 运行日志显示区
self.log_text = tk.Text(
self.root, width=100, height=20,
state='disabled', bg='#f5f5f5'
)
self.log_text.place(x=30, y=150)
# 控制按钮
tk.Button(
self.root, text='开始采集',
command=self.start_crawl,
bg='#4CAF50', fg='white',
font=('微软雅黑', 12), width=15
).place(x=350, y=520)四、日志系统设计
4.1 日志配置
完善的日志系统有助于问题定位和调试:
python
import logging
from logging.handlers import TimedRotatingFileHandler
def setup_logger():
"""配置日志记录器"""
logger = logging.getLogger('crawler')
logger.setLevel(logging.DEBUG)
# 格式化模板
formatter = logging.Formatter(
'[%(asctime)s][%(levelname)s][%(filename)s:%(lineno)d] %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(formatter)
# 文件处理器(按天轮转)
file_handler = TimedRotatingFileHandler(
filename='./logs/crawler.log',
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8'
)
file_handler.setLevel(logging.DEBUG)
file_handler.setFormatter(formatter)
logger.addHandler(console_handler)
logger.addHandler(file_handler)
return logger4.2 日志记录示例
运行过程中的关键节点记录:
[2024-01-15 10:23:45][INFO][crawler.py:156] 开始采集视频: dQw4w9WgXcQ
[2024-01-15 10:23:46][DEBUG][api.py:89] 获取初始continuation令牌
[2024-01-15 10:23:47][INFO][crawler.py:178] 第1页采集完成,获取评论20条
[2024-01-15 10:23:49][INFO][crawler.py:178] 第2页采集完成,获取评论20条
[2024-01-15 10:23:52][WARNING][crawler.py:201] 触发频率限制,延时3秒五、技术难点与解决方案
5.1 难点分析
- 动态加载机制:评论通过JavaScript动态渲染,需分析XHR请求
- 反爬验证:内部使用多种反爬手段
- 数据格式化:富文本评论包含emoji、链接等特殊字符
- 大规模采集:批量视频采集时的效率与稳定性平衡
5.2 优化策略
- 请求池管理:复用TCP连接,减少握手开销
- 智能重试:遇到临时错误时自动重试,最多3次
- 断点续传:支持从上次中断位置继续采集
- 资源释放:确保文件句柄和网络连接正确关闭
六、应用场景
该技术方案可应用于以下场景:
- 舆情分析:采集特定话题下的用户评论进行情感分析
- 内容研究:研究视频内容对用户评论的影响
- 竞品分析:对比不同创作者/频道的互动数据
- 学术研究:社交媒体数据分析和自然语言处理研究
七、技术总结
本文介绍了一种基于Python的ytb评论采集技术方案,核心要点包括:
- 通过分析网页API实现高效数据采集
- 采用增量存储策略确保数据安全
- 完善的日志系统便于问题排查
- 图形界面降低使用门槛
技术限制说明:
- 需要配置相应的网络环境才能正常访问
- 采集速度受限于平台反爬策略
- 仅供学习研究使用,请遵守相关平台的服务条款
八、演示视频
软件演示视频:
【GUI开发】用python开发YouTube评论采集软件!
九、仓库地址
本项目的github地址:
本文仅作技术交流和学习探讨,具体实现需遵守相关法律法规和平台政策。