上个月一个朋友找我------某动力电池企业的质量总监,让我帮他们看看质量成本数据。
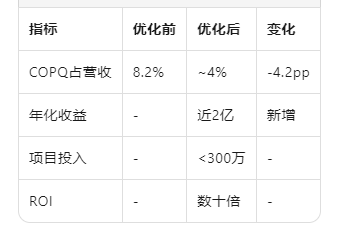
他说:"我们COPQ占营收8.2%,老板让我降到5%以内,不知道怎么下手。"
我说:"先把数据拆清楚。"

一、COPQ四分类模型
COPQ(Cost of Poor Quality)分四类:
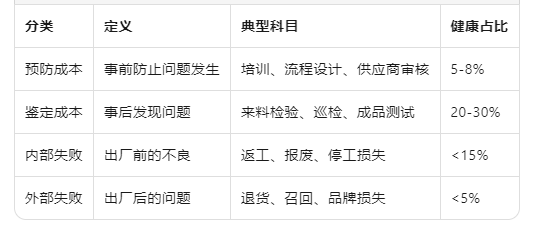
他家的数据:
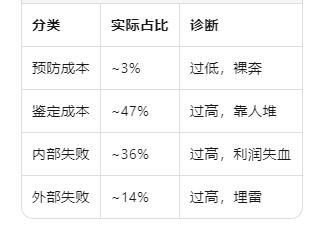
问题一目了然:钱花错了地方。
二、三个项目的DOE实战
我们用六西格玛方法论做了三个项目。
项目1:涂布工序气泡缺陷
问题:良率82%,气泡占不良32%
DOE设计:
三因素二水平全因子实验
因素A:涂布速度(1.0, 1.2)
因素B:浆料粘度(4500, 5200)
因素C:烘箱温度(85+110, 统一95)
import numpy as np
from pyDOE2 import ff2n
2^3全因子设计
design = ff2n(3)
print(design)
输出:8个runs的组合矩阵
实际跑了8组实验,ANOVA分析找到显著因子:A(涂布速度)和B×C交互效应。
最优窗口:
-
涂布速度:1.2 m/min
-
浆料粘度:4500 cP
-
烘箱温度:第一段85°C,第二段110°C
结果:良率从82% → 96.3%。年化收益数千万级。
项目2:来料检验优化
原来100%全检,47个检验员。
用Minitab做抽样方案设计:
ANSI/ASQ Z1.4 单次抽样
AQL = 1.0, Level II
Lot size = 5000
Sample size = 200, Ac=5, Re=6
改成智能抽检+关键参数全检后:
-
检验员:47人 → 28人
-
漏检率:0.8% → 0.3%
-
年省人工成本:数百万
项目3:供应商质量前置
对TOP10供应商做QSB审核+早期遏制。
来料不良率:3.2% → 0.8%。
年化节省:退货+索赔+换料 = 数千万。
三、COPQ优化结果
四、关键洞察
1. 六西格玛不是工具堆砌,是问题定义
很多企业一上来就学DOE、学SPC,但问题定义不清楚,工具越用越乱。先测COPQ,找到最大的浪费点,再选工具。
2. 数据系统是前提
这家企业能做成,是因为MES系统有完整数据。另一家企业数据靠人工记录,光是数据清洗就花了两个月。
3. 预防投入是杠杆
预防成本从3%提到合理比例,鉴定成本从47%压下来,内部外部失败双降。钱花对地方,比少花钱更重要。
五、自测工具
如果你也想测自家COPQ结构,可以用这个简易框架:
COPQ快速自测清单:
□ 预防成本占质量成本比例
<5% → 裸奔,急需补课
5-8% → 健康
>10% → 可能过度
□ 鉴定成本占质量成本比例
<20% → 可能不足
20-35% → 健康
>45% → 靠人堆,考虑自动化
□ 内部失败占质量成本比例
<10% → 优秀
10-20% → 可接受
>30% → 利润在流血
□ 外部失败占质量成本比例
<3% → 优秀
3-8% → 需关注
>10% → 埋雷
你家的COPQ结构是什么比例?欢迎在评论区分享。
关于作者:张驰咨询首席MBB顾问,25年企业变革项目实战经验,主导2000+家企业六西格玛导入。更多案例和方法论,可关注我们的知乎专栏。