1. 简介
Step 3.7 Flash 是一个拥有 198B 参数的稀疏专家混合模型,它结合了一个 196B 参数的语言主干网络和一个 1.8B 参数的视觉编码器,以实现原生图像理解。该模型专为高频生产工作负载而设计,每个令牌激活约 110 亿个参数,吞吐量高达每秒 400 个令牌。Step 3.7 Flash 支持 256k 上下文窗口,并提供三种可选的推理级别,让开发者可以轻松在速度、成本和认知深度之间取得平衡。
我们为需要扩展结合感知、搜索和推理的智能体工作流的开发者构建了 Step 3.7 Flash。它旨在处理密集型任务,例如一次性解析海量财务报告、运行具有跨源验证功能的多步骤搜索循环,或在高吞吐量管道中运行并发编码智能体。
2. 能力与性能
多模态感知与验证
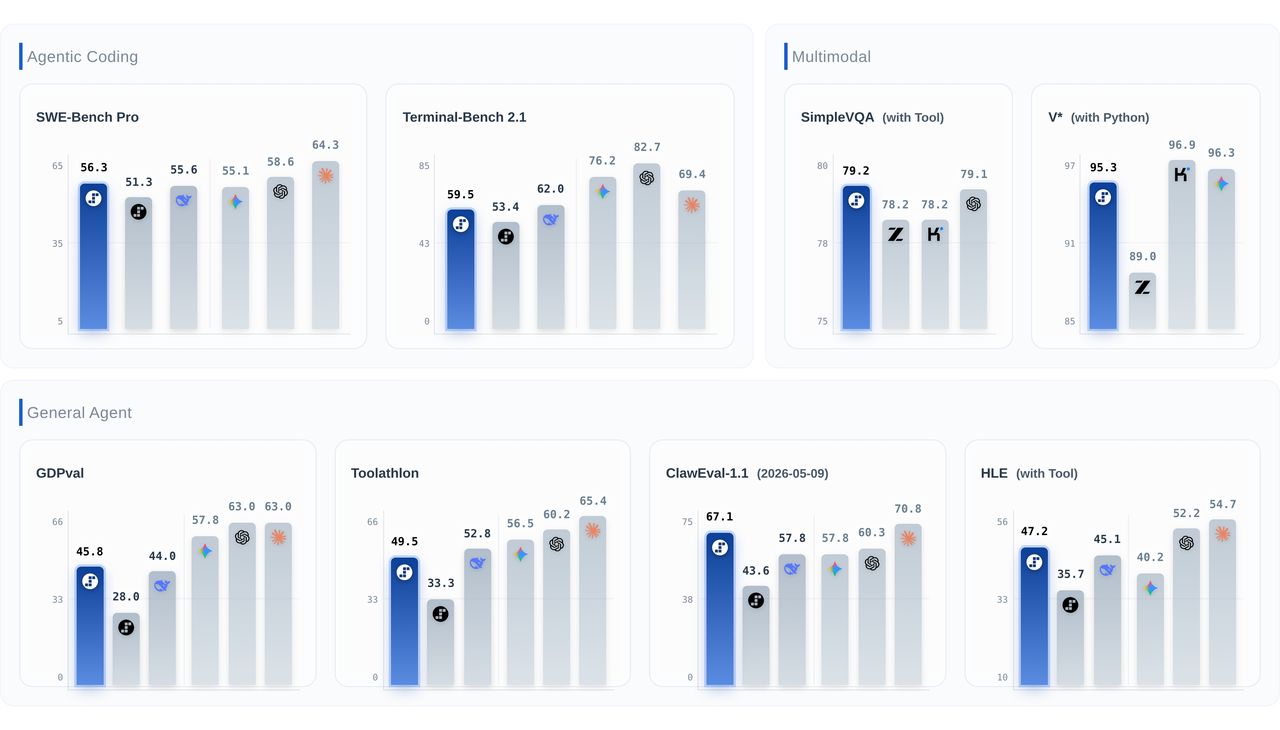
该模型提供顶级的视觉智能,在 SimpleVQA 基准测试中以 79.2 分获得第一名,并在 V* 基准测试中达到 95.3 分,与前沿模型持平。这些指标反映了其超越基本图像描述的强大视觉基础和检索增强推理能力。该模型能够准确处理密集的视觉界面,例如 UI 线框图、应用程序 GUI 和数据图表,并将其映射为结构化代码。当遇到不完整的视觉资源时,它能够独立识别缺失数据并执行查找以验证上下文,然后返回经过事实核查的结论。
工作流完整性与工具编排
执行可靠性对于自主智能体至关重要。Step 3.7 Flash 在 ClawEval-1.1 基准测试中以 67.1 分领先,显著优于最接近的竞争对手。这一性能表明其在多轮编排过程中对对抗性陷阱具有高抵抗力,并严格遵守系统策略。凭借在 Toolathlon 和 HLE w. Tool 基准测试中的得分,该模型确保了高轨迹完整性。Step 3.7 Flash 能够可靠地与外部 API 交互,并执行长视野工作流,而不会偏离指令或违反系统约束。
代码工程与专业基准
Step 3.7 Flash 专为实时工程任务而构建,在 SWE-Bench PRO 基准测试中以 56.3 分获得明确的第二名。它能够独立追踪多文件代码库,从原始问题报告中隔离错误,并生成能通过自动化单元测试的功能性补丁。虽然与同类模型的绝对峰值相比,在 Terminal-Bench 2.1 和 GPDVal-AA 等评估中显示出未来优化的明确领域,但它们为系统交互和结构化专业交付成果建立了可靠的基线。
3. 定价
| 令牌类型 | 价格 |
|---|---|
| 输入 | $0.20 / 百万令牌 |
| 输出 | $1.15 / 百万令牌 |
4. 可用性、部署与生态系统
- 可用性:Step 3.7 Flash 已在 StepFun 开放平台上线,并即将通过合作伙伴扩大可用性。
- 部署:Step 3.7 Flash 支持在云、数据中心和本地环境中灵活部署。对于大规模生产和企业用例,它可以部署在现代数据中心基础设施上。对于本地和工作站场景,它也可以在具有至少 128GB 统一内存的高内存设备上运行。
- 生态系统:Step 3.7 Flash 在流行的开源推理和模型开发基础设施中得到支持。对于推理和服务,开发者可以使用 vLLM、SGLang、Hugging Face Transformers 和 llama.cpp。对于模型开发和定制工作流,StepFun 模型支持已集成到 NVIDIA Nemo 生态系统中。
5. 示例
您可以在几分钟内使用 StepFun 的 API 或其他推理提供商开始使用 Step 3.7 Flash。
请根据您所在的地区选择正确的
base_url。StepFun 运营着两个区域平台,拥有独立的 API 主机。您传递给 OpenAI 客户端的base_url必须与您的 API 密钥签发的平台匹配,否则请求将被拒绝为未授权。
- 全球 :
base_url=https://api.stepfun.ai/v1- 中国 :
base_url=https://api.stepfun.com/v1为避免硬编码错误的区域,以下示例从环境变量中读取 API 密钥和基础 URL。在运行前导出它们:
bashexport STEP_API_KEY="sk-..." export STEP_BASE_URL="https://api.stepfun.ai/v1" # 中国平台请使用 https://api.stepfun.com/v1
5.1 聊天示例
python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["STEP_API_KEY"],
base_url=os.environ["STEP_BASE_URL"],
)
completion = client.chat.completions.create(
model="step-3.7-flash",
messages=[
{
"role": "system",
"content": "You are an AI assistant provided by StepFun. You are good at Chinese, English, and many other languages, and you can see, think, and act to help users get things done.",
},
{
"role": "user",
"content": "Introduce StepFun's artificial intelligence capabilities."
},
],
)
print(completion)5.2 文本和图像输入示例
python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["STEP_API_KEY"],
base_url=os.environ["STEP_BASE_URL"],
)
completion = client.chat.completions.create(
model="step-3.7-flash",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What is in this picture?"},
{
"type": "image_url",
"image_url": {"url": "https://example.com/photo.jpg"},
},
],
},
],
)
print(completion)6. 本地部署
Step 3.7 Flash 针对本地推理进行了优化,并支持行业标准后端,包括 vLLM、SGLang、Hugging Face Transformers 和 llama.cpp。
6.1 vLLM
我们推荐使用 StepFun 预构建的支持 Step 3.7 的 vLLM Docker 镜像。
- 安装 vLLM。
bash
# 通过 Docker
docker pull vllm/vllm-openai:stepfun37- 启动服务器。
- 对于 FP8 模型
bash
vllm serve <MODEL_PATH_OR_HF_ID> \
--served-model-name step3p7-flash \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--disable-cascade-attn \
--reasoning-parser step3p5 \
--enable-auto-tool-choice \
--tool-call-parser step3p5 \
--speculative_config '{"method": "mtp", "num_speculative_tokens": 3}' \
--trust-remote-code- 对于 BF16 模型
bash
vllm serve <MODEL_PATH_OR_HF_ID> \
--served-model-name step3p7-flash-bf16 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--disable-cascade-attn \
--reasoning-parser step3p5 \
--enable-auto-tool-choice \
--tool-call-parser step3p5 \
--speculative_config '{"method": "mtp", "num_speculative_tokens": 3}' \
--trust-remote-code- 对于 NVFP4 模型
与标准精度相比,运行 FP4 量化版本需要激活 modelopt 并对齐 FP8 KV 缓存。
bash
python3 -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port ${PORT} \
--model stepfun-ai/Step-3.7-Flash-NVFP4 \
--served-model-name step3p7 \
--tensor-parallel-size 4 \
--gpu-memory-utilization 0.9 \
--enable-expert-parallel \
--trust-remote-code \
--quantization modelopt \
--kv-cache-dtype fp8 \
--max-model-len 8192 \
--reasoning-parser step3p5 \
--enable-auto-tool-choice \
--tool-call-parser step3p5 \
--async-scheduling6.2 SGLang
- 安装 SGLang。
bash
# 通过 Docker
docker pull lmsysorg/sglang:dev-step-3.7-flash
# 或从源码安装
pip install "sglang[all] @ git+https://github.com/sgl-project/sglang.git"- 启动服务器。
注意: 对于 Blackwell GPU,可以使用
--mm-attention-backend fa4。
- 对于 BF16 模型
bash
sglang serve --model-path stepfun-ai/Step-3.7-Flash \
--tp 8 \
--reasoning-parser step3p5 \
--tool-call-parser step3p5 \
--enable-multimodal \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--enable-multi-layer-eagle \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000- 对于 FP8 模型
bash
sglang serve --model-path stepfun-ai/Step-3.7-Flash-FP8 \
--tp 8 \
--ep 4 \
--reasoning-parser step3p5 \
--tool-call-parser step3p5 \
--enable-multimodal \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--enable-multi-layer-eagle \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000- 对于 NVFP4 模型
bash
sglang serve --model-path stepfun-ai/Step-3.7-Flash-NVFP4 \
--tp 4 --ep 4 \
--moe-runner-backend flashinfer_trtllm \
--kv-cache-dtype fp8_e4m3 \
--quantization modelopt_fp4 \
--trust-remote-code \
--reasoning-parser step3p5 \
--tool-call-parser step3p5 \
--attention-backend trtllm_mha6.3 Transformers
使用此代码片段进行快速功能验证。对于高吞吐量服务,请使用 vLLM 或 SGLang。
注意: 部署此模型需要
transformers5.0 或更高版本。
python
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_PATH = "<MODEL_PATH_OR_HF_ID>"
# 1. 设置
processor = AutoProcessor.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map="auto",
dtype="auto",
trust_remote_code=True
)
# 2. 准备输入
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://example.com/photo.jpg"},
{"type": "text", "text": "What is in this picture?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
# 3. 生成
generated_ids = model.generate(**inputs, max_new_tokens=128, do_sample=False)
output_text = processor.decode(generated_ids[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(output_text)6.4 llama.cpp
系统要求
GGUF 模型权重:
| 组件 | 量化 | 文件大小 |
|---|---|---|
| 语言模型 | Q4_K_S | 111.5 GB |
| 语言模型 | IQ4_XS | 104.99 GB |
| 语言模型 | Q3_K_L | 102.5 GB |
| 多模态投影器 | FP16 | 3.97 GB |
- 运行时开销: ~7 GB
- 最低统一内存 / VRAM: 120 GB
- 推荐: 128 GB 统一内存
步骤
- 使用 llama.cpp:
bash
git clone https://github.com/stepfun-ai/llama.cpp.git
cd llama.cpp
git checkout -b step3.7 origin/step3.7- 在 Mac 上构建 llama.cpp:
bash
cmake -B build-macos -S . \
-DCMAKE_BUILD_TYPE=Release \
-DBUILD_SHARED_LIBS=ON \
-DLLAMA_BUILD_SERVER=ON \
-DLLAMA_BUILD_TESTS=ON \
-DGGML_METAL=ON \
-DGGML_METAL_EMBED_LIBRARY=ON \
-DGGML_BLAS=ON \
-DGGML_BLAS_VENDOR=Apple \
-DGGML_ACCELERATE=ON \
-DGGML_NATIVE=ON
cmake --build build-macos -j8- 在 DGX-Spark 上构建 llama.cpp:
bash
cmake -S . -B build-cuda \
-DCMAKE_BUILD_TYPE=Release \
-DGGML_CUDA=ON \
-DGGML_CUDA_GRAPHS=ON \
-DGGML_CUDA_FORCE_MMQ=ON \
-DLLAMA_OPENSSL=OFF \
-DLLAMA_BUILD_COMMON=ON \
-DLLAMA_BUILD_TOOLS=ON \
-DLLAMA_BUILD_SERVER=ON \
-DLLAMA_BUILD_EXAMPLES=OFF \
-DLLAMA_BUILD_TESTS=OFF
cmake --build build-cuda -j8- 在 AMD Windows 上构建 llama.cpp:
bash
cmake -S . -B build-vulkan \
-DCMAKE_BUILD_TYPE=Release \
-DGGML_VULKAN=ON \
-DGGML_NATIVE=ON \
-DLLAMA_BUILD_SERVER=ON \
-DLLAMA_BUILD_UI=OFF \
-DLLAMA_BUILD_TOOLS=ON
cmake --build build-vulkan -j8- 使用
llama-cli运行:
bash
./llama-cli -m Step3.7_Q4_K_S.gguf -b 2048 -ub 2048 -fa on --temp 1.0 -p "What's your name?"- 使用
llama-batched-bench测试性能:
bash
./llama-batched-bench -m step3.7_Q4_K_S.gguf -c 32768 -b 2048 -ub 2048 -npp 0,2048,8192,16384,32768 -ntg 128 -npl 17. 在智能体平台上使用 Step 3.7 Flash
您可以在 Hermes Agent、OpenClaw、Kilo Code 等智能体平台上使用 Step 3.7 Flash。
8. 联系我们
在我们努力通过扩展广泛的模型能力来塑造 AGI 的未来时,我们希望确保我们正在解决正确的问题。我们邀请您成为这个持续反馈循环的一部分------您的见解直接影响我们的优先级。
- 报告问题: 遇到限制?您可以在 GitHub / HuggingFace 上提出问题或发起讨论。
📄 许可证
本项目根据 Apache 2.0 许可证开源。