引言
在AI编程工具蓬勃发展的今天,字节跳动推出的Trae(与AI深度协作的集成开发环境)正成为开发者社区的热门话题。作为一款AI原生IDE,Trae不仅提供代码自动补全,更通过深度集成的AI能力实现了真正的"智能协作"。本文将带您全面了解Trae的最新动态、核心功能、技术原理以及实操指南。
一、工具介绍与最新动态
1.1 Trae是什么?
Trae是由字节跳动推出的一款由AI驱动的集成编程开发环境,定位为"智能协作AI IDE"。它与AI深度集成,提供AI自动编程、代码自动补全、智能问答等功能,旨在帮助开发者自动化完成开发任务,甚至在一些项目中实现端到端开发。
1.2 版本差异与收费模式(2026年3月更新)
Trae目前分为国内版与国外版,两者在模型支持和收费策略上有显著差异:
| 版本 | 支持模型 | 收费模式 | 适用人群 |
|---|---|---|---|
| 国内版 | 豆包、DeepSeek(满血版) | 完全免费 | 中文开发者、预算有限的个人开发者 |
| 国外版 | Claude系列(3.5/3.7/4)、Gemini-2.5-Pro、GPT系列、DeepSeek等 | 首月3美元,次月起10美元/月 | 追求顶尖模型效果的专业开发者 |
最新收费调整 :国外版近期从免费转向付费模式,目前的套餐为首月3美元、次月10美元,价格约为Cursor的一半。付费用户享有600次快速请求和无限慢速请求次数,相比之下Cursor仅提供500次快速请求,Trae的性价比优势明显。
小贴士:目前账号没有多人使用的限制,开发者可以找人拼单分摊成本。Claude系列模型生成内容质量特别高,有条件的话推荐体验国外版。
1.3 Trae 1.4.0 版本亮点
根据官方信息,Trae 1.4.0版本带来了多项重要更新:
- 付费免排队能力:新用户首充3美元可获得600次快速队列,超级模型(Claude-4/3.7/3.5-Sonnet、Gemini-2.5-Pro等)体验更丝滑
- 新增账号管理:可实时查看模型及队列用量,选购低至0.02美元/次的容量包
- Agent能力优化:让AI更自主决策,提升生成效果
- 工具调用扩充:减少编程时的人工依赖
- 智能体分享:支持一键分享与导入,快速复用Prompt和MCP配置
- 语言环境引导:新增对Python、Java、Go等语言的配置引导
二、核心功能全景
2.1 智能代码生成:自然语言转代码
Trae最基础也最强大的功能是通过自然语言描述生成可运行代码。支持Python、Java、Go、JavaScript、C++等主流语言。
示例:输入"用Python爬取微博热搜前10并保存到Excel",Trae将生成完整的爬虫脚本,包括请求处理、数据解析和Excel写入。
2.2 Builder模式:从零构建完整项目
Builder模式是Trae的项目级开发功能,允许开发者使用自然语言描述需求,由AI自动生成完整的项目结构、代码文件和开发流程。
工作原理流程图:
用户自然语言描述
意图解析
技术栈推荐
项目结构生成
多文件代码生成
依赖配置
可运行项目
项目类型库
最佳实践库
代码模板
实际案例:输入"创建一个Python Flask Web应用,实现用户注册登录功能,使用SQLite数据库",Trae会自动生成完整的MVC架构项目,包括模型定义、路由处理、前端模板和配置文件。
2.3 跨文件代码理解:项目级上下文感知
这是Trae的核心技术突破。它能够解析整个代码仓库的文件结构,理解跨文件的类、函数依赖关系,并根据项目上下文补全代码。
应用场景:
- 大型项目重构时自动更新所有关联调用点
- 遗留代码维护中快速理解代码依赖关系
- 调用内部API时自动补全参数
2.4 多模态能力:图像转代码
Trae支持直接上传UI截图生成前端代码。上传图片后,AI会解析布局结构、色彩体系和交互元素,输出响应式HTML/CSS代码。
测试数据:一个电商商品卡片截图可在90秒内转化为带hover效果的组件代码,并保留设计稿的间距、字体等细节。
2.5 智能调试与优化
- Bug精准修复:粘贴报错信息,AI定位问题根源并提供可应用的代码修补方案
- 代码优化:识别低效代码,建议向量化操作或算法优化
- 自动添加注释、拆分过长函数、规范变量命名
三、技术深度解析:代码索引原理
Trae之所以能实现精准的跨文件理解和智能补全,核心在于其代码语义索引体系。下面从技术视角拆解其实现原理。
3.1 索引的核心价值
传统编辑器只能做"文本级"处理,而Trae的代码语义索引将"无结构的代码文本"转化为"可快速检索的结构化数据",解决两个核心问题:
- 效率:检索速度从"秒级"降至"毫秒级"
- 精准度:理解代码的语义关系,而非仅匹配字符
3.2 索引构建流程(五步法)
文件扫描与过滤
语法解析
生成AST
语义分析
跨文件关联
结构化存储
校验与增量更新
忽略文件
node_modules等
各语言解析器
实体提取
关系梳理
键值+图数据库
步骤详解:
-
文件扫描与过滤:遍历项目文件,过滤掉node_modules、日志、缓存等无关文件,识别文件编码和语言类型
-
语法解析(生成AST):调用各语言官方解析器生成抽象语法树,将"文本代码"转化为"机器可理解的语法骨架"
- Python:
ast模块 - JavaScript:
@babel/parser - Java:
javac抽象语法树API
- Python:
-
语义分析(跨文件关联):这是索引构建的"灵魂步骤",完成三类分析:
- 实体提取:识别类、函数、接口、变量,记录元信息
- 关系梳理:分析调用关系、导入关系、继承关系、依赖关系
- 上下文补充:为每个元素关联所属模块、注释、作用域
-
结构化存储 :采用嵌入式混合数据库方案:
- 键值数据库(如LevelDB):存储实体信息,支持毫秒级精准查询
- 图数据库(如Neo4j Embedded):存储关系信息,支持高效的关系遍历
-
校验与增量更新:检查解析失败的文件,用户修改代码后仅重新解析修改的文件,保证实时性且降低开销
3.3 索引调用流程(以#Workspace提问为例)
当用户提问"add函数被哪里调用了?"时,背后的技术流程如下:
-
捕获操作,解析意图:提取关键词"add、函数、调用",确定意图为检索所有调用add函数的关系
-
构造查询请求:
python# 伪代码:Trae内部查询逻辑 # 1. 通过键值数据库查add函数的实体ID add_entity_id = kv_db.get_entity_id(name="add", entity_type="function") # 2. 通过图数据库查所有调用add函数的关系 call_rels = graph_db.get_relationships(target_entity_id=add_entity_id, relationship_type="call") -
数据库高效检索:键值数据库O(1)时间复杂度匹配实体ID,图数据库基于实体ID遍历所有关系,整个过程<10ms(百万行代码项目)
-
结果处理与转换:将结构化数据转换为用户可理解的回答:"add函数在src/main.py的main函数中被调用(第6行),调用代码:calc.add(5, 3)"
3.4 技术选型对比
为什么Trae不直接用JSON+SQL?核心原因是"适配性":
| 方案 | 优点 | 缺点 |
|---|---|---|
| JSON文件 | 结构直观 | 检索需全量解析,不支持关系查询,速度慢 |
| SQL关系库 | 成熟稳定 | 图关系查询需多次JOIN,效率低 |
| Trae混合方案 | 兼顾实体查询与关系遍历 | 需定制化封装API |
四、国内版安装与上手指南
4.1 安装步骤
-
下载安装包 :访问国内版官网 https://www.trae.com.cn,点击"立即获取Trae IDE"
-
安装程序 :双击下载的安装程序,按照提示一步步操作直至完成

-
首次启动:
- 双击Trae图标打开
- 在导入配置环节单击"跳过"(或从VS Code/Cursor导入现有配置)
- 继续单击"跳过"直至登录界面
-
账号登录:
- 单击"登录"
- 输入手机号,获取并输入验证码
- 出现"登录以使用Trae"界面,单击确认

-
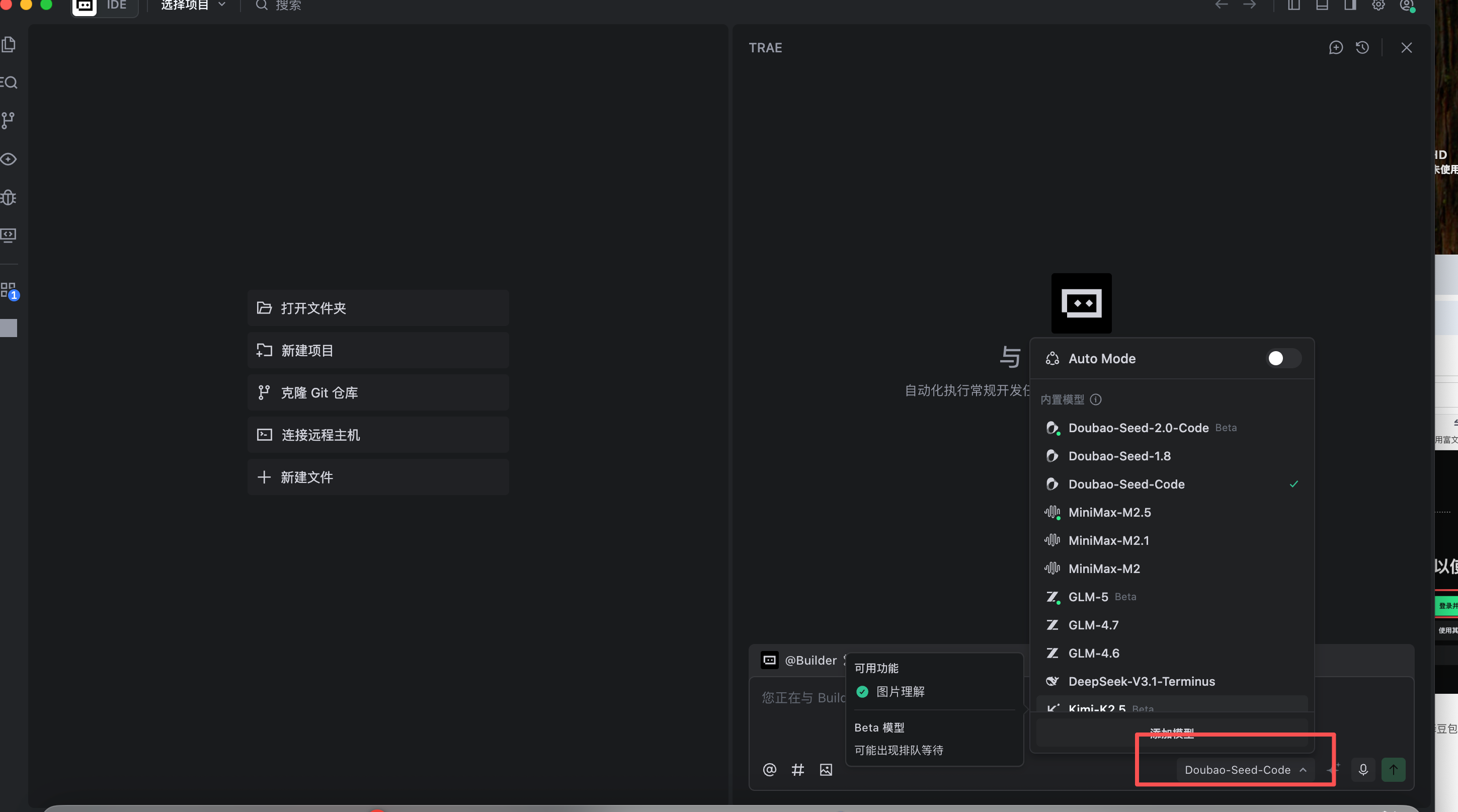
选择模型 :在界面右下角输入框右侧的飞机形状图标处,可以选择豆包或DeepSeek模型
五、深入探索:Builder智能体与规则定制
Trae的核心竞争力不仅在于其强大的AI模型,更在于它如何将这些模型与开发环境深度融合。本节将深入探讨Trae的智能体架构和规则定制能力,帮助您从"会用"进阶到"用得精"。
5.1 Builder:基础开发智能体
Builder是Trae的原生智能体,专注于纯代码开发任务。它通过内置工具集实现了对开发全流程的闭环支持。
5.1.1 Builder的核心能力
Builder智能体
文件系统操作
终端命令执行
代码预览与调试
需求即代码转化
创建文件/文件夹
编辑现有文件
文件重命名/删除
运行脚本
安装依赖
启动服务
实时渲染预览
自动错误修复
依赖自动安装
自然语言生成代码
代码重构优化
具体能力详解:
-
文件系统操作:Builder可以直接在您的项目中创建、编辑和管理文件。无论是新建组件文件,还是批量修改多个文件的代码,都可以通过自然语言指令完成。
-
终端命令执行:Builder能够运行终端命令,包括安装依赖、执行测试脚本、启动开发服务器等。这意味着您无需在IDE和终端之间频繁切换。
-
代码预览与调试 :Builder支持实时渲染代码效果,并在遇到错误时自动修复。例如,当运行一个React组件时发现依赖缺失,Builder会自动执行
npm install安装所需模块。 -
需求即代码转化:这是Builder的核心价值------将自然语言描述直接转化为可运行代码。您只需描述需求,Builder就能生成或重构相应的代码。
5.1.2 Builder的典型应用场景
场景一:快速生成组件代码
输入:@Builder 创建一个React Hook组件,实现表单输入验证,支持必填、邮箱格式和密码强度检查
输出:自动生成完整的useFormValidation hook,包含所有验证逻辑和错误提示场景二:自动修复语法错误
输入:@Builder 我的代码报错"Unexpected token",帮我检查并修复
输出:Builder分析错误位置,自动修复语法问题,并解释错误原因场景三:基于项目上下文优化代码
输入:@Builder 分析整个项目的性能瓶颈,给出优化建议
输出:Builder遍历所有文件,识别低效循环、冗余渲染等问题,提供具体优化方案5.2 Builder with MCP:扩展工具集成智能体
如果说Builder是"全能工匠",那么Builder with MCP就是为这个工匠配备了"万能工具箱"。MCP(Model Context Protocol)协议允许Builder调用外部工具和服务,实现跨平台协作。
5.2.1 MCP的工作原理
Builder智能体
MCP协议层
MCP工具市场
Figma连接器
数据库连接器
API服务连接器
创意工具连接器
设计稿转代码
数据模型操作
第三方API调用
多媒体素材生成
完整应用输出
5.2.2 MCP的核心能力
通过MCP协议,Builder可以:
-
连接第三方工具:从MCP市场添加各类连接器,如Figma、Supabase数据库、各类API服务等
-
自动化复杂任务:例如将Figma设计稿直接转为前端代码,或者操作Blender进行3D建模
-
增强决策能力:结合联网搜索(#Web)和文档解析(#Doc),动态获取外部知识辅助开发
5.2.3 MCP的典型应用场景
场景一:前端开发全流程自动化
输入:@Builder with MCP 连接我的Figma设计文件,将其转换为响应式React组件,并添加Tailwind样式
输出:Builder通过MCP读取Figma设计稿,分析布局和样式,生成完整的React组件代码场景二:全栈调试与数据操作
输入:@Builder with MCP 检查数据库连接,帮我调试用户登录接口返回500错误的原因
输出:Builder连接数据库查看表结构,分析后端代码,定位问题并修复场景三:创意工程与多媒体生成
输入:@Builder with MCP 为我的游戏生成一组8bit风格的音乐音效,并创建对应的图标
输出:Builder调用音乐生成接口和图标生成工具,返回可直接使用的素材文件5.3 规则定制:让AI更懂你的开发习惯
Trae最强大的功能之一是其规则定制能力。通过设置个人规则和项目规则,您可以让AI完全按照您的编码风格和团队规范工作。
5.3.1 规则设置入口
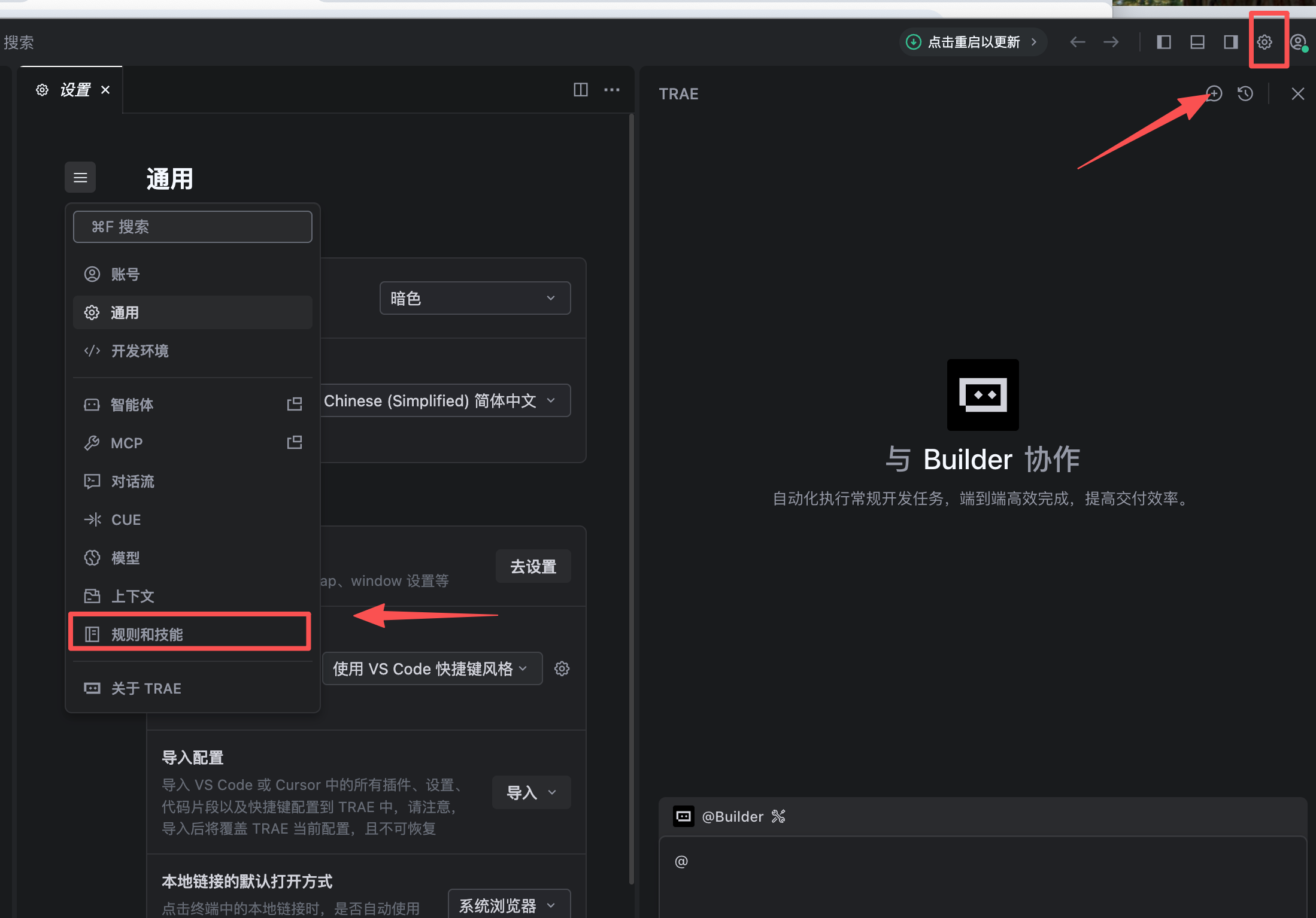
在AI对话窗口右上角点击设置图标 > 规则和技能,即可进入规则设置页面。
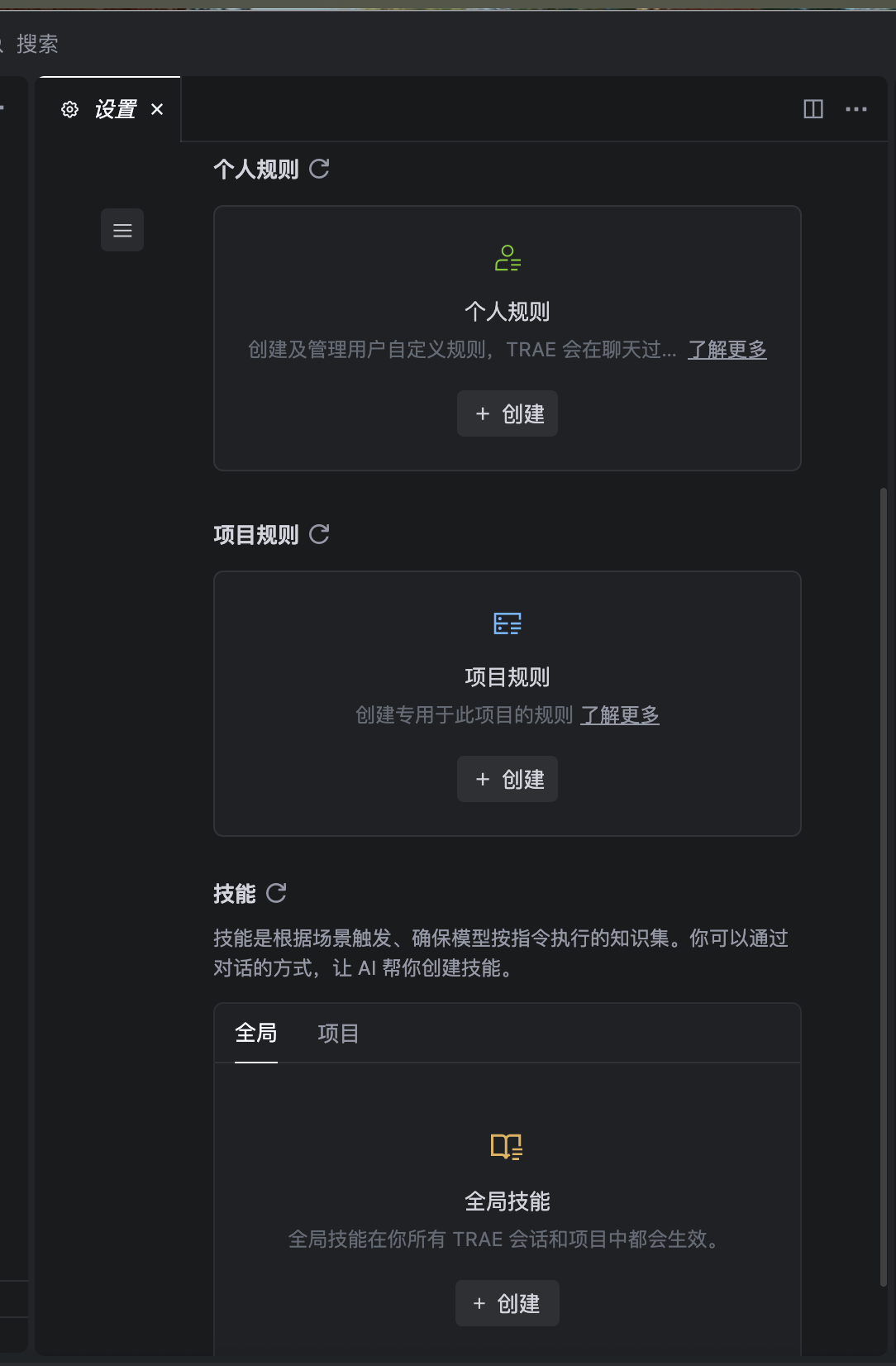
规则设置
个人规则
全局生效
项目规则
当前项目生效
语言偏好
注释习惯
命名规范
手动创建
AI自动生成
编辑.trae/rules/下的文件
自然语言描述需求
AI生成规则文件
接受/修改/重新生成
5.3.2 个人规则:全局生效的编码风格
个人规则适用于所有项目,用于定义您的编码偏好,如:
- 语言偏好:使用TypeScript而非JavaScript,使用单引号而非双引号
- 注释习惯:函数必须包含JSDoc注释,复杂逻辑需要行内注释
- 命名规范:组件使用PascalCase,工具函数使用camelCase
创建方法:
- 在"个人规则"区域点击"+创建user_rules.md"
- 在打开的Markdown文件中编写规则,保存后立即生效
个人规则示例:
markdown
# 个人编码规则
## python
1.编码规范基准
- 严格遵守 **PEP 8** 编码规范
- 代码格式化使用 **Black**(保持一致性)
- 导入排序使用 **isort**(配合Black配置)
- 代码检查使用 **flake8** 或 **pylint**
2. 函数生成规则
- 所有函数必须包含类型注解**
- 复杂逻辑必须有行内注释解释意图**5.3.3 项目规则:团队协作的规范利器
项目规则仅对当前项目生效,特别适合团队协作场景,确保所有成员遵循统一的编码规范。
手动创建步骤:
- 在"项目规则"区域点击"+创建project_rules.md"
- 系统自动在
.trae/rules/目录生成文件 - 编辑文件,保存后立即生效
AI自动创建步骤(更智能的方式):
- 输入提示词:"请在.trae/rules文件夹下,生成project_rules.md规则文件,用于Vue3项目开发规范"
- AI自动生成符合需求的规则文件
- 点击接受即可使用;如果不满意,可以手动修改或让AI重新生成
项目规则示例:
markdown
## Python项目开发规范
## 项目结构
- `src/` 存放源代码主目录
- `src/models/` 存放数据模型类
- `src/services/` 存放业务逻辑层
- `src/api/` 存放接口路由层
- `src/utils/` 存放工具函数
- `src/config/` 存放配置文件
- `tests/` 存放测试代码
- `tests/unit/` 单元测试
- `tests/integration/` 集成测试
- `scripts/` 存放辅助脚本
- `docs/` 存放项目文档
## 命名规范
- 模块/文件名:`snake_case.py`,如 `user_service.py`
- 类名:`PascalCase`,如 `UserProfile`、`DatabaseConnection`
- 函数/方法名:`snake_case`,如 `get_user_by_id()`
- 变量名:`snake_case`,如 `user_name`、`total_count`
- 常量名:`UPPER_SNAKE_CASE`,如 `MAX_RETRY_COUNT`
- 私有属性/方法:单下划线前缀 `_private_method`
## Python特定规范
- 使用 **类型注解** 声明所有函数参数和返回值
- 使用 `async/await` 处理I/O密集型操作
- 异常处理使用特定异常类型,禁止捕获 `Exception`
- 文件操作必须使用 `with` 语句确保资源释放
- 导入顺序:标准库 → 第三方库 → 本地模块(每组空一行)
## 文档规范
- 每个模块必须有模块级文档字符串
- 每个公开类/函数必须有文档字符串(Google风格)
- 复杂算法必须添加算法思路说明
- 待办事项用 `# TODO:` 标记
- 已知问题用 `# FIXME:` 标记
## 测试规范
- 使用 `pytest` 作为测试框架
- 测试文件命名:`test_模块名.py`
- 测试类命名:`TestClassName`
- 测试函数命名:`test_功能描述_场景`
- 每个测试函数只测试一个功能点
- 使用 `@pytest.fixture` 管理测试依赖5.3.4 实战案例:使用规则生成测试用例
下面通过一个完整案例,演示如何使用规则实现自动化测试用例生成。
场景:根据产品需求文档自动生成测试用例
步骤1:准备需求文档
在资源管理器中新建文件夹,创建.md文件,将产品需求文档内容复制进去
markdown
# 用户登录功能需求文档
## 功能描述
用户可以通过邮箱和密码登录系统,登录成功后跳转到仪表盘页面
## 验证规则
- 邮箱必填,必须符合邮箱格式
- 密码必填,长度6-20位
- 连续5次登录失败,账号锁定30分钟
## 预期行为
- 登录成功:返回用户信息,跳转仪表盘
- 登录失败:显示具体错误提示
- 账号锁定:显示剩余解锁时间步骤2:创建测试用例生成规则
通过AI自动创建规则文件:
输入:请在.trae/rules文件夹下,生成测试用例生成规则文件,用于根据需求文档生成完整的测试用例AI生成的规则文件可能包含:
markdown
# 测试用例生成规则
## 输出格式
- 使用Markdown表格格式
- 包含字段:用例ID、测试场景、前置条件、测试步骤、预期结果、实际结果、状态
## 测试覆盖要求
- 必须包含正向测试用例
- 必须覆盖所有异常场景
- 必须包含边界值测试
- 必须包含安全性测试
## 命名规范
- 用例ID格式:MODULE_XXX_YYY(模块_功能_序号)
- 测试场景描述简洁明确步骤3:引用文档生成测试用例
在AI对话窗口中,使用#引用需求文档和规则文档,然后发送指令:
请根据引用的需求文档,按照测试规则生成完整的测试用例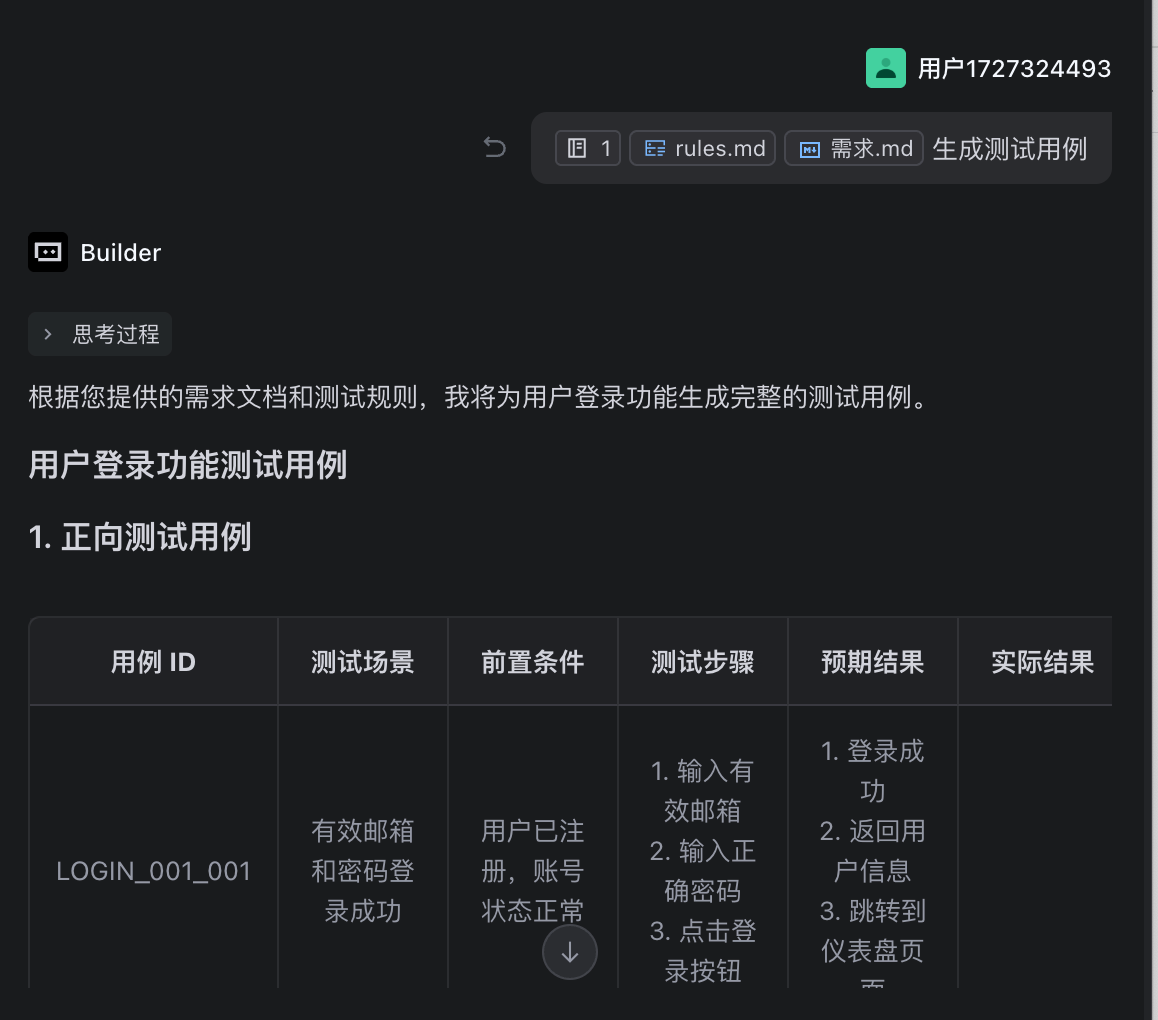
步骤4:生成结果展示
AI将输出结构化的测试用例表格:
用户登录功能测试用例
1. 正向测试用例
| 用例 ID | 测试场景 | 前置条件 | 测试步骤 | 预期结果 | 实际结果 | 状态 |
|---|---|---|---|---|---|---|
| LOGIN_001_001 | 有效邮箱和密码登录成功 | 用户已注册,账号状态正常 | 1. 输入有效邮箱 2. 输入正确密码 3. 点击登录按钮 | 1. 登录成功 2. 返回用户信息 3. 跳转到仪表盘页面 | ||
| LOGIN_001_002 | 邮箱大小写混合登录 | 用户已注册,账号状态正常 | 1. 输入大小写混合的邮箱 2. 输入正确密码 3. 点击登录按钮 | 1. 登录成功 2. 邮箱不区分大小写 |
2. 异常场景测试用例
| 用例 ID | 测试场景 | 前置条件 | 测试步骤 | 预期结果 | 实际结果 | 状态 |
|---|---|---|---|---|---|---|
| LOGIN_002_001 | 邮箱为空 | 无 | 1. 邮箱留空 2. 输入密码 3. 点击登录按钮 | 显示提示:"邮箱不能为空" | ||
| LOGIN_002_002 | 密码为空 | 无 | 1. 输入邮箱 2. 密码留空 3. 点击登录按钮 | 显示提示:"密码不能为空" | ||
| LOGIN_002_003 | 邮箱格式不正确 | 无 | 1. 输入无效格式邮箱(如:test@) 2. 输入密码 3. 点击登录按钮 | 显示提示:"邮箱格式不正确" | ||
| LOGIN_002_004 | 密码长度小于 6 位 | 无 | 1. 输入有效邮箱 2. 输入 5 位密码 3. 点击登录按钮 | 显示提示:"密码长度必须在 6-20 位之间" | ||
| LOGIN_002_005 | 密码长度大于 20 位 | 无 | 1. 输入有效邮箱 2. 输入 21 位密码 3. 点击登录按钮 | 显示提示:"密码长度必须在 6-20 位之间" | ||
| LOGIN_002_006 | 用户不存在 | 无 | 1. 输入未注册的邮箱 2. 输入任意密码 3. 点击登录按钮 | 显示提示:"用户不存在" | ||
| LOGIN_002_007 | 密码错误 | 用户已注册 | 1. 输入有效邮箱 2. 输入错误密码 3. 点击登录按钮 | 显示提示:"密码错误" | ||
| LOGIN_002_008 | 账号已被锁定 | 账号因连续失败已被锁定 | 1. 输入有效邮箱 2. 输入正确密码 3. 点击登录按钮 | 显示提示:"账号已锁定,请在 XX 分钟后重试" |
3. 边界值测试用例
| 用例 ID | 测试场景 | 前置条件 | 测试步骤 | 预期结果 | 实际结果 | 状态 |
|---|---|---|---|---|---|---|
| LOGIN_003_001 | 密码长度为 6 位(最小值) | 用户已注册,密码为 6 位 | 1. 输入有效邮箱 2. 输入 6 位正确密码 3. 点击登录按钮 | 登录成功 | ||
| LOGIN_003_002 | 密码长度为 20 位(最大值) | 用户已注册,密码为 20 位 | 1. 输入有效邮箱 2. 输入 20 位正确密码 3. 点击登录按钮 | 登录成功 | ||
| LOGIN_003_003 | 邮箱长度最小值 | 用户已注册 | 1. 输入最短有效邮箱 2. 输入正确密码 3. 点击登录按钮 | 登录成功 | ||
| LOGIN_003_004 | 邮箱长度最大值 | 用户已注册 | 1. 输入最长有效邮箱 2. 输入正确密码 3. 点击登录按钮 | 登录成功 | ||
| LOGIN_003_005 | 连续登录失败 4 次 | 账号状态正常 | 1. 连续 4 次输入错误密码 2. 第 5 次输入正确密码 | 第 5 次登录成功,账号未被锁定 | ||
| LOGIN_003_006 | 连续登录失败 5 次触发锁定 | 账号状态正常 | 1. 连续 5 次输入错误密码 2. 第 6 次输入正确密码 | 第 6 次登录失败,显示账号锁定提示 | ||
| LOGIN_003_007 | 锁定 30 分钟后自动解锁 | 账号已被锁定 | 1. 等待 30 分钟 2. 输入正确密码 3. 点击登录按钮 | 登录成功,账号已解锁 | ||
| LOGIN_003_008 | 锁定 29 分钟时尝试登录 | 账号已被锁定 | 1. 等待 29 分钟 2. 输入正确密码 3. 点击登录按钮 | 登录失败,显示剩余解锁时间 |
4. 安全性测试用例
| 用例 ID | 测试场景 | 前置条件 | 测试步骤 | 预期结果 | 实际结果 | 状态 |
|---|---|---|---|---|---|---|
| LOGIN_004_001 | SQL 注入攻击防护 | 无 | 1. 邮箱输入:' OR '1'='1 2. 输入任意密码 3. 点击登录按钮 |
登录失败,不暴露数据库信息 | ||
| LOGIN_004_002 | XSS 脚本注入防护 | 无 | 1. 邮箱输入:<script>alert('xss')</script>@test.com 2. 输入密码 3. 点击登录按钮 |
登录失败,脚本不执行 | ||
| LOGIN_004_003 | 密码传输加密 | 无 | 1. 输入邮箱和密码 2. 抓包查看请求数据 | 密码以加密形式传输,不可见明文 | ||
| LOGIN_004_004 | 登录失败次数记录 | 无 | 1. 连续 3 次登录失败 2. 检查系统记录 | 系统正确记录失败次数为 3 | ||
| LOGIN_004_005 | 锁定时间精确计算 | 账号已被锁定 | 1. 查看账号锁定时间 2. 计算剩余解锁时间 | 显示的剩余时间与实际情况一致 | ||
| LOGIN_004_006 | 会话令牌安全性 | 登录成功 | 1. 登录成功后获取会话令牌 2. 验证令牌有效性 | 令牌有效且具备合理的过期时间 | ||
| LOGIN_004_007 | 重复提交防护 | 无 | 1. 快速多次点击登录按钮 | 只处理一次登录请求,不重复提交 | ||
| LOGIN_004_008 | 敏感信息不记录日志 | 登录失败 | 1. 查看系统日志 | 日志中不包含密码等敏感信息 |
5. 特殊场景测试用例
| 用例 ID | 测试场景 | 前置条件 | 测试步骤 | 预期结果 | 实际结果 | 状态 |
|---|---|---|---|---|---|---|
| LOGIN_005_001 | 网络超时处理 | 无 | 1. 模拟网络超时 2. 点击登录按钮 | 显示"网络连接超时,请重试" | ||
| LOGIN_005_002 | 服务器错误处理 | 无 | 1. 模拟服务器 500 错误 2. 点击登录按钮 | 显示"服务器错误,请稍后重试" | ||
| LOGIN_005_003 | 多设备同时登录 | 无 | 1. 同一账号在两个设备同时登录 | 两个设备都能成功登录 | ||
| LOGIN_005_004 | 登录后刷新页面 | 已登录成功 | 1. 登录成功后刷新页面 | 保持登录状态,不退出 | ||
| LOGIN_005_005 | 登录后点击浏览器后退按钮 | 已登录成功 | 1. 登录成功后点击后退 | 不返回登录页面或重新提交表单 |
测试用例统计:
- 正向测试用例:2 个
- 异常场景测试用例:8 个
- 边界值测试用例:8 个
- 安全性测试用例:8 个
- 特殊场景测试用例:5 个
- 总计:31 个测试用例
所有测试用例已按照规则要求生成,覆盖了正向流程、异常处理、边界条件、安全性等各个方面。
六、进阶技巧与最佳实践
6.1 高效使用Builder的指令设计
要让Builder发挥最大效能,指令设计至关重要。以下是一个优秀的指令模板:
【指令结构】
@Builder [任务类型] + [具体需求] + [约束条件] + [输出格式]
【示例】
@Builder 创建一个Node.js脚本,实现以下功能:
1. 读取当前目录下的所有CSV文件
2. 合并所有CSV文件内容
3. 输出合并后的JSON文件
要求:使用fs模块,添加错误处理,提供进度日志
输出:生成完整的脚本代码,并添加详细注释6.2 规则复用与团队共享
Trae支持规则的导入导出,您可以:
- 将团队规范导出为模板,新成员一键导入
- 在不同项目间复用相似的规则配置
- 在社区分享自己的规则文件,获取他人优化建议
6.3 性能优化建议
在使用Builder进行大型项目开发时,可以遵循以下建议:
- 分阶段开发:将大型需求拆分为多个小任务,逐步完成
- 善用项目上下文 :通过
#Workspace引用整个项目,让AI理解全局 - 定期清理对话:长时间对话可能影响响应速度,适时开启新对话
- 合理使用快速请求:付费用户拥有600次快速请求,复杂任务使用快速请求,简单任务使用慢速请求
七、未来展望与总结
7.1 从"按次计费"到"按Token计费"的行业趋势
2026年2月,Trae调整计费方案,标志着AI编程工具从"补贴推广期"迈向"价格发现年"。背后的逻辑是:
- Agent模式消耗激增:一次复杂任务可能消耗百万级Token(读取上下文、反复思考)
- 算力成本真实化:厂商不再愿意为海量Context消耗买单
对于开发者而言,这意味着需要从"只会问怎么写代码"的低级使用者,进化为"懂得如何用最少Token换取最大产出"的高级使用者。
7.2 总结
Trae作为字节跳动推出的AI原生IDE,凭借强大的模型支持(Claude/GPT/豆包/DeepSeek)、深度的代码理解能力和友好的中文界面,正在成为开发者不可或缺的生产力工具。
其核心技术------代码语义索引,通过将代码转化为"实体+关系"的结构化数据,让编辑器从"文本编辑器"升级为"语义编辑器",实现了真正的智能感知。
无论您是初学编程的小白,还是经验丰富的专业开发者,Trae都能帮助您将注意力从重复编码中解放出来,专注于业务逻辑设计与用户体验优化。在这个AI编程的新时代,掌握Trae这样的工具,就是掌握了未来的竞争力。