1. 什么是 Alembic,为什么需要它?
Alembic 是由 SQLAlchemy 的作者 Mike Bayer 编写的数据库迁移工具。你可以把它理解成「数据库的 Git」------它跟踪数据库结构(Schema)的变化,让你可以在不同版本之间前进和后退。
没有 Alembic 时的痛点
假设你在开发一个博客项目,一开始 users 表只有 id 和 name,后来需要加一个 email 字段。你可能会:
- 手动登录数据库执行
ALTER TABLE users ADD COLUMN email VARCHAR(255); - 告诉团队成员「记得去改一下数据库」
- 生产环境上线时再手动执行一遍
这种方式的问题显而易见:容易遗漏、无法追踪、无法回滚。
有了 Alembic 之后
- 所有数据库结构的变更都以 迁移脚本 的形式保存在代码仓库中
- 团队成员只需执行一条命令
alembic upgrade head即可同步最新结构 - 可以随时 回滚 到任意历史版本
- 支持自动检测 SQLAlchemy Model 的变化,自动生成迁移脚本
2. 安装与初始化
安装
pip install alembic sqlalchemy如果你使用 PostgreSQL:
php
pip install psycopg2-binary初始化 Alembic 环境
在项目根目录下执行以下命令完成初始化:
csharp
alembic init alembic执行后,项目目录结构如下:
bash
myproject/
├── alembic/
│ ├── env.py # 核心配置脚本,每次运行迁移都会执行
│ ├── README
│ ├── script.py.mako # 迁移脚本的模板文件
│ └── versions/ # 存放所有迁移版本文件的目录
│ └── (这里会生成迁移脚本)
├── alembic.ini # Alembic 的主配置文件
└── app/
└── models.py # 你的 SQLAlchemy 模型理解各个文件的作用
alembic.ini --- 主配置文件,主要配置数据库连接 URL:
ini
[alembic]
# 迁移脚本存放位置
script_location = alembic
# 数据库连接 URL
sqlalchemy.url = sqlalchemy.url = postgresql+psycopg2://username:password@db_ip:5432/db_name
# 省略其他...env.py --- 这是 Alembic 的核心运行脚本。每次你执行任何 alembic 命令,这个文件都会被执行。它负责:
- 建立数据库连接
- 配置迁移上下文
- 区分「在线模式」(直接执行 SQL)和「离线模式」(生成 SQL 文件)
versions/ --- 存放所有迁移文件。文件名格式类似 3512b954651e_add_users_table.py,使用部分 GUID 而非递增整数来命名,这样可以更好地支持分支合并。
3. 基本使用
3.1 创建你的第一个 Model
先创建一个简单的 SQLAlchemy 模型文件:
ini
# app/models.py
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy.orm import declarative_base
import datetime
Base = declarative_base()
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
name = Column(String(50), nullable=False)
email = Column(String(200), nullable=False, unique=True)
created_at = Column(DateTime, default=datetime.datetime.utcnow)3.2 将Model 与 Alembic关联
修改 alembic/env.py,让 Alembic 知道你的 Model 在哪里:
python
# alembic/env.py 中找到这行:
# target_metadata = None
# 替换为:
import sys
import os
from app.models import Base # 导入你的 Base
target_metadata = Base.metadata # 告诉 Alembic 用哪个 metadata 来检测变化
# 或 target_metadata = [Base.metadata, ]💡 新手常见错误 :忘记把
target_metadata = None改成你的Base.metadata,导致自动生成的迁移脚本是空的。
3.3 创建第一个迁移脚本
css
alembic revision --autogenerate-m "create users table"执行后,alembic/versions/ 目录下会生成类似这样的文件:
python
# alembic/versions/673707e9f34b_create_users_table.py
"""create users table
Revision ID: 673707e9f34b
Revises:
Create Date: 2026-03-20 08:57:19.170729
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
# 版本标识,Alembic 用这个来追踪当前在哪个版本
revision: str = '673707e9f34b'
down_revision: Union[str, Sequence[str], None] = None # 前一个版本的 revision ID, None 表示这是第一个迁移
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('users',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('name', sa.String(length=50), nullable=False),
sa.Column('email', sa.String(length=200), nullable=False),
sa.Column('created_at', sa.DateTime(), nullable=True),
sa.PrimaryKeyConstraint('id'),
sa.UniqueConstraint('email')
)
op.create_index(op.f('ix_users_id'), 'users', ['id'], unique=False)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_index(op.f('ix_users_id'), table_name='users')
op.drop_table('users')
# ### end Alembic commands ###每个迁移脚本包含两个函数:
upgrade()--- 应用变更(往新版本走)downgrade()--- 撤销变更(往旧版本退)
3.4 执行迁移(升级到最新版本)
bash
alembic upgrade headhead 表示升级到最新版本。执行后,Alembic 会:
- 连接数据库
- 检查
alembic_version表(首次运行时自动创建),确认当前所处的版本 - 依次执行所有尚未应用的迁移脚本中的
upgrade()函数
如果你想升级到某个特定版本:
bash
alembic upgrade 3512b954651e # Revision ID或者升级 N 步:
alembic upgrade +23.5 回滚迁移
回滚到上一个版本:
alembic downgrade -1回滚到某个特定版本:
arduino
alembic downgrade 3512b954651e # alembic downgrade 3512b954651e回滚到最初状态(撤销所有迁移):
csharp
alembic downgrade base4. 自动生成迁移脚本(autogenerate)
手动编写迁移脚本很麻烦,Alembic 的杀手锏功能是 自动生成(autogenerate) 。
其工作原理是:将你的 SQLAlchemy Model 定义(目标状态)与数据库中实际的表结构(当前状态)进行比对,自动生成一个描述两者「差异」的迁移脚本。
使用示例
假设你在 user.py 中新增了一个 phone 字段:
ini
# app/models/User.py
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy.orm import declarative_base
import datetime
Base = declarative_base()
class User(Base):
__tablename__ = "users" # 命名约束,定义表名,建议添加
id = Column(Integer, primary_key=True, index=True)
name = Column(String(50), nullable=False)
email = Column(String(200), nullable=False, unique=True)
phone = Column(String(20), nullable=False, unique=True) # 新增phone字段
created_at = Column(DateTime, default=datetime.datetime.utcnow)然后执行自动生成命令:
css
alembic revision --autogenerate -m "add phone field to user table" Alembic 会自动生成:
python
# alembic/versions/7f29ab2b2004_add_phone_field_to_user_table.py
"""add phone field to user table
Revision ID: 7f29ab2b2004
Revises: 673707e9f34b
Create Date: 2026-03-20 09:12:51.346000
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision: str = '7f29ab2b2004'
down_revision: Union[str, Sequence[str], None] = '673707e9f34b'
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.add_column('users', sa.Column('phone', sa.String(length=20), nullable=False))
op.create_unique_constraint(None, 'users', ['phone'])
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint(None, 'users', type_='unique')
op.drop_column('users', 'phone')
# ### end Alembic commands ###最后执行升级命令使变更生效:
bash
alembic upgrade head查看当前版本和历史
查看当前数据库所在的版本:
sql
alembic current输出示例
scss
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
7f29ab2b2004 (head)查看所有迁移历史:
bash
alembic history输出示例:
sql
673707e9f34b -> 7f29ab2b2004 (head), add phone field to user table
<base> -> 673707e9f34b, create users tableautogenerate 能检测哪些变化?
默认支持检测✅
- 新增 / 删除表
- 新增 / 删除列
- 列的 nullable 状态变化
- 基本索引变化
- 显式命名的唯一约束变化
- 基本外键约束变化
无法检测 ❌
| 变化类型 | 原因 |
|---|---|
| 表名重命名 | 会被识别为「删除旧表 + 新建新表」,需手动改成 rename 操作 |
| 列名重命名 | 同上,会被识别为「删除旧列 + 新增新列」,直接导致数据丢失 |
| 匿名约束 | 没有名字的约束无法被可靠追踪 |
| 不原生支持 ENUM 的数据库上的枚举类型 | SQLite 等数据库用 CHAR + CHECK 模拟枚举,Alembic 无法从反射结果中判断这是否是一个枚举 |
| 存储过程、函数、触发器等 | 超出 Alembic 的管理范围 |
💡 自动生成的迁移脚本永远不是 100% 完美的,每次生成后都必须人工审核! 这是官方文档明确强调的原则,autogenerate 的目标是「辅助」而非「替代」人工判断。
5.结合Fastapi + SQLModel使用
SQLModel是为FastApi设计的与数据库交互的库,基于 Python 类型注解,并由 Pydantic 和 SQLAlchemy 驱动。
1. 安装依赖
css
pip install fastapi[standard] sqlmodel2. 定义模型
python
# app/models/User.py
from sqlmodel import SQLModel, Field
from datetime import datetime, timezone
class UserBase(SQLModel):
"""
用户基础模型
公共字段基类,被 Create / Response 等 Schema 复用
"""
name: str = Field(index=True, description="用户名")
email: str = Field(index=True, unique=True, description="用户邮箱")
created_at: datetime = Field(lambda: datetime.now(timezone.utc), description="创建时间")
class User(UserBase, table=True):
"""
用户模型
映射数据库表 users
"""
__tablename__ = "users"
id: int = Field(default=None, primary_key=True)
# request schema
class UserCreate(UserBase):
"""
创建用户的请求体
"""
pass
# response schema
class UserRead(UserBase):
"""
返回给前端的响应体
"""
id: int3. 修改迁移脚本模板文件
script.py.mako 是所有迁移脚本的模板文件。由于 SQLModel 生成的迁移脚本默认不会导入 sqlmodel 模块,但生成的脚本内容通常又依赖它,因此推荐在模板中统一添加这个导入,避免每次生成后都要手动修改。
python
# alembic/script.py.mako
# 添加 **import sqlmodel**
**"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
Create Date: ${create_date}
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
import sqlmodel # 新增代码
${imports if imports else ""}
# revision identifiers, used by Alembic.
revision: str = ${repr(up_revision)}
down_revision: Union[str, Sequence[str], None] = ${repr(down_revision)}
branch_labels: Union[str, Sequence[str], None] = ${repr(branch_labels)}
depends_on: Union[str, Sequence[str], None] = ${repr(depends_on)}
def upgrade() -> None:
"""Upgrade schema."""
${upgrades if upgrades else "pass"}
def downgrade() -> None:
"""Downgrade schema."""
${downgrades if downgrades else "pass"}**4. 配置 env.py
ini
from app.models.User import User
target_metadata = [
User.metadata,
]
# 省略其他5.生成迁移脚本
css
alembic revision --autogenerate -m "create users table"生成的迁移脚本如下:
python
"""create users table
Revision ID: 54b2d338fcc9
Revises:
Create Date: 2026-03-20 10:11:18.524007
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
import sqlmodel # 如果不修改mako文件,这里需要手动引入sqlmodel
# revision identifiers, used by Alembic.
revision: str = '54b2d338fcc9'
down_revision: Union[str, Sequence[str], None] = None
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('users',
sa.Column('name', sqlmodel.sql.sqltypes.AutoString(), nullable=False),
sa.Column('email', sqlmodel.sql.sqltypes.AutoString(), nullable=False),
sa.Column('created_at', sa.DateTime(), nullable=False),
sa.Column('id', sa.Integer(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
op.create_index(op.f('ix_users_email'), 'users', ['email'], unique=True)
op.create_index(op.f('ix_users_name'), 'users', ['name'], unique=False)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_index(op.f('ix_users_name'), table_name='users')
op.drop_index(op.f('ix_users_email'), table_name='users')
op.drop_table('users')
# ### end Alembic commands ###6. 多环境管理
实际项目中,通常需要分别管理本地开发、预发布(staging)和生产(production)三套环境的数据库,每套环境都有各自独立的连接配置和迁移历史。Alembic 支持通过 -n 参数指定目标环境来实现这一需求。
1. 修改alembic.ini
ini
[alembic]
script_location = alembic/local
sqlalchemy.url = postgresql+psycopg2://username:paasowrd@local_db_ip:5432/local_db_name
[staging]
script_location = alembic/staging
sqlalchemy.url = postgresql+psycopg2://username:paasowrd@staging_db_ip:5432/staging_db_name
[production]
script_location = alembic/production
sqlalchemy.url = postgresql+psycopg2://username:paasowrd@production_db_ip:5432/production_db_ip_name
[DEFAULT]
prepend_sys_path = .
version_path_separator = os
# 省略其他配置2. 初始化alembic环境
bash
alembic init alembic/local
alembic -n staging init alembic/staging
alembic -n production init alembic/production生成的目录结构如下
bash
your_project/
├── alembic/
│ ├── local/
│ │ └── versions/
│ ├── production/
│ │ └── versions/
│ └── staging/
│ └── versions/
├── app/
│ └── models/
└── alembic.ini3. 针对不同环境执行迁移
bash
# local(默认环境,无需 -n 参数)
alembic revision --autogenerate -m "add users table"
alembic upgrade head
# staging
alembic -n staging revision --autogenerate -m "add users table"
alembic -n staging upgrade head
# production
alembic -n production revision --autogenerate -m "add users table"
alembic -n production upgrade head7. 生产环境最佳实践
1. 迁移前务必备份数据库
在对生产数据库执行任何迁移之前,应当先完整备份,以防迁移失败时可以快速恢复。
perl
# 全量备份
pg_dump -U postgres -F c -v -f test_db_$(date +%Y%m%d_%H%M%S).backup test_db
# 若需要恢复
psql -U postgres -c "CREATE DATABASE test_db_restore;"
pg_restore -U postgres -d test_db_restore -v --clean test_db_20260320_031055.backup2. 生产环境的数据库 URL 不应硬编码在配置文件中
将数据库连接地址明文写入 alembic.ini 存在安全隐患,推荐改用 pydantic_settings 从环境变量中读取。
第一步:删除 alembic.ini 中的 sqlalchemy.url
ini
# 删除sqlalchemy.url
[production]
script_location = alembic/production第二步:新增 pydantic 配置文件
arduino
# app/core/settings.py
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
DATABASE_URL: str
settings = Settings()第三步:修改 production 的 env.py
python
# alembic/production/env.py
from app.core.settings import settings
# 使用环境变量里的databse url配置
config.set_main_option("sqlalchemy.url", settings.DATABASE_URL) 第四步:设置环境变量后再执行迁移命令
bash
# 设置迁URL后再执行迁移命令
export DATABASE_URL="你的DATABSE_URL"
alembic -n production revision --autogenerate -m "create users table"8. 枚举类型的正确处理方式
枚举(Enum)字段的迁移处理是一个容易踩坑的地方,值得单独说明。
为什么不推荐 PostgreSQL 原生 Enum?
Alembic 虽然支持 PostgreSQL 的原生 Enum 类型,但实际使用中存在以下问题:
- PostgreSQL 原生枚举类型只能追加值,不能删除
- 如果需要修改枚举值,只能重建整个枚举类型,操作繁琐
- Alembic 无法自动识别枚举值的变化,需要完全手动处理迁移脚本
python
# app/models/User.py
from enum import Enum
from sqlmodel import SQLModel, Field
from datetime import datetime, timezone
class UserStatus(str, Enum):
"""用户状态枚举"""
ACTIVE = "active"
BANNED = "banned"
DELETED = "deleted"
class UserBase(SQLModel):
# 省略其他
status: UserStatus = Field(default=UserStatus.ACTIVE, description="用户状态") # 使用原生Enum,❌不推荐推荐方案:varchar + CHECK 约束
使用 sa_column 将字段定义为 varchar 类型,并通过 CHECK 约束限制合法值范围。这样 Alembic 就能检测到枚举值的变化并自动生成迁移脚本。
ini
# app/models/User.py
from sqlalchemy import Column, Enum as SaEnum
class UserBase(SQLModel):
status: UserStatus | None = Field(
default=None,
description="用户状态",
sa_column=Column(SaEnum(
UserStatus,
name="user_status",
create_constraint=True,
native_enum=False,
nullable=True
))
)
# 省略其他生成的迁移脚本如下:
python
# alembic/production/versions/568f7d9f2553_change_status_field.py
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.add_column(
'users',
sa.Column(
'status',
sa.Enum('ACTIVE', 'BANNED', 'DELETED',
name='user_status',
native_enum=False,
create_constraint=True
),
nullable=True
)
)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_column('users', 'status')
# ### end Alembic commands ###查看 users 表的约束,可以看到 status 字段类型为 varchar,并关联了名为 user_status 的 CHECK 约束。
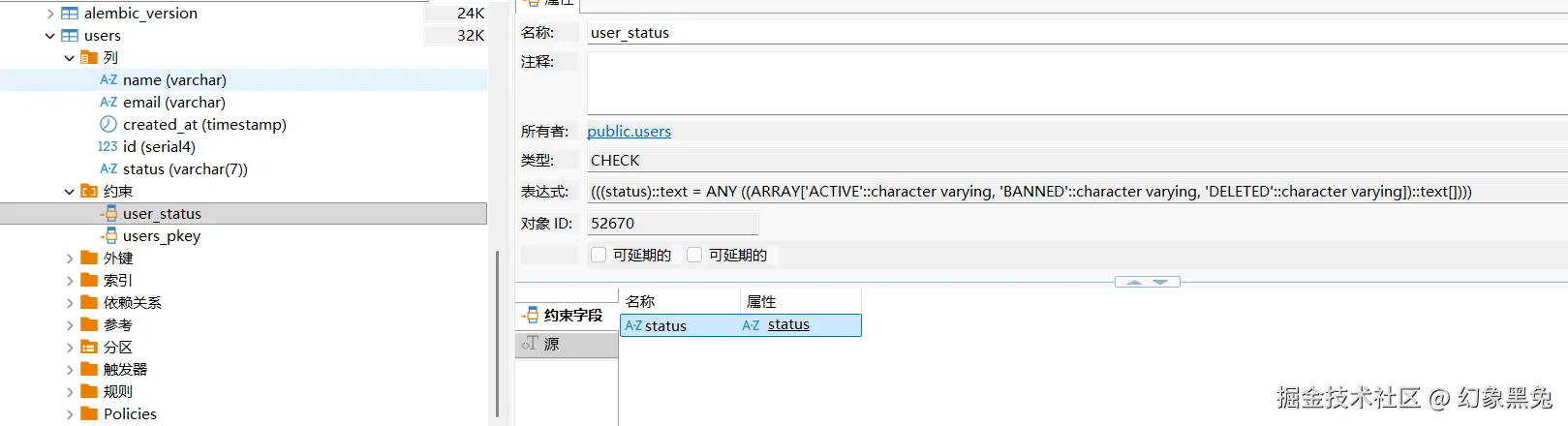
这种方案最大的优势是:当你修改 UserStatus 枚举时,Alembic 能够自动识别变化并生成对应的迁移脚本。
场景一:新增枚举值
python
# app/models/User.py
class UserStatus(str, Enum):
"""用户状态枚举"""
ACTIVE = "active"
BANNED = "banned"
DELETED = "deleted"
IN_ACTIVE = "in_active" # 新增自动生成的迁移脚本如下:
python
# alembic/production/versions/568f7d9f2553_change_status_field.py
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.alter_column('users', 'status',
existing_type=sa.VARCHAR(length=7),
type_=sa.Enum('ACTIVE', 'BANNED', 'DELETED', 'IN_ACTIVE', name='user_status', native_enum=False, create_constraint=True),
existing_nullable=True)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.alter_column('users', 'status',
existing_type=sa.Enum('ACTIVE', 'BANNED', 'DELETED', 'IN_ACTIVE', name='user_status', native_enum=False, create_constraint=True),
type_=sa.VARCHAR(length=7),
existing_nullable=True)
# ### end Alembic commands ###注意:直接执行上述脚本会报错:
sql
sqlalchemy.exc.ProgrammingError: (psycopg2.errors.DuplicateObject) constraint "user_status" for relation "users" already exists原因是 Alembic 在 alter_column 时会尝试重新创建 CHECK 约束,但旧的约束还未删除。需要手动在脚本中先删除旧约束:
python
# alembic/production/versions/568f7d9f2553_change_status_field.py
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check') # 手动添加:先删除旧约束
op.alter_column('users', 'status',
existing_type=sa.VARCHAR(length=7),
type_=sa.Enum('ACTIVE', 'BANNED', 'DELETED', 'IN_ACTIVE', name='user_status', native_enum=False, create_constraint=True),
existing_nullable=True)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check') # # 手动添加:先删除旧约束
op.alter_column('users', 'status',
existing_type=sa.Enum('ACTIVE', 'BANNED', 'DELETED', 'IN_ACTIVE', name='user_status', native_enum=False, create_constraint=True),
type_=sa.VARCHAR(length=7),
existing_nullable=True)
# ### end Alembic commands ###场景二:修改已有枚举值
💡 Alembic 只能检测枚举结构的增删变化(新增或删除某个枚举值),对于修改枚举值本身 (如将
BANNED改为DISABLED)则无法感知,需要完全手动编写迁移脚本。
python
# app/models/User.py
class UserStatus(str, Enum):
"""用户状态枚举"""
ACTIVE = "active"
DISABLED = "disabled" # 将BANNED修改为DISABLED
DELETED = "deleted"
IN_ACTIVE = "in_active"对于这类情况,需要手动编写迁移脚本,包括:先删除旧约束、更新现有数据中的历史枚举值、再创建新约束:
python
# alembic/productionversions/0d46a300af09_change_status_banned_to_disabled.py
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check')
op.execute("UPDATE users SET status = 'IN_ACTIVE' WHERE status = 'IS_ACTIVE'")
op.execute("UPDATE users SET status = 'DISABLED' WHERE status = 'BANNED'")
op.create_check_constraint(
'user_status', 'users',
"status IN ('ACTIVE', 'DISABLED', 'DELETED', 'IN_ACTIVE')"
)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint('user_status', 'users', type_='check')
op.execute("UPDATE users SET status = 'BANNED' WHERE status = 'DISABLED'")
op.create_check_constraint(
'user_status', 'users',
"status IN ('ACTIVE', 'BANNED', 'DELETED', 'IN_ACTIVE')"
)
# ### end Alembic commands ###
```Alembic入门教程