@toc ## 摘要 本周阅读了论文AutoRegressive Image Generation With Randomized Parallel Decoding(ARPG)和Attention Distillation: A Unified Approach to Visual Characteristics Transfer两篇论文,借鉴其中的思想,来解决自己的问题。 ## Abstract This week, I read two papers: "AutoRegressive Image Generation With Randomized Parallel Decoding (ARPG)" and "Attention Distillation: A Unified Approach to Visual Characteristics Transfer". I drew inspiration from the ideas presented in these papers to address my own problems.
- AutoRegressive Image Generation With Randomized Parallel Decoding(ARPG)
将随机自回归和生成分成两阶段
关键:
1、查询时需要明确的位置引导。
2、掩码建模的训练效率低 ,比如BERT,一句话mask掉一些单词,借助上下文进行预测,原本的输入由于mask,割裂了两个连续词之间的相关性,mask掉的词是预测的目标,这些词之间也没有很大的相关性。
3、关注到masktoken是多余的,未掩码的部分才是真正该注意的位置,mask之间的关注是浪费的,RandAR的输入是cls,pos_inst,t,...,pos_inst,t。
于是就拆分成两个阶段
1、打乱输入的图片和对应的位置编码,然后输入自回归模型得到图片k、v特征。
2、用query和kv来计算交叉注意力得到生成的图片。
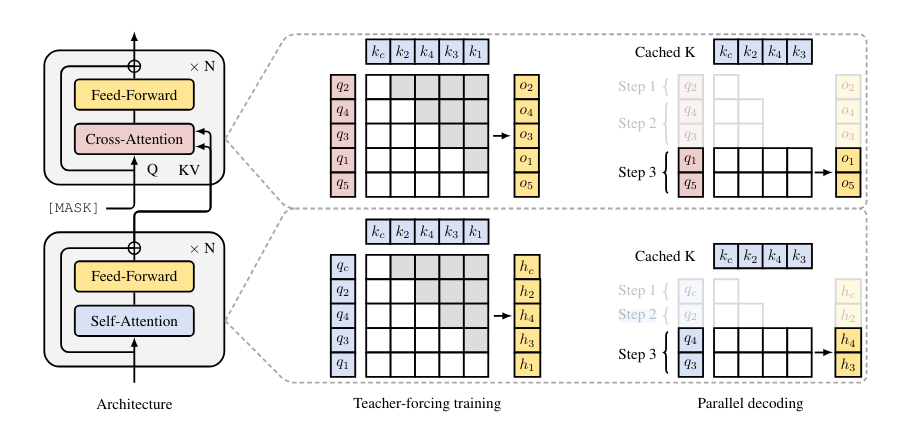
示意图
- Attention Distillation: A Unified Approach to Visual Characteristics Transfer
关键假设:kv特征代表了图像的视觉外观,kv替换可以实现外观转移。
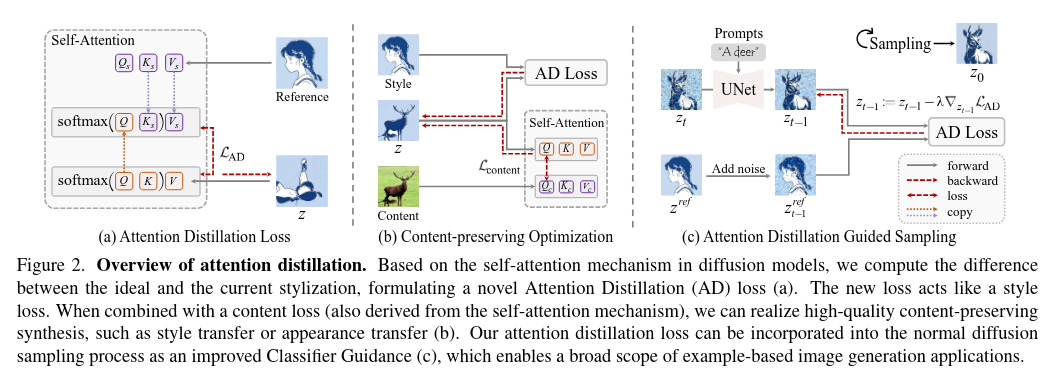
示意图
a、对参考图进行自注意力操作得到K_s,V_s,然后一个随机噪声z开始去噪生成,每一步去噪都会计算当前的QKV,然后计算KV与K_s、V_s的损失。
b、对需要迁移的图片计算Q_c、K_c、V_c,然后在噪声z去噪的时候使用内容损失来保证迁移的过程不丢失内容。
c、注意力蒸馏引导采样通过在扩散采样的每一步用AD Loss微调潜变量z,实现了快速、高质量的风格迁移,同时保持了扩散模型的灵活性和可控性。
当前任务:用文本rec2替换img1内原有的文本rec1,形成img2.
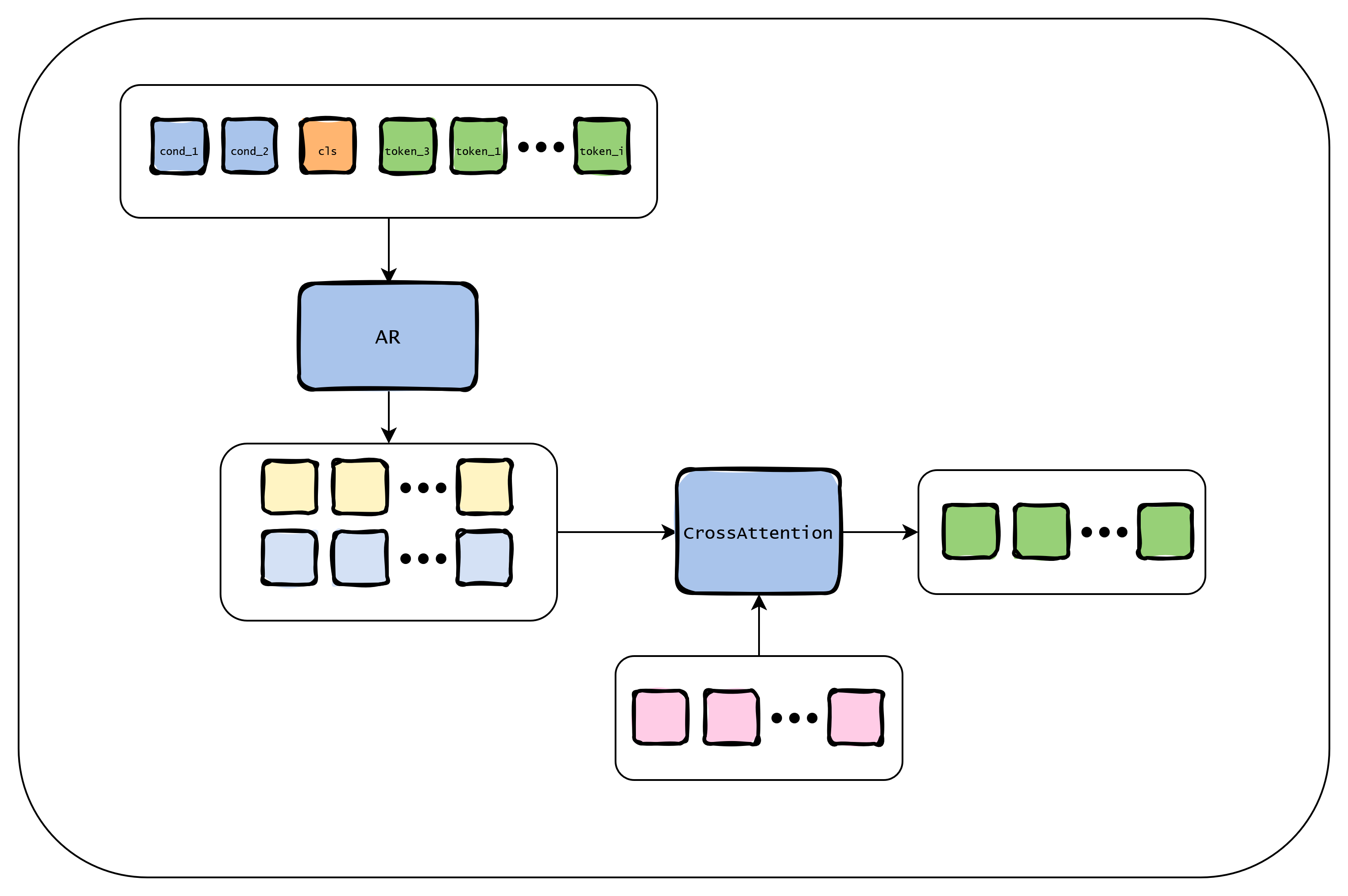
示意图
rec2作为条件参与自回归,mask掩码不掩盖rec2区域,第二阶段的query为空白mask查询。
缺点:解释性差,Q的来源复杂,原图中包含了视觉文本,rec2提供了语义文本。
优点:不需要构造一个麻烦的查询,rec2在自回归中融合。
需要去掉视觉文本的干扰,但是又希望留下视觉文本的风格、颜色、位置等信息,现有监督项不能很好的解决这个问题。
现有条件是:img1和img2只有文本部分的内容不一致,其余的风格、背景是一致的。
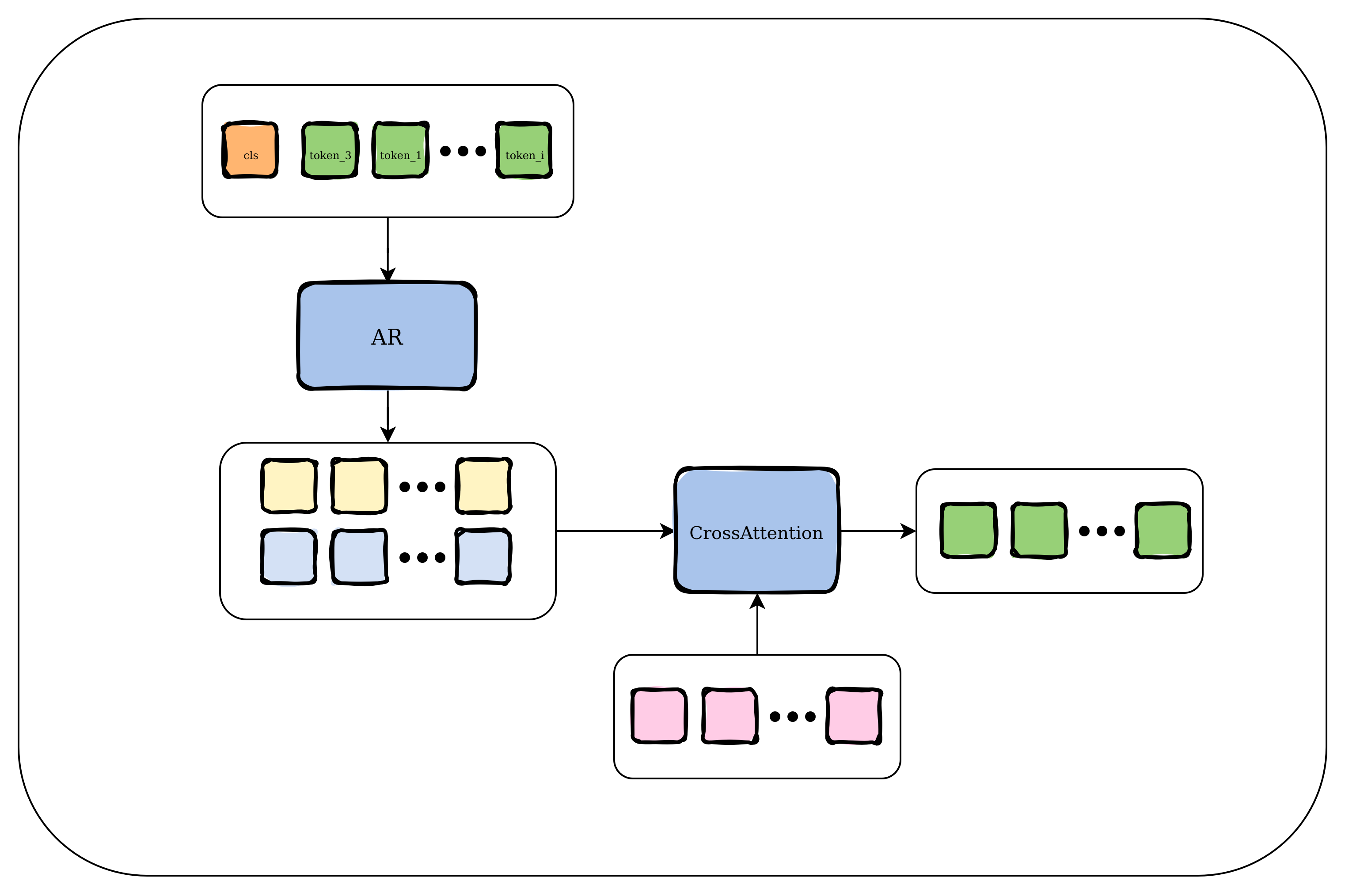
示意图
只将img1输入到自回归模型提取K_1,V_1,然后用rec2来作为query查询,和K_1,V_1计算交叉注意力,得到特征。
问题:
1、提取的K_1,V_1能力不足,监督项少,导致提取困难。
2、rec2作为查询,简单的编码然后广播到256长度,模型需要将rec2对应到图片中正确的部分,语义不对齐,模型编辑困难。
总结
后续将会利用论文提出的假设或者结论来解决上面提到的问题。