一、资源下载
docker拉取显卡驱动、ollama(模型部署)、openwebui(前端对话)镜像
# 根据cuda版本修改
docker pull nvidia/cuda:xx.xx.x-cudnn-devel-ubuntu24.04
docker pull ollama/ollama
docker pull openwebui/openwebui
modelscope下载官方gguf格式模型,根据硬件显卡显存大小选择其中一种量化模式的模型即可。
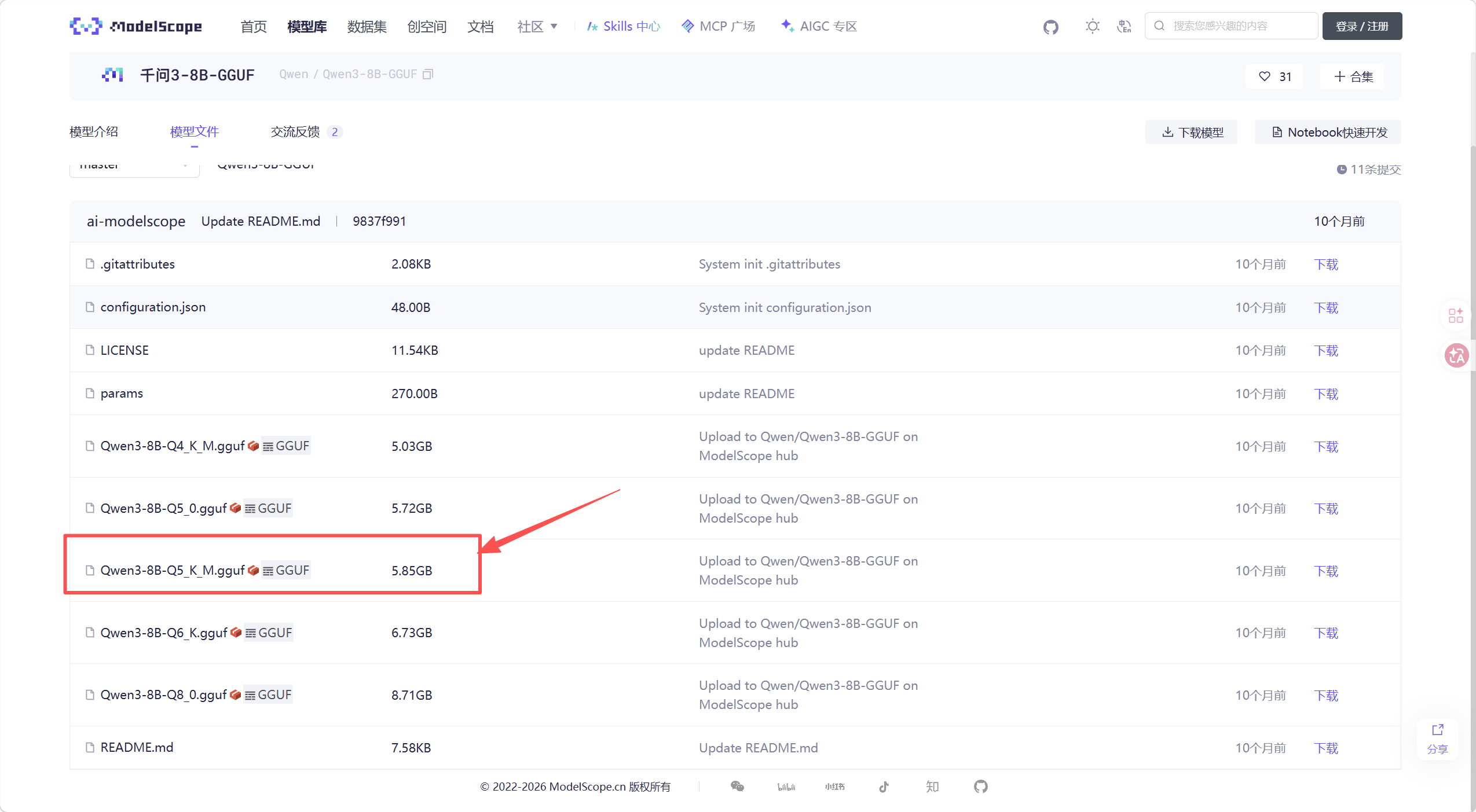
# 在安装了modelscope的python虚拟环境(venv)下运行
(venv)modelscope download --model Qwen/Qwen3-8B-GGUF xxx.gguf --local_dir ./dir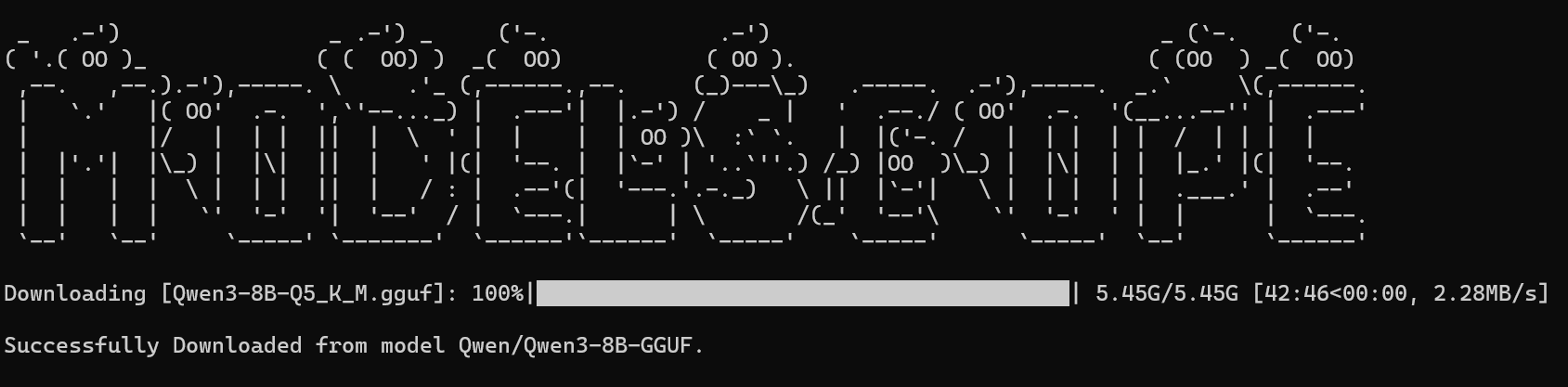
二、部署
1.启动ollama容器
在模型下载目录下创建docker-compose.yml文件,将下面启动内容文本编辑保存。
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
- .:/models
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
ollama_data:CMD进入当前路径的windows命令窗口,输入下面指令启动容器。
docker compose up -d2.导入模型
在模型文件所在目录打开 CMD,执行指令后创建Modelfile文件
# 注意把文件名换成你实际下载的 gguf 文件名
echo FROM /models/qwen3-xxx.gguf > Modelfile
导入本地模型指令:
docker exec -it ollama ollama create qwen3-8b -f /models/Modelfile
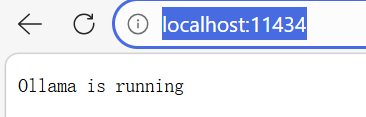
网页输入localhost:11434,即可测试是否模型部署成功
3.启动openwebUI容器
新建一个docker-compose.yml文件,输入以下内容
services:
openwebui:
image: ghcr.io/open-webui/open-webui:main
container_name: openwebui
restart: unless-stopped
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://host.docker.internal:11434
- ENABLE_RAG_WEB_SEARCH=false
- ENABLE_SEARCH_QUERY=false
- RAG_EMBEDDING_ENGINE=ollama
- RAG_OLLAMA_BASE_URL=http://host.docker.internal:11434
- ENABLE_OPENAI_API=false
- OPENAI_API_KEY=none
volumes:
- openwebui_data:/app/backend/data
volumes:
openwebui_data:指令启动
docker compose up -d三、使用
注册账户

开始使用
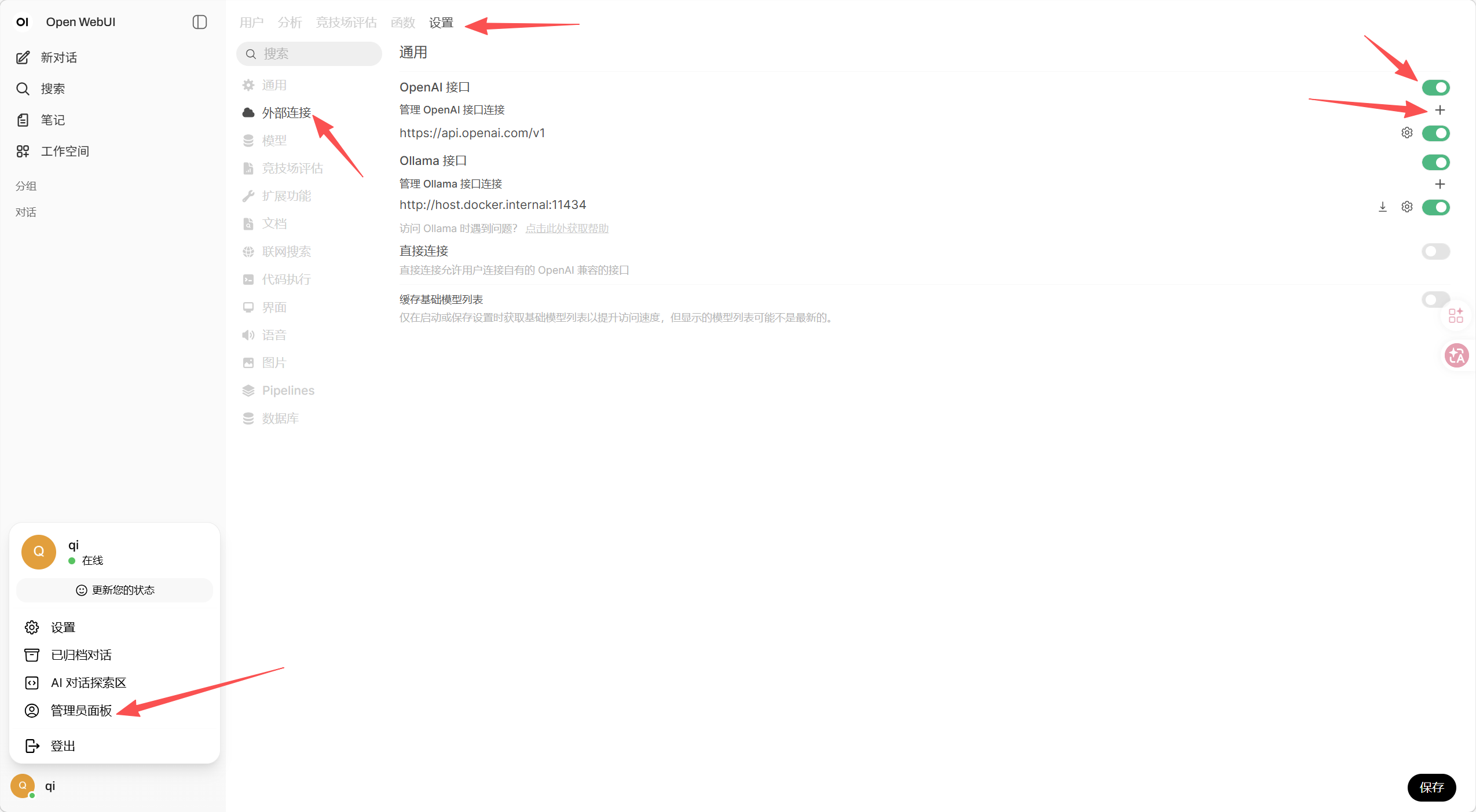
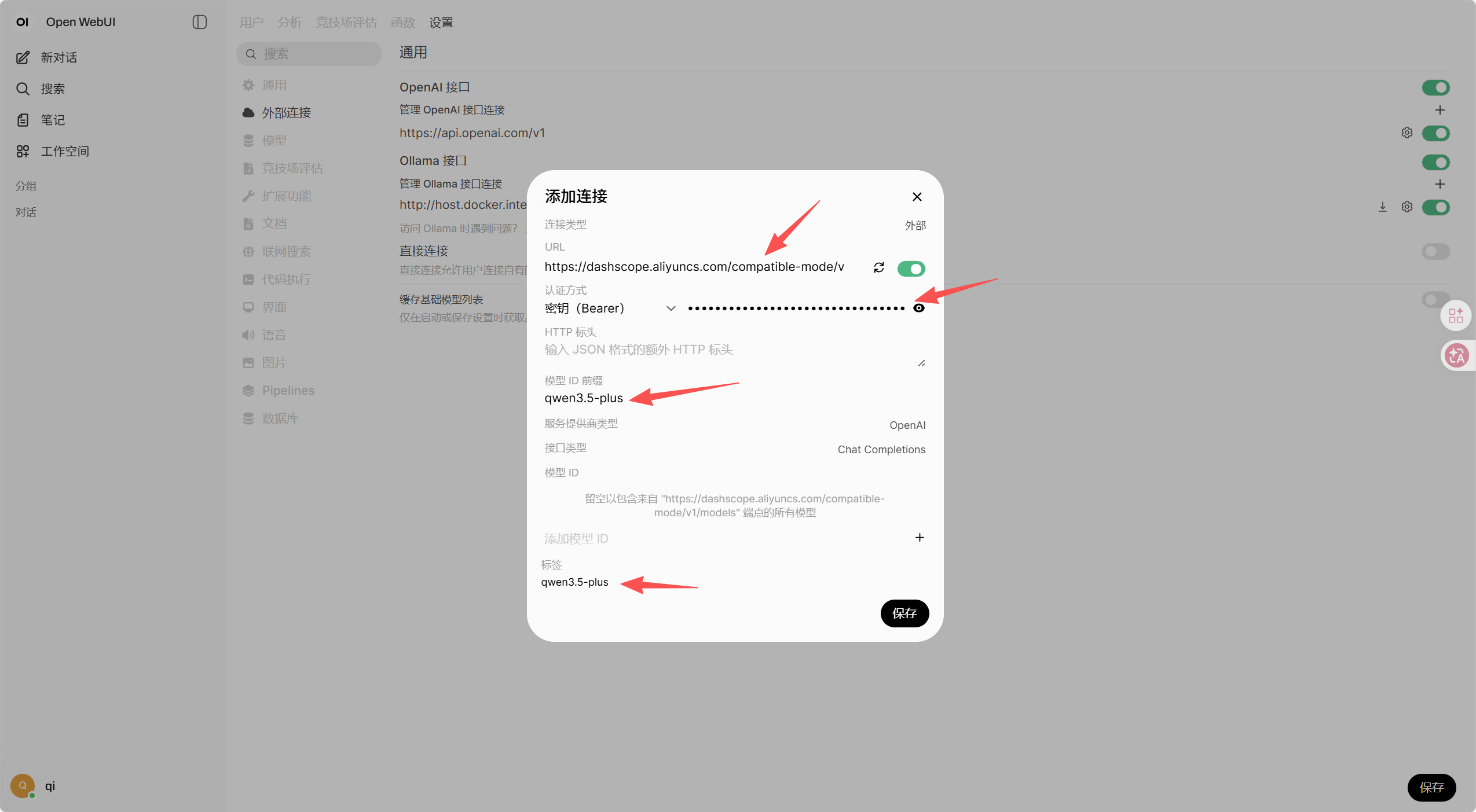
添加新的模型地址(以百炼API为例),新建openai接口
新建对话即可看到可用的外部所有模型