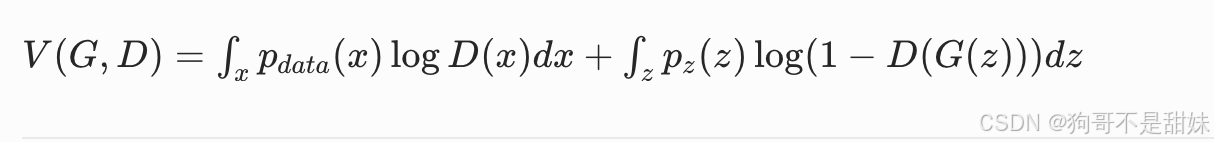研究背景
深度学习在判别式模型 (高维输入映射到类别标签,如图像分类)上取得巨大成功,核心依赖反向传播、Dropout 和分段线性激活函数;但生成式模型发展受限,原因是极大似然估计等方法涉及难以近似的概率计算,且难以在生成场景中利用分段线性激活函数的优势,本文提出的 GAN 框架解决了这一痛点。
特征维度 :回答的是「一个数据样本的属性 / 特征,需要几个数值描述? 」
想让模型学 "猫的图像分布",传统方法需要先算出「所有可能的猫图像的概率和(配分函数)」,但猫的图像有无数种(姿势、颜色、角度),根本算不出来;只能用 MCMC 反复采样 "近似猫的分布",但采样可能只停留在 "橘猫",学不会 "布偶猫",最终模型只能生成橘猫,丧失多样性。

核心框架
GAN 由**生成器(G)和 判别器(D)两个多层感知器(MLP)组成**
G:把无意义的随机噪声z,通过网络神经映射,变成如同真实样本一样


初始状态,辨别器强,因此,总体是0,
后面慢慢的生成器开始发力,然后总体的都是1/2


核心训练方法(讲清「怎么训」,突出「简单高效」)
- 训练的核心原则:交替训练 D 和 G(D 训 k 步,G 训 1 步),原因是 "一次性把 D 训到最优计算量太大,还会过拟合";
- 训练的技术亮点 :仅用反向传播 + Dropout,生成样本仅需正向传播,对比传统模型的 "马尔可夫链 / 近似推理",突出 GAN 的计算简洁性(汇报时可加一句「这是 GAN 最核心的工程优势」)。
如何求期望

因此等价于
最大化,就是不看积分那里,然后求极值点