在分布式微服务架构成为主流的今天,你是否遇到过这样的场景:单接口压测时性能表现完美,可线上大促流量一进来,系统就出现响应超时、服务雪崩、数据库宕机?核心原因在于,传统的单接口、单系统压测,无法模拟真实线上的全链路流量场景,无法捕捉到跨服务调用、资源竞争、链路依赖带来的隐藏性能瓶颈。全链路压测,正是解决这一问题的核心方案,它通过模拟真实的线上用户行为与全链路流量模型,在预发环境甚至生产环境完成对整个分布式系统的性能验证,提前暴露瓶颈风险,保障系统的稳定性。
一、核心概念与易混淆点明确区分
1.1 压测类型的核心差异
很多开发者会混淆不同压测类型的适用场景,这里做明确区分:
| 压测类型 | 核心目标 | 适用场景 | 核心局限 |
|---|---|---|---|
| 单接口压测 | 验证单个接口的基线性能 | 接口开发完成后的基础性能验证 | 无法模拟多接口、跨服务的真实链路场景 |
| 单系统压测 | 验证单个服务的承载能力 | 单个服务迭代后的性能回归 | 无法覆盖依赖服务的瓶颈,与线上真实场景脱节 |
| 全链路压测 | 验证整个分布式系统的端到端性能与稳定性 | 大促前的系统容量验证、架构迭代后的全链路性能回归 | 对环境、数据、流量模型的真实性要求极高 |
1.2 全链路压测的核心指标与易混淆点纠正
压测指标的解读直接决定瓶颈定位的准确性,这里纠正行业内常见的认知误区:
1.2.1 吞吐量指标
- QPS(Queries Per Second) :每秒查询数,指系统每秒能处理的请求数量,通常用于读接口的性能衡量。
- TPS(Transactions Per Second) :每秒事务数,指系统每秒能处理的完整业务事务数量,一个事务对应一次完整的全链路业务操作(比如一次下单包含订单创建、库存扣减、支付回调等多个接口调用),是全链路压测的核心吞吐量指标。
❝
误区纠正:QPS和TPS不能划等号,一个TPS可能对应多个QPS,只有单接口的场景下两者才近似相等。
1.2.2 响应时间指标
- 平均RT:所有请求的响应时间的平均值,参考价值有限,极易被极端值影响。
- P95 RT:95%的请求响应时间都低于该值,是衡量系统用户体验的核心指标,线上核心链路通常要求P95 RT < 500ms。
- P99 RT:99%的请求响应时间都低于该值,反映系统的长尾性能,是定位系统瓶颈的关键指标,核心链路通常要求P99 RT < 1s。
❝
误区纠正:只看平均RT会完全掩盖长尾问题,比如100个请求中99个耗时10ms、1个耗时10s,平均RT仅109.9ms,但实际有1%的用户体验极差,线上故障往往由P99 RT的异常引发。
1.2.3 稳定性指标
- 错误率:请求失败的占比,核心链路要求错误率 < 0.01%,非核心链路 < 0.1%。
- 系统可用性:压测周期内系统正常服务的时间占比,核心系统要求达到99.99%以上。
1.2.4 并发指标
- 并发用户数:同时向系统发起请求的用户数量,分为虚拟并发用户数和真实并发用户数,和TPS没有固定的换算关系,取决于接口的响应时间。
❝
误区纠正:不是并发用户数越高,TPS越高。当系统达到性能瓶颈后,并发用户数继续增加,TPS会保持不变甚至下降,RT会急剧上升,错误率也会飙升。
二、全链路压测方案的标准化设计
压测结果有效的核心前提,是压测方案与线上真实场景的一致性,方案设计必须覆盖四大核心模型。
2.1 业务模型设计
业务模型是压测方案的核心,必须完全基于线上真实的流量数据构建:
- 梳理核心业务链路:覆盖用户从进入系统到完成核心操作的全流程,比如电商场景的商品浏览→加购→下单→支付→订单查询。
- 确定链路流量占比:基于线上近7天的流量日志,统计各链路的请求占比,比如商品浏览占60%、加购占20%、下单占15%、支付占5%,压测时必须严格按照该比例构造流量。
- 明确业务规则约束:比如下单的库存校验、用户登录态校验、风控规则等,压测脚本必须完全复现线上的业务规则,避免压测场景与线上脱节。
2.2 数据模型设计
压测数据的真实性直接决定压测结果的可信度,必须满足四大要求:
- 数据量级与线上一致:比如线上用户表有1亿条数据,压测环境不能仅准备1万条,否则数据库的索引选择性、SQL执行计划都会与线上完全不同。
- 数据分布与线上一致:模拟线上的热点数据分布,比如20%的商品贡献80%的流量,避免所有数据均匀分布导致无法复现热点Key、锁竞争等线上常见问题。
- 数据脱敏与合规:严禁直接使用线上真实的用户隐私数据,必须对手机号、身份证号、银行卡号等敏感信息进行脱敏处理。
- 数据可重复使用:压测数据必须支持多次压测重复使用,避免单次压测后数据失效,比如压测前重置库存数据、订单数据。
2.3 环境模型设计
压测环境必须与线上环境保持1:1的一致性,核心包含四个维度:
- 硬件配置一致:服务器的CPU、内存、磁盘、网络带宽必须与线上一致,容器化部署的场景下,容器的CPU配额、内存配额、副本数必须与线上一致。
- 软件版本一致:JDK、MySQL、Redis、MQ、微服务组件等所有软件的版本,必须与线上完全一致,避免版本差异带来的性能变化。
- 部署架构一致:负载均衡策略、服务集群拓扑、跨可用区部署架构、第三方依赖的调用链路,必须与线上完全一致。
- 依赖服务模拟一致:对于第三方接口、外部系统,不能直接调用线上服务,必须使用挡板(Mock)模拟,且Mock的响应时间、错误率必须与线上真实情况一致。
2.4 施压模型设计
针对不同的压测目标,必须选择对应的施压策略,核心分为四类:
- 基准压测:单线程循环调用核心接口,持续1-5分钟,获取单接口的基线性能(最大TPS、最低RT),作为后续优化的对比基准,同时验证压测脚本的正确性。
- 负载压测:阶梯式加压,比如每1分钟增加100并发用户,直到TPS达到线上日常峰值的2倍,持续运行30分钟以上,验证系统在日常负载下的稳定性,定位常规瓶颈。
- 峰值压测:模拟线上大促的峰值流量,直接加压到线上峰值的3-5倍,持续运行10-30分钟,验证系统的峰值承载能力,保障大促稳定性。
- 极限压测(破坏性压测) :持续加压,直到系统TPS下降、RT飙升、错误率上升,找到系统的极限承载能力,同时验证系统的熔断、降级、限流等容错机制是否生效,会不会出现服务雪崩。
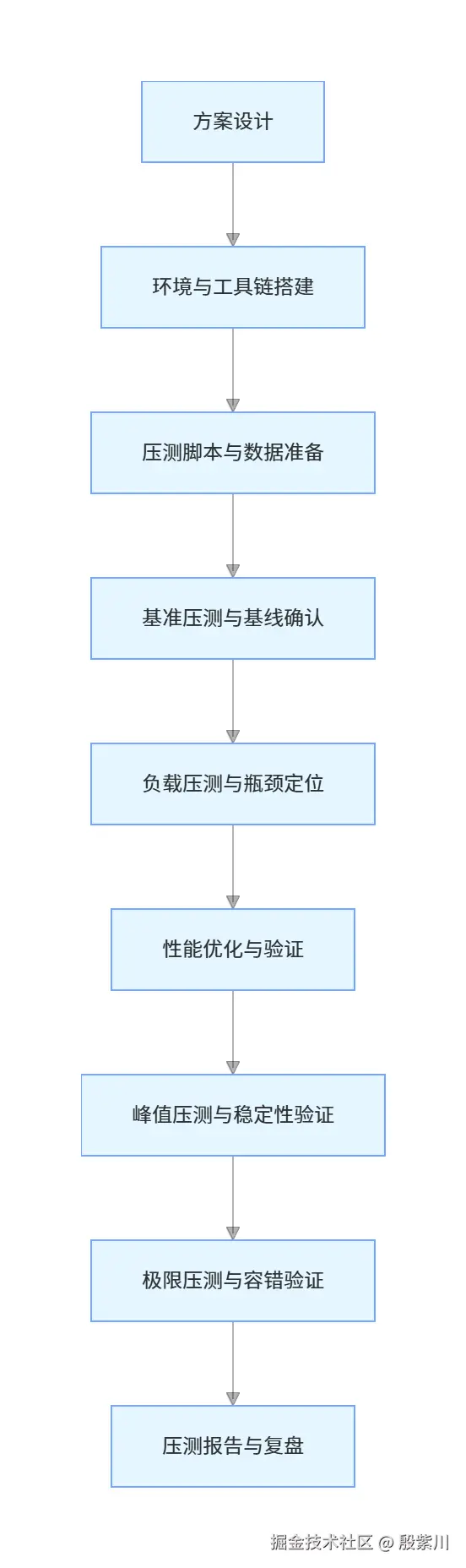
三、压测环境与工具链搭建
本章节所有工具均采用2024年发布的最新稳定版本,确保兼容性与安全性。
3.1 核心工具链选型
| 工具类型 | 工具选型与版本 | 核心优势 |
|---|---|---|
| 施压工具 | Apache JMeter 5.6.3 | 开源、功能强大、支持分布式压测、国内生态完善,适合全链路压测的复杂场景 |
| 全链路追踪工具 | Apache SkyWalking 9.7.0 | 无侵入式探针、支持多语言、全链路拓扑可视化、精准定位慢调用,适配主流微服务架构 |
| 监控工具 | Prometheus 2.53.1 + Grafana 11.2.0 | 业界标准的监控方案,支持全维度指标采集、自定义告警、可视化大盘,覆盖从基础设施到应用的全链路监控 |
| 数据隔离工具 | MyBatis-Plus 3.5.7 影子表插件 + RocketMQ 5.3.0 影子主题 | 实现压测流量与业务流量的严格隔离,避免压测数据污染线上业务库 |
3.2 压测流量隔离的核心实现
生产环境全链路压测的核心前提,是压测流量与业务流量的严格隔离,行业通用的成熟方案是影子库/影子表机制,底层逻辑如下:
- 压测流量标记:在HTTP请求Header中添加压测标记
x-pressure-test: true,通过SkyWalking的链路透传能力,将标记全链路传递到所有服务。 - 写操作路由:数据访问层检测到压测标记后,自动将所有写操作路由到影子库/影子表,读操作可路由到业务库(读操作不污染数据)。
- 中间件隔离:MQ的压测消息自动路由到影子主题,Redis的压测数据添加统一前缀,避免与业务数据冲突。
四、全链路瓶颈定位的标准化方法论
瓶颈定位的核心原则是自上而下,从链路到节点,从指标到根因,先通过全链路追踪锁定瓶颈链路,再深入节点定位瓶颈资源,最终分析根因。
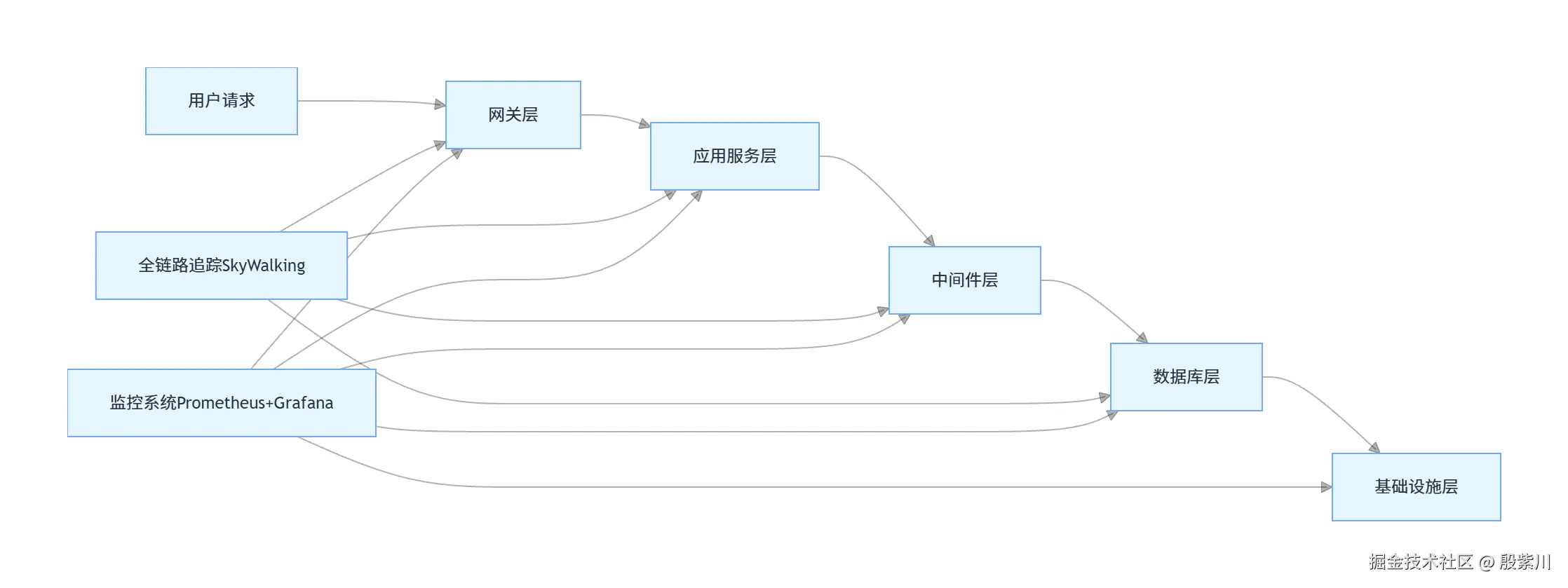
4.1 网关层瓶颈定位
网关是全链路的入口,也是第一个容易出现瓶颈的环节,常见瓶颈与定位方法如下:
- 常见瓶颈:路由规则过多、过滤器逻辑复杂、Netty线程池阻塞、TCP连接数不足、SSL握手耗时过长、限流规则不合理。
- 定位方法:通过SkyWalking的网关拓扑,查看网关的RT、TPS、错误率分布;通过Prometheus的网关指标,查看Netty线程池的活跃线程数、TCP连接数、CPU使用率;通过网关的访问日志,定位慢请求的来源。
- 核心判断阈值:网关CPU使用率持续超过70%、Netty worker线程池活跃线程数达到最大线程数的80%、TCP全连接队列溢出,即可判定网关层存在瓶颈。
4.2 应用服务层瓶颈定位
应用服务是业务逻辑的核心,也是最容易出现性能问题的环节,分为四大类瓶颈:
4.2.1 代码逻辑瓶颈
- 常见问题:循环内调用数据库/Redis、大对象序列化/反序列化、锁竞争激烈、正则表达式回溯、内存泄漏、冗余的业务逻辑。
- 定位方法 :通过SkyWalking的链路追踪,找到Span耗时最长的业务方法;通过Arthas 3.7.2的
trace命令,在线查看方法内每个步骤的执行耗时,精准定位慢代码。 - 示例命令 :
trace com.example.service.OrderService createOrder -n 10,该命令会输出createOrder方法内每一行代码的执行耗时,直接锁定慢逻辑。
4.2.2 JVM瓶颈
- 常见问题:FullGC频繁、YoungGC耗时过长、元空间溢出、堆内存溢出、堆外内存泄漏、GC暂停时间过长。
- 定位方法 :通过Grafana的JVM监控大盘,查看GC的频率、耗时、堆内存的使用趋势;通过
jstat -gc <pid> 1000 10命令实时查看GC情况;通过jmap命令生成堆内存快照,使用MAT工具分析内存泄漏的根因。 - 核心判断阈值:FullGC频率超过1小时1次、YoungGC单次耗时超过50ms、P99 GC暂停时间超过200ms、堆内存使用率持续超过80%,即可判定JVM存在瓶颈。
4.2.3 线程池瓶颈
- 常见问题:核心线程数设置不合理、最大线程数过大导致上下文切换频繁、队列长度过长导致请求排队超时、拒绝策略频繁触发。
- 定位方法 :通过Prometheus的线程池指标,查看线程池的活跃线程数、队列长度、拒绝次数;通过Arthas的
thread命令,查看线程的状态,定位阻塞的线程。 - 核心判断阈值:活跃线程数持续达到核心线程数的90%、队列排队长度超过队列容量的50%、出现拒绝策略触发,即可判定线程池存在瓶颈。
4.2.4 依赖调用瓶颈
- 常见问题:RPC调用超时、数据库慢查询、Redis慢查询、第三方接口响应慢、依赖服务熔断。
- 定位方法:通过SkyWalking的链路追踪,查看每个依赖调用的耗时占比,直接锁定慢依赖;通过依赖服务的监控指标,查看依赖服务的性能情况。
4.3 中间件层瓶颈定位
4.3.1 Redis瓶颈定位
- 常见问题:热点Key、大Key、慢查询、内存不足、RDB/AOF持久化阻塞、网络带宽不足、连接数不足。
- 定位方法 :通过Redis的
SLOWLOG GET 10命令查看慢查询;通过INFO命令查看内存使用、连接数、命中率;通过Prometheus的Redis指标,查看QPS、响应时间、CPU使用率;通过redis-cli --hotkeys命令查找热点Key。 - 核心判断阈值:Redis CPU使用率持续超过80%、Key命中率低于99%、慢查询数量持续增加、内存使用率超过maxmemory的80%,即可判定Redis存在瓶颈。
4.3.2 MQ瓶颈定位
- 常见问题:生产消息耗时过长、消费速度跟不上生产速度、消息堆积、Broker磁盘IO瓶颈、网络带宽不足。
- 定位方法:通过MQ的Dashboard,查看生产TPS、消费TPS、消息堆积量;通过Prometheus的MQ指标,查看Broker的磁盘IO、CPU使用率、消息延迟。
- 核心判断阈值:消息堆积量持续增长、消费TPS低于生产TPS、Broker磁盘IO使用率持续超过80%,即可判定MQ存在瓶颈。
4.4 数据库层瓶颈定位
数据库是全链路最常见的瓶颈点,行业内80%的性能问题都出在数据库层。
- 常见问题:慢SQL、索引失效、行锁等待、表锁、事务隔离级别过高、连接数不足、磁盘IO瓶颈、内存不足、SQL执行计划错误。
- 定位方法 :通过MySQL的慢查询日志,找到执行耗时超过1s的慢SQL;通过
EXPLAIN命令分析SQL的执行计划,判断索引是否生效;通过SHOW ENGINE INNODB STATUS命令查看事务和锁等待情况;通过Prometheus的MySQL指标,查看连接数、QPS、TPS、锁等待时间、慢查询数量。 - 核心判断阈值:慢SQL数量持续增加、行锁等待时间超过500ms、连接数使用率超过80%、磁盘IO使用率持续超过90%,即可判定数据库存在瓶颈。
4.5 基础设施层瓶颈定位
- 常见问题:CPU使用率过高、内存不足导致Swap分区使用、磁盘IOPS不足、网络带宽不足、Linux内核参数配置不合理。
- 定位方法 :通过Prometheus的节点指标,查看CPU使用率、内存使用率、磁盘IO、网络流量;通过
top、iostat、vmstat、netstat等命令,定位具体的资源瓶颈。 - 核心判断阈值:CPU用户态使用率持续超过80%、CPU内核态使用率持续超过30%、Swap分区使用率超过10%、磁盘IO使用率持续超过90%、网络带宽使用率持续超过80%,即可判定基础设施存在瓶颈。
五、全链路性能优化的可落地实战方案
本章节的优化方案均对应上一章节的瓶颈场景,所有代码、参数配置均经过验证,可直接落地使用。
5.1 网关层优化
- 线程池优化 :调整Netty的worker线程池,默认配置为CPU核心数2,IO密集型场景可调整为CPU核心数4,避免线程池阻塞;调整boss线程池为CPU核心数,提升连接接受能力。
- 过滤器优化:精简过滤器链,移除非必要的过滤器;过滤器逻辑尽量轻量化,严禁在过滤器中执行远程调用、复杂业务逻辑;将非核心过滤器调整为异步执行。
- 路由优化:合并重复的路由规则,使用前缀匹配代替正则匹配,减少路由匹配的耗时;开启路由缓存,避免每次请求都重新匹配路由。
- 网络优化:开启TCP端口复用、HTTP连接复用,减少TCP握手耗时;调整TCP的keepalive参数,减少无效连接占用;关闭不必要的SSL验证,提升HTTPS性能。
- 缓存优化:对静态资源、热点接口的响应结果做本地缓存,减少后端服务的调用压力;开启网关的响应压缩,减少网络传输的数据量。
5.2 应用服务层优化
5.2.1 代码逻辑优化
- 避免循环内调用数据库/Redis,改为批量操作,减少网络IO次数,示例代码如下(Spring Boot 3.3.5 + MyBatis-Plus 3.5.7,JDK 21):
scss
// 错误写法:循环内调用数据库,产生N次数据库交互,性能极差
public List<OrderVO> getOrderList(List<Long> orderIds) {
List<OrderVO> orderVOList = new ArrayList<>();
for (Long orderId : orderIds) {
Order order = orderMapper.selectById(orderId);
orderVOList.add(convert(order));
}
return orderVOList;
}
// 正确写法:批量查询,仅1次数据库交互,性能提升数十倍
public List<OrderVO> getOrderList(List<Long> orderIds) {
List<Order> orderList = orderMapper.selectBatchIds(orderIds);
return orderList.stream().map(this::convert).toList();
}- 避免大对象的序列化与反序列化,精简返回字段,使用DTO代替DO,仅返回前端需要的字段,减少序列化耗时和网络传输量。
- 减少锁竞争,使用乐观锁代替悲观锁,使用分段锁代替全局锁,避免用
synchronized修饰整个方法,尽量缩小锁的范围。 - 避免正则表达式的回溯,复杂正则提前编译为
Pattern对象,避免每次调用都重新编译;使用贪婪匹配代替惰性匹配,减少回溯次数。 - 非核心逻辑异步化,比如下单成功后的短信通知、消息推送,使用异步线程处理,不影响主链路的响应时间。
5.2.2 JVM优化(JDK 21)
ruby
-Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+ParallelRefProcEnabled -XX:MaxMetaspaceSize=1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/jvm/heapdump.hprof -XX:+UnlockExperimentalVMOptions -XX:+UseStringDeduplication -XX:+DisableExplicitGC- 核心优化说明:
-Xms与-Xmx设置为相同值,避免堆内存动态调整带来的性能损耗;MaxGCPauseMillis设置GC目标暂停时间,G1GC会自动调整新生代大小以满足该目标;开启字符串去重,减少内存占用;禁用显式GC,避免代码中System.gc()触发的FullGC。 - 内存优化原则:堆内存大小设置为服务器物理内存的50%-70%,预留足够的内存给系统内核和堆外内存使用。
5.2.3 线程池优化(基于Brain Goetz的线程池配置公式,生产验证的最佳实践)
线程池配置必须按照任务类型拆分,CPU密集型任务与IO密集型任务严禁使用同一个线程池,正确的配置示例如下:
java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.*;
@Configuration
public class ThreadPoolConfig {
// 获取服务器CPU核心数
private static final int CPU_CORE = Runtime.getRuntime().availableProcessors();
// IO密集型任务线程池:适用于数据库、Redis、RPC调用等IO阻塞型任务
@Bean("ioTaskExecutor")
public ExecutorService ioTaskExecutor() {
return new ThreadPoolExecutor(
CPU_CORE * 2,
CPU_CORE * 4,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(CPU_CORE * 20),
new ThreadFactory() {
private int threadCount = 0;
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "io-task-pool-" + (++threadCount));
thread.setDaemon(true);
return thread;
}
},
// 自定义拒绝策略:快速失败,触发降级
(r, executor) -> {
throw new RuntimeException("系统繁忙,请稍后再试");
}
);
}
// CPU密集型任务线程池:适用于加密、计算、序列化等CPU消耗型任务
@Bean("cpuTaskExecutor")
public ExecutorService cpuTaskExecutor() {
return new ThreadPoolExecutor(
CPU_CORE + 1,
CPU_CORE * 2,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(CPU_CORE * 10),
new ThreadFactory() {
private int threadCount = 0;
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "cpu-task-pool-" + (++threadCount));
thread.setDaemon(true);
return thread;
}
},
// 调用者执行策略:避免任务丢失,降低提交速度
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
}- 核心优化说明:IO密集型任务的核心线程数公式为
CPU核心数 * 2 / 阻塞系数,阻塞系数通常为0.8-0.9,因此8核CPU的核心线程数设置为16-80;队列长度不宜设置过长,否则会导致请求排队时间过长,RT飙升;自定义线程工厂设置线程名称,方便问题排查。
5.2.4 依赖调用优化
- 超时控制:所有RPC调用、HTTP调用、数据库调用、Redis调用必须设置超时时间,避免线程被长时间阻塞,导致线程池耗尽。
- 熔断降级:使用Resilience4j实现熔断降级,当依赖服务的错误率超过阈值时,自动触发熔断,快速失败,避免服务雪崩。
- 批量处理:多个小的调用合并为批量调用,比如多个Redis的
get命令改为mget命令,多个数据库的selectById改为selectBatchIds,减少网络IO次数。
5.3 中间件层优化
5.3.1 Redis优化(Redis 7.4.1)
- 大Key优化:单个Key的Value大小严禁超过10KB,大Key会导致网络IO阻塞、Redis主线程卡顿,大Key必须拆分为多个小Key;禁用Hash、Set、Zset等集合类型的元素数量超过1000个的大Key。
- 热点Key优化:热点Key采用「本地缓存Caffeine + Redis」的多级缓存架构,将热点数据缓存到应用本地,减少Redis的访问压力;热点Key打散到多个Redis节点,避免单节点压力过大。
- 慢查询优化:禁用
KEYS *、FLUSHALL、HGETALL等高危命令,使用SCAN代替KEYS,避免阻塞Redis主线程;复杂的集合操作改为分批处理,减少单次操作的耗时。 - 持久化优化:采用RDB+AOF混合持久化模式,RDB做全量备份,AOF做增量备份;AOF的
fsync策略设置为everysec,平衡性能与数据安全性;关闭自动RDB触发,改为低峰期手动执行。 - 内存优化:设置
maxmemory-policy为allkeys-lru,淘汰最近最少使用的Key,避免内存满了导致的OOM;开启内存压缩,减少内存占用。
5.3.2 MQ优化(RocketMQ 5.3.0)
- 生产端优化:开启批量发送,设置批量大小为16KB,减少网络IO次数;开启消息压缩,减少消息体积;使用异步发送,避免阻塞业务主线程;设置发送超时时间,避免线程阻塞。
- 消费端优化:提高消费并行度,增加Topic的分区数与消费者线程数,分区数建议设置为消费者线程数的2倍;批量消费,一次消费多条消息,减少offset提交的次数;消费逻辑严禁出现慢调用,避免消费速度跟不上生产速度。
- Broker优化:调整刷盘策略为异步刷盘,提升吞吐量;调整磁盘IO调度算法为
mq-deadline,提升SSD的IO性能;开启消息堆外内存存储,减少GC压力。
5.4 数据库层优化(MySQL 8.4.3)
5.4.1 索引优化
- 核心查询必须建立索引,避免全表扫描;联合索引遵循最左前缀匹配原则,where条件中的等值查询字段放在前面,排序、分组字段放在后面。
- 示例:订单查询SQL的索引优化,原始SQL如下:
sql
SELECT id,order_no,user_id,order_status,create_time FROM t_order WHERE user_id = 123 AND order_status = 0 ORDER BY create_time DESC LIMIT 10;- 正确的联合索引创建语句:
arduino
CREATE INDEX idx_userid_status_createtime ON t_order (user_id, order_status, create_time);- 优化说明:该索引完全匹配最左前缀匹配原则,where条件中的
user_id、order_status都能用到索引,order by的create_time也能用到索引,避免了文件排序,同时查询的所有字段都包含在索引中,实现了覆盖索引,无需回表查询,性能提升数十倍。 - 索引使用禁忌:避免索引字段使用函数、隐式类型转换、模糊查询以%开头、OR连接非索引字段,这些场景都会导致索引失效,触发全表扫描。
- 索引数量控制:单表索引数量严禁超过5个,过多的索引会导致insert、update、delete操作的性能大幅下降,因为每次写操作都需要更新所有索引。
5.4.2 SQL优化
- 禁用
SELECT *,只查询需要的字段,减少数据传输和内存占用。 - 避免深分页查询,比如
LIMIT 100000, 10,改为主键过滤优化:
sql
-- 错误写法:深分页,会扫描100010行数据,性能极差
SELECT * FROM t_order ORDER BY id DESC LIMIT 100000, 10;
-- 正确写法:主键过滤,仅扫描10行数据,性能提升上万倍
SELECT * FROM t_order WHERE id < 100000 ORDER BY id DESC LIMIT 10;- 批量操作代替循环单条操作,比如批量插入、批量更新,减少事务提交次数和网络IO次数。
- 避免大事务,事务内的操作尽量精简,事务执行时间尽量缩短,避免长事务导致的锁等待、MVCC的undo log膨胀。
5.4.3 事务优化
- 选择合适的事务隔离级别,线上生产环境建议使用
READ COMMITTED,避免REPEATABLE READ的间隙锁导致的锁等待问题,提升并发性能,MySQL 8.4.3默认的隔离级别是REPEATABLE READ,可通过配置文件修改。 - 严禁在事务内执行远程调用、RPC调用、HTTP调用,避免事务时间过长,导致锁持有时间过长,引发锁等待和死锁。
- 非核心场景使用最终一致性代替强一致性,比如通过MQ实现分布式事务,提升系统的并发性能。
5.4.4 MySQL生产环境核心参数配置(16G内存服务器,经过生产验证)
ini
[mysqld]
# 内存核心配置
innodb_buffer_pool_size = 10G
innodb_log_buffer_size = 64M
innodb_log_file_size = 2G
# 连接配置
max_connections = 1000
wait_timeout = 600
interactive_timeout = 600
# IO性能配置
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
innodb_io_capacity = 2000
innodb_io_capacity_max = 4000
# 慢查询日志配置
slow_query_log = ON
long_query_time = 1
log_queries_not_using_indexes = ON
# 事务与锁配置
transaction_isolation = READ-COMMITTED
innodb_lock_wait_timeout = 5
# 字符集配置
character_set_server = utf8mb4
collation_server = utf8mb4_unicode_ci- 核心优化说明:
innodb_buffer_pool_size是InnoDB的核心缓存,缓存索引和数据,设置为服务器内存的50%-70%,越大越好,减少磁盘IO;innodb_flush_log_at_trx_commit和sync_binlog设置为1,是双1配置,保证数据不丢失,若对性能要求高、对数据丢失容忍度高,可改为2和1000,性能提升显著。
5.5 基础设施层优化
5.5.1 Linux内核参数优化(生产环境通用配置,提升网络与IO性能)
ini
# /etc/sysctl.conf
# TCP核心优化
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 3
# 连接队列优化
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 65535
# 缓冲区优化
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# 内核优化
vm.swappiness = 0
vm.overcommit_memory = 1
vm.dirty_ratio = 10
vm.dirty_background_ratio = 5- 核心优化说明:
tcp_tw_reuse开启TIME_WAIT状态的端口复用,提升短连接的性能;somaxconn调整TCP全连接队列大小,避免高并发下连接被拒绝;vm.swappiness=0关闭Swap分区,避免内存交换导致的性能急剧下降。
5.5.2 硬件优化
- CPU优化:关闭CPU的节能模式,设置为性能模式,避免CPU降频;将应用进程绑定到指定的CPU核心,减少上下文切换开销。
- 磁盘优化:使用SSD硬盘,严禁使用机械硬盘;调整磁盘IO调度算法为
mq-deadline(SSD);使用XFS文件系统,提升大文件的IO性能;关闭文件的atime属性,减少磁盘IO。 - 网络优化:使用万兆网卡,避免千兆网卡的带宽瓶颈;开启网卡多队列,将网卡中断绑定到不同的CPU核心,提升网络处理能力。
六、全链路压测完整实战案例
6.1 案例场景与技术栈
- 业务场景:电商核心下单全链路,链路流程:用户发起下单请求→Spring Cloud Gateway网关→订单服务→库存服务(扣减库存)→支付服务(创建支付单)→返回下单结果。
- 技术栈版本:JDK 21 LTS、Spring Boot 3.3.5、Spring Cloud 2023.0.3、MyBatis-Plus 3.5.7、MySQL 8.4.3 LTS、Redis 7.4.1、JMeter 5.6.3、SkyWalking 9.7.0。
6.2 核心服务代码实现
订单服务的核心pom.xml依赖配置,所有版本均为最新稳定版,可直接编译:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.5</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>order-service</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>order-service</name>
<description>Order Service</description>
<properties>
<java.version>21</java.version>
<spring-cloud.version>2023.0.3</spring-cloud.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2023.0.3.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>9.7.0</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>订单服务的核心下单接口代码,符合Spring Boot 3.x规范,可直接运行:
less
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import feign.FeignException;
import lombok.Data;
import org.apache.skywalking.apm.toolkit.trace.Trace;
import org.springframework.web.bind.annotation.*;
import java.time.LocalDateTime;
// 订单实体类
@Data
@TableName("t_order")
public class Order {
@TableId(type = IdType.AUTO)
private Long id;
private Long userId;
private Long productId;
private Integer count;
private Integer orderStatus;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
// 订单Mapper接口
public interface OrderMapper extends BaseMapper<Order> {}
// 库存服务Feign客户端
@FeignClient(name = "stock-service")
public interface StockFeignClient {
@PostMapping("/stock/deduct")
Boolean deductStock(@RequestParam Long productId, @RequestParam Integer count);
}
// 支付服务Feign客户端
@FeignClient(name = "pay-service")
public interface PayFeignClient {
@PostMapping("/pay/create")
Long createPayOrder(@RequestParam Long orderId, @RequestParam Long userId, @RequestParam Integer amount);
}
// 下单请求DTO
@Data
public class OrderCreateDTO {
private Long userId;
private Long productId;
private Integer count;
}
// 订单服务接口
@RestController
@RequestMapping("/order")
public class OrderController {
private final OrderMapper orderMapper;
private final StockFeignClient stockFeignClient;
private final PayFeignClient payFeignClient;
// Spring Boot 3.x推荐的构造器注入
public OrderController(OrderMapper orderMapper, StockFeignClient stockFeignClient, PayFeignClient payFeignClient) {
this.orderMapper = orderMapper;
this.stockFeignClient = stockFeignClient;
this.payFeignClient = payFeignClient;
}
@PostMapping("/create")
@Trace(operationName = "createOrder")
public String createOrder(@RequestBody OrderCreateDTO dto) {
// 1. 调用库存服务扣减库存
Boolean deductResult;
try {
deductResult = stockFeignClient.deductStock(dto.getProductId(), dto.getCount());
} catch (FeignException e) {
return "库存扣减失败:" + e.getMessage();
}
if (!deductResult) {
return "库存不足,下单失败";
}
// 2. 创建订单
Order order = new Order();
order.setUserId(dto.getUserId());
order.setProductId(dto.getProductId());
order.setCount(dto.getCount());
order.setOrderStatus(0);
order.setCreateTime(LocalDateTime.now());
order.setUpdateTime(LocalDateTime.now());
orderMapper.insert(order);
// 3. 调用支付服务创建支付单
Long payOrderId;
try {
payOrderId = payFeignClient.createPayOrder(order.getId(), dto.getUserId(), dto.getCount() * 100);
} catch (FeignException e) {
return "支付单创建失败:" + e.getMessage();
}
return "下单成功,订单号:" + order.getId() + ",支付单号:" + payOrderId;
}
}库存服务的核心扣减库存接口代码:
kotlin
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.bind.annotation.*;
// 库存实体类
@Data
@TableName("t_stock")
public class Stock {
@TableId(type = IdType.AUTO)
private Long id;
private Long productId;
private Integer stockNum;
}
// 库存Mapper接口
public interface StockMapper extends BaseMapper<Stock> {}
// 库存服务接口
@RestController
@RequestMapping("/stock")
public class StockController {
private final StockMapper stockMapper;
public StockController(StockMapper stockMapper) {
this.stockMapper = stockMapper;
}
@PostMapping("/deduct")
@Transactional(rollbackFor = Exception.class)
public Boolean deductStock(@RequestParam Long productId, @RequestParam Integer count) {
int updateRows = stockMapper.update(
"UPDATE t_stock SET stock_num = stock_num - ? WHERE product_id = ? AND stock_num >= ?",
count, productId, count
);
return updateRows > 0;
}
}6.3 压测执行与瓶颈定位
- 基准压测:单线程循环调用下单接口,持续3分钟,得到基线性能:单线程TPS=50,平均RT=20ms,P99 RT=30ms,错误率0。
- 负载压测:JMeter设置阶梯加压,初始100并发,每30秒增加100并发,最大1000并发,持续时间300秒。当并发达到500时,TPS达到2000,平均RT=250ms,P99 RT=800ms,错误率0.05%;当并发达到800时,TPS不再上升,稳定在2200左右,平均RT飙升到500ms,P99 RT=2s,错误率上升到1.2%。
- 瓶颈定位 :通过SkyWalking的链路追踪,发现下单链路的耗时分布:库存扣减接口耗时占比60%,订单创建耗时占比20%,支付单创建耗时占比20%。深入库存服务的链路,发现库存扣减的SQL执行耗时平均400ms,是核心瓶颈。通过
EXPLAIN分析SQL执行计划,发现product_id字段没有建立索引,SQL触发了全表扫描,导致性能极差。
6.4 性能优化与效果验证
- 核心优化操作 :给
t_stock表的product_id字段建立唯一索引,SQL语句如下:
sql
CREATE UNIQUE INDEX uk_product_id ON t_stock (product_id);同时优化库存服务的线程池配置、JVM参数,调整MySQL的innodb_buffer_pool_size为10G。 2. 优化后的压测结果:并发达到1000时,TPS达到5000,平均RT=200ms,P99 RT=500ms,错误率0.005%,系统吞吐量提升127%,完全满足线上峰值流量的承载要求。
七、全链路压测的避坑指南
7.1 压测环境与数据的坑
- 坑1:压测环境与线上环境不一致,比如服务器配置低、数据量小、软件版本不同,导致压测结果完全无效。正确做法:压测环境必须与线上环境1:1配置,数据量级和分布与线上完全一致。
- 坑2:压测数据都是冷数据,没有热点分布,无法模拟线上的热点场景,导致压测结果与线上表现完全不符。正确做法:压测数据的热点分布必须与线上一致,比如20%的商品贡献80%的流量。
- 坑3:压测流量没有隔离,污染线上业务数据,导致线上数据错乱。正确做法:生产环境压测必须使用影子库、影子表、影子队列,严格隔离压测流量与业务流量。
7.2 压测执行的坑
- 坑4:一上来就满压,没有阶梯加压,导致系统直接宕机,无法定位瓶颈。正确做法:阶梯式加压,每一步加压后等待系统稳定,记录指标,逐步定位瓶颈。
- 坑5:压测过程中开启限流、熔断规则,导致无法测到系统的真实性能。正确做法:压测前关闭限流、熔断规则,压测完极限性能后,再验证限流、熔断规则的有效性。
- 坑6:压测脚本参数固定,导致缓存全部命中,无法测到数据库的真实性能。正确做法:压测参数使用随机的、与线上分布一致的数据,避免缓存穿透、缓存命中过高。
7.3 结果解读的坑
- 坑7:只看平均RT,忽略P95、P99 RT,导致线上长尾请求过多,用户体验极差。正确做法:核心指标是P99 RT、错误率、TPS,平均RT仅作为参考。
- 坑8:只压核心接口,忽略非核心接口,导致线上非核心接口先崩,影响核心链路。正确做法:压测模型必须与线上真实流量占比一致,覆盖所有核心和非核心链路。
- 坑9:单次压测就得出结论,结果存在偶然性。正确做法:每次优化后,重复压测3次以上,取平均值,确保结果的稳定性和准确性。
- 坑10:压测过程中不监控,只看最终结果,无法定位瓶颈出现的时间点和根因。正确做法:压测前搭建完整的监控体系,压测过程中实时监控全链路指标,出现异常立即停止。
八、总结
全链路压测不是一次性的活动,而是分布式系统性能治理的持续过程。它的核心价值,不是为了测出系统的极限TPS,而是通过模拟真实的线上流量场景,提前暴露系统的隐藏瓶颈,通过标准化的瓶颈定位方法论,找到根因,通过可落地的性能优化方案,提升系统的承载能力与稳定性,最终保障线上业务的平稳运行。性能优化没有银弹,只有基于真实场景的压测、精准的根因定位、持续的优化迭代,才能打造出高可用、高性能的分布式系统。