目录
前言
最近我在接触一套内部网关服务,一开始看这套流程的时候其实挺懵的。 脑子里总有几个问题反复打转: (1)客户端为什么只带一个 `sk-...` 形式的 token 就能访问不同服务? (2)网关到底是怎么知道该把请求转发到哪里去的? (3)路由和策略分别在管什么? (4)凭证池又是什么,为什么有些服务不需要客户端自己传真实 API Key? (5)请求失败了,网关为什么还能自动重试? 这段时间边看边改、边踩坑边理解,终于把这条链路大体理顺了。 这篇文章就想用一种尽量白话的方式,把整个流程讲清楚。
一、先看整体:这套网关到底在做什么
如果先不看代码,只看它的职责,这套网关其实可以概括成一句话:
客户端只需要带内部 token 访问统一入口,网关再根据服务名、路由配置、策略配置和凭证池配置,自动完成鉴权、限流、额度控制、凭证注入和请求转发。
也就是说,客户端并不需要直接知道:
- 真正的上游地址是什么
- 上游服务要求什么认证头
- 真实外部 API Key 是什么
- 某个服务失败后怎么切换到下一套凭证
这些复杂的事情,统一由网关接管。下边是一张全链路的治理架构图:
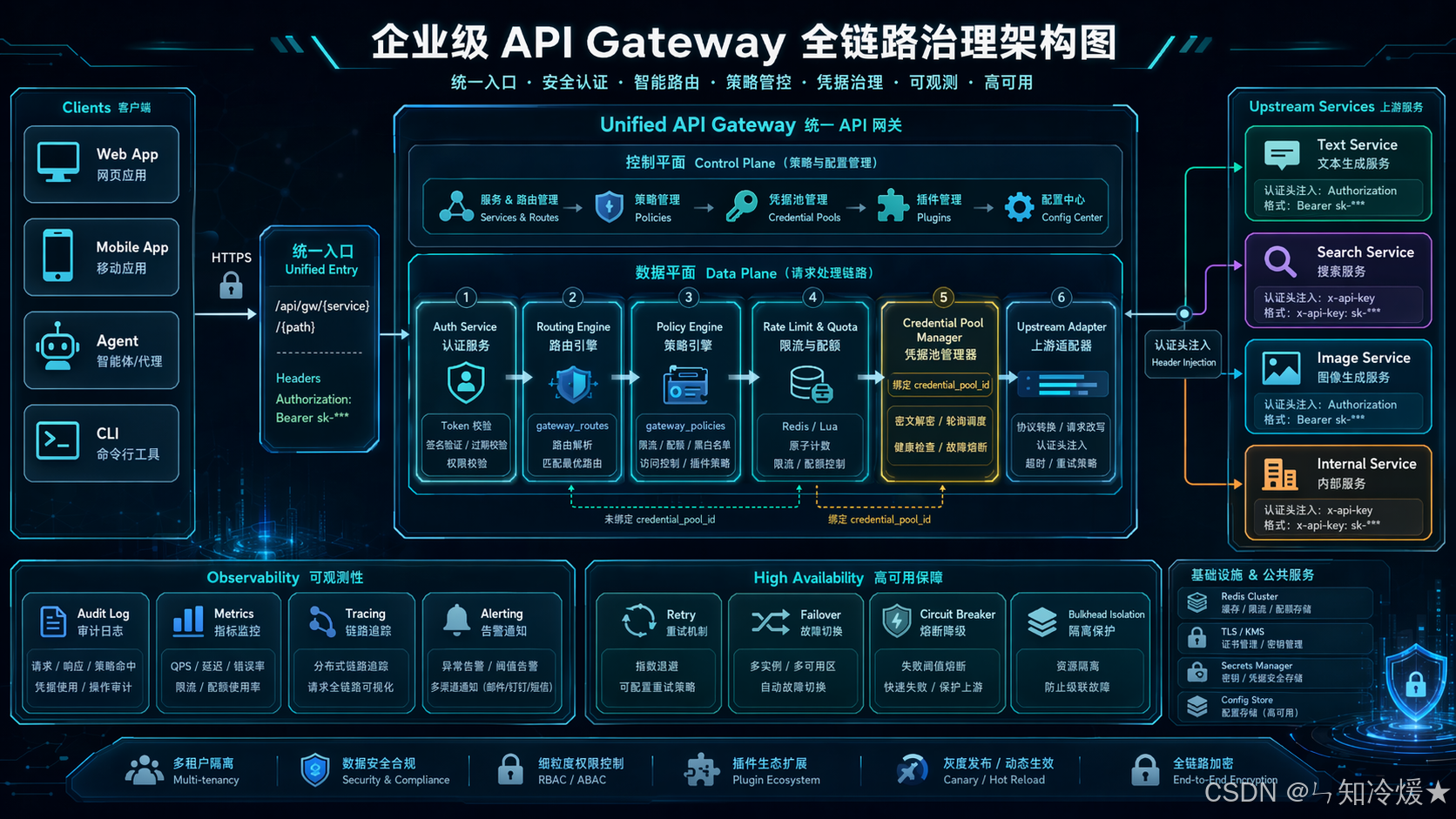
1-1、统一入口长什么样
所有请求都走这一类地址:
text
/api/gw/{service_name}/{path}比如:
text
/api/gw/text-service/v1/chat/completions
/api/gw/search-service/v1/query
/api/gw/image-service/v1/generate可以把它拆成三部分理解:
/api/gw:固定前缀,表示走网关{service_name}:服务名,比如text-service、search-service、image-service{path}:要转发给上游服务的具体路径
这里最关键的一点是:
service_name决定"走哪条路由"path决定"访问上游服务的哪个接口"
1-2、这套设计解决了什么问题
从结果上看,这套网关解决的是几个典型问题:
- 客户端不需要知道真实上游地址
- 客户端不需要接触真实外部 API Key
- 网关可以统一做鉴权、限流、额度控制
- 不同上游服务的认证差异可以在网关层适配
- 多个凭证可以统一放到凭证池里做故障切换
所以它不只是"转发请求的中间层",更像是一个统一治理层。
二、请求是怎么进入网关的
2-1、客户端先带什么信息
客户端在调用网关时,必须先带内部 token,也就是:
http
Authorization: Bearer sk-...这个 token 不是上游厂商的真实 API Key,而是平台内部 token。
它主要用来完成两件事:
- 证明你有权限访问网关
- 让网关对你做限流、额度控制、审计
所以从客户端的角度来看,最重要的一件事其实就是:
我只要拿着内部 token 去请求网关即可。
2-2、网关收到请求后先干什么
请求进来之后,网关不会立刻转发,而是先做鉴权。
它会检查:
- 有没有
Authorization头 - 格式是不是
Bearer sk-... - 这个 token 是否存在
- token 状态是否正常
- 是否还有额度
- 是否超过频率限制
如果这里不通过,请求就不会继续往下走。
所以这一步本质上是:
先确认"你是谁,你能不能用"。
2-3、为什么这一层不能省
很多人一开始会想:
既然最后还是要转发到上游,为什么不直接调上游?
原因就在这里。
这层内部 token 鉴权,是平台控制整个调用体系的基础。
它让平台可以统一知道:
- 谁在调用
- 调了哪个服务
- 调了多少次
- 有没有超额
- 后续是否需要审计
没有这层,客户端就只能直接面对各个上游服务,平台就很难做统一治理。
三、路由和策略分别在干什么
这是我一开始最容易混的地方。
后来我发现,可以把这两个东西简单理解成:
gateway_routes决定"请求往哪儿走"gateway_policies决定"请求怎么管"
3-1、路由:决定请求发到哪里
客户端请求的是:
text
/api/gw/{service_name}/{path}所以网关会根据 service_name 去数据库里查路由配置,主要查这张表:
gateway_routes
这张表一般会告诉网关:
- 这个服务名对应哪个上游地址
- 协议类型是什么
- 是否绑定了凭证池
- 是否启用
- 超时时间是多少
例如:
service_name = text-servicetarget_url = https://upstream.example.com
那么如果客户端请求的是:
text
/api/gw/text-service/v1/chat/completions网关最终就会把它拼成:
text
https://upstream.example.com/v1/chat/completions所以路由负责的事情很简单:
决定这个请求最终要发到哪里。
3-2、策略:决定请求怎么被限制
除了查路由,网关还会查策略表:
gateway_policies
这张表主要负责定义:
- 限流值
- 配额值
- 匹配哪些 path
- 是对整个服务生效,还是只对某些接口生效
所以策略负责的是:
决定这个请求能不能放行,以及能用多少、用多快。
3-3、限流和额度控制在哪里发生
这是整套流程里非常关键的一层。
很多人会以为:
token 合法就一定能调
其实不是。
token 合法只是第一步,后面还会继续做限流和额度控制。
网关会根据:
- 当前
service_name - 当前
path - 当前调用者身份
- 对应策略配置
- token 自己的额度信息
去判断:
- 当前频率有没有超
- 当前总额度还有没有剩余
- 当前时间窗口内是否允许继续调用
所以这一步本质上是在解决:
你虽然有资格进来,但这次还能不能继续用。
四、凭证池到底是干什么的
这是整套系统里最有意思的一层,也是我最近才真正搞懂的地方。
4-1、为什么还要有凭证池
客户端带进来的 sk-...,只是平台内部 token。
但很多时候,真正转发给上游服务时,网关还需要另外一套"真实外部凭证"。
这时就会用到凭证池。
如果某条路由绑定了 credential_pool_id,说明这个服务背后还有一层真实凭证管理。
网关会根据路由配置,到对应的凭证池里找一个可用凭证。
背后通常会涉及这几张表:
credential_poolscredentials
它们一起完成这些事:
- 找到当前路由绑定的凭证池
- 从池里挑一个可用凭证
- 把加密存储的密文解密成真实 key
- 准备注入到上游请求头里
所以凭证池的意义可以理解成:
客户端只管访问网关,网关代替客户端去保管和使用真实外部凭证。
4-2、为什么不同服务的请求头可能不一样
这里还有一个特别容易误解的点。
并不是所有上游服务都用同一种认证头。
例如:
有些服务要求:
http
Authorization: Bearer xxx有些服务则要求:
http
x-api-key: xxx所以网关拿到真实凭证之后,还要根据服务类型决定:
这个凭证应该放在哪个请求头里发给上游。
也就是说,这里其实有两层鉴权:
第一层是:
- 客户端 -> 网关
- 用
Authorization: Bearer sk-...
第二层是:
- 网关 -> 上游
- 用真实外部凭证
- 但具体放在
Authorization还是x-api-key,要看上游要求
4-3、凭证池的价值到底是什么
这一层带来的好处非常明显:
- 客户端不需要接触真实上游 API Key
- 真实 key 统一由服务端托管
- 一条路由可以挂多个凭证
- 某个凭证失败时可以切换下一套
- 上游凭证更新时不需要改客户端
所以凭证池其实是这套系统"安全性"和"可维护性"的核心之一。
五、请求真正转发时,网关都做了什么
5-1、网关最终是怎么转发的
当前面的几步都通过后,网关才会真正开始往上游发请求。
这时它已经拿到了:
- 目标上游地址
- 完整 path
- 过滤后的请求头
- 注入好的上游凭证
- 请求体
- 查询参数
然后它会把请求转发给真正的目标服务。
例如客户端访问的是:
text
/api/gw/text-service/v1/chat/completions但网关真正发出去的可能是:
text
https://upstream.example.com/v1/chat/completions或者客户端访问的是:
text
/api/gw/search-service/v1/query而网关最终发出去的可能是:
text
https://search.example.net/v1/query5-2、失败之后为什么还能继续试
这套系统还有一个很实用的能力:
- 支持失败重试
- 支持故障切换
如果某个凭证在调用上游时失败了,比如:
- 被限流
- 被拒绝
- 暂时不可用
网关不会立刻把整个请求判死,而是可能会:
- 把当前凭证标记为冷却
- 从同一个凭证池里取下一个可用凭证
- 再重试一次
所以这一步可以理解成:
把"单把钥匙失效"变成"自动换一把钥匙继续试"。
5-3、把整个流程串起来看
如果按顺序把整个流程串起来,其实很清晰:
第一步,客户端发请求:
text
/api/gw/{service_name}/{path}并带上:
http
Authorization: Bearer sk-...第二步,网关做内部鉴权。
第三步,查 gateway_routes,得到:
- 上游
target_url - 是否绑定凭证池
第四步,查 gateway_policies,得到:
- 限流规则
- 配额规则
第五步,做限流和额度控制。
第六步,如果绑定了凭证池,就去:
credential_poolscredentials
拿一个可用真实凭证。
第七步,根据不同服务,把真实凭证放到:
Authorization- 或
x-api-key - 或其他上游要求的位置
第八步,把请求转发到真实服务地址。
第九步,如果失败,就触发:
- 重试
- 凭证切换
- 故障转移
六、我现在对这套设计的理解
6-1、为什么现在觉得它合理了
以前我会觉得这套设计有点绕,
为什么不让客户端直接拿真实外部 key 去调上游服务?
现在再回头看,它其实非常合理。
第一,安全性更高。
客户端不需要接触真实外部凭证,真实 key 全部保存在服务端。
第二,客户端更简单。
客户端只管一个内部 token,不需要知道各种上游服务的差异。
第三,服务治理更统一。
鉴权、限流、额度、审计、策略控制都统一放在网关层处理。
第四,更适合扩展。
以后如果再接一个新服务,只需要补:
- 一条路由
- 一条策略
- 一个凭证池
客户端调用方式基本不用变。
第五,更适合高可用。
凭证池、失败重试、故障切换这些能力,能直接提升外部调用的稳定性。
6-2、我踩过的几个认知坑
最近边学边改的时候,我自己最容易掉进去的几个坑,也顺手记一下。
第一个坑 :以为客户端传给网关的 Authorization 会原样发给上游。
其实不是。客户端的 Authorization: Bearer sk-... 是给网关自己的。上游那一层的认证头,通常是网关重新注入的。
第二个坑 :以为后台上传了凭证,客户端就什么都不用管了。
也不是。后台上传凭证解决的是"网关 -> 上游"这层认证。客户端 -> 网关 这一层仍然需要内部 token。
第三个坑 :以为所有上游都吃 Bearer。
其实不同上游可能要求不同头:
- 有的要
Authorization - 有的要
x-api-key
所以网关有时候需要做服务级别的适配。
第四个坑 :以为路由表里会存完整接口地址。
通常不是。路由表里更多存的是 target_url 这种基础地址,而具体 path 是来自客户端请求里的 {path}。
6-3、我现在最简单的理解
如果让我现在用一句话总结这套流程,我会这么说:
客户端拿内部 token 访问统一网关入口,网关先鉴权、查路由、查策略、做限流和额度控制;如果绑定了凭证池,就自动取真实上游凭证并注入请求头,最后把请求转发到真正的目标服务;如果失败,还能重试和切换凭证。
对刚开始接触这类系统的人来说,这一套一开始确实会觉得绕。
但一旦把每一层拆开理解,就会发现它其实很合理。
如果你也像我一样,刚开始看网关系统时有点懵,我建议先别一上来就盯着代码细节看,先强行把问题拆成这 5 句:
- 客户端拿什么访问网关?
- 网关怎么知道请求发到哪里?
- 网关怎么判断这个请求能不能放行?
- 网关从哪里拿真实上游凭证?
- 网关最终把什么头发给上游?
只要这 5 句想清楚了,整条链路基本也就通了。