目录
protobuf介绍
Protocol Buffers(简称protobuf)是Google开发的一种语言无关、平台无关的序列化数据结构的方法,它能将结构化的数据高效地序列化为紧凑的二进制格式,常用于数据存储和网络通信。
主要优势
高效性:相比JSON和XML等文本格式,Protobuf序列化后的数据体积更小(通常小3-10倍),序列化和反序列化的速度也更快,能显著提升性能。
跨语言与平台无关性:通过定义一次.proto数据结构描述文件,可以生成对应Java、C++、Python、Go等多种语言的代码,支持多个平台。
向后兼容性强:可以在不破坏现有代码的情况下,对数据结构进行扩展(如添加新字段),确保了系统的平滑升级。
用途:存储数据持久化(将复杂的数据结构如对象、结构体高效地存储到文件或数据库中)、网络数据传输。
protobuf的使用特点
protobuf是需要依赖protoc编译器编译.proto文件生成的头文件和源文件来使用的。
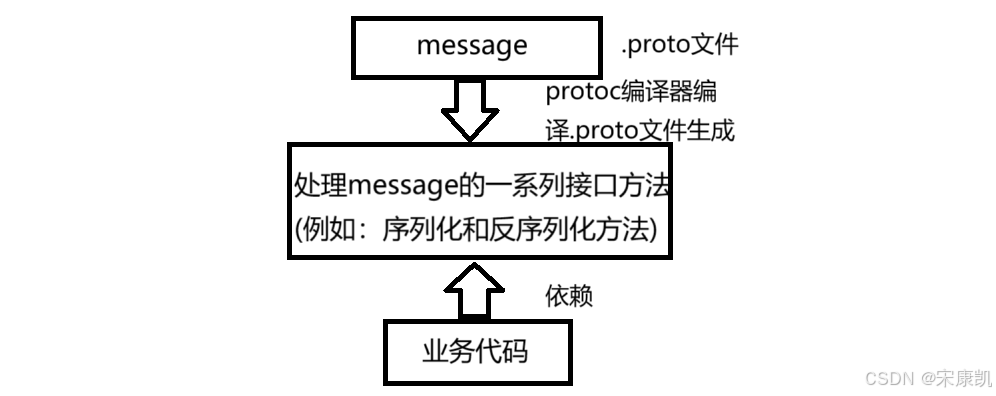
protobuf的最大好处就是帮我们自动生成:获取和设置message字段的方法,以及序列化和反序列化message结构数据的方法(这些方法代码都是需要使用protoc编译指令才能生成的,供我们自己的业务使用),大大提高了效率。
安装protobuf
protobuf下载网址:https://github.com/protocolbuffers/protobuf/releases
本博客以protobuf的v21.11版本为例。
Windows下安装(x64为例)
(1)下载压缩包

(2)解压

protoc编译器在bin目录中

(3)配置环境变量
将protoc编译器所在地路径配置到系统地path环境变量中

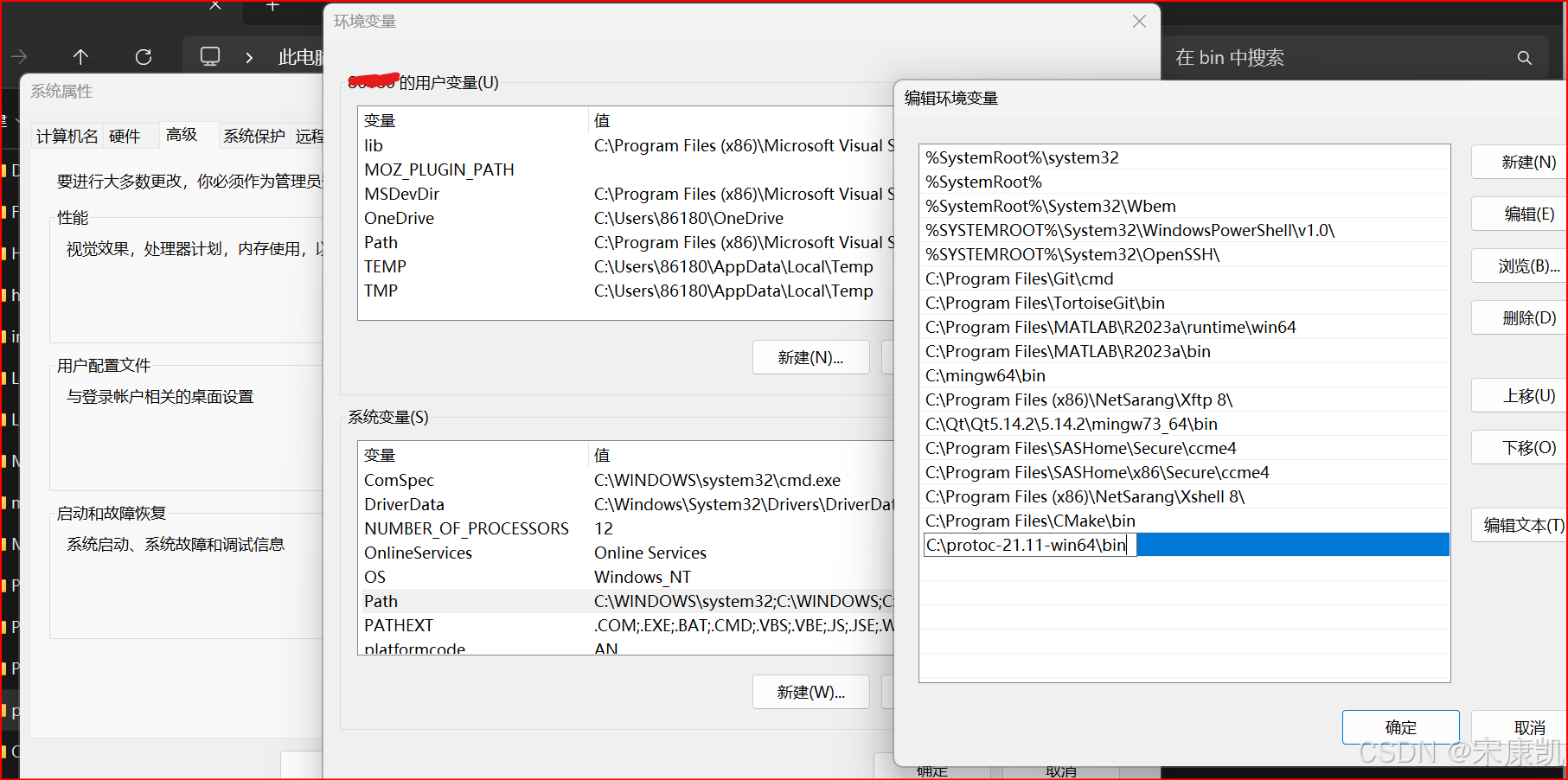
(4)使用Windows中执行protoc --version命令查看其版本

Linux下安装(Ubuntu22.04为例)
安装ProtoBuf前一定要先安装依赖库:autoconf automake libtool curl make g++ unzip
(1)执行安装依赖库指令:
bash
sudo apt-get install autoconf automake libtool curl make g++ unzip -y(2)下载压缩包

我这里下载所有语言通用的zip包
bash
wget https://github.com/protocolbuffers/protobuf/releases/download/v21.11/protobuf-all-21.11.zip(3)解压下载的zip包到当前目录下
bash
unzip protobuf-all-21.11.zip -d ./(4)解压完成后,进入protobuf-21.11目录

进入该目录后,主要执行下图中两个可执行程序

(5)执行./autogen.sh,但如果下载的具体的某一语言zip包,不需要执行这一步。
(6)有两种执行方式任选其中一种即可。1.执行./configure,protobuf默认安装在/usr/local目录,lib、bin、include都是分散的;2.执行./configure --prefix=/usr/local/protobuf,修改安装目录(执行下面的sudo make install指令时),统一安装到/usr/local/protobuf目录下。
执行完上面指令后就会在protobuf-21.11目录下看到生成的makefile文件

(7)然后依次执行make、make check、sudo make install
执行sudo make install后如果使用的是第二种./configure --prefix=/usr/local/protobuf指令的,此时/usr/local目录下就会生成一个protobuf目录这个目录中就有bin、lib、include。如下:

现在回忆一下刚才执行./configure是用的那种方式,如果是第二种方式即修改了安装目录,那么需要在**/etc/profile文件**中添加一些内容。如下:
bash
# 添加内容如下:
#(动态库搜索路径) 程序加载运⾏期间查找动态链接库时指定除了系统默认路径之外的其他路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/
#(静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/
#执⾏程序搜索路径
export PATH=$PATH:/usr/local/protobuf/bin/
#c程序头⽂件搜索路径
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/
#c++程序头⽂件搜索路径
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/
#pkg-config 路径
export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/重新执行/etc/profile文件使其生效
bash
source /etc/profileprotobuf快速上手
protobuf的工作流程
- 编写.proto文件,在该文件中自定义message结构体信息。
- 使用protoc命令对.proto文件进行编译,会生成对应编程语言关于message结构体类代码(头文件代码和源文件代码),生成的这些代码中有获取、设置、序列化、反序列化message结构体类中的数据的方法。
- 我们自己的业务代码依赖生成的头文件代码和源文件代码。
编译.proto文件
protoc --proto_path=.proto所在的路径 --cpp_out=目的路径 需要编译的.proto
通过编译这个contacts.proto文件看肯到底生成了那些代码
cpp
//contacts.proto
syntax = "proto3"; //protobuf的版本
package contacts; //命名空间
message PeopleInfo{
string name = 1;
int32 age = 2;
}分析生成的C++代码
使用protoc命令编译contacts.proto文件,会生成一个头文件和一个源文件

contacts.pb.h中是有一个PeopleInfo的类,这个类中有获取和设置每个字段的方法。
cpp
//contacts.pb.h部分源码
namespace contacts{
class PeopleInfo final :
public ::PROTOBUF_NAMESPACE_ID::Message /* @@protoc_insertion_point(class_definition:contacts.PeopleInfo) */ {
public:
/*...*/
// string name = 1;
void clear_name();
const std::string& name() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_name(ArgT0&& arg0, ArgT... args);
std::string* mutable_name();
PROTOBUF_NODISCARD std::string* release_name();
void set_allocated_name(std::string* name);
private:
const std::string& _internal_name() const;
inline PROTOBUF_ALWAYS_INLINE void _internal_set_name(const std::string& value);
std::string* _internal_mutable_name();
// int32 age = 2;
void clear_age();
int32_t age() const;
void set_age(int32_t value);
private:
int32_t _internal_age() const;
void _internal_set_age(int32_t value);
};
}生成的C++代码中的PeopleInfo类继承自Message类,而Message类继承自MessageLite类,MessageLite类中有序列化和反序列化生成的C++代码中的PeopleInfo类的方法。
cpp
//Message类部分源码
class MessageLite {
public:
//序列化
// Serialize the message and write it to the given C++ ostream. All
// required fields must be set.
bool SerializeToOstream(std::ostream *output) const;
// Serialize the message and store it in the given string. All required
// fields must be set.
bool SerializeToString(std::string *output) const;
// Serialize the message and store it in the given byte array. All required
// fields must be set.
bool SerializeToArray(void *data, int size) const;
//反序列化
// Parse a protocol buffer from a C++ istream. If successful, the entire
bool ParseFromIstream(std::istream* input);
// Parses a protocol buffer contained in a string. Returns true on success.
bool ParseFromString(const std::string& data);
// Parse a protocol buffer contained in an array of bytes.
bool ParseFromArray(const void* data, int size);
};注意:.proto文件通过protoc指令编译生成C++代码,.protoc文件中的每个message消息类型都会有对应的一个C++类这个C++类名就是message消息类型名,message消息结构中的字段都会在生成的C++类中存在且名称一致,生成的C++类中也会有获取、设置、清除这些字段的值的方法,这些方法的命名都是以原始字段名(.proto文件中的message消息类型中的定义的字段名)来扩展的。
使用示例
一个使用protobuf序列化和反序列化结构数据的例子
cpp
#include <iostream>
#include "contacts.pb.h"
using namespace std;
int main()
{
string people_str = "";
{
contacts::PeopleInfo people;
people.set_name("hello");
people.set_age(21);
if (!people.SerializeToString(&people_str)) {
cerr << "序列化失败!" << endl;
return 1;
}
cout << "序列化结果: " << people_str << endl;
}
{
contacts::PeopleInfo people;
if (!people.ParseFromString(people_str)) {
cerr << "反序列化失败!" << endl;
return 2;
}
cout << "name: " << people.name() << endl;
cout << "age: " << people.age() << endl;
}
return 0;
}makefile文件:
cpp
test:main.cpp contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
.PHONY:clean
clean:
rm -f test contacts.pb.*注意:使用g++编译代码的时候需要加上-std=c++11(通过protoc指令编译.proto文件生成的C++代码中是涉及到C++11中的特性的)和-lprotobuf(需要指定链接的protobuf库)。

在终端打印显示存在乱码,protobuf序列化后的数据是紧凑且高效的二进制数据,此例中使用string对象接收序列化后的二进制字节序列因此会出现空格乱码,而JSON和XML序列化后的数据是文本数据,因此protobuf是相对于JSON和XML是比较安全的。
消息字段的定义
在.proto文件中需要定义message消息类型,该结构中需要定义字段。
字段定义格式
字段类型 字段名 = 字段唯一编号(该编号在一个message中必须是唯一的,不同message中的字段编号可以重复)
字段名命名规范
全小写字母,多个字母用_连接。
字段规则
加在字段类型的前面。
singular:message中的字段默认就是这个规则。message消息类型中可以包含该字段1次或0次。
repeated:将字段设置为了数组。message消息类型中可以包含该字段任意次(包含0次)。
字段类型
标量数据类型和特殊数据类型(包含enum、Any等类型)。
标量数据类型
| .proto Field Type | Notes | C++ Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码。负数的编码效率低,若字段可能为负值应使用sint32代替 | int32 |
| int64 | 使用变长编码。负数的编码效率低,若字段可能为负值应使用sint64代替 | int64 |
| uint32 | 使用变长编码 | uint32 |
| uint64 | 使用变长编码 | uint64 |
| sint32 | 使用变长编码 | int32 |
| sint64 | 使用变长编码 | int64 |
| fixed32 | 定长4字节。若字段值常大于2^28则效率高于uint32 | uint32 |
| fxed64 | 定长8字节。若字段值常大于2^56则效率高于uint64 | uint64 |
| sfixed32 | 定长4字节 | int32 |
| sfixed64 | 定长4字节 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串 | string |
| bytes | string |
注:变长编码是指经过protobuf编码后,原本4字节或8字节的的数据可能会被变为其他字节数的数据。
字段唯一编号
用来标识字段,字段编号一旦开始使用就不能更改。
字段编号19000~19999被作为预留编号,不能使用。
字段编号1~15被protobuf编码后只占1个字节,字段编号16~2047被protobuf编码后占2个字节,因此我们需要让非常频繁使用的字段来使用字段编号1~15。
message类型其他用法
可以导入其他.proto文件中的message消息类型
使用import可将其他.proto文件导入其他的.proto文件中,这里要注意命名空间的正确指定,在.proto文件中使用 . 来指定命名空间相当于C++中的作用域限定符 :: 。
bash
//Phone.proto
syntax = "proto3"; //protobuf的版本
package contacts_2; //命名空间
message Phone{
string number = 1;
}
cpp
//PeopleInfo.proto
syntax = "proto3"; //protobuf的版本
package contacts_1; //命名空间
import "Phone.proto";
message PeopleInfo{
string name = 1;
int32 age = 2;
repeated contacts_2.Phone phones = 3;
}message消息类型可作为字段类型
.proto文件中可以定义多个message消息类型,message消息类型可作为字段类型嵌套使用,可多层嵌套。如下:在PeopleInfo中嵌套Phone类型message数组。
cpp
//contacts.proto
syntax = "proto3"; //protobuf的版本
package contacts; //命名空间
message PeopleInfo{ //联系人
string name = 1;
int32 age = 2;
message Phone{
string number = 1;
}
repeated Phone phones = 3;
}
message Contacts{ //通讯录
repeated PeopleInfo contacts = 1;
}分析生成的C++代码
通过编译这个contacts.proto文件发现生成contacts.pb.h中C++代码里有一个PeopleInfo_Phone类(这个类就是消息类型PeopleInfo中嵌套的消息类型Phone生成的C++类):
cpp
class PeopleInfo_Phone final : public Message{
public:
// string number = 1;
void clear_number();
const std::string &number() const;
template <typename ArgT0 = const std::string &, typename... ArgT>
void set_number(ArgT0 &&arg0, ArgT... args);
std::string *mutable_number();
};看看这个message数组生成的C++代码是怎样的:
cpp
class PeopleInfo final : public Message {
public:
// repeated .contacts.PeopleInfo.Phone phones = 3;
int phones_size() const;
void clear_phones();
::contacts::PeopleInfo_Phone *mutable_phones(int index);
::PROTOBUF_NAMESPACE_ID::RepeatedPtrField<::contacts::PeopleInfo_Phone> *
mutable_phones();
const ::contacts::PeopleInfo_Phone &phones(int index) const;
::contacts::PeopleInfo_Phone *add_phones();
const ::PROTOBUF_NAMESPACE_ID::RepeatedPtrField<
::contacts::PeopleInfo_Phone> &
phones() const;
};使用示例
使用嵌套的message消息类型,将联系人对象序列化到文件中。这里为了也演示从文件中反序列化数据到对象中,采取的流程是:先从文件中反序列化数据到联系人对象中,在向联系人对象中添加新的联系人,最后将这些联系人数据全部序列化到文件中。
cpp
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
void AddPeopleInfo(contacts_1::PeopleInfo* peopleinfo)
{
cout << "--------------新增联系人---------------" << endl;
cout << "请输入联系人的姓名: ";
string name = "";
getline(cin, name);
peopleinfo->set_name(name);
cout << "请输入联系人的年龄: ";
int age = 0;
cin >> age;
peopleinfo->set_age(age);
cin.ignore(numeric_limits<streamsize>::max(), '\n');//清空缓冲区中的字符直到遇到'\n',并且也将'\n'清除掉
for(int i = 1;;++i){
cout << "请输入联系人的电话" << i << "(只输入回车完成电话新增): ";
string number = "";
getline(cin, number);
if(number.empty()){
break;
}
contacts_1::PeopleInfo_Phone* phone = peopleinfo->add_phones();
phone->set_number(number);
}
cout << "-------------新增联系人成功-------------" << endl;
}
//将对象数据序列化到文件中
int main()
{
contacts_1::Contacts contacts;
fstream input("contacts.bin", ios::in | ios::binary);
if(!input){
cout << "contacts.bin not find, create it." << endl;
}
else if(!contacts.ParseFromIstream(&input)){
cerr << "parse err!" << endl;
input.close();
return 1;
}
AddPeopleInfo(contacts.add_contacts());
fstream output("contacts.bin", ios::out | ios::binary | ios::trunc);//std::ios::out模式下文件不存在则创建文件
if(!output){
cerr << "open contacts.bin err!" << endl;
input.close();
return 2;
}
if(!contacts.SerializeToOstream(&output)){
cerr << "serialize err!" << endl;
input.close();
output.close();
return 3;
}
cout << "write success." << endl;
input.close();
output.close();
return 0;
}特殊字段类型
enum类型
给Phone消息类型中加入一个enum类型的字段,也就是在message消息类型中嵌套enum枚举类型,对应的PeopleInfo消息类型如下:
cpp
message PeopleInfo{
string name = 1;
int32 age = 2;
message Phone{
string number = 1;
enum PhoneType{
MP = 0; //移动电话
LP = 1; //固定电话
}
PhoneType type = 2;
}
repeated Phone phones = 3;
}枚举类型名称:驼峰法定义,首字母大写。常量值定义:为大写字母,多个字母用_连接。
注意:enum类型中的第一个常量值必须是0(这是为了与proto2语法兼容),不建议使用负数作为常量值。
分析生成的C++代码
cpp
namespace contacts_1 {
enum PeopleInfo_Phone_PhoneType : int {
PeopleInfo_Phone_PhoneType_MP = 0,
PeopleInfo_Phone_PhoneType_LP = 1,
};
class PeopleInfo_Phone final : public ::PROTOBUF_NAMESPACE_ID::Message {
// .contacts_1.PeopleInfo.Phone.PhoneType type = 2;
public:
void clear_type();
::contacts_1::PeopleInfo_Phone_PhoneType type() const;
void set_type(::contacts_1::PeopleInfo_Phone_PhoneType value);
private:
::contacts_1::PeopleInfo_Phone_PhoneType _internal_type() const;
void _internal_set_type(::contacts_1::PeopleInfo_Phone_PhoneType value);
};
}可以看到在命名空间contacts_1中生成了一个PeopleInfo_Phone_PhoneType的枚举类,PeopleInfo_Phone类生成了获取、设置、清除type变量的方法。
Any类型
Any类型可以理解为泛型类型,Any类型中可以存储任意message消息,Any类型字段可用repeated修饰。
Any类型是Google已经定义好的类型,在安装protobuf的时,安装的protobuf的include目录中就有一个Any.proto文件,我当时安装的时候是将protobuf的include目录放在了自己创建的名为protobuf的目录下,而any.proto是在这个include目录下的google/prtotobuf目录下:

使用vi /usr/local/protobuf/include/google/protobuf/any.proto查看Any类型如下:
cpp
//any.proto源码
syntax = "proto3";
package google.protobuf;
message Any {
string type_url = 1;
bytes value = 2;
}向PeopleInfo消息类型中添加一个表示联系人的地址信息Address消息类型字段,对应的PeopleInfo消息类型如下:
cpp
syntax = "proto3"; //protobuf的版本
package contacts_1; //命名空间
import "google/protobuf/any.proto"; //导入any.proto中的内容
message Address{
string home_address = 1; //家庭地址
string work_address = 2; //工作地址
}
message PeopleInfo{
string name = 1;
int32 age = 2;
message Phone{
string number = 1;
enum PhoneType{
MP = 0; //移动电话
LP = 1; //固定电话
}
PhoneType type = 2;
}
repeated Phone phones = 3;
google.protobuf.Any data = 4; //需要指定对应的命名空间google.protobuf
}使用vi /usr/local/protobuf/include/google/protobuf/any.pb.h查看C++代码Any类:
cpp
//any.pb.h部分源码
PROTOBUF_NAMESPACE_OPEN //其实这是用#defined定义的命名空间开始宏
class PROTOBUF_EXPORT Any final : public ::PROTOBUF_NAMESPACE_ID::Message {
bool PackFrom(const ::PROTOBUF_NAMESPACE_ID::Message &message) {
GOOGLE_DCHECK_NE(&message, this);
return _impl_._any_metadata_.PackFrom(GetArena(), message);
}
bool PackFrom(const T& message) {
return _impl_._any_metadata_.PackFrom<T>(GetArena(), message);
}
bool UnpackTo(::PROTOBUF_NAMESPACE_ID::Message *message) const {
return _impl_._any_metadata_.UnpackTo(message);
}
bool UnpackTo(T* message) const {
return _impl_._any_metadata_.UnpackTo<T>(message);
}
template<typename T> bool Is() const {
return _impl_._any_metadata_.Is<T>();
}
};
PROTOBUF_NAMESPACE_CLOSE //其实这是用#defined定义的命名空间结束宏注意:在C++代码中使用Any类型要加上google::protobuf命名空间,PROTOBUF_NAMESPACE_OPEN和PROTOBUF_NAMESPACE_CLOSE就是两个宏,在系统的的/usr/local/protobuf/include/google/protobuf/port_def.inc中有定义,因此在C++代码中使用Any时要带上google::protobuf命名空间,在.proto文件中使用Any也是一样的。
cpp
port_def.inc部分源码
#define PROTOBUF_NAMESPACE_OPEN \
namespace google { \
namespace protobuf {
#define PROTOBUF_NAMESPACE_CLOSE \
} /* namespace protobuf */ \
} /* namespace google */PackFrom方法:将任意消息类型转换为Any类型。
UnPackto方法:将Any类型转换回之前对应的任意消息类型。
Is方法:判断Any存放的消息类型是否为typename T。
分析生成的C++代码
cpp
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
// .google.protobuf.Any data = 4;
bool has_data() const;
void clear_data();
const ::PROTOBUF_NAMESPACE_ID::Any &data() const;
PROTOBUF_NODISCARD ::PROTOBUF_NAMESPACE_ID::Any *release_data();
::PROTOBUF_NAMESPACE_ID::Any *mutable_data();
};has_data方法:检查这个Any类型的字段是否被设置。
oneof类型
如果现在消息类型中有多个可选字段,但是将来只有一个可选字段会被设置,那么就可以使用oneof类型,也能有节约内存的效果。
给PeopleInfo消息类型中加入一个其他联系方式字段,可能时qq也可能时wechat,因此就需要oneof类型。
cpp
message PeopleInfo{
/*...*/
oneof other_contact{
string qq = 5;
string wechat = 6;
}
}注意:1.可选字段中的编号不能与非可选字段编号冲突。2.不能repeated修饰oneof里的可选字段。3.如果同时设置oneof中的多个可选字段,那么只会将最后设置的可选字段保留下来,其他的会被清除掉。
分析生成的C++代码
cpp
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
enum OtherContactCase {
kQq = 5,
kWechat = 6,
OTHER_CONTACT_NOT_SET = 0,
};
public:
// string qq = 5;
bool has_qq() const;
void clear_qq();
const std::string &qq() const;
template <typename ArgT0 = const std::string &, typename... ArgT>
void set_qq(ArgT0 &&arg0, ArgT... args);
std::string *mutable_qq();
public:
// string wechat = 6;
bool has_wechat() const;
void clear_wechat();
const std::string &wechat() const;
template <typename ArgT0 = const std::string &, typename... ArgT>
void set_wechat(ArgT0 &&arg0, ArgT... args);
std::string *mutable_wechat();
public:
void clear_other_contact();
OtherContactCase other_contact_case() const;
};other_contacts_case方法:获取设置了oneof中的那个可选字段,这个方法的返回值类型是OtherContactCase,这是生成的C++代码中的一个enum枚举类型,在PeopleInfo类中。
map类型
map<key_type, value_type> map_field = 字段编号;
注意:1. key_type是除float和bytes以外的任意标量类型,value_type可以是任意类型。2.map不能被repeated修饰。map中存的数据是无序的。
cpp
message PeopleInfo{
/*...*/
map<string,string> remark = 7;
}分析生成的C++代码
cpp
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
// map<string, string> remark = 7;
int remark_size() const;
void clear_remark();
const ::PROTOBUF_NAMESPACE_ID::Map<std::string, std::string> &remark() const;
::PROTOBUF_NAMESPACE_ID::Map<std::string, std::string> *mutable_remark();
};默认值
对通过序列化得到的二进制数据进行反序列化时,但是该二进制数据中没有反序列化的目标对象中的字段数据时,那么反序列化后这个目标对象中的这个字段的值就是默认值,不同字段类型的默认字段值不同:
字符串:默认值是空字符串。
字节:默认值是空字节。
布尔值:默认值是false。
数值类型:默认值是0。
枚举值:默认值是第一个枚举常量值必须是0.
被repeated修饰的字段(相当于数组):默认是空的。
对于message类型、Any类型、oneof类型在生成的C++的代码中都有has_方法判断这些类型的字段是否被设置值。
保留(reserved)字段
通过删除或注释掉字段来更新message消息类型结构,未来我们在增加新字段时可能会使用以前存在但已经被删除或注释的字段编号,新增加的字段的使用场景和之前同字段编号的字段使用场景不同,但是其字段编号相同就会导致错误,因为已经被序列化的二进制数据,在进行反序列化时,是按照字段编号反序列化到对应的字段中,这样就会出现数据损坏等问题。
正确的做法是使用reserved将指定字段编号或字段名设置为保留项:
cpp
message exmple{
reserved 1, 2 to 3;
reserved "field4";
int32 field1 = 1;//error
int32 field2 = 2;//error
int32 field3 = 3;//error
int32 field4 = 4;//error
}未知字段
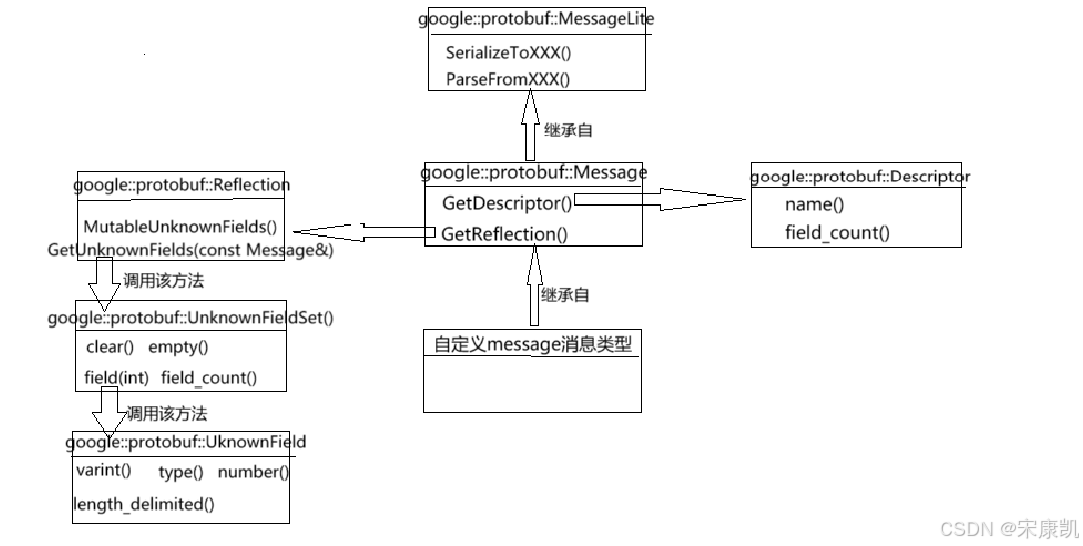
解析良好的protobuf已序列化二进制数中的未识别字段的表示方式。例如:当旧程序反序列化带有新字段的二进制数据,这些新字段就会成为旧程序的未知字段,在proto3.5开始就会保留未知字段。
这是message消息类型和未知字段的关系图:
现在来验证一下:分别有client1(新程序,序列化添加的联系人信息到文件中)和client2(旧程序,从文件中反序列化联系人信息并打印),client1和client2刚开始的.proto文件内容一致,当client1往文件中序列化一个联系人的数据后,然后此时client1中.proto文件字段进行更新,将字段编号为2的age的字段注释掉,增加一个字段编号为3的birthday字段。
cpp
//contact_1.proto和contacts_2.proto
syntax = "proto3"; //protobuf的版本
package contacts_1; //命名空间
message PeopleInfo{
string name = 1;
int32 age = 2;
}
message Contacts{
repeated PeopleInfo contacts = 1;
}client1的main.cpp文件在本博客的 快速上手 部分,这里就不再写了。
client2的mian.cpp文件:
cpp
//client2的main.cpp
#include <iostream>
#include <fstream>
#include <google/protobuf/unknown_field_set.h>
#include "contacts.pb.h"
using namespace std;
void PrintPeopleInfo(const contacts_1::Contacts& contacts)
{
for(int i = 0;i < contacts.contacts_size();++i){
cout << "-----------联系人" << i + 1 << "------------" << endl;
contacts_1::PeopleInfo people = contacts.contacts(i);
cout << "姓名: " << people.name() << endl;
cout << "年龄: " << people.age() << endl;
const google::protobuf::Reflection* reflection = contacts_1::PeopleInfo::GetReflection();
const google::protobuf::UnknownFieldSet& unknown_set = reflection->GetUnknownFields(people);
//打印未知字段
for(int j = 0;j < unknown_set.field_count(); ++j){
const google::protobuf::UnknownField& unknown_field = unknown_set.field(j);
cout << "未知字段编号: " << unknown_field.number()
<< " 类型: " << unknown_field.type();
switch((int)(unknown_field.type())){
case google::protobuf::UnknownField::Type::TYPE_VARINT:
cout << " 值: " << unknown_field.varint() << endl;
break;
case google::protobuf::UnknownField::Type::TYPE_LENGTH_DELIMITED:
cout << " 值: " << unknown_field.length_delimited() << endl;
break;
}
}
}
}
int main()
{
contacts_1::Contacts contacts;
fstream input("../client1/contacts.bin", ios::in | ios::binary);
if(!contacts.ParseFromIstream(&input)){
cerr << "parse err!" << endl;
input.close();
return 1;
}
PrintPeopleInfo(contacts);
input.close();
return 0;
}client1增加一个联系人:
更新client1的contacts_1.proto文件:
cpp
message PeopleInfo{
string name = 1;
//int32 age = 2;
reserved 2;
string birthday = 3;
}接着添加一个联系人信息:

client2从文件中进行反序列化并打印:
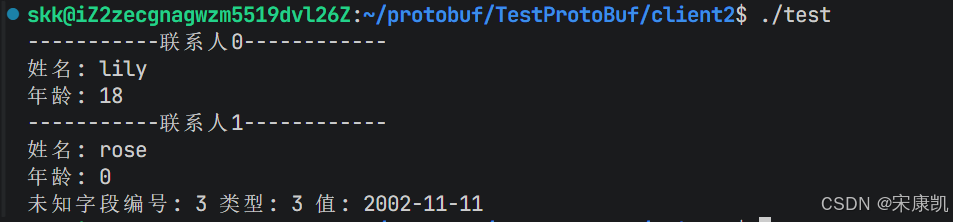
可以看到,client1第二次添加的联系人的 string birthday = 3; 字段,对于client2来说就是未知字段,client2反序列化时没被填充的字段被设置为了该字段类型的默认值,也就是第二个联系人的年龄字段age被设置为了默认值0。
前后兼容性
根据上面的例子可以得到:client1在添加了一个联系人之后,在message消息类型新增加了一个字段编号为3的birthday字段,并将原来的age字段注释,并保留了该字段对应的编号,我这里称此时的client1为"新版本",而client2的.proto文件中的message类型未做更新,我这里称client2为"旧版本",
向前兼容:老版本能够正确识别新版本中新增加的字段,老版本会将birthday字段当作未知字段。
向后兼容:老版本也能正确识别新版本中的字段内容。
老版本反序列化含有字段编号为3的birthday字段二进制数据时,会保留该未知字段;新版本反序列化文件中的含有第一次添加的联系人(该联系人中的字段编号为2对于新版本来说就是未知字段)二进制数据不会出现错误,同时这个第一次添加的联系人中的字段编号为2的age会继续保留在新版本再次序列化到文件的二进制数据中,这体现了前后兼容型。
选项option
.proto文件中可以声明选项,使用option来标注,选项会影响protoc编译器的处理方式。
optimize_for:该选项为文件选项,可以设置protoc编译器的优先级别,分别为:SPEED、CODE_SIZE、LITE_RUNTIME,选择不同的选项值编译.proto文件生成的代码内容不同。
SPEED:protoc生成的代码是高度优化,代码运行效率高,但是使用该选项值编译生成的代码会占用更多空间。SPEED是默认选项。
CODE_SIZE:编译生成的代码占用空间少,但是效率低,适用于包含大量.proto文件和对速度要求不高的项目。
LITE_RUNTIME:编译生成的代码占用空间少,效率高,但是以牺牲protobuf提供的反射功能为代价,因此我们在C++中链接protobuf库时仅需链接libprotobuf-lite,而非libprotobuf。位置字段不会保留、无法通过Descriptor、Reflection等接口在运行时动态访问或修改消息的字段信息(如:遍历字段、按名称获取字段值等),不会生成google::protobuf::Message类的C++代码。