1. AI 编程的一些问题(背景)
你是否在 Vibe Coding 中遇到过这些问题
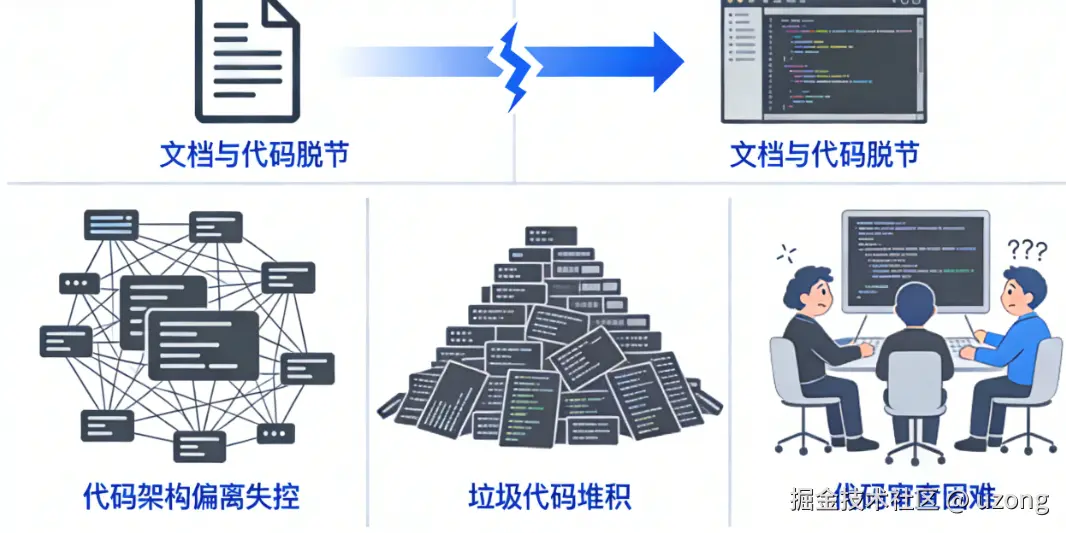
- 文档与代码脱节,上下文跟不上或冗余,导致理解偏差,代码质量越来越差;甚至之前明确告知的禁忌,在后续沟通中仍被遗忘。
- 代码和架构偏离失控:明明一小时能做完的事,却要在反复纠正 Prompt 上绞尽脑汁,审查代码更是难受;特别是反复向对方阐述想法后,实现结果仍难以令人满意。
- 垃圾代码越来越多:不会主动清理上一轮遗留的废代码,反而基于它继续构建,导致废料不断堆积。
- 生成的代码审查起来令人头疼,不敢未经严格审查就直接上线,否则一旦出问题肯定要被背锅
整体看来,缺少的是约束、正确引导和及时修正反馈等机制。Harness Engineering 正是在这一背景下出现的。
2. Harness Engineering 出现
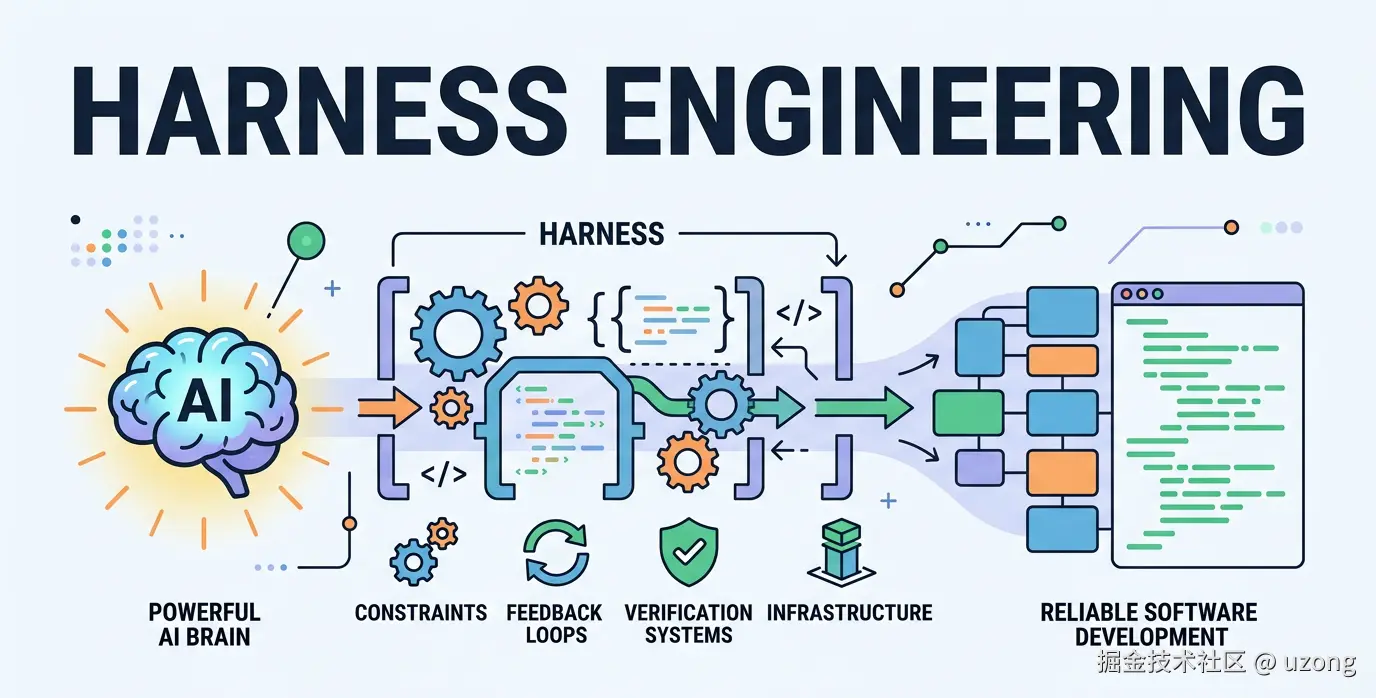
随着工程实践的深入,从上下文工程,逐步进化到 Harness Engineering 了。Harness Engineering 的核心思想可以用一句话概括: "Humans steer, agents execute"(人类掌舵,代理执行) 在这个新范式下,工程师的角色从"代码编写者"转变为"系统驾驭者",其主要任务变为设计能让AI高效、可靠工作的系统和环境,通过环境、工具、规则和反馈机制,让AI在高速奔跑时既能释放全部力量,又不会偏离轨道。Harness Engineering 是一套围绕 AI Agent 构建的约束、反馈与控制系统
3. OpenAI 的百万行代码实验

OpenAI 内部进行了一项为期五个月的实验,充分展示了 Harness Engineering 的潜力:
团队:一个由3人起步的工程师团队。
起点:一个空的 Git 仓库。
过程 :完全依靠 AI 智能体(Codex)进行开发,没有手动编写任何一行源代码。
成果 :构建出一个包含超过 100万行代码 的完整 Beta 版产品。
效率 :期间合并了约1500个拉取请求(PR),OpenAI 估计这种方式比传统开发节省了约 10倍的时间。
利用 5 个月时间,完全依靠 Codex(AI 编码智能体)构建了一个内部复杂产品,交付了近 100 万行代码 。在整个过程中,没有一行代码是由人工手写的。
过程中一些细节:
- 编写了详尽的架构约束
- 为 AI 接入了 Chrome DevTools 协议,使其能通过截图验证 UI 渲染,
- 设计了严密的反馈回路,使得 AI 在 90% 的情况下能自主修复 CI 失败
4. Harness Engineering 的演进
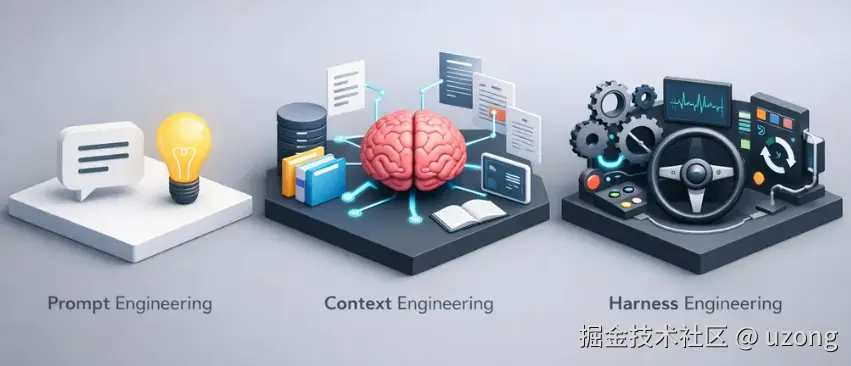
2.1. Prompt Engineering
第一阶段是2022-2024年的提示词工程:这是AI工程化的启蒙阶段。核心逻辑是打磨「一次性指令」。
通过few-shot、角色扮演等技巧,让模型单次输出更精准,本质上是"教AI怎么听一句话"。
这一阶段的局限的在于,指令的有效性高度依赖人工经验,无法实现规模化复用,且难以应对复杂任务的持续输出需求
2.2. Context Engineering
第二阶段是2025年左右的上下文工程:该阶段破解了提示工程的单点局限。此时,行业意识到单条指令不足以支撑复杂决策。
开始为模型动态构建完整上下文,包括文件、历史记录、知识库等,让AI做决策时有全面的信息支撑,本质是"给AI配全参考资料"。
但这一阶段仍处于"被动响应"模式,缺乏对AI输出的主动控制机制,复杂任务落地时依然面临稳定性不足的问题
2.3. Harness Engineering
2026年,Harness Engineering 成为AI工程化的第三阶段,也是当前最先进的工程范式。
它包含了前两个阶段的核心能力,但将其上升到全生命周期控制系统设计,通过约束、反馈、架构规则、工具链管理,让AI Agent能够持续、稳定、高质量地完成工作,本质上是"为AI搭建一个能长期高效干活的办公室"。
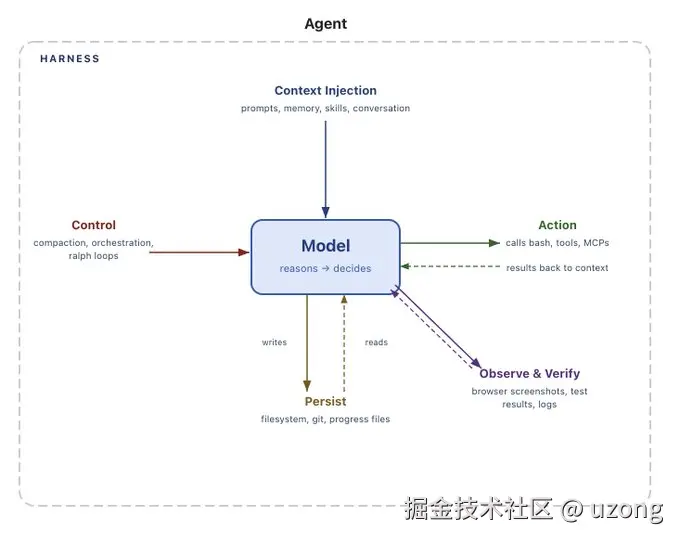
5. Harness Engineering 核心组成
构建一个完整的控制系统 Harness Engineering,其中包含了上下文、约束与熵管理
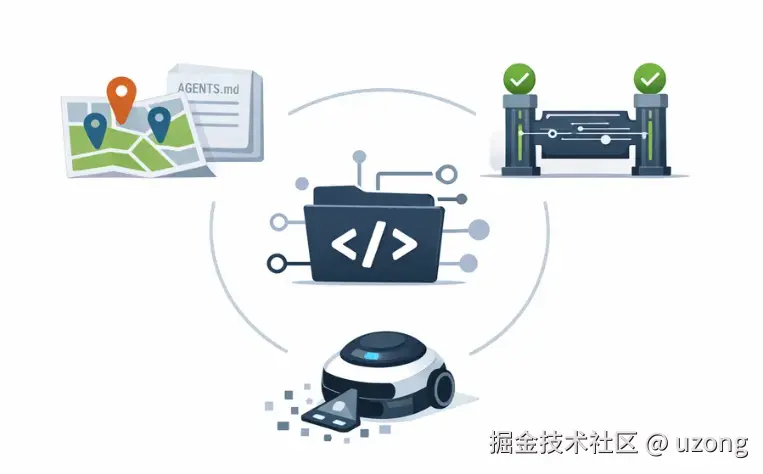
5.1. 上下文工程,
核心问题:Agent 无法访问你脑中的架构决策、团队约定和历史教训。
核心观点:
- 为 AI 准备的"导航地图" :OpenAI 项目中散布着88个
AGENTS.md文件。根目录的文件定义全局默认规则,子目录的文件则覆盖本地规则 - 渐进式披露:AI 从根目录的入口文件开始,按需深入到具体子目录获取局部上下文,而不是一次性灌入海量信息。
OpenAI的核心做法是将代码仓库作为Agent唯一的知识来源,所有规则、文档、代码都进行版本化管理,把老员工"口口相传"的隐性经验全部显性化,让Agent能随时找到所有需要的信息。
同时,他们摒弃了"大一统的指令文档",采用≤60行的AGENTS.md作为"目录",通过渐进式披露原则,让Agent在每个任务中只获取所需上下文,既避免信息冗余,又防止关键约束遗漏。
此外,还为Agent配备浏览器、可观测性栈,让它能自己验证结果、排查问题。
5.2. 架构约束,用"硬规则"替代软性指令
核心问题:靠人工 Code Review 无法跟上 AI 的代码产出速度,架构容易漂移失控。
解决方案:将架构规则"代码化",用机器而非人来守住边界。OpenAI 用 AI 自己编写 Linter(代码检查工具)来约束 AI。
强制执行的围栏:例如,规定"service 层不能反向依赖 controller 层",并将此规则写入 Linter。每当 AI 提交代码,Linter 会自动运行,如果违规,代码将无法合并。
反馈闭环:Linter 的错误信息本身也是上下文的一部分,它会告诉 AI"为什么错了"以及"如何修复",AI 读取后会自动修正代码并重新提交。
Harness不会依赖人工审查来约束AI,而是将架构文档、依赖关系、格式规范转化为可执行的硬约束,比如通过linter(代码检查工具)、结构化测试等,一旦AI输出违反规则,CI(持续集成)会直接挂掉,且报错信息会自带修复指引,把"老师傅经验"写进编译器。
5.3. 熵管理
核心问题:AI 会复制代码库中已有的坏模式,导致技术债务指数级堆积
- 解决方案:将清理技术债务变成一个自动化的、持续的过程
- 后台清洁 Agent:构建一个"清洁 Agent",定期扫描代码库,识别偏离"黄金原则"(如代码重复、模式不佳)的地方,并自动生成重构 PR。这就像代码库的"垃圾回收机制",持续、小额地偿还技术债务
解决AI规模化输出带来的"混乱"问题, AI生成代码时,技术债会呈指数级增长,因为Agent不会主动清理上一轮的遗留内容,反而会基于此继续构建。OpenAI的解法是部署GC Agent(垃圾回收Agent),定期扫描并修复过时文档、架构漂移、代码异味,实现代码库的"自我清洁",避免信噪比持续恶化。
6. 行业实践经验
- 设计AI友好的架构,AI在结构清晰、边界明确的系统中效率最高
- 反馈闭环
- 建立技术债务清理机制,避免坏的模式扩散
- 程师角色重构与技能升级,将核心技能也从编码能力,转向系统设计、规则制定、反馈循环设计与多Agent协调能力
- 将隐性知识系统化,立知识库维护机制,确保信息时效性,避免Agent基于过时知识犯错。
7. 重构AI时代的工程师角色
Harness Engineering的兴起,不仅是AI工程范式的变革,更重塑了人类工程师的角色定位。过去工程师的核心能力是"写代码";而在Harness时代,工程师的角色转变为"系统驾驭者",核心任务变为设计工程环境、明确任务意图、构建反馈循环,将精力从繁琐的代码编写中解放出来,聚焦于更具创造性的系统设计工作。
Harness Engineering 的兴起标志着工程师从"代码生产者"向"系统监考官"的转型
程师不再直接编写业务逻辑,而是编写"描述逻辑的逻辑"------即架构文档、验证规则和反馈系统。
在 AI 能够处理琐碎编码的背景下,人类对系统整体稳定性、模块解耦和长远技术债的判断力变得前所未有的重要。
未来的顶尖工程师将以其构建的"AI 运行环境"的质量来定义其价值,而非其手写代码的速度。
正如 Martin Fowler 所言:"我们正在进入一个工程师不再追求'写得更好',而是追求'管得更好'的时代。"对于开发者而言,掌握 Harness Engineering 将是通往 AI 时代高级工程师的必经之路
8. 结束总结
Harness Engineering 预示着未来软件开发将运行在两个循环中:
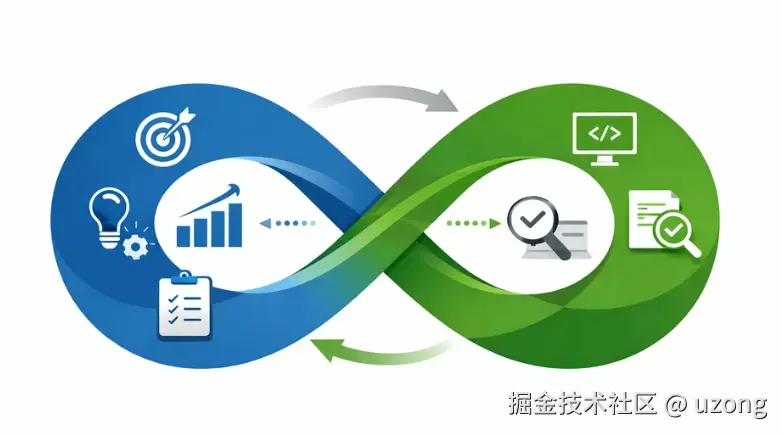
人类循环 :关注 "为什么做" ------制定业务目标、产品决策和战略方向。
AI 循环 :关注 "怎么实现" ------负责代码生成、测试、修复和验证。
人类不再逐行写代码,而是负责设计系统、制定规则、管理循环。换句话说,人类负责建造杠杆,AI 负责放大杠杆。Harness Engineering 的核心价值,就是用工程方法让概率性的 AI 系统能够可靠地运行。
每天都有各种新名词出现,知识永远学不完,AI 带来的焦虑还在蔓延。作为普通人,我们是不是该停下来想一想:什么才是我真正需要的。
9. 参考资料
martinfowler.com/articles/ex...
blog.langchain.com/improving-d...
developer.aliyun.com/article/171...