无数据/零样本量化2------GDFQ: Generative low-bitwidth data free quantization
译文标题:GDFQ:一种生成式的低比特位宽零样本量化方法
出处:2020 ECCV
作者:Xu Shoukai等
作者单位:华南理工
论文地址:http://arxiv.org/abs/2003.03603
论文代码地址:https://github.com/xushoukai/GDFQ
文章目录
- [无数据/零样本量化2------GDFQ: Generative low-bitwidth data free quantization](#无数据/零样本量化2——GDFQ: Generative low-bitwidth data free quantization)
- 前言
- 一、研究动机
- 二、创新点
-
- [2.1 低比特位宽的有效性](#2.1 低比特位宽的有效性)
- [2.2 生成器生成样本](#2.2 生成器生成样本)
- 三、方法
-
- [3.1 回顾](#3.1 回顾)
-
- [3.1.1 模型训练](#3.1.1 模型训练)
- [3.1.2 ZeroQ的问题](#3.1.2 ZeroQ的问题)
- [3.2 创新方法](#3.2 创新方法)
-
- [3.2.1 知识匹配生成器](#3.2.1 知识匹配生成器)
- [3.2.2 合成数据驱动的低bit量化](#3.2.2 合成数据驱动的低bit量化)
- [3.2.3 训练过程](#3.2.3 训练过程)
-
- [(1). 训练生成器G](#(1). 训练生成器G)
- [(2). 微调训练量化网络Q](#(2). 微调训练量化网络Q)
- [四、 实验](#四、 实验)
-
- [4.1 分类边界的动机实验](#4.1 分类边界的动机实验)
- [4.2 主实验结果](#4.2 主实验结果)
- [4.3 消融实验](#4.3 消融实验)
-
- [4.3.1 对于知识匹配生成器 G G G的分析](#4.3.1 对于知识匹配生成器 G G G的分析)
- [4.3.2 对微调训练量化模型 Q Q Q的分析](#4.3.2 对微调训练量化模型 Q Q Q的分析)
- [4.3.3 对于固定BNS参数的分析](#4.3.3 对于固定BNS参数的分析)
- [4.4 补充实验](#4.4 补充实验)
-
- [4.4.1 对于微调训练必要性的分析](#4.4.1 对于微调训练必要性的分析)
- [4.4.2 对于交替微调训练策略的分析](#4.4.2 对于交替微调训练策略的分析)
- [4.4.3 对于生成器G停止阈值的分析](#4.4.3 对于生成器G停止阈值的分析)
- 五、结论
- 参考文献
前言
在2012年开启了深度学习第三次浪潮,经过15年的发展,深度学习取得了很大的进步。在不断发展的过程中,模型的规模做的越来越大,参数量也越来越多。在边缘侧部署最新的深度学习模型/算法一直是有一个挑战性的问题。其中主要包括参数的存储问题、推理时延问题和功耗问题。
随着硬件也能在底层支持dibit运算,解决此问题的最好方式是Quantization量化方法。即在推理时将FP32全精度的Wight权重和Activation激活参数,转换为Int8或者更低精度的整数格式进行运算。这样做的好处是在底层可是使用ALU整数逻辑单元,使得运行时计算速度更快;参数格式的变化减少了在部署和运行时的存储要求,同这也是降低功耗的重要原因之一。
quantization方法分为PTQ(Post Training Qauntion)训练后量化和QAT(Quantization-Aware Training)量化感知训练。
- PTQ方法是一个简单的离线量化法,在获得Pre-Training Model预训练的模型后,将模型weight权重参数直接进行调整到要求的bit精度,然后冻结起来;随后量化Activation激活参数,但是Activation激活参数是要在模型做前向推理的时候才能量化参数,所以要想将其转换为对应精度还是需要一部分原始训练数据集来进行校准,获取对应的零点Zero PointZero和缩放因子Scale。
- QAT方法是一个Fine-Training微调方法,拿着模型插入量化和反量化算子。使用原始数据集进行训练微调,使其收敛。
这两种主流方式都是需要 原始数据集部分或者全部做参与的。 但是在真实场景下,收敛后的模型是开源可被获取,但是训练数据集是专有且不可被访问的。例如含有生物特征的医学数据,金融数据、用户信息数据或者军事用途数据。
所以在此背景之上,零样本是模型量化种遇到的一个重要问题。
一、研究动机
有一些工作 2已经能够证明,一个训练的很好的模型,其中包含了丰富的原始数据集的信息。但是有两个问题存在:
- 存在那些信息?
- 这些信息如何被使用?
在具有BN层的NN神经网络中,BN被设计的初衷是为了稳定分布,并且可以学习到分类边界将数据集划分为不同类别。也就是说,原始训练数据集的分类边界和数据分布的信息被隐藏至预训练的NN神经网络中。
但是目前的无数据/零样本量化方法 1,2仅仅关注了 单个样本/ 网络参数,DFQ1重点关注了网络参数本身的分布信息; ZeroQ1仅关注了 单个样本的信息而非整个样本。
这篇论文的研究动机就是在零样本的场景下,通过BNS(Batch Normal Statics)的统计信息,利用生成器来生成有意义的样本。
二、创新点
2.1 低比特位宽的有效性
提出的GDFQ 方法在4bit上依旧有效。
2.2 生成器生成样本
提出使用知识匹配生成器 充分挖掘预训练模型的有效信息,从而生成有意义的样本。
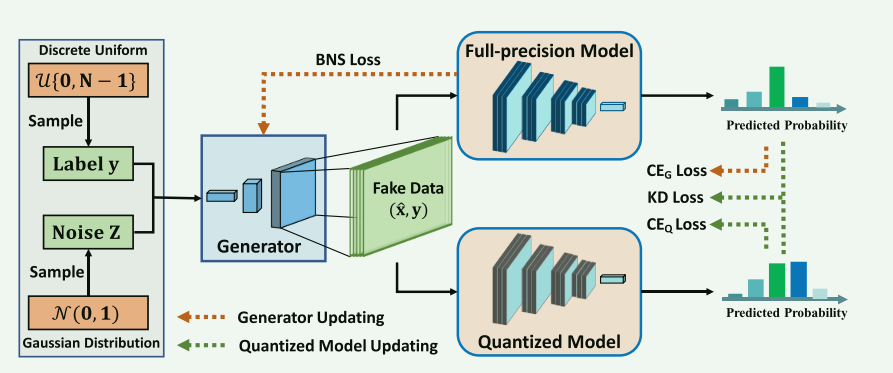
三、方法
3.1 回顾
在数据隐私场景下,原始训练样本不可被访问,常规的PTQ和QAT方法通常不能工作。
3.1.1 模型训练
对于一个零样本场景下的QAT,经验误差损失函数定义如下:
min Q , x ^ E x ^ , y ℓ ( Q ( x \^ ) , y ) , ( 1 ) \min_{Q,\hat{\mathbf{x}}}\mathbb{E}_{\hat{\mathbf{x}},y}\left\\ell(Q(\\hat{\\mathbf{x}}),y)\\right,\quad(1) Q,x^minEx^,yℓ(Q(x\^),y),(1)
其中, ( x ^ , y ) ( \hat{\mathbf{x}},y) (x^,y)为合成的假样本; Q Q Q代表量化神经网络模型; l ( ⋅ , ⋅ ) \mathcal {l}(\cdot,\cdot) l(⋅,⋅)代表损失函数,例如交叉熵损失;
3.1.2 ZeroQ的问题
ZeroQ方法利用BNS信息构造样本,通过使用反向传播算法,构造合成样本,一定程度上提升了Q量化模型的性能,但是存在两个问题:
- 不含标签信息,忽略了预训练模型中含有的分类边界知识。
- 出发点是从单个样本进行考虑,非是全体样本。
3.2 创新方法
本文重点聚焦了利用存在 预训练神经网络模型中丰富的数据信息,使用生成器 G G G来生成有意义的数据,基本定义如下:
x ^ = G ( z ∣ y ) , z ∼ p ( z ) , ( 2 ) \hat{\mathbf{x}}=G(\mathbf{z}|y),\quad\mathbf{z}\sim p(\mathbf{z}),\quad(2) x^=G(z∣y),z∼p(z),(2)
其中 z z z是一个服从分布 p ( ⋅ ) p(\cdot) p(⋅)的随机向量,一般选择Gaussian/Uniform分布, y y y是样本 x ^ \hat{\mathbf{x}} x^的标签。
3.2.1 知识匹配生成器
预训练模型中含有分类边界信息,使用对抗生成网络GANs可以生成合成样本。但是由于原始数据不可被使用,所以GAN中的判别器不能工作,但是在分类神经网络模型中的最后一层,实际上包含了原始数据的类别,我们使用分类信息来判别生成数据的质量。先定义知识匹配生成器 G G G:
x ^ = G ( z ∣ y ) , z ∼ N ( 0 , 1 ) , ( 3 ) \hat{\mathbf{x}}=G(\mathbf{z}|y),\quad\mathbf{z}\sim N(0,1),\quad(3) x^=G(z∣y),z∼N(0,1),(3)
其中 z z z是一个在 z z z条件下服从Gaussian分布 N ( 0 , 1 ) N(0,1) N(0,1)的随机噪声向量。其中 y y y是样本标签,y服从 0 , n − 1 0,n-1 0,n−1的离散均匀分布,n为样本类别数量。
如何生成高质量样本?一个核心思想就是G生成的样本,输入预训练的全精度模型M后的输出结果应与y相同,于是定义带有预训练模型分类信息生成器 G G G的交叉熵loss C E ( ⋅ , ⋅ ) \mathrm{CE}(\cdot,\cdot) CE(⋅,⋅)如下:
L C E G ( G ) = E z , y C E ( M ( G ( z ∣ y ) ) , y ) , ( 4 ) \mathcal{L}{\mathrm{CE}}^{G}(G)=\mathbb{E}{\mathbf{z},y}\left\\mathrm{CE}(M(G(\\mathbf{z}\|y)),y)\\right , \quad(4) LCEG(G)=Ez,yCE(M(G(z∣y)),y),(4)
此外预训练模型中 存储了训练数据的分布信息,使用BNS批量归一化来捕获。在此过程中使用的,定义带有预训练模型BNS信息的生成器 G G G 的loss 如下:
L B N S ( G ) = ∑ i = 0 L ∥ μ l r − μ l ∥ 2 2 + ∥ σ l r − σ l ∥ 2 2 , ( 5 ) \mathcal{L}{BNS}\left( G \right) =\sum{i=0}^L{\lVert \mu _{l}^{r}-\mu _l \rVert _{2}^{2}+\lVert \sigma _{l}^{r}-\sigma _l\rVert _{2}^{2},\quad \left( 5 \right)} LBNS(G)=i=0∑L∥μlr−μl∥22+∥σlr−σl∥22,(5)
其中 μ l r \mu _{l}^{r} μlr 和 σ l r \sigma _{l}^{r} σlr 代表 G G G合成的样本在第 l l l个BN层所计算的均值和标准差; μ l \mu _{l} μl 和 σ l \sigma _{l} σl 代表预训练模型在第 l l l个BN层所存储的均值和标准差。
通过公式(4)和公式(5) 可以获取预训练模型中的分类边界信息和统计信息,有助于生成有意义的样本。
3.2.2 合成数据驱动的低bit量化
生成器 G G G生成了含有统计信息和分类边界信息的合成样本,可以无数据量化问题转变为一个有监督的量化问题 。预训练模型中含有"知识",但是在量化的过程中,这些"知识"随着精度截断部分丢失。
本节的出发点就是利用这些合成样本对量化神经网络进行Fine-Tunning微调,使这些知识再次迁移到量化模型上来。
首先从全精度模型上获得一个量化神经网络:
θ q = { − 2 k − 1 , i f θ ′ < − 2 k − 1 2 k − 1 − 1 , i f θ ′ > 2 k − 1 − 1 θ ′ , otherwise, ( 6 ) \theta_q=\begin{cases}-2^{k-1},&\mathrm{if~}\theta^{\prime}<-2^{k-1}\\2^{k-1}-1,&\mathrm{if~}\theta^{\prime}>2^{k-1}-1\\\theta^{\prime},&\text{otherwise,}&\end{cases}(6) θq=⎩ ⎨ ⎧−2k−1,2k−1−1,θ′,if θ′<−2k−1if θ′>2k−1−1otherwise,(6)
利用合成样本微调量化模型 Q Q Q,使之精度尽可能的和预训练的全精度模型 M M M接近。定义微调量化模型 Q Q Q的交叉熵损失 C E ( ⋅ , ⋅ ) \mathrm{CE}(\cdot,\cdot) CE(⋅,⋅) loss:
L C E Q ( Q ) = E x ^ , y C E ( Q ( x \^ ) , y ) . ( 7 ) \mathcal{L}{\mathrm{CE}}^Q(Q)=\mathbb{E}{\hat{\mathbf{x}},y}\left\\mathrm{CE}(Q(\\hat{\\mathbf{x}}),y)\\right.\quad(7) LCEQ(Q)=Ex^,yCE(Q(x\^),y).(7)
其中 ( x ^ , y ) (\hat{\mathbf x},y) (x^,y)是带有标签的样本。
由于数据是合成的,从合成数据中进行微调所能获得的知识有限。采用知识蒸馏 4的方式来恢复Q的性能:
L K D ( Q ) = E x ^ K L ( Q ( x \^ ) , M ( x \^ ) ) . ( 8 ) \mathcal{L}{\mathrm{KD}}(Q)=\mathbb{E}{\hat{\mathbf{x}}}\left\\mathrm{KL}(Q(\\hat{\\mathbf{x}}),M(\\hat{\\mathbf{x}}))\\right.\quad(8) LKD(Q)=Ex^KL(Q(x\^),M(x\^)).(8)
固定BNS参数
在量化微调的时候,有一个小技巧就是固定Q的BNS参数。因为这些BNS信息来自预训练的全精度神经网络模型,是原始训练数据的真实分布表示。这样做有助于提升Q的性能。
3.2.3 训练过程
训练过程见算法1(下图)描述,首先得到量化模型 Q Q Q,和常规生成器G一样有一个预热。二者交替训练(这样做的好处是可以提高样本多样性)。

(1). 训练生成器G
随机从Gaussian分布中采样一个带有 y y y标签的随机向量噪声,生成器 G G G的训练loss如下:
L 1 ( G ) = L C E G ( G ) + β L B N S ( G ) . ( 9 ) \mathcal{L}1(G)=\mathcal{L}{\mathrm{CE}}^G(G)+\beta \mathcal{L}_{\mathrm{BNS}}(G).\quad(9) L1(G)=LCEG(G)+βLBNS(G).(9)
(2). 微调训练量化网络Q
首先量化预训练神经网络模型 M M M得到量化模型 Q Q Q,将BN层的BNS固定,进行Fine-Tuning训练微调Q,迁移 M M M的"知识"以恢复 Q Q Q的性能,其微调训练loss 定义如下:
L 1 ( Q ) = L C E Q ( Q ) + γ L K D ( Q ) . ( 9 ) \mathcal{L}1(Q)=\mathcal{L}{\mathrm{CE}}^Q(Q)+\gamma \mathcal{L}_{\mathrm{KD}}(Q).\quad(9) L1(Q)=LCEQ(Q)+γLKD(Q).(9)
四、 实验
4.1 分类边界的动机实验
实验动机是为了探索本文提出的GDFQ方法生成的数据是否带有分类边界信息,思路是做一个简单的c测试验证二分类网络(几个线性层,几个BN层+几个Relu层)。验证本文提出的方法所产生的合成假数据带有分类边界的。
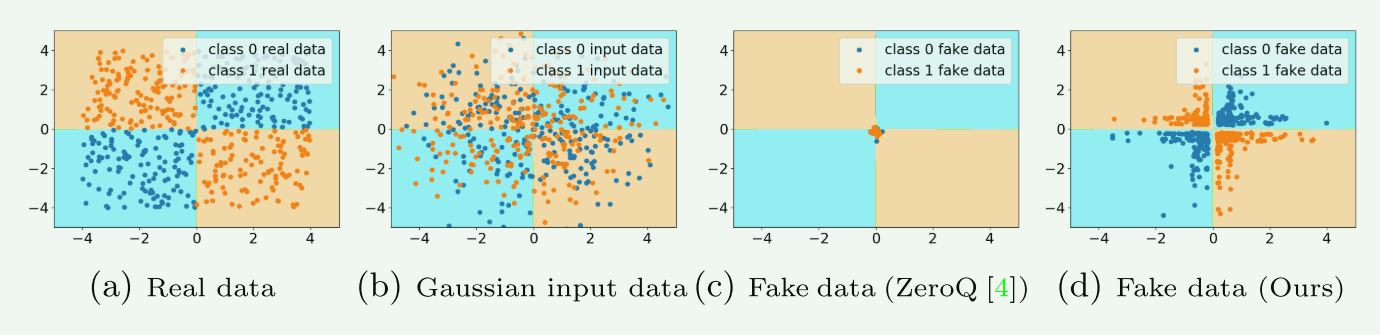
- 图(a)展示了一个真实样本;
- 图(b)展示了一个Gaussian采样的样本;
- 图©ZeroQ产生的样本;
- 图(d)本文GDFQ样本。
分析:不难看出,ZeroQ生成的样本糊在了中心点,因为他没有考虑标签,生成的样本没有类别间信息;相反的是本文提出的GDFQ生成的样本有明确的类别间信息。
4.2 主实验结果
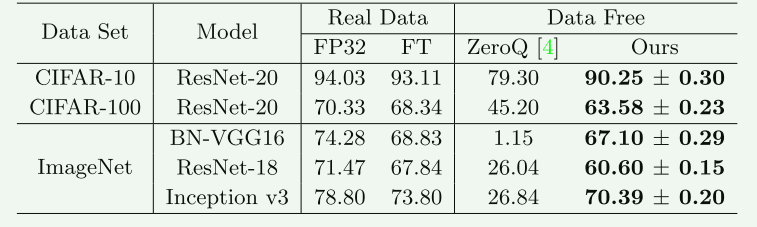
实验说明:
- FT代表的是使用真实数据进行的微调;
- 量化的bit位宽 W4A4 。
实验结果分析
可是说是效果非常明显,具体数据可以自行分析。
4.3 消融实验
4.3.1 对于知识匹配生成器 G G G的分析
实验说明:
- CIFAR-100 在ResNet20上.
- W4A4
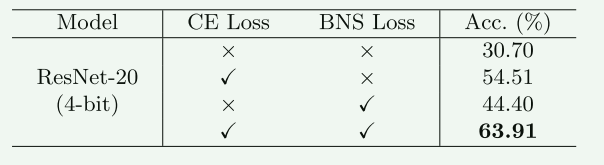
实验结果分析:
对于生成器 G G Gloss 中的CE loss和BNS loss任何一个子部件均是起到了正向作用。
4.3.2 对微调训练量化模型 Q Q Q的分析
实验说明:
- CIFAR-100 在ResNet20上.
- W4A4
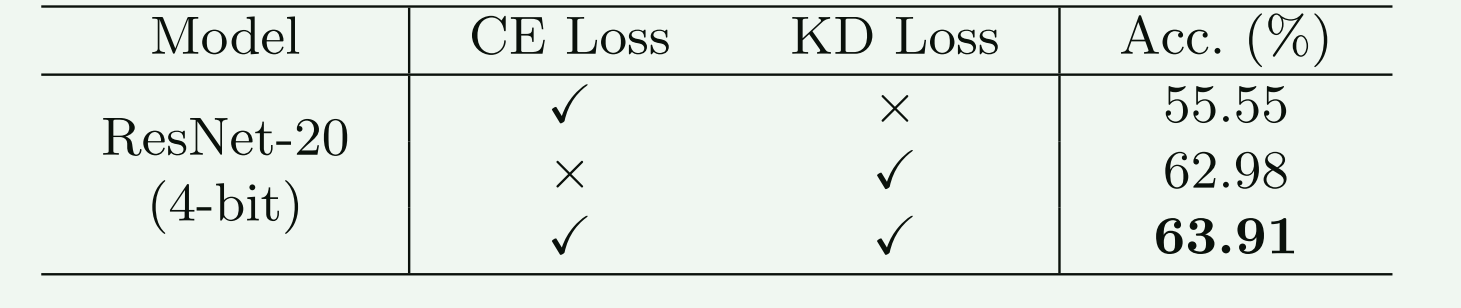
实验结果分析:
对于量化模型 Q Q Q微调训练的loss 函数中的CE loss和KD loss任何一个子部件均是起到了正向作用。
4.3.3 对于固定BNS参数的分析
实验说明:
- CIFAR-10 /CIFAR-100 在ResNet20上;
- W4A4;
- w/o 代表微调过程中没有固定BNS,w代表固定了BNS。

实验结果分析:
对于量化模型 Q Q Q微调训练过程中的固定BNS参数技巧是有效的。
4.4 补充实验
4.4.1 对于微调训练必要性的分析
实验说明:
- 对比PTQ的其他方法直接使用真实数据进行校准;而本文使用微调训练的方式
- W4A4;
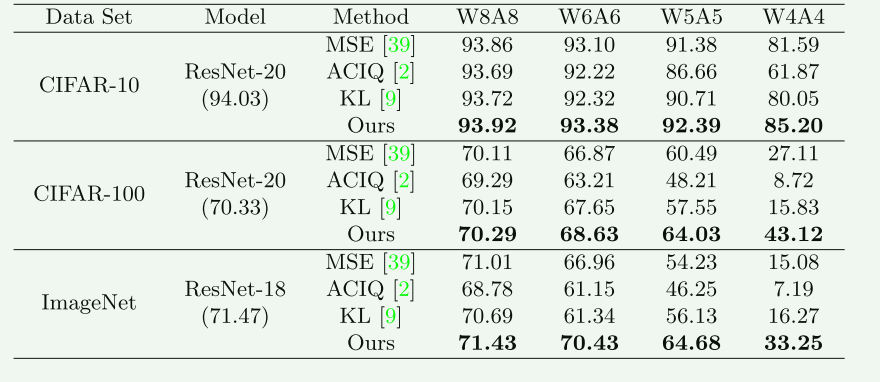
实验结果:
- 对比使用了真实数据校准的其他 PTQ方法;而本文使用微调训练的方式 效果最佳;
- 数据集越大,ACC准确度越低;
- 量化比特位宽越低,ACC准确度越低。
4.4.2 对于交替微调训练策略的分析
实验说明:
- CIFAR-10 /CIFAR-100 在ResNet20上;
- W4A4;
- Seperate Training 二阶段法,先训练生成G使其收敛;随后使量化模型收敛; Alternating Training本文提出的交替训练法。
 实验结果:
实验结果:
- Alternating Training有效;
4.4.3 对于生成器G停止阈值的分析
实验目的:
为了探索生成器G在不同停止阈值条件(当生成的样本在全精度的预训练模型的准确度大于阈值 η \eta η时就停止对生成器G的训练)下 对量化模型的影响。
实验说明:
- CIFAR-10 /CIFAR-100 在ResNet20上;
- W4A4。

实验结果:
随着阈值条件的提高,量化准确度逐步提高,直到生成器的训练不停止,可以取得最佳实验结果。也说明了不停机可以充分榨取预训练模型中所含有"知识",生成不同多样性的样本。可以提高微调Q的结果。
五、结论
提出了GDFQ方法,生成器+训练微调的范式,可以提高零样本场景下的低比特模型量化精度。
- 知识匹配生成器:提出一个生成器,可以生成含有分类边界和统计信息的有标签样本;(重点:之后很多方法都是从生成器入手)
- 训练微调:利用这些样本对Q进行微调训练(一个思路是PTQ也可以微调训练)具有很好的效果。
参考文献
1Cai, Yaohui, et al. "Zeroq: A novel zero shot quantization framework." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
2Zhang, Chiyuan, et al. "Understanding deep learning requires rethinking generalization." arXiv preprint arXiv:1611.03530 (2016)
3Nagel, Markus, et al. "Data-free quantization through weight equalization and bias correction." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
4Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).