PyTorch强化学习实战(11)------N步DQN(N-step DQN)
0. 前言
自从 DeepMind 在 2015 年提出深度Q网络 (Deep Q-Network, DQN)模型以来,研究人员已经提出了诸多改进方案,通过对基础架构的调整显著提升了原始 DQN 的收敛性、稳定性和样本效率。
2017 年 DeepMind 的 Hessel 等人发表了名为 Rainbow: Combining improvements in deep reinforcement learning 的论文,系统性地整合了 DQN 的六大核心改进。仅通过这六种方法的组合,便在 Atari 游戏测试集上达到了当时的最高水平。尽管 2017 年后又涌现出许多新研究不断刷新记录,但 Rainbow 论文中的方法至今仍具有实用价值。本节将深入探讨 N步DQN (N-step DQN),通过贝尔曼方程展开提升收敛速度与稳定性。本节将解析 N步DQN 方法的原理、实现方案,并与经典 DQN 进行性能对比。
1. N-step DQN 原理
为了理 N步DQN (N-step DQN) 算法的原理,我们再次回顾Q学习中的贝尔曼更新公式:
Q ( s t + 1 , a t + 1 ) = r t + γ max a Q ( s t + 1 , a t + 1 ) Q(s_{t+1}, a_{t+1}) = r_{t} + \gamma \max_{a} Q(s_{t+1}, a_{t+1}) Q(st+1,at+1)=rt+γamaxQ(st+1,at+1)
该方程具有递归特性,这意味着我们可以通过表示 Q ( s t + 1 , a t + 1 ) Q(s_{t+1}, a_{t+1}) Q(st+1,at+1) 得到如下结果:
Q ( s t , a t ) = r t + γ max a r a , t + 1 + γ max a ′ Q ( s t + 2 , a ′ ) Q(s_{t}, a_{t}) = r_{t} + \gamma \max_{a}r_{a,t+1}+\\gamma \\max_{a'}Q(s_{t+2},a') Q(st,at)=rt+γamaxra,t+1+γa′maxQ(st+2,a′)
值 r a , t + 1 r_{a,t+1} ra,t+1 表示在时间 t + 1 t+1 t+1 执行动作 a a a 后获得的即时奖励。如果我们假设在步骤 t + 1 t+1 t+1 选择的动作 a a a 是最优的(或者接近最优),就可以省略 max a \underset {a}{\max} amax 操作,简化为:
Q ( s t , a t ) = r t + γ r t + 1 + γ 2 max a ′ Q ( s t + 2 , a ′ ) Q(s_{t}, a_{t}) = r_{t} + \gamma r_{t+1}+\gamma^2 \underset{a'}{\max} Q(s_{t+2}, a') Q(st,at)=rt+γrt+1+γ2a′maxQ(st+2,a′)
这个值可以无限次地递归展开。显然,这种展开方式可以通过将单步转移采样替换为 n 步转移序列,直接应用于 DQN 的更新过程。为了理解这种展开为何能加速训练,参考下图所示的示例:该环境包含四个状态( s 1 s_1 s1 至 s 4 s_4 s4),除终止状态 s 4 s_4 s4 外,其他状态都只能执行单一动作:
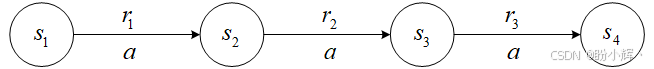
那么在单步更新的情况下,共有三个可能的更新(由于只有一个可选动作,因此无需使用 max 运算):
Q ( s 1 , a ) ← r 1 + γ Q ( s 2 , a ) Q ( s 2 , a ) ← r 2 + γ Q ( s 3 , a ) Q ( s 3 , a ) ← r 3 Q(s_1, a) ← r_1 + γQ(s_2, a) \\ Q(s_2, a) ← r_2 + γQ(s_3, a) \\ Q(s_3, a) ← r_3 Q(s1,a)←r1+γQ(s2,a)Q(s2,a)←r2+γQ(s3,a)Q(s3,a)←r3
假设在训练初期按此顺序完成更新:前两次更新实际无效,因为初始 Q ( s 2 , a ) Q(s_2,a) Q(s2,a) 和 Q ( s 3 , a ) Q(s_3,a) Q(s3,a) 值存在随机误差。只有第三次更新能正确将 r 3 r_3 r3 赋值给终止状态前的 s 3 s_3 s3 状态。
当反复执行更新时:第二次迭代会将正确值赋给 Q ( s 2 , a ) Q(s_2,a) Q(s2,a),但 Q ( s 1 , a ) Q(s_1,a) Q(s1,a) 仍含噪声。直到第三次迭代所有Q值才趋于准确。可见即便单步更新,也需要三次迭代才能将正确值传递至所有状态。
接下来,考虑两步更新的情况:
Q ( s 1 , a ) ← r 1 + γ r 2 + γ 2 Q ( s 3 , a ) Q ( s 2 , a ) ← r 2 + γ r 3 Q ( s 3 , a ) ← r 3 Q(s_1, a) ← r_1 + γr_2 + γ^2Q(s_3, a) \\ Q(s_2, a) ← r_2 + γr_3 \\ Q(s_3, a) ← r_3 \\ Q(s1,a)←r1+γr2+γ2Q(s3,a)Q(s2,a)←r2+γr3Q(s3,a)←r3
在这种情况下,首次迭代即可正确更新 Q ( s 2 , a ) Q(s_2,a) Q(s2,a) 和 Q ( s 3 , a ) Q(s_3,a) Q(s3,a),第二次迭代就能准确修正 Q ( s 1 , a ) Q(s_1,a) Q(s1,a)。这表明多步更新能加速价值传播,提升收敛效率。但需要注意的是,过度展开反而会导致 DQN 完全无法收敛。
问题的根源在于展开过程中我们舍弃了 max 运算。严格来说这是不准确的:我们假设经验采样的动作选择是最优的,但训练初期的随机策略显然不符合该假设。这种情况下计算的 Q ( s t , a t ) Q(s_t,a_t) Q(st,at) 可能低于真实最优值(因为部分动作路径未遵循Q值最大化原则)。展开步数越多,更新偏差越大。
庞大的经验回放缓冲区会进一步加剧这个问题------其中存储的旧策略(基于早期不准确的Q值)产生的转移样本,会错误地更新当前Q值估计,进而破坏训练进程。
强化学习方法主要分为两大类别:
- 异策略方法 (Off-policy,也称离线策略) :异策略方法不依赖于"数据新鲜度"。例如经典
DQN就属于异策略方法,这意味着我们可以使用数百万步前采样的旧环境数据,这些数据仍具有学习价值。因为这类方法仅通过即时奖励加上最佳动作价值的当前折扣近似值,来更新动作价值函数 Q ( s t , a t ) Q(s_t,a_t) Q(st,at)。即使动作at是随机采样的也无妨------对于特定状态 s t s_t st 下的这个具体动作 a t a_t at,我们的更新始终正确。正因如此,异策略方法可以使用超大规模的经验缓冲区,使数据更接近独立同分布 (independent and identically distributed,iid) 的理想状态 - 同策略方法 (On-policy,也称在线策略) :同策略方法严格要求训练数据必须根据当前更新的策略进行采样。这是因为同策略方法试图间接(如
n步DQN)或直接改进当前策略
选用哪种方法取决于具体场景。异策略方法可以利用历史数据甚至人类示范进行训练,但通常收敛速度较慢;同策略方法收敛更快,但需要获取大量新鲜环境数据,成本可能极高。
那么,既然"n步机制"会将 DQN 转变为同策略方法,导致大容量经验回放缓冲区失效,我们为何还要讨论 n步DQN?实际上,只要有助于加速 DQN 训练,仍可采用 n步DQN,但需谨慎选择 n 值。取 2 或 3 这样的较小数值通常效果良好,因为经验回放缓冲区中的轨迹与单步转移差异不大。这种情况下,收敛速度通常能获得相应提升,而过大的 n 值反而会破坏训练过程。
2. 实现N步DQN
由于 ExperienceSourceFirstLast 类已支持多步贝尔曼展开 (unroll),我们的 N步DQN 实现极其简单。只需对经典 DQN进行两处修改即可将其升级为 n 步版本:
- 在创建
ExperienceSourceFirstLast时,通过steps_count参数传入所需的展开步数 - 将向
calc_loss_dqn函数传递正确的gamma值。由于贝尔曼方程现在是n步的,经验链末端状态的折扣系数不再是简单的 γ γ γ,而应是 γ n γ^n γn
python
exp_source = lib.experience.ExperienceSourceFirstLast(
env, agent, gamma=params.gamma,steps_count=n_steps)n_steps 参数通过命令行传入(默认值为 4 步),另一处关键修改是通过调整传入 calc_loss_dqn 函数的 gamma 值:
python
loss_v = common.calc_loss_dqn(
batch, net, tgt_net.target_model,
gamma=params.gamma**n_steps, device=device)3. 训练结果
训练模块 dqn_n_steps.py 新增了 -n 命令行选项用于指定贝尔曼方程的展开步数。下图展示了基准 DQN 与 N步DQN (参数配置相同,n 分别取 2 和 3)的训练曲线对比。可以看到,贝尔曼多步展开显著提升了收敛速度:
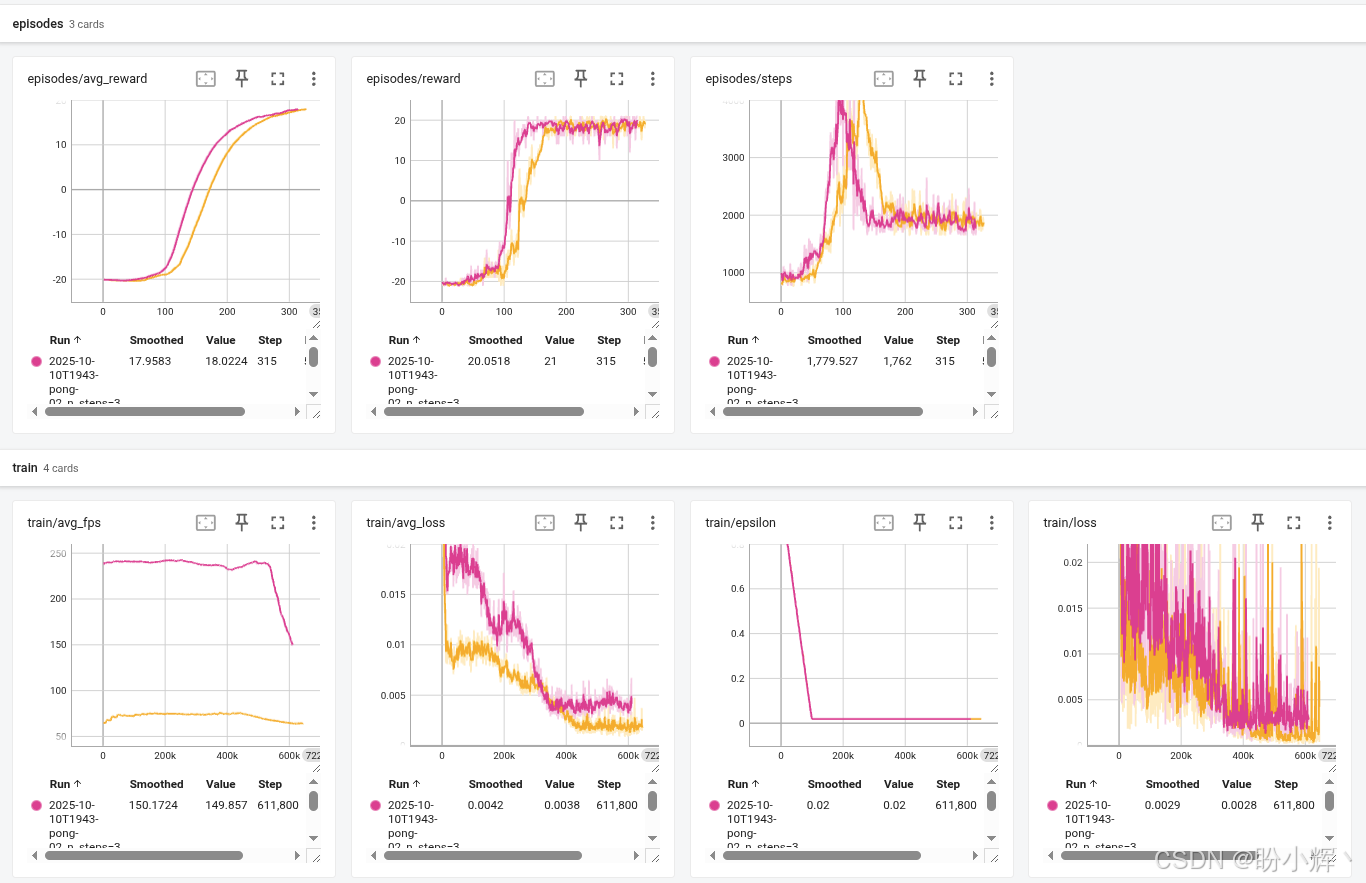
如图所示,3 步 DQN 的收敛速度明显快于经典 DQN。接下来,继续观察更高阶的 n 值表现如何,下图显示了 n = 2 到 6 的奖励动态变化:

可以看到,从三步到四步虽然有所改善,但增益幅度已大幅降低。n = 5 的表现反而有所下降,与 n=2 效果相近,n = 6 时同样如此。因此,在本节中,n=3 是最优解。
4. 超参数调优
在 N步DQN 中,超参数调优是针对每个 n 值(从 2 到 6)单独进行的。下表列出了不同 n 值对应的最佳参数和解决游戏所需的训练局数:
| n | 学习率 | γ \gamma γ | 局数 |
|---|---|---|---|
| 2 | 3.97 × 10 − 5 3.97\times 10^{-5} 3.97×10−5 | 0.98 | 293 |
| 3 | 7.82 × 10 − 5 7.82\times 10^{-5} 7.82×10−5 | 0.98 | 260 |
| 4 | 6.07 × 10 − 5 6.07\times 10^{-5} 6.07×10−5 | 0.98 | 290 |
| 5 | 7.52 × 10 − 5 7.52\times 10^{-5} 7.52×10−5 | 0.99 | 268 |
| 6 | 6.78 × 10 − 5 6.78\times 10^{-5} 6.78×10−5 | 0.995 | 261 |
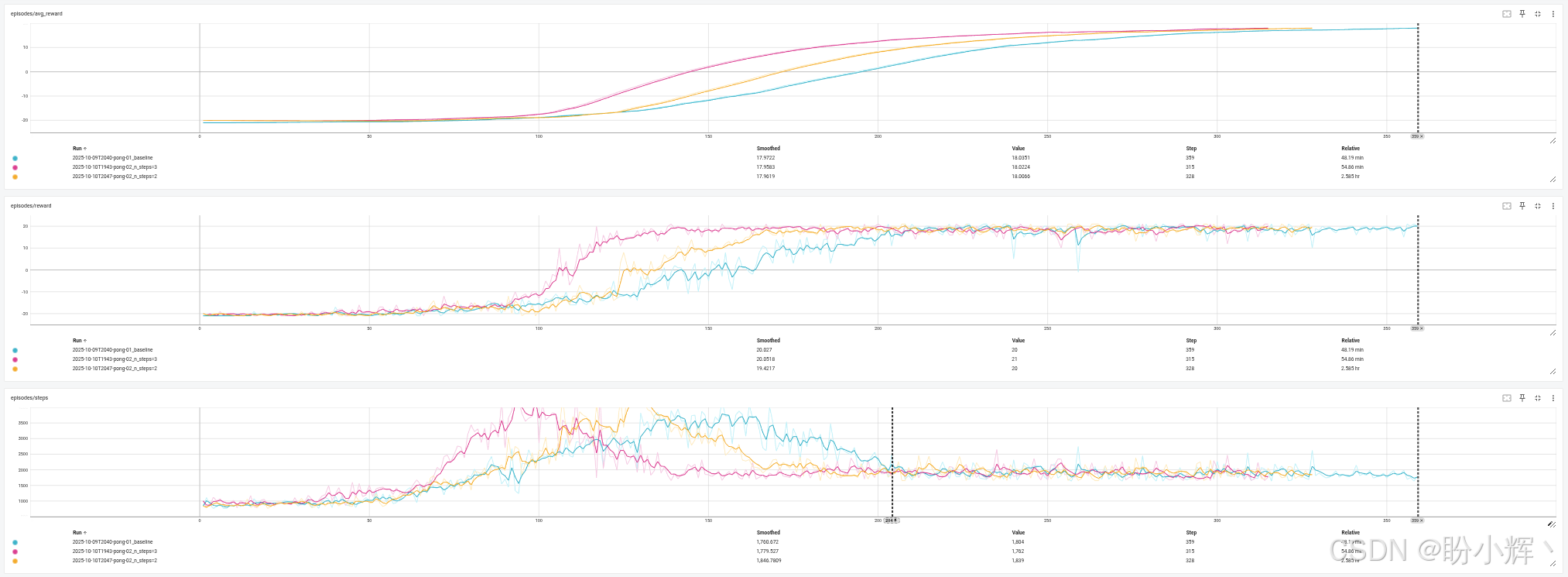
该表格也验证了未调参版本对比的结论------将贝尔曼方程展开 2 到 3 步可以提升收敛性,但继续增加 n 值反而会降低效果。n=6 的结果与 n=3 相当,但 n=4 和 n=5 的表现更差,因此我们应该将 n 值控制在 3 步以内。
下图对比了经过调参的经典 DQN 与 n=2、n=3 的 N步DQN 的训练动态表现。
小结
本节介绍了 N步DQN,一种通过扩展贝尔曼方程更新步骤来加速深度Q网络 (Deep Q-Network, DQN) 收敛与提升稳定性的方法。N 步更新通过考虑未来多步奖励来加速价值传播,相比单步 DQN 能更快收敛。但展开步数 n 需谨慎选择,因为过大的 n 会引入偏差,并使 DQN 倾向于同策略学习,削弱经验回放缓冲区的优势。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程