文章目录
-
- 前言
- 一、选型别只盯着跑分,这几个问题更值得问
- [二、为什么我建议重点关注 Apache IoTDB](#二、为什么我建议重点关注 Apache IoTDB)
- 三、代码实战:从建模到查询
-
- [3.1 设备树建模 --- 工业场景的核心](#3.1 设备树建模 — 工业场景的核心)
- [3.2 批量写入 --- 高吞吐的关键](#3.2 批量写入 — 高吞吐的关键)
- [3.3 时间范围查询 --- 时序分析的基础](#3.3 时间范围查询 — 时序分析的基础)
- [3.4 聚合和降采样 --- 降低存储和查询成本](#3.4 聚合和降采样 — 降低存储和查询成本)
- [3.5 异常检测场景 --- 实际应用示例](#3.5 异常检测场景 — 实际应用示例)
- 四、工程落地的几个实际优势
- 结语
前言
如果你在工业互联网、能源电力、智能制造或者车联网领域做过数据平台,大概都绕不开一个问题:现有的数据库,真的撑得住吗?
不是说撑不住,而是一旦设备量上来,数据规模上来,查询逻辑复杂起来,很多团队才意识到------用通用数据库"硬撑"时序数据,早期可以,后期很痛。写入开始限速,历史数据查得越来越慢,存储成本居高不下,聚合分析还要自己写一堆逻辑......这种情况并不罕见。
这也是为什么时序数据库这几年越来越被重视。今天这篇文章,我想从工程实践的角度,聊聊时序数据库选型应该关注什么,以及为什么我会建议你重点看看 Apache IoTDB。

一、选型别只盯着跑分,这几个问题更值得问
很多人做时序数据库选型,第一反应是找 benchmark,看写入 TPS、查询延迟、压缩比。这些数字当然有参考价值,但真正决定一个项目成不成的,往往不是某一项指标跑得漂不漂亮,而是综合能力能不能撑住业务增长。
结合我看过的一些实际案例,我觉得选型时有六个问题值得认真想清楚:
第一,高吞吐写入能不能扛住? 设备上报数据是持续的,不是一个峰值,而是 7×24 小时的压力。峰值跑得好看,但持续写入是否稳定,才是关键。
第二,长期存储的成本有没有认真算过? 时序数据不是写一天,是写几年。单机写入很快,但每年多出来的存储费用,会不会让后期维护越来越难受?
第三,查询语义够不够? "能查"和"查得顺手"差很多。时间范围过滤、聚合、降采样、多设备对齐------这些场景你要自己拼 SQL 实现,还是数据库原生支持,体验天差地别。
第四,扩容路径清不清晰? 从单机到集群,有没有合理的演进路线,还是要推倒重来?
第五,能不能融入现有技术栈? 你的团队可能已经在用 Spark、Flink、Grafana,时序数据库能不能顺滑接进来,直接影响交付效率。
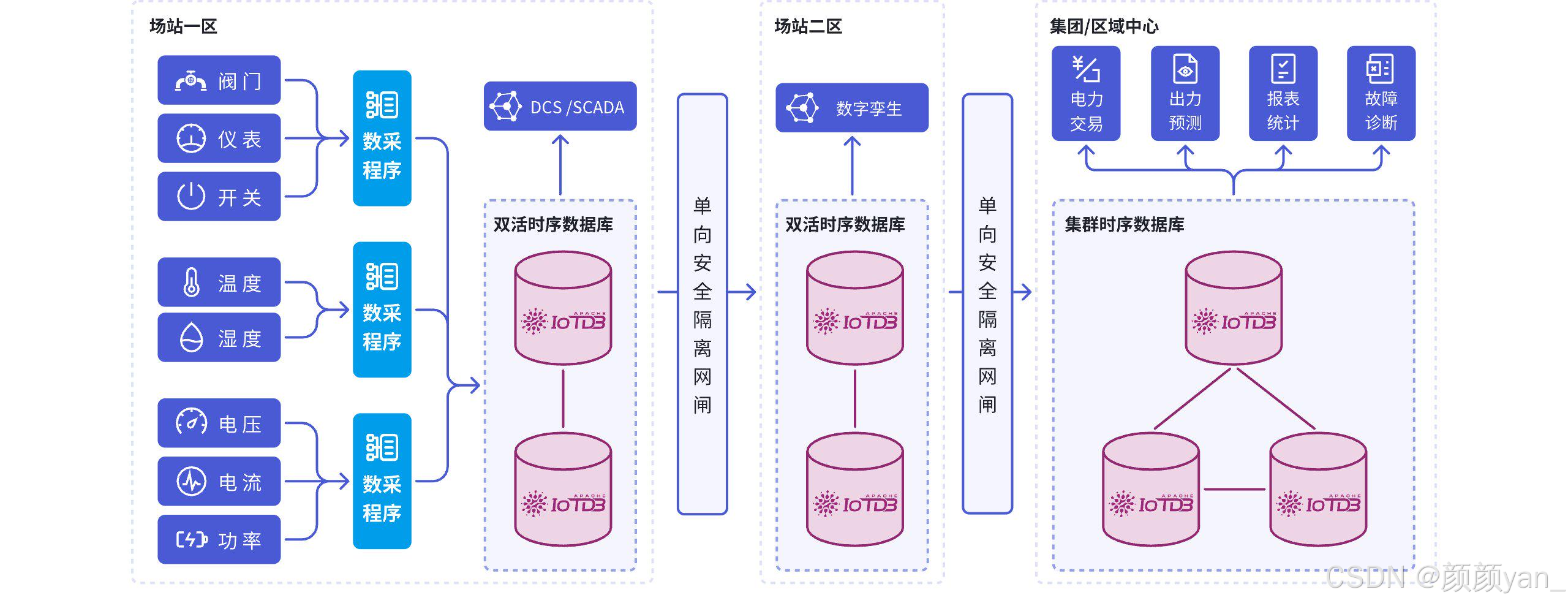
第六,有没有针对工业场景做过真正的架构优化? 工业现场的数据很复杂:设备类型多、协议杂、网络不稳定、设备层级深。一个只适合互联网监控数据的方案,在工业场景里可能会水土不服。
二、为什么我建议重点关注 Apache IoTDB
市面上的时序数据库不少,各家有各家的侧重点。Apache IoTDB的出发点是工业物联网,而不是往这个方向勉强扩展。
Apache IoTDB的定位很直接:工业物联网时序数据库管理系统,支持端边云协同的轻量化架构,面向时序数据的收集、存储、管理和分析。它强调多协议兼容、高压缩率、高吞吐读写、工业级稳定和极简运维。
再来看具体能力。IoTDB 支持数百万低功耗设备的高速写入,支持树形结构的设备管理(符合工业场景的层级关系),支持通配符元数据匹配,同时与 Hadoop、Spark、Flink、Grafana 等大数据生态有集成能力。这意味着,IoTDB 不只是"能存时序数据",而是可以作为平台底座,融入你现有技术栈的一个完整系统。
三、代码实战:从建模到查询
3.1 设备树建模 --- 工业场景的核心
工业场景的设备层级往往很深。比如一个电力集团,可能是这样的结构:
root
├── power_grid
│ ├── region_north
│ │ ├── substation_001
│ │ │ ├── transformer_01
│ │ │ │ ├── voltage
│ │ │ │ ├── current
│ │ │ │ └── temperature
│ │ │ └── transformer_02
│ │ │ ├── voltage
│ │ │ └── current
│ │ └── substation_002
│ └── region_south
└── wind_farm
├── turbine_001
│ ├── wind_speed
│ ├── power_output
│ └── blade_angle
└── turbine_002IoTDB 的树形设备管理天然支持这种结构。你不需要把所有设备打平成标签,而是直接用路径表示层级关系。这样做的好处是:查询时可以用通配符精确定位,维护时层级清晰,后期扩展也很方便。
3.2 批量写入 --- 高吞吐的关键
设备数据持续上报,你需要高效的批量写入。IoTDB 支持多种写入方式:
sql
-- 方式一:单条插入(不推荐用于高吞吐场景)
INSERT INTO root.power_grid.region_north.substation_001.transformer_01
(timestamp, voltage, current, temperature)
VALUES (1704067200000, 220.5, 150.3, 45.2);
-- 方式二:批量插入同一设备的多个时间点(推荐)
INSERT INTO root.power_grid.region_north.substation_001.transformer_01
(timestamp, voltage, current, temperature)
VALUES
(1704067200000, 220.5, 150.3, 45.2),
(1704067260000, 220.6, 150.1, 45.3),
(1704067320000, 220.4, 150.5, 45.1);
-- 方式三:多设备同时写入(真正的高吞吐)
INSERT INTO root.power_grid.region_north.substation_001.transformer_01
(timestamp, voltage, current, temperature),
root.power_grid.region_north.substation_001.transformer_02
(timestamp, voltage, current)
VALUES
(1704067200000, 220.5, 150.3, 45.2, 219.8, 149.9),
(1704067260000, 220.6, 150.1, 45.3, 219.9, 150.1);这种批量写入方式,在设备数量多、上报频率高的场景下,能显著提升吞吐量。
3.3 时间范围查询 --- 时序分析的基础
时序数据最常见的查询就是"某个时间段内的数据"。IoTDB 原生支持这种查询,而且语法很直观:
sql
-- 查询某个变压器在过去一小时内的电压和电流
SELECT voltage, current
FROM root.power_grid.region_north.substation_001.transformer_01
WHERE time >= 1704063600000 AND time < 1704067200000;
-- 查询多个变压器的数据(用通配符)
SELECT voltage, current
FROM root.power_grid.region_north.substation_001.*
WHERE time >= 1704063600000 AND time < 1704067200000;
-- 查询整个地区所有变压器的数据
SELECT voltage, current
FROM root.power_grid.region_north.**.transformer_*
WHERE time >= 1704063600000 AND time < 1704067200000;注意这里的通配符用法:* 匹配单层,** 匹配多层。这对工业场景特别有用,因为你经常需要跨多个层级聚合数据。
3.4 聚合和降采样 --- 降低存储和查询成本
时序数据最大的痛点之一是数据量太大。如果你有 100 万个设备,每个设备每秒上报一次数据,一天就是 8.64 亿条记录。长期存储这样的数据,成本会很恐怖。
IoTDB 支持原生的聚合和降采样,可以在查询时直接做数据压缩:
sql
-- 按小时聚合:计算每小时的平均电压
SELECT avg(voltage) as avg_voltage, max(current) as max_current
FROM root.power_grid.region_north.substation_001.transformer_01
WHERE time >= 1704000000000 AND time < 1704086400000
GROUP BY (1h);
-- 按 5 分钟降采样:每 5 分钟取一个数据点
SELECT first_value(voltage), last_value(current)
FROM root.power_grid.region_north.substation_001.transformer_01
WHERE time >= 1704000000000 AND time < 1704086400000
GROUP BY (5m);
-- 多个设备同时聚合
SELECT avg(voltage), max(temperature)
FROM root.power_grid.region_north.substation_001.*
WHERE time >= 1704000000000 AND time < 1704086400000
GROUP BY (1h);这种能力对成本控制很关键。你可以把原始数据存一周,然后自动降采样到小时级别存一年,这样既保留了细粒度数据用于故障排查,又大幅降低了长期存储成本。
3.5 异常检测场景 --- 实际应用示例
来看一个更贴近实际的场景:检测变压器温度异常。
sql
-- 查询过去 24 小时内温度超过 50°C 的记录
SELECT timestamp, temperature
FROM root.power_grid.region_north.substation_001.transformer_01
WHERE time >= now() - 86400000 AND temperature > 50
ORDER BY timestamp DESC;
-- 查询温度变化率异常的时间段(温度在 10 分钟内上升超过 5°C)
SELECT t1.timestamp, t1.temperature, t2.temperature
FROM root.power_grid.region_north.substation_001.transformer_01 t1,
root.power_grid.region_north.substation_001.transformer_01 t2
WHERE t1.timestamp = t2.timestamp + 600000
AND (t2.temperature - t1.temperature) > 5
AND t1.timestamp >= now() - 86400000;
-- 统计每小时温度超过阈值的次数
SELECT count(*) as over_threshold_count
FROM root.power_grid.region_north.substation_001.transformer_01
WHERE temperature > 50 AND time >= now() - 604800000
GROUP BY (1h);这些查询在传统数据库里需要自己写复杂的逻辑,但在 IoTDB 里都是原生支持的。
四、工程落地的几个实际优势
存储成本是长期账,不是短期账
很多选型团队在前期只看写入速度,却忽略了一个更现实的问题:数据要存三年,成本怎么算?
假设你有 100 万个设备,每个设备每 10 秒上报一次数据(3 个字段),一年的数据量大概是:
100 万设备 × 3 个字段 × (365 × 24 × 3600 / 10) 次 = 9.46 亿条记录如果用通用数据库,每条记录按 500 字节算,一年就是 473 GB。三年就是 1.4 TB。如果用云存储,这笔钱会很可观。
IoTDB 的高压缩率(通常能达到 10:1 以上)可以把这个数字压到 140 GB 左右,成本直接降 90%。这不是小数字。
查询语义真的做了时序优化
一个真正的时序数据库,不是把时间字段加进关系型表里就算完了,而是要让时序查询变得顺手。
比如你想查"过去 7 天内,每个变压器的最高温度",在 IoTDB 里是这样的:
sql
SELECT max(temperature)
FROM root.power_grid.region_north.substation_001.*
WHERE time >= now() - 604800000
GROUP BY (device);在传统数据库里,你可能需要:
sql
SELECT device_id, MAX(temperature)
FROM transformer_data
WHERE timestamp >= DATE_SUB(NOW(), INTERVAL 7 DAY)
GROUP BY device_id;看起来差不多,但当你的查询变得更复杂时(比如多个时间窗口、多个聚合函数、跨多个层级的设备),IoTDB 的优势就很明显了。
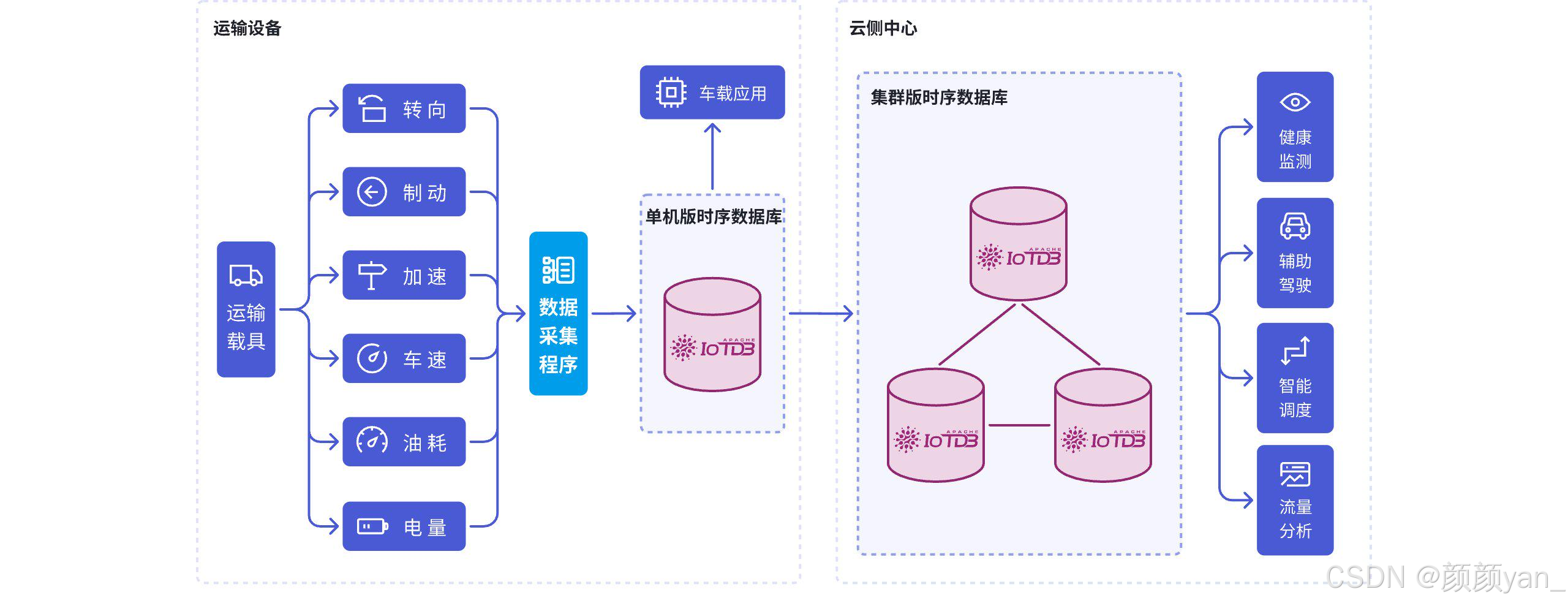
单机到集群有清晰的演进路径
很多团队要么一开始就上太重的分布式架构,运维压力巨大;要么只考虑了单机,后面扩容一团糟。
IoTDB 的架构设计允许你先用单机版验证业务逻辑,然后根据数据量和吞吐量需求,平滑升级到集群版。这个演进路径比较自然,也更符合大多数企业项目的实际节奏。
结语
时序数据库的选型没有放之四海而皆准的答案,但有一条判断标准是通用的:选一个真正为你的场景设计的产品,而不是把其他场景的优秀方案硬套进来。
如果你的业务涉及设备监控、工业制造、能源电力、车联网、智慧交通或智慧园区,数据来源持续不断、时间维度分析很重要、数据还需要长期保存,那 Apache IoTDB 真的值得进入你的 shortlist 重点评估。
- 🔗 开源下载:https://iotdb.apache.org/zh/Download/
- 🔗 企业版官网:https://timecho.com