RNN
如何处理序列信息
词向量取均值:忽略语序信息,将所有词语视为同等重要。
全连接网络(Fully Connected Network, FCN):每个词元孤立处理,没有考虑上下文的顺序关系和依赖关系。
1D-CNN:可以获取局部依赖关系,但感受野固定,无法设定所有句子的最佳窗口大小。
RNN 的思想是在处理序列的每一步时,网络不仅接收当前时间步的输入 xt,还会接收一个来自上一步的"记忆",即隐藏状态 ht−1。
所有时间步的U和W是共享的,可以处理任意长度的时间序列。
实践代码
python
import torch
import torch.nn as nn
import numpy as np
# 约定: (B, T, E, H) 分别表示 批次/序列长度/输入维度/隐藏维度
B, E, H = 1, 128, 3
def prepare_inputs():
"""
使用 NumPy 准备输入数据
使用示例句子: "播放 周杰伦 的 《稻香》"
构造最小词表和随机(可复现)词向量, 生成形状为 (B, T, E) 的输入张量。
"""
np.random.seed(42)
vocab = {"播放": 0, "周杰伦": 1, "的": 2, "《稻香》": 3}
tokens = ["播放", "周杰伦", "的", "《稻香》"]
ids = [vocab[t] for t in tokens]
# 词向量表: (V, E)
V = len(vocab)
emb_table = np.random.randn(V, E).astype(np.float32)
# 取出序列词向量并加上 batch 维度: (B, T, E)
x_np = emb_table[ids][None]
return tokens, x_np
def manual_rnn_numpy(x_np, U_np, W_np):
"""
使用 NumPy 手动实现 RNN(无偏置): h_t = tanh(U x_t + W h_{t-1})
Args:
x_np: (B, T, E)
U_np: (E, H)
W_np: (H, H)
Returns:
outputs: (B, T, H)
final_h: (B, H)
"""
B_local, T_local, _ = x_np.shape
h_prev = np.zeros((B_local, H), dtype=np.float32)
steps = []
for t in range(T_local):
x_t = x_np[:, t, :]
h_t = np.tanh(x_t @ U_np + h_prev @ W_np)
print(h_t,x_t,h_prev,W_np)
steps.append(h_t)
h_prev = h_t
outputs = np.stack(steps, axis=1)
return outputs, h_prev
def pytorch_rnn_forward(x, U, W):
"""
使用api nn.RNN (tanh, bias=False)。
Returns:
outputs: (B, T, H)
final_h: (B, H)
"""
rnn = nn.RNN(
input_size=E,
hidden_size=H,
num_layers=1,
nonlinearity='tanh',
bias=False,
batch_first=True,
bidirectional=False,
)
with torch.no_grad():
# PyTorch 内部存放的是转置后的权重
rnn.weight_ih_l0.copy_(U.T)
rnn.weight_hh_l0.copy_(W.T)
y, h_n = rnn(x)
return y, h_n.squeeze(0)
_, x_np = prepare_inputs()
# PyTorch 张量,用于 nn.RNN 模块
x = torch.from_numpy(x_np).float()
# 使用可学习参数 U, W(无偏置)
torch.manual_seed(7)
U = torch.randn(E, H)
W = torch.randn(H, H)
# --- 手写 RNN (使用 NumPy) ---
U_np = U.detach().numpy()
W_np = W.detach().numpy()
print("--- 手写 RNN (NumPy) ---")
out_manual_np, hT_manual_np = manual_rnn_numpy(x_np, U_np, W_np)
print("输入形状:", x_np.shape)
print("手写输出形状:", out_manual_np.shape)
print("手写最终隐藏形状:", hT_manual_np.shape)
print("\n--- PyTorch nn.RNN ---")
out_torch, hT_torch = pytorch_rnn_forward(x, U, W)
print("模块输出形状:", out_torch.shape)
print("模块最终隐藏形状:", hT_torch.shape)
print("\n--- 对齐验证 ---")
# 将 NumPy 结果转回 PyTorch 张量以进行比较
out_manual = torch.from_numpy(out_manual_np)
hT_manual = torch.from_numpy(hT_manual_np)
print("逐步输出一致:", torch.allclose(out_manual, out_torch, atol=1e-6))
print("最终隐藏一致:", torch.allclose(hT_manual, hT_torch, atol=1e-6))
print("最后一步输出等于最终隐藏:", torch.allclose(out_torch[:, -1, :], hT_torch, atol=1e-6))
python
h_w = W
h_u = U
ht = torch.zeros(B, H)
_, x_np = prepare_inputs()
x = torch.from_numpy(x_np)
T = x.shape[1]
for t in range(T):
x_t = x[:, t,:]
h_prev = ht
ht = F.tanh(h_prev @ h_w + x_t @ h_u)
print(ht)
print(ht[-1])
print(F.softmax(ht[-1]))双向神经网络BiRNN
同时训练从左向右的正向RNN和从右往左的反向RNN,其中参数独立但损失相加,能够同时被正向反向网络优化bidirectional参数设置为 True,hidden_size为原来的两倍,存储当前时间步的正向隐藏层和反向隐藏层。
BiRNN依旧没有解决长距离依赖问题并且无法用于实时预测场景(需要提前看到后文)。
反向传播:重点!
反向传播会有一个累乘导致梯度消失,影响的是比较靠后的时间步在表征时吃不到前面的信息。




LSTM与GRU
LSTM
双轨并行:细胞状态Ct用于长期记忆,按元素加权与相加,无连乘;Ht短期记忆与当前的输出,计算依赖当前的Ct。
**门结构:**sigmoid为激活函数的全连接层,输入是xt和ht-1的拼接向量,输出是一个元素值在0-1内的向量,该向量用于与其他向量的按元素乘法。
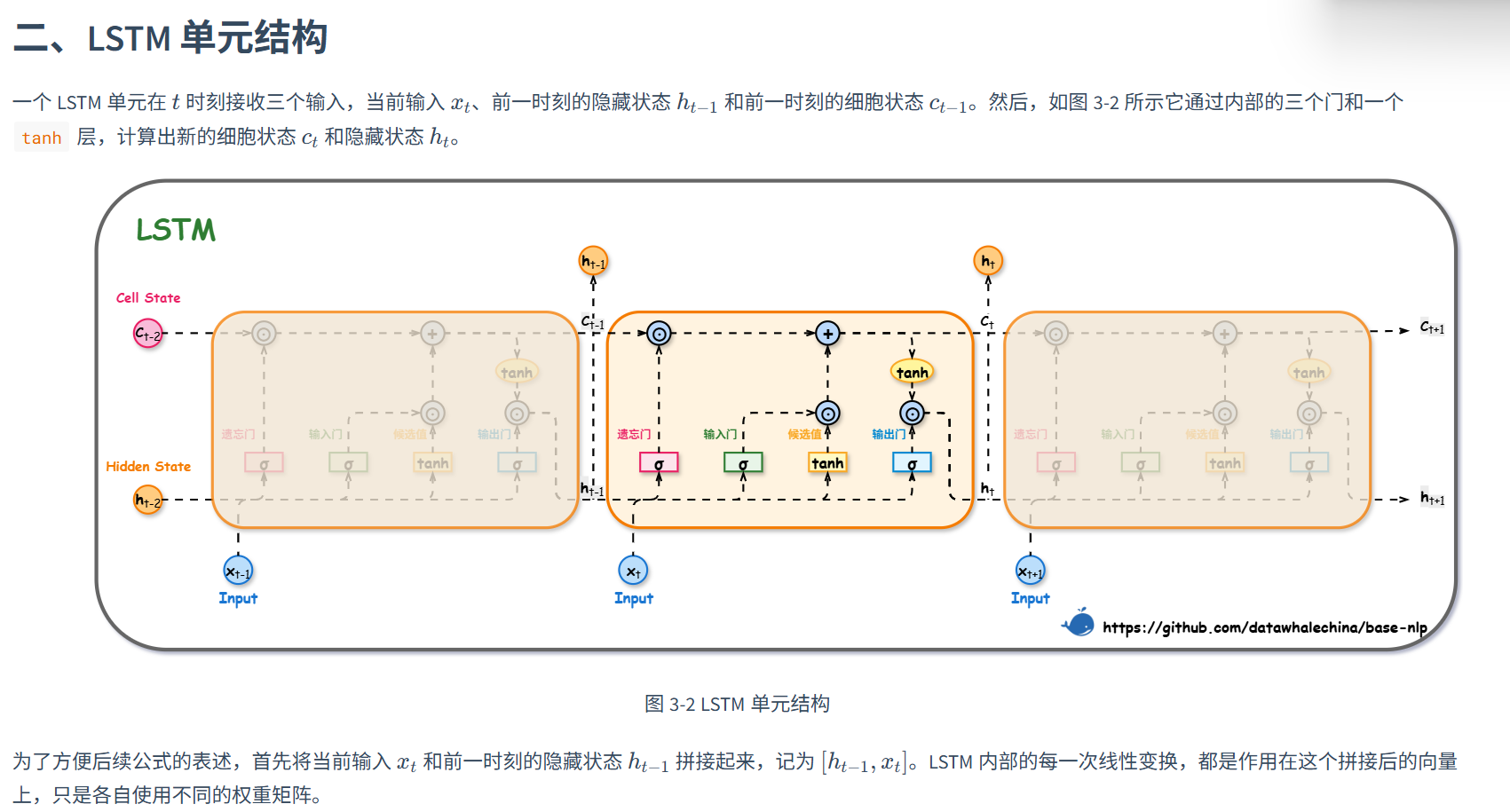
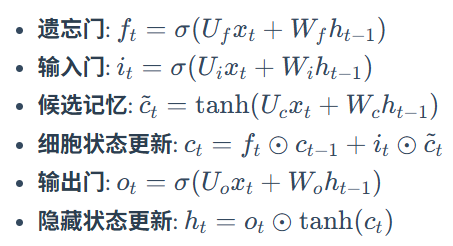
等价于
LSTM如何解决长距离依赖:重点!
ft的连乘由Uf和Wf掌控,这两部分参数是可以学习的,可以使得


| 模型 | 梯度回传的乘积项 | 长距离下的梯度变化 |
|---|---|---|
| 普通 RNN | ∏(tanh′⋅Wh),每一项都 < 1,被动衰减 | 指数衰减到 0,梯度消失 |
| LSTM | ∏fi,每一项由模型控制,关键信息下接近 1 | 几乎不衰减,梯度稳定回传 |
GRU
不再区分ct和ht,只在ht上进行传播,另一个是简化门控结构 ,将 LSTM 的三个门简化为了两个门。其中更新门(Update Gate, ztzt) 的作用类似于 LSTM 中耦合的遗忘门和输入门,同时决定了保留多少旧信息以及接收多少新信息;**重置门(Reset Gate, rtrt)**则决定在计算候选状态时忽略多少旧信息。
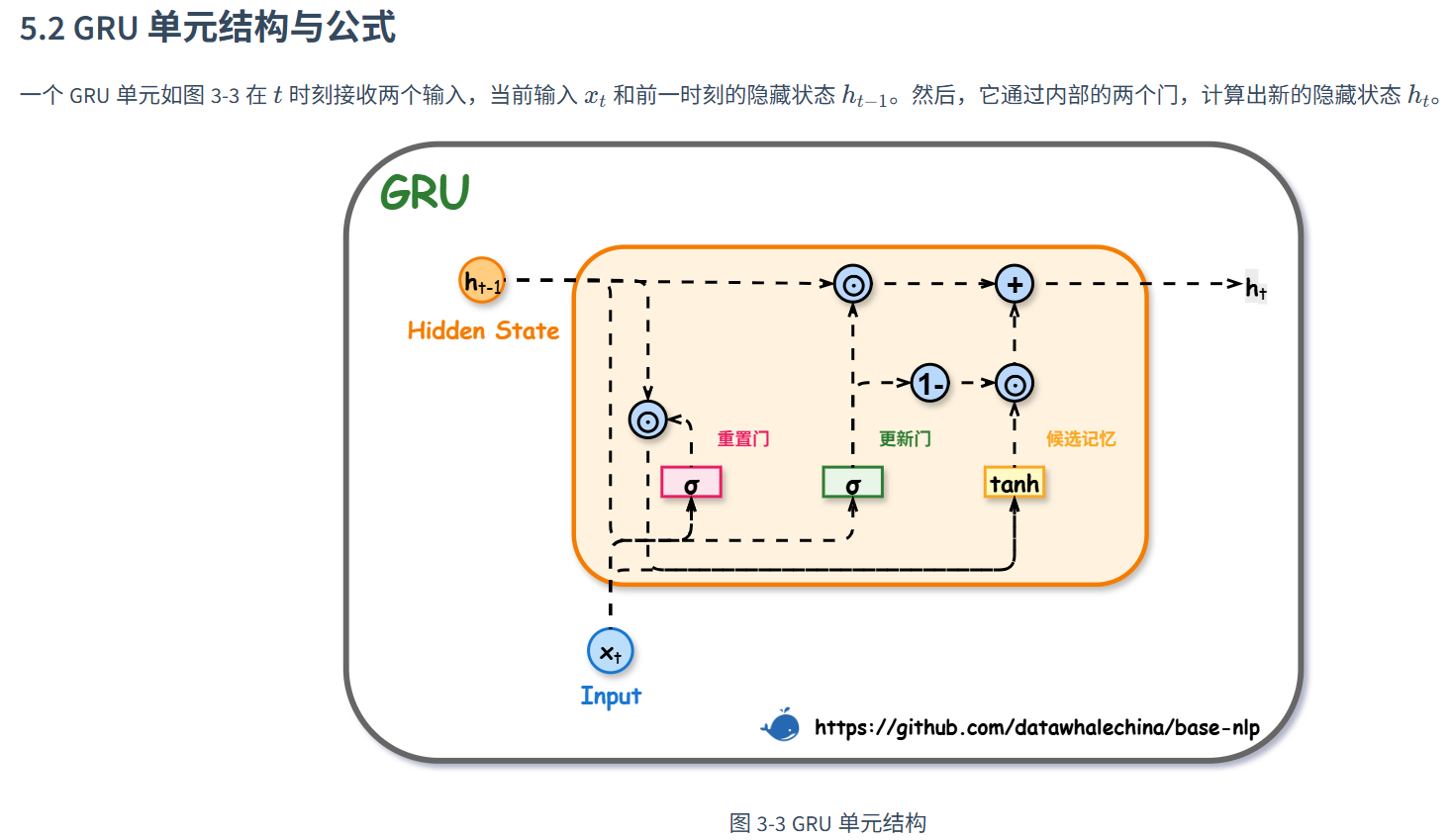

LSTM变体
窥孔连接 ,允许门控单元直接访问细胞状态:遗忘门和输入门 在做决策时会"窥视" 前一时刻的细胞状态 ct−1,而输出门在做决策时则会"窥视" **当前刚刚更新的细胞状态 ct**。
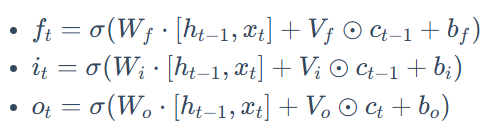
耦合输出门和遗忘门,遗忘门= 1-输出门
基于LSTM做文本分类
与之前dnn的dataset,dataloader基本一致,collate_fn加上返回长度张量,Trainer和Predictor在遍历解析dataloader也同样要做长度张量的解析。
python
def collate_fn(batch):
max_batch_len = max(len(item["token_ids"]) for item in batch)
batch_token_ids, batch_labels, batch_lengths = [], [], []
for item in batch:
token_ids = item["token_ids"]
# 新增:记录真实长度
lengths = len(token_ids)
padding_len = max_batch_len - lengths
padded_ids = token_ids + [0] * padding_len
batch_token_ids.append(padded_ids)
batch_labels.append(item["label"])
# 新增:将长度加入列表
batch_lengths.append(lengths)
return {
"token_ids": torch.tensor(batch_token_ids, dtype=torch.long),
"labels": torch.tensor(batch_labels, dtype=torch.long),
# 新增:返回长度张量
"lengths": torch.tensor(batch_lengths, dtype=torch.long),
}模型构建
forward函数现在额外接收lengths参数。- 打包 (Packing) :
pack_padded_sequence是处理填充序列的关键。它会将一个填充过的批次数据(例如,多个句子被填充到相同长度)压缩成一个更紧凑的表示,LSTM 只需对真实的、非填充部分进行计算,大大提高了效率和准确性。 - 最终状态提取 :LSTM 的输出
hidden张量包含了所有层在最后一个时间步的隐藏状态。我们通常取最后一层(对于单向 LSTM 是hidden[-1,:,:])作为整个序列的语义表示。如果是双向 LSTM,则需要拼接前向和后向的最终隐藏状态。 - 最后,将这个代表序列的
hidden向量送入分类器。
python
class TextClassifierLSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_classes,
n_layers=1, dropout=0.3, bidirectional=False):
super(TextClassifierLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(
input_size=embed_dim,
hidden_size=hidden_dim,
num_layers=n_layers,
dropout=dropout,
bidirectional=bidirectional,
batch_first=True # 关键参数:输入和输出张量的维度为 (batch, seq, feature)
)
num_directions = 2 if bidirectional else 1
self.classifier = nn.Linear(hidden_dim * num_directions, num_classes)
def forward(self, token_ids, lengths):
embedded = self.embedding(token_ids)
# 1. 打包序列
packed_embedded = nn.utils.rnn.pack_padded_sequence(
embedded,
lengths.cpu(), # 长度必须在CPU上
batch_first=True,
enforce_sorted=False
)
# 2. LSTM 前向传播
# hidden 和 cell 的形状: [n_layers * num_directions, batch_size, hidden_dim]
packed_output, (hidden, cell) = self.lstm(packed_embedded)
# 3. 提取最终隐藏状态用于分类
if self.lstm.bidirectional:
# 拼接最后一个时间步的前向和后向的隐藏状态
# hidden[-2,:,:] 是前向的最后一个隐藏状态
# hidden[-1,:,:] 是后向的最后一个隐藏状态
hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)
else:
# 只取最后一层的最后一个隐藏状态
hidden = hidden[-1,:,:]
# 4. 分类
logits = self.classifier(hidden)
return logits