ICMR2024 对比学习与知识蒸馏技术相结合应用于图像超分辨率重建
1. 摘要
近年来,得益于深度学习的发展,单幅图像超分辨率(Single Image Super-Resolution, SISR)技术得到了快速的进步。然而,为了取得更好的性能,大多数基于卷积神经网络(Convolutional Neural Networks, CNNs)的方法盲目地加深网络深度,导致模型参数量大 ,不可避免地带巨大的计算开销和内存消耗 ,限制了其在资源受限设备上的应用。
针对这个问题,作者提出了一种基于对比学习的知识蒸馏框架 ,对参数量大的超分辨率模型进行压缩和加速 。学生网络的构建方式非常经典------直接减少教师网络的层数(很多知识蒸馏的文章都是这么操作的,如ECCV2024 MTKD等。具体而言,该方法从教师网络中蒸馏中间特征图的统计信息 (在空间维度上计算相似度),用于训练轻量级的学生网络。此外,通过显式知识迁移,引入了一种新的对比损失函数,以提高学生网络的重建性能。
实验结果表明,所的对比蒸馏框架在可接受性能损失的前提下,能够有效地压缩模型大小。
2. 引言
对于单幅图像超分这个任务,作者认为现有的CNN方法虽然取得了显著进展,但往往伴随着巨大的参数量和计算开销 (如EDSR超过4300万参数 ,RCAN推理单张图像需要919.20G FLOPs的计算量 ),难以直接部署在资源受限的设备上。因此,亟需设计计算高效的图像超分模型 。知识蒸馏(Knowledge Distillation, KD)作为一种迁移学习手段,能够通过预训练的复杂教师网络来指导学生网络的训练。然而,目前大多数知识蒸馏方法主要聚焦于高级视觉任(如图像分类) ,而图像超分作为像素级回归预测的低层视觉任务,如何有效利用知识蒸馏来压缩超分模型仍然是一个亟待研究的问题。
与现有主要依赖正样本信息 的方法不同,作者提出了一种将对比学习融入蒸馏过程 的新框架。具体来说,作者将教师网络生成的超分图像作为正样本 ,同时引入无关的超分图像作为负样本 。通过这种对比学习机制,学生网络的输出在向量空间中需要与教师网络的输出紧密对齐,同时远离负样本的表示 。通过同时利用正负样本信息,该框架为蒸馏过程设定了解空间的上界和下界,从而在不增加额外计算负担的前提下进一步提升网络性能。
作者的贡献总结如下:
- 作者将对比学习引入到超分任务的知识蒸馏中,利用正负样本信息共同约束学生网络的学习,弥补了现有知识蒸馏方法在超分任务中仅依赖正样本的局限性;
- 通过教师网络输出作为正样本、无关图像作为负样本 的对比学习策略,该框架为学生网络的解空间设定了上下界,有效提升了蒸馏效率与重建质量;
- 所提出的方法在不增加推理计算开销的前提下,显著提升了轻量化超分网络的性能,为资源受限场景下的超分模型部署提供了新的解决方案。
3. 相关工作
3.1 图像超分
- Dong等人提出了第一个基于CNN的超分方法------SRCNN。
- Lim等人使用局部和残差连接,提出了EDSR,模型参数量超过4300万。
- RCAN引入了通道注意力和二阶通道注意力,可以利用特征的相关性来提高性能,但是其卷积层数量超过800,模型参数量超过1500万。
- 一些轻量化模型结构也被提出以减少模型冗余,例如GhostSR。
3.2 知识蒸馏应用于视觉任务
- Hinton等人第一次提出知识蒸馏的概念------KD。
- Tung等他提出了一种新的蒸馏损失,鼓励学生网络生成的特征图与教师网络对应的特征图之间保持统计相似性。
- Gao等人首次将知识蒸馏引入到了图像超分领域。
- 为了有效传递结构知识,He等人提出了FAKD框架,旨在从特征图中提取二阶统计信息,以低计算和内存成本训练一个轻量级的图像超分学生网络。
4. 方法
作者提出了一种基于知识蒸馏的模型压缩方法,用于参数量庞大的超分模型。该框架的整体结构如下图所示,学生网络中的特征提取块数量远少于教师网络,以此减小学生模型的参数量。该方法主要包含两个核心模块及一个扩展模块:
- 知识蒸馏(Knowledge Distillation);
- 对比学习(Contrastive Learning);
- 幽灵特征模块(Ghost Feature Module);
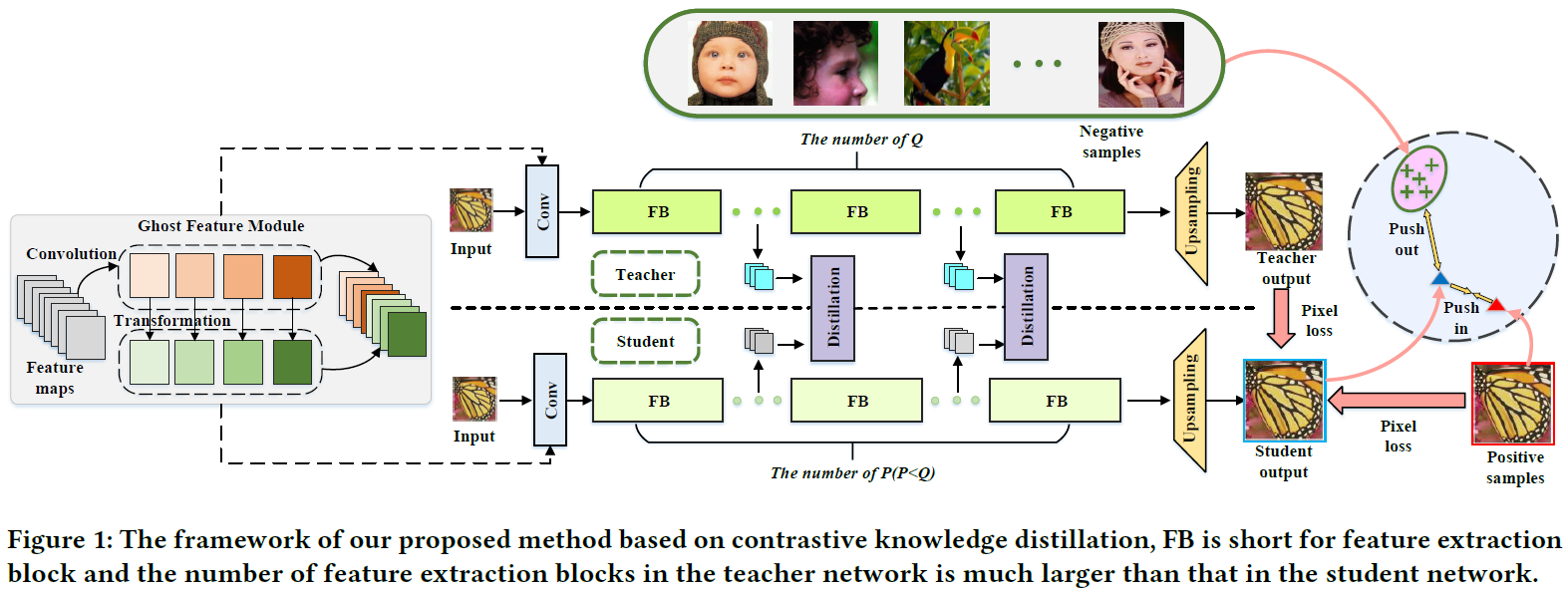
4.1 知识蒸馏
为了将教师网络中的知识迁移到学生网络,作者提出通过计算中间输出特征图的统计相似性 来实现知识蒸馏。相似度矩阵越接近,蒸馏效果越好。在论文中,分别提取了网络的前部、中部和后部 三个阶段的特征图,它们分别对应初级、中级和高级的视觉信息。这种分层区分的特征能够更好地促进学生网络模仿教师网络的特征生成方式。
具体来说,给定教师网络第 l l l个中间层的激活特征图 F t l ∈ R B × C × H × W F_t^l \in \mathbb{R}^{B \times C \times H \times W} Ftl∈RB×C×H×W和学生网络的特征图 F s l ∈ R B × C × H × W F_s^l \in \mathbb{R}^{B \times C \times H \times W} Fsl∈RB×C×H×W,通过简单的特征变换得到 F ~ t l \tilde{F}_t^l F~tl 和 F ~ s l \tilde{F}_s^l F~sl,然后进行特征归一化,得到用于蒸馏的特征图相似性矩阵 A ^ t l \hat{A}_t^l A^tl 和 A ^ s l \hat{A}_s^l A^sl。实现过程如下:
A t l = A ~ t l / ∥ A ~ t l ∥ 2 ; A ~ t l = F ~ t l ⋅ F ~ t l ⊤ A_t^l = \tilde{A}_t^l / \|\tilde{A}_t^l\|_2; \quad \tilde{A}_t^l = \tilde{F}_t^l \cdot \tilde{F}_t^{l \top} Atl=A~tl/∥A~tl∥2;A~tl=F~tl⋅F~tl⊤
A s l = A ~ s l / ∥ A ~ s l ∥ 2 ; A ~ s l = F ~ s l ⋅ F ~ s l ⊤ A_s^l = \tilde{A}_s^l / \|\tilde{A}_s^l\|_2; \quad \tilde{A}_s^l = \tilde{F}_s^l \cdot \tilde{F}_s^{l \top} Asl=A~sl/∥A~sl∥2;A~sl=F~sl⋅F~sl⊤
作者重点关注特征的空间相似性 ,这种相似性能够捕捉图像空间中像素之间的成对相似关系。在空间相似性计算中, F t l F_t^l Ftl和 F s l F_s^l Fsl分别被重塑为 F ~ t l ∈ R B × H W × C \tilde{F}_t^l \in \mathbb{R}^{B\times HW \times C} F~tl∈RB×HW×C和 F ~ s l ∈ R B × H W × C \tilde{F}_s^l \in \mathbb{R}^{B\times HW \times C} F~sl∈RB×HW×C,然后通过上述公式得到用于蒸馏的特征图 { A t l , A s l } ∈ R B × H W × H W \{A_t^l,A_s^l\}\in \mathbb{R}^{B\times HW \times HW} {Atl,Asl}∈RB×HW×HW。
最终,为了鼓励学生网络生成与教师网络相似的特征模式,蒸馏损失函数的定义如下:
L K D = 1 ∣ A ∣ ∑ l = 1 N ∥ A t l − A s l ∥ 2 L_{KD} = \frac{1}{|A|} \sum_{l=1}^{N} \left\| A_t^l - A_s^l \right\|_2 LKD=∣A∣1l=1∑N Atl−Asl 2
其中 ∣ A ∣ |A| ∣A∣ 表示相似性矩阵中的元素数量, N N N 表示提取中间特征的层数。
4.2 对比学习
在本文中,作者将学生网络生成的样本 O S O_S OS视为特征空间中的锚点(anchor) 。训练过程中提供的原始高分辨率(HR)图像作为正样本 ,记作 O P o s O_{Pos} OPos。在每个训练批次中,作者选择 K K K张与当前输入图像内容不同的低分辨率(LR)图像作为负样本 ,记作 { O N e g ( i ) , i = 1 , 2 , ... , K } \{O_{Neg}^{(i)}, i = 1, 2, \dots, K\} {ONeg(i),i=1,2,...,K}。这些LR图像通过双三次插值上采样到与正样本相同的分辨率。
参考感知损失的操作,作者通过VGG网络将样本投影到特征空间。基于正负样本的对比损失函数可表示为以下形式:
L C L = ∑ j = 1 M ∥ Φ j ( O S ) − Φ j ( O P o s ) ∥ 1 ∑ i = 1 K ∥ Φ j ( O S ) − Φ j ( O N e g ( i ) ) ∥ 1 L_{CL} = \sum_{j=1}^{M} \frac{\left\| \Phi_j(O_S) - \Phi_j(O_{Pos}) \right\|1}{\sum{i=1}^{K} \left\| \Phi_j(O_S) - \Phi_j(O_{Neg}^{(i)}) \right\|_1} LCL=j=1∑M∑i=1K Φj(OS)−Φj(ONeg(i)) 1∥Φj(OS)−Φj(OPos)∥1
其中 Φ j ( . ) \Phi_j(.) Φj(.)表示预训练VGG网络中第 j j j层的特征提取操作, M M M表示隐藏层的总数。
通过训练,上述对比损失引入了约束:将学生网络的输出 O S O_S OS在语义空间中拉近 到正样本 O P o s O_{Pos} OPos附近;推着 O S O_S OS在语义空间中远离 负样本 O N e g ( i ) O_{Neg}^{(i)} ONeg(i)。
最终,总损失函数为:
L a l l = α L S R + β L K D + γ L C L L_{all} = \alpha L_{SR} + \beta L_{KD} + \gamma L_{CL} Lall=αLSR+βLKD+γLCL
其中 L S R L_{SR} LSR用于衡量超分图像与真实图像在像素级别上的距离。在论文中 α = 1 , β = 1 , γ = 200 \alpha=1, \beta=1, \gamma=200 α=1,β=1,γ=200。
4.3 幽灵特征模块
在本文中,作者还提出了一个模型变体,即在对比知识蒸馏框架中使用幽灵特征(Ghost Feature) 。幽灵特征出自CVPR2022 GhostNet论文。为了减少神经网络的计算消耗,提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过廉价简单的线性变化操作来进一步高效地生成幽灵特征。
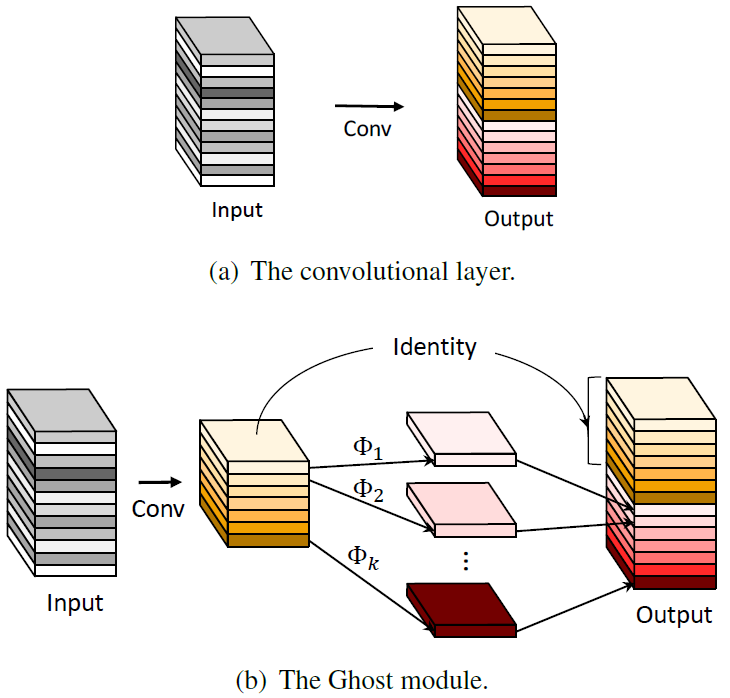
假设RCAN-B20G10是作者使用的教师模型,B20代表该模型有每个RCAB里面有20个残差块,G10代表该模型一共有10个RCAB;RCAN-B6G10是作者使用的学生模型,可以发现学生模型的RCAB更简单,但是RCAB的数量是相同的;RCAN-B6G10-G表示在此基础上使用幽灵特征,Ghost操作是从一部分"固有特征"中高效地"生成"出更多的"幽灵特征图",这也意味着RCAN-B6G10-G不需要那么多通道数,通常来说使用幽灵特征可以大大压缩参数,但同时会增加GPU占用和推理时间。

5. 实验
5.1 实验设置和细节
训练集:DIV2K。
测试集:Set5、Set14、BSD100和Urban100。
评估指标:YCbCr颜色空间的Y通道的PSNR和SSIM。
基线模型:RCAN和SAN。
5.2 客观比较
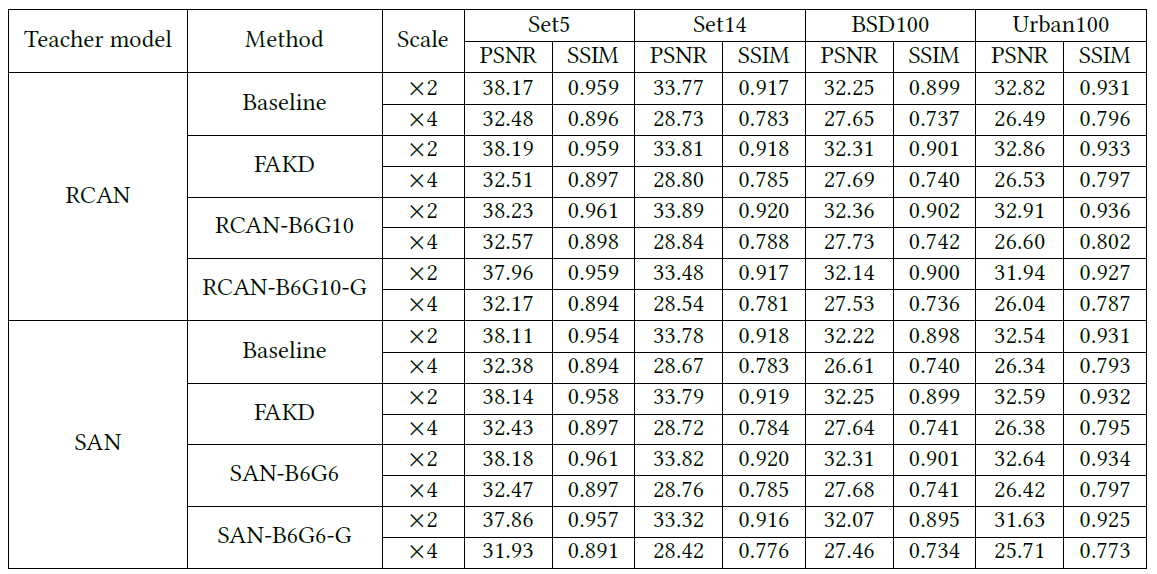
下表展示了在×2和×4尺度下训练RCAN和SAN网络的定量结果(PSNR/SSIM)。从这些结果可以得出以下结论:
-
以RCAN为例,Baseline是只使用重建损失训练的超分模型,效果不如使用了知识蒸馏的超分模型(如FAKD和RCAN-B6G10)。
-
作者使用对比蒸馏框架训练的学生模型RCAN-B6G10,在所有测试集中均优于FAKD。
-
RCAN-B6G10-G是使用幽灵特征的参数量更小的模型,参数量约为RCAN-B6G10的20%,其超分性能依旧客观。
-
笔者认为该实验有部分不足之处:与现有方法的对比过少,只有Baseline和FAKD,应该多与其他知识蒸馏框架做对比,如2018ACCV Gao等人方法和2022ICPR MTKDSR等,才能展示所提方法的先进性。
5.3 主观比较

5.4 消融实验
不同损失函数的消融实验
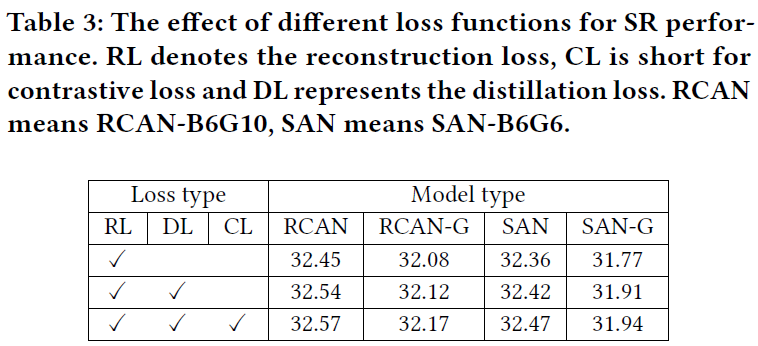
在RCAN、RCAN-G、SAN和SAN-G四个模型中,以重建损失(RL)为基础,依次添加中间特征相似度损失(DL)和对比损失(CL),模型的性能都有进一步提升。
具体地,通过引入蒸馏损失(DL和CL),可以将鲁棒模型的知识迁移到学生模型中,从而提升学生模型的性能。这种提升在小型模型中更为显著。例如,对于模型SAN-B6G6-G,其模型参数量仅为0.746M,通过蒸馏损失,PSNR值提升了0.17dB。
6. 结论
本文提出了一种基于知识蒸馏的模型压缩框架,该框架能够通过对比学习 有效地压缩任何大型模型。在训练过程中,对比学习策略尽可能地将模型的解空间限制在与内容相关的正样本附近,并远离与内容无关的负样本 。为了进一步减少模型参数量,提出使用幽灵特征生成代替原始网络的卷积模块,从而显著降低网络的冗余度,并获得一个更轻量级的网络。实验结果表明,对于参数量较大的超分辨率模型,所提知识蒸馏框架具有较好的加速压缩效果。
7. 文章待改进点
本文在对比学习与知识蒸馏结合方面给出了很有价值的探索,出于学术交流与后续研究的角度,这里也想冒昧地提出几点可以进一步完善的方面,说得不对的地方还请见谅:
-
实验对比可以更加充分 :目前主要对比了Baseline和FAKD,若能与更多知识蒸馏方法(如2018ACCV Gao等人方法和2022ICPR MTKDSR等)进行对比,或许能更全面地展示所提框架的先进性。
-
鼓励代码开源:考虑到论文提出的蒸馏框架具有较强的通用性,如果能在论文接收后开源代码(哪怕只提供推理部分的代码),相信会极大地方便后续研究者复现和拓展,也有助于促进该方向的科研生态。
-
公式部分存在笔误:公式(4)中绿色箭头与红色箭头所指的公式项相同,推测其中一个是教师网络的特征相似度矩阵,另一个是学生网络的特征相似度矩阵。虽然不影响整体理解,但如果能在修订时加以区分,会让读者更加清晰。
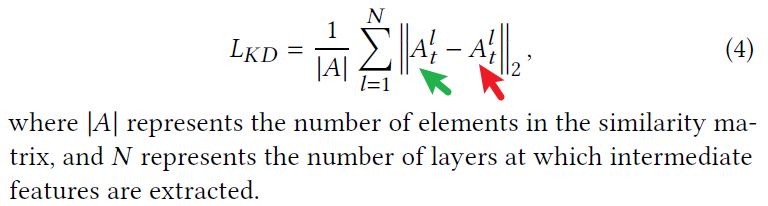
最后感谢小伙伴们的学习噢~