4.4 Reflection
在我们已经实现的 ReAct 和 Plan-and-Solve 范式中,智能体一旦完成了任务,其工作流程便告结束。然而,它们生成的初始答案,无论是行动轨迹还是最终结果,都可能存在谬误或有待改进之处。Reflection 机制的核心思想,正是为智能体引入一种事后(post-hoc)的自我校正循环,使其能够像人类一样,审视自己的工作,发现不足,并进行迭代优化。
4.4.1 Reflection 机制的核心思想
Reflection 机制的灵感来源于人类的学习过程:我们完成初稿后会进行校对,解出数学题后会进行验算。这一思想在多个研究中得到了体现,例如 Shinn, Noah 在2023年提出的 Reflexion 框架3。其核心工作流程可以概括为一个简洁的三步循环:执行 -> 反思 -> 优化。
-
执行 (Execution):首先,智能体使用我们熟悉的方法(如 ReAct 或 Plan-and-Solve)尝试完成任务,生成一个初步的解决方案或行动轨迹。这可以看作是"初稿"。
-
反思 (Reflection)
:接着,智能体进入反思阶段。它会调用一个独立的、或者带有特殊提示词的大语言模型实例,来扮演一个"评审员"的角色。这个"评审员"会审视第一步生成的"初稿",并从多个维度进行评估,例如:
- 事实性错误:是否存在与常识或已知事实相悖的内容?
- 逻辑漏洞:推理过程是否存在不连贯或矛盾之处?
- 效率问题:是否有更直接、更简洁的路径来完成任务?
- 遗漏信息 :是否忽略了问题的某些关键约束或方面? 根据评估,它会生成一段结构化的反馈 (Feedback),指出具体的问题所在和改进建议。
-
优化 (Refinement):最后,智能体将"初稿"和"反馈"作为新的上下文,再次调用大语言模型,要求它根据反馈内容对初稿进行修正,生成一个更完善的"修订稿"。
如图4.3所示,这个循环可以重复进行多次,直到反思阶段不再发现新的问题,或者达到预设的迭代次数上限。我们可以将这个迭代优化的过程形式化地表达出来。假设 OiO**i 是第 ii 次迭代产生的输出(O0O 0 为初始输出),反思模型 πreflectπ reflect 会生成针对 OiO**i 的反馈 FiF**i :Fi=πreflect(Task,Oi)F**i =π reflect(Task,O**i )随后,优化模型 πrefineπ refine 会结合原始任务、上一版输出以及反馈,生成新一版的输出 Oi+1O**i +1:Oi+1=πrefine(Task,Oi,Fi)O**i +1=π refine(Task,O**i ,F**i)
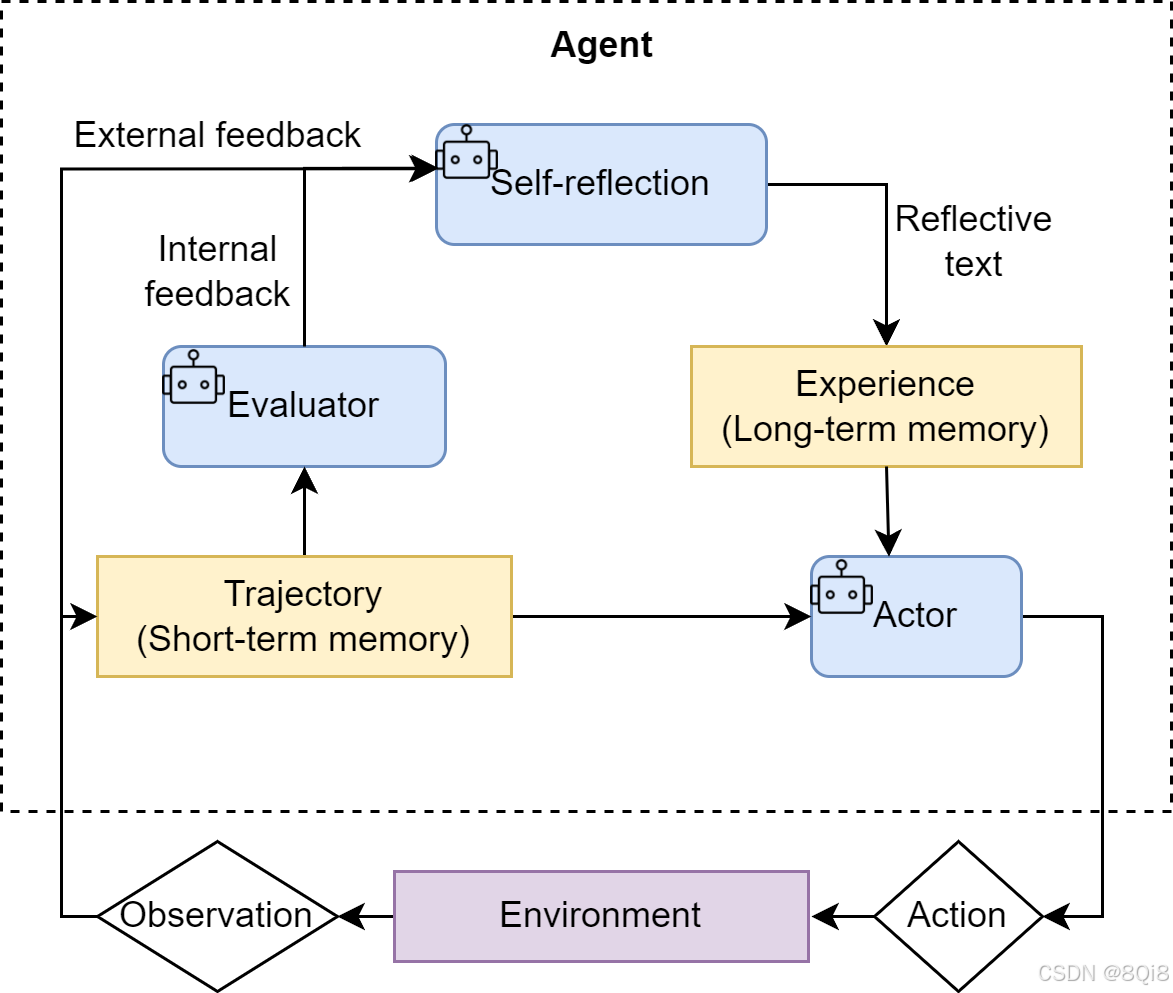
图 4.3 Reflection 机制中的"执行-反思-优化"迭代循环
与前两种范式相比,Reflection 的价值在于:
- 它为智能体提供了一个内部纠错回路,使其不再完全依赖于外部工具的反馈(ReAct 的 Observation),从而能够修正更高层次的逻辑和策略错误。
- 它将一次性的任务执行,转变为一个持续优化的过程,显著提升了复杂任务的最终成功率和答案质量。
- 它为智能体构建了一个临时的**"短期记忆"。整个"执行-反思-优化"的轨迹形成了一个宝贵的经验记录,智能体不仅知道最终答案,还记得自己是如何从有缺陷的初稿迭代到最终版本的。更进一步,这个记忆系统还可以是多模态的**,允许智能体反思和修正文本以外的输出(如代码、图像等),为构建更强大的多模态智能体奠定了基础。
4.4.2 案例设定与记忆模块设计
为了在实战中体现 Reflection 机制,我们将引入记忆管理机制,因为reflection通常对应着信息的存储和提取,如果上下文足够长的情况,想让"评审员"直接获取所有的信息然后进行反思往往会传入很多冗余信息。这一步实践我们主要完成代码生成与迭代优化。
这一步的目标任务是:"编写一个Python函数,找出1到n之间所有的素数 (prime numbers)。"
这个任务是检验 Reflection 机制的绝佳场景:
- 存在明确的优化路径:大语言模型初次生成的代码很可能是一个简单但效率低下的递归实现。
- 反思点清晰:可以通过反思发现其"时间复杂度过高"或"存在重复计算"的问题。
- 优化方向明确:可以根据反馈,将其优化为更高效的迭代版本或使用备忘录模式的版本。
Reflection 的核心在于迭代,而迭代的前提是能够记住之前的尝试和获得的反馈。因此,一个"短期记忆"模块是实现该范式的必需品。这个记忆模块将负责存储每一次"执行-反思"循环的完整轨迹。
python
from typing import List, Dict, Any, Optional
class Memory:
"""
一个简单的短期记忆模块,用于存储智能体的行动与反思轨迹。
"""
def __init__(self):
"""
初始化一个空列表来存储所有记录。
"""
self.records: List[Dict[str, Any]] = []
def add_record(self, record_type: str, content: str):
"""
向记忆中添加一条新记录。
参数:
- record_type (str): 记录的类型 ('execution' 或 'reflection')。
- content (str): 记录的具体内容 (例如,生成的代码或反思的反馈)。
"""
record = {"type": record_type, "content": content}
self.records.append(record)
print(f"📝 记忆已更新,新增一条 '{record_type}' 记录。")
def get_trajectory(self) -> str:
"""
将所有记忆记录格式化为一个连贯的字符串文本,用于构建提示词。
"""
trajectory_parts = []
for record in self.records:
if record['type'] == 'execution':
trajectory_parts.append(f"--- 上一轮尝试 (代码) ---\n{record['content']}")
elif record['type'] == 'reflection':
trajectory_parts.append(f"--- 评审员反馈 ---\n{record['content']}")
return "\n\n".join(trajectory_parts)
def get_last_execution(self) -> Optional[str]:
"""
获取最近一次的执行结果 (例如,最新生成的代码)。
如果不存在,则返回 None。
"""
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
return None这个 Memory 类的设计比较简洁,主体是这样的:
- 使用一个列表
records来按顺序存储每一次的行动和反思。 add_record方法负责向记忆中添加新的条目。get_trajectory方法是核心,它将记忆轨迹"序列化"成一段文本,可以直接插入到后续的提示词中,为模型的反思和优化提供完整的上下文。get_last_execution方便我们获取最新的"初稿"以供反思。
4.4.3 Reflection 智能体的编码实现
有了 Memory 模块作为基础,我们现在可以着手构建 ReflectionAgent 的核心逻辑。整个智能体的工作流程将围绕我们之前讨论的"执行-反思-优化"循环展开,并通过精心设计的提示词来引导大语言模型扮演不同的角色。
(1)提示词设计
与之前的范式不同,Reflection 机制需要多个不同角色的提示词来协同工作。
- 初始执行提示词 (Execution Prompt) :这是智能体首次尝试解决问题的提示词,内容相对直接,只要求模型完成指定任务。
bash
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""- 反思提示词 (Reflection Prompt) :这个提示词是 Reflection 机制的灵魂。它指示模型扮演"代码评审员"的角色,对上一轮生成的代码进行批判性分析,并提供具体的、可操作的反馈。
bash
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在<strong>算法效率</strong>上的主要瓶颈。
# 原始任务:
{task}
# 待审查的代码:
```python
{code}
```
请分析该代码的时间复杂度,并思考是否存在一种<strong>算法上更优</strong>的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答"无需改进"。
请直接输出你的反馈,不要包含任何额外的解释。
"""- 优化提示词 (Refinement Prompt) :当收到反馈后,这个提示词将引导模型根据反馈内容,对原有代码进行修正和优化。
bash
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
{last_code_attempt}
评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""(2)智能体封装与实现
现在,我们将这套提示词逻辑和 Memory 模块整合到 ReflectionAgent 类中。
python
# 假设 llm_client.py 和 memory.py 已定义
# from llm_client import HelloAgentsLLM
# from memory import Memory
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory()
self.max_iterations = max_iterations
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# --- 1. 初始执行 ---
print("\n--- 正在进行初始尝试 ---")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# --- 2. 迭代循环:反思与优化 ---
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思
print("\n-> 正在进行反思...")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 检查是否需要停止
if "无需改进" in feedback:
print("\n✅ 反思认为代码已无需改进,任务完成。")
break
# c. 优化
print("\n-> 正在进行优化...")
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终生成的代码:\n```python\n{final_code}\n```")
return final_code
def _get_llm_response(self, prompt: str) -> str:
"""一个辅助方法,用于调用LLM并获取完整的流式响应。"""
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
return response_text4.4.4 运行实例与分析
完整的代码同样参考本书配套的代码仓库 code 文件夹,这里提供一个输出实例。
python
--- 开始处理任务 ---
任务: 编写一个Python函数,找出1到n之间所有的素数 (prime numbers)。
--- 正在进行初始尝试 ---
🧠 正在调用 qwen3.5-plus 模型...
✅ 大语言模型响应成功:
```python
from typing import List
def find_primes(n: int) -> List[int]:
"""
Find all prime numbers between 1 and n (inclusive).
This function implements the Sieve of Eratosthenes algorithm to efficiently
generate prime numbers up to the specified limit.
Args:
n (int): The upper limit of the range to search for prime numbers.
Returns:
List[int]: A list containing all prime numbers between 1 and n.
"""
if n < 2:
return []
is_prime = [True] * (n + 1)
is_prime[0] = is_prime[1] = False
p = 2
while p * p <= n:
if is_prime[p]:
for i in range(p * p, n + 1, p):
is_prime[i] = False
p += 1
return [num for num, prime in enumerate(is_prime) if prime]
```
📝 记忆已更新,新增一条 'execution' 记录。
--- 第 1/2 轮迭代 ---
-> 正在进行反思...
🧠 正在调用 qwen3.5-plus 模型...
✅ 大语言模型响应成功:
时间复杂度分析:
当前代码采用埃拉托斯特尼筛法(Sieve of Eratosthenes),时间复杂度为 O(n log log n),空间复杂度为 O(n)。
主要算法瓶颈:
1. 冗余标记:合数会被其多个质因数重复标记(例如 12 会被 2 和 3 分别标记),导致不必要的计算操作。
2. 解释器开销:内层循环 `for i in range(...): is_prime[i] = False` 在 Python 层面执行,存在较高的解释器开销,未利用底层优化。
改进建议:
1. 算法层面:改用线性筛法(欧拉筛,Linear Sieve)。确保每个合数仅被其最小质因数标记一次,将时间复杂度优化至 O(n)。
2. 实现层面:在 Python 中,建议使用切片赋值(Slice Assignment)替代内层循环(例如 `is_prime[p*p::p] = [False] * len(...)`),利用 C 级优化显著提升执行速度。
结论:
当前算法未达到理论最优,存在显著性能提升空间。
📝 记忆已更新,新增一条 'reflection' 记录。
-> 正在进行优化...
🧠 正在调用 qwen3.5-plus 模型...
✅ 大语言模型响应成功:
```python
from typing import List
def find_primes(n: int) -> List[int]:
"""
Find all prime numbers between 1 and n (inclusive).
This function implements an optimized Sieve of Eratosthenes algorithm.
It utilizes Python's slice assignment to leverage C-level optimizations,
significantly reducing interpreter overhead compared to standard loops.
While theoretical complexity is O(n log log n), this implementation
offers superior practical performance in Python environments.
Args:
n (int): The upper limit of the range to search for prime numbers.
Returns:
List[int]: A list containing all prime numbers between 1 and n.
"""
if n < 2:
return []
# Initialize boolean array; index i represents number i
is_prime = [True] * (n + 1)
is_prime[0] = is_prime[1] = False
# Only need to sieve up to sqrt(n)
for p in range(2, int(n**0.5) + 1):
if is_prime[p]:
# Use slice assignment for C-level optimization
# Marks multiples of p starting from p*p as False
is_prime[p * p : n + 1 : p] = [False] * ((n - p * p) // p + 1)
# Collect all indices that are still marked as True
return [num for num, prime in enumerate(is_prime) if prime]
```
📝 记忆已更新,新增一条 'execution' 记录。
--- 第 2/2 轮迭代 ---
-> 正在进行反思...
🧠 正在调用 qwen3.5-plus 模型...
✅ 大语言模型响应成功:
时间复杂度分析:
当前实现为埃拉托斯特尼筛法,时间复杂度为 O(n log log n),空间复杂度为 O(n)。
主要算法瓶颈:
1. 理论复杂度非最优:存在线性筛法(欧拉筛),时间复杂度可达 O(n)。当前算法虽在实际中表现良好,但未达到理论下界。
2. 空间扩展性受限:O(n) 的空间复杂度在处理 n > 10^8 级别数据时极易导致内存溢出,无法处理大规模数据。
3. 运行时内存开销:切片赋值中 `[False] * ...` 在每次循环均分配新列表对象,产生大量临时内存分配与垃圾回收开销,削弱了 C 层优化优势。
改进建议:
1. 算法层面:
- 若追求理论时间最优,应采用线性筛法(Linear Sieve)。
- 若需处理超大范围 n,应采用分段筛法(Segmented Sieve),将空间复杂度降至 O(√n)。
2. 实现层面:
- 使用 `bytearray` 替代 `list` 存储布尔值,可减少约 8 倍内存占用并提升缓存命中率。
- 避免在循环内创建临时列表,可预分配缓冲区或使用原生循环配合 `bytearray` 进行标记。
📝 记忆已更新,新增一条 'reflection' 记录。
-> 正在进行优化...
🧠 正在调用 qwen3.5-plus 模型...
✅ 大语言模型响应成功:
```python
from typing import List
def find_primes(n: int) -> List[int]:
"""
Find all prime numbers between 1 and n (inclusive).
This function implements the Linear Sieve (Euler Sieve) algorithm.
Time Complexity: O(n)
Space Complexity: O(n)
Optimizations based on code review feedback:
1. Uses Linear Sieve for theoretical O(n) time complexity.
2. Uses bytearray instead of list[bool] to reduce memory footprint
and improve cache locality.
3. Avoids temporary list allocations during the sieving process
compared to slice assignment methods.
Args:
n (int): The upper limit of the range to search for prime numbers.
Returns:
List[int]: A list containing all prime numbers between 1 and n.
"""
if n < 2:
return []
# bytearray uses 1 byte per element, significantly less than list[bool]
# 1 indicates prime, 0 indicates composite
is_prime = bytearray([1]) * (n + 1)
is_prime[0] = 0
is_prime[1] = 0
primes: List[int] = []
# Linear Sieve logic
for i in range(2, n + 1):
if is_prime[i]:
primes.append(i)
# Iterate through known primes to mark composites
for p in primes:
if i * p > n:
break
is_prime[i * p] = 0
# Ensure each composite is marked only once by its smallest prime factor
if i % p == 0:
break
return primes
```
📝 记忆已更新,新增一条 'execution' 记录。
--- 任务完成 ---
最终生成的代码:
```python
from typing import List
def find_primes(n: int) -> List[int]:
"""
Find all prime numbers between 1 and n (inclusive).
This function implements the Linear Sieve (Euler Sieve) algorithm.
Time Complexity: O(n)
Space Complexity: O(n)
Optimizations based on code review feedback:
1. Uses Linear Sieve for theoretical O(n) time complexity.
2. Uses bytearray instead of list[bool] to reduce memory footprint
and improve cache locality.
3. Avoids temporary list allocations during the sieving process
compared to slice assignment methods.
Args:
n (int): The upper limit of the range to search for prime numbers.
Returns:
List[int]: A list containing all prime numbers between 1 and n.
"""
if n < 2:
return []
# bytearray uses 1 byte per element, significantly less than list[bool]
# 1 indicates prime, 0 indicates composite
is_prime = bytearray([1]) * (n + 1)
is_prime[0] = 0
is_prime[1] = 0
primes: List[int] = []
# Linear Sieve logic
for i in range(2, n + 1):
if is_prime[i]:
primes.append(i)
# Iterate through known primes to mark composites
for p in primes:
if i * p > n:
break
is_prime[i * p] = 0
# Ensure each composite is marked only once by its smallest prime factor
if i % p == 0:
break
return primes
```这个运行实例展示了 Reflection 机制是如何驱动智能体进行深度优化的:
- 有效的"批判"是优化的前提 :在第一轮反思中,由于我们使用了"极其严格"且"专注于算法效率"的提示词,智能体没有满足于功能正确的初版代码,而是精准地指出了其
O(n * sqrt(n))的时间复杂度瓶颈,并提出了算法层面的改进建议------埃拉托斯特尼筛法。 - 迭代式改进 : 智能体在接收到明确的反馈后,于优化阶段成功地实现了更高效的筛法,将算法复杂度降至
O(n log log n),完成了第一次有意义的自我迭代。 - 收敛与终止: 在第二轮反思中,智能体面对已经高效的筛法,展现出了更深层次的知识。它不仅肯定了当前算法的效率,甚至还提及了分段筛法等更高级的优化方向,但最终做出了"在一般情况下无需改进"的正确判断。这个判断触发了我们的终止条件,使优化过程得以收敛。
这个案例充分证明,一个设计良好的 Reflection 机制,其价值不仅在于修复错误,更在于驱动解决方案在质量和效率上实现阶梯式的提升,这使其成为构建复杂、高质量智能体的关键技术之一。
4.4.5 Reflection 机制的成本收益分析
尽管 Reflection 机制在提升任务解决质量上表现出色,但这种能力的获得并非没有代价。在实际应用中,我们需要权衡其带来的收益与相应的成本。
(1)主要成本
- 模型调用开销增加:这是最直接的成本。每进行一轮迭代,至少需要额外调用两次大语言模型(一次用于反思,一次用于优化)。如果迭代多轮,API 调用成本和计算资源消耗将成倍增加。
- 任务延迟显著提高:Reflection 是一个串行过程,每一轮的优化都必须等待上一轮的反思完成。这使得任务的总耗时显著延长,不适合对实时性要求高的场景。
- 提示工程复杂度上升:如我们的案例所示,Reflection 的成功在很大程度上依赖于高质量、有针对性的提示词。为"执行"、"反思"、"优化"等不同阶段设计和调试有效的提示词,需要投入更多的开发精力。
(2)核心收益
- 解决方案质量的跃迁:最大的收益在于,它能将一个"合格"的初始方案,迭代优化成一个"优秀"的最终方案。这种从功能正确到性能高效、从逻辑粗糙到逻辑严谨的提升,在很多关键任务中是至关重要的。
- 鲁棒性与可靠性增强:通过内部的自我纠错循环,智能体能够发现并修复初始方案中可能存在的逻辑漏洞、事实性错误或边界情况处理不当等问题,从而大大提高了最终结果的可靠性。
综上所述,Reflection 机制是一种典型的"以成本换质量"的策略。它非常适合那些对最终结果的质量、准确性和可靠性有极高要求,且对任务完成的实时性要求相对宽松的场景。例如:
- 生成关键的业务代码或技术报告。
- 在科学研究中进行复杂的逻辑推演。
- 需要深度分析和规划的决策支持系统。
反之,如果应用场景需要快速响应,或者一个"大致正确"的答案就已经足够,那么使用更轻量的 ReAct 或 Plan-and-Solve 范式可能会是更具性价比的选择。
4.5 本章小结
在本章中,以第三章掌握的大语言模型知识为基础,我们通过"亲手造轮子"的方式,从零开始编码实现了三种业界经典的智能体构建范式:ReAct、Plan-and-Solve 与 Reflection。我们不仅探索了它们的核心工作原理,还通过具体的实战案例,深入了解了各自的优势、局限与适用场景。
核心知识点回顾:
- ReAct:我们构建了一个能与外部世界交互的 ReAct 智能体。通过"思考-行动-观察"的动态循环,它成功地利用搜索引擎回答了自身知识库无法覆盖的实时性问题。其核心优势在于环境适应性 和动态纠错能力,使其成为处理探索性、需要外部工具输入的任务的首选。
- Plan-and-Solve:我们实现了一个先规划后执行的 Plan-and-Solve 智能体,并利用它解决了需要多步推理的数学应用题。它将复杂的任务分解为清晰的步骤,然后逐一执行。其核心优势在于结构性 和稳定性,特别适合处理逻辑路径确定、内部推理密集的任务。
- Reflection (自我反思与迭代):我们构建了一个具备自我优化能力的 Reflection 智能体。通过引入"执行-反思-优化"的迭代循环,它成功地将一个效率较低的初始代码方案,优化为了一个算法上更优的高性能版本。其核心价值在于能显著提升解决方案的质量,适用于对结果的准确性和可靠性有极高要求的场景。
本章探讨的三种范式,代表了智能体解决问题的三种不同策略,如表4.1所示。在实际应用中,选择哪一种,取决于任务的核心需求:
表 4.1 不同 Agent Loop 的选择策略
