文章目录
-
- 引言:为什么需要集成学习?
- 一、集成学习的哲学基础
-
- [1.1 偏差-方差权衡的平衡艺术](#1.1 偏差-方差权衡的平衡艺术)
- [1.2 多样性的力量](#1.2 多样性的力量)
- 二、核心思想全景解析
-
- [2.1 Bagging:并行民主制](#2.1 Bagging:并行民主制)
- [2.2 Boosting:串行进化论](#2.2 Boosting:串行进化论)
- [2.3 Stacking:分层元学习](#2.3 Stacking:分层元学习)
- [2.4 Voting/平均法:简单直接](#2.4 Voting/平均法:简单直接)
- 三、常见误区深度解析
-
- [误区 1:随机森林就是 Bagging 的全部](#误区 1:随机森林就是 Bagging 的全部)
- [误区 2:参数平均与结果平均效果相同](#误区 2:参数平均与结果平均效果相同)
- [误区 3:集成学习总是比单一模型好](#误区 3:集成学习总是比单一模型好)
- [误区 4:Boosting 一定比 Bagging 好](#误区 4:Boosting 一定比 Bagging 好)
- 四、集成学习方法汇总对比
- 五、实践选择指南
-
- [5.1 根据问题特性选择](#5.1 根据问题特性选择)
- [5.2 根据数据规模选择](#5.2 根据数据规模选择)
- [5.3 根据模型类型选择](#5.3 根据模型类型选择)
- [5.4 生产环境考虑因素](#5.4 生产环境考虑因素)
- 五、总结与核心要点
-
- [5.1 核心思想回顾](#5.1 核心思想回顾)
- [5.2 关键避坑指南](#5.2 关键避坑指南)
- [5.3 实用建议](#5.3 实用建议)
- [5.4 未来发展趋势](#5.4 未来发展趋势)
引言:为什么需要集成学习?
在机器学习领域,有一个被反复验证的真理:多个弱学习器的组合往往能胜过单个强学习器。这就是集成学习的核心价值------通过集体智慧超越个体极限。无论是 Kaggle 竞赛的冠军方案,还是工业界的生产系统,集成学习都扮演着至关重要的角色。
本文将系统解析集成学习的核心思想,澄清常见误区,并提供实用的选择指南。
一、集成学习的哲学基础
1.1 偏差-方差权衡的平衡艺术
任何机器学习模型都在偏差(Bias)和方差(Variance)之间寻找平衡点:
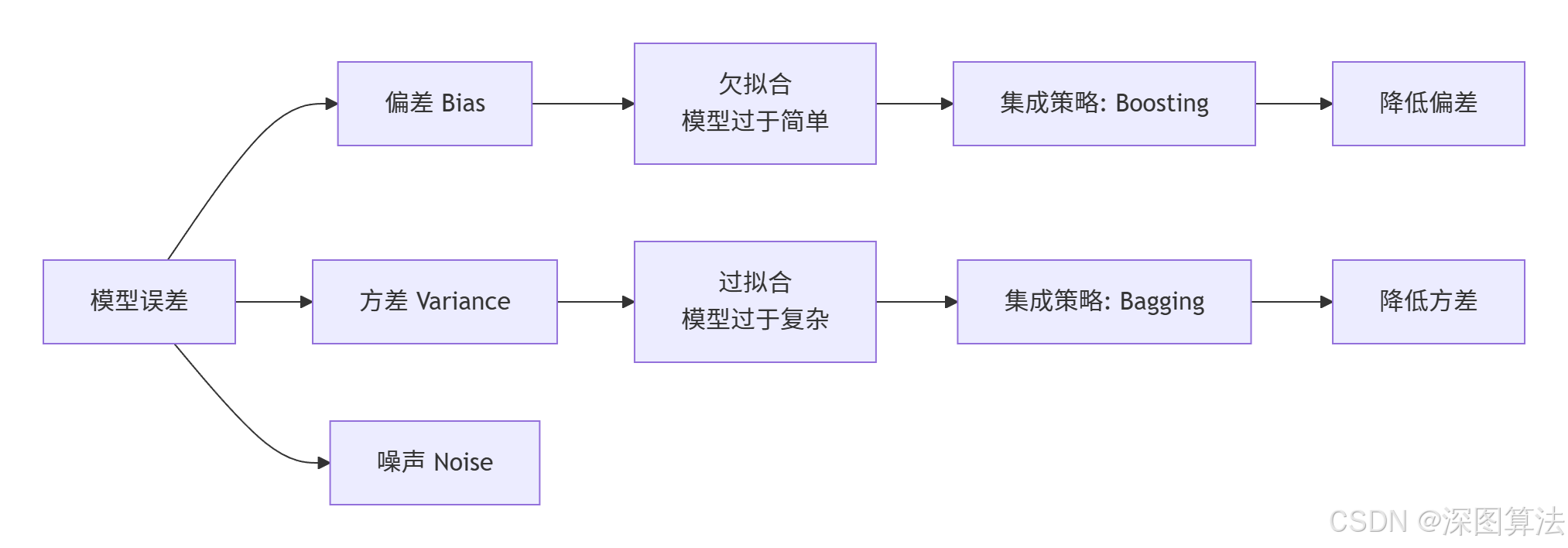
- 高偏差模型:过于简单,无法捕捉数据中的复杂模式(欠拟合)
- 高方差模型:过于复杂,对训练数据中的噪声过度敏感(过拟合)
- 集成学习的魔法:通过不同策略,有的放矢地降低偏差或方差
1.2 多样性的力量
集成学习有效性的前提是基学习器的多样性。如果所有基学习器都犯同样的错误,集成也无法纠正这些错误。多样性来源包括:
- 数据多样性:使用不同的数据子集(Bagging)
- 特征多样性:使用不同的特征子集(随机森林)
- 算法多样性:使用不同的学习算法(Voting/Stacking)
- 参数多样性:使用不同的超参数设置
二、核心思想全景解析
2.1 Bagging:并行民主制
Bagging(Bootstrap Aggregating) 的核心思想是并行训练多个同质但略有差异的模型,然后聚合它们的预测结果 。
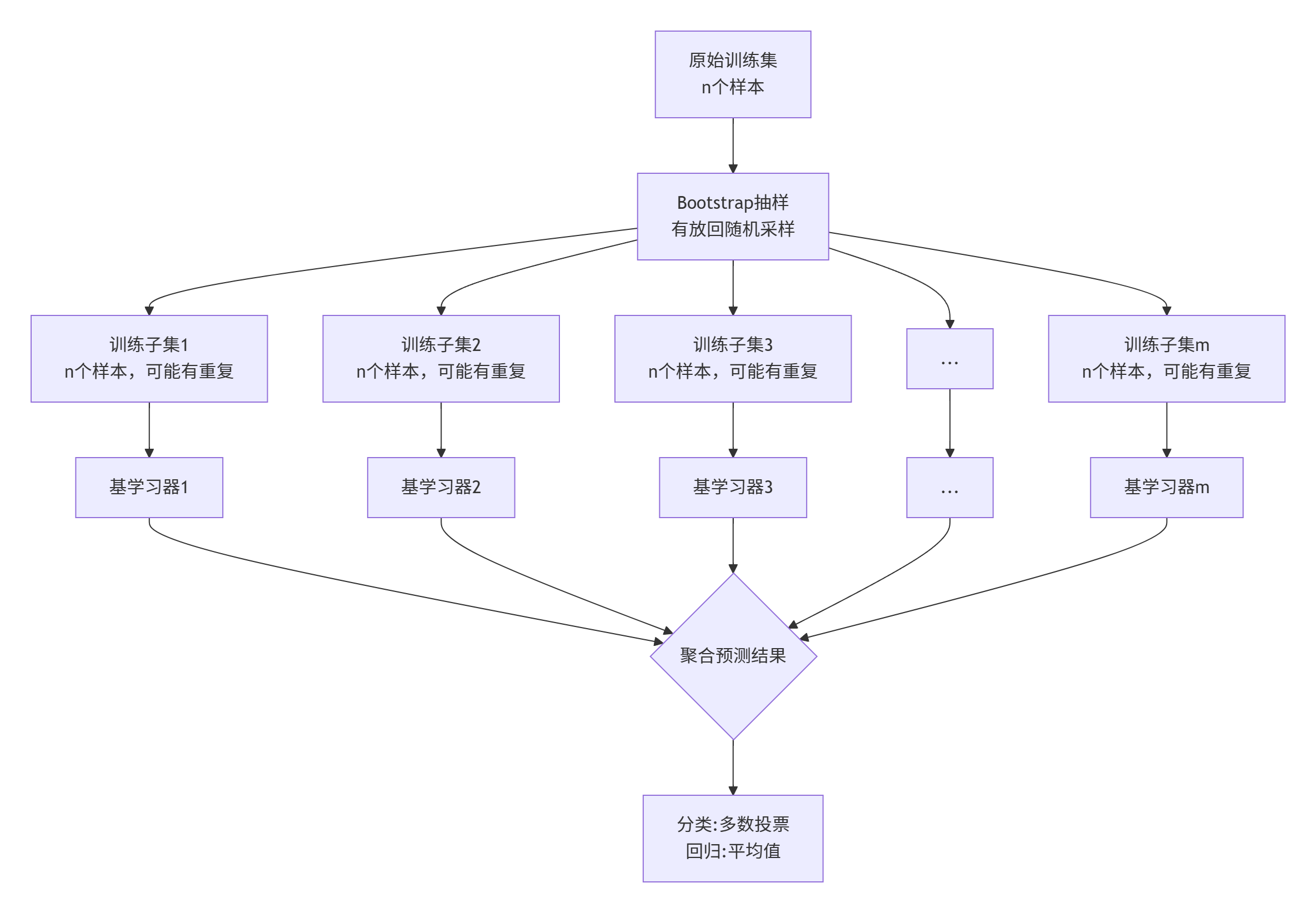
关键特性:
- Bootstrap 抽样:每个基学习器使用不同的训练子集(有放回抽样)
- 并行训练:所有基学习器可以同时训练,效率高
- 降低方差:特别适合容易过拟合的模型
典型代表:随机森林(Random Forest)
2.2 Boosting:串行进化论
Boosting 的核心思想是串行训练多个模型,每个后续模型专注于修正前序模型的错误 。
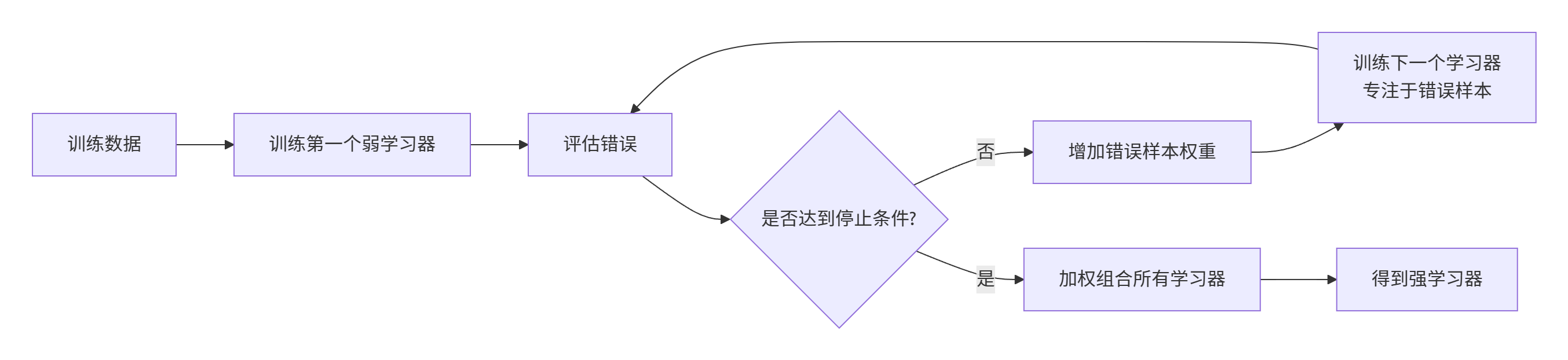
Boosting 家族演进:
AdaBoost (1997) → Gradient Boosting (2001) → XGBoost (2016) → LightGBM (2017) → CatBoost (2017)现代梯度提升三巨头对比:
| 特性 | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| 核心创新 | 正则化目标函数,稀疏感知 | 基于直方图的决策树,梯度单边采样 | 有序提升,类别特征处理 |
| 训练速度 | 较快 | 非常快 | 中等 |
| 内存使用 | 中等 | 低 | 中等 |
| 类别特征 | 需要编码 | 需要编码 | 原生支持 |
| 过拟合控制 | 正则化项 | 深度限制,叶子优先生长 | 有序提升,正则化 |
| 适用场景 | 通用场景,中小数据集 | 大数据集,需要快速训练 | 包含大量类别特征的数据 |
2.3 Stacking:分层元学习
Stacking 的核心思想是使用元学习器来学习如何最佳组合多个基学习器的预测 。
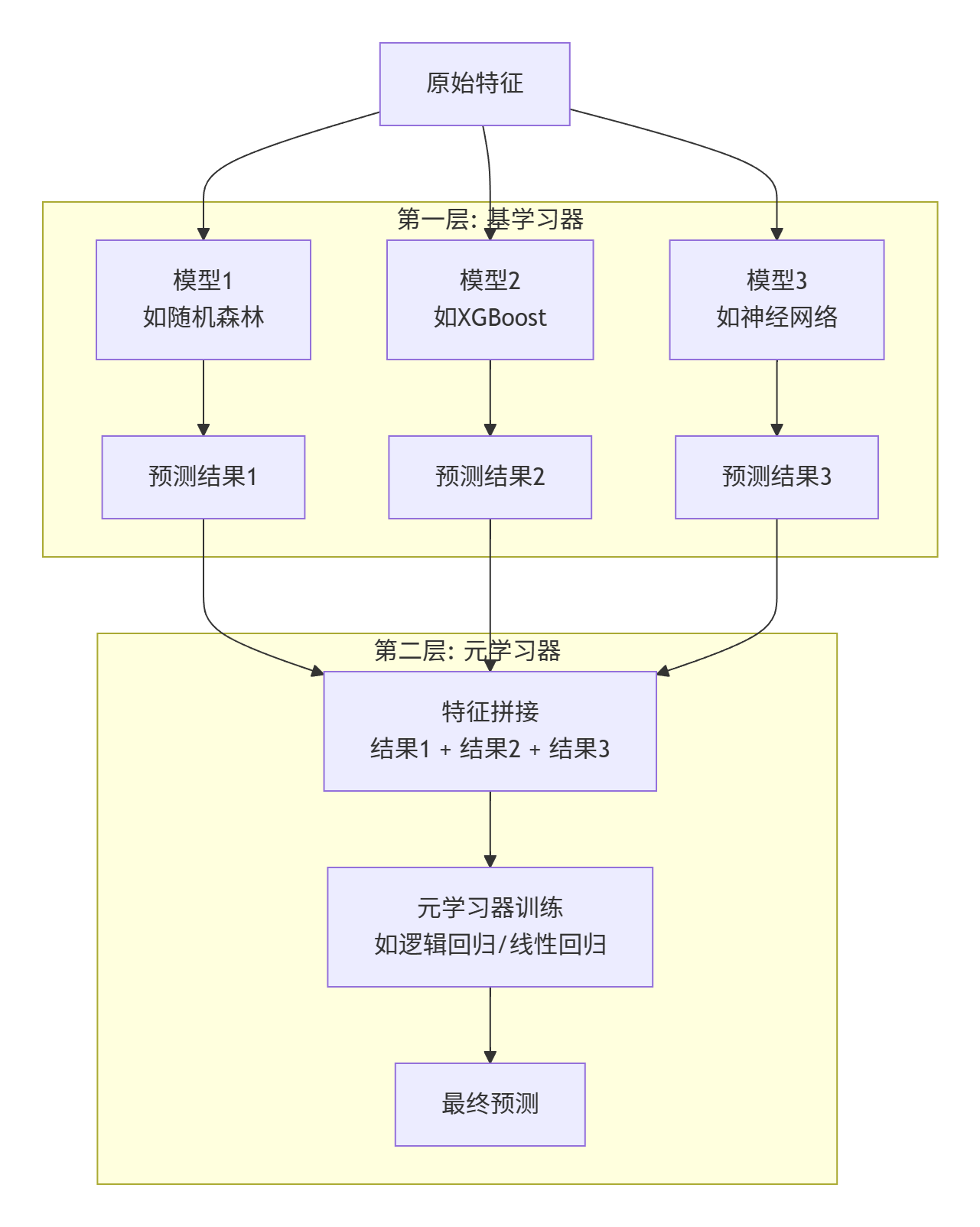
Stacking vs Blending:
| 特性 | Stacking | Blending |
|---|---|---|
| 数据使用 | K 折交叉验证 | 简单 hold-out 集 |
| 数据利用率 | 高(使用全部数据) | 较低 |
| 过拟合风险 | 较低 | 较高 |
| 实现复杂度 | 较高 | 较低 |
2.4 Voting/平均法:简单直接
Voting 是最直接的集成方式,通过投票或平均来综合多个模型的预测。
两种投票机制:
-
**硬投票(Hard Voting)**:每个模型投一票,取票数最多的类别
-
**软投票(Soft Voting)**:考虑每个模型的预测概率,取概率平均最大的类别
Scikit-learn中的VotingClassifier示例
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC创建投票集成
voting_clf = VotingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('dt', DecisionTreeClassifier(random_state=42)),
('svc', SVC(probability=True, random_state=42))
],
voting='soft' # 软投票,考虑概率
)
三、常见误区深度解析
误区 1:随机森林就是 Bagging 的全部
事实 :随机森林是 Bagging 的一个特化和优化版本,但 Bagging 的思想可以应用于任何基学习器。
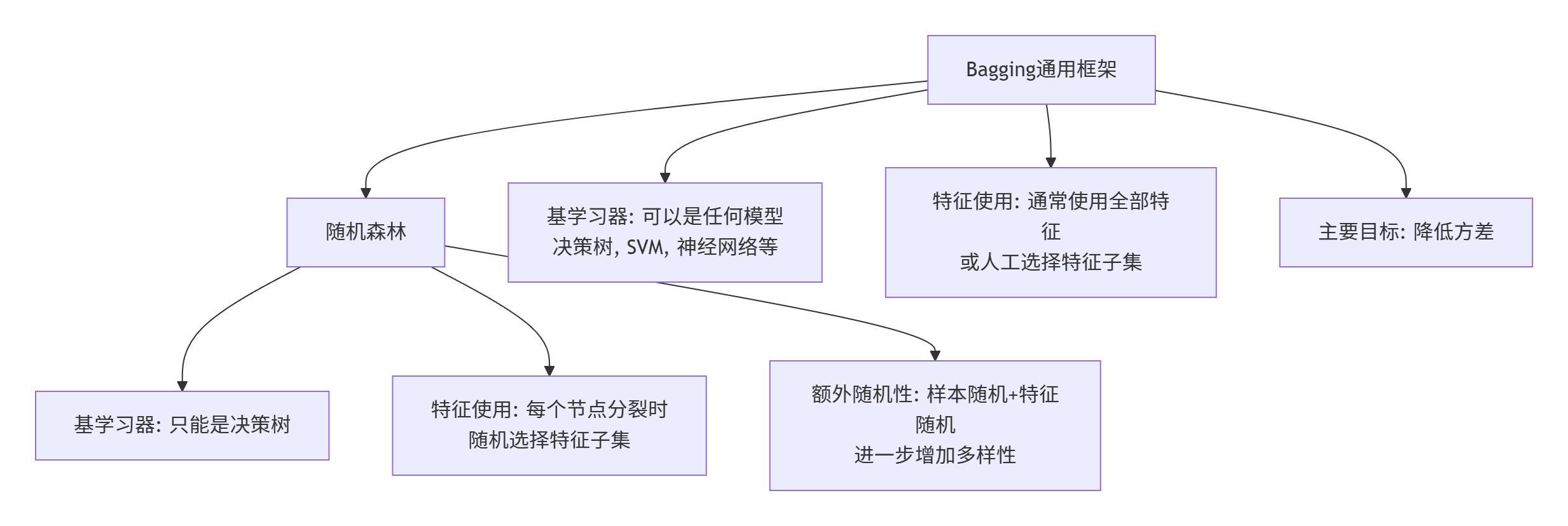
关键区别:
- 随机森林 = Bagging + 特征随机选择 + 决策树基学习器
- 通用 Bagging = Bootstrap 抽样 + 任意基学习器 + 结果聚合
误区 2:参数平均与结果平均效果相同
这是一个非常重要的技术细节,很多初学者容易混淆:
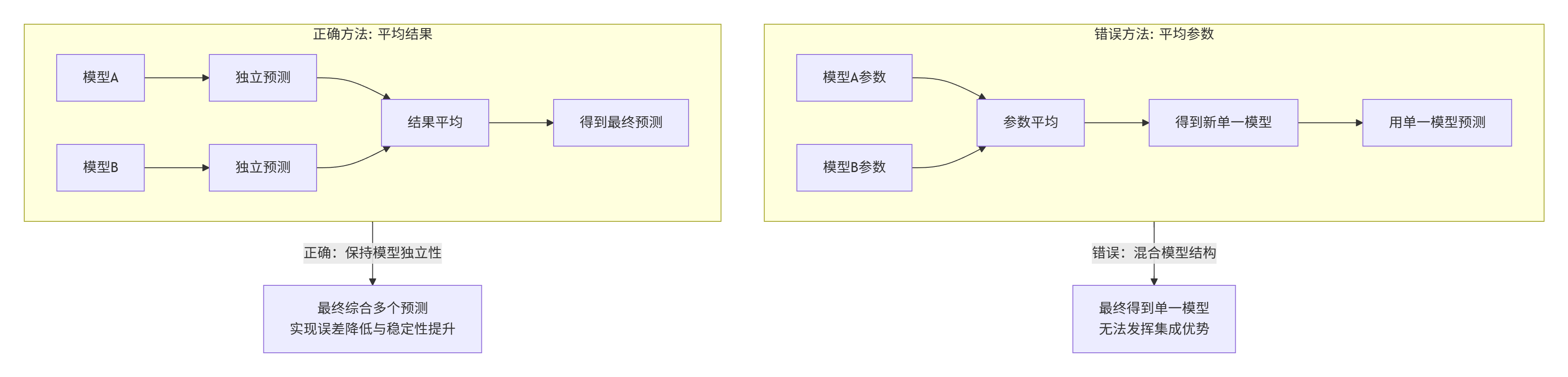
为什么参数平均是错的?
- 模型非线性:大多数机器学习模型是非线性的,参数的线性组合不等于预测结果的线性组合
- 损失信息:平均参数会混合不同模型的决策边界,可能得到毫无意义的中间模型
- 破坏结构:神经网络等模型的参数具有复杂的内部结构,简单平均会破坏这种结构
正确做法 :始终对预测结果进行平均或投票,而不是对模型参数进行平均。
误区 3:集成学习总是比单一模型好
事实:集成学习有前提条件,不是银弹。
集成学习有效的条件:
- 基学习器足够准确:如果所有基学习器都是随机猜测,集成也不会变好
- 基学习器具有多样性:错误应该尽可能不相关
- 集成方法选择恰当:针对问题特性选择正确的集成策略
何时可能失败:
- 基学习器都犯相同的系统性错误
- 数据量太小,无法支持多个模型的训练
- 计算资源有限,无法承受集成带来的开销
误区 4:Boosting 一定比 Bagging 好
事实:没有绝对的好坏,只有适合与否。
| 场景 | 推荐方法 | 理由 |
|---|---|---|
| 高方差问题(过拟合) | Bagging | 通过降低方差提高稳定性 |
| 高偏差问题(欠拟合) | Boosting | 通过降低偏差提高精度 |
| 数据噪声大 | Bagging | 对噪声更鲁棒 |
| 数据质量高 | Boosting | 能更好利用数据信息 |
| 需要可解释性 | Bagging | 随机森林提供特征重要性 |
| 追求最高精度 | Boosting | 通常能达到更高精度 |
四、集成学习方法汇总对比
| 特性 | Bagging | Boosting | Stacking | Voting/平均 | Blending |
|---|---|---|---|---|---|
| 核心机制 | 并行训练 + 结果聚合 | 串行训练 + 错误修正 | 分层训练 + 元学习 | 直接投票或平均 | 简单分层融合 |
| 训练方式 | 并行 | 串行 | 分层 | 并行 | 两阶段 |
| 基学习器关系 | 同质、相互独立 | 同质、顺序依赖 | 异质或同质 | 异质或同质 | 异质或同质 |
| 主要目标 | 降低方差 | 降低偏差 | 提升泛化 | 稳健预测 | 简化 Stacking |
| 代表算法 | 随机森林、Bagged Trees | AdaBoost、XGBoost、LightGBM | Stacking 集成 | 硬投票、软投票 | Blending 集成 |
| 数据使用 | Bootstrap 抽样 | 相同数据,权重调整 | 原始数据 + 预测特征 | 相同数据 | Hold-out 集划分 |
| 并行性 | 高 | 低 | 中等 | 高 | 中等 |
| 过拟合风险 | 低 | 较高(对噪声敏感) | 中等(需交叉验证) | 低 | 较高 |
| 实现复杂度 | 低 | 中等 | 高 | 很低 | 中等 |
| 适用场景 | 高方差模型、需要稳定性 | 高偏差模型、追求精度 | 模型多样、追求极致性能 | 快速实现、基线方法 | 数据量大、简化实现 |
五、实践选择指南
5.1 根据问题特性选择
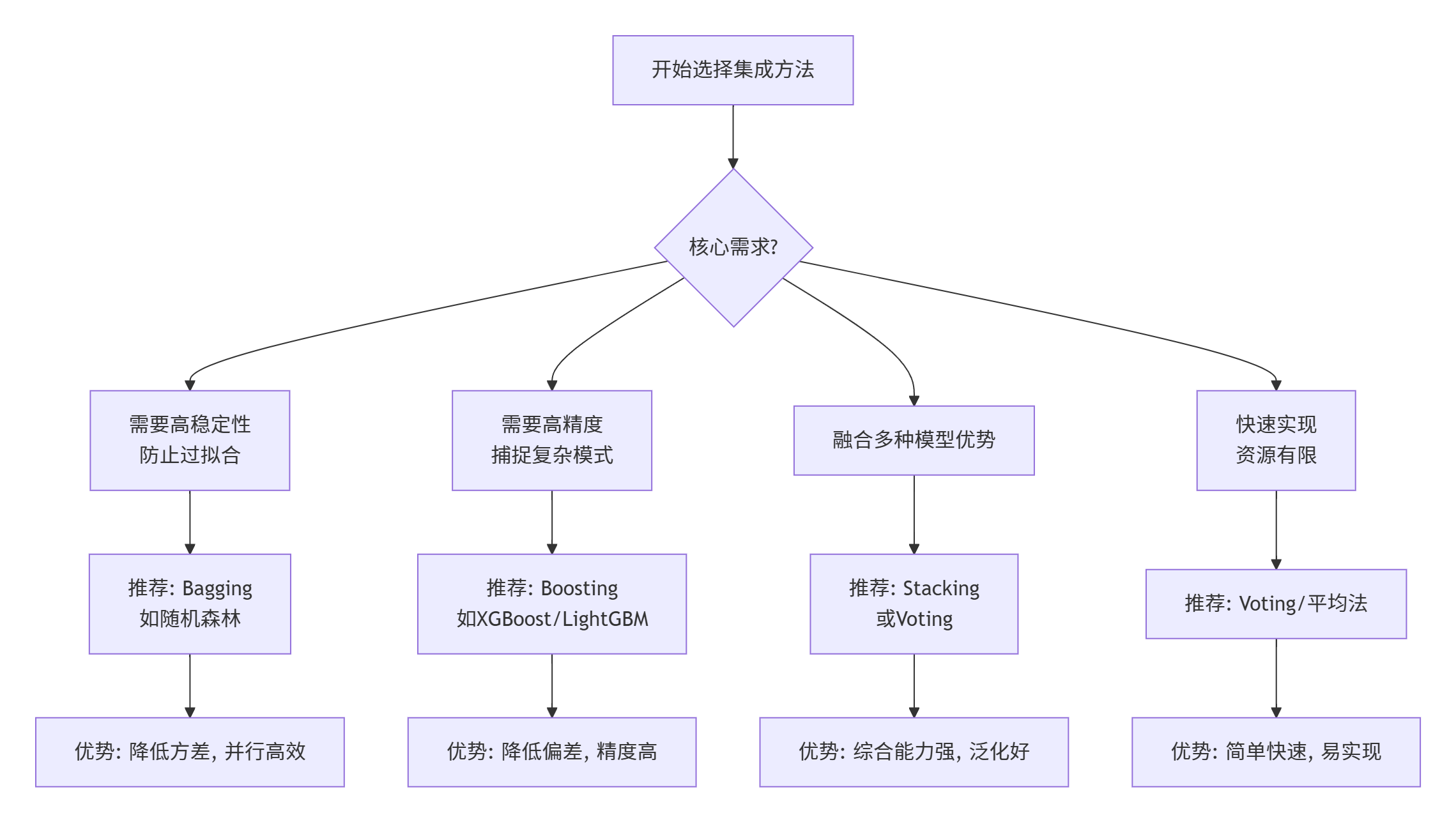
5.2 根据数据规模选择
| 数据规模 | 推荐方法 | 理由 | 注意事项 |
|---|---|---|---|
| 小数据 (n<10K) | Bagging、简单 Voting | 避免过拟合,提升稳定性 | 避免复杂 Boosting,容易过拟合 |
| 中数据 (10K-1M) | 梯度提升系列、Stacking | 平衡精度与效率 | 需要足够的验证数据 |
| 大数据 (n>1M) | LightGBM、分布式 Bagging | 注重训练效率,可并行化 | 考虑计算资源和时间成本 |
5.3 根据模型类型选择
-
同质模型集成
- Bagging:相同类型模型,不同数据子集
- Boosting:相同类型模型,顺序修正错误
-
异质模型集成
- Stacking:不同类型模型,元学习器融合
- Voting:不同类型模型,直接投票平均
5.4 生产环境考虑因素
-
推理延迟要求
- 低延迟:Bagging(可并行预测)、简单 Voting
- 可接受一定延迟:Boosting、Stacking
-
模型可解释性需求
- 高可解释性:Bagging(特征重要性)、简单模型
- 可接受黑盒:Boosting、复杂 Stacking
-
持续学习能力
- 在线学习:部分 Bagging 变体
- 批量更新:大多数集成方法需要全量重训
-
资源约束
- 计算资源有限:Voting、简单 Bagging
- 存储资源有限:考虑模型压缩、蒸馏
五、总结与核心要点
5.1 核心思想回顾
- Bagging:并行民主制,通过 Bootstrap 抽样和数据扰动降低方差,适合高方差模型。
- Boosting:串行进化论,通过顺序修正错误降低偏差,适合高偏差模型。
- Stacking:分层元学习,通过元学习器融合异质模型优势,追求极致性能。
- Voting/平均法:简单直接,快速获得稳健预测,适合资源有限场景。
- Blending:简化版 Stacking,使用 hold-out 集而非交叉验证,实现更简单。
5.2 关键避坑指南
- 不要平均参数:始终对预测结果进行平均,而不是模型参数。
- 确保多样性:基学习器的多样性是集成有效的前提。
- 理解偏差-方差:根据问题特性选择合适的集成策略。
- 考虑计算成本:在精度和效率之间找到平衡点。
- 验证集成效果:严格使用交叉验证,避免过拟合。
5.3 实用建议
- 从简单开始:先尝试单个模型,再考虑集成。
- 理解数据特性:根据数据规模、噪声水平、特征复杂度选择方法。
- 考虑业务需求:平衡精度、速度、可解释性、资源消耗。
- 持续监控优化:生产环境需要持续监控模型性能,适时调整。
5.4 未来发展趋势
- 自动化集成:AutoML 技术将集成学习过程自动化。
- 深度集成:神经网络与集成学习的深度融合。
- 可解释性增强:在保持性能的同时提升模型可解释性。
- 资源高效集成:面向边缘计算和移动设备的轻量级集成方法。
集成学习的本质是利用集体智慧超越个体极限。无论是 Bagging 的民主投票,Boosting 的持续进化,还是 Stacking 的元学习,都在以不同的方式践行这一理念。掌握这些思想,理解它们的适用场景和局限,你就能在机器学习的道路上走得更稳、更远。
记住:没有最好的集成方法,只有最适合你问题的方法。通过实验、分析和理解,找到属于你的最佳集成策略。