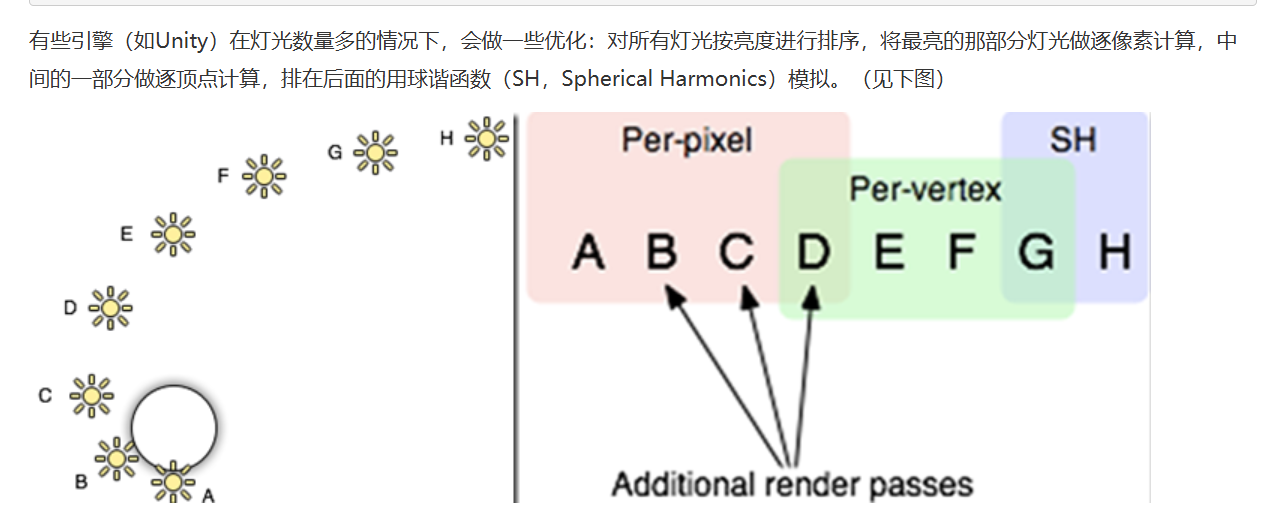
如Unity)在灯光数量多的情况下,会做一些优化:对所有灯光按亮度进行排序,将最亮的那部分灯光做逐像素计算,中间的一部分做逐顶点计算,排在后面的用球谐函数(SH,Spherical Harmonics)模拟。
https://www.cnblogs.com/timlly/p/10463467.html#1-%E5%89%8D%E8%A8%80
-
G 和 B 被压了不少,所以不会是霓虹感,而是偏肉、偏枣、偏砖
-
三通道差距不大,说明脏灰感会上来
-

-
看"通道关系"和"相对比例"


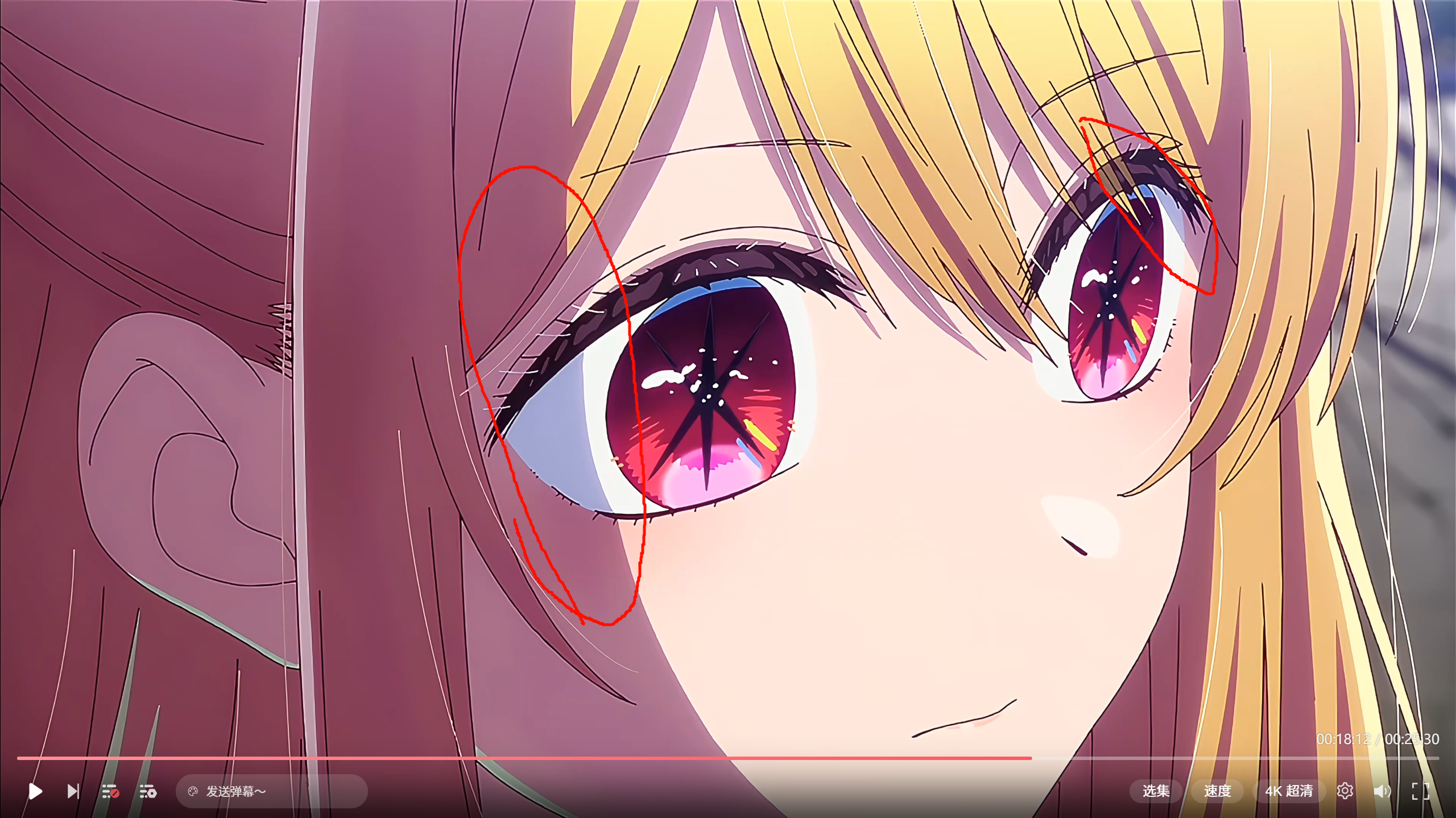
看太快真没注意过,这里的层和终末地里的leavat眼睛结构是一样的


眼睛到底在看哪?
严格说,这张不算"直视镜头",更接近"视线落在镜头附近"或者"朝向观众侧的假性对视"。如果按物理相机去理解,"看镜头"意味着角色双眼视轴大致指向相机光心附近。
但这张图里,脸是明显三分之四侧脸,不是正脸;鼻子和下巴的转向也说明头部朝向并没有正对相机。在真实摄影里,镜头可以当物理实体。
因为相机有明确位置、镜头有明确口径、角色视线有明确落点。你甚至可以区分她是在看左镜片、右镜片、监视器旁边,还是在看摄影师眼睛。
动画里常有一种默认约定:
-
只要虹膜摆位足够朝前
-
眼白分布没有明显偏向一侧
-
头部朝向和视线差不多对着观众区域
观众就会读成"她在看过来"
即便从严格几何上,它未必真在看镜头中心。
如果把角色头模真的做成 3D,再放一个相机,你会发现很多二维动画里的"对视"其实经不起严格投影检查。因为二维角色设计经常为了可爱、亲近感、角色识别度,会故意牺牲部分真实眼球透视。尤其大眼角色,
二维角色的 gaze,究竟是由几何决定,还是由知觉决定。答案通常是后者占上风。
虹膜,中央的瞳孔缩放,指示视野方向

BRDF 退居到底层,高光可读性优先于这些约束,所以它首先是"告诉你鼻子在这里、脸朝这里、角色很通透"脸部面积大、结构简化、鼻梁信息少。鼻尖这一下亮点会极大提升
是"表演资产",不是"照明资产",先保证"像这个角色、好看、可读"。保留一点明暗大关系,让脸不至于完全平。
"物理上近乎平涂,但知觉上被读成轻微渐变"。你知道那块区域是鼻子,不是随机色块。人眼一旦把它识别成鼻梁/鼻尖附近的面,就会自动套用"这里应该有朝向变化"的模型。于是即使底色几乎一样,也会被读出一点从侧面到正面的转折感。
把眼球也当做了平面,轻微的内凹,但可以不影响整体

实际上都是平滑,平和直的阴影线,2d的目的,优先保证平和直,"可读"的树立

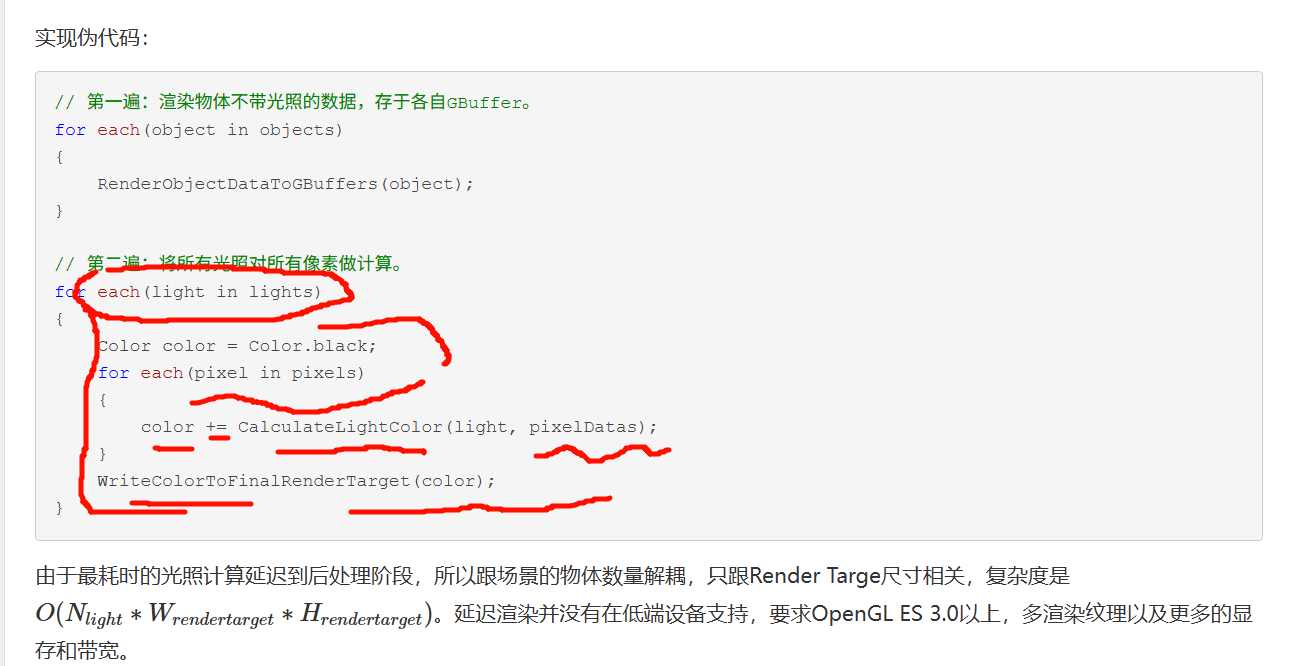
延迟到后处理阶段,所以跟场景的物体数量解耦
-
Launcher 版里的是"随发行版附带的源码 / 已预编译引擎对应的源码"
-
GitHub 上的是"完整引擎源码仓库 / source tree / full source distribution"
再精确一点:
-
.cpp/.h是源码 -
这些源码经过编译生成
.dll/.lib/.exe等,是二进制 -
GitHub 仓库不是"源码的源码",而是"源码仓库"
-
只有像
.y/.l、DSL、代码生成模板、meta 描述,再生成.cpp的场景,才勉强可以说"生成源码的上游输入",但 UE 日常语境里一般不会这么说
GPU Skin的做法是将骨骼矩阵列表作为Uniform传入Shader,然后在Vertex Shader中对模型顶点进行蒙皮计算
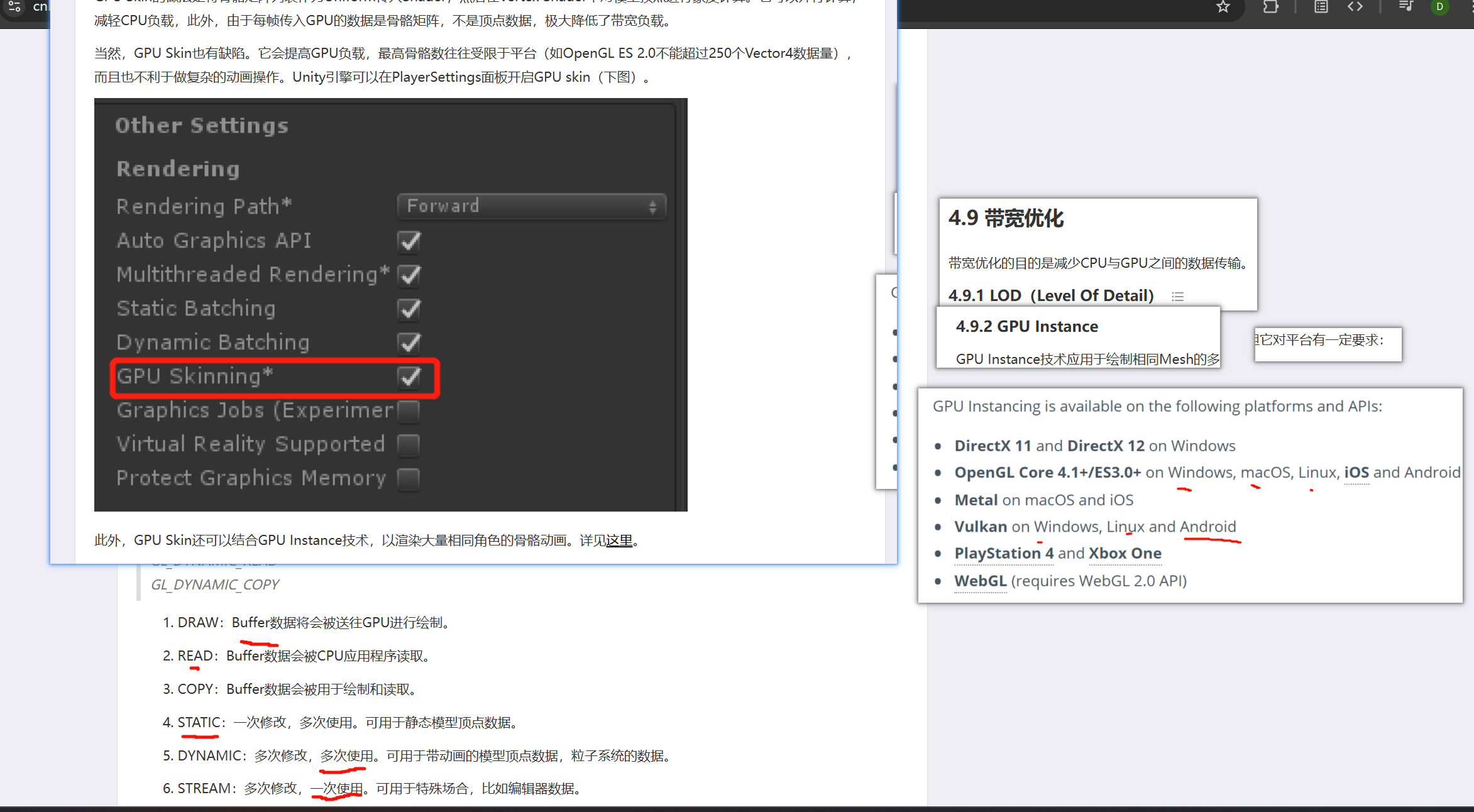
动态纹理采样(Dynamic Texture Lookup,也叫Dependent Texture Read)OpenGL ES3.0则没有这问题。后处理(FXAA & TAA)暗角:Vignette色差:Chromatic Aberration压缩资源占用多一份内存CPU的频率是最高的家用PC的主频可达3.2GHz甚至更高内存的存取速度远低于CPU,约是CPU的1/10硬盘存取速度又远低于内存,普遍是0.1Gb/s,远低于内存读取速度网络更慢,目前即便是光纤,也不过0.02Gb/s多级缓存策略多了层磁盘缓存二进制格式数据量最小,但可读性适合存储模型/纹理/字体/音频等数据量少。表达同样的数据,JSON格式可以比XML少40%首选JSON无疑。使用进度条。思路是将卡顿逻辑抽离出来,分成若干阶段(step)也可以用异步方式CPU占用普遍高,内存操作频繁,磁盘IO频繁,渲染消耗普遍高,导致带宽负载和GPU消耗高。
网络包中只需要发送RotationY。限制部分协议在短时间内重复发送压缩字节的方法zlib开源库网络包做一次
压缩图片占用的内存大小跟图片的尺寸和像素格式相关,跟文件格式没关系
合批后的顶点数超过65535,便会越界,导致渲染异常
几何体光栅化后形成的最小表示单元,它经过一系列片元操作(alpha测试,深度测试,模板测试等)后,才可能最终写入渲染纹理成为像素(pixel)。
https://www.cnblogs.com/timlly?page=4
送进 GPU 光栅化器参与 rasterization 的 primitive,在实时渲染里几乎总是 triangle。
也就是说,不管你在 DCC 里建的是:
-
triangle
-
quad
-
n-gon
进入引擎真正渲染之前,都会先三角化。之后光栅化器处理的是三角形 primitive,生成 fragment,fragment 再经过 alpha test / depth test / stencil test / blend 等流程,最后才可能写成 render target 里的 pixel。
Smith将Cook-Torrance的DFG部分的G几何项有效地结合起来Cook和Torrance于1982年联合理想环境下的光照模拟Schlick模型简化了Phong模型的镜面反射中的指数运算
GGX非常逼真地模拟半透明物体的效果。
虽然它提出时被用于半透明物体的模拟,但它作为一种描述微平面法线 方向分布的函数,同样适用于渲染表面粗糙的不透明物体。

Metallic :金属度,意义跟UE4的一致。但它可以用金属贴图代替,此时Smoothness参数会消失。Smoothness:光滑度,跟UE的粗糙度取值刚好相反,但都是表示材质表面的粗糙程度。Unity中使用遮蔽图为人物阴暗面(脸部,脖子)屏蔽环境光的影响。太阳光中不同波长的光所具有的能量。传统物理学上的辐射通量将会计算这个由不同波长构成的函数的总面积,这种计算很复杂,耗费大量性能。在PBR技术中,不直接使用波长的强度,而是使用三原色编码(RGB)来简化辐射通量的计算。
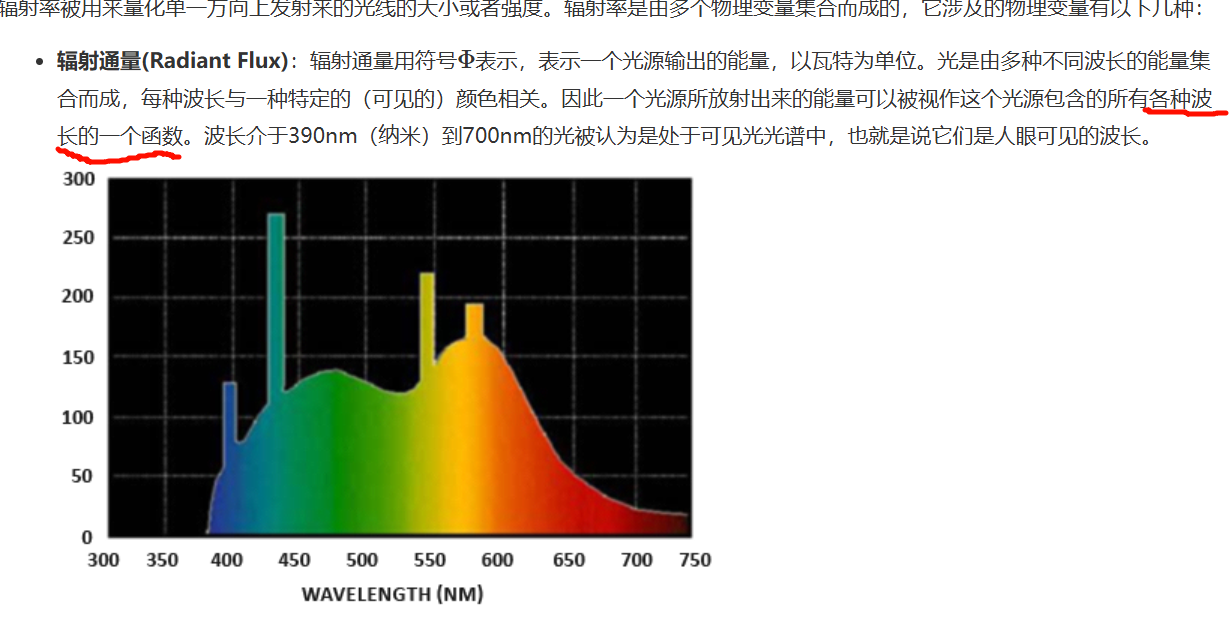
辐射强度(Radiant Intensity):符号II 表示,单位球面上,每单位立体角所投送的辐射通量。


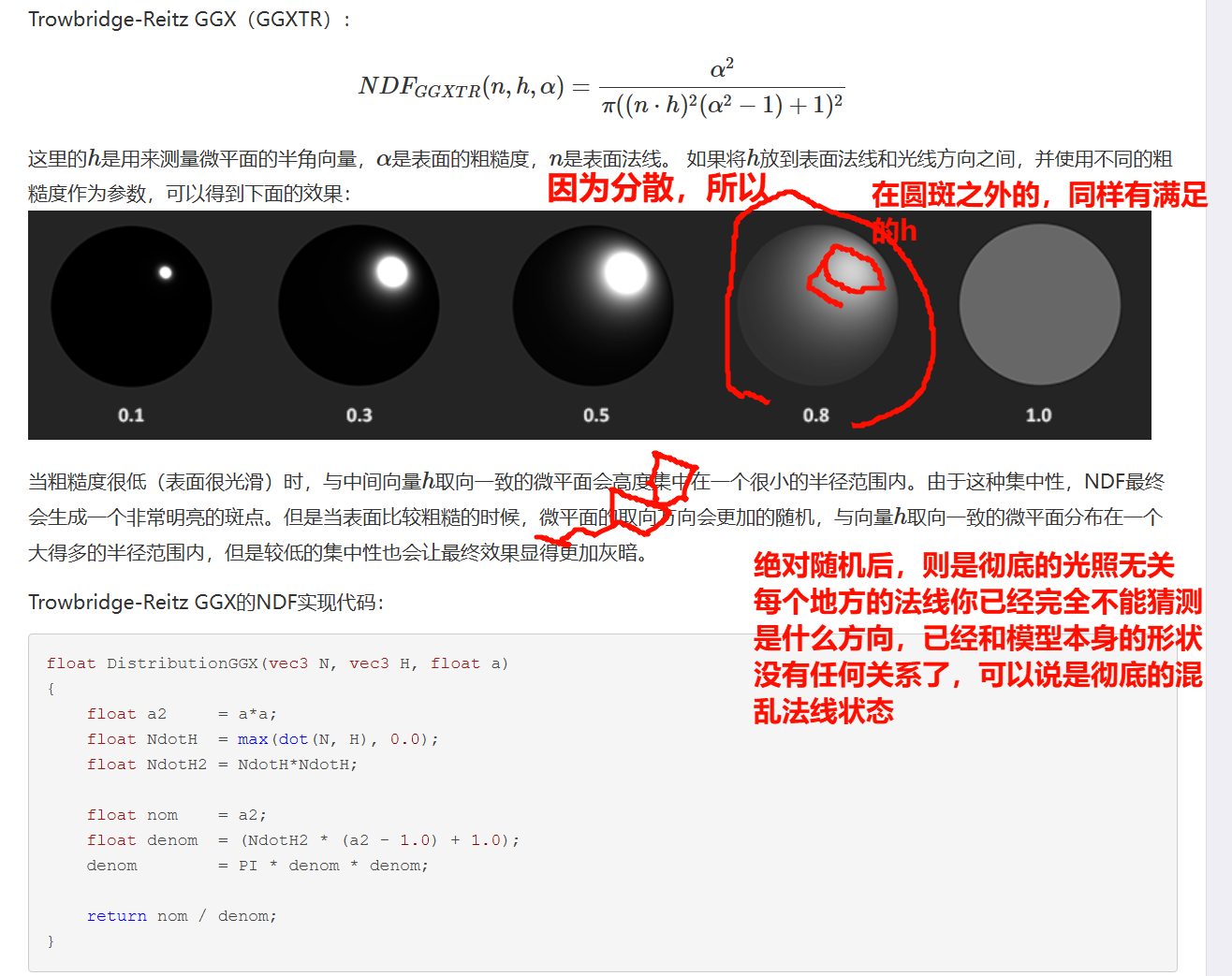
同一块表面,从斜着看会显得更"瘦"。FF (Fresnel equation) :菲涅尔方程,描述的是在不同的表面角下表面反射的光线所占的比率。平面相对比较粗糙的时候,平面表面上的微平面有可能挡住其他的微平面从而减少表面所反射的光线。DD (Normal Distribution Function,NDF):法线分布函数,估算在受到表面粗糙度的影响下,取向方向与中间向量一致的微平面的数量。这是用来估算微平面的主要函数。统计学上近似的表示了与某些(如中间)向量hh 取向一致的微平面的比率。
d本就是一个拆出的独立物理项,不能错误的认为必须依存于其他,
公式里出色的地方在于统计的模拟,只通过这样的公式就模拟出来了整体从完全依附形体到彻底脱离形体的过程
出色的拟合过程这是论文的探讨区域,的确很复杂,但是都是证明这个公式的可用,所以使用者实际上属于跳过了优越性的论证,
理论上以完美的90度观察任意材质的表面都应该会出现全反射现象(所有物体、材质都有菲涅尔现象)。
基础反射率 F0F_0F0
这是 Fresnel 项在正入射时的值:
F0=F(θ=0)F_0 = F(\theta=0)F0=F(θ=0)
意思是视线或入射方向和表面法线重合时,表面有多少能量会以镜面方式被反射回去。
对电介质,F0F_0F0 通常较低,常见在 0.02 到 0.08 左右。
对金属,F0F_0F0 很高,而且往往是 RGB 有色的。导体或者金属表面而言基础反射率一般是带有色彩的,这也是为什么要用RGB三原色来表示的原因(法向入射的反射率可随波长不同而不同)。
这里如果按物理意义理解,应该是"占入射总能量的比例",不是"反射光 ÷ 折射光"的比值。
更准确地说,Fresnel 方程给的是:
-
反射率 RRR:入射能量里有多少被反射
-
透射率 TTT:入射能量里有多少被透射/折射
在无吸收的理想情况下:
R+T=1R + T = 1R+T=1
所以 Fresnel 讨论的是"对整体入射能量的分配"。
你圈出来那句"表面上被反射的光除以被折射的光的比例",表述不严谨,严格说是有问题的。它容易让人理解成"反射量和折射量彼此相除",但 Fresnel 不是在定义这个。
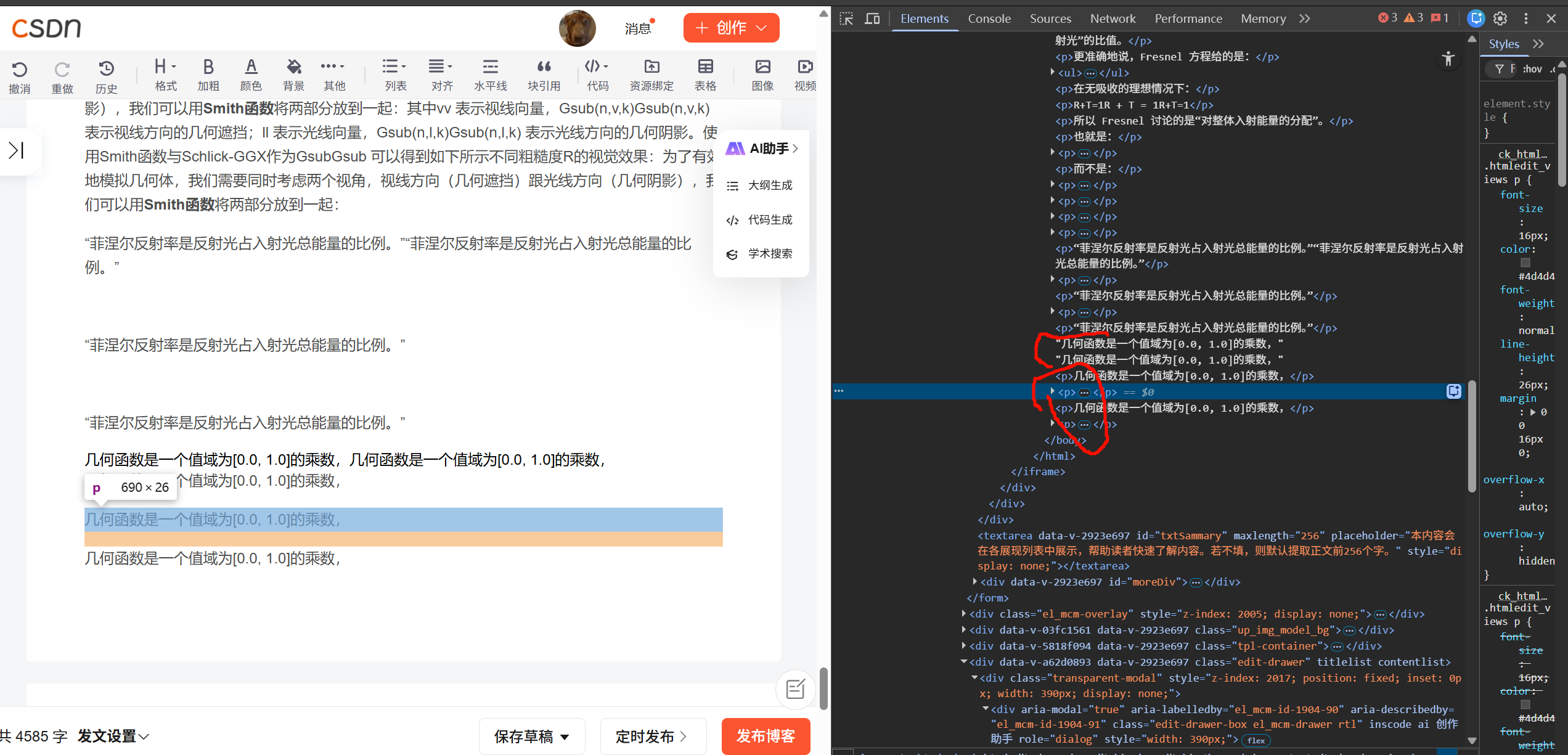
通过预先计算电介质与导体的值,我们可以对两种类型的表面使用相同的Fresnel-Schlick近似,但是如果是金属表面的话就需要对基础反射率添加色彩。类似NDF,几何函数也使用粗糙度作为输入参数,更粗糙意味着微平面产生自阴影的概率更高。几何函数使用由GGX和Schlick-Beckmann组合而成的模拟函数Schlick-GGX:αα 的值取决于你的引擎怎么将粗糙度转化成αα ,会进一步讨论如何和在什么地方进行这个转换。有效地模拟几何体
为了有效地模拟几何体,我们需要同时考虑两个视角,视线方向(几何遮挡)跟光线方向(几何阴影),我们可以用Smith函数 将两部分放到一起:其中vv 表示视线向量,Gsub(n,v,k)Gsub(n,v,k) 表示视线方向的几何遮挡;ll 表示光线向量,Gsub(n,l,k)Gsub(n,l,k) 表示光线方向的几何阴影。使用Smith函数与Schlick-GGX作为GsubGsub 可以得到如下所示不同粗糙度R的视觉效果:为了有效地模拟几何体,我们需要同时考虑两个视角,视线方向(几何遮挡)跟光线方向(几何阴影),我们可以用Smith函数将两部分放到一起:
所以现在调试的好了---但不多
由GGX和Schlick-Beckmann组合而成的模拟函数Schlick-GGX:
同时考虑两个视角,视线方向(几何遮挡)跟光线方向(几何阴影)用Smith函数将两部分放到一起:vv 表示视线向量,Gsub(n,v,k)Gsub(n,v,k) 表示视线方向的几何遮挡;ll 表示光线向量,Gsub(n,l,k)Gsub(n,l,k) 表示光线方向的几何阴影。使用Smith函数与Schlick-GGX作为GsubGsub
所以,这个几何自遮挡,更多的是对形体的保留,这个添加了很多的细节,
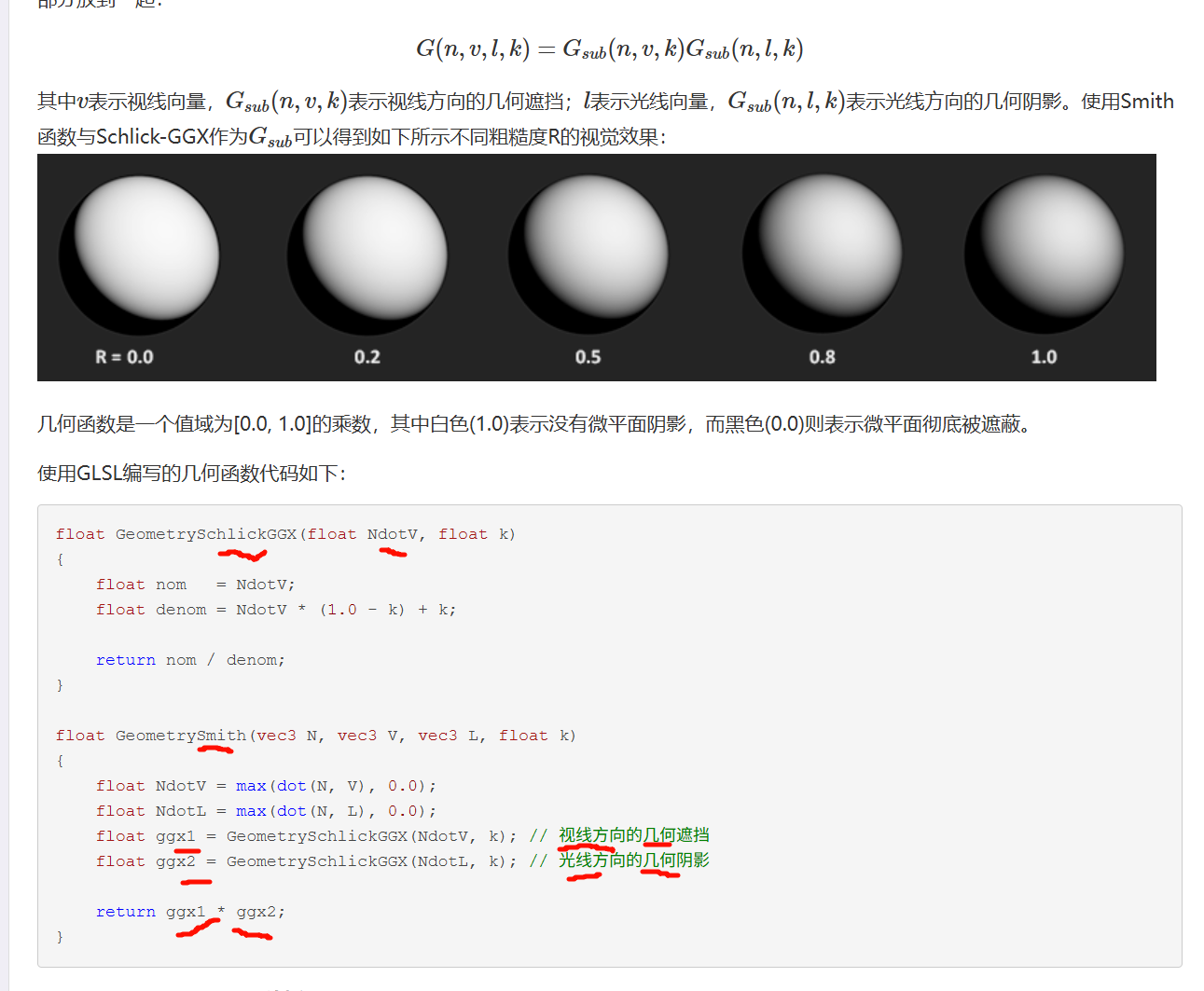
黑色(0.0)则表示微平面彻底被遮蔽。部分我们我们都用基于物理的BRDF替换提到菲涅尔项FF 代表光在表面的反射比率,它直接影响ksks 因子,意味着反射方程的镜面反射部分已经隐含了因子ksks 最终的Cook-Torrance去掉了ksks )
Lo(p,ωo)=∫Ω(kdcπ+DFG4(ωo⋅n)(ωi⋅n))Li(p,ωi)n⋅ωidωi
无论环境光怎么样设置都能得到一个接近真实的渲染结果,这让美术的人生都变得美好了。除非我们通过金属度属性在F0跟albedo之间进行线性插值,才能得到一个不同的非金属F0。denom 是 denominator 的缩写
所以:
-
num= numerator = 分子 -
denom= denominator = 分母
你图里这一行:
overflow-visible!
glsl
denom = PI * denom * denom;
意思是把前面算出来的那个中间量继续整理成 GGX 分布函数最终公式里的分母。
对应的 GGX NDF 标准形式是:
D=α2π((N⋅H)2(α2−1)+1)2D = \frac{\alpha^2}{\pi \left((N \cdot H)^2(\alpha^2 - 1) + 1\right)^2}D=π((N⋅H)2(α2−1)+1)2α2法线分布函数跟几何函数中使用粗糙度的平方替代原始粗糙度进行计算光照效果会更正确一些。
当这些都定义好了之后,在计算NDF和G分量就是很简单的事情了:
然后就可以计算Cook-Torrance BRDF了:
glsl
vec3 numerator = NDF * G * F;
float denominator = 4.0 * max(dot(N, V), 0.0) * max(dot(N, L), 0.0);
vec3 specular = numerator / max(denominator, 0.001); 到这里,我们终于可以计算每个光源对反射方程的贡献了。因为菲涅尔值相当于kSkS ,可用F代表任意光击中表面后被反射的部分,根据能量守恒定律我们可以用kSkS 直接计算得到kDkD :
glsl
vec3 kS = F;
vec3 kD = vec3(1.0) - kS;
kD *= 1.0 - metallic; // 由于金属表面不折射光,没有漫反射颜色,通过归零kD来实现这个规则金属表面不折射光,因此没有漫反射颜色,我们通过归零kDkD 来实现这个规则。
将kSkS 移除方程式,是因为我们已经在BRDF中乘过菲涅尔参数F了,此处不需要再乘一次。
为了使用这个结果我们还需要在着色器的最后进行伽马校正(Gamma Correct),在线性空间计算光照对于PBR是非常非常重要的,所有输入参数同样要求是线性的,不考虑这一点将会得到错误的光照结果。
伽马矫正之后还保持高动态范围
在物理和基于物理的渲染(PBR)中,
纯金属几乎没有漫反射 。由于金属内部拥有大量自由电子,光线穿过表面时会被迅速吸收并转化为热能,无法重新折射射出,因此所有反射光线仅在表面发生镜面反射。我们在日常生活中看到的金属色泽(如金、铜)实际上是镜面反射不同频率光线的结果。
PBR 中的金属表现: 在现代PBR(基于物理的渲染)材质工作流中,金属通常被认为没有漫反射(Diffuse = 0,纯黑),它们的光泽全靠高光(Specular/Reflection)来体现。
float GeometrySchlickGGX(float NdotV, float roughness) { float r = (roughness + 1.0); float k = (r*r) / 8.0; float nom = NdotV; float denom = NdotV * (1.0 - k) + k; return nom / denom; }
介绍IBL结合PBR之前,先回顾一下反射方程:
Lo(p,ωo)=∫Ω(kdcπ+ksDFG4(ωo⋅n)(ωi⋅n))Li(p,ωi)n⋅ωidωi
每一个来自周围环境的入射光ωiωi 都可能存在辐射,
可以假设它的每个像素是一个单独的发光光源。
获取任意方向向量ωiωi 的场景辐射很简单,如下:
glsl
vec3 radiance = texture(_cubemapEnvironment, w_i).rgb; 为解决积分有两个要求:
- 需要用某种方法获得给定任意方向向量ωiωi 的场景辐射。
- 解决积分需尽可能快并实时。
可分开处理漫反射和镜面反射的积分。先从漫反射积分开始。
Lambert漫反射是个常量项(颜色cc ,折射因子kdkd 和ππ )并且不依赖积分变量。因此,可见常量部分移出漫反射积分:
Lo(p,ωo)=kdcπ∫ΩLi(p,ωi)n⋅ωidωiLo(p,ωo)=kdcπ∫ΩLi(p,ωi)n⋅ωidωi
因此,积分只依赖ωiωi (假设pp 在环境贴图的中心)。据此,可以计算或预计算出一个新的cubemap,这个cubemap存储了用卷积(convolution)计算出的每个采样方向(或像素)ωoωo 的漫反射积分结果。
卷积(convolution)为了卷积环境图,解决每个输出ωoωo 采样方向的积分,离散地采样大量的在半球ΩΩ 的方向ωiωi 并取它们辐射的平均值。辐射方程依赖于位置p所有非直接漫反射光需来自于同一个环境图,引擎用放置遍布场景的反射探头(reflection probe)来解决,
球体图(Equirectangular map)
有些文献翻译成全景图,它与cubemap不一样的是:cubemap需要6张图,而球体图只需要一张,并且存储的贴图有一定形变:

从球体图到立方体图从球体图采样出环境光照信息开销远大于直接采样立方体图(cubemap)像素着色器中,会对变形的球体图的每个部位映射到立方体的每一边,
uniform sampler2D equirectangularMap;
对于立方体图的采样,像素着色器如下:
glsl
#version 330 core
out vec4 FragColor;
in vec3 localPos;
uniform samplerCube environmentMap;
void main()
{
// 从cubemap采样颜色
vec3 envColor = texture(environmentMap, localPos).rgb;
// HDR -> LDR
envColor = envColor / (envColor + vec3(1.0));
// Gamma校正(只在颜色为线性空间的渲染管线才需要)
envColor = pow(envColor, vec3(1.0/2.2));
FragColor = vec4(envColor, 1.0);
}(indirect irradiance lighting)
非直接光依旧包含了漫反射和镜面反射两个部分,所以我们需要加个权重给漫反射。
分裂和近似法(split sum approximation)。
=∫ΩLi(p,ωi)dωi∗∫Ωfr(p,ωi,ωo)n⋅ωidωi
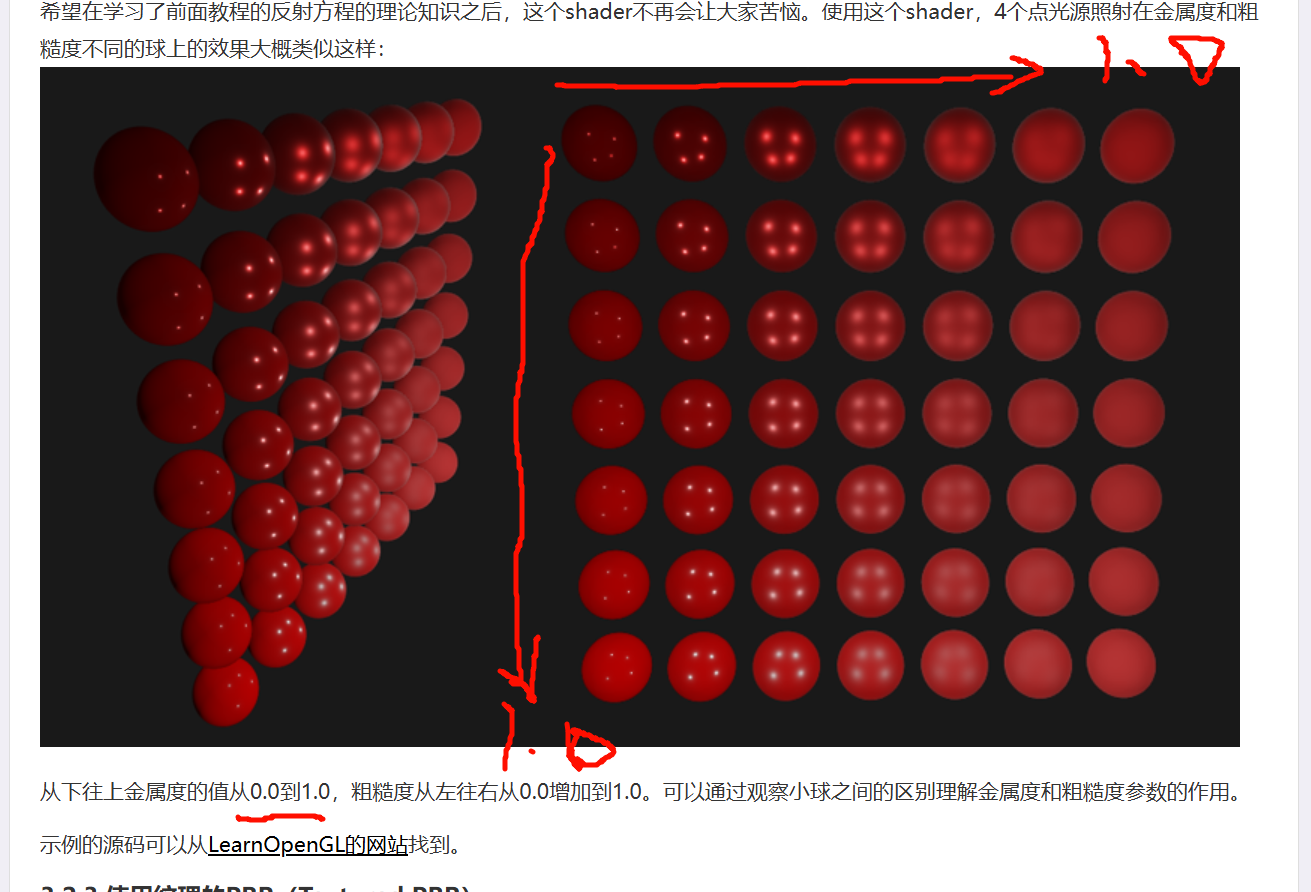
会加入粗糙度。随着粗糙度等级的增加,环境图使用更多的散射采样向量来卷积,创建出更模糊的反射。
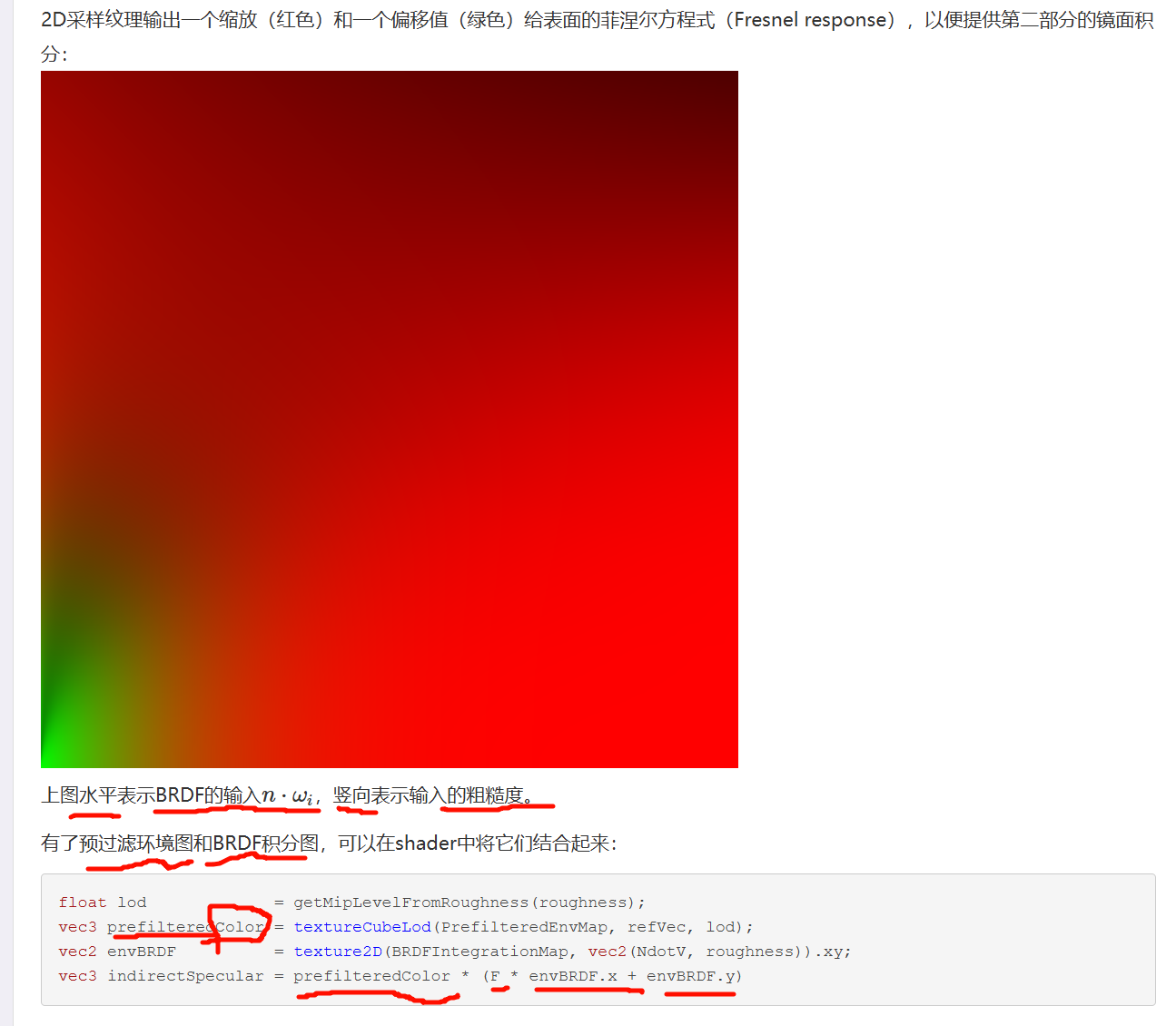
生成采样向量和它们的散射强度,需要用到Cook-Torrance BRDF的法线分布图(NDF),
不需要关心视线方向。这就意味着当从某个角度看向下面这张图的镜面表面反射时,无法获得很好的掠射镜面反射(grazing specular reflections)。然而通常这被认为是一个较好的妥协:
光源中的光来自于电子的振动,电子振动所伴生的电磁波辐射形成了光波,
- 线性运动 :电子的线性运动是核外电子的绕核运动及在导电时电子的流动,它所伴生电磁波的宏观表现是磁场。电子的线性运动不是产生光的原因。
- 振动 :电子的振动与发光息息相关,它会使电磁脱离场源形成电磁波,也就是产生了光,而不是所谓的光子。引起电子振动有两种原因:
- 一是高温物质核外电子的跃迁引发的振动,这种振动需要物质的温度大大高于环境温度,运转速率很高的核外电子跃迁辐射才能达到可见光的频率。这种高温物质核外电子的跃迁辐射所形成发光的光源叫热光源。岩浆、铁水、火焰、灯丝等高温物质的发光属于热光源。
- 二是电子在磁场或电场的作用下引发的受激振动,这样的电子振动与温度无关、与核外电子运转速率无关。这种不需要高温而使电子振动所形成辐射的光源叫冷光源。日光灯、节能灯、极光、萤火虫的发光、半导体发光(LED)等属于冷光源。
高温物质核外电子的跃迁辐射所形成发光的光源叫热光源。
不需要高温而使电子振动
的光源叫冷光源
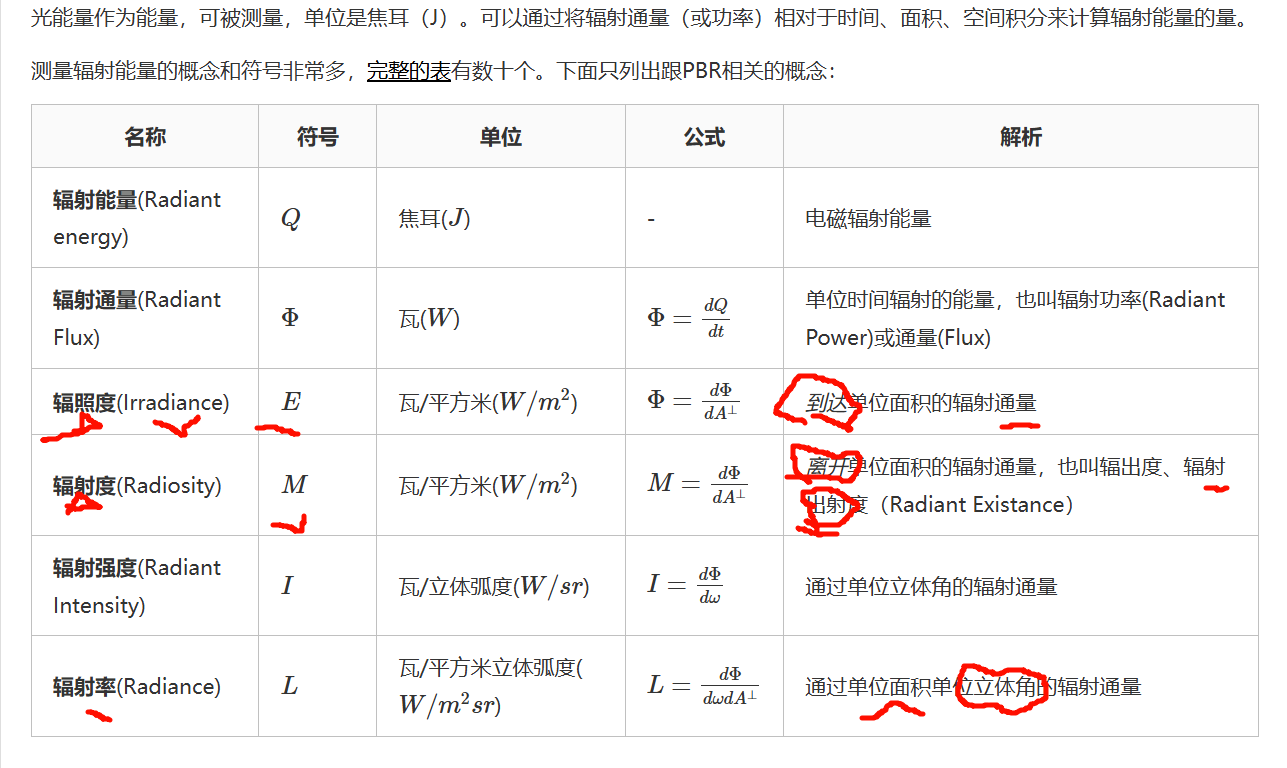
离开和进入,辐射,辐射,辐射出度,辐照入度,辐射强度
单位很多,辐射率radiance才是联合了立体角概念的,辐射强度都不算准确
单位 W/(m^2\cdot sr)
意思是:
"某个表面点,在某个方向上,每单位投影面积、每单位方向范围里的通量密度"。
所以它比前面多了一个 sr,不是因为它突然在算三维体积,而是因为它除了区分"面积",还区分"方向"。
你会觉得莫名其妙,是因为中文里"立体角"这个词很容易把人带偏。
几何光学是将光的波长视作无限小,以致可以将光当成直线来研究的一门物理分支。
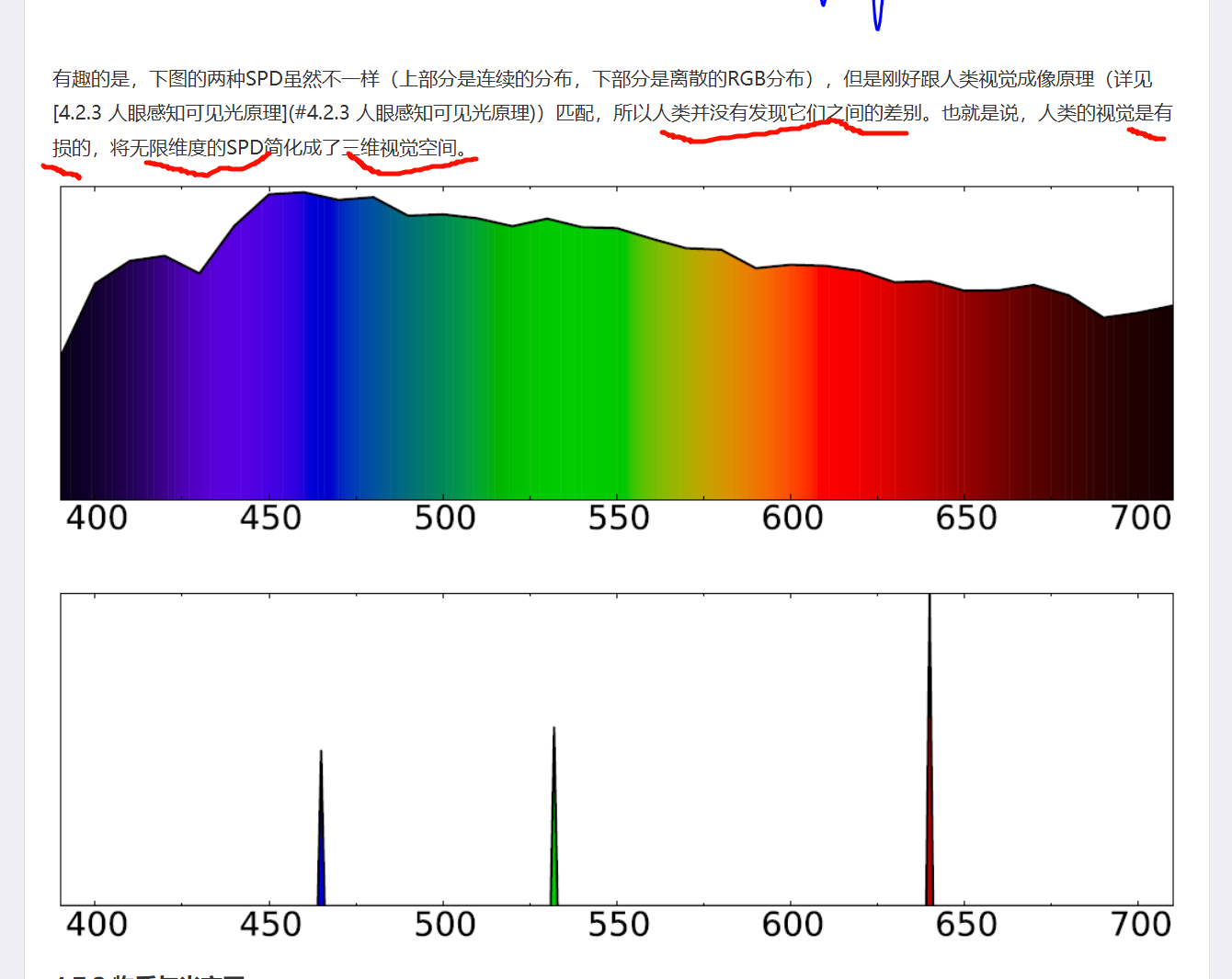
BRDF最终的光照计算结果是几何函数和油墨算法(ink-selection)结合的结果。
如果文章在讨论"表面颜色怎么形成"或者"如何从 RGB 推回各颜色分量反射率",作者可能突然引入了印刷/颜料/光谱反射模型。
这时"油墨"是在说一种颜色生成模型,不是在说 BRDF 的几何光学项。
如果把它们放在同一系统里,可以这么理解:
最终观感颜色 = 光源光谱 × 材料的波长反射特性 × 方向反射分布
其中:
-
"方向反射分布"可以由 BRDF 负责
-
"波长反射特性"可能由颜料/油墨/吸收模型负责
Semantic Scholar 本质上就是一个学术论文整合与检索平台,更准确地说是:
它不是论文"首发网站",
而是把很多来源的学术论文、作者、引用关系、相关论文等信息聚合起来,供你搜索、筛选、追踪。
Google Scholar:覆盖极广,但规模不透明。Google Scholar
Semantic Scholar:头部论文检索平台,200M+ 级别,强项是 AI 辅助发现。Semantic Scholar+1
OpenAlex:开放学术元数据/图谱基础设施,公开 works 数更大。OpenAlex
Dimensions:更偏"连接型科研数据库",范围超出论文本身。Digital Science
这些网站大多是"免费检索入口",不是"所有论文全文免费仓库"。
你能不能直接读全文,主要取决于这篇论文是不是 Open Access,或者你所在机构有没有订阅。
不该只看引用数,还该看这几个东西:
-
venue:发在哪,SIGGRAPH、EGSR、HPG、CGF、TOG 还是杂源
-
年份:是不是刚出来
-
主题:是不是窄领域问题
-
被谁引:后续高质量工作有没有接它
-
作者和团队:是不是长期做这个方向的人
Karis、Hable、Heitz、Akenine-Möller、Wyman、ARM graphics team、Unity graphics、Frostbite rendering team
The names you've listed represent the "Who's Who" of modern real-time computer graphics, specifically the researchers and engineers who authored the definitive textbook
Real-Time Rendering (4th Edition)
These contributors bridge the gap between academic research and industry application in gaming and mobile hardware:
- Tomas Akenine-Möller
: Lead author of the "Real-Time Rendering" series and a distinguished researcher at NVIDIA (formerly Intel and Lund University) known for his work on triangle-box overlap tests
and mobile GPU architectures. - Brian Karis
: A Senior Graphics Programmer at Epic Games famous for his work on the UE4 Physically Based Shading model and the Nanite technology in Unreal Engine 5. - John Hable
: A rendering engineer (formerly at Naughty Dog) well-known for his popular filmic tone mapping operators and work on high-end character rendering. - Eric Heitz
: A Unity researcher whose work on procedural stochastic textures
and Masked-Sample Photocopying has solved long-standing issues with repetitive texture tiling in games. - Chris Wyman
: A Principal Research Scientist at NVIDIA focusing on ray tracing and light transport, often contributing to the state-of-the-art in real-time global illumination. - Industry Teams :
- ARM Graphics Team: Responsible for the Mali GPU architectures and mobile-specific rendering optimizations .
- Unity & Frostbite (EA) Rendering Teams : The primary developers behind the most widely used commercial game engines (Unity's HDRP/URP and Frostbite's PBR engine used in Battlefield).
- https://www.realtimerendering.com/refs.html


Micro(微观/微小)和Macro(宏观/巨大)是 表示规模、范围的相对概念 。Micro指个体、局部或微细细节(如微观经济、显微镜);Macro指整体、全局或宏大趋势(如宏观经济、大局观)。在机器学习中,Macro对类别平均,Micro对样本平均。
核心区别与应用场景:
- 概念定义:
- Micro (微观): 源自希腊语,指"小",侧重于细部、个别单位或极小量。
- Macro (宏观): 源自希腊语,指"长"或"大",侧重于整体架构、总体趋势。
- 经济学领域:
- Microeconomics (微观经济学): 研究个人、家庭、企业如何做出决策,关注供需、价格。
- Macroeconomics (宏观经济学): 研究整体经济行为,关注GDP、通胀、失业率等总体指标。
- 数据与机器学习(分类评估):
- Macro F1: 每个类别独立计算指标(Precision/Recall),然后取平均值。平等对待所有类别,适用于类别不平衡但注重所有类别表现的场景。
- Micro F1: 考虑所有类别的总体真阳性、假阳性总数。平等对待每个样本,在类别不平衡时(主要类别主导),Micro 往往更优。
- 游戏与项目管理(星际争霸等):
- Micro (微操): 操控单个兵种的战斗技巧。
- Macro (运营/大局): 经营经济、建造基地、管理资源和人口的技术。
- 发音差异:
- Micro: 发音类似 "my-kro" (/ˈmaɪ.kroʊ/)。
- Macro: 发音类似 "ma-kro" (/ˈmæk.roʊ/),"a" 发短元音。