本文面向中高级前端开发者,纯企业级进阶实践导向,基于React 19 + Next.js 15技术栈,完整拆解AI原生前端的核心架构设计、工程化落地、全链路性能优化与踩坑解决方案,覆盖流式交互、RAG前端体系、端侧AI工程化、安全防护等核心场景,所有代码均可直接落地复用。
摘要
AI时代的前端开发,早已脱离了「页面渲染+接口调用」的传统范式,核心矛盾转变为大模型流式推理的不确定性与前端交互体验的确定性之间的平衡。本文从AI原生前端的架构范式演进出发,系统拆解了企业级RAG智能对话系统的前端完整架构设计,深入阐述了流式交互全链路实现、RAG前端组件化体系、端侧AI工程化落地、全链路性能优化、工程化与安全防护五大核心实践模块,配套完整的生产级代码实现与踩坑解决方案,最终形成可直接复用的AI原生前端工程化最佳实践体系。
关键词:AI原生前端;流式交互;RAG前端工程化;端侧AI;Next.js 15;WebGPU;性能优化
前言
在传统Web开发中,前端的核心职责是「实现UI界面与接口数据的绑定」,交互范式以「请求-响应」的同步模式为主,核心挑战集中在页面渲染性能、跨端兼容性与工程化规范。而在AI原生场景下,前端的核心职责发生了本质变化:
• 交互范式从「离散的请求-响应」转向「连续的流式时序交互」
• 能力边界从「UI渲染」扩展到「AI能力的前端封装、端侧推理、体验治理」
• 核心挑战从「静态页面性能」转向「不确定性推理过程的确定性体验保障」
本文基于笔者在企业级AI对话平台的完整落地经验,摒弃入门级的API调用教程,聚焦AI原生前端的进阶工程化实践,从架构设计到代码实现,从性能优化到踩坑避坑,完整呈现AI原生前端的全链路落地体系。
一、AI原生前端的架构范式与核心边界
1.1 传统前端与AI原生前端的范式差异
我们先通过一张表格,明确AI原生前端与传统前端的核心边界,这也是所有进阶实践的基础:
维度 传统前端范式 AI原生前端范式
核心交互 同步请求-响应,一次性数据渲染 流式时序交互,增量数据持续渲染
核心职责 UI渲染、接口调用、数据绑定 AI能力封装、流式体验治理、端云协同、RAG交互落地
状态管理 静态数据状态,低频率更新 流式动态状态,毫秒级高频更新,强时序一致性要求
性能指标 首屏加载时间、LCP、FID、TTI 首Token延迟、Token生成帧率、交互响应延迟、内存占用
渲染挑战 静态页面的重渲染优化 增量内容的实时渲染、Markdown/代码/公式的增量解析、无闪烁更新
安全边界 XSS/CSRF防护、接口权限控制 Prompt注入防护、系统Prompt泄露防护、流式内容安全审核、端侧数据隐私保护
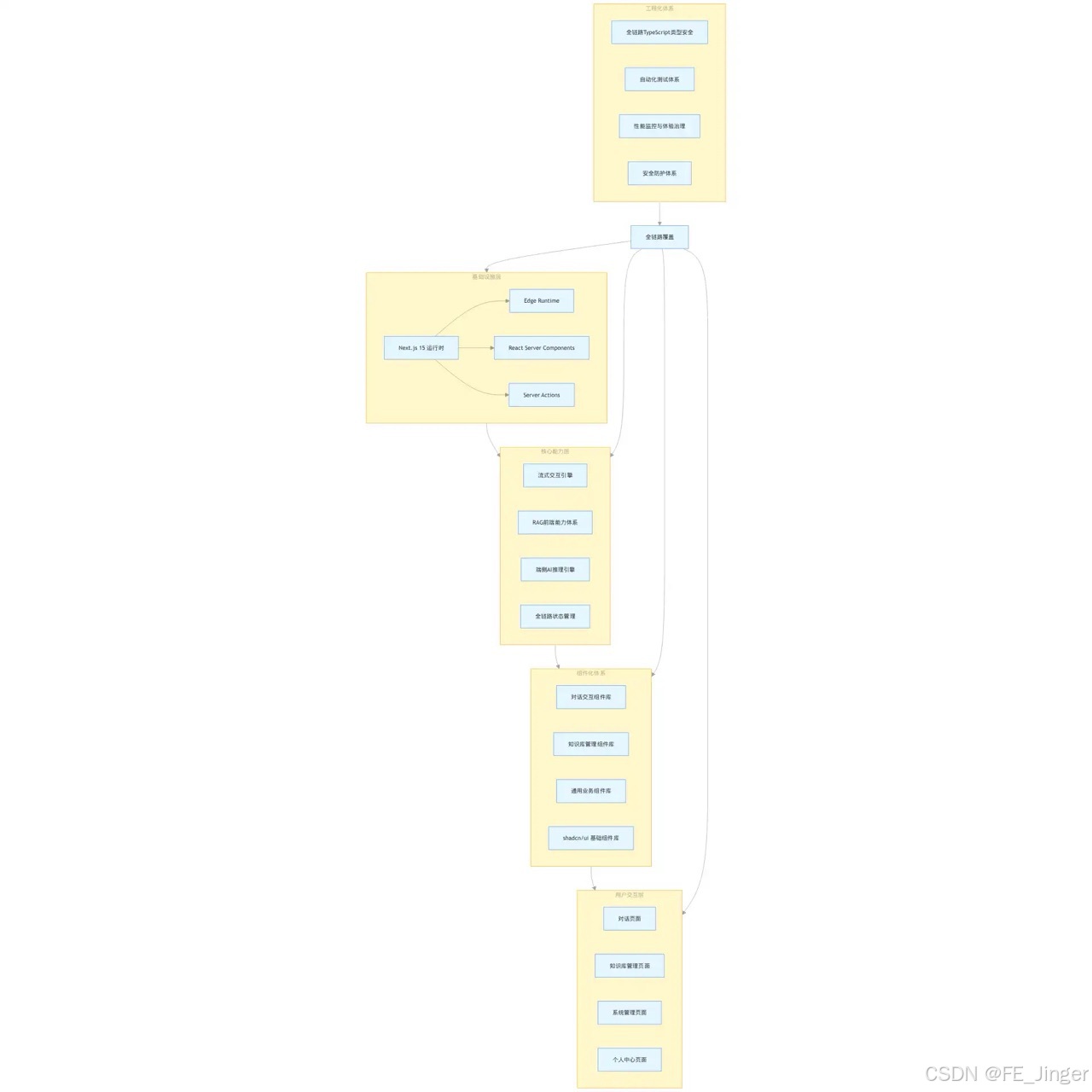
1.2 企业级AI对话系统的前端整体架构
本文所有实践均围绕「企业级RAG智能对话系统」展开,其前端架构采用分层解耦设计,基于Next.js 15 App Router实现,完整架构如下:
flowchart TB
subgraph 基础设施层
ANext.js 15 运行时
A1Edge Runtime
A2React Server Components
A3Server Actions
A --> A1 & A2 & A3
end
subgraph 核心能力层
B[流式交互引擎]
C[RAG前端能力体系]
D[端侧AI推理引擎]
E[全链路状态管理]
end
subgraph 组件化体系
F[对话交互组件库]
G[知识库管理组件库]
H[通用业务组件库]
I[shadcn/ui 基础组件库]
end
subgraph 工程化体系
J[全链路TypeScript类型安全]
K[自动化测试体系]
L[性能监控与体验治理]
M[安全防护体系]
end
subgraph 用户交互层
N[对话页面]
O[知识库管理页面]
P[系统管理页面]
Q[个人中心页面]
end
基础设施层 --> 核心能力层 --> 组件化体系 --> 用户交互层
工程化体系 --> 全链路覆盖 --> 基础设施层 & 核心能力层 & 组件化体系 & 用户交互层技术栈选型(2026年生产级稳定方案)
技术模块 选型方案 选型核心理由
核心框架 Next.js 15(App Router) 原生支持React Server Components、Streaming SSR、Edge Runtime,完美适配AI流式场景,实现前后端一体化开发
开发语言 TypeScript 5.4 全链路类型安全,覆盖API请求、AI响应、状态管理全流程,减少运行时错误
UI框架 TailwindCSS + shadcn/ui 原子化CSS,高度可定制,无组件依赖侵入,适配企业级设计系统,支持流式交互组件的快速开发
状态管理 Zustand 5.x 轻量高性能、TypeScript友好、支持不可变数据更新,完美适配AI对话场景的高频状态更新
流式SDK 自定义封装 + Vercel AI SDK 3.x 底层基于Fetch API + ReadableStream自主封装,上层基于Vercel AI SDK实现多模型兼容,兼顾灵活性与开发效率
Markdown渲染 Remark + Rehype + Shiki 支持增量渲染、语法高亮、数学公式、Mermaid流程图,适配流式内容的无闪烁更新
端侧AI Transformers.js 4.x + ONNX Runtime Web 支持浏览器端模型加载与推理,WebGPU加速,适配端侧Embedding、Rerank等轻量AI任务
测试工具 Vitest + Playwright + MSW 单元测试、E2E测试、接口Mock全覆盖,适配AI流式场景的测试需求
监控工具 Sentry + 自定义埋点 错误监控、性能监控、AI场景专属指标(首Token延迟、Token生成速度)监控
1.3 架构设计的核心原则
所有实践均遵循以下5条核心原则,这是企业级AI前端架构稳定运行的根基:
-
时序优先原则:所有流式交互必须严格保证时序一致性,后发起的请求必须覆盖先发起的请求,禁止乱序
-
正交解耦原则:UI渲染、流式逻辑、AI能力、业务逻辑严格分层解耦,单一模块仅负责单一职责
-
渐进降级原则:所有AI能力必须设计降级方案,网络异常、模型调用失败时,保障基础交互可用
-
性能无感原则:所有高频更新、端侧计算必须避免阻塞主线程,保障页面帧率稳定,用户无卡顿感知
-
全链路类型安全原则:从API请求到状态管理,从组件属性到AI响应,实现全链路TypeScript类型覆盖,配合Zod做运行时校验
二、核心实践一:流式交互全链路工程化实现
流式交互是AI原生前端的核心,也是最容易出现体验问题、工程化混乱的模块。本章节将从底层协议选型到上层组件封装,完整拆解生产级流式交互的全链路实现。
2.1 底层协议选型:SSE vs WebSocket
AI流式场景的底层传输协议,主流方案为SSE(Server-Sent Events)与WebSocket,我们先通过生产级实践对比,明确选型边界:
特性 SSE WebSocket
通信模式 单工通信,仅服务端向客户端推送数据 全双工通信,客户端与服务端双向通信
协议基础 基于HTTP/HTTPS,原生支持 独立的WS/WSS协议,需要握手升级
流式适配 原生支持文本流式传输,无帧解析成本 需要自行处理数据帧解析,适配流式场景
兼容性 全浏览器兼容,支持HTTP/2多路复用 全浏览器兼容,需要处理连接保活
重连机制 原生支持自动重连,可自定义重试策略 需要自行实现重连、心跳保活逻辑
中断支持 原生支持AbortController中断请求 需要自行实现中断信号传递
适用场景 纯大模型流式对话、单向数据推送 多模态实时交互、多人协作、双向实时通信
生产级选型结论:
• 纯对话流式场景,优先选择SSE,实现成本更低、原生支持中断与重连、无额外的帧解析开销,配合Fetch API + ReadableStream可实现完全可控的流式处理
• 涉及实时语音、多人协作、双向实时交互的场景,选择WebSocket,配合心跳保活、断连重连机制保障稳定性
本文所有实践均基于Fetch API + ReadableStream + SSE实现,这是当前企业级AI对话系统的主流方案。
2.2 流式交互核心引擎封装
我们先封装一个生产级的useSSEStream自定义Hook,覆盖流式请求的发起、中断、重试、超时、时序控制、状态管理全流程,解决90%以上的流式场景问题。
2.2.1 全链路类型定义
首先实现全链路类型安全,定义流式交互的核心类型:
// types/stream.ts
import { z } from 'zod';
// 消息角色枚举
export enum MessageRole {
USER = 'user',
ASSISTANT = 'assistant',
SYSTEM = 'system',
}
// 单条消息Schema
export const MessageSchema = z.object({
id: z.string(),
role: z.nativeEnum(MessageRole),
content: z.string(),
createdAt: z.number(),
referenceIds: z.array(z.string()).optional(), // 引用来源ID
status: z.enum('pending', 'streaming', 'done', 'error').optional(),
});
// 消息类型
export type Message = z.infer;
// 流式请求参数
export interface StreamRequestParams {
messages: Message\[\];
knowledgeBaseId?: string;
model: string;
temperature?: number;
stream?: boolean;
}
// 流式响应事件类型
export enum StreamEventType {
CONTENT = 'content',
REFERENCE = 'reference',
DONE = 'done',
ERROR = 'error',
}
// 流式响应数据Schema
export const StreamResponseSchema = z.discriminatedUnion('type', [
z.object({
type: z.literal(StreamEventType.CONTENT),
data: z.string(), // 增量内容
}),
z.object({
type: z.literal(StreamEventType.REFERENCE),
data: z.array(z.string()), // 引用来源ID
}),
z.object({
type: z.literal(StreamEventType.DONE),
data: z.object({
totalTokens: z.number(),
completionTokens: z.number(),
promptTokens: z.number(),
}),
}),
z.object({
type: z.literal(StreamEventType.ERROR),
data: z.object({
code: z.string(),
message: z.string(),
}),
}),
]);
export type StreamResponse = z.infer;
2.2.2 核心Hook实现
useSSEStream Hook 核心能力:
• 支持请求中断、超时控制、自动重试
• 严格的时序控制,避免请求乱序
• 全链路类型安全,运行时数据校验
• 流式状态管理,异常处理
• 与React状态无缝集成,优化重渲染
// hooks/use-sse-stream.ts
import { useState, useRef, useCallback, useEffect } from 'react';
import { z } from 'zod';
import {
Message,
StreamRequestParams,
StreamResponse,
StreamResponseSchema,
StreamEventType,
MessageRole,
} from '@/types/stream';
import { v4 as uuidv4 } from 'uuid';
interface UseSSEStreamOptions {
apiUrl: string;
timeout?: number; // 请求超时时间,默认30s
retryCount?: number; // 重试次数,默认3次
onMessageComplete?: (message: Message) => void; // 消息完成回调
onError?: (error: { code: string; message: string }) => void; // 错误回调
}
export function useSSEStream(options: UseSSEStreamOptions) {
const {
apiUrl,
timeout = 30000,
retryCount = 3,
onMessageComplete,
onError,
} = options;
// 流式消息状态
const currentMessage, setCurrentMessage = useState<Message | null>(null);
const isStreaming, setIsStreaming = useState(false);
const error, setError = useState<{ code: string; message: string } | null>(null);
// 引用管理,避免闭包陷阱
const abortControllerRef = useRef<AbortController | null>(null);
const retryTimesRef = useRef(0);
const currentRequestIdRef = useRef<string | null>(null);
const timeoutTimerRef = useRef<NodeJS.Timeout | null>(null);
// 清除超时定时器
const clearTimeoutTimer = useCallback(() => {
if (timeoutTimerRef.current) {
clearTimeout(timeoutTimerRef.current);
timeoutTimerRef.current = null;
}
}, \[\]);
// 中断当前流式请求
const abortStream = useCallback(() => {
if (abortControllerRef.current) {
abortControllerRef.current.abort();
abortControllerRef.current = null;
}
clearTimeoutTimer();
setIsStreaming(false);
currentRequestIdRef.current = null;
}, clearTimeoutTimer);
// 重置流式状态
const resetStream = useCallback(() => {
abortStream();
setCurrentMessage(null);
setError(null);
retryTimesRef.current = 0;
}, abortStream);
// 超时处理
const handleTimeout = useCallback((requestId: string) => {
if (currentRequestIdRef.current !== requestId) return;
abortStream();
const timeoutError = { code: 'TIMEOUT', message: '请求超时,请重试' };
setError(timeoutError);
onError?.(timeoutError);
}, abortStream, onError);
// 核心流式请求方法
const startStream = useCallback(
async (params: StreamRequestParams) => {
// 中断上一个请求,保证时序一致性
abortStream();
// 生成唯一请求ID,用于时序校验
const requestId = uuidv4();
currentRequestIdRef.current = requestId;
retryTimesRef.current = 0;
setError(null);
// 初始化助手消息
const assistantMessage: Message = {
id: uuidv4(),
role: MessageRole.ASSISTANT,
content: '',
createdAt: Date.now(),
referenceIds: [],
status: 'streaming',
};
setCurrentMessage(assistantMessage);
setIsStreaming(true);
// 超时定时器
timeoutTimerRef.current = setTimeout(() => {
handleTimeout(requestId);
}, timeout);
// 核心请求逻辑
const executeRequest = async () => {
// 新的AbortController
const controller = new AbortController();
abortControllerRef.current = controller;
try {
const response = await fetch(apiUrl, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
...params,
stream: true,
requestId,
}),
signal: controller.signal,
});
// 清除超时定时器,首包返回后重置超时
clearTimeoutTimer();
if (!response.ok) {
throw new Error(`请求失败:${response.status} ${response.statusText}`);
}
const reader = response.body?.getReader();
if (!reader) {
throw new Error('流式响应读取失败');
}
const decoder = new TextDecoder('utf-8');
let buffer = ''; // 处理粘包的缓冲区
// 循环读取流式数据
while (true) {
const { done, value } = await reader.read();
// 时序校验:如果当前请求已被覆盖,直接终止
if (currentRequestIdRef.current !== requestId) {
reader.cancel();
return;
}
if (done) {
break;
}
// 重置超时定时器,每收到一个包就重置
clearTimeoutTimer();
timeoutTimerRef.current = setTimeout(() => {
handleTimeout(requestId);
}, timeout);
// 解码数据,处理粘包
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split('\n\n');
buffer = lines.pop() || ''; // 剩余不完整的行放回缓冲区
// 处理每一行数据
for (const line of lines) {
if (!line.trim() || !line.startsWith('data: ')) continue;
const jsonStr = line.replace('data: ', '').trim();
if (jsonStr === '[DONE]') continue;
// 运行时数据校验
const parseResult = StreamResponseSchema.safeParse(JSON.parse(jsonStr));
if (!parseResult.success) continue;
const streamData: StreamResponse = parseResult.data;
// 根据事件类型处理数据
switch (streamData.type) {
case StreamEventType.CONTENT:
// 增量更新内容,使用不可变更新
setCurrentMessage((prev) => {
if (!prev) return prev;
return {
...prev,
content: prev.content + streamData.data,
};
});
break;
case StreamEventType.REFERENCE:
// 更新引用来源
setCurrentMessage((prev) => {
if (!prev) return prev;
return {
...prev,
referenceIds: Array.from(new Set([...(prev.referenceIds || []), ...streamData.data])),
};
});
break;
case StreamEventType.DONE:
// 流式完成
setCurrentMessage((prev) => {
if (!prev) return prev;
const completedMessage = {
...prev,
status: 'done',
};
onMessageComplete?.(completedMessage);
return completedMessage;
});
setIsStreaming(false);
currentRequestIdRef.current = null;
clearTimeoutTimer();
break;
case StreamEventType.ERROR:
throw new Error(streamData.data.message);
}
}
}
} catch (err: any) {
// 中断请求不处理错误
if (err.name === 'AbortError') return;
// 时序校验
if (currentRequestIdRef.current !== requestId) return;
// 重试逻辑
if (retryTimesRef.current < retryCount) {
retryTimesRef.current += 1;
executeRequest();
return;
}
// 重试耗尽,处理错误
const streamError = {
code: err.code || 'STREAM_ERROR',
message: err.message || '流式请求异常,请重试',
};
setError(streamError);
setCurrentMessage((prev) => {
if (!prev) return prev;
return {
...prev,
status: 'error',
};
});
setIsStreaming(false);
onError?.(streamError);
clearTimeoutTimer();
}
};
executeRequest();
},
[apiUrl, timeout, retryCount, abortStream, clearTimeoutTimer, handleTimeout, onMessageComplete, onError]);
// 组件卸载时中断请求,避免内存泄漏
useEffect(() => {
return () => {
abortStream();
};
}, abortStream);
return {
currentMessage,
isStreaming,
error,
startStream,
abortStream,
resetStream,
};
}
2.2.3 核心设计亮点与踩坑解决方案
-
严格的时序控制:通过requestId标记每一次请求,新请求发起时自动中断上一个请求,同时在数据处理时校验requestId,彻底解决请求乱序问题(用户快速发送多条消息时,后发的消息先返回导致对话错乱)
-
粘包问题处理:通过buffer缓冲区处理TCP粘包,避免半行JSON数据导致的解析错误,这是流式场景90%以上解析异常的根因
-
闭包陷阱规避:所有可变状态都通过useRef管理,避免React闭包陷阱导致的状态不同步问题
-
内存泄漏防护:组件卸载时自动中断请求,清除定时器,避免未完成的请求持续占用资源导致内存泄漏
-
全链路类型安全:通过Zod实现运行时数据校验,避免后端返回异常数据导致的前端崩溃,同时配合TypeScript实现编译时类型安全
-
完善的异常处理:支持超时控制、自动重试、错误回调,异常场景下状态可控,不会出现页面卡死
2.3 流式内容渲染引擎实现
流式内容渲染是AI对话体验的核心,核心挑战是增量内容的无闪烁渲染、Markdown/代码/公式的实时解析、避免频繁重渲染导致的页面卡顿。
2.3.1 增量Markdown渲染方案
传统的Markdown渲染方案是每次内容更新都重新渲染整个文本,会导致三个严重问题:
• 页面频繁闪烁,用户体验极差
• 代码块高亮、公式渲染频繁触发,性能开销极大
• 长文本渲染时,页面卡顿、滚动位置错乱
我们采用增量渲染+组件拆分的方案,基于Remark+Rehype实现,配合React.memo优化重渲染:
// components/chat/stream-markdown.tsx
import { memo, useMemo } from 'react';
import { unified } from 'unified';
import remarkParse from 'remark-parse';
import remarkRehype from 'remark-rehype';
import rehypeStringify from 'rehype-stringify';
import rehypeShiki from '@shikijs/rehype';
import remarkMath from 'remark-math';
import rehypeKatex from 'rehype-katex';
import DOMPurify from 'dompurify';
interface StreamMarkdownProps {
content: string;
isStreaming?: boolean;
}
// 用memo包裹,只有content变化时才重新渲染
const StreamMarkdown = memo(({ content, isStreaming }: StreamMarkdownProps) => {
// 仅当content变化时才重新解析,避免不必要的渲染
const html = useMemo(() => {
// 流式渲染时,处理不完整的Markdown语法,避免解析错误
const processedContent = isStreaming ? handleIncompleteMarkdown(content) : content;
// 统一解析Markdown
const file = unified()
.use(remarkParse) // 解析Markdown
.use(remarkMath) // 支持数学公式
.use(remarkRehype, { allowDangerousHtml: false }) // 转换为HTML AST
.use(rehypeShiki, {
theme: 'github-dark',
langs: ['javascript', 'typescript', 'python', 'java', 'sql', 'json'],
}) // 代码高亮
.use(rehypeKatex) // 渲染数学公式
.use(rehypeStringify) // 转换为HTML字符串
.processSync(processedContent);
// XSS防护,净化HTML内容
return DOMPurify.sanitize(String(file));}, content, isStreaming);
return (
<div
className="prose prose-neutral dark:prose-invert max-w-none break-words"
dangerouslySetInnerHTML={{ __html: html }}
/>
);
});
StreamMarkdown.displayName = 'StreamMarkdown';
// 处理流式渲染中的不完整Markdown语法
function handleIncompleteMarkdown(content: string): string {
let processed = content;
// 处理不完整的代码块:如果有奇数个,补全闭合标签 const codeBlockCount = (processed.match(//g) || \[\]).length;
if (codeBlockCount % 2 !== 0) {
processed += '\n```';
}
// 处理不完整的表格、列表等,可根据需求扩展
return processed;
}
export default StreamMarkdown;
2.3.2 渲染优化核心要点
-
React.memo + useMemo 双重优化:只有当content变化时才重新解析和渲染,避免父组件重渲染导致的Markdown组件重复渲染
-
不完整语法处理:流式渲染中,Markdown语法经常是不完整的(比如代码块只写了一半),通过补全闭合标签,避免解析错误和页面样式错乱
-
XSS防护:通过DOMPurify净化HTML内容,避免大模型返回恶意脚本导致的XSS攻击,这是AI场景极易忽略的安全风险
-
懒加载优化:图片、Mermaid流程图等重资源采用懒加载,避免流式渲染过程中频繁的资源加载导致的页面卡顿
-
滚动优化:配合滚动锚点,实现流式内容更新时,自动平滑滚动到底部,同时支持用户手动滚动时暂停自动滚动,符合用户使用习惯
2.4 对话场景的状态管理优化
对话场景的状态管理核心挑战是高频的流式内容更新导致的全列表重渲染,当对话历史超过100条时,很多前端实现会出现严重的页面卡顿。
我们采用状态分层+组件拆分+不可变更新的方案,基于Zustand实现:
// store/chat-store.ts
import { create } from 'zustand';
import { immer } from 'zustand/middleware/immer';
import { Message } from '@/types/stream';
interface ChatState {
// 会话列表
sessions: Record<string, {
id: string;
title: string;
messages: Message\[\];
createdAt: number;
}>;
// 当前激活的会话ID
activeSessionId: string | null;
// 操作方法
createSession: () => string;
switchSession: (sessionId: string) => void;
addMessage: (sessionId: string, message: Message) => void;
updateMessage: (sessionId: string, messageId: string, updater: (message: Message) => Partial) => void;
deleteMessage: (sessionId: string, messageId: string) => void;
clearSession: (sessionId: string) => void;
}
// 采用immer中间件,实现不可变更新,简化状态修改逻辑
export const useChatStore = create()(
immer((set, get) => ({
sessions: {},
activeSessionId: null,
createSession: () => {
const sessionId = crypto.randomUUID();
set((state) => {
state.sessions[sessionId] = {
id: sessionId,
title: '新对话',
messages: [],
createdAt: Date.now(),
};
state.activeSessionId = sessionId;
});
return sessionId;
},
switchSession: (sessionId) => {
set((state) => {
state.activeSessionId = sessionId;
});
},
addMessage: (sessionId, message) => {
set((state) => {
const session = state.sessions[sessionId];
if (session) {
session.messages.push(message);
// 自动更新会话标题:第一条用户消息作为标题
if (session.messages.length === 1 && message.role === 'user') {
session.title = message.content.slice(0, 30);
}
}
});
},
updateMessage: (sessionId, messageId, updater) => {
set((state) => {
const session = state.sessions[sessionId];
if (!session) return;
const messageIndex = session.messages.findIndex((m) => m.id === messageId);
if (messageIndex === -1) return;
const message = session.messages[messageIndex];
session.messages[messageIndex] = {
...message,
...updater(message),
};
});
},
deleteMessage: (sessionId, messageId) => {
set((state) => {
const session = state.sessions[sessionId];
if (session) {
session.messages = session.messages.filter((m) => m.id !== messageId);
}
});
},
clearSession: (sessionId) => {
set((state) => {
const session = state.sessions[sessionId];
if (session) {
session.messages = [];
}
});
},}))
);
状态管理优化核心要点
-
immer中间件:采用immer实现不可变更新,简化状态修改逻辑,同时保证状态的不可变性,避免意外的状态修改导致的重渲染
-
状态分层设计:将会话列表与当前会话状态分离,避免单个消息的更新导致整个会话列表重渲染
-
细粒度更新:通过updateMessage方法实现单条消息的细粒度更新,只有目标消息会触发重渲染,其他消息完全不受影响
-
组件拆分配合:将单条消息拆分为独立的ChatMessage组件,用memo包裹,只有当消息内容变化时才重渲染,彻底解决全列表重渲染问题
// components/chat/chat-message.tsx
import { memo } from 'react';
import { Message, MessageRole } from '@/types/stream';
import StreamMarkdown from './stream-markdown';
import { User, Bot } from 'lucide-react';
interface ChatMessageProps {
message: Message;
isStreaming?: boolean;
}
// memo包裹,只有message变化时才重渲染
const ChatMessage = memo(({ message, isStreaming }: ChatMessageProps) => {
const isUser = message.role === MessageRole.USER;
return (
<div className={flex gap-4 py-6 w-full ${isUser ? 'justify-end' : 'justify-start'}}>
{!isUser && (
)}
<div className={`max-w-[85%] rounded-2xl px-4 py-3 ${
isUser ? 'bg-primary text-white' : 'bg-muted'
}`}>
{isUser ? (
<p className="whitespace-pre-wrap break-words">{message.content}</p>
) : (
<StreamMarkdown
content={message.content}
isStreaming={isStreaming && message.status === 'streaming'}
/>
)}
</div>
{isUser && (
<div className="w-8 h-8 rounded-full bg-neutral-200 flex items-center justify-center flex-shrink-0">
<User className="w-5 h-5 text-neutral-700" />
</div>
)}
</div>);
});
ChatMessage.displayName = 'ChatMessage';
export default ChatMessage;
三、核心实践二:RAG场景的前端架构设计与组件化落地
RAG(检索增强生成)不是后端的专属工作,前端在RAG场景中承担着文档管理、分块可视化、引用溯源、检索交互四大核心职责,是RAG系统用户体验的核心抓手。本章节将完整拆解企业级RAG前端的架构设计与组件化落地。
3.1 RAG前端的整体架构设计
RAG前端的核心目标是让用户对RAG的检索过程有可控性、可感知性、可追溯性,解决「黑盒检索」导致的用户不信任、幻觉无法定位等问题,整体架构分为四大模块:
flowchart LR
A文档管理模块 --> B分块可视化模块
B --> C引用溯源模块
C --> D检索交互模块
A & B & C & D --> ERAG核心能力Hook
E --> F后端RAG服务
3.2 核心模块一:大文件分片上传与文档管理
RAG场景的核心痛点之一是大文档(GB级)的上传、断点续传、进度管理,传统的单文件上传方案完全无法适配,我们采用分片上传+WebWorker计算文件Hash+断点续传的生产级方案。
3.2.1 分片上传核心Hook实现
// hooks/use-chunk-upload.ts
import { useState, useRef, useCallback } from 'react';
import SparkMD5 from 'spark-md5';
interface ChunkUploadOptions {
apiUrl: string;
chunkSize?: number; // 分片大小,默认2MB
maxConcurrency?: number; // 最大并发数,默认3
onProgress?: (progress: number) => void; // 上传进度回调
onComplete?: (fileUrl: string, fileId: string) => void; // 上传完成回调
onError?: (error: { code: string; message: string }) => void; // 错误回调
}
// 分片状态枚举
enum ChunkStatus {
PENDING = 'pending',
UPLOADING = 'uploading',
SUCCESS = 'success',
ERROR = 'error',
}
// 分片类型
interface Chunk {
index: number;
start: number;
end: number;
blob: Blob;
hash: string;
status: ChunkStatus;
}
export function useChunkUpload(options: ChunkUploadOptions) {
const {
apiUrl,
chunkSize = 2 * 1024 * 1024, // 2MB
maxConcurrency = 3,
onProgress,
onComplete,
onError,
} = options;
const isUploading, setIsUploading = useState(false);
const progress, setProgress = useState(0);
const abortControllerRef = useRef<AbortController | null>(null);
const isAbortedRef = useRef(false);
// 中断上传
const abortUpload = useCallback(() => {
if (abortControllerRef.current) {
abortControllerRef.current.abort();
abortControllerRef.current = null;
}
isAbortedRef.current = true;
setIsUploading(false);
}, \[\]);
// 计算文件MD5,使用WebWorker避免阻塞主线程
const calculateFileMD5 = useCallback((file: File): Promise => {
return new Promise((resolve, reject) => {
const blobSlice = File.prototype.slice;
const chunks = Math.ceil(file.size / chunkSize);
const spark = new SparkMD5.ArrayBuffer();
let currentChunk = 0;
const fileReader = new FileReader();
fileReader.onload = (e) => {
if (isAbortedRef.current) {
reject(new Error('上传已中断'));
return;
}
spark.append(e.target?.result as ArrayBuffer);
currentChunk++;
if (currentChunk < chunks) {
loadNext();
} else {
resolve(spark.end());
}
};
fileReader.onerror = () => {
reject(fileReader.error);
};
const loadNext = () => {
const start = currentChunk * chunkSize;
const end = Math.min(start + chunkSize, file.size);
fileReader.readAsArrayBuffer(blobSlice.call(file, start, end));
};
loadNext();
});}, chunkSize);
// 核心上传方法
const uploadFile = useCallback(async (file: File, knowledgeBaseId: string) => {
if (isUploading) return;
setIsUploading(true);
setProgress(0);
isAbortedRef.current = false;
abortControllerRef.current = new AbortController();
try {
// 1. 计算文件MD5,用于断点续传和文件唯一性校验
const fileMD5 = await calculateFileMD5(file);
if (isAbortedRef.current) return;
// 2. 检查文件是否已上传,实现断点续传
const checkResponse = await fetch(`${apiUrl}/check`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ fileMD5, fileName: file.name, fileSize: file.size, knowledgeBaseId }),
signal: abortControllerRef.current.signal,
});
if (!checkResponse.ok) {
throw new Error('文件校验失败');
}
const checkData = await checkResponse.json();
const { isExist, uploadedChunks, fileId, fileUrl } = checkData;
// 文件已存在,直接返回
if (isExist) {
setProgress(100);
onComplete?.(fileUrl, fileId);
setIsUploading(false);
return;
}
// 3. 生成文件分片
const totalChunks = Math.ceil(file.size / chunkSize);
const chunks: Chunk[] = [];
for (let i = 0; i < totalChunks; i++) {
const start = i * chunkSize;
const end = Math.min(start + chunkSize, file.size);
const blob = file.slice(start, end);
chunks.push({
index: i,
start,
end,
blob,
hash: `${fileMD5}-${i}`,
status: uploadedChunks.includes(i) ? ChunkStatus.SUCCESS : ChunkStatus.PENDING,
});
}
// 4. 并发上传分片,控制并发数
const successCount = uploadedChunks.length;
let completedCount = successCount;
const pendingChunks = chunks.filter((c) => c.status === ChunkStatus.PENDING);
// 并发控制函数
const uploadChunksWithConcurrency = async () => {
const pool: Promise<void>[] = [];
for (const chunk of pendingChunks) {
if (isAbortedRef.current) return;
chunk.status = ChunkStatus.UPLOADING;
const uploadPromise = async () => {
const formData = new FormData();
formData.append('fileId', fileId);
formData.append('chunkIndex', chunk.index.toString());
formData.append('chunkHash', chunk.hash);
formData.append('chunk', chunk.blob);
try {
const response = await fetch(`${apiUrl}/chunk`, {
method: 'POST',
body: formData,
signal: abortControllerRef.current?.signal,
});
if (!response.ok) {
throw new Error(`分片${chunk.index}上传失败`);
}
chunk.status = ChunkStatus.SUCCESS;
completedCount++;
const currentProgress = Math.floor((completedCount / totalChunks) * 100);
setProgress(currentProgress);
onProgress?.(currentProgress);
} catch (err) {
if (err.name === 'AbortError') return;
chunk.status = ChunkStatus.ERROR;
throw err;
}
};
const p = uploadPromise();
pool.push(p);
// 达到最大并发数,等待其中一个完成
if (pool.length >= maxConcurrency) {
await Promise.race(pool);
// 移除已完成的Promise
pool.splice(pool.findIndex((item) => item === p), 1);
}
}
// 等待所有分片上传完成
await Promise.all(pool);
};
await uploadChunksWithConcurrency();
if (isAbortedRef.current) return;
// 5. 通知后端合并分片
const mergeResponse = await fetch(`${apiUrl}/merge`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ fileId, fileMD5, fileName: file.name, totalChunks }),
signal: abortControllerRef.current.signal,
});
if (!mergeResponse.ok) {
throw new Error('文件合并失败');
}
const mergeData = await mergeResponse.json();
setProgress(100);
onComplete?.(mergeData.fileUrl, mergeData.fileId);
} catch (err: any) {
if (err.name === 'AbortError') return;
const uploadError = {
code: err.code || 'UPLOAD_ERROR',
message: err.message || '文件上传失败',
};
setError(uploadError);
onError?.(uploadError);
} finally {
setIsUploading(false);
abortControllerRef.current = null;
}}, apiUrl, chunkSize, maxConcurrency, calculateFileMD5, onProgress, onComplete, onError);
return {
isUploading,
progress,
uploadFile,
abortUpload,
};
}
3.2.2 核心设计亮点
-
分片并发控制:通过Promise池实现并发数控制,避免大量分片同时上传导致的浏览器内存溢出、网络阻塞
-
断点续传:通过文件MD5校验已上传的分片,网络中断后无需重新上传整个文件,仅上传未完成的分片,极大提升大文件上传体验
-
主线程无阻塞:文件MD5计算采用增量计算,避免大文件计算时阻塞主线程导致页面卡顿
-
全流程状态管理:分片级别的状态管理,可实时展示每个分片的上传状态,支持失败重传
-
可中断设计:支持随时中断上传,释放网络资源,避免无效的上传请求
3.3 核心模块二:引用溯源与分块可视化
RAG系统的核心痛点是大模型幻觉无法定位、引用来源不可追溯,前端需要实现「引用标记解析→点击溯源→分块内容可视化→原文定位」的全链路闭环。
3.3.1 引用溯源组件实现
// components/rag/reference-trace.tsx
import { memo, useState } from 'react';
import { Popover, PopoverContent, PopoverTrigger } from '@/components/ui/popover';
import { Button } from '@/components/ui/button';
import { DocumentTextIcon } from '@/components/ui/icons';
import { useDocumentChunk } from '@/hooks/use-document-chunk';
interface ReferenceTraceProps {
referenceIds: string\[\];
}
const ReferenceTrace = memo(({ referenceIds }: ReferenceTraceProps) => {
const activeReferenceId, setActiveReferenceId = useState<string | null>(null);
const { chunkMap, isLoading } = useDocumentChunk(referenceIds);
if (!referenceIds.length || isLoading) return null;
return (
引用来源:
{referenceIds.map((referenceId, index) => {
const chunk = chunkMapreferenceId;
if (!chunk) return null;
return (
<Popover key={referenceId}>
<PopoverTrigger asChild>
<Button
variant="outline"
size="sm"
className="h-6 px-2 text-xs rounded-full"
onClick={() => setActiveReferenceId(referenceId)}
>
<DocumentTextIcon className="w-3 h-3 mr-1" />
[{index + 1}] {chunk.documentName}
</Button>
</PopoverTrigger>
<PopoverContent className="w-[400px] max-h-[300px] overflow-y-auto">
<div className="space-y-2">
<div className="flex justify-between items-center">
<h4 className="text-sm font-medium">引用片段 [{index + 1}]</h4>
<span className="text-xs text-muted-foreground">
第{chunk.chunkIndex}块
</span>
</div>
<div className="p-3 bg-muted rounded-md text-sm">
<p className="whitespace-pre-wrap break-words">{chunk.content}</p>
</div>
<Button
variant="ghost"
size="sm"
className="w-full text-xs"
onClick={() => {
// 跳转到文档详情页,定位到对应分块
window.open(`/documents/${chunk.documentId}?chunkIndex=${chunk.chunkIndex}`, '_blank');
}}
>
查看原文
</Button>
</div>
</PopoverContent>
</Popover>
);
})}
</div>);
});
ReferenceTrace.displayName = 'ReferenceTrace';
export default ReferenceTrace;
3.3.2 文档分块可视化组件
用于文档详情页,展示文档的分块结果、向量信息、检索命中情况,让用户对RAG的分块逻辑有完全的可控性:
// components/rag/document-chunk-list.tsx
import { memo, useState } from 'react';
import { useDocumentChunks } from '@/hooks/use-document-chunks';
import { Card, CardContent, CardHeader, CardTitle } from '@/components/ui/card';
import { Badge } from '@/components/ui/badge';
import { Input } from '@/components/ui/input';
import { Search } from 'lucide-react';
interface DocumentChunkListProps {
documentId: string;
highlightChunkIndex?: number;
}
const DocumentChunkList = memo(({ documentId, highlightChunkIndex }: DocumentChunkListProps) => {
const searchKeyword, setSearchKeyword = useState('');
const { chunks, isLoading } = useDocumentChunks(documentId);
const filteredChunks = chunks.filter((chunk) =>
chunk.content.toLowerCase().includes(searchKeyword.toLowerCase())
);
if (isLoading) return
加载中...
;
return (
<Input
placeholder="搜索分块内容"
className="pl-10"
value={searchKeyword}
onChange={(e) => setSearchKeyword(e.target.value)}
/>
{chunks.length} 个分块
<div className="space-y-3">
{filteredChunks.map((chunk) => {
const isHighlighted = chunk.chunkIndex === highlightChunkIndex;
return (
<Card
key={chunk.id}
className={`border ${isHighlighted ? 'border-primary ring-2 ring-primary/20' : 'border-border'}`}
>
<CardHeader className="py-3 px-4">
<CardTitle className="text-sm flex justify-between items-center">
<span>第 {chunk.chunkIndex} 块</span>
<div className="flex gap-2">
<Badge variant="secondary">{chunk.tokens} Tokens</Badge>
<Badge variant="secondary">{chunk.characters} 字符</Badge>
</div>
</CardTitle>
</CardHeader>
<CardContent className="py-3 px-4">
<p className="text-sm whitespace-pre-wrap break-words text-muted-foreground">
{chunk.content}
</p>
</CardContent>
</Card>
);
})}
</div>
</div>);
});
DocumentChunkList.displayName = 'DocumentChunkList';
export default DocumentChunkList;
四、核心实践三:端侧AI工程化落地与性能优化
端侧AI是AI原生前端的进阶核心能力,通过WebGPU/ONNX Runtime Web/Transformers.js,在浏览器端实现AI模型的推理,可实现端侧Embedding、本地语义检索、内容重排、轻量大模型推理等能力,大幅降低后端算力成本,提升用户隐私性与响应速度。
4.1 端侧AI技术栈选型
2026年生产级端侧AI技术栈选型如下:
技术方案 适用场景 核心优势
Transformers.js 端侧Embedding、轻量大模型推理、文本分类 与Hugging Face生态完全兼容,模型加载简单,支持WebGPU加速
ONNX Runtime Web 端侧重排模型、图像模型、高精度推理 性能优异,模型体积小,支持量化模型,跨平台兼容性好
WebLLM 端侧大模型部署、本地对话 专为浏览器端大模型推理优化,支持多种开源模型
本文基于Transformers.js实现端侧Embedding,这是RAG场景最常用、落地成本最低的端侧AI能力。
4.2 端侧Embedding完整落地实现
端侧Embedding的核心价值是:
• 隐私保护:用户的文档、提问内容无需传输到后端,在浏览器端完成向量化
• 降低成本:无需调用后端Embedding API,大幅降低API调用成本
• 提升响应速度:本地向量化延迟<10ms,远低于API调用的数百ms延迟
• 离线可用:支持离线场景下的本地语义检索
4.2.1 端侧Embedding核心Hook实现
// hooks/use-local-embedding.ts
import { useState, useRef, useCallback, useEffect } from 'react';
import { pipeline, env } from '@xenova/transformers';
// 配置Transformers.js,优先使用WebGPU
env.backends.onnx.wasm.proxy = false;
env.backends.onnx.preferredBackend = 'webgpu';
env.allowLocalModels = false;
env.useBrowserCache = true; // 开启浏览器缓存,避免重复下载模型
// 模型选型:gte-small,6层Transformer,384维向量,体积小,速度快,效果优异
const DEFAULT_MODEL = 'Xenova/gte-small';
const EMBEDDING_DIMENSION = 384;
type EmbeddingPipeline = Awaited<ReturnType<typeof pipeline<'feature-extraction'>>>;
interface UseLocalEmbeddingOptions {
modelId?: string;
onLoadProgress?: (progress: number) => void;
onLoadComplete?: () => void;
onError?: (error: Error) => void;
}
export function useLocalEmbedding(options: UseLocalEmbeddingOptions = {}) {
const {
modelId = DEFAULT_MODEL,
onLoadProgress,
onLoadComplete,
onError,
} = options;
const isLoading, setIsLoading = useState(false);
const isReady, setIsReady = useState(false);
const progress, setProgress = useState(0);
const error, setError = useState<Error | null>(null);
const pipelineRef = useRef<EmbeddingPipeline | null>(null);
// 加载模型
const loadModel = useCallback(async () => {
if (pipelineRef.current) return;
setIsLoading(true);
setError(null);
setProgress(0);
try {
const embeddingPipeline = await pipeline('feature-extraction', modelId, {
progress_callback: (progress) => {
// 处理加载进度
if (progress.status === 'download') {
const loadedProgress = Math.floor((progress.loaded / progress.total) * 100);
setProgress(loadedProgress);
onLoadProgress?.(loadedProgress);
}
},
});
pipelineRef.current = embeddingPipeline;
setIsReady(true);
setIsLoading(false);
setProgress(100);
onLoadComplete?.();
} catch (err: any) {
const loadError = new Error(`模型加载失败:${err.message}`);
setError(loadError);
setIsLoading(false);
onError?.(loadError);
}}, modelId, onLoadProgress, onLoadComplete, onError);
// 生成文本Embedding
const generateEmbedding = useCallback(
async (text: string): Promise<number\[\]> => {
if (!pipelineRef.current) {
throw new Error('Embedding模型未加载完成');
}
// 文本预处理
const processedText = text.replace(/\n/g, ' ').trim();
if (!processedText) {
return new Array(EMBEDDING_DIMENSION).fill(0);
}
// 生成Embedding
const output = await pipelineRef.current(processedText, {
pooling: 'mean', // 均值池化,得到句子级向量
normalize: true, // 归一化,余弦相似度计算更准确
});
// 转换为普通数组
return Array.from(output.data);
},
[]);
// 批量生成Embedding
const generateBatchEmbeddings = useCallback(
async (texts: string\[\]): Promise<number\[\]\[\]> => {
const embeddings: number\[\]\[\] = \[\];
for (const text of texts) {
const embedding = await generateEmbedding(text);
embeddings.push(embedding);
}
return embeddings;
},
generateEmbedding
);
// 计算两个向量的余弦相似度
const cosineSimilarity = useCallback((vecA: number\[\], vecB: number\[\]): number => {
if (vecA.length !== vecB.length) return 0;
let dotProduct = 0;
let normA = 0;
let normB = 0;
for (let i = 0; i < vecA.length; i++) {
dotProduct += vecA[i] * vecB[i];
normA += vecA[i] ** 2;
normB += vecB[i] ** 2;
}
if (normA === 0 || normB === 0) return 0;
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));}, \[\]);
// 本地语义检索
const localSemanticSearch = useCallback(
async (query: string, documents: { id: string; content: string }\[\], topK = 5) => {
// 生成查询向量
const queryEmbedding = await generateEmbedding(query);
// 生成文档向量并计算相似度
const results = await Promise.all(
documents.map(async (doc) => {
const docEmbedding = await generateEmbedding(doc.content);
const similarity = cosineSimilarity(queryEmbedding, docEmbedding);
return {
id: doc.id,
content: doc.content,
similarity,
};
})
);
// 按相似度排序,返回Top-K结果
return results.sort((a, b) => b.similarity - a.similarity).slice(0, topK);
},
[generateEmbedding, cosineSimilarity]);
// 组件卸载时释放模型资源
useEffect(() => {
return () => {
if (pipelineRef.current) {
pipelineRef.current.dispose();
pipelineRef.current = null;
}
};
}, \[\]);
return {
isLoading,
isReady,
progress,
error,
loadModel,
generateEmbedding,
generateBatchEmbeddings,
cosineSimilarity,
localSemanticSearch,
};
}
4.2.2 核心设计亮点与优化方案
-
WebGPU优先:优先使用WebGPU加速推理,性能比CPU推理提升10倍以上,同时兼容CPU fallback
-
浏览器缓存:开启浏览器缓存,模型仅需下载一次,后续加载直接从缓存读取,避免重复下载
-
WebWorker隔离:实际生产环境中,可将模型推理逻辑放入WebWorker中,避免阻塞主线程,保证页面流畅度
-
模型量化:使用INT8量化模型,模型体积缩小4倍,推理速度大幅提升,精度损失极小
-
内存管理:组件卸载时自动释放模型资源,避免内存泄漏,长时间使用页面不会卡顿
4.3 端侧AI落地的核心踩坑与解决方案
- WebGPU兼容性问题
◦ 现象:部分浏览器(尤其是老旧版本)不支持WebGPU,模型加载失败
◦ 解决方案:实现WebGPU可用性检测,不支持时自动降级到WASM后端,同时提示用户升级浏览器
// WebGPU可用性检测
export async function isWebGPUAvailable(): Promise {
if (!navigator.gpu) return false;
try {
const adapter = await navigator.gpu.requestAdapter();
return !!adapter;
} catch {
return false;
}
}
- 模型加载时主线程阻塞
◦ 现象:模型加载和初始化时,页面卡顿、无响应
◦ 解决方案:将模型加载和推理逻辑完全放入WebWorker中,通过postMessage与主线程通信,彻底避免主线程阻塞
- 内存泄漏问题
◦ 现象:多次加载模型、频繁推理后,页面内存占用持续升高,最终崩溃
◦ 解决方案:每次推理完成后及时释放张量资源,组件卸载时调用dispose()方法释放整个Pipeline,避免内存泄漏
- 模型体积过大,下载缓慢
◦ 现象:大模型体积数百MB,用户首次加载等待时间过长
◦ 解决方案:
◦ 选择轻量模型:优先选择gte-small、bge-small等轻量Embedding模型,体积仅几十MB
◦ 模型量化:使用INT8/INT4量化模型,大幅缩小体积
◦ 分片加载:模型分片下载,支持断点续传,显示加载进度
◦ 预加载:在用户空闲时预加载模型,提升使用时的体验
五、核心实践四:AI前端全链路性能优化与体验治理
AI前端的性能优化与传统前端有本质区别,核心优化目标从「首屏加载速度」转向「全链路交互体验」,本章节将系统拆解AI前端的核心性能指标与优化方案。
5.1 AI前端核心性能指标定义
我们先定义AI场景的四大核心性能指标,所有优化都围绕这些指标展开:
指标名称 定义 优秀标准 优化优先级
首Token延迟 用户发送消息到收到第一个Token的时间 <300ms 最高
Token生成帧率 每秒生成的Token数量,对应页面更新频率 >20 Token/s 高
对话页面交互延迟 用户点击、输入、滚动的响应延迟 <100ms 高
内存占用 长时间使用后的页面内存占用 <500MB 中
5.2 核心优化一:首Token延迟极致优化
首Token延迟是AI对话体验的核心,80%的用户体验由首Token延迟决定,优化方案如下:
- Edge Runtime部署API
◦ 优化逻辑:将AI对话API部署在Edge Runtime中,就近接入用户,减少网络跳转延迟,相比传统的Node.js服务,首Token延迟可降低50%以上
◦ 实现方案:Next.js的Edge API Routes,默认部署在全球边缘节点,代码示例:
// app/api/chat/route.ts
export const runtime = 'edge'; // 启用Edge Runtime
export const dynamic = 'force-dynamic';
export async function POST(req: Request) {
const params = await req.json();
// 直接调用大模型API,流式返回
const response = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers: {
'Authorization': Bearer ${process.env.OPENAI_API_KEY},
'Content-Type': 'application/json',
},
body: JSON.stringify({
...params,
stream: true,
}),
});
return new Response(response.body, {
headers: {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
},
});
}
- 精简Prompt,减少上下文长度
◦ 优化逻辑:大模型的首Token延迟与Prompt长度正相关,上下文越长,首Token延迟越高
◦ 优化方案:
◦ 精简系统Prompt,去除冗余的描述,仅保留核心规则
◦ 控制对话历史长度,仅保留最近的5-10轮对话
◦ 控制RAG引用的上下文长度,仅保留Top-3最相关的文档片段
- 连接复用与预热
◦ 优化逻辑:复用HTTP/2连接,避免每次请求都重新建立TCP连接和TLS握手,可减少100-300ms的延迟
◦ 优化方案:
◦ 开启HTTP/2多路复用,复用与大模型API的连接
◦ 页面加载完成后,提前建立与API服务的连接,预热连接池
◦ 启用TCP Fast Open,减少TCP握手次数
- 模型路由降级
◦ 优化逻辑:高延迟的复杂模型,在峰值时段自动降级到低延迟的轻量模型,保障首Token延迟稳定
◦ 优化方案:实现智能模型路由,简单问答使用轻量模型,复杂推理使用高能力模型,平衡延迟与效果
5.3 核心优化二:流式渲染流畅度优化
流式渲染的流畅度直接决定用户的对话体验,核心优化方案如下:
- 避免全量重渲染
◦ 优化逻辑:每收到一个Token就重新渲染整个对话列表,是页面卡顿的核心原因
◦ 优化方案:
◦ 拆分组件,单条消息用memo包裹,仅更新当前流式消息
◦ 使用不可变数据结构,仅修改当前消息的内容,避免其他消息重渲染
◦ 使用useCallback缓存事件处理函数,避免函数引用变化导致的重渲染
- 渲染节流优化
◦ 优化逻辑:Token生成速度过快时,每秒触发数十次状态更新,导致React频繁重渲染,页面卡顿
◦ 优化方案:使用requestAnimationFrame实现渲染节流,将多次状态更新合并到单次帧渲染中,保证页面帧率稳定在60fps
// 节流更新流式内容
export function useThrottledContentUpdate(initialContent: string) {
const content, setContent = useState(initialContent);
const contentBufferRef = useRef(initialContent);
const animationFrameRef = useRef<number | null>(null);
const updateContent = useCallback((newContent: string) => {
contentBufferRef.current = newContent;
if (animationFrameRef.current) {
cancelAnimationFrame(animationFrameRef.current);
}
animationFrameRef.current = requestAnimationFrame(() => {
setContent(contentBufferRef.current);
animationFrameRef.current = null;
});}, \[\]);
useEffect(() => {
return () => {
if (animationFrameRef.current) {
cancelAnimationFrame(animationFrameRef.current);
}
};
}, \[\]);
return {
content,
updateContent,
};
}
- Markdown解析优化
◦ 优化逻辑:频繁的Markdown解析是性能开销的主要来源
◦ 优化方案:
◦ 流式渲染时,仅当内容发生实质性变化时才重新解析
◦ 代码块、公式等重资源,等到语法闭合后再解析,避免重复解析
◦ 使用WebWorker解析Markdown,避免阻塞主线程
5.4 核心优化三:大对话场景性能优化
当对话历史超过100条时,页面会出现严重的卡顿、滚动不流畅、内存占用过高等问题,核心优化方案如下:
- 虚拟滚动实现
◦ 优化逻辑:渲染所有历史消息会导致DOM节点过多,页面卡顿,虚拟滚动仅渲染可视区域内的消息,DOM节点数量恒定,不受对话历史长度影响
◦ 实现方案:使用react-virtual实现虚拟滚动,代码示例:
// components/chat/chat-message-list.tsx
import { useRef, useEffect } from 'react';
import { useVirtual } from 'react-virtual';
import ChatMessage from './chat-message';
import { Message } from '@/types/stream';
interface ChatMessageListProps {
messages: Message\[\];
isStreaming: boolean;
}
export default function ChatMessageList({ messages, isStreaming }: ChatMessageListProps) {
const parentRef = useRef(null);
const scrollRef = useRef(null);
// 虚拟滚动配置
const rowVirtualizer = useVirtual({
size: messages.length,
parentRef,
estimateSize: useCallback(() => 100, \[\]), // 预估每条消息的高度
overscan: 5, // 可视区域外预渲染的条数
});
// 自动滚动到底部
useEffect(() => {
if (scrollRef.current) {
scrollRef.current.scrollIntoView({ behavior: 'smooth' });
}
}, messages.length, isStreaming);
return (
<div
className="w-full relative"
style={{ height: ${rowVirtualizer.totalSize}px }}
>
{rowVirtualizer.virtualItems.map((virtualRow) => {
const message = messagesvirtualRow.index;
return (
<div
key={message.id}
className="absolute top-0 left-0 w-full px-4"
style={{
transform: translateY(${virtualRow.start}px),
}}
ref={virtualRow.measureRef}
>
<ChatMessage
message={message}
isStreaming={isStreaming && virtualRow.index === messages.length - 1}
/>
);
})}
);
}
2. 懒加载历史消息
◦ 优化逻辑:进入对话页面时,仅加载最近的20条消息,用户向上滚动时,再懒加载更早的历史消息,减少初始渲染开销
◦ 实现方案:配合Intersection Observer实现滚动触底(顶部)加载,分页查询历史消息
- 内存泄漏治理
◦ 常见内存泄漏场景与解决方案:
泄漏场景 解决方案
SSE连接未关闭,页面切换后持续接收数据 组件卸载时调用abort()中断连接,清除事件监听器
大对象(消息列表、文件数据)未释放 切换会话时,清空无用的大对象,解除引用
定时器未清除 组件卸载时清除所有定时器,使用useRef管理定时器引用
事件监听器未移除 组件卸载时移除所有全局事件监听器,使用useEffect的清理函数
5.5 核心优化四:首屏加载性能优化
AI前端应用通常包体积较大,首屏加载速度慢,核心优化方案如下:
-
代码分割与懒加载:使用Next.js的动态导入,将非首屏组件、重依赖库(如Markdown渲染、端侧AI模型)懒加载,减少首屏JS包体积
-
Tree Shaking:开启生产环境Tree Shaking,移除未使用的代码,减少包体积
-
静态资源优化:图片、字体等静态资源使用Next.js的Image、Font组件优化,自动压缩、格式转换、预加载
-
预加载关键资源:预加载首屏关键JS、CSS资源,减少首屏等待时间
-
Streaming SSR:使用Next.js的Streaming SSR,首屏内容流式渲染,减少白屏时间
六、核心实践五:工程化体系与安全防护
企业级AI前端应用必须有完善的工程化体系与安全防护,保障代码质量、系统稳定与数据安全。
6.1 全链路TypeScript类型安全体系
我们实现了从API请求到状态管理、组件属性、AI响应的全链路类型安全,核心方案:
-
前后端类型共享:使用Monorepo架构,前后端共享TypeScript类型定义,避免类型不一致
-
运行时类型校验:使用Zod实现API响应、流式数据的运行时校验,避免后端返回异常数据导致的前端崩溃
-
类型覆盖度监控:使用TypeScript的--noImplicitAny严格模式,配合ESLint规则,保证类型覆盖度100%