基于 ComfyUI 工作流学习 AnimateDiff:单图生成视频的入门实践与问题分析
一、前言
AnimateDiff 是当前基于扩散模型实现图像动态化的重要方案之一,在 ComfyUI 生态中也已经形成了较为成熟的接入方式。对于初学者而言,单图生成视频是理解 AnimateDiff 工作机制的一个合适入口。
与文生图任务相比,图生视频不仅关注画面内容本身,还需要额外处理时间维度上的连续性问题,包括:
- 人物主体是否稳定
- 背景是否保持一致
- 帧间是否出现明显抖动或闪烁
- 动态是否自然、是否符合预期
因此,在 AnimateDiff 的学习阶段,首先建立"最小可运行工作流",再逐步观察和分析稳定性问题,比直接追求复杂动作生成更具实践价值。
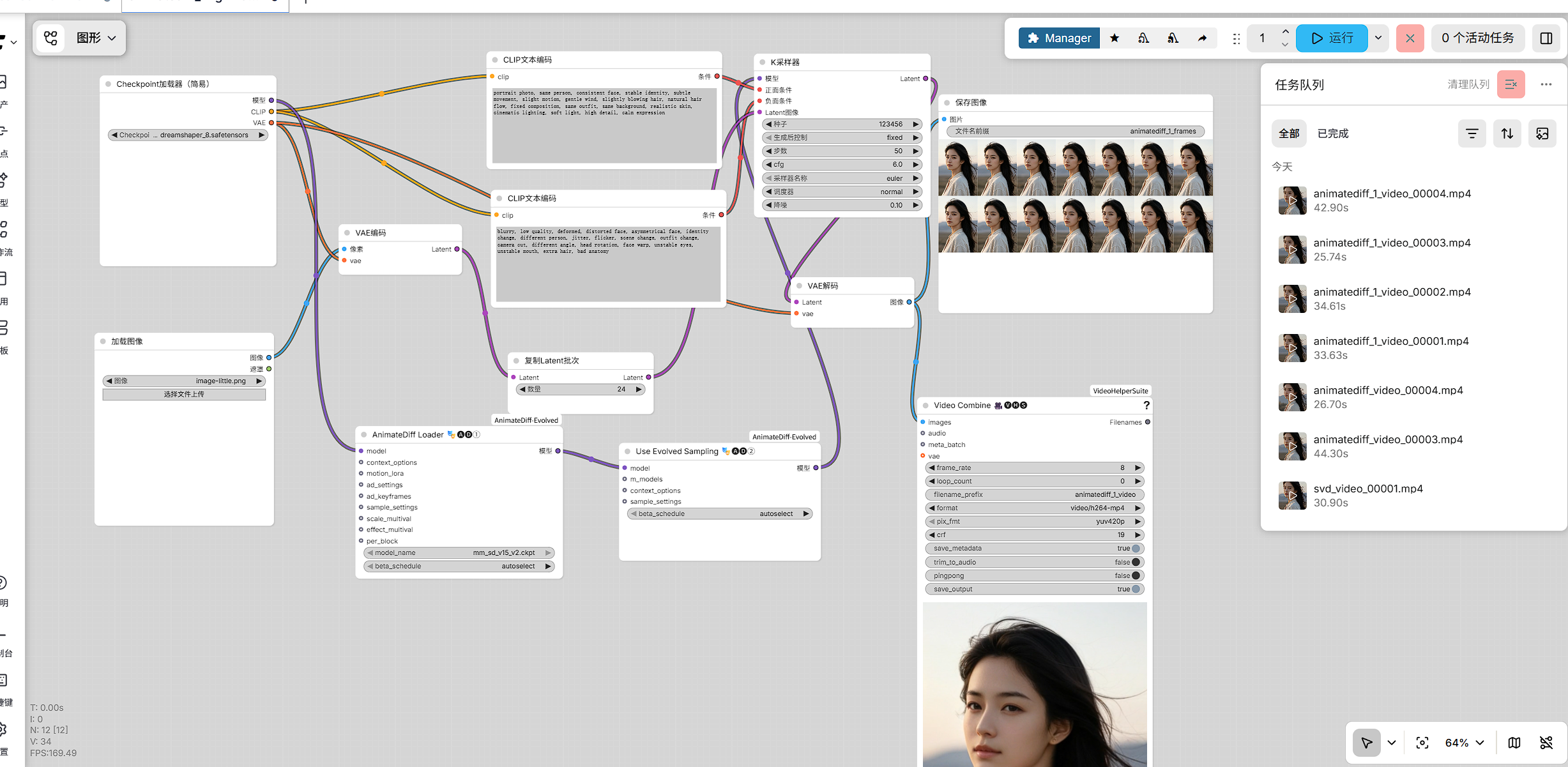
工作流截图
视频截图

视频播放网站
哔哩哔哩
二、当前工作流的目标
该工作流的核心目标如下:
- 输入一张静态图片
- 基于 AnimateDiff 生成连续视频帧
- 尽量保持人物、服装、背景与构图稳定
- 输出可直接播放的 mp4 视频
从定位上看,这类工作流更适合以下任务:
- 静态图动态化
- 角色展示类短视频
- 写真图轻动态增强
- 插画、海报、立绘的动态处理
- AI 图像转视频的基础实验
需要强调的是,该工作流的重点并不在于生成复杂表演动作,而在于为静态图增加可接受的动态感。
三、工作流核心结构分析
从现有工作流配置可以看出,视频生成链路中涉及的关键节点主要包括:
ADE_AnimateDiffLoaderGen1ADE_UseEvolvedSamplingCLIPTextEncodeVAEDecodeSaveImageVHS_VideoCombine
1. AnimateDiff 运动模块加载
工作流通过 ADE_AnimateDiffLoaderGen1 节点接入 AnimateDiff,其节点配置中使用的运动模块为:
mm_sd_v15_v2.ckpt
该模块的作用是在原有扩散生成链路中引入时间维度上的变化能力,使模型能够从单张静态图出发,生成具有跨帧连续性的动态序列。
2. 采样方式
工作流中使用了 ADE_UseEvolvedSampling 节点 。
这表明视频并非由单张图简单重复构成,而是通过 AnimateDiff 的运动建模参与采样过程,在潜空间中形成连续变化,从而输出一组具有时序相关性的图像帧。
3. 输出方式
工作流最终存在两类输出:
- 逐帧图像保存
- 合成视频输出
其中,视频输出名称为 animatediff_video,输出格式为 video/h264-mp4 。
这种设计有利于同时进行两类检查:
- 逐帧检查:观察局部是否抖动、变形、闪烁
- 整体播放检查:观察动态是否自然、连贯
对于 AnimateDiff 的学习与调试而言,这是较为实用的输出方式。
四、提示词设计思路
在 AnimateDiff 工作流中,提示词不仅影响静态画面风格,也会影响动态倾向与时序稳定性。
当前工作流在提示词设计上采取了"先稳定、后动态"的策略。
4.1 正向提示词
当前正向提示词为:
slight motion, subtle movement, wind blowing hair, stable composition, same outfit, same background, cinematic lighting
这组提示词具有较明确的控制目标:
slight motion:控制整体运动幅度偏小subtle movement:进一步强调细微动态wind blowing hair:引导头发区域可能出现轻微摆动stable composition:尽量保持构图不变same outfit:约束服装一致性same background:约束背景稳定性cinematic lighting:增强光影表现与观感
这类提示词适合作为入门阶段的默认模板,因为视频生成中的首要问题通常不是"动作是否足够大",而是"画面是否足够稳定"。
4.2 反向提示词
当前反向提示词为:
blurry, low quality, deformed, jitter, flicker, scene change, outfit change, camera cut, different angle
这组反向词主要用于抑制视频生成中的常见异常现象:
- 模糊
- 低质量
- 结构变形
- 画面抖动
- 帧间闪烁
- 场景跳变
- 服装变化
- 镜头切换感
- 视角偏移
可以看出,该工作流的设计目标非常明确,即优先保证时序一致性与主体稳定性。
五、该工作流适合学习 AnimateDiff 的原因
1. 工作流结构完整,便于理解整体链路
当前流程已经覆盖了:
- 图像输入
- 文本条件编码
- AnimateDiff 模块加载
- 采样
- 解码
- 帧图保存
- 视频导出
这构成了一个典型的单图转视频最小闭环 。
对于学习阶段而言,能够先完整理解这一闭环,比直接叠加更多控制器更有意义。
2. 能够清晰体现 AnimateDiff 的核心作用
通过该工作流可以较容易建立一个关键认知:
AnimateDiff 的核心价值并不在于重新决定"画什么",而在于补充"如何在时间维度上变化"。
也就是说,基础模型与提示词主要负责画面内容与风格,而 AnimateDiff 则重点参与跨帧动态建模。
3. 适合观察视频稳定性问题
由于正向与反向提示词都在强调稳定性 ,因此该工作流特别适合用于观察如下问题:
- 人物身份是否稳定
- 脸部是否漂移
- 背景是否发生变化
- 服装是否一致
- 帧间是否存在闪烁和抖动
这些问题构成了 AnimateDiff 入门阶段最重要的评估维度。
六、当前工作流可实现的效果
从当前生成结果的类型来看,该工作流更适合实现"整体轻微动态",而不是幅度较大的复杂动作。
1. 整体画面获得轻微生命感
生成结果通常会呈现出以下特征:
- 人物存在轻微呼吸感
- 姿态有细小变化
- 画面不再完全静止
这类变化虽然幅度有限,但对于静态图来说,已经能够明显增强动态观感。
2. 发丝与边缘细节可能出现轻微变化
在 wind blowing hair 的提示引导下 ,部分结果中会出现一定程度的头发边缘摆动或细节变化。
这类效果对于写真图、立绘、海报和角色展示内容具有较强的视觉增益。
3. 适合用于氛围类动态展示
如果输入图像本身的构图与光影质量较高,则 AnimateDiff 往往能够进一步提升整体氛围感,适用于:
- AIGC 作品展示
- 短视频平台视觉展示
- 静态封面动态化
- 角色展示类视频内容
七、当前遗留问题:局部动作难以精确控制
尽管该工作流已经能够生成一定程度的动态效果,但在更细粒度的动作控制上仍存在较明显的不足。
其中最典型的两个问题如下。
1. 难以稳定实现人物微笑
当目标是让角色只产生一个轻微微笑动作时,生成结果通常会出现以下情况:
- 嘴部变化不明显
- 嘴型变形或不自然
- 表情不协调
- 面部其他区域同步漂移
- 人物身份一致性下降
这说明当前基础工作流并不具备较强的局部表情控制能力。
2. 难以只让头发区域运动
尽管正向提示词中已经包含 wind blowing hair ,但模型不会严格只对头发区域进行变化。
实际生成时,经常出现以下现象:
- 头发产生变化的同时,脸部也发生变化
- 肩膀、衣领等相邻区域共同波动
- 背景边缘受到扰动
- 局部运动与全局轻微漂移混合出现
这表明当前提示词只能提供语义方向上的引导,而不能构成严格的局部区域控制。
八、问题原因分析
1. AnimateDiff 更偏向全局时序建模
AnimateDiff 的主要优势在于处理整张图像在时间维度上的连续变化,其目标更接近:
- 让画面看起来处于持续变化之中
- 让前后帧具备自然过渡关系
而不是:
- 对某一块区域进行像素级、动作级的严格控制
因此,在"微笑""眨眼""只让头发摆动"等需求下,其表现往往不够稳定。
2. 单图输入缺乏真实动作参考
当前工作流属于典型的单图生成视频模式,模型所接收到的输入主要是:
- 一张静态图
- 一组文本提示
而缺少如下更强约束信息:
- 参考动作
- 面部关键点
- 驱动视频
- 区域级控制信号
在这种情况下,模型只能依据语义先验推断可能的动态方向,因此更容易出现动作不准确、局部变化失控或细节变形等问题。
3. 提示词的控制粒度天然有限
类似 slight motion、subtle movement、wind blowing hair 这样的提示词,本质上属于高层语义描述 。
它们可以告诉模型"希望出现什么类型的动态",但无法精确约束:
- 哪一部分必须运动
- 哪一部分绝对不能运动
- 动作从何时开始
- 动作持续到何时
- 动作幅度应如何变化
因此,仅通过文本提示词很难实现真正意义上的局部运动精控。
九、后续优化方向
针对当前工作流中暴露出的局部运动控制问题,后续可从以下几个方向继续优化。
1. 引入区域控制机制
如果目标是"仅让头发变化"或"仅让面部表情变化",可考虑引入以下方法:
- 遮罩控制
- 局部重绘
- 局部约束采样
相较于完全依赖全局提示词,这类方式更有助于提升指定区域的动作可控性。
2. 结合 ControlNet 或结构约束方法
为进一步增强生成过程中的动作约束能力,可结合:
- 姿态控制
- 面部关键点控制
- 深度控制
- 结构控制
这些方法有助于提升时序稳定性,并降低人物结构漂移的概率。
3. 引入参考动作驱动
如果目标已经从"轻微动态增强"转向"明确表情生成"或"指定动作生成",则可进一步考虑:
- 参考视频驱动
- 人脸关键点驱动
- 专用面部动画模型
对于微笑、眨眼、张嘴、说话等精细表情任务,上述方案通常比通用 AnimateDiff 工作流更合适。
十、总结
基于当前 ComfyUI 工作流的实践结果,可以得到以下结论。
1. 该工作流适合作为 AnimateDiff 入门模板
其主要优点包括:
- 结构清晰
- 配置直观
- 易于跑通
- 能形成完整的视频生成闭环
- 支持同时输出帧图和 mp4 视频
对于初学者而言,这类工作流能够有效建立对 AnimateDiff 基础机制的理解。
2. 该工作流适合"整体轻动态"而非"局部精控"
从结果表现来看,其更适合:
- 静态图动态化
- 轻微呼吸感
- 发丝轻摆
- 角色展示与氛围增强
而在以下场景中则存在明显不足:
- 微笑控制
- 局部表情变化
- 只让单一区域运动
- 高精度动作编辑
3. AnimateDiff 的使用边界需要明确
当前结果表明,AnimateDiff 更适合承担"让画面自然动起来"的任务,而不适合作为局部动作精确编辑器直接使用。
如果目标是更高层级的动作控制,就需要在工作流中引入更多结构化约束,而不是仅依赖提示词本身。
结语
这次实践的核心价值,在于建立了对 AnimateDiff 能力边界的清晰认识。
对于单图生成视频任务而言,当前工作流已经能够较稳定地实现静态图的轻微动态增强,并帮助理解 AnimateDiff 在时间维度建模中的作用 。与此同时,局部动作控制能力不足的问题也表现得非常明确,尤其是在人物微笑、头发单独摆动等需求下,现有基础流程仍难以达到理想效果。
因此,在后续的学习与优化中,重点不应仅放在增加提示词复杂度上,而应更多关注以下方向:
- 区域级控制
- 结构约束
- 参考动作驱动
- 面部动画专用方案
对于 AnimateDiff 的学习路径而言,先完成"稳定地动起来",再逐步推进到"可控地怎么动",是更合理的技术演进顺序。