
标题:World Reconstruction From Inconsistent Views
来源:德国慕尼黑工业大学
链接:https://lukashoel.github.io/video_to_world
文章目录
- 摘要
- 一、场景初始化
-
- [1. 利用视频扩散模型(VDMs)生成视频](#1. 利用视频扩散模型(VDMs)生成视频)
- [2. 利用几何基础模型(GFM)获取几何信息](#2. 利用几何基础模型(GFM)获取几何信息)
- [3. 点云重投影(Unprojection)](#3. 点云重投影(Unprojection))
- [4. 关键步骤:过滤方案(Filtering Scheme)](#4. 关键步骤:过滤方案(Filtering Scheme))
- 二、几何配准
-
- [1.第一阶段:非刚性迭代帧到模型 ICP](#1.第一阶段:非刚性迭代帧到模型 ICP)
- 2.第二阶段:全局非刚性优化
- [三、非刚性高斯泼溅优化(Non-rigid Gaussian Splatting Optimization)](#三、非刚性高斯泼溅优化(Non-rigid Gaussian Splatting Optimization))
-
- [1. 逆向变形优化 (Backward Deformation Optimization)](#1. 逆向变形优化 (Backward Deformation Optimization))
- [2. 3D 场景整合 (3D Scene Consolidation)](#2. 3D 场景整合 (3D Scene Consolidation))
- [3. 非刚性感知渲染 (Non-rigid Aware Rendering)](#3. 非刚性感知渲染 (Non-rigid Aware Rendering))
- 实验
摘要
视频扩散模型能够生成高质量且多样化的三维场景,但单帧图像在输出序列中常缺乏三维一致性,这给三维场景重建带来挑战。
本文通过将视频帧非刚性对齐至全局一致坐标系,有效解决这些不一致性问题 ,从而生成清晰精细的点云重建结果。首先,几何基础模型将每帧图像提升为像素级三维点云,但由于初始一致性缺失,该点云中存在未对齐的表面。随后,我们采用定制化非刚性迭代帧到模型ICP算法实现全帧初始对齐,再通过全局优化进一步提升点云锐度。最终,我们将该点云作为三维重建的初始数据,并创新性地提出逆形变渲染损失函数,成功从不一致视角构建出高质量且可探索的三维环境。
实验表明,本方法生成的三维场景质量显著优于基线模型,实现了视频模型向三维一致性世界生成器的高效转化。
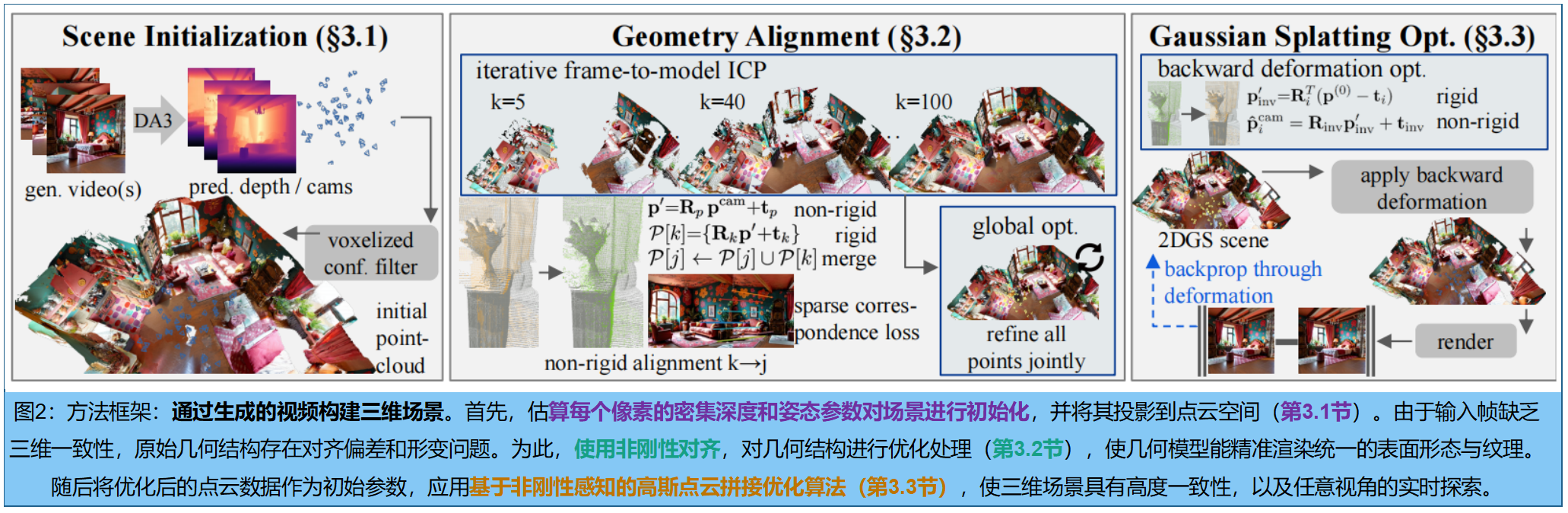
一、场景初始化
1. 利用视频扩散模型(VDMs)生成视频
接受文本、初始帧或特定的摄像机轨迹(旋转 R \mathbf{R} R、平移 t \mathbf{t} t、内参 K \mathbf{K} K)控制,使用 VDM 生成描述静态场景的多视角图像序列 V = { I i } i = 0 N \mathbf{V} = \{\mathbf{I}i\}{i=0}^N V={Ii}i=0N。 生成的帧之间仍存在"生成漂移(Generative Drift)",导致 3D 几何不一致,直接重建会出现重影或扭曲。
2. 利用几何基础模型(GFM)获取几何信息
使用预训练模型(DepthAnything-3)处理生成视频,输出 每一帧的逐像素深度图 d \mathbf{d} d、置信度图 c \mathbf{c} c 以及相机参数 ( R , t , K ) (\mathbf{R}, \mathbf{t}, \mathbf{K}) (R,t,K):
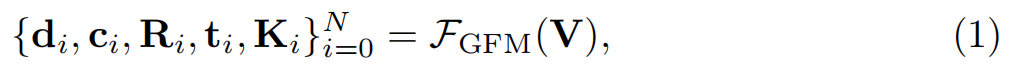
3. 点云重投影(Unprojection)
利用相机内参逆矩阵 K − 1 \mathbf{K}^{-1} K−1,将 2D 像素坐标 ( u , v ) (u, v) (u,v) 结合深度 d d d 转换回 3D 空间中的点(像素点 -> 相机坐标系 p i c a m \mathbf{p}_i^{cam} picam--> 全局世界坐标系 P ˉ \bar{\mathcal{P}} Pˉ),获得带颜色的未对齐的(Misaligned)初始点云:
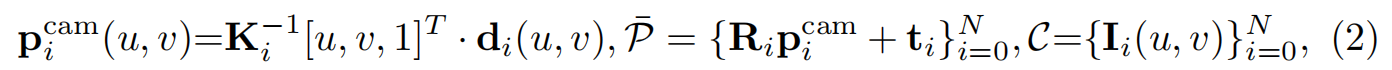
4. 关键步骤:过滤方案(Filtering Scheme)
为了确保初始化的点云足够可靠,作者设计了一个基于**体素(Voxel)**的过滤机制:
- 分配体素 : 将每个 3D 点 p k \mathbf{p}_k pk 分配到对应的体素 v k \mathbf{v}_k vk 中。
- 置信度阈值 ( τ l o c \tau_{loc} τloc): 计算每个体素内所有点的平均置信度,过滤掉低置信度的噪声点。
- 占用阈值 ( τ c n t \tau_{cnt} τcnt): 统计每个体素内的点数,过滤掉点数过少的稀疏区域(可能是不一致的幻觉产生的)。
最终点云 P \mathcal{P} P: 仅保留同时满足"高置信度 "且"在多个视角中被观测到"的点。
二、几何配准
1.第一阶段:非刚性迭代帧到模型 ICP
核心目标:将每一帧的点云 P k \mathcal{P}k Pk 迭代地对齐到当前的累积模型 P j \mathcal{P}j Pj 中 。
- 形变模型
使用基于 Hashgrid 的多层感知机(MLP)作为变形神经场,预测3D点 p \mathbf{p} p 的一个 6 维的指数坐标 ξ \xi ξ(twist),它代表了 se ( 3 ) \text{se}(3) se(3) 空间中的一个变换。 p ′ = R p p cam + t p , P ˉ k = { R k p ′ + t k ∣ p ∈ P k } (3) \mathbf{p}' = \mathbf{R}_p \mathbf{p}^{\text{cam}} + \mathbf{t}_p, \quad \bar{\mathcal{P}}k = \{ \mathbf{R}_k \mathbf{p}' + \mathbf{t}_k | \mathbf{p} \in \mathcal{P}k \} \tag{3} p′=Rppcam+tp,Pˉk={Rkp′+tk∣p∈Pk}(3)解析:公式描述了如何将相机坐标系下的点通过神经场预测的局部旋转 R p \mathbf{R}_p Rp 和平移 t p \mathbf{t}_p tp 进行非刚性变换,然后再应用全局相机位姿 ( R k , t k ) (\mathbf{R}_k, \mathbf{t}_k) (Rk,tk) 将其转换到统一的世界坐标系(或参考帧坐标系)。
- 点到平面距离损失:
L data = 1 ∑ p ∈ P k w ( p ) ∑ p ∈ P k w ( p ) ( ( p ′ − q nn ( j ) ) ⋅ n nn ( j ) ) 2 (4) \mathcal{L}{\text{data}} = \frac{1}{\sum{\mathbf{p} \in \mathcal{P}k} w(\mathbf{p})} \sum_{\mathbf{p} \in \mathcal{P}k} w(\mathbf{p}) ((\mathbf{p}' - \mathbf{q}{\text{nn}(j)}) \cdot \mathbf{n}{\text{nn}(j)})^2 \tag{4} Ldata=∑p∈Pkw(p)1p∈Pk∑w(p)((p′−qnn(j))⋅nnn(j))2(4)
解析:测量变换后的点 p ′ \mathbf{p}' p′ 与其在模型中的最近邻点 q \mathbf{q} q 之间的距离,并投影到 q \mathbf{q} q 的法向量 n \mathbf{n} n 上。这比单纯的点到点距离更鲁棒。
w ( p ) = { 1 , if ∥ p ′ − q nn ( j ) ∥ 2 < d max 2 0 , otherwise (5) w(\mathbf{p}) = \begin{cases} 1, & \text{if } \|\mathbf{p}' - \mathbf{q}{\text{nn}(j)}\|^2 < d{\text{max}}^2 \\ 0, & \text{otherwise} \end{cases} \tag{5} w(p)={1,0,if ∥p′−qnn(j)∥2<dmax2otherwise(5)
解析:这是一个权重因子(mask),如果点对之间的距离超过阈值 d max d_{\text{max}} dmax,则视其为离群点(Outlier),权重设为 0,不参与计算。
- 稀疏对应损失
利用深度学习匹配器(如 RoMa)获取图像间的 2D 匹配对,以辅助对齐: L corr = ∑ i w i ∥ P j s i − P k t i ∥ 2 ∑ i w i (6) \mathcal{L}_{\text{corr}} = \frac{\sum_i w_i \|\mathcal{P}_j\\mathbf{s}_i - \mathcal{P}_k\\mathbf{t}_i\|^2}{\sum_i w_i} \tag{6} Lcorr=∑iwi∑iwi∥Pjsi−Pkti∥2(6)
解析:s i \mathbf{s}_i si 和 t i \mathbf{t}_i ti 分别是源图像和目标图像中的像素坐标,公式计算对应 3D 点之间的欧几里得距离。这有助于解决重叠较小时的对齐问题。
- 正则化项:总变分损失
为了保证形变的平滑性(类似于 As-Rigid-As-Possible 约束): L tv = 1 ∣ P k ∣ ∑ p ∈ P k ∥ F θ k ( p ) − F θ k ( p ± s vox ) ∥ 2 (7) \mathcal{L}{\text{tv}} = \frac{1}{|\mathcal{P}k|} \sum{\mathbf{p} \in \mathcal{P}k} \|\mathcal{F}{\theta_k}(\mathbf{p}) - \mathcal{F}{\theta_k}(\mathbf{p} \pm s_{\text{vox}})\|^2 \tag{7} Ltv=∣Pk∣1p∈Pk∑∥Fθk(p)−Fθk(p±svox)∥2(7)
解析: F θ k \mathcal{F}{\theta_k} Fθk 是预测变换的 MLP。**该公式惩罚相邻点(距离为 s vox s{\text{vox}} svox)之间变换预测的差异,确保局部的形变场是连续且平滑的**。
2.第二阶段:全局非刚性优化
第一阶段完成后,由于是序贯对齐,可能会产生漂移(Drift)导致表面变厚。因此需要对所有相机的位姿和变形网络 进行联合优化。
- 全局能量函数
E ( { R i , t i , θ i } i = 1 N ) = L data global + λ color L color global + λ anchor L anchor (8) E(\{\mathbf{R}i, \mathbf{t}i, \theta_i\}{i=1}^N) = \mathcal{L}{\text{data}}^{\text{global}} + \lambda_{\text{color}} \mathcal{L}{\text{color}}^{\text{global}} + \lambda{\text{anchor}} \mathcal{L}_{\text{anchor}} \tag{8} E({Ri,ti,θi}i=1N)=Ldataglobal+λcolorLcolorglobal+λanchorLanchor(8)
- 锚点正则化
为了防止优化过程中出现退化解(即模型乱掉),约束更新后的参数不要偏离第一阶段的结果太远: L anchor = 1 N ∑ i = 1 N 1 M ∑ k = 1 M ∥ F θ i ( a k , i ) − ξ k , i ( 0 ) ∥ 2 + ∥ ξ g , i − ξ g , i ( 0 ) ∥ 2 (9) \mathcal{L}{\text{anchor}} = \frac{1}{N} \sum{i=1}^N \left \\frac{1}{M} \\sum_{k=1}\^M \\\|\\mathcal{F}_{\\theta_i}(\\mathbf{a}_{k,i}) - \\xi_{k,i}\^{(0)}\\\|\^2 + \\\|\\xi_{g,i} - \\xi_{g,i}\^{(0)}\\\|\^2 \\right \tag{9} Lanchor=N1i=1∑NM1k=1∑M∥Fθi(ak,i)−ξk,i(0)∥2+∥ξg,i−ξg,i(0)∥2(9)
解析: N N N 为帧数, M M M 为每帧下采样的样本点数。第一项:约束每个点的局部形变 F \mathcal{F} F 接近第一阶段结束时的值 ξ ( 0 ) \xi^{(0)} ξ(0)。第二项:约束相机的位姿参数 ξ g \xi_g ξg 接近第一阶段得到的初始位姿 ξ g ( 0 ) \xi_g^{(0)} ξg(0)。
三、非刚性高斯泼溅优化(Non-rigid Gaussian Splatting Optimization)
在完成之前的几何对齐后,虽然得到了对齐的点云 P 0 \mathcal{P}0 P0,但由于输入图像集 { I i } \{\mathbf{I}_i\} {Ii} 之间存在不一致性(生成漂移),直接渲染效果很差。本节的核心目标是构建一个统一的"标准空间(Canonical State)"重建,并通过非刚性形变场来解释各帧之间的一致性。
1. 逆向变形优化 (Backward Deformation Optimization)
为了将标准空间(Canonical space)中的3DGS映射到每一帧的观测空间,需要求解逆向变形。
- 模型构建 :使用一个基于 Hashgrid 的 MLP F θ inv − 1 \mathcal{F}{\theta{\text{inv}}}^{-1} Fθinv−1 来学习逆向变形场。输入标准空间中的点 p ∈ P 0 \mathbf{p} \in \mathcal{P}0 p∈P0 和视图嵌入(view embedding),输出 6 维指数坐标 ξ inv \xi^{\text{inv}} ξinv。
- 坐标变换: p inv ′ = R i T ( p ( 0 ) − t i ) , p ^ cam = R inv p inv ′ + t inv (10) \mathbf{p}'{\text{inv}} = \mathbf{R}i^T(\mathbf{p}^{(0)} - \mathbf{t}i), \quad \hat{\mathbf{p}}^{\text{cam}} = \mathbf{R}{\text{inv}}\mathbf{p}'{\text{inv}} + \mathbf{t}{\text{inv}} \tag{10} pinv′=RiT(p(0)−ti),p^cam=Rinvpinv′+tinv(10)该公式描述了如何将标准空间点 p ( 0 ) \mathbf{p}^{(0)} p(0) 通过相机位姿的逆变换和学习到的局部逆向变形 ( R inv , t inv ) (\mathbf{R}{\text{inv}}, \mathbf{t}{\text{inv}}) (Rinv,tinv),转换回原始的相机观测空间坐标 p ^ cam \hat{\mathbf{p}}^{\text{cam}} p^cam。
- 优化目标 : L inverse = 1 M ∑ i = 1 M ∥ p ^ i cam − p i cam ∥ 2 , E ( θ inv ) = L inverse + λ tv L tv (11) \mathcal{L}{\text{inverse}} = \frac{1}{M} \sum{i=1}^{M} \|\hat{\mathbf{p}}i^{\text{cam}} - \mathbf{p}i^{\text{cam}}\|^2, \quad E(\theta{\text{inv}}) = \mathcal{L}{\text{inverse}} + \lambda_{\text{tv}} \mathcal{L}_{\text{tv}} \tag{11} Linverse=M1i=1∑M∥p^icam−picam∥2,E(θinv)=Linverse+λtvLtv(11)通过监督学习,使逆变换后的点云尽力还原到原始的观测位置,并辅以全变分(TV)正则化项以保证形变场的平滑。
2. 3D 场景整合 (3D Scene Consolidation)
利用学到的逆向变形场,将点云转化为高斯表示(2DGS)。
- 初始化 :将对齐的点云 P 0 \mathcal{P}0 P0 作为 2D 高斯圆盘的中心位置,利用估计的法线确定其朝向。
- 属性设置 :
- Scale:取每个点到其 k = 10 k=10 k=10 个最近邻点的平均欧式距离。
- Opacity:统一初始化为 0.1。
- Color:将点云颜色转换为 0 阶球面谐波系数(SH coefficients)。
3. 非刚性感知渲染 (Non-rigid Aware Rendering)
由于输入图像存在几何不一致,直接从固定相机渲染会撤销之前的几何对齐成果。因此,作者提出了一种 "非刚性感知"的渲染目标:
- 渲染逻辑 : 在渲染每一帧之前,利用公式 (10) 先将标准空间中的高斯分布进行非刚性变形,使其回到具有不一致性的帧空间中,然后再进行光栅化渲染。
- 渲染损失 : L rend = 1 N ∑ i = 0 N ( λ 1 ∥ I ^ i − I i ∥ 1 + λ 2 LPIPS ( I ^ i , I i ) ) (12) \mathcal{L}{\text{rend}} = \frac{1}{N} \sum{i=0}^{N} (\lambda_1 \|\hat{\mathbf{I}}_i - \mathbf{I}_i\|^1 + \lambda_2 \text{LPIPS}(\hat{\mathbf{I}}_i, \mathbf{I}_i)) \tag{12} Lrend=N1i=0∑N(λ1∥I^i−Ii∥1+λ2LPIPS(I^i,Ii))(12)结合了 L 1 L_1 L1 损失和感知损失(LPIPS),强制标准空间的3DGS在经过形变后能够解释不一致的图像观测。
- 总目标函数 (还引入了 2DGS 的深度Depth和法线Normal正则项): E ( G , { R i , t i } i = 0 N ) = L rend + λ d L d + λ n L n (13) E(\mathcal{G}, \{\mathbf{R}i, \mathbf{t}i\}{i=0}^N) = \mathcal{L}{\text{rend}} + \lambda_d \mathcal{L}_d + \lambda_n \mathcal{L}_n \tag{13} E(G,{Ri,ti}i=0N)=Lrend+λdLd+λnLn(13)
优势 :通过非刚性形变场"吸收"了生成图像中的几何漂移,使得3DGS可以在一个干净、对齐的标准空间中优化 ,从而获得更尖锐、更详细的外观。
细节优化 :收敛速度快(几千次迭代即可)。采用两阶段训练:第二阶段专门优化高阶球面谐波系数以处理高光(Specular)场景。在特定阶段会冻结相机位姿和高斯位置,以防止模型陷入将"生成漂移(Generative Drift)"错误解释为"视点依赖效果(View-dependent effects)"的退化解。
实验
1.实验细节
超参数配置:粗到精的ICP优化采用 s v o x = 4 c m , 2 c m s_{vox}=4cm,2cm svox=4cm,2cm和 d m a x = 5 c m , 3 c m d_{max}=5cm,3cm dmax=5cm,3cm参数,分别进行50次和150次迭代,学习率为 1 e − 3 1e−3 1e−3, λ c o l o r = 0.05 , λ c o r r = 1.0 , λ t v = 10.0 λ_{color}=0.05,λ_{corr}=1.0,λ_{tv}=10.0 λcolor=0.05,λcorr=1.0,λtv=10.0. 设置为1e−3。我们将百分位数阈值设为 θ l o c = 15.0 , θ c n t = 50.0 , θ d = θ g = 75.0 θ_{loc}=15.0,θ_{cnt}=50.0,θ_d=θ_g=75.0 θloc=15.0,θcnt=50.0,θd=θg=75.0 ,异常值剔除的最大标准差设为 σ d = 2.5 , σ c = 1.5 σ_d=2.5,σ_c=1.5 σd=2.5,σc=1.5. 。对于 L c o r r L_{corr} Lcorr算法,我们最多检测20组图像对中的5,000个对应关系。全局优化阶段再进行100次迭代, λ a n c h o r = 50.0 λ_{anchor} =50.0 λanchor=50.0。在单个A6000 GPU上处理N=50张图像时,两个阶段平均耗时25分钟/20GB内存。根据2DGS24的配置方案,我们将P0子样本量缩减至约150万GS基元,采用5,000次迭代进行三维场景优化,耗时10分钟/8GB内存且不进行密度增强处理。可选地对SH进行额外10,000次迭代优化。
2.单目视频3D重建
与近期基于多款先进视频扩散模型生成帧的三维重建方法进行对比。具体而言, 利用Wan-2.2,从文本生成包含多种室内外场景及摄像机运动的单视频序列 ,并通过ViewCrafter88、Gen3C56、Seva91和Voyager26实现摄像机控制 。此外,我们还采用了近期自回归世界生成器Genie3 5和HY-WorldPlay
我们基于从这些视频中采样的50张图像,采用多种基线方法重建三维场景。首先,使用随机初始化的3DGS- MCMC 34和DA342中的可优化相机参数。其次,将DA342的点位作为3DGS33的初始化参数,并通过深度损失函数90对DA3深度图进行位置正则化处理。我们将此方法称为"DA3"42。在优化3DGS前,采用 VGGT -X43方法(该方法通过束调整技术实现刚性对应点对齐),当使用DA342替代 VGGT 43预测时,我们将此方法称为" VGGT -X†"。
图3和图4重建结果 :video2world在三维一致性空间中生成的纹理更加锐利细腻,视觉保真度与输入视频帧相当。相比之下,基线方法未能校正生成帧中固有的生成漂移现象,这会导致输入姿态下的渲染效果出现模糊现象(例如图3顶部的砖块纹理)。这种问题在新视角下尤为明显:不一致的图像观测会导致三维场景中出现漂浮伪影,限制了从任意位置进行探索的能力。我们的方法采用非刚性感知方式优化场景,显著提升了视角稳定性------即在保持视频帧高视觉保真度的同时,能够从新颖视角探索三维世界。该方法有效将任何视频扩散模型转化为三维世界生成器,实现了持久性、高质量且实时的渲染效果。


表1的计算一致性与保真度指标:基于既定的世界评分基准16,并针对每种重建方法的所有虚拟现实设备(VDM)进行平均计算。本方法获得最高的一致性评分,这凸显了其从不一致视角重建三维场景的能力。渲染质量在基准方法中表现最优,与输入视频质量相当(CLIP- IQA +:47.39,CLIP美学:39.04)。
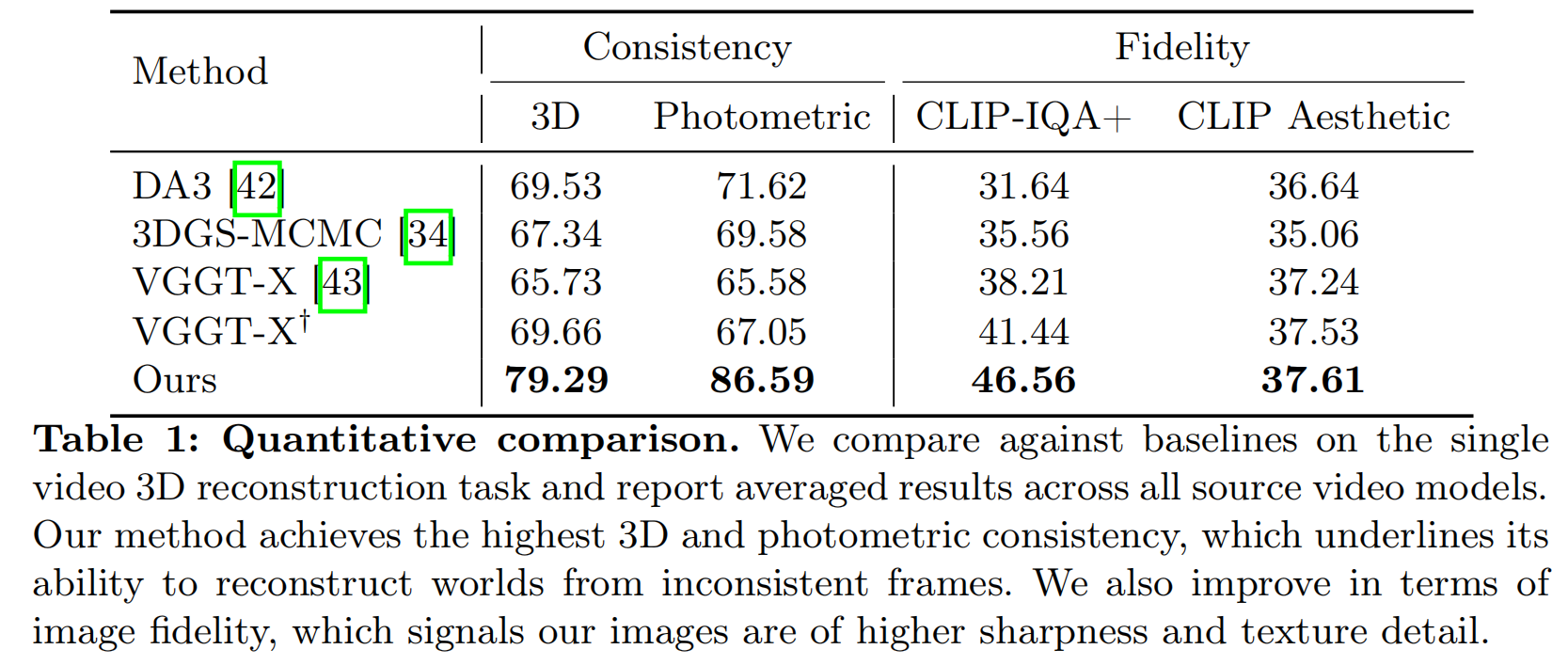
图5对比了 所有适用基准方法所使用的三维点云初始化数据。与DA342的预测结果相比,我们的方法显著提升了单个表面的对齐精度(例如在花园场景中实现了多窗口与幻灯片的统一)。 VGGT -X43由于未建模非刚性形变,其生成的点云密度较低且对齐精度较差。

#pic_center =40%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E