AI-TestHub:从零构建智能测试用例生成平台
>一个帮助测试人员从需求文档自动生成测试用例并生成selenium脚本文件的AI工具,支持PDF/Word解析、两阶段AI生成、异步任务处理,测试效率提升70%以上
一、项目背景
1.1 痛点分析
接上文写了一篇专门对于电商平台自动化测试的文章,对于这个电商平台的功能测试部分我发现一个普遍存在的效率瓶颈:每天要花大量时间阅读需求文档、编写测试用例。
以我所在的电商项目为例:
- 一个中等规模的需求文档(约10页),包含登录、购物车、支付等模块
- 资深测试工程师编写完整用例需要2-3小时
- 新手可能需要半天甚至更久
- 过程中还容易遗漏边界条件和异常场景
每天两眼一睁就在编用例,所以我就想:能不能让AI来承担这份重复性工作?用户上传需求文档,系统自动分析并生成规范的测试用例。
1.2 项目目标
核心目标:实现Web应用,支持PDF/Word文档上传,AI自动生成结构化测试用例
质量目标:生成的用例覆盖功能、边界、异常场景,格式规范可直接使用
技术目标:采用现代技术栈,代码清晰,便于学习和扩展
简历目标:作为一个完整的测开项目,体现后端开发、AI工程化和测试思维
二、项目框架设计
2.1 技术栈集
Python + FastAPI + SQLAlchemy + MySQL + DeepSeek API + pdfplumber + python-docx + pandas + HTML5/JavaScript + Docker
2.2 项目架构
整体流程设计
用户在前端创建项目后,上传 PDF/Word 文档,系统解析文本存入数据库。点击"生成用例"时,后端创建任务记录,通过 `BackgroundTasks` 将 AI 调用放入后台队列,立即返回 `task_id`。前端轮询任务状态,后台独立执行:先调用 AI 提取需求点,再基于需求点生成 JSON 格式用例,逐条存入数据库,最后标记任务完成。生成后的用例支持在线编辑、删除和导出 Excel,每条用例还可单独生成 Selenium 自动化脚本。
项目目录
ai-testhub/
│
├── 📁 app/ # 核心应用代码
│ ├── 📁 api/ # API 路由层
│ │ ├── 📄 projects.py # 项目管理(增删改查)
│ │ ├── 📄 upload.py # 文档上传(PDF/Word)
│ │ ├── 📄 generate.py # 用例生成(异步任务)
│ │ └── 📄 cases.py # 用例管理(增删改查 + 导出)
│ │
│ ├── 📁 core/ # 核心配置层
│ │ ├── 📄 config.py # 环境变量配置
│ │ └── 📄 database.py # 数据库连接管理
│ │
│ ├── 📁 models/ # 数据模型层
│ │ └── 📄 models.py # 四张表结构定义
│ │
│ ├── 📁 services/ # 业务逻辑层
│ │ ├── 📄 parser.py # PDF/Word 文档解析
│ │ ├── 📄 ai_service.py # AI 调用核心(两阶段 Prompt)
│ │ └── 📄 export.py # Excel 导出服务
│ │
│ ├── 📁 static/ # 前端静态文件
│ │ ├── 📄 index.html # 主页面
│ │ ├── 📁 css/ # 样式文件
│ │ └── 📁 js/ # 交互逻辑
│ │
│ └── 📄 main.py # FastAPI 应用入口
│
├── 📁 exports/ # Excel 导出临时目录
├── 📁 uploads/ # 用户上传文档存储目录
├── 📄 .env # 环境变量(API Key、数据库密码)
├── 📄 .env.example # 环境变量模板
├── 📄 docker-compose.yml # Docker 容器编排
├── 📄 Dockerfile # 后端镜像构建
├── 📄 requirements.txt # Python 依赖清单
├── 📄 init_db.py # 数据库初始化脚本
└── 📄 README.md # 项目说明文档
2.3 数据库设计
| 表名 | 主要字段 | 作用 |
|---|---|---|
projects |
id, name, description | 测试项目管理 |
documents |
id, project_id, content_text | 上传文档及解析内容 |
tasks |
id, project_id, status, progress | 异步任务进度追踪 |
test_cases |
id, project_id, steps(JSON), automation_code | 测试用例及自动化脚本 |
关键设计:
-
使用级联删除 (
cascade="all, delete-orphan"),删除项目时自动清理关联数据 -
Task表用UUID做主键,避免暴露任务数量
-
steps字段使用JSON类型,直接存储步骤列表,存取方便
三、核心内容详解
3.1 文档解析服务 (services/parser.py)
功能:将PDF和Word文档转换为纯文本
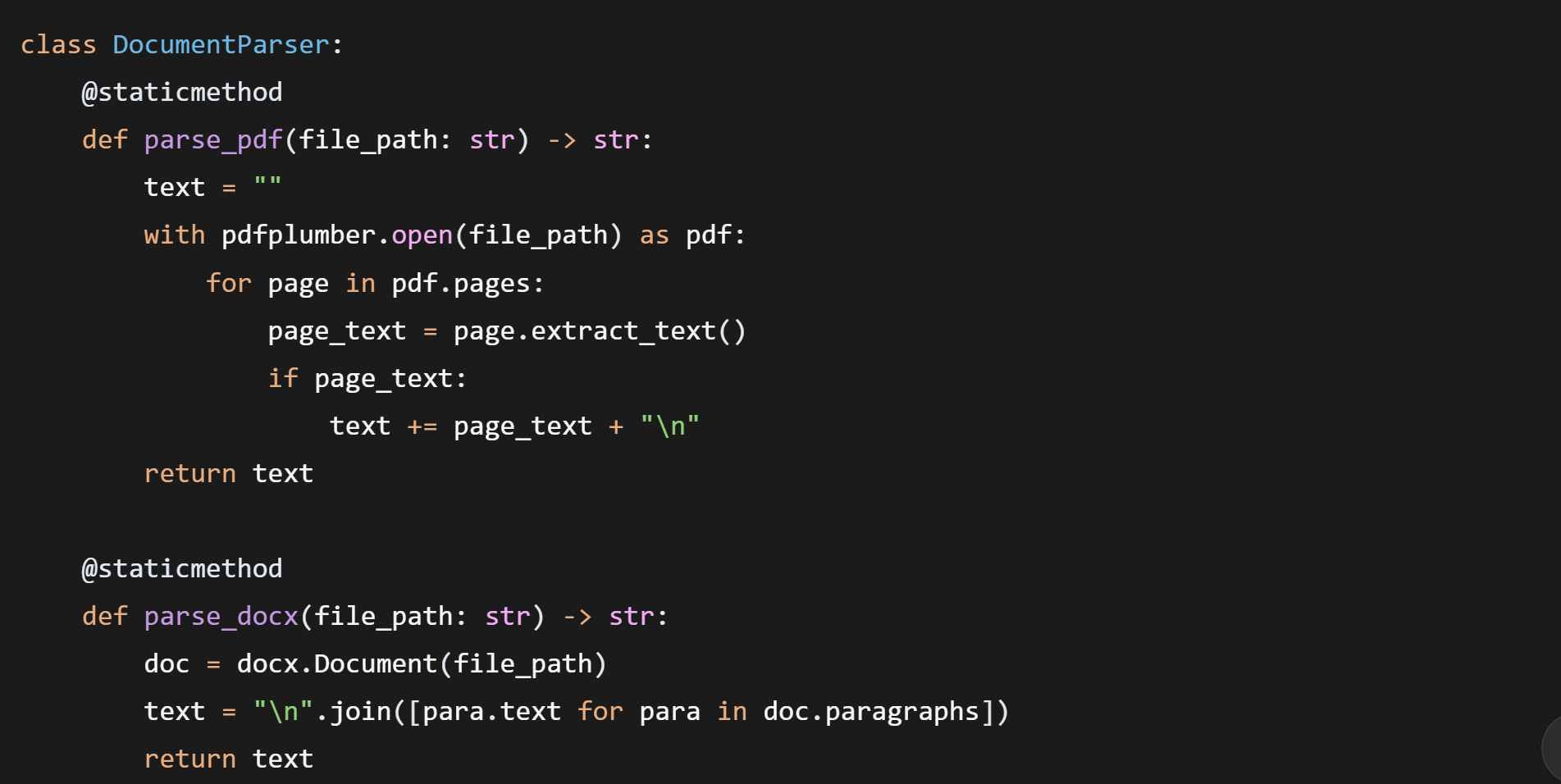
技术要点:
-
pdfplumber比PyPDF2准确率高,能更好处理表格和复杂布局 -
with语句自动管理文件资源,避免内存泄漏 -
统一返回纯文本,上层调用不关心原始格式
3.2 AI服务核心 (services/ai_service.py)
这是项目的灵魂,采用两阶段Prompt设计:
第一阶段:提取需求点
第二阶段:生成测试用例 
请直接输出JSON数组为什么分两阶段?
-
直接生成:AI容易遗漏需求点或生成不相关内容
-
分阶段:先让AI"理解"文档(提取需求),再"创作"(生成用例),逻辑更清晰,质量更高
3.3 异步任务调度 (api/generate.py)
AI调用耗时10-30秒,必须异步处理:
前端轮询实现:
javascript
3.4 异步AI调用的核心处理
OpenAI SDK是同步的,直接调用会阻塞FastAPI事件循环。解决方案:
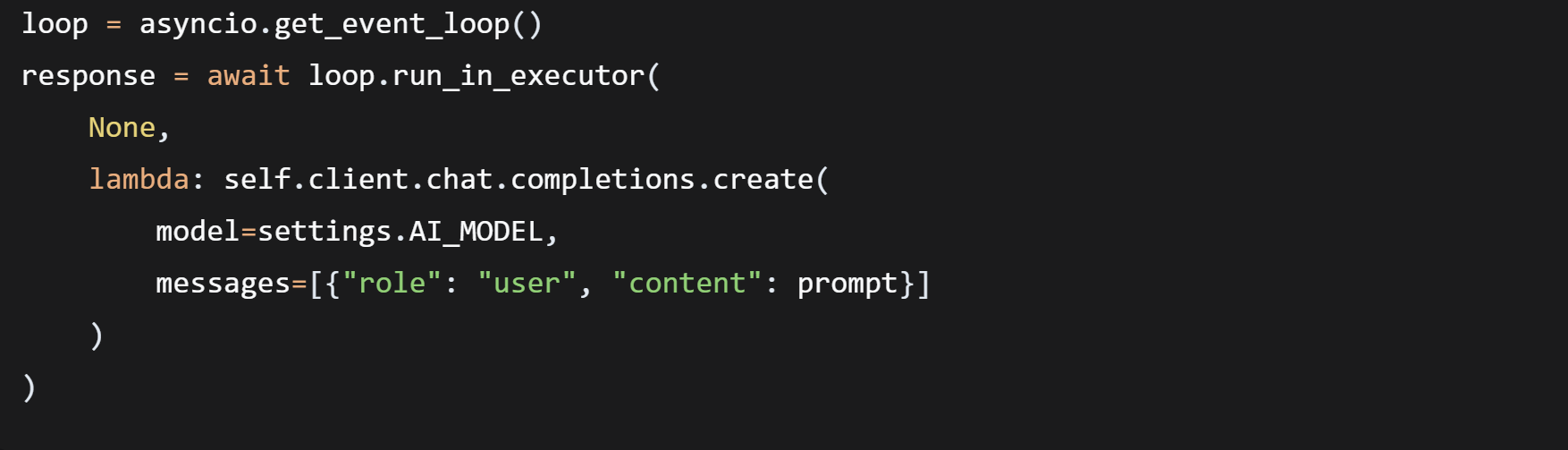
run_in_executor将同步调用放到线程池执行,主线程通过await让出控制权,可以继续处理其他请求。
3.5 用例导出 (api/cases.py)
支持导出Excel:
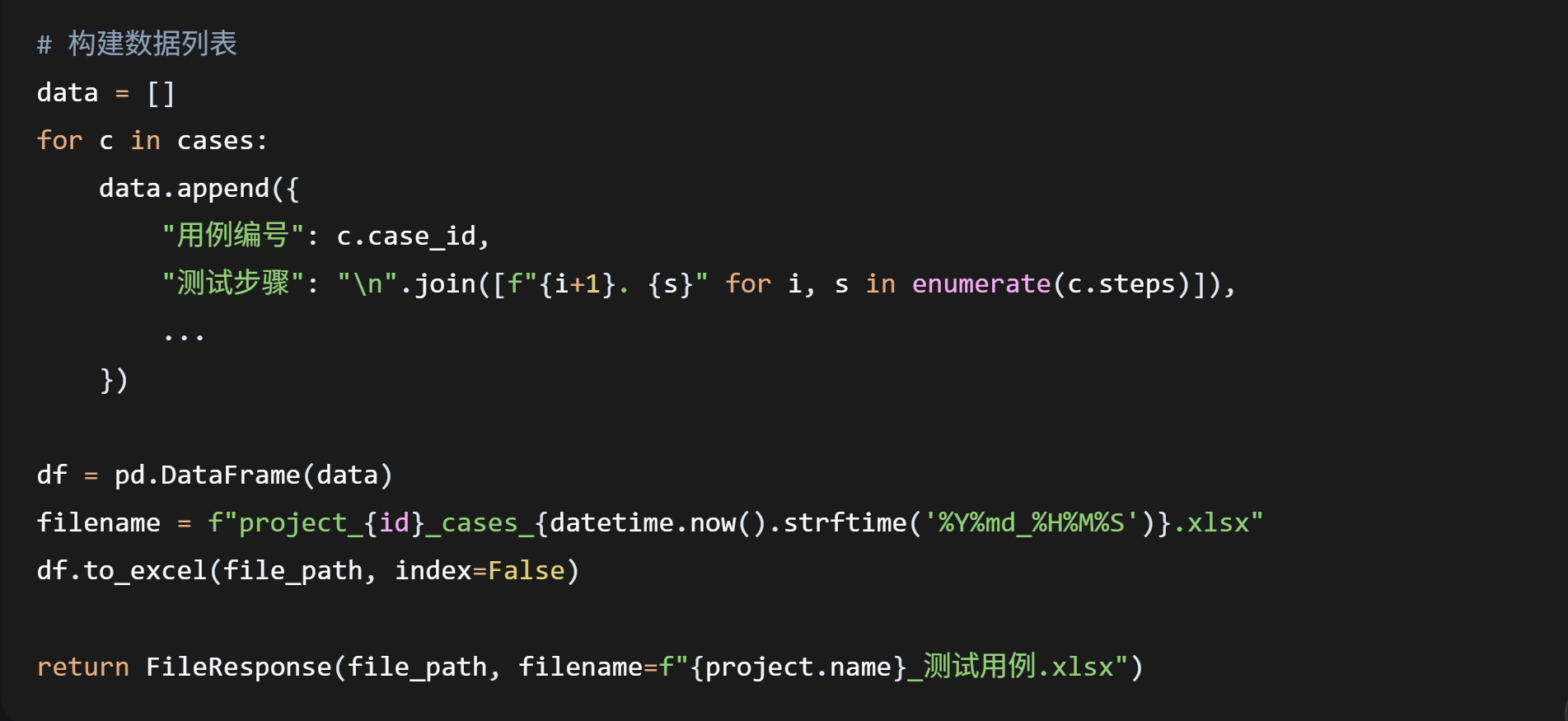
技术要点:
-
pandas的
to_excel一行代码生成Excel -
文件名带时间戳避免冲突
-
下载时使用项目名作为文件名,用户体验好
四、难点攻克
难点一:AI返回格式不稳定
问题:AI有时返回markdown包裹的JSON,有时直接返回JSON,有时不是合法JSON格式。
解决方案:
python
难点二:PDF解析乱码或失败
问题:部分PDF文件编码不标准,提取出乱码;或者PDF全是图片,没有文字。
解决方案:
-
使用
pdfplumber替代PyPDF2,准确率更高 -
解析失败时自动删除已保存的文件
-
返回友好错误信息给前端

难点三:异步任务的状态追踪
问题:用户可能想知道AI生成到哪一步了,是卡住了还是在正常处理。
解决方案:
-
设计tasks表记录状态和进度
-
在AI服务的各个阶段更新进度(20%提取需求、40%生成用例...)
-
前端轮询获取进度并显示进度条
五、项目成果
该项目有效提升了测试的效率,以下是一个对比图:
5.1效果对比图
| 对比维度 | 手工操作 | 使用平台 | 提升效果 |
|---|---|---|---|
| 文档阅读+用例编写 | 2-3小时 | 5-10分钟 | 效率提升 90% 以上 |
| 用例格式规范性 | 因人而异,格式不统一 | 统一模板输出,规范一致 | 实现标准化 |
| 边界场景覆盖 | 依赖个人经验,容易遗漏 | AI 自动补充边界值和异常场景 | 覆盖更全面 |
| 回归测试效率 | 每次需求变更需重新编写 | 重新上传文档即可生成 | 维护成本降低 |
以一个典型的电商登录模块为例:原来手工编写用例需要 1 小时(包含正常登录、密码错误、账号锁定、验证码过期等场景),现在只需上传需求文档,5 分钟即可生成包含 10-20 条用例的完整测试方案。
5.2 技术收获
通过这个项目的开发,我在以下方面有了深入理解和实践:
FastAPI 异步编程 :掌握了 FastAPI 的异步路由、BackgroundTasks 后台任务、依赖注入等核心特性,理解了如何在异步框架中处理同步的第三方 SDK(如 OpenAI),以及如何用 run_in_executor 将同步调用放到线程池执行。
AI Prompt 工程:积累了实用的 Prompt 设计经验,特别是两阶段设计------先提取需求再生成用例,比一次性生成准确率更高。同时掌握了处理 AI 返回格式不稳定问题的方法(JSON 清理、异常兜底)。
异步任务状态追踪:设计并实现了完整的任务状态机(pending → processing → completed/failed),通过数据库记录进度并在各阶段更新,前端通过轮询获取实时进度,用户体验良好。
数据库设计:熟悉了 SQLAlchemy ORM 的使用,包括表关系定义(一对多、级联删除)、JSON 字段存储、UUID 主键设计等。
Docker 容器化:掌握了编写 Dockerfile 和多容器编排(docker-compose)的技能,实现了项目的快速部署和环境统一。
六、未来规划
RAG 检索增强生成:当前版本每次生成都是基于当前文档独立生成,没有利用历史用例。计划引入向量数据库(如 ChromaDB),将公司历史用例向量化存储,生成新用例时先检索相似的历史用例作为参考上下文,让生成的用例更符合公司规范,同时复用之前积累的测试经验。
更多文档格式支持:目前仅支持 PDF 和 Word,后续计划扩展支持 Markdown(技术文档常用)、Excel(测试数据)、图片(OCR 识别需求文档截图),满足更多使用场景。
用例评审流程:测试用例生成后通常需要评审。计划增加在线评审功能,支持多人评论、版本对比、评审记录追踪,帮助团队规范用例质量管控流程。
自定义 Prompt 模板:不同团队可能有不同的用例格式要求(如是否需要优先级、是否需要关联需求ID)。计划允许用户自定义 Prompt 模板,根据团队规范灵活调整生成格式。
七、写在最后
这个项目是我对"AI + 测试"方向的一次探索尝试。起初的想法很朴素:既然 AI 能理解文档、能生成代码,那能否帮助测试同学从重复的用例编写中解放出来?带着这个问题,我开始从 0 到 1 搭建这个平台。
在技术实现上,两阶段 Prompt 的设计是反复调试后的成果------先让 AI 提取需求点,再基于需求点生成用例,将复杂任务拆解为多个简单任务的组合,生成的用例质量显著提升。异步任务加轮询的模式则解决了 AI 调用长耗时与用户体验之间的矛盾,后台独立执行,前端实时反馈,让等待变得可感知。
这个项目还有很多不完善的地方,生成的脚本中元素定位器仍需手动补充,文档格式也仅支持 PDF 和 Word。后续计划引入 RAG 检索历史用例,持续优化生成质量。作为刚入门的学生,这次开发让我对后端架构和 AI 工程化有了更具体的认知。AI 不会取代测试工程师,但或许能让我们把精力放在更有价值的事情上,不断完善增强自己的能力。