What is Prompt Engineering ------ 提示词工程是什么?
- 简介
- [1. 提示工程技术本质](#1. 提示工程技术本质)
-
- [1.1 LLM的核心生成机制:自回归令牌预测](#1.1 LLM的核心生成机制:自回归令牌预测)
- [1.2 提示工程的工程化定义](#1.2 提示工程的工程化定义)
- [1.3 提示效果的核心影响因子](#1.3 提示效果的核心影响因子)
- [2. LLM 的输出配置:采样算法与参数协同机制](#2. LLM 的输出配置:采样算法与参数协同机制)
-
- [2.1 最大令牌长度(max_tokens):截断机制与语义约束](#2.1 最大令牌长度(max_tokens):截断机制与语义约束)
- [2.2 温度(Temperature):概率分布的熵控制](#2.2 温度(Temperature):概率分布的熵控制)
- [2.3 Top-K与Top-P采样:候选令牌的范围约束](#2.3 Top-K与Top-P采样:候选令牌的范围约束)
-
- [Top-K 采样](#Top-K 采样)
- Top-P(核采样)
- [2.4 采样参数的协同机制与优先级规则](#2.4 采样参数的协同机制与优先级规则)
- [3. 核心提示范式](#3. 核心提示范式)
-
- [3.1 基础提示范式:通用场景的核心解法](#3.1 基础提示范式:通用场景的核心解法)
-
- [3.1.1 零样本提示(Zero-shot Prompting)](#3.1.1 零样本提示(Zero-shot Prompting))
- [3.1.2 单样本/少样本提示(One-shot/Few-shot Prompting)](#3.1.2 单样本/少样本提示(One-shot/Few-shot Prompting))
- [3.1.3 系统、角色和上下文提示 (System, role and contextual prompting)](#3.1.3 系统、角色和上下文提示 (System, role and contextual prompting))
- [3.2 进阶推理范式:解决复杂任务的核心技术](#3.2 进阶推理范式:解决复杂任务的核心技术)
-
- [3.2.1 回退提示(Step-back Prompting)](#3.2.1 回退提示(Step-back Prompting))
- [3.2.2 思维链(Chain of Thought, CoT)](#3.2.2 思维链(Chain of Thought, CoT))
- [3.2.3 自我一致性(Self-Consistency)](#3.2.3 自我一致性(Self-Consistency))
- [3.2.4 思维树(Tree of Thoughts, ToT)](#3.2.4 思维树(Tree of Thoughts, ToT))
- [3.2.5 ReAct(Reason & Act):推理与行动协同范式](#3.2.5 ReAct(Reason & Act):推理与行动协同范式)
- [3.2.6 自动提示工程(Automatic Prompt Engineering, APE)](#3.2.6 自动提示工程(Automatic Prompt Engineering, APE))
- [4. 代码提示工程](#4. 代码提示工程)
-
- [4.1 编写代码的提示(Prompts for writing code)](#4.1 编写代码的提示(Prompts for writing code))
- [4.2 解释代码的提示(A prompt for explaining code)](#4.2 解释代码的提示(A prompt for explaining code))
- [4.3 翻译代码的提示(Prompts for translating code)](#4.3 翻译代码的提示(Prompts for translating code))
- [4.4 调试和审查代码的提示(Prompts for debugging and reviewing code)](#4.4 调试和审查代码的提示(Prompts for debugging and reviewing code))
- [5. 工业级提示工程最佳实践与工程化体系](#5. 工业级提示工程最佳实践与工程化体系)
-
- [5.1 14条核心最佳实践](#5.1 14条核心最佳实践)
- [5.2 提示词实验记录体系](#5.2 提示词实验记录体系)
- [5.3 企业级提示词工程化管理体系](#5.3 企业级提示词工程化管理体系)
- [6. 技术挑战与未来趋势](#6. 技术挑战与未来趋势)
-
- [6.1 核心技术挑战](#6.1 核心技术挑战)
- [6.2 未来发展趋势](#6.2 未来发展趋势)
- 总结
本文基于Google 官方《Prompt Engineering》白皮书拆解,深入解析提示工程的底层数学原理、核心采样算法、进阶推理范式、代码工程化落地体系与工业级最佳实践。
简介
大型语言模型(LLM)的自回归生成本质,决定了提示词(Prompt)是约束模型输出分布、对齐任务目标的核心载体。提示工程并非「话术优化」,而是一门融合了自然语言理解、概率统计、推理系统设计与工程化迭代的交叉技术。本文基于Google官方白皮书的技术框架,从LLM生成的底层数学原理出发,逐层拆解输出配置的采样算法机制、12种核心提示范式的技术逻辑与适用边界、代码场景的全生命周期提示方案,最终落地为工业级可复用的提示工程最佳实践与管理体系。
1. 提示工程技术本质
1.1 LLM的核心生成机制:自回归令牌预测
LLM的本质------令牌(Token)级的自回归条件概率预测引擎,这是所有提示工程技术的底层逻辑。
Token:Token(令牌)是大语言模型(LLM)处理、理解和生成文本的最小计算与语义单元,是自然语言文本和模型可识别的数字向量之间的核心桥梁。文本转 Token 的过程叫做分词,由和大模型配套的专属分词器(Tokenizer)完成,不同模型(Gemini、GPT、LLaMA、Gemma)的分词器训练规则不同,对同一段文本的拆分结果、Token 数量也会有差异,这也是白皮书强调「提示词需要针对特定模型优化」的底层原因之一。
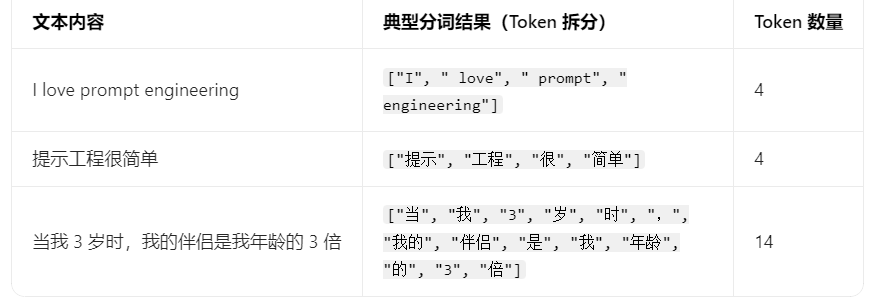
从数学层面,LLM的生成过程可形式化定义为:
对于给定的提示词序列 X = x 1 , x 2 , . . . , x n X = x_1, x_2, ..., x_n X=x1,x2,...,xn,模型的目标是逐一生成输出序列 Y = y 1 , y 2 , . . . , y m Y = y_1, y_2, ..., y_m Y=y1,y2,...,ym,每一步的生成都基于已有的全部上下文,对下一个令牌的条件概率分布进行采样:
P ( y t ∣ y 1 , y 2 , . . . , y t − 1 , X ) P(y_t | y_1, y_2, ..., y_{t-1}, X) P(yt∣y1,y2,...,yt−1,X)
模型会持续迭代这一过程,直到生成终止符(EOS)或达到预设的最大令牌长度。
提示工程的核心技术本质,就是通过结构化设计提示词序列 X X X,精准约束模型的条件概率分布,让模型的采样结果收敛到任务预期的目标分布,同时最小化幻觉、偏离任务、逻辑错误等负向输出的概率。
1.2 提示工程的工程化定义
提示工程给出了严格的工程化定义:提示工程是设计高质量提示以引导LLM产生准确输出的系统性过程,包含需求拆解、提示设计、参数调优、效果评估、迭代调试、版本管理六大核心环节。
这一定义彻底区分了「随意提问」与「提示工程」的边界:前者是无目标的自然语言交互,后者是面向任务目标的、可量化、可迭代、可复现的工程化活动。同时,提示工程并非算法工程师的专属技能,但其高阶应用必须建立在对LLM工作原理、模型特性、采样机制的深度理解之上,这就是为什么现在提示词工程师可以是文科生,因为他们的语言描述能力会更佳。
1.3 提示效果的核心影响因子
提示效果的全维度影响因子,也是提示工程需要优化的全链路变量:
- 模型特性:模型架构、训练数据分布、微调方向、上下文窗口限制,提示词必须针对特定模型(Gemini/GPT/LLaMA/Gemma)做针对性优化,不存在完全通用的提示词;
- 生成配置:温度、Top-K、Top-P、最大令牌长度等采样参数,直接决定令牌的选择逻辑,是提示工程的核心控制变量;
- 提示词设计:结构、措辞、指令清晰度、示例质量、上下文信息、角色定义,是提示工程的核心优化对象;
- 迭代与评估体系:提示词的版本迭代、效果量化评估、边界case测试,决定了提示词的工业级鲁棒性。
2. LLM 的输出配置:采样算法与参数协同机制
脱离生成配置谈提示词优化,是无法实现精准输出控制的。本节深入拆解各配置参数的算法原理、数学逻辑与参数协同规则。
2.1 最大令牌长度(max_tokens):截断机制与语义约束
技术原理
max_tokens 参数定义了模型单次生成的最大令牌数量,其本质是硬截断机制,而非语义层面的简洁性控制。
- 该参数仅控制模型停止生成的阈值,无法让模型主动生成简洁内容。当生成令牌数达到阈值时,模型会无条件终止生成,无论内容是否完整;
- 令牌数量与计算成本、推理时延呈正相关,同时直接影响复杂推理任务的效果:ReAct、思维树等多步推理范式,必须预留足够的令牌长度,避免推理过程被强制中断。
工程化最佳实践
- 语义层面的长度控制,必须在提示词中通过指令明确(如「用1句话总结」「输出不超过200字」),再通过max_tokens做兜底截断;
- 推理类任务的max_tokens建议设置为上下文窗口的1/3以上,为多步推理预留足够空间;
- 生产环境中,需根据任务类型设置max_tokens的上下限,避免超长输出导致的成本溢出与接口超时。
2.2 温度(Temperature):概率分布的熵控制
数学原理
温度参数是LLM采样的核心控制变量,其本质是对softmax函数的输出概率分布进行缩放,改变分布的熵值,从而控制输出的随机程度。
带温度系数的softmax公式定义如下:
P i = exp ( z i / T ) ∑ j = 1 V exp ( z j / T ) P_i = \frac{\exp(z_i / T)}{\sum_{j=1}^{V} \exp(z_j / T)} Pi=∑j=1Vexp(zj/T)exp(zi/T)
其中:
- z i z_i zi 为模型输出的第i个令牌的logits值;
- T T T 为温度系数,取值范围通常为 0 , 2 0, 2 0,2;
- V V V 为模型的词汇表总量。
技术特性
- T = 0(贪婪解码):公式退化为取最大值操作,模型始终选择概率最高的令牌,输出完全确定(仅当两个令牌logits完全相同时,会因平局处理出现微小差异)。适合数学计算、事实问答、代码生成等需要绝对确定性的场景;
- T 降低:概率分布会被锐化,高概率令牌的权重被放大,低概率令牌的权重被抑制,输出更贴合事实、确定性更强,幻觉概率显著降低;
- T 升高:概率分布会被平滑化,不同令牌的概率差异被缩小,模型会更多采样低概率令牌,输出的多样性、创造性显著提升,但同时幻觉、偏离主题的概率也会升高;
- T → +∞:所有令牌的采样概率趋于均等,输出变为完全随机的乱码。
Google官方推荐基线配置
| 任务场景 | 推荐温度值 | 核心适配逻辑 |
|---|---|---|
| 数学计算、逻辑推理、事实检索 | 0 | 完全确定性输出,消除推理过程的随机性 |
| 代码生成、代码调试、数据解析 | 0.1 | 极低随机性,保证代码语法正确、逻辑严谨 |
| 通用问答、内容总结、文本分类 | 0.2 | 低随机性,兼顾输出稳定性与自然度 |
| 文案创作、内容生成、头脑风暴 | 0.7-0.9 | 高随机性,释放模型的创造性与多样性 |
2.3 Top-K与Top-P采样:候选令牌的范围约束
温度参数控制了概率分布的形状,而Top-K与Top-P则是对候选令牌的范围进行硬约束,二者共同构成了采样的前置过滤机制。
Top-K 采样
技术原理:模型仅从概率最高的K个令牌中选择下一个生成内容,过滤掉所有概率排名在K之后的低概率令牌。
- K=1:等同于贪婪解码,仅选择概率最高的令牌;
- K值越大:候选令牌范围越广,输出的创造性越强;
- K值等于词汇表大小:等同于无约束采样,参数完全失效。
核心特性:Top-K设置了候选令牌数量的硬限制,适合词汇分布相对固定的场景(如代码生成),但无法适配不同token预测场景下的概率分布差异------部分场景下前K个令牌的累积概率已接近1,而部分场景下前K个令牌的累积概率仍极低。
Top-P(核采样)
技术原理:模型从累积概率不超过P的最小令牌集合中选择下一个生成内容,按照令牌概率从高到低累加,直到累积概率超过P值停止,最终的令牌集合即为采样候选集。
- P=0:等同于贪婪解码,仅选择概率最高的令牌;
- P=1:无约束采样,参数完全失效;
- P值越接近1:候选令牌范围越广,输出多样性越强。
核心特性:Top-P基于累积概率质量做动态约束,完美适配不同预测场景的概率分布差异。当模型对下一个令牌的预测非常确定时(如代码的固定语法关键字),Top-P会自动缩小候选集;当模型预测不确定性高时(如创意写作),Top-P会自动扩大候选集,是比Top-K更灵活的采样机制。
2.4 采样参数的协同机制与优先级规则
温度、Top-K、Top-P并非独立工作,其交互逻辑直接决定最终的采样行为,这是90%以上开发者都会忽略的核心技术点。
核心协同流程(以Gemini模型为例)
- 模型输出所有令牌的logits值,计算初始概率分布;
- 执行Top-K过滤,保留概率排名前K的令牌;
- 对Top-K过滤后的令牌,执行Top-P过滤,保留累积概率不超过P的令牌集合;
- 对最终的候选令牌集合,通过带温度的softmax缩放概率分布;
- 从缩放后的分布中采样,得到最终的下一个令牌。
极端参数的优先级规则
当参数设置为极端值时,会直接覆盖其他参数的效果,Google给出了明确的优先级结论:
- 当温度T=0,或Top-K=1,或Top-P=0时,其他所有采样参数完全失效,模型执行贪婪解码;
- 当Top-K设置为词汇表大小,或Top-P=1时,该参数完全失效,仅由其他参数控制采样行为;
- 当温度T>10时,温度参数失效,候选集中的所有令牌将被等概率随机采样。
工程化调优方法论
- 优先固定温度参数:根据任务的确定性/创造性需求,确定温度基线;
- 再微调Top-P:通用场景推荐P=0.95作为基线,创意场景可提升至0.99,严谨场景可降低至0.9;
- 最后适配Top-K:Gemini模型默认关闭Top-K(设置为40),代码场景可降低至20,创意场景可提升至40;
- 禁止同时设置多个极端参数,避免参数之间相互抵消,导致输出不可控。
3. 核心提示范式
有12种核心提示范式,本节将从技术原理、适用边界、工程化模板、落地要点四个维度,对每个范式进行深度解析,覆盖从基础通用场景到复杂推理场景的全需求。
3.1 基础提示范式:通用场景的核心解法
基础范式覆盖了80%的工业级通用场景,是所有高阶提示技术的基础,核心解决「指令遵循、格式对齐、任务收敛」三大基础问题。
3.1.1 零样本提示(Zero-shot Prompting)
技术原理:零样本提示是最基础的提示范式,仅通过任务描述与指令定义,让模型直接完成目标任务,无需提供任何示例。其底层依赖模型的指令微调(Instruction Tuning)能力,模型通过训练数据学习到通用的指令遵循逻辑,直接泛化到新的任务。
工程化模板:
# 核心任务定义
[用清晰的动词明确任务目标,如:将以下电影评论分类为正面(POSITIVE)/中性(NEUTRAL)/负面(NEGATIVE)]
# 输出约束
[明确输出格式、长度、内容限制,如:仅返回大写的分类标签,不输出任何额外解释内容]
# 待处理内容
评论:[输入文本]
情绪:示例:
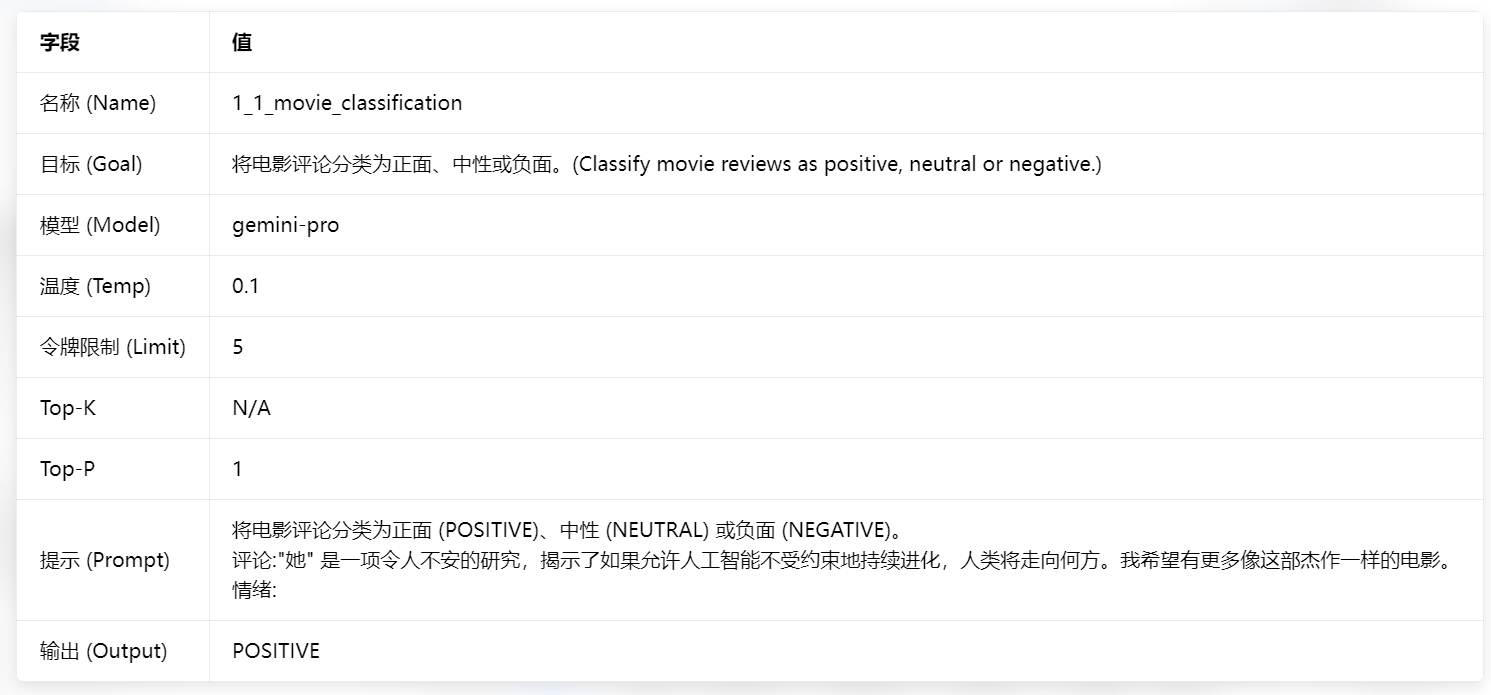
适用场景 :简单文本分类、内容总结、通用问答、翻译等低复杂度、强指令遵循的任务;
技术边界:效果上限完全依赖模型能力,复杂逻辑推理、结构化输出、边缘case处理场景中,错误率显著升高。
3.1.2 单样本/少样本提示(One-shot/Few-shot Prompting)
少样本提示为最重要、最高效的提示工程技术,其工业级落地效果远超零样本提示。
技术原理 :少样本提示的底层是大模型的上下文学习(In-Context Learning, ICL)能力------模型无需微调,仅通过提示词中的几个示例,就能学习到任务的输出格式、逻辑规则、判断标准,并泛化到新的输入中。目前学界对ICL的核心假说包括贝叶斯推理假说、隐式微调假说、任务向量对齐假说,其核心共识是:示例通过上下文窗口,为模型提供了任务的目标分布锚点,大幅缩小了模型的预测空间。
少样本提示示例

此表展示了少样本提示在结构化输出任务 (JSON生成) 中的威力。它显示了提供不同复杂度的示例 (简单披萨vs.双拼披萨) 如何教会模型期望的格式和逻辑,使其能够准确处理新的类似请求。少样本提示利用了模型的上下文学习能力。通过观察示例,模型可以推断出潜在的任务和期望的输出格式,而无需显式的指令调整。因此,示例的质量和多样性至关重要。
工程化设计原则(Google推荐):
- 示例质量优先:示例必须覆盖任务的核心场景、边界case,格式完全统一,无逻辑错误;
- 示例数量:通用任务推荐3-5个示例,复杂分类任务推荐6个以上示例,需平衡效果与上下文窗口占用;
- 分类任务必须混合类别:示例中需打乱不同类别的顺序,避免模型学习到「位置偏差」,而非分类特征本身;
- 示例与目标输入格式完全对齐:示例的输入格式、输出格式必须和最终的任务输入完全一致,最大化ICL的泛化效果。
适用场景 :结构化输出、复杂分类任务、格式固定的生成任务、代码生成、指令遵循难度高的场景;
技术边界:无法解决超出模型知识边界的问题,无法修复模型的固有逻辑缺陷,过多示例会导致上下文窗口溢出与信息衰减。
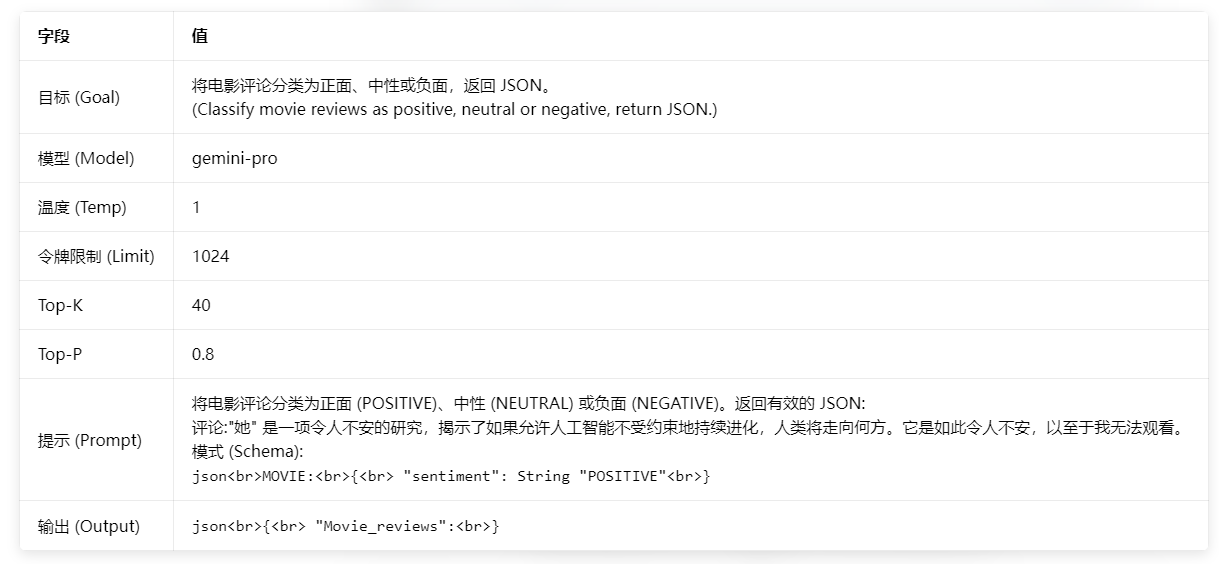
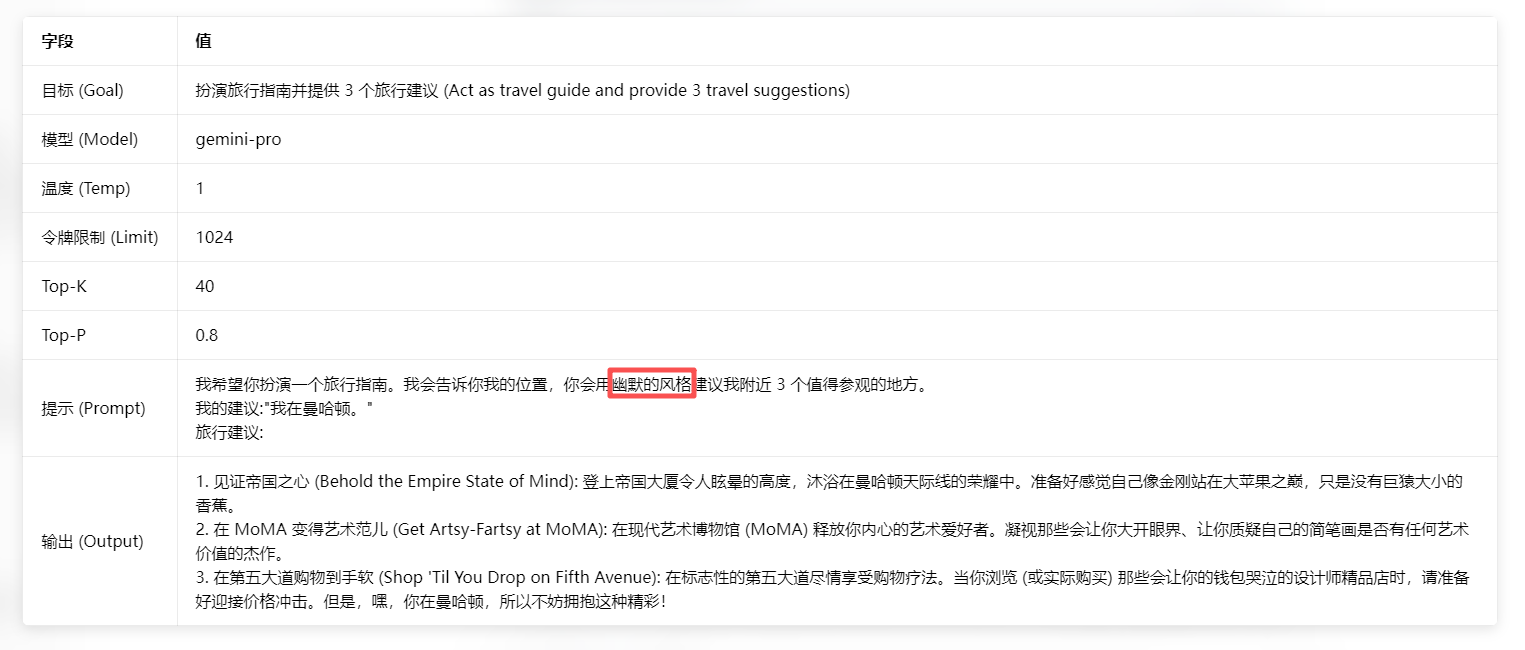
3.1.3 系统、角色和上下文提示 (System, role and contextual prompting)
这三个范式构成了提示词的分层架构,分别对应「全局规则定义、输出风格对齐、任务信息注入」三个维度,工业级提示词通常会三者组合使用。
| 范式 | 技术核心 | 工程化模板 | 核心作用 |
|---|---|---|---|
| 系统提示(System Prompting) | 定义模型的全局任务目标、输出规则、格式约束、安全边界,是模型的「全局行为准则」,在对话全周期生效 | # 系统规则你是一名专业的代码审查助手,核心职责是对输入的Python代码进行安全审计与质量评估。1. 仅返回JSON格式的审查结果,禁止输出额外文本;2. 结果必须包含bug等级、问题描述、修复方案、优化建议四个字段;3. 严格遵循PEP8编码规范进行评估;4. 禁止生成有害代码与违规内容。 |
从全局约束模型的行为,固定输出格式与任务边界,大幅降低提示词的冗余度,提升多轮对话的一致性 |
| 角色提示(Role Prompting) | 为模型分配特定的身份与专业角色,通过激活模型训练数据中该角色的相关知识、语料、表达习惯,让输出贴合角色的专业度、语调、逻辑体系 | # 角色定义我希望你扮演一名拥有10年经验的知识产权律师,专注于互联网领域的著作权纠纷案件。你的回答必须符合中国法律体系,用词严谨,具备法律文书的专业性,同时用通俗的语言解释法律条款。 |
定制输出的专业度、风格与语调,提升输出的领域适配性,让模型的回答更贴合目标受众的需求 |
| 上下文提示(Contextual Prompting) | 为模型提供任务专属的背景信息、参考资料、业务规则、输入数据,解决模型的知识盲区、幻觉问题,让输出完全基于给定的上下文,而非模型的固有训练数据 | # 任务背景你正在为一个80年代复古街机游戏的垂直博客撰写文章,博客的核心受众是复古游戏收藏者与怀旧玩家,内容聚焦于街机游戏的硬件设计、玩法创新、行业历史。# 参考资料[此处粘贴博客的历史文章、行业资料、目标游戏的背景信息]基于以上背景与参考资料,推荐3个符合博客定位的文章主题,并为每个主题撰写200字左右的内容大纲。 |
为模型提供任务专属的信息输入,解决模型的知识滞后问题,大幅降低幻觉概率,让输出完全对齐业务需求 |
-
系统提示示例:
-
角色提示示例:
对于此我们除了让他扮演角色的同时,还可以赋予性格。
-
上下文提示示例:

3.2 进阶推理范式:解决复杂任务的核心技术
面对数学计算、逻辑推理、多步骤规划、实时信息查询等复杂场景,基础范式无法保证输出的准确性,需要通过进阶推理范式,模拟人类的思考过程,提升模型的复合推理能力。
3.2.1 回退提示(Step-back Prompting)
技术原理 :回退提示的核心是抽象推理激活,通过让模型先思考与具体问题相关的高层通用原则、核心背景知识,再用这些抽象原则解决具体问题。该范式解决了LLM的「推理短视」问题------模型容易被具体问题的细节干扰,忽略了底层的通用规则,导致推理错误。
核心执行流程(两步法):
- 回退抽象步骤:设计提示词,让模型输出解决目标问题所需的核心原则、关键设定、通用知识,激活模型的高层先验知识;
- 具体推理步骤:将第一步生成的抽象原则作为上下文,设计提示词让模型基于这些原则,解决具体的目标问题。
示例:
- 传统提示(在与回退提示比较之前)
作为基线,显示了直接请求创意内容(尤其是在高温度下)时可能产生的通用输出。

- 回退提示的第一步 - 生成一般概念
提出一个更抽象、基于原则的问题,以引出与特定任务相关的基础想法或主题。
- 使用回退上下文的最终提示
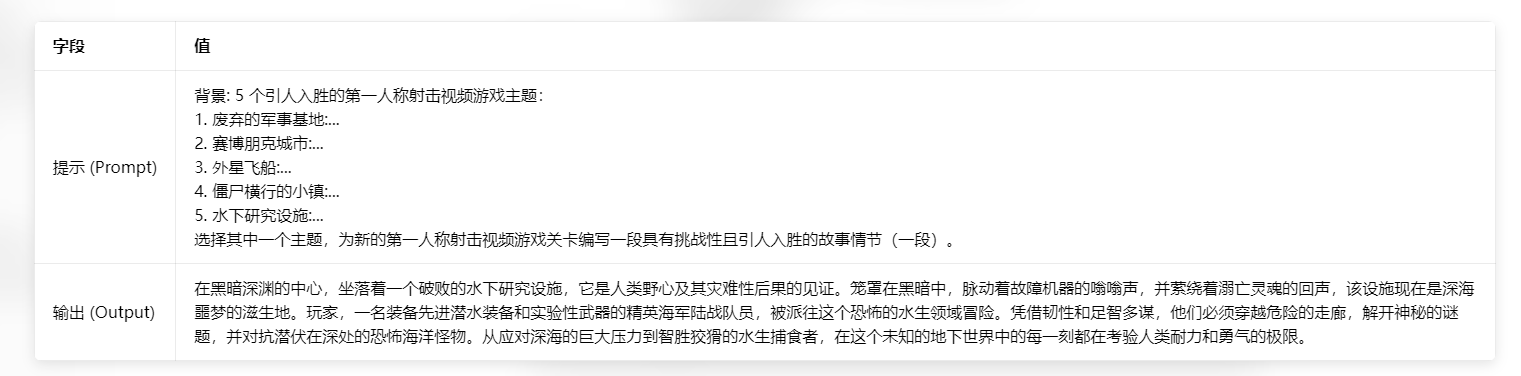
此示例示范了回退方法的有效性。通过首先生成一般概念,然后将它们用作上下文,最终的输出比直接方法更具体、更具主题性,并且可以说更引人入。
通过实验验证,回退提示生成的内容,在主题贴合度、逻辑严谨性、细节丰富度上,远超直接提问的结果,尤其适合创意设计、方案规划、复杂问题拆解等场景。
适用场景 :创意内容生成、复杂方案设计、易被细节干扰的推理任务、跨领域知识应用场景;
技术边界:需要模型具备目标领域的基础抽象知识,无法解决完全超出模型认知边界的问题。
3.2.2 思维链(Chain of Thought, CoT)
技术原理:CoT是提升LLM推理能力的核心范式,其核心是让模型将复杂问题拆解为多步中间推理过程,而非直接输出答案。从技术层面,CoT通过强制模型生成中间推理步骤,将复合推理任务拆解为多个简单的子任务,每一步子任务的推理结果都作为下一步的上下文,大幅降低了单步推理的难度,同时让模型的推理过程可解释、可调试。
CoT解决了LLM的两个核心缺陷:
- 复合推理能力不足:直接提问时,模型无法完成多步逻辑运算,容易出现跳跃性推理错误;
- 推理过程黑盒:直接输出答案时,无法定位模型的错误节点,而CoT让推理过程完全透明。
两大核心实现方式:
- 零样本CoT:仅需在提示词结尾添加触发语「让我们一步一步地思考」,无需额外示例,适合快速落地通用推理场景;
- 少样本CoT:在提示词中提供「问题-推理过程-答案」的完整示例,引导模型遵循指定的推理逻辑,适合高复杂度、高准确率要求的专业场景。
CoT最佳实践:
- 必须让模型先输出推理过程,再给出最终答案,推理过程会改变模型最终答案的概率分布;
- CoT提示必须将温度设置为0,保证推理过程的确定性,避免随机采样导致的逻辑断裂;
- 推理步骤必须可拆解、可验证,避免模型在推理过程中出现幻觉;
- 数学计算、逻辑推理场景,必须在CoT中明确每一步的计算公式与计算过程。
示例:
因为我们要尝试解决数学问题的提示示例(一个常见的 LLM 失败模式------在直接提问时,即使是简单的算术/逻辑推理问题也可能出错,为 CoT 的引入奠定了基础):
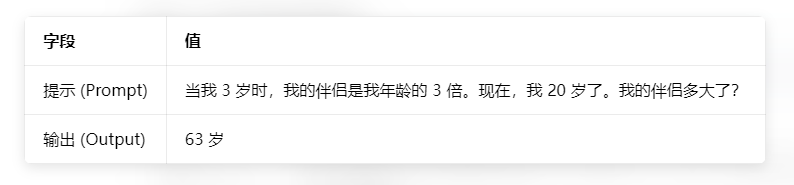
我们进行思维链提示:

同时当与单样本或少样本结合时,思维链提示可能非常强大,比如带单样本的思维链提示示例:

适用场景 :数学计算、逻辑推理、多步骤问题拆解、代码逻辑梳理、法律案例分析、财务核算等需要严谨推理的场景;
技术边界:无法解决模型本身不具备的知识问题,无法修复模型的基础算术缺陷,过长的推理链会出现错误累积与逻辑漂移。
3.2.3 自我一致性(Self-Consistency)
技术原理 :自我一致性是CoT的升级范式,其核心逻辑是正确的答案通常可以通过多条不同的推理路径得到,而错误的答案往往只有零散、不一致的推理过程。该范式通过高温度采样生成多条独立的CoT推理路径,提取每条路径的最终答案,通过多数投票机制选择出现频率最高的答案作为最终结果,大幅降低单条推理路径的错误概率。
核心执行流程:
- 设置较高的温度(0.5-0.7),向模型多次发送相同的CoT提示,生成N条不同的推理路径与对应答案;
- 从每条生成结果中,提取最终的标准化答案;
- 对所有答案进行统计,选择出现次数最多的答案作为最终结果;
- 可选步骤:对多数答案对应的推理路径进行合并优化,输出最终的严谨推理过程。
示例:

此表完美地展示了自我一致性机制。它表明,即使使用 CoT,单次运行(尤其是在鼓励多样性的高温度下)也可能得出不正确或不太稳健的结论(如尝试 2)。生成多个推理路径并进行多数投票(3 次中有 2 次认为是重要)提供了更稳健的最终答案
适用场景 :高风险分类任务、复杂逻辑推理、需要高准确率的专业判断、司法/金融/医疗等容错率极低的场景;
技术边界:计算成本与推理时延随采样次数线性提升,不适合低延迟要求的在线推理场景,当模型对问题完全不具备认知时,多数投票也无法得到正确答案。
3.2.4 思维树(Tree of Thoughts, ToT)
技术原理 :思维树是CoT的泛化升级,将线性的推理过程扩展为树状的搜索结构,模拟人类解决复杂问题时的「多方案探索-状态评估-回溯优化」过程。CoT仅能沿着单一路径推理,一旦出现错误就会导致最终结果错误;而ToT可以同时探索多条推理路径,对每个中间节点的推理状态进行评估,保留有效路径,剪枝无效路径,甚至回溯到之前的节点重新探索,大幅提升复杂规划、组合优化问题的解决能力。
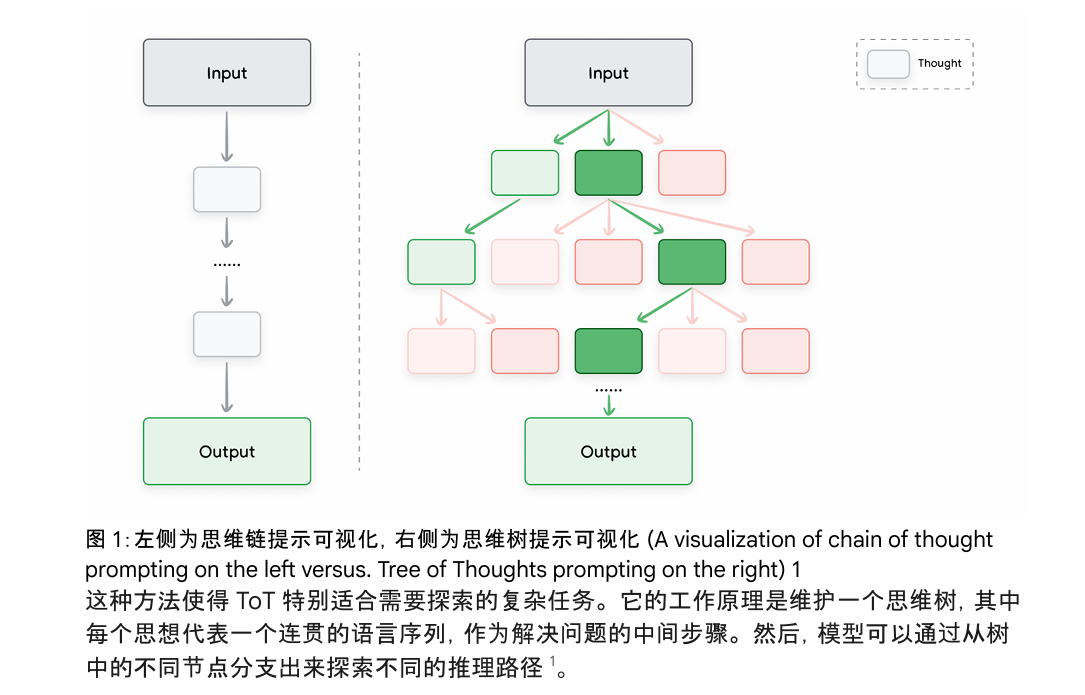
核心执行流程:
- 问题拆解:将目标问题拆解为多个有序的思考步骤,每个步骤对应思维树的一层节点;
- 思想生成:对每个节点,生成多个候选的推理思路与中间结果,作为子节点;
- 状态评估:对每个候选节点进行有效性评估,判断该路径是否能导向正确的结果;
- 搜索与回溯:采用BFS/DFS策略,对树状结构进行搜索,保留高价值路径,剪枝低价值路径,必要时回溯到父节点重新生成思路;
- 结果聚合:对所有有效路径的最终结果进行评估,选择最优结果作为最终输出。
适用场景 :复杂规划任务、组合优化问题、多方案比选、逻辑谜题、创意写作的多支线规划等;
技术边界:实现复杂度高,需要大量的令牌资源与推理算力,通常需要通过代码实现,不适合简单的日常场景。
3.2.5 ReAct(Reason & Act):推理与行动协同范式
技术原理 :ReAct是大模型智能体(Agent)的核心基础范式,其核心是将自然语言推理与外部工具调用深度融合,让模型在推理过程中,通过调用外部工具获取实时信息、执行具体操作,解决LLM固有训练数据滞后、无法与实时环境交互、专业知识不足的核心缺陷。
ReAct模拟了人类解决问题的核心逻辑:先思考需要做什么,再通过行动获取信息,再基于新的信息更新思考,循环往复直到解决问题。
核心执行循环:
- 思考(Thought):模型基于当前的问题与上下文,推理当前需要解决的子问题,制定下一步的行动计划;
- 行动(Act):模型调用对应的外部工具(搜索、代码解释器、API、数据库等),执行计划中的操作;
- 观察(Observation):模型接收工具返回的执行结果,获取新的上下文信息;
- 循环迭代:模型基于观察结果更新思考,制定新的行动计划,直到找到问题的最终解决方案。
示例:让 LLM 找出:Metallica 乐队成员共有多少个孩子(基于LangChain + Vertex AI)
python
# ReAct Agent 核心实现:查询Metallica乐队成员的孩子总数
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain.llms import VertexAI
import os
# 配置SerpAPI密钥(用于谷歌搜索)
os.environ["SERPAPI_API_KEY"] = "YOUR_SERPAPI_KEY"
# 提示:Metallica 乐队成员有多少个孩子?
prompt = "How many kids do the band members of Metallica have?"
# 初始化LLM,低温度保证事实准确性
llm = VertexAI(model_name="gemini-pro", temperature=0.1)
# 加载工具:此处使用SerpAPI网络搜索,可扩展代码解释器、API等工具
tools = load_tools(["serpapi"], llm=llm)
# 初始化ReAct Agent,零样本模式通过工具描述自动选择工具
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 执行Agent任务
result = agent.run(prompt)
print("最终答案:", result)输出:
找出了 Metallica 乐队有四名成员。然后它搜索每个乐队成员以请求孩子的总数,并将总数相加。最后,它返回孩子的总数作为最终答案。

执行过程的核心逻辑 :
模型会自动执行「思考-行动-观察」的循环:先推理出需要先获取Metallica的乐队成员名单,再逐个搜索每个成员的孩子数量,最后累加得到总数,全程无需人工干预,自动完成多步工具调用与推理。
适用场景 :需要实时信息的问答、多工具协同的复杂任务、业务流程自动化、智能客服、企业级知识库问答等;
技术边界:需要配套的工具调用体系与权限管理,工具返回结果的质量直接决定推理效果,长循环中容易出现推理漂移,需要配套错误重试与状态管理机制。
3.2.6 自动提示工程(Automatic Prompt Engineering, APE)
技术原理 :APE是提示工程的元级应用,核心是用大模型自动化完成提示词的生成、评估、迭代优化全流程,实现提示工程的自动化与规模化。其底层逻辑是将提示词本身作为优化对象,通过LLM的生成能力与评估能力,构建提示词优化的闭环,大幅降低人工提示词优化的成本,同时提升提示词的泛化能力。
实现流程:
- 提示生成阶段:基于核心任务目标,让LLM生成多个候选提示词/表达变体,覆盖不同的措辞、结构、风格;
- 提示评估阶段:定义量化评估指标(如BLEU、ROUGE、准确率、召回率),构建测试数据集,对每个候选提示词进行效果打分;
- 提示筛选与迭代阶段:选择评估分数最高的提示词,进行人工微调或自动化迭代优化,最终落地为生产环境的提示词;
- 持续优化阶段:基于线上运行的效果数据,持续自动化迭代优化提示词,适配模型更新与业务变化。
示例:使用 LLM 生成提示
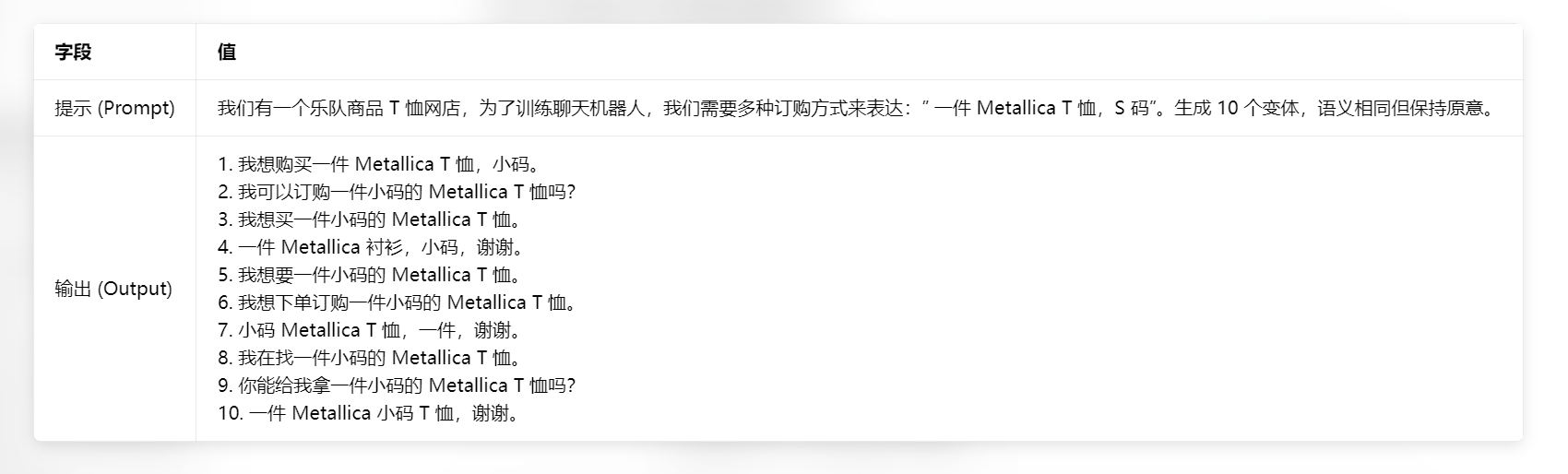
此表示范了 APE 的核心思想------使用 LLM 本身来为给定任务生成多样化的措辞或指令,自动化了提示设计或数据增强的部分创造性过程
适用场景 :客服机器人训练、批量场景的提示词优化、同一场景的多表达方式生成、企业级提示词规模化管理等;
技术边界:需要高质量的测试数据集与评估体系,评估指标的设计直接决定最终提示词的效果,完全自动化的提示优化仍需人工校验。
4. 代码提示工程
LLM已经成为开发者的核心提效工具,而提示词的设计直接决定了生成代码的质量、可用性、安全性与可维护性。
4.1 编写代码的提示(Prompts for writing code)
代码生成是开发者最高频的场景,工业级代码生成的提示词设计核心框架,包含6个核心要素:
- 明确编程语言与运行环境:指定语言版本、运行平台、依赖库版本,避免生成不兼容的代码;
- 清晰定义核心功能:用结构化的语言描述代码的输入、输出、核心逻辑、业务规则;
- 约束代码规范:明确编码规范(如PEP8、Google代码规范)、注释要求、异常处理要求;
- 性能与安全要求:指定性能优化目标、安全编码规范(如防SQL注入、XSS攻击);
- 测试要求:要求生成对应的单元测试用例,验证代码功能;
- 示例补充:复杂场景通过少样本示例,指定代码的结构与风格。
工程化模板:
# 代码生成需求
1. 编程语言:Python 3.10+
2. 核心功能:实现一个批量文件重命名工具,支持用户输入文件夹路径、文件名前缀,为文件夹内所有文件添加前缀重命名
3. 核心要求:
- 必须检查文件夹是否存在,不存在时给出明确提示
- 必须区分文件与子文件夹,仅重命名文件,不处理子目录
- 必须保留原文件的扩展名
- 必须添加异常处理,捕获文件操作过程中的所有异常
- 必须添加中文注释,注释清晰易懂
4. 编码规范:严格遵循PEP8编码规范
5. 额外要求:生成对应的单元测试用例,使用pytest框架示例:

注意:展示的效果不太好,事实上直接给出代码会变成这样规范的形式
bash
#!/bin/bash
# 询问文件夹名称
echo "输入文件夹名称:"
read folder_name
# 检查文件夹是否存在
if [ ! -d "$folder_name" ]; then
echo "文件夹不存在。"
exit 1
fi
# 获取文件夹中的文件列表
files=("$folder_name"/*)
# 通过在文件名前加上 "draft_" 来重命名每个文件
for file in "${files[@]}"; do
# 从完整路径中提取基本文件名
base_name=$(basename "$file")
# 构建新的文件路径
new_file_path="$folder_name/draft_$base_name"
# 重命名文件
mv "$file" "$new_file_path"
done
echo "文件重命名成功。"4.2 解释代码的提示(A prompt for explaining code)
核心提示设计要点:
- 明确解释的受众(编程新手/资深开发者/业务人员);
- 指定解释的粒度(逐行解释/核心逻辑解释/算法原理讲解);
- 要求补充代码的适用场景、边界条件、潜在风险。
工程化模板:
请为以下Bash代码做逐行解释,受众是Linux入门新手,需要解释每个命令的作用、参数含义,以及代码的整体执行流程,同时说明代码的适用场景与注意事项。
[此处粘贴待解释的代码]示例:

4.3 翻译代码的提示(Prompts for translating code)
核心提示设计要点:
- 明确源语言与目标语言,指定版本与依赖库;
- 要求贴合目标语言的语法规范与最佳实践,而非直译;
- 保留原代码的所有功能、异常处理、注释;
- 说明翻译过程中的适配修改点与原因。
工程化模板:
将以下Bash代码翻译成Python代码,要求:
1. 适配Python 3.10+版本,使用os、shutil标准库,不使用第三方依赖
2. 完全保留原代码的所有功能与异常处理逻辑
3. 遵循PEP8编码规范,添加中文注释
4. 翻译完成后,说明代码的适配修改点与原因
[此处粘贴待翻译的代码]示例(将之前bash转化为python):
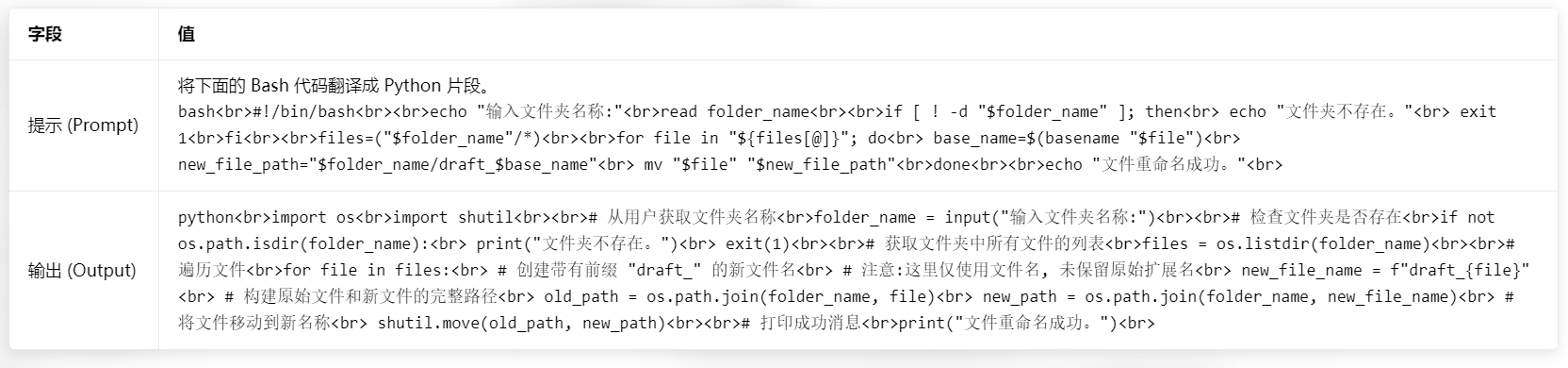
注意:代码会按照格式给出来的
python
import os
import shutil
# 从用户获取文件夹名称
folder_name = input("输入文件夹名称:")
# 检查文件夹是否存在
if not os.path.isdir(folder_name):
print("文件夹不存在。")
exit(1)
# 获取文件夹中所有文件的列表
files = os.listdir(folder_name)
# 遍历文件
for file in files:
# 创建带有前缀 "draft_" 的新文件名
# 注意:这里仅使用文件名, 未保留原始扩展名
new_file_name = f"draft_{file}"
# 构建原始文件和新文件的完整路径
old_path = os.path.join(folder_name, file)
new_path = os.path.join(folder_name, new_file_name)
# 将文件移动到新名称
shutil.move(old_path, new_path)
# 打印成功消息
print("文件重命名成功。")4.4 调试和审查代码的提示(Prompts for debugging and reviewing code)
代码调试提示的核心是必须提供完整的错误回溯信息,这能让模型的错误定位准确率提升80%以上。
调试提示工程化模板:
以下Python代码运行时出现了报错,报错信息已提供,请完成以下工作:
1. 精准定位错误的根本原因,详细解释错误发生的逻辑;
2. 修复代码中的所有bug,保证代码可正常运行;
3. 对代码进行全面的优化,包括异常处理、代码规范、健壮性、可读性;
4. 说明所有的修改点与优化原因。
报错回溯信息:
[此处粘贴完整的报错Traceback信息]
待调试代码:
[此处粘贴完整的代码]代码审查提示工程化模板:
请对以下Python代码进行全面的代码审查,审查维度包括:
1. 语法错误、逻辑bug、潜在的运行风险
2. 安全漏洞,包括注入风险、权限控制、数据泄露等
3. 代码规范与可读性,是否符合PEP8规范
4. 性能优化点,是否存在低效的代码逻辑
5. 可维护性与可扩展性优化建议
最终输出要求:
- 按照审查维度分点说明,每个问题必须给出具体的修改方案
- 输出优化后的完整代码
- 代码基于Python 3.10+版本
待审查代码:
[此处粘贴完整的代码]示例:

运行代码会发生报错,那么我们给一个prompt:
问题描述
以下 Python 代码给出了错误:
Traceback (most recent call last): File "/Users/leeboonstra/Documents/test_folder/rename_files.py", line 7, in <module> text = toUpperCase(prefix) NameError: name 'toUpperCase' is not defined调试要求
调试错误所在,并解释如何改进代码。
那么结果不仅会给出修改后的完整代码,还会给出代码的解析和代码哪里做了修改.
5. 工业级提示工程最佳实践与工程化体系
Google经过大量工业级项目验证的核心经验,本节将其深化为可落地的工程化体系,覆盖提示词的设计、迭代、管理、评估全流程。
5.1 14条核心最佳实践
- 提供示例是最高优先级的实践:少样本示例是提升提示效果最有效的方式,任何场景下,优先通过示例明确任务要求;
- 简洁设计,清晰优先:提示词的核心是清晰易懂,避免复杂行话、冗余信息、歧义表述,用直接的动词定义任务;
- 对输出要求极致具体:明确输出的长度、格式、内容边界、风格、约束条件,不要让模型猜测你的需求;
- 优先使用指令,而非约束:多告诉模型「要做什么」,少告诉模型「不要做什么」,积极指令的效果远好于消极约束,仅在安全合规场景使用约束;
- 双重控制输出长度:通过提示词的语义指令控制长度,再通过max_tokens做兜底截断;
- 用变量实现提示词复用:在提示词中使用{变量}模板,适配不同的输入场景,实现提示词的工程化复用;
- 多维度实验迭代:同一个需求,尝试不同的措辞、结构、格式、风格,对比效果,找到最优解;
- 分类任务的少样本示例必须混合类别:避免模型学习位置偏差,保证泛化能力;
- 持续适配模型更新:模型版本迭代后,必须重新测试提示词效果,调整提示词适配新的模型特性;
- 非创意场景优先使用结构化输出:数据提取、分类、解析等任务,要求输出JSON等结构化格式,限制幻觉,提升下游系统的兼容性;
- 协同实验,交叉验证:多个人共同设计提示词,对比不同思路的效果,避免个人思维盲区;
- CoT提示必须遵循规范:推理在前,答案在后,温度设置为0,保证推理的确定性;
- 必须全链路记录提示词实验:用结构化的表格,记录每一次提示词实验的名称、版本、目标、模型、配置参数、提示词内容、输出结果、效果评估,避免重复踩坑;
- 迭代是提示工程的核心:没有万能的提示词,必须持续测试、优化、迭代,直到满足业务需求。
5.2 提示词实验记录体系
没有记录的提示工程,就是无效的工程。工业级场景下,必须建立标准化的提示词实验记录体系,模板如下:
| 字段 | 描述 | 示例值 |
|---|---|---|
| 提示名称与版本 | 提示词的唯一标识与版本号,便于追溯 | movie_review_classification_v1.2 |
| 任务目标 | 一句话明确提示词的核心任务目标 | 将电影评论分类为正面/中性/负面,仅返回大写标签,准确率≥95% |
| 使用模型 | 模型名称与版本号 | gemini-1.5-pro |
| 温度 | 采样温度参数 | 0.1 |
| 最大令牌数 | max_tokens参数 | 10 |
| Top-K | Top-K采样参数 | 20 |
| Top-P | Top-P采样参数 | 0.9 |
| 完整提示词 | 本次实验的完整提示词文本 | 粘贴完整提示词 |
| 测试输出结果 | 核心测试case的输出结果 | 粘贴输出结果 |
| 效果评估 | 量化评估结果,标注是否达标 | 测试集准确率92%,未达标,边界case分类错误 |
| 问题记录 | 本次实验的问题与优化方向 | 负面评论的边界case识别错误,需补充少样本示例 |
5.3 企业级提示词工程化管理体系
工业级落地时,需建立完整的提示词管理体系,包含四大核心模块:
- 版本管理体系:将提示词纳入代码库管理,和业务代码一样进行版本控制、分支管理、变更评审,记录每一次变更的原因与效果;
- 测试与评估体系:为每个提示词构建标准化的测试数据集,包含常规case、边界case、异常case,建立量化评估指标(准确率、召回率、格式合规率、幻觉率),每次提示词变更都必须执行自动化测试;
- 灰度发布体系:提示词变更时,采用灰度发布策略,先小流量验证效果,再全量上线,避免提示词变更导致的线上业务故障;
- 监控与告警体系:线上运行时,监控提示词的输出格式合规率、异常率、时延、成本,建立异常告警机制,及时发现模型迭代、提示词退化导致的业务问题。
6. 技术挑战与未来趋势
6.1 核心技术挑战
- 上下文窗口限制与信息衰减:长上下文场景下,模型对提示词中间部分的信息关注度显著降低,导致长提示词的效果衰减;
- 幻觉问题:即使是最完善的提示词,也无法完全消除模型的幻觉,需要结合RAG、工具调用等技术共同缓解;
- 长链推理的错误累积:多步推理场景下,前序步骤的错误会不断累积,导致最终结果完全错误,需要配套推理校验、回溯机制;
- 模型迭代的兼容性问题:大模型版本迭代后,原有提示词的效果可能出现显著退化,需要持续适配与优化;
- 提示词的安全风险:提示词注入、越狱攻击、数据泄露等安全问题,是企业级落地必须解决的核心风险。
6.2 未来发展趋势
- 提示工程的自动化与智能化:APE技术将持续发展,实现提示词的全自动生成、评估、优化、迭代,大幅降低人工成本;
- 提示词的编译优化:类似代码的编译过程,将自然语言提示词编译为模型最优的输入格式,提升提示词的执行效率与效果;
- 多智能体系统的提示工程:面向多智能体协同场景,设计角色分工、任务协同、通信机制的提示工程体系;
- 端侧模型的提示工程优化:针对端侧大模型的算力、内存限制,优化提示词的长度、结构,实现端侧场景的高效提示;
- 提示工程与模型微调的融合:将提示工程与低秩适配(LoRA)等微调技术结合,实现「提示+微调」的协同优化,最大化模型的任务效果。
总结
随着大模型技术的快速发展,提示工程已经从「锦上添花的技巧」,变成了「释放大模型全部潜力的核心工程能力」。提示工程从来不是玄学,而是一门建立在数学、概率统计、自然语言理解、软件工程之上的严谨技术。
对于开发者而言,掌握提示工程,本质上是掌握了与大模型协作的核心语言,能够将大模型的能力转化为具体的业务价值。