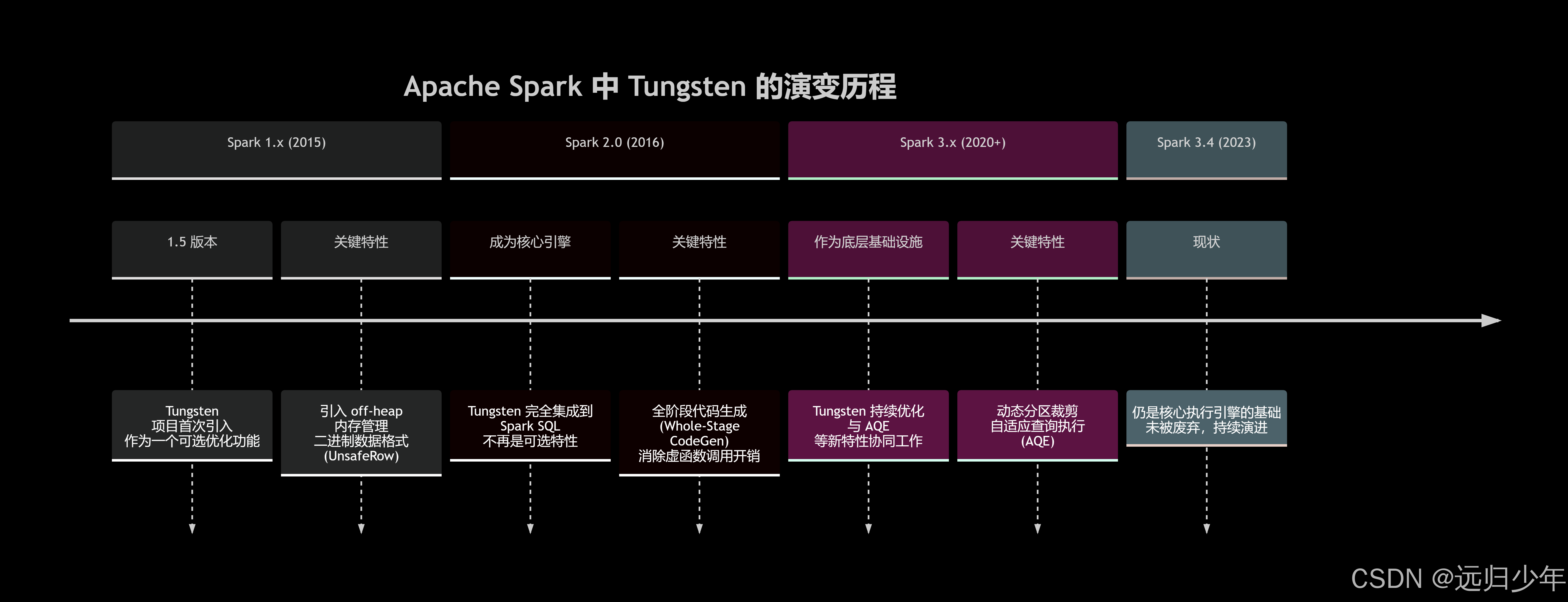
摘要: Tungsten 是 Apache Spark 于 2015 年发布的底层执行引擎,旨在突破 JVM 的内存管理与 CPU 效率瓶颈,通过堆外内存、缓存感知计算、向量化执行和 WholeStage CodeGen 四大机制,将 Spark 的执行性能提升了数倍乃至数十倍。本文从背景出发,逐层剖析各项技术的实现原理,并提供新老方案的详细对比。
目录
- [背景:JVM 的天花板](#背景:JVM 的天花板)
- [Tungsten 整体架构](#Tungsten 整体架构)
- [核心机制一:堆外内存与 UnsafeRow](#核心机制一:堆外内存与 UnsafeRow)
- 核心机制二:缓存感知计算
- [核心机制三:向量化执行与 SIMD](#核心机制三:向量化执行与 SIMD)
- [核心机制四:WholeStage CodeGen](#核心机制四:WholeStage CodeGen)
- 新老方案对比
- 实际使用效果与调优指南
- 总结
背景:JVM 的天花板
Spark 早期构建在 JVM 之上,这带来了跨平台能力和丰富的生态,却也继承了 JVM 在大数据场景下的三个根本性瓶颈:
① 内存效率低下
Java 对象模型为每个对象附加了 12~16 字节的对象头(Mark Word + 类指针),一个仅包含两个 int 字段的对象实际需要占用 24 字节,而其真实数据只有 8 字节。在处理数十亿行数据时,这种膨胀意味着大量内存被元数据消耗。
② GC 停顿不可控
Spark 作业大量创建和销毁 Java 对象,频繁触发 JVM 的垃圾回收。Full GC 时整个 JVM 暂停(Stop-The-World),在生产环境中常见秒级甚至十几秒的 GC 停顿,严重影响作业稳定性。
③ CPU 利用率不足
传统的火山模型(Volcano Model)每次从下层算子拉取一行数据,产生大量虚函数调用,CPU 分支预测器无法有效工作,流水线频繁被清空;数据以行式存储,无法利用 CPU 的 SIMD 向量化指令批量处理。
Tungsten 项目正是为了系统性地解决这三个问题而生。
Tungsten 整体架构


Tungsten 的设计哲学是让 Spark 贴近硬件,而不是依赖 JVM 这个中间层。它的四大机制分别从内存管理、数据访问模式、指令级并行和代码结构四个维度,系统性地消除 JVM 带来的性能损耗。
核心机制一:堆外内存与 UnsafeRow
传统 JVM 对象模型的问题

UnsafeRow 的内存格式
UnsafeRow 是一块连续的堆外(或堆内)内存区域,其格式严格定义为三部分:
| 区域 | 大小 | 说明 |
|---|---|---|
| Null 位图 | ceil(N/64) × 8 字节 |
每个 bit 表示对应字段是否为 null |
| 固定宽度字段区 | N × 8 字节 |
所有字段统一占 8 字节(int/long/double 直接存值,string/array 存偏移量+长度) |
| 变长字段区 | 按需 | 字符串、数组等变长数据紧跟其后 |
这种布局的核心优势是:随机访问任意字段的时间复杂度为 O(1),只需一次指针加法计算偏移量即可,完全不依赖 JVM 的对象图遍历。
堆外内存的配置
python
# 启用堆外内存(默认关闭)
spark = SparkSession.builder \
.config("spark.memory.offHeap.enabled", "true") \
.config("spark.memory.offHeap.size", "4g") \
.getOrCreate()堆外内存完全由 Tungsten 的 MemoryManager 管理,通过 sun.misc.Unsafe 的 allocateMemory / freeMemory 直接申请和释放操作系统内存,JVM GC 无法感知,也不会对其进行扫描和回收。
核心机制二:缓存感知计算
CPU Cache 与内存访问延迟

现代 CPU 的性能不仅仅取决于时钟频率,数据访问模式同样关键。如果程序的内存访问是随机的,CPU 需要频繁从主内存加载数据,带来大量缓存缺失(Cache Miss),性能急剧下降。
缓存友好的排序算法
传统 Spark 在排序时需要移动完整的行数据(Row Object),这些对象分散在堆的各处,排序过程会产生大量随机内存访问。
Tungsten 的策略是只排序指针:
传统方式(移动完整行):
┌──────────────────────────────────────────────────┐
│ [Row A: 200B] → swap → [Row B: 200B] → swap ... │ 大量内存移动
└──────────────────────────────────────────────────┘
Tungsten 方式(排序指针 + key):
┌──────────────────────────────────────────────┐
│ [(ptr_A, key_A), (ptr_B, key_B), ...] │ 64B 指针数组,完整放入 L1 Cache
└──────────────────────────────────────────────┘
排序完成后,按指针顺序顺序读取完整行
→ 顺序访问,CPU prefetch 全部命中Tungsten 还将 QuickSort 替换为 RadixSort(基数排序):基数排序的访问模式是顺序的,非常适合缓存感知场景,在整数类型的 key 上比 QuickSort 快 3~5 倍。
核心机制三:向量化执行与 SIMD
逐行处理 vs 向量化批处理

SIMD(Single Instruction Multiple Data,单指令多数据)是现代 CPU 的核心特性。Intel AVX2 寄存器宽 256 位,可同时处理 8 个 32 位整数;AVX-512 宽 512 位,可处理 16 个。列式存储使同一列的数据在内存中连续排列,天然与向量寄存器对齐,是实现 SIMD 的前提。
Tungsten 的 ColumnarBatch 格式将数据以列式内存布局组织,每列是一个连续的原始数组,配合 JVM 的 JIT 编译器生成 SIMD 指令,实现向量化的 filter、scan、hash 操作。
核心机制四:WholeStage CodeGen
这是 Tungsten 中影响最深远的机制,也是性能提升最显著的部分。
火山模型的根本问题

CodeGen 的编译流程
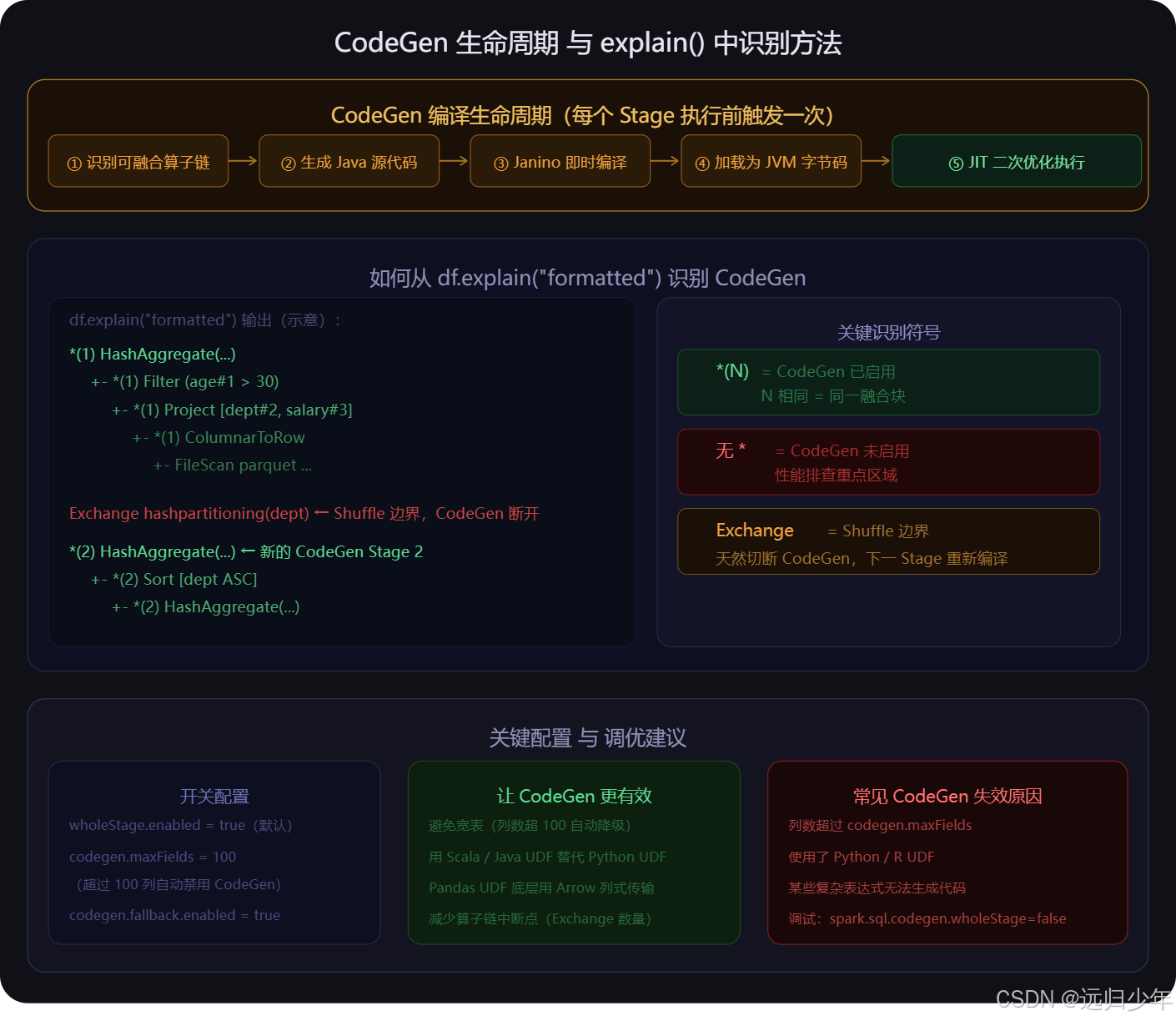
WholeStage CodeGen 使用 Janino(一个轻量级的 Java 编译器)在运行时动态生成并编译 Java 代码。生成的代码经过 JVM 的 JIT(Just-In-Time)编译器进行二次优化,最终生成包含 SIMD 指令的本地机器码。
整个编译过程在每个 Stage 开始执行前触发一次,编译耗时通常在 100ms 以内,对长时间运行的作业几乎没有影响。
识别 CodeGen 是否生效
sql
-- 使用 explain 查看执行计划
df.explain("formatted")输出示例:
== Physical Plan ==
*(1) HashAggregate(keys=[dept#1], functions=[avg(salary#2)]) ← *(1) 表示 CodeGen 已启用
+- *(1) Filter (age#3 > 30)
+- *(1) Project [dept#1, salary#2, age#3]
+- *(1) FileScan parquet [dept#1,salary#2,age#3]
Exchange hashpartitioning(dept#1, 200) ← Shuffle 边界,CodeGen 断开
*(2) HashAggregate(keys=[dept#1], functions=[partial_avg(...)] ← 新的 CodeGen Stage*(N) 星号前缀表示该算子已被 CodeGen 融合,数字相同表示属于同一个融合块。Exchange(Shuffle)是天然的 CodeGen 边界,下一个 Stage 重新开始编译。
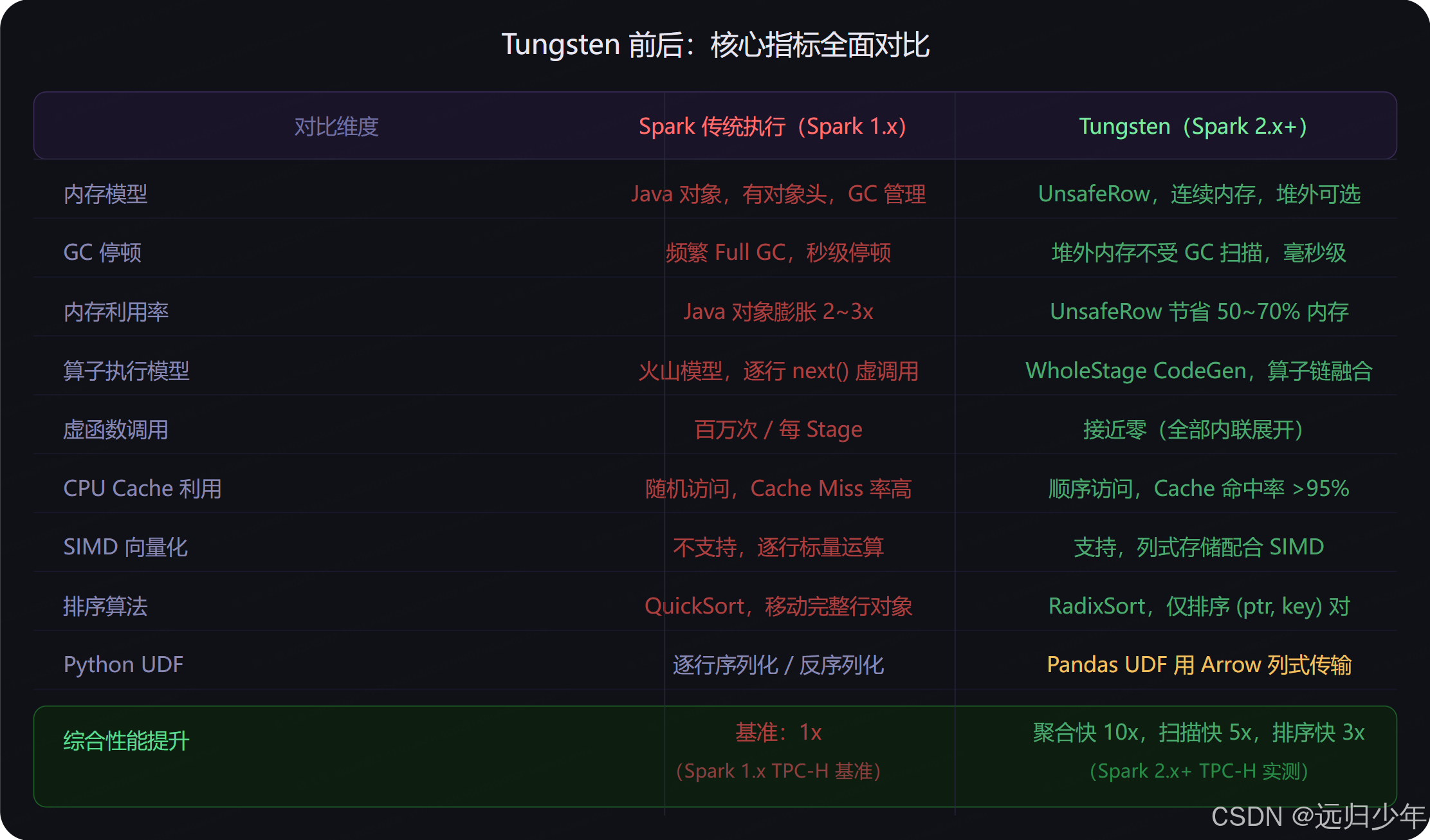
新老方案对比
实际使用效果与调优指南
验证 Tungsten 是否启用
python
# 默认全部开启,可通过以下方式验证
spark.conf.get("spark.sql.tungsten.enabled") # 已废弃,默认 true
spark.conf.get("spark.sql.codegen.wholeStage") # WholeStage CodeGen
spark.conf.get("spark.sql.codegen.maxFields") # 最大列数限制,默认 100
spark.conf.get("spark.memory.offHeap.enabled") # 堆外内存
# 查看 CodeGen 生成的代码(调试用)
spark.conf.set("spark.sql.codegen.comments", "true")
spark.conf.set("spark.sql.codegen.logging.maxLines", "1000")影响 Tungsten 效果的常见场景
场景一:宽表导致 CodeGen 降级
python
# 列数超过 codegen.maxFields(默认 100)时 CodeGen 自动关闭
wide_df = spark.read.parquet("wide_table_with_200_cols/")
# 解决方案:只选择需要的列
narrow_df = wide_df.select("col1", "col2", "col3", "col4", "col5")
# 或调大阈值(需权衡生成代码的大小)
spark.conf.set("spark.sql.codegen.maxFields", "200")场景二:Python UDF 打断 CodeGen 链
python
from pyspark.sql.functions import udf
from pyspark.sql.types import DoubleType
# 不推荐:Python UDF 跨语言调用,CodeGen 完全失效
@udf(returnType=DoubleType())
def calc_tax_python(salary):
return salary * 0.2
df.withColumn("tax", calc_tax_python("salary")) # 无法 CodeGen
# 推荐方案一:改用内置函数(完整 CodeGen)
from pyspark.sql.functions import col
df.withColumn("tax", col("salary") * 0.2) # 完整 CodeGen ✓
# 推荐方案二:Pandas UDF(Arrow 列式传输,批量处理)
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf(DoubleType())
def calc_tax_pandas(salary: pd.Series) -> pd.Series:
return salary * 0.2
df.withColumn("tax", calc_tax_pandas("salary")) # 批量传输,效率高 ✓场景三:堆外内存减少 GC 停顿
python
# 适用于:大量 cache() / Shuffle 操作,GC 停顿频繁的场景
spark = SparkSession.builder \
.config("spark.executor.memory", "8g") \
.config("spark.memory.offHeap.enabled", "true") \
.config("spark.memory.offHeap.size", "4g") \
.getOrCreate()
# 监控 GC 停顿:在 Spark UI 的 Executor 页面查看 GC Time 列
# 如果 GC Time / Task Time > 10%,考虑开启堆外内存性能调优决策流程
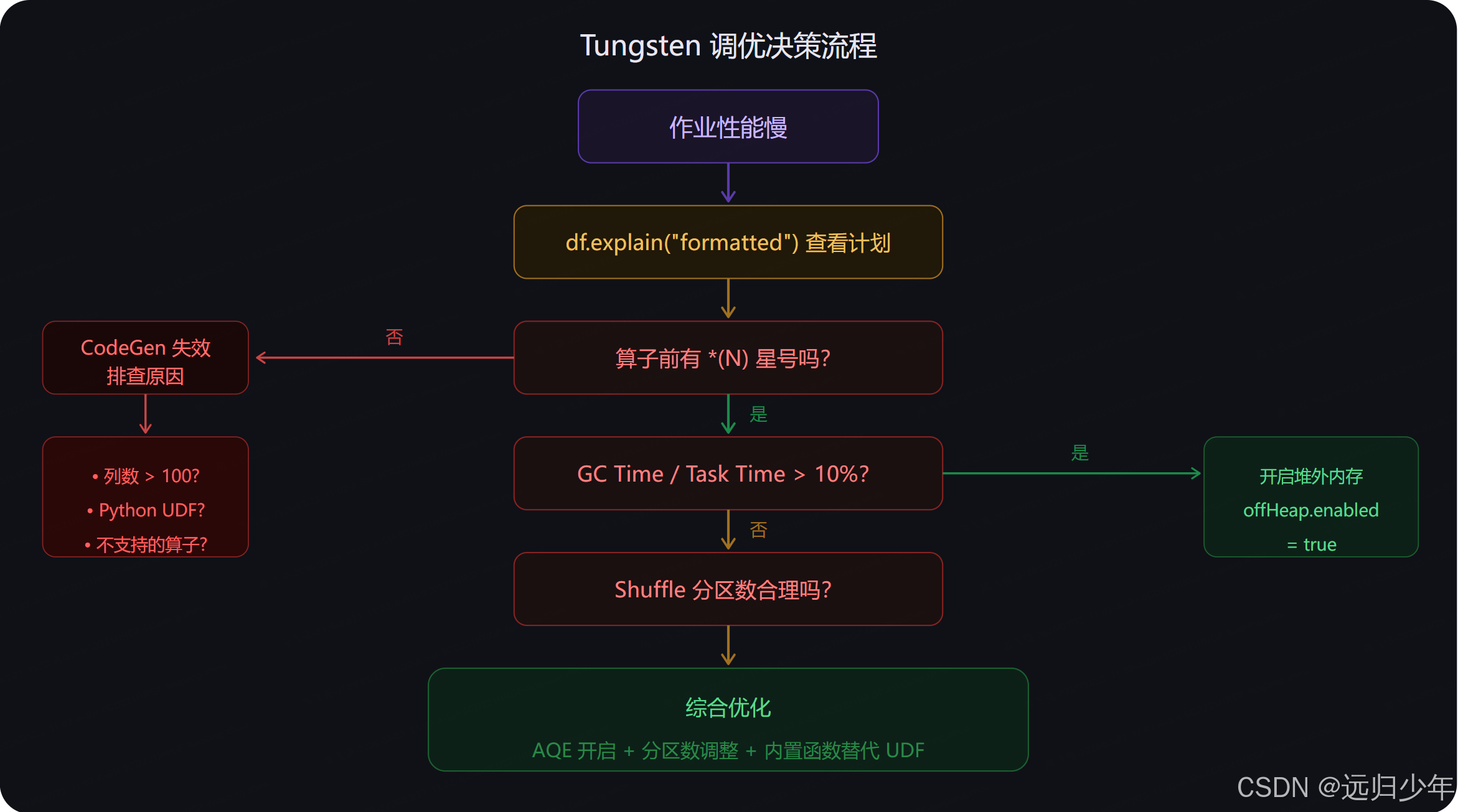
关键配置速查
python
# ── WholeStage CodeGen ──
spark.conf.set("spark.sql.codegen.wholeStage", "true") # 默认 true
spark.conf.set("spark.sql.codegen.maxFields", "100") # 最大列数,超出自动关闭
spark.conf.set("spark.sql.codegen.fallback.enabled", "true") # 失败时优雅降级
# ── 堆外内存 ──
spark.conf.set("spark.memory.offHeap.enabled", "true")
spark.conf.set("spark.memory.offHeap.size", "4g") # 按 executor 内存的 50% 设置
# ── 向量化读取(Parquet / ORC)──
spark.conf.set("spark.sql.parquet.enableVectorizedReader", "true") # 默认 true
spark.conf.set("spark.sql.orc.enableVectorizedReader", "true") # 默认 true
spark.conf.set("spark.sql.columnVector.offheap.enabled", "true") # 列向量也用堆外
# ── AQE(配合 Tungsten 效果更好)──
spark.conf.set("spark.sql.adaptive.enabled", "true") # Spark 3.0+ 默认 true
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "64mb")总结
Tungsten 本质上是一次从上到下的硬件感知重构:
| 机制 | 解决的问题 | 性能收益 |
|---|---|---|
| UnsafeRow + 堆外内存 | JVM 对象膨胀 + GC 停顿 | 内存节省 50~70%,GC 从秒级降至毫秒级 |
| 缓存感知计算 | CPU Cache Miss 频繁 | 排序性能提升 3~5x |
| SIMD 向量化 | CPU 利用率低,逐行处理 | 扫描 / Filter 吞吐提升 2~8x |
| WholeStage CodeGen | 火山模型虚调用开销 | 聚合类操作提升 10x+ |
对使用者而言,这四个机制默认全部开启,无需手动干预。需要关注的场景是:列数超过 100 导致 CodeGen 降级,Python UDF 打断执行链,以及 GC 停顿影响稳定性时考虑开启堆外内存。df.explain("formatted") 中的 *(N) 星号是判断 Tungsten 是否充分发挥作用最直接的指标。
参考资料
本文基于 Apache Spark 3.x / 4.x,部分实现细节因版本而异。