在现代高并发架构中,Redis凭借其卓越的性能成为了事实上的标准缓存解决方案。然而,单点故障是任何生产系统无法容忍的风险。主从复制(Master-Slave Replication) 不仅是实现数据冗余、保障高可用(High Availability)的基础,也是读写分离、横向扩展读能力的核心手段。
一、核心原理深度剖析
Redis的主从复制经历了从早期简单的全量同步到2.8版本引入PSYNC支持部分重同步(增量同步)的演进。当前主流版本(6.x/7.x)均基于PSYNC命令实现智能同步。
1. 全量同步(Full Resynchronization)
全量同步通常发生在以下场景:
- 从节点首次连接主节点。
- 从节点断开时间过长,主节点的
repl-backlog-buffer中已覆盖掉了从节点缺失的数据。 - 从节点重启且RunID发生变化,主节点认为这是一个全新的从节点。
全量同步流程图解:
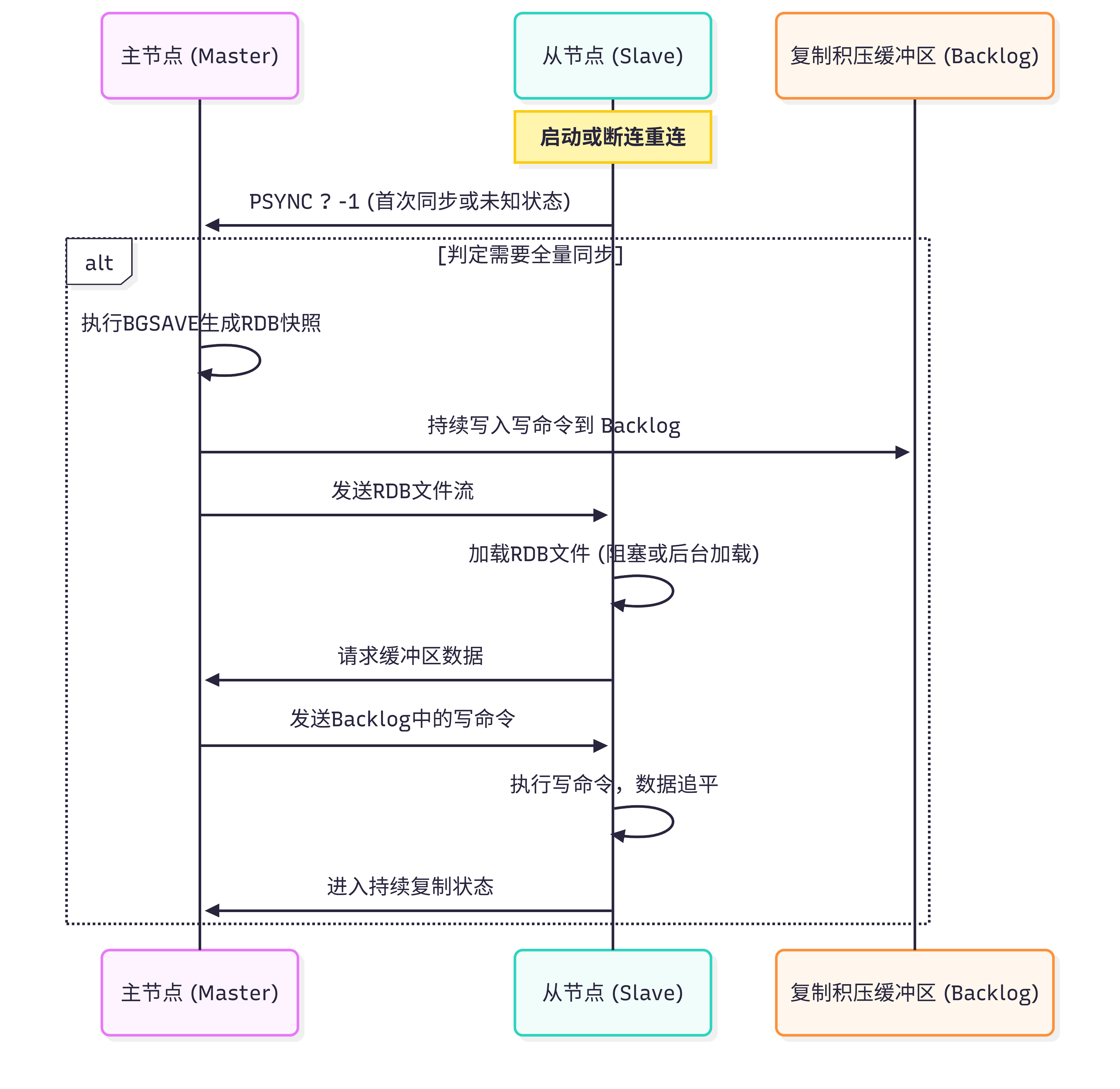
关键机制解析:
- RDB快照生成 :主节点执行
BGSAVE,将内存数据持久化到磁盘。在此期间,主节点继续处理写请求,并将这些新写入的命令存入复制积压缓冲区(Replication Backlog Buffer)。 - 数据传输 :RDB文件生成完毕后,主节点将其发送给从节点。从节点在加载RDB期间(取决于配置
slave-load-disabled),可能会阻塞服务或拒绝读请求(视版本和配置而定)。 - 命令重放:从节点加载完RDB后,向主节点请求发送在RDB生成期间产生的写命令。主节点将Backlog中的这部分命令发送给从节点,从节点执行后,数据达到一致。
2. 增量同步(Partial Resynchronization)
增量同步是Redis高可用的关键优化。当主从网络短暂抖动导致断连,重连后若满足特定条件,无需传输整个RDB,仅需同步缺失的那部分命令。
触发条件:
- 从节点保存了之前主节点的
RunID。 - 从节点记录了自己的复制偏移量(
offset)。 - 主节点发现从节点请求的
offset之后的数据,仍然存在于自己的repl-backlog-buffer中。
增量同步流程图解:
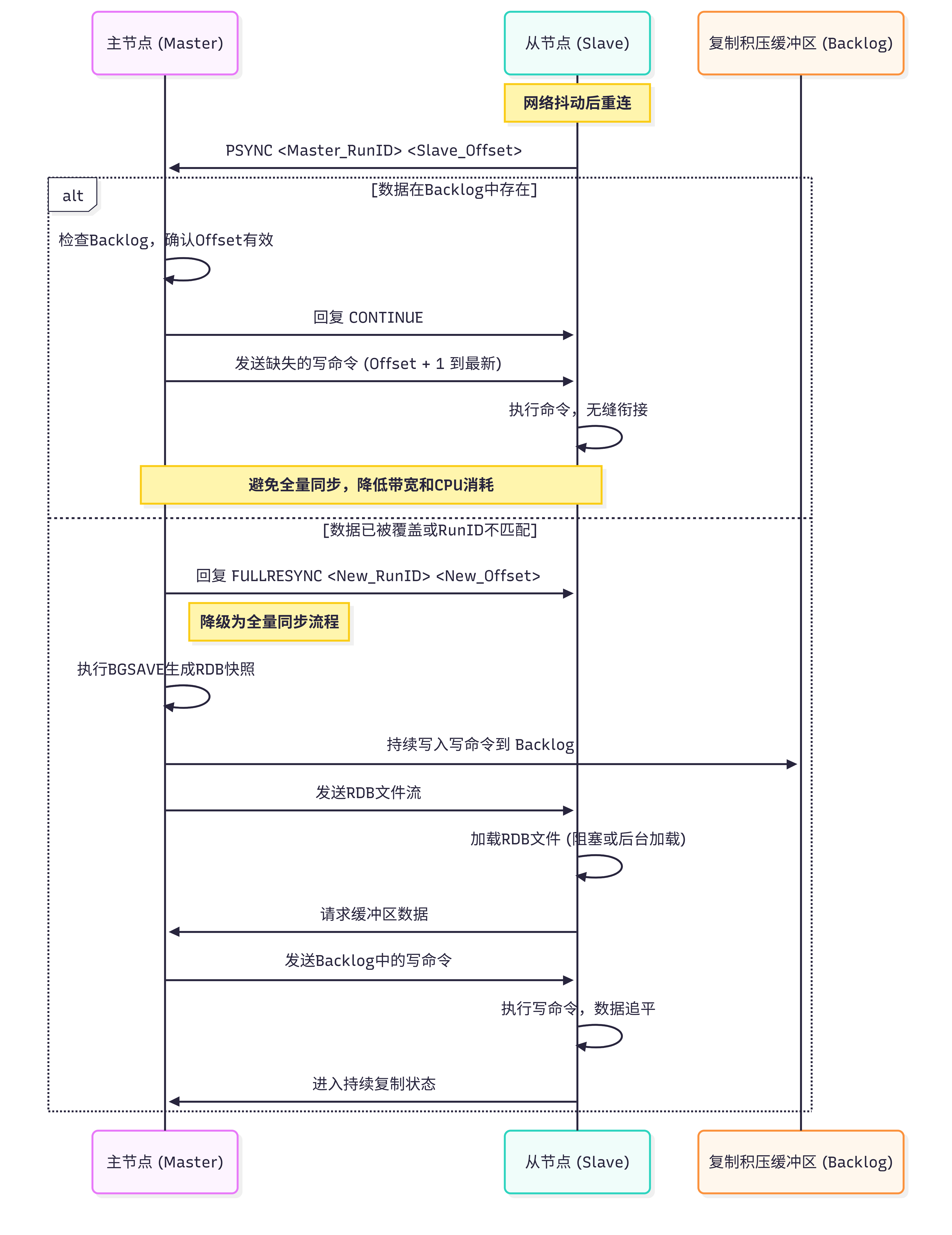
核心参数 repl-backlog-size:
这是控制增量同步成功率的关键配置。它是一个环形缓冲区。如果主从断连时间过长,或者主节点写入量巨大,导致新数据覆盖了旧数据(即从节点需要的offset之前的数据已不存在),则必须回退到全量同步。
- 经验法则:在写多读少的高并发场景,建议适当调大此值(如256MB或512MB),以容忍更长时间的网络波动。
3. 关键数据结构与参数对比
| 特性/参数 | 全量同步 (Full Sync) | 增量同步 (Partial Sync) | 备注 |
|---|---|---|---|
| 触发命令 | PSYNC ? -1 或 FULLRESYNC |
PSYNC <runid> <offset> |
2.8+ 版本核心 |
| 数据传输 | 完整RDB文件 + 缓冲区命令 | 仅缺失的写命令 | 增量同步极大节省带宽 |
| 资源消耗 | 高 (磁盘IO, 网络带宽, CPU) | 低 (仅网络带宽) | 全量同步可能引起主节点瞬时阻塞 |
| 依赖条件 | 无 | repl-backlog-buffer 未覆盖 |
需合理设置 repl-backlog-size |
| RunID要求 | 不需要或已变更 | 必须匹配上次记录的Master RunID | RunID变更意味着主节点重启或切换 |
| 适用场景 | 初始化、长时间断连、主节点重启 | 网络短暂抖动、从节点临时宕机 | 生产环境应极力避免频繁全量同步 |
二、常用命令与实战应用
以下是生产环境中排查主从问题的"手术刀"命令。
1. 核心监控命令
-
INFO REPLICATION- 用途:查看当前节点角色、连接状态、偏移量、Backlog大小等。
- 关键指标 :
role: master/slaveconnected_slaves: 从节点数量master_repl_offset/slave_repl_offset: 主从偏移量差值即为延迟数据量。repl_backlog_active: 1表示Backlog已激活。master_last_io_seconds_ago: 最后一次交互时间,若过大说明网络不通。
-
CLIENT LIST(在主节点执行)- 用途 :查看所有连接的客户端,筛选出
slave类型的连接。 - 技巧 :
CLIENT LIST | grep slave,可查看每个从节点的off(偏移量) 和lag(延迟),精准定位哪个从节点落后。
- 用途 :查看所有连接的客户端,筛选出
2. 控制与调试命令
-
SLAVEOF <ip> <port>/REPLICAOF <ip> <port>(Redis 5.0+)- 用途:动态建立主从关系。
- 注意:在生产环境变更拓扑时需极其谨慎,避免数据覆盖。
-
DEBUG SLEEP <seconds>- 用途:模拟主节点停顿,测试从节点的超时机制和增量同步触发(仅限测试环境!)。
-
CONFIG GET repl-backlog-size- 用途:动态查看或调整(部分版本支持动态修改,建议重启生效)积压缓冲区大小。
生产环境推荐配置示例:
bash
# 根据内存大小调整积压缓冲区,建议为预估断线期间写入量的 2 倍
repl-backlog-size 256mb
# 云环境或内存盘环境开启无盘复制
repl-diskless-sync yes
# 等待 5 秒,凑够一批从节点再开始发送,提高并发效率
repl-diskless-sync-delay 5
# 超时时间设置要大于网络最大抖动时间
repl-timeout 603. 生产环境最佳实践
- 避免在主节点进行大规模Key删除或过期:这会导致主节点处理变慢,进而影响向从节点发送心跳和命令的速度,增大延迟。
- 合理设置超时时间 :
repl-timeout默认60秒,在网络不稳定的跨机房部署中,可适当调大,防止误判断连触发全量同步。 - 监控全量同步频率 :如果监控发现频繁发生全量同步(通过日志
Full resync requested by slave),首要检查repl-backlog-size是否过小,或网络是否存在持续性丢包。
三、核心机制解析
1. 复制偏移量与心跳检测
复制的核心在于保证数据的一致性,而**复制偏移量(Replication Offset)**是衡量主从数据进度的标尺。
- Master 节点 :维护
master_repl_offset。每当 Master 接收到写命令并传播给从节点时,该值递增。即使没有写命令,Master 也会每秒向从节点发送一个带有当前偏移量的"空反馈"(PING),以维持心跳和偏移量同步。 - Slave 节点 :维护
slave_repl_offset。从节点接收数据流后更新此值,并通过心跳包定期上报给 Master。
工作流程 :
Master 通过比对 master_repl_offset 和各 Slave 上报的 slave_repl_offset,判断从节点的滞后程度。如果差值在允许范围内,则判定为"部分同步";否则触发"全量同步"。
2. 复制积压缓冲区(Replication Backlog)与部分重同步
这是 Redis 2.8 引入的最重要优化之一,解决了网络闪断导致的昂贵全量复制问题。
- 结构 :
repl-backlog是一个固定大小的环形队列(Ring Buffer),存在于 Master 内存中。 - 原理 :
- Master 将所有的写命令写入缓冲区,并记录写入时的偏移量。
- 当从节点断线重连时,发送
PSYNC <runID> <offset>请求。 - Master 检查:
runID是否匹配(确认是否是原来的主节点)。- 请求的
offset之后的数据是否还在repl-backlog中。
- 命中:仅发送缺失的增量数据(Partial Resynchronization)。
- 未命中:若数据已被新数据覆盖(环形队列回卷),则被迫进行全量复制(Full Resynchronization)。
关键配置 :repl-backlog-size。设置过小容易导致频繁全量同步;设置过大则浪费内存。建议根据网络带宽和平均断线恢复时间估算(例如:带宽 10MB/s,预计恢复时间 60s,则至少需要 600MB)。
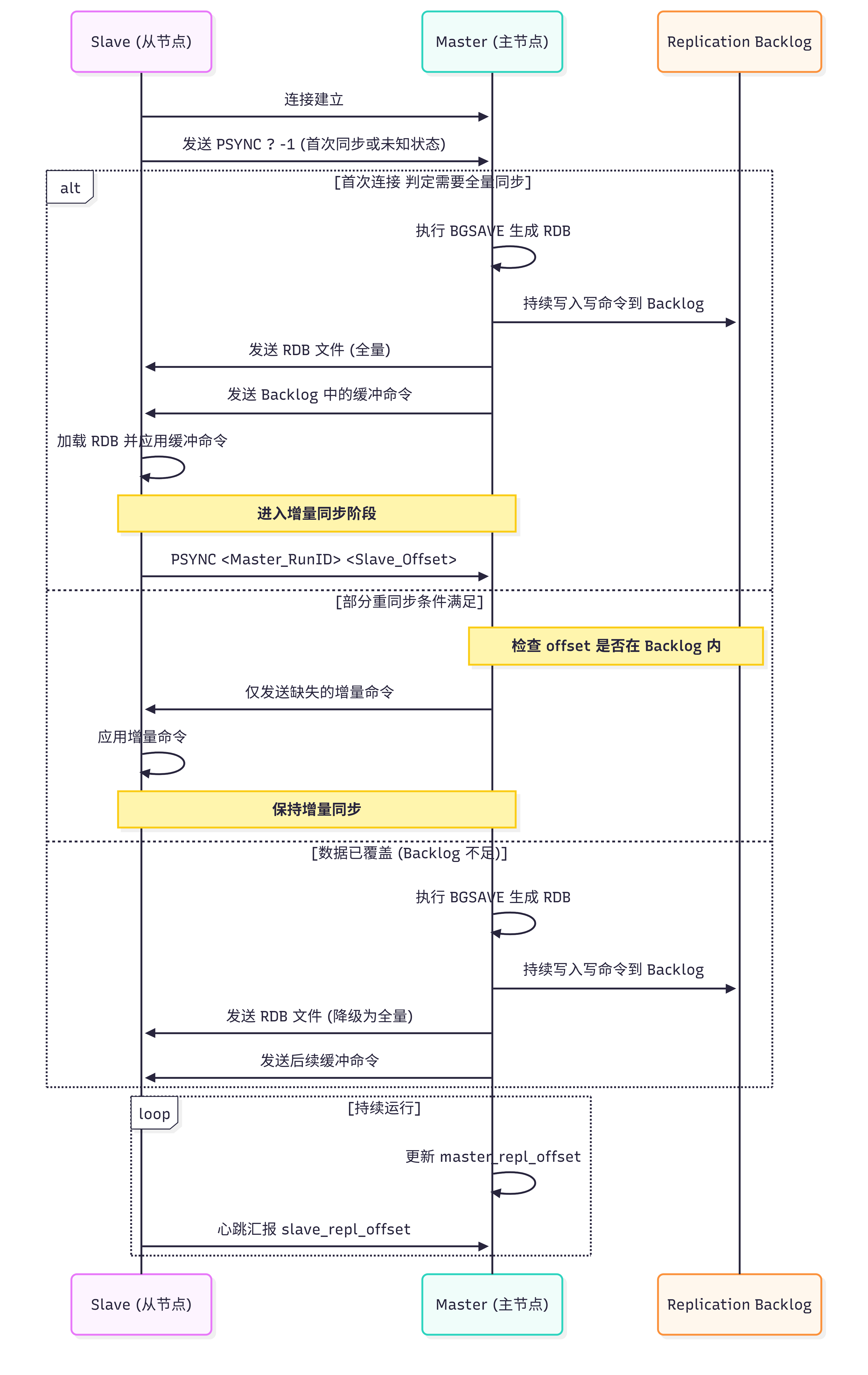
3. 全量复制与部分重同步流程图解
以下流程图展示了从连接建立到数据同步的完整状态机流转:
4. 无盘复制(Diskless Replication)深度剖析
在传统模式下,Master 需先将快照写入磁盘(RDB 文件),再读取发送给 Slave。这在磁盘 I/O 受限的云环境或高性能场景下可能成为瓶颈。
- 原理 :开启
repl-diskless-sync yes后,Master 直接调用fork()创建子进程,子进程直接将序列化后的数据流通过 Socket 发送给从节点,完全跳过磁盘写入步骤。 - 优势 :
- 显著降低磁盘 I/O 压力。
- 减少全量复制的延迟(省去了写盘时间)。
- 劣势与风险 :
- 阻塞新从节点:在无盘传输期间,Master 无法同时服务其他新的全量同步请求(因为子进程忙于发送流),必须等待当前传输完成。
- 网络依赖:完全依赖网络带宽稳定性,若传输中途失败,需重新开始,且无法像有盘模式那样利用已有的 RDB 文件重试。
- 配置参数 :
repl-diskless-sync-delay用于等待更多从节点同时连接,以批量发送,提高效率。
数据流向对比图 :

四、高频面试题
Q1: Redis主从复制是同步还是异步的?这对数据一致性有什么影响?
答 :Redis的主从复制是异步 的。主节点写完数据后,立即返回成功给客户端,然后后台线程将命令发送给从节点。
影响 :这意味着存在数据丢失窗口。如果主节点在将数据同步给从节点前宕机,且未开启持久化或持久化未完成,这部分数据将永久丢失。这也是为什么在强一致性要求场景下,单纯的主从架构不够用,需要配合哨兵(Sentinel)的确认机制或转向Redis Cluster及外部强一致方案(如ZooKeeper协调)。但在绝大多数缓存场景,这种最终一致性是可接受的,以换取极高的写入性能。
Q2: Redis 6.0 引入的多线程IO对主从复制有影响吗?
答:有影响且是正向的。Redis 6.0的多线程主要用于处理网络IO(读写命令),而命令执行依然是单线程。对于主从复制,主节点需要向多个从节点发送大量的数据(尤其是全量同步的RDB和增量同步的命令流)。多线程IO显著提升了主节点向从节点分发数据的效率,减少了因网络发送阻塞导致的复制延迟,特别是在高并发写和多从节点的场景下效果明显。
Q3: 简述repl-backlog-buffer的作用。如果它满了会发生什么?
答 :它是一个环形缓冲区,用于暂存主节点最近的写命令,以支持从节点的增量同步。
后果 :如果从节点断连时间过长,或者主节点写入速度极快,导致新数据覆盖了从节点所需的旧数据(即从节点请求的offset之前的数据已不在Buffer中),增量同步失败。主节点将强制从节点进行全量同步。这会消耗大量网络带宽和主节点CPU(生成RDB),可能导致线上服务抖动。因此,根据业务写入吞吐量合理估算并设置该参数至关重要。
Q4: 主从延迟(Replication Lag)产生的根本原因是什么?如何排查?
答 :
根本原因通常有三点:
- 网络带宽瓶颈:主节点写入速度 > 网络传输速度。
- 从节点负载过高:从节点正在处理大量读请求或持久化(BGSAVE/BGAOF),阻塞了复制线程(注:Redis 6.0 前复制线程与命令执行线程在某些场景下存在竞争,6.0 后有所优化但依然存在 IO 阻塞)。
- 大命令阻塞 :主节点执行了
KEYS *或超大值的删除操作,导致生成的二进制流巨大,从节点回放耗时。
排查步骤:
- 使用
INFO replication查看master_repl_offset与slave_repl_offset的差值。- 检查从节点
INFO stats中的blocked_clients或 CPU 使用率。- 使用
SLOWLOG检查是否有大命令。- 监控网络流量是否打满。
Q5: 主节点重启后,从节点一定会发生全量复制吗?
答 :
不一定 。取决于
runID和repl-backlog。
- 如果主节点重启但配置了持久化且保留了
dump.rdb和server.id(某些定制版或通过配置固定 RunID,但在原生 Redis 中重启通常会变 RunID),RunID 改变则必然全量。- 关键点 :原生 Redis 重启后
runID会变化,因此从节点会识别为新的主节点,通常会发生全量复制。除非使用了某些高可用中间件或特定配置保持了 RunID 不变,且偏移量在 Backlog 内,才可能部分同步。但在标准原生行为下,主节点重启意味着新的复制纪元,从节点会走全量。
Q6: 复制积压缓冲区(Backlog)满了会发生什么?如何合理设置大小?
答 :
当主从断线时间过长,产生的增量数据超过了
repl-backlog-size,环形队列发生覆盖,从节点重连时将无法找到对应的偏移量,从而退化为主从全量复制 。
计算公式 :Size = 写入吞吐量 (MB/s) × 预期最大断线恢复时间 (s) × 安全系数 (1.5~2)。例如:写入 10MB/s,要求容忍 1 分钟断线,则
10 * 60 * 2 = 1200MB。切勿盲目设大,需考虑内存成本。