本文将对比LongAdder与AtomicLong在多并发累加下的效率
测试程序
ini
public static <T> void test(
Supplier<T> supplier,
Consumer<T> add
){
T t = supplier.get();
List<Thread> threadList=new ArrayList<>();
for (int i=0;i<5000;i++){
threadList.add(new Thread(()->{
for (int k=0;k<50000;k++){
add.accept(t);
}
}));
}
Long start=System.nanoTime();
threadList.forEach(Thread::start);
threadList.forEach(thread -> {
try {
thread.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Long end=System.nanoTime();
System.out.println(t+" "+"cost:"+(end-start)/1000000);
}
css
public static void main(String[] args) throws ExecutionException, InterruptedException {
for (int i=0;i<4;i++){
test(AtomicInteger::new, AtomicInteger::getAndIncrement);
}
System.out.println();
for (int i=0;i<4;i++){
test(LongAdder::new,LongAdder::increment);
}
}最终结果:
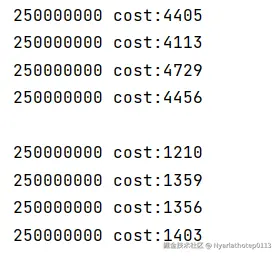
可以看出LongAdder的效率是AtomicInteger的4倍左右。
那么为什么LongAdder的效率就比AtomicInteger的效率高出这么多?
AtomicIntegr保证结果正确的实现
我们翻看其源码,发现它使用了Unsafe的getAndAddInt
arduino
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
return v;
}这是一个自旋+CAS操作,因此在有大量线程同时对AtomicInteger进行操作时,将同时有大量的线程陷入自旋状态。正是这种大量的自旋,导致cpu空转浪费。并且频繁的 CAS 操作会导致 CPU 缓存行在多核之间无效化,引发"总线风暴",严重影响所有核的性能。
LongAdder为什么那么快?
AtomicInteger的缺点已经很明显了,就是大量线程同时去竞争同一个内存地址,尝试让其数值加1,而LongAdder采用"分段累加"的思路,将大量的线程分布到不同的段上,以空间换时间,分散热点。
LongAdder内部有一个核心的 base值,和一个 Cell[]数组(称为单元格数组)。这继承于Striped64类
arduino
/** CPU核心数,用于限制表格大小 */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* 单元格数组。当非空时,其长度为2的幂。
*/
transient volatile Cell[] cells;
/**
* 基础值,主要在没有竞争时使用,也可作为表格初始化竞争期间的备用值。通过CAS更新。
*/
transient volatile long base;
/**
* 自旋锁(通过CAS锁定),在调整大小和/或创建单元格时使用。
*/
transient volatile int cellsBusy;- 当没有竞争时,它像
AtomicLong一样,直接 CAS 更新base值。 - 当竞争发生过,但是竞争较低,即对应的
Cell无人竞争,尝试CAS更新Cell。 - 当竞争很激烈,调用最终方法
longAccumulate
csharp
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
// 第一层判断:在cell为null的时候,直接通过cas更新base值
if ((cs = cells) != null || !casBase(b = base, b + x)) {
// 执行到这里,说明两种情况之一:
// 1. cells数组已经初始化了(说明之前发生过竞争)
// 2. cells还没初始化,但通过casBase直接累加到base的操作失败了(说明发生了第一次竞争)
int index = getProbe(); // 获取当前线程的哈希码,用于定位到cells数组的某个位置
boolean uncontended = true; // 一个"乐观"的标志,假设定位到的Cell没有竞争
// 第二层判断:尝试走"Cell路径"
if (cs == null || // 情况1: cells数组未初始化(由casBase失败进入)
(m = cs.length - 1) < 0 || // 情况2: cells数组长度为0(容错检查)
(c = cs[index & m]) == null || // 情况3: 哈希到的那个Cell槽位是空的
!(uncontended = c.cas(v = c.value, v + x))) // 情况4: 对找到的Cell进行CAS累加操作失败了!
{
// 上述四个条件任何一个为true,就进入最终的"终极解决方法"
longAccumulate(x, null, uncontended, index);
}
}
// 如果第一层的if条件都不满足,说明cells为null,且casBase成功了,方法直接结束,这是最快、无竞争的路径。
}longAccumulate的处理逻辑如下:
ini
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended, int index) {
if (index == 0) {
ThreadLocalRandom.current(); // 强制初始化线程的随机数种子
index = getProbe();// 重新获取哈希码
wasUncontended = true;// 标记为无竞争重新开始
}
// 无限循环,直到成功
for (boolean collide = false;;) { // True if last slot nonempty
Cell[] cs; Cell c; int n; long v;
//分支1:当cell数组已经存在的时候
if ((cs = cells) != null && (n = cs.length) > 0) {
//分支1.1:对应的那个槽是空的
if ((c = cs[(n - 1) & index]) == null) {
//先判断锁是否存在
if (cellsBusy == 0) { // Try to attach new Cell
//预创建一个新的Cell
Cell r = new Cell(x); // Optimistically create
//再次判断锁并尝试cas获得锁
if (cellsBusy == 0 && casCellsBusy()) {
try { // Recheck under lock
Cell[] rs; int m, j;
// 双重检查,防止其他线程已创建
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & index] == null) {
rs[j] = r; //放入槽位
break; // 成功退出循环
}
} finally {
//释放锁
cellsBusy = 0;
}
continue; // 槽位已被占用,重试
}
}
collide = false;
}
//子分支1.2:之前 CAS 失败过,重新哈希
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // 标记为无竞争,重新尝试
// 子分支1.3:尝试 CAS 累加
else if (c.cas(v = c.value,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;// CAS 成功,累加完成
// 子分支1.4:数组已最大或已过时
else if (n >= NCPU || cells != cs)
collide = false; // 不扩容
else if (!collide)
collide = true;
//获取锁并扩容
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == cs)
//扩容两倍
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
index = advanceProbe(index);
}
//分支2:未初始化cell数组
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try {
//双重检查
if (cells == cs) {
//初始大小为2
Cell[] rs = new Cell[2];
//并在对应的位置创建cell
rs[index & 1] = new Cell(x);
cells = rs;
break;
}
} finally {
cellsBusy = 0;
}
}
//回退对base cas
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
}
}当Cell数组存在时:
ini
cells != null
↓
定位到Cell c = cells[index & (n-1)]
↓
分支判断:
├── 1. c == null → 创建新Cell并放入
├── 2. 之前CAS cell失败(wasUncontended=false) → 重新哈希,标记为无竞争
├── 3. 尝试c.cas(v, v+x) 来cas更新cell → 成功则退出
├── 4. 数组已达最大(NCPU)或已过时 → 不扩容,重新哈希
├── 5. 未标记冲突(!collide) → 标记冲突,重新哈希
└── 6. 已标记冲突(collide=true) → 发生第二次cas冲突,获取锁,扩容2倍
↓
每次失败后:index = advanceProbe(index) // 重新哈希当Cell数组不存在时:
ini
cells == null
↓
尝试获取锁(cellsBusy)
↓
成功:
Cell[] rs = new Cell[2]; // 初始化大小为2
rs[index&1] = new Cell(x); // 放入当前线程槽位
cells = rs;
↓
失败:回退到base变量CAS获取锁失败后:
objectivec
cellsBusy CAS失败
↓
回退到base变量尝试CAS
↓
成功:退出循环
失败:重新循环最终使用sum方法,累加所有的Cell
csharp
public long sum() {
Cell[] cs = cells;
long sum = base;
if (cs != null) {
for (Cell c : cs)
if (c != null)
sum += c.value;
}
return sum;
}伪共享的解决
伪共享(False Sharing) 是一种在多核CPU架构下,由缓存系统引发的高性能"隐形杀手"。它指的是多个不相关的变量,因为被加载到同一个CPU缓存行(Cache Line)中,导致一个线程修改其中一个变量时,会"误伤"地使整个缓存行失效,从而拖慢其他线程的读写速度。
现代CPU为了弥补与内存之间的速度鸿沟,引入了多级缓存(L1、L2、L3)。数据在缓存和内存之间不是以单个字节为单位传输,而是以一个固定大小的块为单位,这个块就叫缓存行,通常是64字节。
伪共享发生的场景:
假设有两个独立的变量 a和 b,它们的内存地址恰好落在同一个64字节的缓存行里。当运行在CPU核心1 上的线程T1频繁修改 a时,它会独占(Invalidate) 这个缓存行。运行在CPU核心2 上的线程T2即使只想读取 b,也会发现它本地的缓存行副本已经失效,必须重新从更慢的内存或L3缓存中加载。这种无谓的、由无关数据引发的缓存行竞争,就是伪共享。
本质就是:变量本身在逻辑上不共享,但承载它们的物理缓存行被共享了,导致了性能下降。
解决方案:使用@sun.misc.Contended
在LongAdder中,因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因
此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
Core-0修改Cell[0]
Core-1要修改Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,因此在Cell上增加这个注解,使得一个缓存行只有一个Cell
LongAdder的缺点
从上文可以知道,LongAdder本质上还是自旋加CAS,但与AtomicInteger不同的是,它将热点分散,使得竞争的强度下降,但是这也导致了,在计算的过程中,数值并不一致,通过Sum保证了最终的一致性,而在计算的过程中,是弱一致性的。