文章目录
-
- [一、引言:Java 的生态与哲学](#一、引言:Java 的生态与哲学)
- [二、JVM 内存模型与对象生命周期](#二、JVM 内存模型与对象生命周期)
-
- [2.1 运行时数据区](#2.1 运行时数据区)
- [2.2 对象创建与内存分配](#2.2 对象创建与内存分配)
- 三、垃圾回收机制深度解析
-
- [3.1 可达性分析算法](#3.1 可达性分析算法)
- [3.2 垃圾收集器对比与选择](#3.2 垃圾收集器对比与选择)
- [3.3 常见 GC 陷阱与调优](#3.3 常见 GC 陷阱与调优)
- [四、并发编程:从 synchronized 到 AQS](#四、并发编程:从 synchronized 到 AQS)
-
- [4.1 synchronized 的底层实现](#4.1 synchronized 的底层实现)
- [4.2 AQS 框架与自定义同步器](#4.2 AQS 框架与自定义同步器)
- [五、性能优化实战:从代码到 JVM](#五、性能优化实战:从代码到 JVM)
-
- [5.1 代码层面的优化](#5.1 代码层面的优化)
- [5.2 JVM 参数调优](#5.2 JVM 参数调优)
- [5.3 常见性能陷阱](#5.3 常见性能陷阱)
- 六、最佳实践总结
- 七、结语
一、引言:Java 的生态与哲学
Java 自 1995 年诞生以来,凭借"一次编写,到处运行"的跨平台能力、自动内存管理(GC)以及丰富的生态,成为企业级应用、大数据、Android 开发等领域的基石。本文将从 JVM 底层原理、并发机制、内存模型、性能调优等维度,深入剖析 Java 的核心技术,并提供实战代码与最佳实践。
二、JVM 内存模型与对象生命周期
2.1 运行时数据区
Java 虚拟机(JVM)将内存划分为多个区域,每个区域承担不同职责。理解这些区域是诊断内存泄漏、优化 GC 的基础。
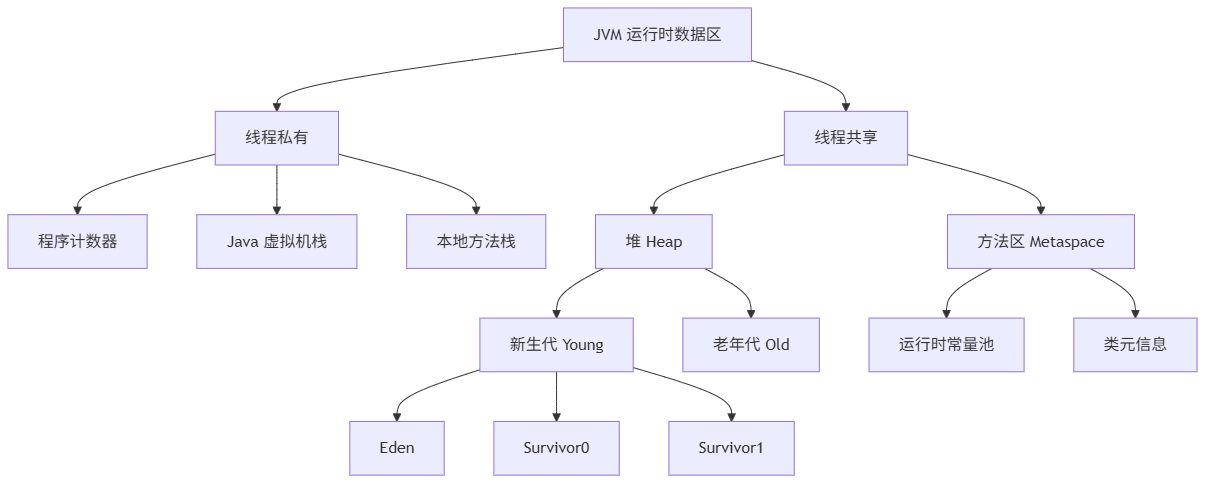
关键点:
- 堆:所有对象实例和数组在此分配,是 GC 的主要区域。
- 栈:每个方法调用创建一个栈帧,包含局部变量表、操作数栈、动态链接、方法出口。
- 方法区:存储类信息、常量、静态变量。JDK8 后使用元空间(Metaspace)替代永久代,使用本地内存。
2.2 对象创建与内存分配
java
public class ObjectCreation {
public static void main(String[] args) {
// 1. 类加载检查
// 2. 分配内存(指针碰撞或空闲列表)
// 3. 初始化零值
// 4. 设置对象头(Mark Word + 类型指针)
// 5. 执行 <init> 方法
User user = new User("Alice", 30);
}
}对象内存布局:
- 对象头:Mark Word(存储哈希码、GC 分代年龄、锁状态标志)、类型指针(指向类元数据)。
- 实例数据:字段值,按顺序排列。
- 对齐填充:保证对象起始地址是 8 字节的整数倍。
最佳实践:
- 避免在循环中创建大量短生命周期对象,防止频繁触发 Minor GC。
- 使用
-XX:+PrintGCDetails观察 GC 日志,调整新生代与老年代比例。
三、垃圾回收机制深度解析
3.1 可达性分析算法
JVM 通过 GC Roots 对象(栈帧中的局部变量、静态变量、JNI 引用等)作为起点,向下搜索引用链。不可达的对象被标记为可回收。
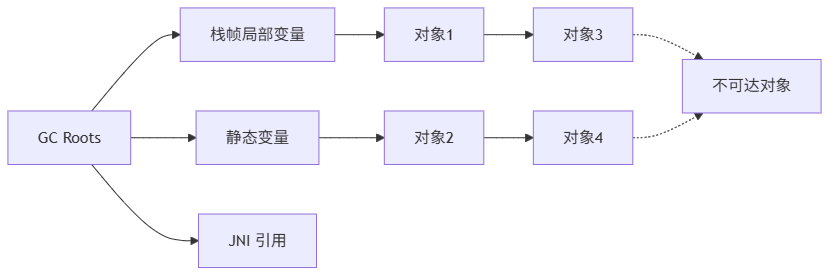
3.2 垃圾收集器对比与选择
| 收集器 | 适用场景 | 特点 | 暂停时间 |
|---|---|---|---|
| Serial | 单核、客户端 | 单线程,简单高效 | 较长 |
| Parallel Scavenge | 吞吐量优先 | 多线程,可控制吞吐量 | 可接受 |
| CMS | 低延迟 | 并发标记清除,减少停顿 | 较短 |
| G1 | 大堆、低延迟 | 分区式,可预测停顿 | 可配置 |
| ZGC | 超大堆、极低延迟 | 染色指针,几乎无停顿 | <10ms |
实战建议:
- 对于响应时间敏感的服务(如 Web 应用),优先选择 G1 或 ZGC。
- 对于批处理任务(如数据清洗),使用 Parallel Scavenge + Parallel Old 组合。
- 使用
-XX:+UseG1GC启用 G1,并通过-XX:MaxGCPauseMillis=200设定目标停顿时间。
3.3 常见 GC 陷阱与调优
陷阱1:System.gc() 显式触发 Full GC
System.gc() 会触发 Full GC,导致长时间停顿。应避免在生产代码中调用,除非明确需要(如测试环境)。
陷阱2:大对象直接进入老年代
超过 -XX:PretenureSizeThreshold 的对象直接在老年代分配,可能导致老年代迅速占满。应合理设置该阈值(如 1MB)。
调优示例:
bash
# 堆大小 4GB,G1 收集器,目标停顿 100ms
java -Xms4g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -jar app.jar四、并发编程:从 synchronized 到 AQS
4.1 synchronized 的底层实现
synchronized 在 JDK6 后经过大量优化,引入偏向锁、轻量级锁、重量级锁的升级过程。
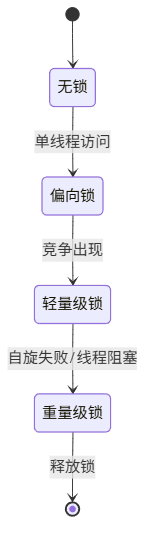
代码示例:
java
public class LockExample {
private int count = 0;
private final Object lock = new Object();
public void increment() {
synchronized (lock) {
count++;
}
}
}最佳实践:
- 尽量缩小同步块范围,减少锁持有时间。
- 使用
java.util.concurrent包中的高级工具(如ReentrantLock、CountDownLatch)替代原始 synchronized。
4.2 AQS 框架与自定义同步器
AbstractQueuedSynchronizer(AQS)是 JUC 锁和同步器的基石,如 ReentrantLock、Semaphore、CountDownLatch 均基于它实现。
核心原理:
- 维护一个 volatile int state 表示同步状态。
- 通过 CLH 队列管理等待线程。
- 提供
tryAcquire、tryRelease等模板方法供子类实现。
自定义独占锁示例:
java
public class SimpleLock extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int acquires) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int releases) {
if (getState() == 0) throw new IllegalMonitorStateException();
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public void unlock() { release(1); }
}性能优化建议:
- 使用
LockSupport.park()替代Object.wait(),避免虚假唤醒。 - 在高并发场景下,优先使用
LongAdder替代AtomicLong,减少 CAS 竞争。
五、性能优化实战:从代码到 JVM
5.1 代码层面的优化
1. 避免创建不必要的对象
java
// 反例:每次循环创建 StringBuilder
for (int i = 0; i < 1000; i++) {
String s = new StringBuilder("prefix").append(i).toString();
}
// 正例:复用 StringBuilder
StringBuilder sb = new StringBuilder("prefix");
for (int i = 0; i < 1000; i++) {
sb.setLength(6); // 重置到 "prefix" 长度
sb.append(i);
String s = sb.toString();
}2. 使用位运算代替取模
java
// 当 n 是 2 的幂时,hash % n 等价于 hash & (n-1)
int index = hash & (table.length - 1);3. 合理使用 Stream API
parallelStream 并非总是更快,数据量小或存在共享资源时反而更慢。建议数据量 > 10,000 且无状态操作时使用。
5.2 JVM 参数调优
典型参数组合:
bash
# 生产环境 8GB 堆,G1 收集器
-Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=100
-XX:+PrintGCDetails -Xloggc:/var/log/gc.log
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/heap.hprof关键参数解释:
-Xms/-Xmx:初始/最大堆大小,建议设为相同值避免动态调整。-XX:NewRatio:新生代与老年代比例,默认 1:2。-XX:SurvivorRatio:Eden 与 Survivor 比例,默认 8:1:1。
5.3 常见性能陷阱
陷阱1:HashMap 并发死循环
JDK7 中 HashMap 在多线程扩容时可能导致环形链表,引发 CPU 100%。解决方案:使用 ConcurrentHashMap。
陷阱2:ThreadLocal 内存泄漏
ThreadLocal 的 key 是弱引用,但 value 是强引用。线程池中线程复用,若未调用 remove(),value 永远不会被回收。
java
ThreadLocal<byte[]> local = new ThreadLocal<>();
try {
local.set(new byte[1024 * 1024]);
// 业务逻辑
} finally {
local.remove(); // 必须清理
}陷阱3:String.intern() 滥用
intern() 会将字符串放入常量池,但 JDK7 后常量池在堆中,大量使用可能导致 Full GC。建议仅对有限且重复的字符串使用。
六、最佳实践总结
- 编码规范 :遵循阿里巴巴 Java 开发手册,使用
@Override、@Deprecated注解,避免魔法值。 - 异常处理:捕获异常时区分业务异常与系统异常,避免吞没异常。
- 日志框架:使用 SLF4J + Logback,异步日志减少 I/O 开销。
- 测试驱动:编写单元测试(JUnit + Mockito),使用 JMH 进行微基准测试。
- 持续监控:集成 Prometheus + Grafana,监控 JVM 指标(GC 频率、堆内存、线程数)。
七、结语
Java 从入门到精通并非一蹴而就,需要深入理解 JVM 原理、并发模型以及性能调优技巧。本文从内存模型、GC 机制、并发编程到实战优化,构建了一个系统化的知识框架。建议读者结合官方文档(如《Java 虚拟机规范》)、开源项目(如 Spring、Netty)以及实际项目经验,不断深化理解。记住:"知其然,更要知其所以然" 是成为 Java 专家的关键。