
去年写过一篇"用大语言模型生成心理学范式",当时的生成思路更像是找一个和目标任务逻辑相近的范式,在原有结构上修改和调整。对于一些结构相似的任务,比如基于flanker生成ANT,这样确实可以生成出可运行的任务,但问题也很明显。
-
第一,这种生成是否能泛化到更多任务,并没有真正验证。
-
第二,生成出来的结果到底能不能运行,很多时候是不确定的。我就一直在想,如何给整个框架增加一个反馈机制,让agent知道这个任务能不能运行(本以为是一个非常复杂的工程,但实际上远比想象中的容易)。
后续由于手上事情较多,做完要用的任务后就没有推进。今年 1 月 agentic coding 开始爆发,然后开始尝试完善已有构架。
1. 生成---反馈闭环
新版本在任务架构里加了一层 response layer,能让任务在运行时明确区分:现在是谁在做这个任务,是人类,还是 agent;如果是agent,那么就将当前trial的信息传递给它。
第一版本,在调试任务时,总是要手动关闭一些功能,比如播放语音的指导语、调整试次数目,这样的不仅麻烦,而且很容易在正式实验时忘记调回来。
现在 response layer 里,至少加入了几种不同的反馈模式。
-
一种是 QA。它本质上是快速运行任务,进行按键反应和流程检查。
-
另一种是 sim。这个模式允许agent按预定的编排(fixed)进行按键或接入模型(sampler),把一个响应模型接进来,去模拟被试在当前任务条件下的反应。这种"模拟"并不是让 agent 真正看到屏幕上的刺激,然后像人一样感知再反应。它更像是任务把当前 trial 的条件告诉 agent,然后由 agent 基于这些条件做反应。
认真考虑过是否要继续往"让 agent 真正看刺激、理解刺激、再做反应"这个方向走。英伟达有类似的项目,让 AI 学打游戏、学习人类按键模式;也听说过使用模型玩KOF的。
这虽然更像是让agent在模拟人的反应,可以回答一些更深入的问题,但是需要解决的问题太多,比如处理视觉输入、界面解析,模型的影响速读、感知误差差等。所走了轻量的模拟路线,具体有什么用,目前的想法尚不成熟。
如果我们是要模拟被试行为,那么仅建模就够了,为什么还要把它放到实际的任务中再按键跑一遍(听起来更像是replay)。我能想到的唯一的用处是,可以考虑让被试看别人(实际上是我们操纵的sampler)完成任务记录其反应。
2. 统一的 device layer
第二个更新,是 device layer 的统一。
这部分目前还没有完成系统测试,但设计目标是明确的:把任务内部的事件和外部设备的 marker/trigger 发送逻辑尽量隔离,然后通过统一层去对接不同设备。
第一个版本的任务,把设备相关的逻辑直接写在任务流里,调试也很麻烦,每次都要手动调代码,关闭端口。此外,长期维护也比较麻烦,一旦设备变了,就要重新相关代码。所以想做一个即插即用的设备层,应对不同的设备同步问题。
现在的方向是,任务内部只产生语义事件,真正怎么发 marker、什么时候发、发给什么设备,由 device/runtime 这一层去处理。这个设计后面会优先在 EEG 场景下继续打磨,因为这是最现实、也最需要稳定性的使用场景。
3. 增加自动绘制任务流程图
这个也是当时想做,但是未做的事情。
流程图基于任务逻辑生成,可以更方便、更直观地展示任务流程。
但目前 task-plot 的效果有时候还是有点像抽卡,不一定一次就能得到理想结果,通常还需要 1 到 3 轮调整。
4. 移除 mcp 模块,改用 skill
第四个比较大的变化,是我把原来的 mcp 模块、以及轻量化的LLMs接口移除了,现在自动化都用skill。
回头看,之前所谓的 mcp,其实并不是真正意义上的 protocol 或一个清晰的系统层。它更多只是 prompt 的组装,是那个阶段为了把 LLM 调起来而做的一层外壳。
那个时候做完后才了解到类似的功能可能使用langchain相关的功能就可以实现。大概也是今年1月份,skill开始火起来,才意识到最适合的就是做成skill的形式。
安装方式:下载到本地或者装到cli对应的位置(比如.gemini/ ./codex)
目前项目提供的skill有3个,
主要是:
4.1 task-build

task-build 根据脚手架,也就是 TAPS 和 psyflow 的结构,再结合文献中的任务流程与参数,对目标任务进行推理、生成、做QA 和 simulation。
第一版基于mcp的任务生成方式,没有任务参数的映射,没有参考文献,没有QA和simulation等信息和流程。新版本这个skill,能生成一些中间文件记录任务参数的映射,参考文献(从哪个文献中推理出来的参数),任务流程,方便后续审计。
使用:
go
请使用本地的task-build技能帮我制作x任务这里它会自动查文献、确定参数为你制作该任务
或者
go
请使用本地的task-build技能,帮我制作 @xxx.pdf 中的任务第二种直接提供文章的方式应该可用,目前还没有测试。
4.2 task-plot
task-plot 读取任务流程,推理被试看到了什么,并尝试生成流程图或相应图示。它现在还不完全稳定,但方向是对的:让任务不仅能跑,也能被检查。由于现在的agent开始支持多模态(比如codex5.4),可以看图,因此后续会继续修改该技能,让它达到自动迭代。(开发这个技能的时候codex5.3还不支持多模态,所以这一部分并未实现)
使用:
go
请使用本地的task-plot技能帮我绘制x的流程图然后它会基于任务流程绘图,并且嵌入readme.md文档。
自动绘制的cyberball任务,刺激的比例有点问题外,其它看起来还行。
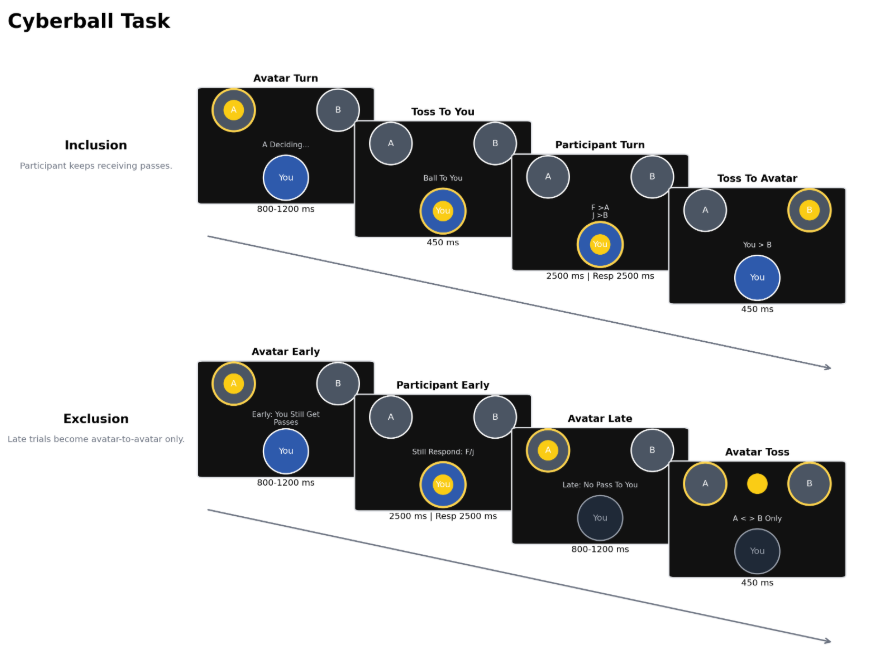
4.3 task-py2js
task-py2js 负责把本地任务转到 js 环境里运行,支持网页端的任务运行。为了支持转换,另外做了 psyflow-web 的底层结构,它本质上是把 jsPsych 那一套已有能力重新封装进一个更接近 psyflow 的结构里。对应的关系大概如下
psychopy-->psyflow (更抽象的功能集合)
jspsych-->psyflow-web (更抽象的功能集合)
这样本地 psyflow 任务往网页版本迁移时,不需要完全重新按另一套思路重写。
目前,网页版本的任务目前主要是 preview为主,提供预览、展示和快速检查。但实际上,如果接上后端(开发成本基本为0),是可以实现网页版任务采集的。

由于目前时间有限、缺乏网页版开发的动机,因此当前仍以preview为主,如果要落实到数据采集,仍需进行严格的对照实验,确保构架的有效性,并且接入后端的管理系统。
使用方式:
go
请使用本地的task-py2js将x任务转为网页版
go
本地应该可用通过npm run dev运行5. 网站重构
原来的网站主要基于 Sphinx + Furo主题,当时制作还是花了一些时间,了解它们的一些使用规范。但是几个月后的今天,前端开发的成本基本为0,所以我把整个任务网站重新做了一遍,目前具体的内容还在填充当中。
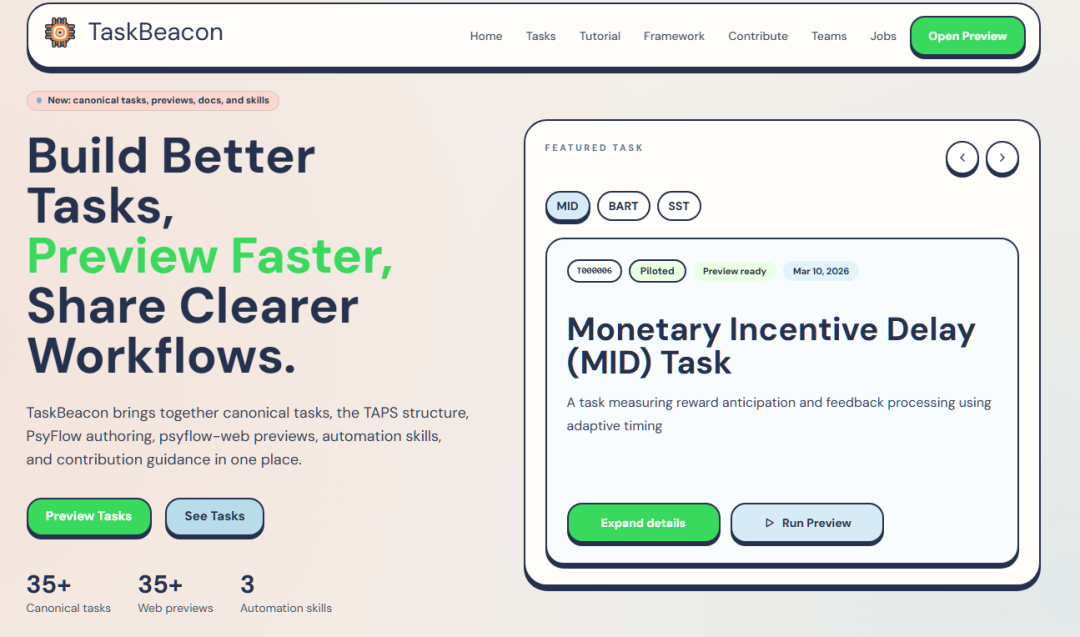
网站现在已经可以通过 action 自动更新和拉取新任务信息。比如 repo 里增加了新任务,它可以自动同步到网站;如果某个任务已经做好了网页版预览,也可以自动出现 preview 按钮。
另外,还为这些任务增加了成熟度标签,提示任务是否使用于真实场景,或有人验证,还是只是过了Agent的验证。

后续可能会在这里开一个验证者的tag,悬停展示贡献者个人信息面板(包括cv链接)
6. 局限
第一个局限,是 psyflow 架构本身还需要更多验证。去年我已经用它大概做了 5 个任务,并且采集了实际数据,目前看效果是可以的。但是目前的任务的构架有较大的改动,比如增加了response和device层,是否影响任务记录需要验证。
第二个局限,是 psyflow-web 现在还很难说已经成熟,它是 vibe coding 的产物,结构是否合理、边界是否清晰,都还需要懂jspsych人类质检员去检查,但这并不是我的专长。
最后需要强调的是: TaskBeacon 目前更像是一个模板系统。用户下载下来,基于模板修改、验证,然后再投入自己的研究。
7. 未来方向
psyflow 任务的人类质检
包括参数、流程图、条件设置、输出文件、指导语、设备 marker 等等。因为 AI 可以帮你生成、帮你检查一部分东西,但最后哪些地方真的能进实验,还是需要人来把关。所以现在在招募实习/助理协助完成相关工作。招募
不同device同步的支持
同样需要进一步验证,并且可能是一个庞大的工程。
psyflow-web 拓展到移动端
测试网页版任务的有效性并考虑拓展到移动端。比如按键问题,手机里没有键盘;再比如不同设备尺寸、浏览器行为、输入延迟和界面适配,这些都会影响任务表现。移动端不是把桌面版页面缩小一下那么简单。
多语言支持
相比做一套复杂的多语言系统,我目前更倾向于让用户直接修改 config.yaml 做本地化。因为这条路最简单,也最可控。当然,后面也不排除提供多语言任务配置,让用户直接下载不同语言版本。
8.感受
不仅是在psyflow的开发过程中,在其他工具的开发中我都会在想这个问题:工具需要优先为人设计,还是为 agent 设计?
去年我在设计 psyflow 的时候,默认还是站在人类使用者的角度去想问题。怎么让人更容易搭任务,怎么让人更容易改参数,怎么让人更容易理解流程,怎么让人更容易维护代码。
但到了今年,这样的想法开始动摇。
当然还需要为人类使用者设计工具,但对于这类需要支持自动生成、检查、迁移、预览和验证的代码工具,人类友好的设计,可能已经不再是唯一的目标。未来越来越多的构建与测试环节都会由 agent 参与,因此一个工具是否 agent友好,可能会变成比界面是否友好更基础的问题。
目前看,一个更合适的方向不是单纯堆 prompt,而是采用"结构化参数/规范层 + 受约束的运行时"这样的范式。某种意义上,TAPS + psyflow 其实已经在往这个方向走:前者负责把任务描述压缩成可推理、可修改的参数空间,后者负责提供可执行、可测试、可反馈的 runtime。
另外一个有意思的地方是,由于我在psyflow早期的版本中使用了cookiecutter来给定taps结构,以mid任务为模板,后续在生成任务过程中,任务的结构严重受到了mid任务结构的污染,最后经过多轮迭代,才得以改善。