前言
线上服务的稳定性,是技术团队的核心生命线。凌晨被告警电话叫醒、故障发生后半小时找不到根因、小问题引发全链路雪崩、核心业务中断造成巨额损失,几乎是每一位后端开发者都经历过的痛点。一套完整的线上运维体系,核心价值不是事后救火,而是构建从风险预判、问题发现、快速止损到根因根治的全闭环能力,把故障扼杀在萌芽状态,实现线上服务的持续稳定运行。
一、全链路监控体系:可观测性的三大支柱与分层落地
监控是运维体系的基石,没有全面、精准的监控,后续的告警和应急都无从谈起。监控的核心不是堆砌指标,而是构建完整的可观测性能力,其核心定义来自CNCF云原生计算基金会,包含三大互补的支柱:指标(Metrics) 、 链路(Tracing) 、 日志(Logging)。
1.1 可观测性三大支柱的核心边界与适用场景
很多开发者会混淆三者的作用,这里先做明确区分:
- 指标(Metrics) :数值型的时序数据,核心用于趋势判断、阈值告警、容量规划,特点是占用存储空间小、可长期保存、支持聚合计算,是监控体系的核心数据基础。比如CPU使用率、接口QPS、GC停顿时间,都属于指标范畴。
- 链路(Tracing) :单次请求的全生命周期流转数据,核心用于分布式系统的问题定位,记录请求从网关到各个微服务、数据库、缓存、第三方接口的完整调用路径、耗时、异常信息,通过TraceId串联整个请求链路。
- 日志(Logging) :离散的事件记录,核心用于根因排查、问题详情追溯,记录程序运行过程中的具体事件、异常堆栈、业务上下文,是故障发生后定位根因的核心依据。
三者不是替代关系,而是互补关系:通过指标发现异常,通过链路定位异常发生的环节,通过日志查看异常的详细原因,构成完整的问题排查闭环。
1.2 监控体系的五层分层架构
一套完整的监控体系,需要从下到上覆盖基础设施、容器运行时、应用、业务、全链路五个层级,避免监控盲区。
1.2.1 基础设施层监控
基础设施层是服务运行的底层底座,覆盖物理机/虚拟机、网络、存储三大核心模块,是所有服务稳定运行的基础。
核心监控指标
| 资源类型 | 核心监控指标 | 指标核心含义 |
|---|---|---|
| CPU | 使用率、1分钟/5分钟/15分钟系统负载、上下文切换频率、软中断占比 | 区分CPU使用率与系统负载:使用率是单位时间内CPU忙碌的比例,负载是等待CPU处理的任务队列长度;单核CPU负载达到1为满负荷,多核CPU满负荷负载等于核心数 |
| 内存 | 使用率、可用内存、swap使用率、swap in/out频率、OOM-Kill事件 | 重点关注swap使用,频繁swap in/out会导致服务性能急剧下降;OOM-Kill事件必须100%覆盖监控 |
| 磁盘 | 分区使用率、inode使用率、IOPS、读写吞吐量、await响应时间、%util使用率 | 重点关注inode使用率,磁盘使用率正常但inode占满会导致无法写入文件;await是IO请求的平均处理时间,机械盘超过20ms、SSD超过1ms即为异常 |
| 网络 | 入/出带宽使用率、TCP重传率、TCP连接数、错包/丢包率、TCP握手失败次数 | TCP重传率超过0.1%会严重影响服务性能,必须重点监控;关注TIME_WAIT、CLOSE_WAIT连接数,避免连接耗尽 |
落地实现
基础设施层监控采用Prometheus + node_exporter实现,核心配置如下:
makefile
# prometheus.yaml 抓取配置
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["10.0.0.1:9100", "10.0.0.2:9100"]
metrics_relabel_configs:
- source_labels: [__name__]
regex: node_cpu_.*|node_memory_.*|node_disk_.*|node_network_.*|node_load.*
action: keep1.2.2 容器与JVM运行时监控
Java服务大多运行在容器/K8s环境中,容器运行时与JVM虚拟机是Java服务运行的核心环境,也是线上问题的高发区。
容器核心监控指标
- 资源限制:CPU限额/请求值、内存限额/请求值
- 运行状态:CPU使用率、内存使用率、重启次数、健康检查失败次数、OOM事件
- 网络存储:容器网络入/出吞吐量、磁盘IO读写吞吐量、容器内文件系统使用率
JVM核心监控指标与底层逻辑
JVM监控是Java开发者必须掌握的核心能力,核心分为四大类指标,每一类都直接关联线上服务的稳定性:
-
内存指标
- 堆内存:Eden区、Survivor区、老年代的使用率、分配速率、最大容量
- 非堆内存:Metaspace、CodeCache、压缩类空间的使用率与容量
- 堆外内存:直接内存(Direct Buffer)、堆外内存的使用率与峰值
- 核心区分:堆内内存受JVM垃圾回收管理,堆外内存不受GC控制,需要手动释放,是内存泄漏的高发区
-
垃圾回收(GC)指标
- Young GC:次数、平均耗时、最大耗时、频率、晋升到老年代的对象大小
- Full GC:次数、耗时、STW停顿时间、触发原因、执行频率
- 异常GC事件:晋升失败(Promotion Failure)、并发模式失败(Concurrent Mode Failure)、元空间GC触发
-
线程与锁指标
- 线程总数、各状态线程数(RUNNABLE/BLOCKED/WAITING/TIMED_WAITING)
- 死锁线程数、线程阻塞次数、锁竞争耗时
- 线程池指标:核心线程数、最大线程数、活跃线程数、队列长度、拒绝执行次数
-
类加载与编译指标
- 已加载类总数、已卸载类总数、类加载速率
- JIT编译耗时、CodeCache使用率
落地实现
JVM监控采用Prometheus + JMX Exporter实现,核心配置如下:
bash
# jmx_exporter config.yaml
---
startDelaySeconds: 0
ssl: false
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:
- pattern: 'java.lang<type=OperatingSystem><>ProcessCpuLoad'
name: jvm_os_process_cpu_load
type: GAUGE
help: JVM进程CPU使用率
- pattern: 'java.lang<type=Memory><>HeapMemoryUsage'
name: jvm_memory_heap_used
type: GAUGE
help: JVM堆内存使用量
attrNameSnakeCase: true
- pattern: 'java.lang<type=GarbageCollector, name=.*><>CollectionTime'
name: jvm_gc_collection_time_ms
type: COUNTER
help: GC累计耗时
labels:
gc_name: $1
- pattern: 'java.lang<type=Threading><>ThreadCount'
name: jvm_threads_total
type: GAUGE
help: JVM当前线程总数1.2.3 应用层监控
应用层监控聚焦Java服务本身的运行状态,是直接反映服务可用性的核心层级,核心覆盖服务可用性、请求性能、外部依赖三大模块。
核心监控指标
-
服务可用性指标
- 服务健康检查状态、在线实例数、上下线事件、进程存活状态
- 服务启动/停止事件、配置变更事件、发布事件
-
请求核心指标
- 流量指标:QPS、峰值QPS、请求总量
- 性能指标:请求响应时间,重点关注P50/P95/P99/P999分位值,而非平均响应时间
- 错误指标:请求成功率、错误码分布(4xx/5xx)、异常类型分布
- 核心区分:平均响应时间会被极端值掩盖,无法反映真实的用户体验;P99分位值代表99%的请求都能在该时间内完成,是衡量用户体验的核心指标
-
外部依赖指标
- 数据库:连接池活跃连接数、等待连接数、SQL执行耗时、慢SQL次数、事务提交/回滚次数
- 缓存:Redis命令执行QPS、响应时间、错误次数、连接数、命中率
- 消息队列:生产/消费TPS、消息堆积量、消费延迟、发送失败次数
- 第三方接口:调用QPS、响应时间、成功率、超时次数
落地实现
应用层监控采用Spring Boot Actuator + Micrometer实现,核心依赖与代码如下:
xml
<!-- pom.xml 核心依赖 -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
<version>3.3.5</version>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<version>1.13.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
<version>3.3.5</version>
</dependency>
</dependencies>
yaml
# application.yaml 配置
management:
endpoints:
web:
exposure:
include: health,prometheus,info
endpoint:
health:
show-details: always
metrics:
tags:
application: ${spring.application.name}
distribution:
percentiles-histogram:
http.server.requests: true
ini
// 自定义请求指标统计切面
package com.example.monitor.aspect;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import jakarta.servlet.http.HttpServletRequest;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import java.util.concurrent.TimeUnit;
@Aspect
@Component
public class RequestMetricsAspect {
private final MeterRegistry meterRegistry;
public RequestMetricsAspect(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
@Around("@annotation(org.springframework.web.bind.annotation.RequestMapping) || @annotation(org.springframework.web.bind.annotation.GetMapping) || @annotation(org.springframework.web.bind.annotation.PostMapping)")
public Object aroundRequest(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.nanoTime();
String path = "unknown";
String method = "unknown";
int status = 200;
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes != null) {
HttpServletRequest request = attributes.getRequest();
path = request.getRequestURI();
method = request.getMethod();
}
try {
Object result = joinPoint.proceed();
return result;
} catch (Exception e) {
status = 500;
throw e;
} finally {
long duration = System.nanoTime() - start;
Timer.builder("http.server.requests.custom")
.tag("path", path)
.tag("method", method)
.tag("status", String.valueOf(status))
.register(meterRegistry)
.record(duration, TimeUnit.NANOSECONDS);
meterRegistry.counter("http.request.total",
"path", path,
"method", method,
"status", String.valueOf(status))
.increment();
}
}
}1.2.4 业务层监控
技术指标正常不代表业务正常,比如支付接口返回200,但实际支付成功率暴跌,这类问题技术监控无法发现,必须通过业务层监控覆盖。业务层监控的核心是:以用户视角,监控核心业务流程的健康状态。
核心监控维度
- 核心业务流程转化率:覆盖用户核心操作的全链路,比如电商场景的商品曝光→点击→加购→下单→支付→发货的全链路转化率,每个环节的转化率异常都能反映业务问题。
- 业务成功率:核心业务操作的成功/失败比例,比如支付成功率、订单创建成功率、用户注册成功率、退款处理成功率。
- 业务量指标:核心业务的实时数据,比如订单量、支付金额、新增用户数、活跃用户数,对比历史同期数据,发现异常波动。
- 业务异常事件:比如库存不足、风控拦截、支付渠道异常、退款失败等业务异常事件的发生次数与频率。
落地实现
业务层监控通过Micrometer自定义业务指标+AOP埋点实现,核心代码如下:
java
// 业务指标注解
package com.example.monitor.annotation;
import java.lang.annotation.*;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface BusinessMetrics {
String businessType();
String operation();
}
java
// 业务指标切面
package com.example.monitor.aspect;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class BusinessMetricsAspect {
private final MeterRegistry meterRegistry;
public BusinessMetricsAspect(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
@Around("@annotation(businessMetrics)")
public Object aroundBusinessOperation(ProceedingJoinPoint joinPoint, BusinessMetrics businessMetrics) throws Throwable {
String businessType = businessMetrics.businessType();
String operation = businessMetrics.operation();
String status = "success";
try {
Object result = joinPoint.proceed();
return result;
} catch (Exception e) {
status = "fail";
throw e;
} finally {
Counter.builder("business.operation.total")
.tag("business_type", businessType)
.tag("operation", operation)
.tag("status", status)
.register(meterRegistry)
.increment();
}
}
}
less
// 业务代码使用示例
package com.example.service;
import com.example.monitor.annotation.BusinessMetrics;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
@BusinessMetrics(businessType = "order", operation = "create")
public void createOrder() {
// 订单创建业务逻辑
}
@BusinessMetrics(businessType = "payment", operation = "pay")
public void payOrder() {
// 订单支付业务逻辑
}
}1.2.5 全链路追踪监控
分布式微服务架构下,一个用户请求会经过网关、多个微服务、数据库、缓存、消息队列等多个节点,一旦出现异常,很难快速定位问题发生的环节。全链路追踪的核心价值,就是通过全局唯一的TraceId,串联起请求的完整流转路径,实现分布式场景下的问题快速定位。
全链路追踪遵循W3C Trace Context全球统一规范,核心概念如下:
- Trace:一次用户请求的完整链路,对应一个全局唯一的TraceId,贯穿整个请求的全生命周期
- Span:请求链路中的一个独立操作单元,比如一次RPC调用、一次数据库查询、一次Redis操作,每个Span都有唯一的SpanId,同时记录父SpanId,形成父子关联关系
- Span Context:Span的上下文信息,包含TraceId、SpanId、采样标记等,在服务之间传递,实现链路的串联
落地实现
全链路追踪采用OpenTelemetry实现,核心配置与集成方式如下:
- 下载OpenTelemetry Java Agent,通过JVM参数挂载到服务启动命令中:
ini
java -javaagent:opentelemetry-javaagent-2.8.0.jar \
-Dotel.service.name=order-service \
-Dotel.traces.exporter=otlp \
-Dotel.metrics.exporter=otlp \
-Dotel.logs.exporter=otlp \
-Dotel.exporter.otlp.endpoint=http://otel-collector:4317 \
-jar order-service.jar- 日志集成TraceId,通过Logback配置实现日志中打印TraceId,实现链路与日志的串联:
xml
<!-- logback-spring.xml 配置 -->
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} trace_id=%X{trace_id} span_id=%X{span_id} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>二、智能告警体系:从告警泛滥到精准触达的核心设计
监控的目的是发现问题,而告警的目的是把问题及时通知给对应的负责人,推动问题解决。但绝大多数团队都面临告警泛滥的问题:每天收到上百条告警,绝大多数都是无效噪音,导致真正的故障告警被淹没,等到用户反馈才发现问题,完全失去了告警的意义。
告警体系的核心设计原则来自Google SRE工作手册,核心是四个关键词:可处理、分级、有上下文、可闭环。
2.1 告警设计的核心原则
- 告警必须是可处理的:这是告警设计的第一原则。如果一条告警触发后,没有对应的处理预案,也不需要人工介入处理,就绝对不要发送告警。无效告警只会增加噪音,降低团队对告警的敏感度。
- 告警必须有明确的分级:不同严重程度的告警,对应不同的通知方式、响应时效、处理流程,绝对不能所有告警都用电话通知,也不能所有告警都只发群消息。
- 告警必须包含完整的上下文:一条合格的告警,必须让接收人一眼就能看懂:发生了什么问题、影响范围有多大、当前的指标数据是什么、对应的处理预案在哪里,而不是只简单说一句"CPU使用率过高"。
- 告警必须形成闭环:每一条告警都必须有触发、通知、处理、关闭的完整流程,告警触发后必须有人跟进处理,处理完成后必须关闭告警,不能石沉大海。
2.2 告警分级标准与响应规范
告警分级是告警体系的核心,必须结合业务影响范围、严重程度制定明确的分级标准,全团队统一认知,统一执行。通用的告警分级分为P0-P3四个等级,具体标准如下:
| 告警级别 | 严重程度 | 核心定义 | 通知方式 | 响应时效 | 处理要求 |
|---|---|---|---|---|---|
| P0 | 致命 | 核心业务全量中断,大面积用户无法使用,造成重大业务损失 | 电话+短信+工作群@全体相关负责人 | 5分钟内必须响应 | 立即启动最高级别应急响应,30分钟内完成止损或业务恢复 |
| P1 | 严重 | 核心业务部分受损,非核心功能中断,影响部分用户使用 | 工作群@对应负责人+短信通知 | 10分钟内必须响应 | 1小时内完成问题处理或业务恢复 |
| P2 | 一般 | 非核心业务异常,不影响用户正常使用,不影响核心业务运行 | 工作群普通消息通知 | 30分钟内必须响应 | 4小时内完成问题处理,不影响业务正常运行 |
| P3 | 提示 | 常规提示类信息,无业务影响,仅需后续关注处理 | 仅系统记录,不主动通知 | 无强制响应时效 | 下个工作日内完成查看与处理 |
2.3 告警降噪的核心策略
告警泛滥的核心原因,是没有做有效的告警降噪,导致大量无效告警淹没了核心告警。常用的告警降噪策略有四种,覆盖告警触发的全流程。
2.3.1 告警抑制
告警抑制的核心逻辑是:当高优先级的告警触发后,自动抑制所有由该故障引发的低优先级、下游依赖的告警,避免告警风暴。
- 典型场景:数据库宕机触发P0告警后,自动抑制所有调用该数据库的服务的接口报错、超时告警,只保留数据库的核心P0告警,避免一次性收到上百条告警。
- 实现方式:通过Alertmanager的inhibit_rules配置实现。
2.3.2 告警聚合
告警聚合的核心逻辑是:将相同服务、相同类型、相同原因的告警,聚合为一条告警通知,避免重复告警。
- 典型场景:集群中100台机器同时触发CPU使用率过高告警,不会发送100条告警,而是聚合为一条告警,说明影响的机器数量、集群、指标范围。
- 实现方式:通过Alertmanager的group_by配置实现,按服务名、告警类型、故障原因分组聚合。
2.3.3 告警静默
告警静默的核心逻辑是:在特定时间窗口内,对特定的告警临时屏蔽通知,避免无效告警。
- 典型场景:服务发布、配置变更、集群扩容、常规运维操作期间,会触发服务重启、健康检查失败、流量波动等临时告警,设置10分钟的静默窗口,不发送告警。
- 实现方式:通过Alertmanager的静默规则实现,支持按时间、服务、告警类型设置静默规则。
2.3.4 动态阈值告警
固定阈值是告警误报的核心原因之一:比如设置CPU使用率超过80%触发告警,凌晨业务低峰期80%的使用率是异常,白天业务高峰期80%的使用率是正常状态,固定阈值会导致大量误报。 动态阈值的核心逻辑是:基于历史同期的指标数据,计算正常的指标基线,当实时指标超过基线的合理幅度时,才触发告警。比如:CPU使用率超过过去7天同期平均值的30%,且持续3分钟,才触发告警。
2.4 告警体系落地实现
告警体系采用Prometheus + Alertmanager实现,核心配置如下:
bash
# prometheus.rules.yaml 告警规则配置
groups:
- name: service_alerts
rules:
- alert: ServiceHighErrorRate
expr: sum(rate(http.request.total{status=~"5.."}[1m])) / sum(rate(http.request.total[1m])) > 0.01
for: 1m
labels:
severity: P0
annotations:
summary: "服务接口错误率过高"
description: "服务{{ $labels.application }}接口5xx错误率超过1%,当前错误率{{ $value | humanizePercentage }},持续时间1分钟"
service: "{{ $labels.application }}"
instance: "{{ $labels.instance }}"
impact: "核心业务接口异常,可能导致用户无法正常使用服务"
plan: "1. 查看服务日志与链路追踪,确认错误原因;2. 若为最近发布导致,立即回滚版本;3. 若为依赖异常,执行降级熔断策略"
- alert: JVMFullGCFrequent
expr: increase(jvm_gc_collection_time_ms{gc_name=~"G1 Old Generation|Full GC"}[5m]) > 0
for: 5m
labels:
severity: P1
annotations:
summary: "JVM Full GC频繁"
description: "服务{{ $labels.application }}实例{{ $labels.instance }}5分钟内发生多次Full GC,累计GC耗时{{ $value }}ms"
service: "{{ $labels.application }}"
instance: "{{ $labels.instance }}"
impact: "服务卡顿、响应时间变长,严重时会导致服务不可用"
plan: "1. 查看JVM监控,确认堆内存使用情况;2. 抓取堆内存Dump,分析是否存在内存泄漏;3. 若为内存泄漏,立即回滚相关版本"
- alert: NodeHighCpuLoad
expr: node_load1 / count by (instance) (node_cpu_seconds_total{mode="idle"}) > 0.8
for: 3m
labels:
severity: P2
annotations:
summary: "服务器CPU负载过高"
description: "服务器{{ $labels.instance }}1分钟CPU负载超过核心数的80%,当前负载{{ $value }}"
instance: "{{ $labels.instance }}"
impact: "服务器性能下降,运行在该服务器上的服务响应变慢"
plan: "1. 查看服务器进程,确认CPU占用高的进程;2. 若为业务进程,查看是否有死循环、频繁GC等问题;3. 若为流量突增,执行扩容操作"
rust
# alertmanager.yaml 核心配置
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'service', 'severity']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'default-receiver'
routes:
- match:
severity: P0
receiver: 'p0-receiver'
continue: false
- match:
severity: P1
receiver: 'p1-receiver'
continue: false
inhibit_rules:
- source_match:
severity: P0
target_match:
severity: P1
equal: ['service']
receivers:
- name: 'p0-receiver'
webhook_configs:
- url: 'http://alert-notify:8080/webhook/p0'
send_resolved: true
- name: 'p1-receiver'
webhook_configs:
- url: 'http://alert-notify:8080/webhook/p1'
send_resolved: true
- name: 'default-receiver'
webhook_configs:
- url: 'http://alert-notify:8080/webhook/default'
send_resolved: true三、应急响应SOP:故障处理的标准化全流程落地
再完善的监控和告警,也无法完全避免故障的发生。当故障发生时,一套标准化的应急响应SOP,能避免团队手忙脚乱、多人操作引发二次故障、故障持续时间无限拉长,实现故障的快速止损、最小化影响。
应急响应的核心原则来自Google SRE应急响应规范,核心是:止损优先、分工明确、全程留痕、不盲目操作。
3.1 应急响应全流程SOP
应急响应全流程分为6个标准化阶段,形成完整的故障处理闭环,流程如下:
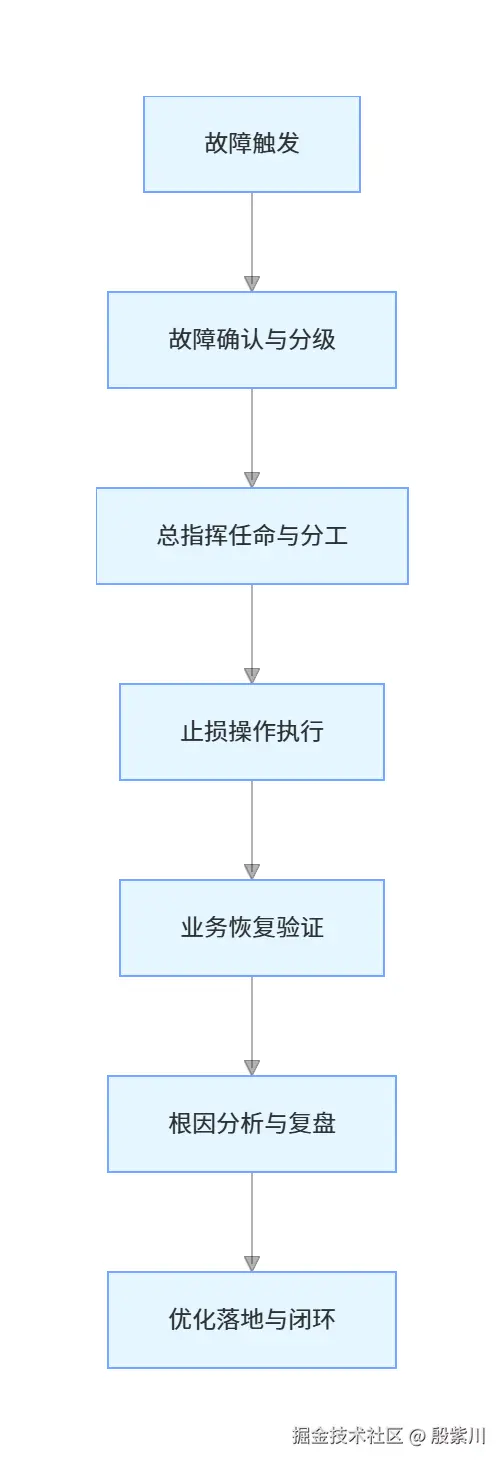
3.1.1 故障触发阶段
故障触发的来源主要有三个:监控告警触发、用户/客服反馈、内部人员巡检发现。 该阶段的核心动作只有一个:立即通知对应服务的负责人,启动故障确认流程,绝对不能视而不见、拖延处理。
3.1.2 故障确认与分级阶段
该阶段是应急响应的基础,必须在最短时间内完成故障的确认、影响范围评估、级别判定,核心动作如下:
-
故障真实性确认:通过监控、日志、链路追踪,确认故障是否真实存在,排除误告警、误报。
-
故障信息收集:通过标准化checklist,收集完整的故障信息,避免信息混乱:
- 故障现象:具体是什么异常?比如接口报错、服务超时、页面无法打开、业务数据异常
- 故障开始时间:精确到分钟,确认故障首次发生的时间
- 影响范围:影响的服务、集群、机房、可用区
- 用户影响:影响的用户群体、用户数量、是否全量用户受影响
- 业务影响:是否影响核心业务、是否造成收入损失、是否有品牌舆情风险
- 变更关联:故障发生前1小时内,是否有代码发布、配置变更、扩容缩容、数据库变更、第三方接口调整
-
故障级别判定:根据故障影响范围、严重程度,对照P0-P3分级标准,判定故障级别,P0/P1级故障必须立即启动全流程应急响应。
-
应急群组建:P0/P1级故障必须立即拉取应急响应群,邀请所有相关服务的负责人、运维、DBA、管理层加入,统一信息同步渠道。
3.1.3 总指挥任命与分工阶段
故障处理过程中,最大的混乱来源就是多头指挥、多人操作、职责不清,甚至出现多人同时操作同一集群,引发二次故障。该阶段的核心是明确总指挥,统一分工,统一指令出口。
-
总指挥任命:P0/P1级故障必须任命一名总指挥,全权负责故障处理的所有决策,所有操作指令必须由总指挥发出,所有信息必须同步给总指挥,避免多头指挥。
-
标准化分工:应急团队分为四个核心小组,职责明确,互不越权:
- 总指挥:统筹全局,决策止损方案,协调资源,把控故障处理进度,最终决策所有操作
- 操作执行组:严格按照总指挥的指令,执行具体的操作,比如版本回滚、流量切换、降级熔断、扩容限流,操作前必须双人复核,操作后同步结果给总指挥
- 信息同步组:全程记录故障处理的所有操作、决策、时间节点,同步故障进展给相关方,统一对外沟通口径,避免信息混乱
- 根因分析组:在不影响止损操作的前提下,同步排查故障根因,为总指挥的止损决策提供数据支撑,绝对不能为了找根因而耽误止损操作
-
核心规则明确:故障处理期间,所有人员必须服从总指挥的指令,没有总指挥的同意,任何人不得私自执行任何线上操作,避免引发二次故障。
3.1.4 止损操作执行阶段
该阶段是应急响应的核心,第一原则是止损优先,根因分析在后。80%以上的线上故障,都是由最近的变更导致的,优先执行止损操作,先恢复业务,再排查根因,绝对不能为了找根因而放任故障持续。
止损操作有明确的优先级排序,优先执行风险最低、见效最快的操作,避免盲目操作:
-
第一优先级:回滚最近的变更 回滚是最安全、最有效、见效最快的止损方式。只要故障发生前有相关的变更,且无法在短时间内确认变更无问题,优先执行回滚操作,不要犹豫。 可回滚的变更包括:代码版本发布、配置文件变更、数据库表结构变更、业务规则调整、限流降级规则变更、第三方依赖版本升级。 核心要求:所有线上变更必须支持一键回滚,必须有完整的回滚方案,禁止发布无法回滚的变更。
-
第二优先级:流量切换与故障隔离 如果故障是由特定集群、机房、可用区、节点导致的,立即执行流量切换,把故障节点的流量切到正常节点,隔离故障源,快速恢复业务。 典型场景:
- 单机房故障,把流量切到备用机房
- 部分服务实例异常,从注册中心摘除异常实例,隔离故障节点
- 灰度发布的版本出现异常,立即关闭灰度流量,切回稳定版本
-
第三优先级:降级与熔断 如果故障是由非核心功能、第三方依赖异常导致的,立即执行降级、熔断操作,关闭非核心功能,熔断异常的第三方依赖,保证核心业务的正常运行。 降级熔断的实现采用Resilience4j,核心代码示例如下:
typescript
package com.example.fallback;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import io.github.resilience4j.retry.annotation.Retry;
import org.springframework.stereotype.Component;
@Component
public class ThirdPartyServiceClient {
@CircuitBreaker(name = "logisticsService", fallbackMethod = "logisticsServiceFallback")
@Retry(name = "logisticsService", fallbackMethod = "logisticsServiceFallback")
public String getLogisticsInfo(String orderId) {
// 调用第三方物流接口
return callLogisticsApi(orderId);
}
public String logisticsServiceFallback(String orderId, Exception e) {
// 降级处理,返回默认值
return "物流信息查询暂时不可用";
}
private String callLogisticsApi(String orderId) {
// 第三方接口调用实现
return "";
}
}- 第四优先级:扩容与限流 如果故障是由流量突增、服务器资源不足导致的,立即执行扩容操作,增加服务实例数,提升服务处理能力;如果扩容无法解决问题,立即执行限流操作,保护核心业务,拒绝超出服务处理能力的请求,避免服务被完全打垮。 限流的实现采用Resilience4j RateLimiter,核心代码示例如下:
kotlin
package com.example.ratelimit;
import io.github.resilience4j.ratelimiter.annotation.RateLimiter;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class OrderController {
@GetMapping("/order/{orderId}")
@RateLimiter(name = "orderQuery", fallbackMethod = "orderQueryFallback")
public String getOrderInfo(@PathVariable String orderId) {
// 订单查询业务逻辑
return "订单信息";
}
public String orderQueryFallback(String orderId, Exception e) {
return "当前查询人数过多,请稍后再试";
}
}- 最低优先级:重启服务 重启服务是下下策,只有在万不得已的情况下才能使用。重启会丢失故障现场,导致后续无法排查根因,而且如果是代码逻辑问题,重启后故障依然会复现。 只有在确认故障是由资源泄漏(内存泄漏、句柄泄漏、线程泄漏)导致,重启能临时恢复业务的情况下,才能执行重启操作,且重启前必须保留完整的故障现场:抓取堆内存Dump、线程栈、GC日志。
3.1.5 业务恢复验证阶段
止损操作执行后,必须通过标准化的验证流程,确认业务已经完全恢复,绝对不能凭感觉判断恢复。核心验证动作如下:
-
技术指标验证:确认核心技术指标恢复到正常水平,包括:
- 服务接口成功率、RT、QPS恢复到正常区间
- 服务实例健康检查全部正常,无异常告警
- JVM、服务器资源指标恢复正常,无异常GC、资源占用过高的情况
- 数据库、缓存、消息队列等外部依赖调用正常,无报错、无超时
-
业务指标验证:确认核心业务指标恢复到正常水平,包括:
- 核心业务流程转化率、成功率恢复正常
- 订单量、支付量、用户操作量恢复到历史同期正常水平
- 无新增的业务异常事件
-
场景抽样验证:模拟用户操作,对核心业务场景进行全流程抽样验证,确认功能正常可用,比如:
- 用户注册、登录、下单、支付全流程验证
- 核心页面访问、功能操作验证
-
持续观察:业务恢复后,必须持续观察10-30分钟,确认业务稳定运行,无异常波动,无故障复现,才能宣布故障结束。
3.1.6 根因分析与复盘阶段
业务恢复后,必须在1个工作日内完成故障复盘,核心目标不是追责,而是找到故障的根本原因,避免同样的故障再次发生。
-
根因分析方法:采用5Why分析法,层层深挖,找到根本原因,而不是停留在表面原因。 示例:
- 表面问题:服务频繁Full GC,导致业务卡顿
- 第1个Why:为什么频繁Full GC?老年代内存占满,无法释放
- 第2个Why:为什么老年代占满?存在内存泄漏,对象无法被GC回收
- 第3个Why:为什么存在内存泄漏?ThreadLocal中存放了大对象,没有手动remove
- 第4个Why:为什么没有remove?代码中只在正常流程执行了remove,异常场景没有在finally块中执行remove
- 第5个Why:为什么代码存在漏洞?开发规范没有明确要求,Code Review没有检查到,静态代码扫描没有拦截
- 根本原因:开发规范缺失,代码评审流程不完善,自动化检测机制缺失,导致问题代码上线
-
复盘输出物:故障复盘必须输出标准化的文档,包含以下内容:
- 故障概述:故障发生时间、持续时间、影响范围、造成的损失
- 故障时间线:故障发生、发现、响应、止损、恢复的完整时间节点
- 根因分析:故障的直接原因、根本原因
- 止损过程:故障处理过程中执行的所有操作、对应的结果
- 优化项:可落地的优化措施,分为立即修复、短期优化、长期优化三类
-
优化项要求:所有优化项必须明确责任人、截止时间、验收标准,绝对不能是空泛的"加强测试""提升代码质量",必须是可落地、可验证的具体措施。
3.1.7 优化落地与闭环阶段
复盘的核心价值在于优化措施的落地,避免同样的故障再次发生。该阶段的核心动作是:
-
优化项跟踪:通过项目管理工具,跟踪所有优化项的落地进度,每周同步进展,确保所有优化项按时完成。
-
效果验证:优化项完成后,必须验证优化效果,比如:
- 新增的监控告警,必须测试是否能正常触发、正常通知
- 新增的静态代码扫描规则,必须验证是否能拦截对应的问题代码
- 完善的开发规范,必须组织团队培训,确保所有成员知晓
-
流程迭代:根据故障复盘的结果,迭代优化监控体系、告警规则、应急响应SOP,完善应急预案,形成完整的闭环,让运维体系持续优化。
3.2 应急响应的红线规则
故障处理过程中,有绝对不能触碰的红线,一旦违反,大概率会引发二次故障,扩大故障影响:
- 严禁无总指挥授权的私自线上操作,所有操作必须经过总指挥同意,双人复核后执行
- 严禁在故障期间同时执行多个变更操作,避免无法定位操作效果,引发新的故障
- 严禁执行无回滚方案的线上操作,所有操作必须有明确的回滚方案
- 严禁在未保留故障现场的情况下重启服务,避免根因无法排查
- 严禁对外发布不一致的故障信息,所有对外沟通必须由信息同步组统一口径
- 严禁为了排查根因而耽误止损操作,永远坚持止损优先的原则
四、运维体系的闭环优化
一套有效的线上运维体系,不是一次性搭建完成就一劳永逸的,而是需要持续迭代、持续优化的闭环系统。整个体系的闭环逻辑如下:
- 通过监控体系发现线上风险与异常
- 通过告警体系将异常及时通知给对应负责人
- 通过应急响应SOP完成故障的快速止损与恢复
- 通过故障复盘找到体系中的漏洞与不足
- 通过优化措施完善监控、告警、应急流程,填补漏洞
- 回到第一步,持续迭代优化
运维体系的优化,核心是围绕"如何更早发现风险、如何更精准通知告警、如何更快止损故障、如何避免故障再次发生"这四个核心目标,持续完善每一个环节,最终实现从被动救火到主动防控的转变,保障线上服务的长期稳定运行。
结尾
线上服务的稳定性,从来都不是靠某一个人的经验,而是靠一套完整、标准化、可落地的体系。监控体系是眼睛,帮你发现风险;告警体系是神经,帮你传递信息;应急响应SOP是手脚,帮你快速解决问题。