导读
达芬奇手术机器人等机器人辅助手术(RAS)系统已在现代手术室中广泛应用,但术中场景理解仍然是一个未解难题------器械频繁遮挡、解剖结构快速变化、多个任务(器械识别、动作识别、下一步预测等)之间存在强依赖关系。现有方法要么是为单一任务训练的专用模型,缺乏跨任务泛化能力;要么是通用VLM直接零样本推理,但因缺少手术领域知识而产生大量幻觉。
新加坡国立大学(NUS)Yueming Jin团队提出了SurgRAW,一个面向手术视频分析的层级多Agent推理框架。SurgRAW将手术场景理解任务分为视觉-语义(VS) 和认知-推理(CI) 两条推理流,由中央编排器分配给专门的Agent处理。VS流通过Panel Discussion(多Agent辩论+知识图谱验证) 确保视觉任务的准确性,CI流通过RAG(检索增强生成) 引入手术领域知识弥补VLM的领域缺口。每个Agent都配备了针对手术场景设计的任务专属CoT提示。
同时,团队发布了SurgCoTBench ------首个面向推理的手术视频基准,包含2,277帧、14,256个QA对、5类手术推理任务。在该基准上,SurgRAW零样本下的表现超越了需要训练的监督基线Surgical-VQA 14.61个百分点 ,相比标准VLM平均提升29.32个百分点。
论文信息
- 标题:SurgRAW: Multi-Agent Workflow with Chain of Thought Reasoning for Robotic Surgical Video Analysis
- 作者:Chang Han Low, Ziyue Wang, Tianyi Zhang, Zhu Zhuo, Zhitao Zeng, Evangelos B. Mazomenos, Yueming Jin(通讯作者)
- 机构:新加坡国立大学(NUS)、新加坡科技研究局(A*STAR)、伦敦大学学院(UCL)
- 发表:IEEE Robotics and Automation Letters (RA-L),2026年2月接收
- 代码 :github.com/jinlab-imvr...
一、手术视频场景理解为什么需要多Agent推理?
手术机器人视频的场景理解面临三个层面的挑战:
感知层面:手术视频中器械频繁重叠遮挡,解剖结构在操作过程中持续变化,空间关系高度动态。这对精细的视觉识别提出了很高要求。
推理层面:手术场景中的多个任务并非独立------识别器械类型影响对当前动作的判断,当前动作又影响对下一步操作的预测。现有方法通常将这些任务分开处理,忽略了任务之间的依赖关系。
知识层面:通用VLM缺少手术领域的专业知识(如达芬奇机器人的器械-动作对应关系、标准手术步骤序列等),直接应用时容易产生幻觉。而领域微调的手术VLM又需要大量标注数据,且仍缺乏跨任务的推理能力。
现有的手术视觉数据集也存在结构性问题:大多只标注1-3种任务,没有覆盖从器械识别到手术结局预测的完整推理链条,无法支撑统一的多任务评测。
SurgRAW同时发布了基准(SurgCoTBench)和方法,填补了这两个空白。
二、SurgCoTBench:首个面向推理的手术视频基准
任务体系
SurgCoTBench覆盖5类手术推理任务,反映了术中感知、空间理解和临床决策的层级关系:
| 任务 | 类型 | 描述 |
|---|---|---|
| 器械识别 | VS | 基于外观、工具几何和上下文线索识别机器人臂上的手术器械 |
| 动作识别 | VS | 判断每个器械正在执行的具体操作(抓取、切割、缝合等),区分左右臂 |
| 动作预测 | CI | 根据当前工具配置、解剖暴露和操作上下文预测下一步手术动作 |
| 患者信息推断 | CI | 从解剖外观、器官特征和视觉上下文推断患者的人口学和临床属性(如年龄段) |
| 手术结局评估 | CI | 基于工具-组织交互、解剖状态和操作线索判断当前帧的主要手术结局 |
其中器械识别和动作识别属于视觉-语义(VS)任务 ,依赖直接可见的视觉线索;动作预测、患者信息和手术结局属于认知-推理(CI)任务,需要结合上下文、领域知识和隐含线索进行推断。
数据构建
SurgCoTBench基于12个达芬奇手术视频(前列腺切除术 + 肺叶切除术)构建:
- 视频来源于公开的YouTube手术录像,包含手术医生的实时口头解说
- 使用Whisper提取语音转录,获得内容丰富、临床准确的文本标注
- 以1 FPS下采样,选取临床有意义的帧(如膀胱颈解剖、淋巴结清扫等阶段)
- GPT-4o基于每帧生成多选题QA对(每帧最多7个),经两位临床医师人工审查
最终数据集包含2,277帧、14,256个QA对。按患者分割为训练集(8个视频)和测试集(4个视频)。
三、SurgRAW的层级多Agent设计
3.1 整体架构
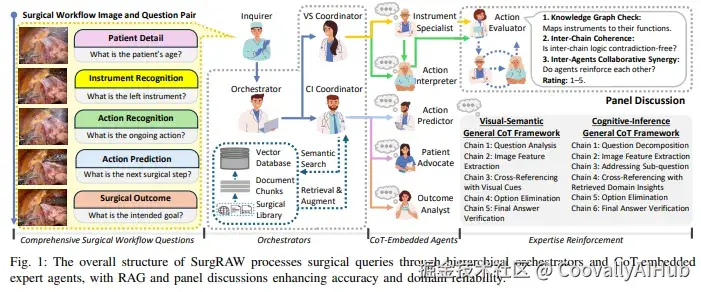
SurgRAW采用层级多Agent系统:
- 顶层编排器(Orchestrator) :接收手术图像和问题,将其分类为VS任务或CI任务
- VS协调器 / CI协调器:将任务分配给对应的专业Agent
- 专业Agent(共5个):器械专家、动作解读器、动作预测器、患者信息分析师、手术结局分析师
- 辅助模块:VS流的Panel Discussion(多Agent辩论),CI流的RAG(检索增强)
每个专业Agent都配备了针对手术场景定制的任务专属CoT提示,将手术推理分解为可验证的逐步推导链。
 图片来源于原论文
图片来源于原论文
3.2 VS流:CoT + Panel Discussion
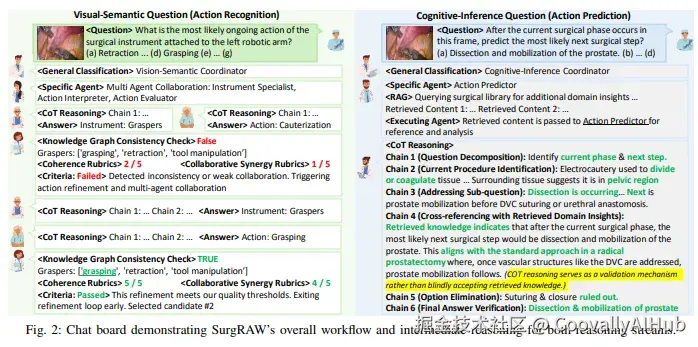
VS任务(器械识别、动作识别)采用5步CoT推理链:
- 问题分析:解析问题意图和约束
- 图像特征提取:识别相关物体、空间关系和视觉属性
- 视觉线索交叉验证:将提取的特征与问题预期对齐
- 选项排除:移除与视觉证据矛盾的选项
- 最终答案验证:确认选择与整体场景和当前手术阶段一致
在CoT推理之后,SurgRAW引入Panel Discussion机制,让多个VS Agent进行协作辩论。辩论由Action Evaluator主持,从三个维度评估:
- 知识图谱一致性检查:基于达芬奇手术机器人官方规格中的器械-动作对应关系,过滤掉不合理的预测
- 链间逻辑连贯性(Inter-Chain Coherence) :评估单个Agent的CoT推理过程是否自洽
- 跨Agent协同性(Inter-Agents Collaborative Synergy) :评估不同Agent的预测是否相互印证
只有当知识图谱检查通过且两个评估维度得分均≥3/5时,结果才被接受;否则触发新一轮协作推理,最多迭代3次。
3.3 CI流:CoT + RAG
CI任务(动作预测、患者信息、手术结局)采用6步CoT推理链:
- 问题分解:将问题拆分为子问题
- 图像特征提取 / 当前操作识别
- 子问题解答:结合视觉线索和上下文
- 领域知识交叉验证:用检索到的手术知识验证中间结论
- 选项排除
- 最终答案验证
CI流的关键辅助模块是RAG:CI协调器从MedlinePlus等医学资源库中检索相关文档,将检索内容动态注入Agent的CoT推理过程。这确保推理结果与已有临床标准对齐,减少幻觉。
图片来源于原论文
四、实验:零样本下的表现如何?
实验设置
- VLM骨干:GPT-4o和Qwen3VL-8B两个版本
- 对比方法:通用VLM(GPT-4o、Qwen3VL-8B、LLaVA-OV-7B)、领域医学VLM(MedGemma、LLaVA-Med-7B)、CoT方法(LLaVA-CoT)、多Agent框架(MDAgents、MedAgents)、监督基线(Surgical-VQA)
- 评估指标:准确率(Acc),3次独立运行的均值±标准差
- SurgRAW为零样本,Surgical-VQA需要训练数据
主要结果
| 方法 | 总体 | CI任务均值 | VS任务均值 |
|---|---|---|---|
| Surgical-VQA(监督) | 47.12±5.46 | 58.76±11.18 | 30.37±1.79 |
| GPT-4o | 31.44±2.57 | 20.11±2.98 | 40.39±3.04 |
| Qwen3VL-8B | 35.69±0.47 | 30.16±1.10 | 44.81±0.48 |
| LLaVA-CoT (GPT-4o) | 38.92±1.83 | 40.74±2.02 | 34.55±1.81 |
| MDAgents (GPT-4o) | 32.88±2.31 | 20.38±2.72 | 41.77±3.01 |
| MedAgents (GPT-4o) | 31.96±2.85 | 20.11±3.21 | 41.71±3.44 |
| SurgRAW-GPT4o | 61.73±2.42 | 70.39±2.16 | 49.81±2.31 |
| SurgRAW-Qwen3VL-8B | 64.03±1.51 | 62.86±2.06 | 65.01±2.20 |
几个关键观察:
- SurgRAW零样本超越监督基线:SurgRAW-GPT4o(61.73)超过需要训练的Surgical-VQA(47.12)14.61个百分点。SurgRAW-Qwen3VL-8B(64.03)进一步拉大差距
- 相比标准VLM平均提升29.32个百分点:GPT-4o从31.44提升到61.73(+30.29),Qwen3VL-8B从35.69提升到64.03(+28.34),平均+29.32
- CI任务提升尤为显著:SurgRAW-GPT4o在Patient Detail上达到96.21(基线GPT-4o仅9.44),Action Prediction从32.98提升到70.48
- SurgRAW的稳定性远优于监督基线:SurgRAW-Qwen3VL-8B的标准差仅±1.51%,而Surgical-VQA高达±5.46%
- 现有多Agent框架在手术领域效果极为有限:MDAgents(32.88)和MedAgents(31.96)与直接用GPT-4o(31.44)相当,几乎没有带来提升,说明通用多Agent框架无法直接迁移到手术场景
- 开源骨干可以超越闭源:SurgRAW-Qwen3VL-8B(64.03)> SurgRAW-GPT4o(61.73),Qwen3VL-8B在VS任务上优势尤为明显(65.01 vs 49.81)
消融实验
CI任务消融(SurgRAW-GPT4o):
| 配置 | 动作预测 | 手术结局 | 患者信息 | CI均值 |
|---|---|---|---|---|
| 无CoT、无RAG | 32.98±5.81 | 17.92±7.33 | 9.44±5.62 | 20.11±2.98 |
| +CoT | 35.68±4.91 | 37.83±5.14 | 56.04±4.00 | 41.32±2.52 |
| +RAG | 49.66±4.27 | 41.51±4.4 | 78.16±3.4 | 58.97±2.2 |
| +CoT+RAG | 70.48±2.81 | 42.87±3.11 | 96.21±3.53 | 70.39±2.16 |
VS任务消融(SurgRAW-GPT4o):
| 配置 | 动作识别 | 器械识别 | VS均值 |
|---|---|---|---|
| 无CoT、无PD | 37.21±7.94 | 43.57±8.83 | 40.39±3.04 |
| +CoT | 39.33±6.85 | 43.57±8.83 | 40.74±3.01 |
| +PD(Panel Discussion) | 41.25±5.61 | 54.13±1.93 | 46.72±2.81 |
| +CoT+PD | 44.52±2.88 | 54.13±1.93 | 49.81±2.31 |
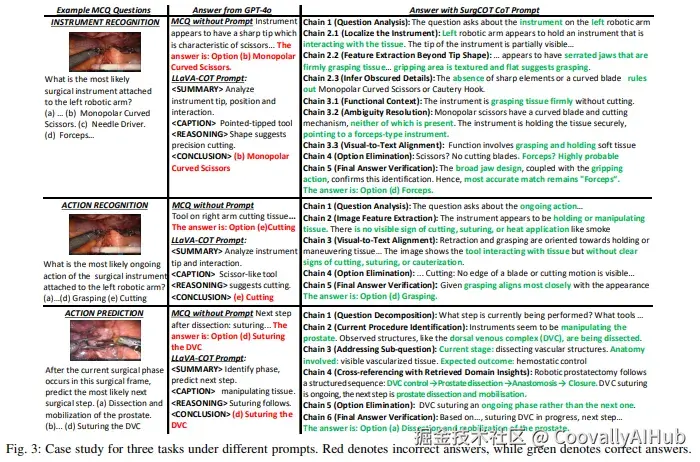
- CoT是CI任务的核心贡献者:仅加CoT就让CI均值从20.11%提升到41.32%(+21.21个百分点),RAG进一步提升至70.39%
- RAG与CoT组合效果远超单独使用:单独用RAG达到58.97%,单独用CoT达到41.32%,两者组合达到70.39%------这说明CoT提供的结构化推理框架使RAG检索到的知识能被更有效地利用
- Panel Discussion对VS任务至关重要:在器械识别上,Panel Discussion直接将准确率从43.57%提升到54.13%(+10.56个百分点),并大幅降低了标准差(从±8.83到±1.93)
 图片来源于原论文
图片来源于原论文
五、总结与思考
核心贡献
SurgRAW的工作包含基准和方法两个层面:
- SurgCoTBench填补了手术视频领域缺少统一多任务推理基准的空白,5类任务覆盖了从感知到临床推理的完整层级。手术医生实时口头解说经Whisper转录后作为高质量语义标注的来源,是一个值得借鉴的数据构建思路
- SurgRAW的双流设计很好地匹配了手术理解中两类任务的不同特点:VS任务需要多Agent交叉验证视觉证据,CI任务需要外部领域知识补充。Panel Discussion和RAG分别针对这两类需求设计
- 任务专属CoT将手术推理拆解为可检查的逐步链条,不依赖LLM自动生成的CoT(LLaVA-CoT在手术领域效果有限),而是根据手术工作流结构人工设计CoT模板
局限性
- 帧级推理的局限:SurgRAW处理单帧输入,无法利用视频的时序信息。论文也提到未来计划扩展到时序推理
- 数据规模有限:SurgCoTBench仅包含12个视频(前列腺切除术+肺叶切除术两种术式),2,277帧。覆盖的术式和场景多样性有限
- 依赖GPT-4o生成QA对:基准中的问题由GPT-4o生成,虽经临床医师审查,但生成质量仍受限于GPT-4o对手术场景的理解能力
- 推理开销:多Agent框架相比单次VLM推理有额外的计算开销
个人思考
SurgRAW在手术AI领域的定位很有价值:它不是要替代专用的器械检测或动作分割模型,而是提供一个可解释的推理层,将多个底层感知任务串联成连贯的临床理解。Panel Discussion机制中基于达芬奇器械规格的知识图谱验证是一个实用的设计------它将硬性的领域约束(如"什么器械能做什么动作")编码为Agent交互的过滤规则。
一个值得关注的结果是:SurgRAW-Qwen3VL-8B(64.03)在总体和VS任务上都超过了SurgRAW-GPT4o(61.73),这说明在配备了合适的Agent框架和CoT后,开源VLM在手术视觉理解上的潜力可以被充分释放,甚至超过闭源模型。