要掌握的不只是"会写几个存储过程",而是要把存储过程、变量、条件判断、参数、分支、循环、游标、条件处理程序、存储函数、触发器这一整套都串起来。后面列出来的面试题,本质上就是这一章
把它理解成:
- 存储过程:数据库里的"函数/方法"
- 变量:数据库编程时临时保存数据
- SQL编程:让 SQL 不只是查表,还能做流程控制
- 触发器:表发生增删改时自动执行的逻辑
存储过程
存储过程是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字和参数来执行,并获取相应结果。 应用程序可以直接 CALL 存储过程名(...) 去调用
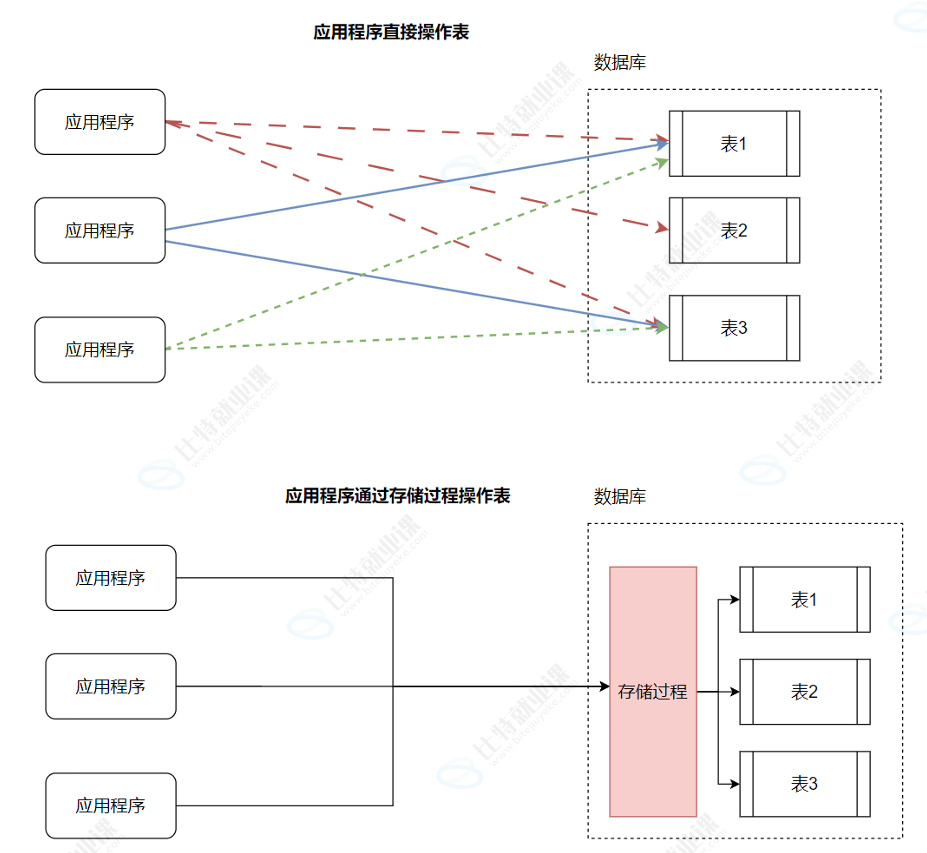
存储过程的特点
封装性、可维护性、可重用性。
• 封装性:将业务逻辑封装在数据库内部,减少应⽤程序的复杂性。
• 可维护性:集中管理数据库操作,便于维护和更新。
• 可重⽤性:可以被多次调⽤,提⾼代码的重⽤性。
优缺点
优点
• 性能优化:存储过程在创建时编译并存储在数据库中,执⾏速度⽐单个SQL语句快。
• 代码重⽤:存储过程可以重复调⽤,减少重复代码,提⾼代码的可维护性。
• 安全性:可以限制⽤⼾直接访问数据库,通过存储过程间接访问,从⽽保证系统安全性。
• 事务管理:可以在存储过程中实现复杂的事务逻辑。
• 降低耦合:当表结构发⽣变化时,只需要修改相应的存储过程,应⽤程序的改动较⼩。
缺点
• 可移植性差:存储过程不能跨数据库移植,更换数据库时需要重新编写。
• 调试困难:只有少数数据库管理系统⽀持存储过程的调试,开发和维护困难。
• 不适合⾼并发场景:在⾼并发场景下,存储过程可能会增加数据库的压⼒,难以维护。
基本语法
创建
为什么要 DELIMITER //
这是初学者最容易懵的点。默认 SQL 结束符是 ;。但存储过程内部本身就会写很多 ;。如果你不改结束符,MySQL 会以为:
- 过程还没写完
- 它就提前结束了
所以先把结束符改成 //,等过程写完后再改回 ;。
sql
delimiter //
create procedure 存储过程名 (参数列表)
begin
-- sql语句
end //
delimiter ;调用
sql
call 存储过程名(参数列表);查看
sql
select *
from information_schema.routines
where routine_schema = '数据库名';
show create procedure 存储过程名;区别是:
- 第一种:看这个库里有哪些存储过程
- 第二种:看某个存储过程的定义
删除
sql
drop procedure [if exists] 存储过程名;示例:计算学生总分
sql
create procedure p_calavg()
begin
select name, chinese + math + english as total
from exam;
end;
call p_calavg();思想:
p_calAvg没参数- 调用后直接返回查询结果
- 说明存储过程可以:
- 做计算
- 查表
- 返回结果集
变量
分成三类:系统变量、用户自定义变量、局部变量。
系统变量
什么是系统变量
系统变量是 mysql 服务器的配置变量,用来控制服务器行为和性能,分为:
- global:全局变量
- session:会话变量
查看系统变量
sql
show [global|session] variables;
show [global|session] variables like 'xxx';
show [global|session] variables like '%xxx%';
select @@[global|session].系统变量名;
比如:
show global variables like 'auto%';
show session variables like 'char%';
select @@global.autocommit;设置系统变量
**重要:
- 如果没有指定 global|session,默认是 session
- session 变量会话结束就失效
- global 变量 mysql 重启后也可能失效,要永久生效得改配置文件**
sql
set [global|session] 系统变量名 = 值;
set @@session.系统变量名 = 值;
示例:
set @@session.autocommit = 0;
set autocommit = 1;典型面试题
问:set autocommit = 0 改的是全局还是会话?
答:默认改的是会话变量。
用户自定义变量
⽤⼾⾃定义变量是在SQL会话中定义的变量,不⽤提前声明,作⽤域为当前会话。这类变量特点很明显:
• 名字前面带 @
• 当前连接里可用
• 连接断了就没了
赋值方式
推荐 :=
原因:因为 sql 里比较相等也用 =,为了避免歧义,赋值更推荐 :=
sql
set @var_name = expr;
set @var_name := expr;
select @var_name := expr;
select 列名 into @var_name from 表名 where ...;实例
sql
set @age := 18;
select @age;
select sno into @sno from student where id = 1;
select @sno;
select count(*) into @count from student;
select @count;
select @var; -- 未赋值返回null注意:未赋值的用户变量,读取时返回 null。这是它和局部变量不一样的地方之一。
局部变量
局部变量只在:
• 存储过程
• 存储函数
• 触发器
内部有效。必须用 declare 声明,作用域只在 begin ... end 块内。
声明
sql
declare 变量名 变量类型 [default 默认值];
比如:
declare stu_count int default 0;赋值
sql
set var_name = 值;
set var_name := 值;
select 列名 into var_name from 表名 where ...;使用示例
- 局部变量要先
declare - 可以有默认值
- 可以接收查询结果
- 过程结束后变量自动销毁
sql
create procedure p1()
begin
declare stu_count int default 0;
select count(*) into stu_count from student;
select stu_count;
end;
call p1();区分三类变量
1)系统变量
mysql 自己的配置项
例子:
sql
select @@session.autocommit;2)用户自定义变量
当前会话临时用,不需要声明,名字带 @
sql
set @x := 100;
select @x;3)局部变量
只能在存储过程/函数/触发器内部用,必须先声明
例子:
sql
declare total int default 0;变量的注意事项
• 变量名不区分大小写
• 局部变量必须先声明后使用
• 用户变量会话结束失效
• 局部变量在过程/函数结束时失效
• 避免用保留字
在存储过程中,声明顺序很重要。通常要按这个顺序来:
-
局部变量
-
游标
-
条件处理程序
sql 编程
结构化查询语⾔(StructuredQueryLanguage)简称SQL,是⼀种特殊⽬的的编程语⾔,是⼀ 种数据库查询和程序设计语⾔,⽤于存取数据以及查询、更新和管理关系数据库系统。
if条件判断
重点
- 不是
endif - 是
end if elseif是连写,不是else if
sql
if 条件1 then
...
[elseif 条件2 then
...
else
...]
end if;示例:分数评级
>= 90优秀>= 80 且 < 90良好>= 60 且 < 80及格< 60不及格
sql
create procedure p2()
begin
declare score int default 86;
declare result varchar(10);
if score >= 90 then
set result := '优秀';
elseif score >= 80 and score < 90 then
set result := '良好';
elseif score >= 60 and score < 80 then
set result := '及格';
else
set result := '不及格';
end if;
select result;
end;参数
三类:
- in:输入参数,默认类型
- out:输出参数,可作为返回值
- inout:输入输出参数
语法
sql
create procedure 存储过程名(
[in/out/inout 参数名 参数类型] [,...]
)
begin
-- sql语句
end示例 1:传入分数,返回等级
sql
create procedure p3(in score int, out result varchar(10))
begin
if score >= 90 then
set result := '优秀';
elseif score >= 80 and score < 90 then
set result := '良好';
elseif score >= 60 and score < 80 then
set result := '及格';
else
set result := '不及格';
end if;
end;
调用:
call p3(88, @result);
select @result;关键理解
• 88 是传进去的 in score
• @result 是外面的用户变量,用来接 out result
• 存储过程执行完后,再 select @result
面试高频点
问:为什么 out 参数通常配合 @变量 用?
因为 out 的结果要"带出来",而调用后你得在会话外层继续访问这个值,所以常用用户变量接收。
示例 2:inout 参数
inout 不只是"返回结果",而是对传入值原地加工。
sql
create procedure p4(inout score int)
begin
set score := score + 10;
end;
set @score := 98;
call p4(@score);
select @score;case 分支
case 有两种写法。
语法一:等值匹配
也就是"一个值匹配多个常量分支"。
CASE 后的 case_value 是⼀个表达式,该表达式的值与每⼀个 when_value ⽐较,当找到⼀个相等的 WHEN ⼦句中的 when_value 时,执⾏相应的 THEN子句的statement_list。如果没有相等的 when_value ,则执⾏ ELSE ⼦句 statement_list (如果存在ELSE)。
sql
case case_value
when when_value then statement_list
[when when_value then statement_list] ...
[else statement_list]
end case语法二:条件匹配
也就是"多个逻辑条件判断"。
计算每个 WHEN ⼦句 search_condition 表达式,直到其中⼀个表达式为真,此时执⾏相应 的 THEN ⼦句的 statement_list 。如果 search_condition 都不相等,则执⾏ ELSE ⼦句statement_list (如果存在ELSE)。
提醒:
-
每个 statement_list 不能为空
-
如果没有任何分支命中,而且没有 else,会报错
所以你最好养成习惯case 一定写 else。
sql
case
when search_condition then statement_list
[when search_condition then statement_list] ...
[else statement_list]
end case循环
while
先判断,后执行。
条件一开始不满足,就一次都不执行
sql
while search_condition do
statement_list
end while;repeat
先执行一次,再判断是否结束。
所以至少执行一次。课件也把它类比成 do ... while。
sql
repeat
statement_list
until search_condition
end repeat;loop+leave/iterate
sql
[begin_label:] loop
statement_list
end loop [end_label]loop 本身没有退出条件。
它就是个"裸循环",通常要配合:
• leave label:跳出整个循环,相当于 break
• iterate label:跳过本次,进入下一轮,相当于 continue
游标
游标是一种数据库对象,允许在存储过程和函数中对查询到的结果集进行逐行检索。
特点:mysql 的游标是只读的,不能更新。
也就是说:
- 你可以
fetch读数据 - 不能直接通过游标改当前行
为什么需要游标
普通 select 是一次拿到整个结果集。但有些业务要"一行一行处理"。
比如:
- 把某个班级的每个学生逐个写入另一张表
- 对结果集每行做判断和加工
- 边遍历边插入/更新
这时就会用到游标。
语法
sql
declare 游标名 cursor for 查询语句;
open 游标名;
fetch 游标名 into 变量[, 变量] ...;
close 游标名;四步流程
- 声明游标
- 打开游标
- 每次抓一行
- 用完关闭
**游标遍历的本质问题:**你不能假设"永远还有下一行"。必须有一个机制告诉你:结果集已经读完了。即条件处理程序。
条件处理程序
条件处理程序就是提前定义"程序执行时可能出现的问题",并规定"遇到问题时怎么处理"。
最典型的用途就是:
- 处理游标读完的情况
- 避免过程异常中断
- 捕获错误/警告后决定继续还是退出
语法
sql
declare handler_action handler
for condition_value [, condition_value] ...
statement
handler_action: {
continue -- 继续执行当前程序
| exit -- 终止执行当前程序
}
condition_value: {
mysql_error_code -- mysql错误码
| sqlstate [value] sqlstate_value -- 状态码
| sqlwarning -- 所有以01开头的sqlstate代码
| not found -- 所有以02开头的sqlstate代码
| sqlexception -- 所有没有被sqlwarning或not found捕获的sqlstate代码
}常见写法
sql
处理游标读完:
declare continue handler for not found set is_done := true;
意思是:
一旦 fetch 时读不到数据
就把 is_done 置为 true
程序继续往下执行
sql
正确示例,增加了:
declare is_done bool default false;
declare continue handler for not found set is_done := true;
然后在循环里这样写:
read_loop: loop
fetch s_cursor into student_name, class_name;
if is_done then
leave read_loop;
end if;
insert into t_student_class values (null, student_name, class_name);
end loop read_loop;这是 mysql 游标遍历的标准套路之一:
-
定义结束标识位 is_done
-
not found 时把它改成 true
-
每次 fetch 之后检查它
-
如果结束,就 leave
存储函数
存储函数是有返回值的存储过程,参数只能是 IN 类型,类似内置函数。它和存储过程的主要区别是:存储函数必须有返回值,存储过程不一定。
存储函数 vs 存储过程
存储过程
- 用
CALL - 可以没有返回值
- 参数可用
IN / OUT / INOUT
存储函数
- 用
SELECT 函数名(...) - 必须有返回值
- 参数只能是
IN
语法
sql
create function 函数名([参数列表])
returns type [characteristic ...]
begin
-- sql语句
return ...;
end;characteristic 是什么
在 mysql 8.0 中,如果开启了二进制日志,创建存储函数时通常需要显式声明函数特性,比如 deterministic 或 reads sql data,否则会报错。
可选项有:
deterministic相同输入,总是相同输出。
no sql函数里不包含 sql。
reads sql data函数里会读数据,比如 select。
modifies sql data函数里会写数据,比如 update/delete。
sql
调用:
select 函数名([参数列表]);触发器
触发器是一个与表关联的数据库对象,在对表进行 insert / update / delete 操作时,会自动触发并执行预定义 sql。它可以在操作之前或之后执行。
可以把它理解成"表级事件监听器"。只要表发生某种变化,就自动执行你写好的逻辑。
mysql 支持三种:
用 old 和 new 访问变化前后的记录。
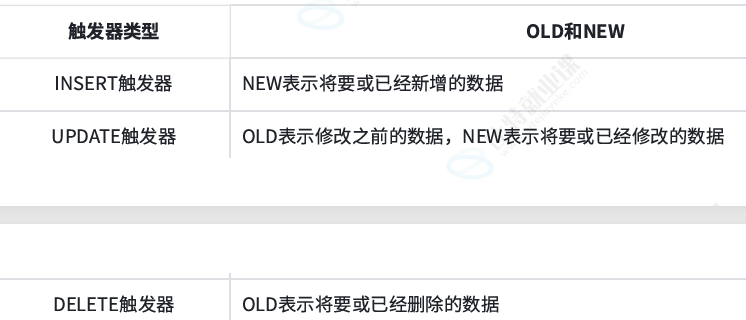
行级触发器 vs 语句级触发器
**• ⾏级触发器:影响几行,就触发几次。**当对表中的每⼀⾏进⾏INSERT、UPDATE或DELETE操作时,⾏级触发器都会被触 发。例如,如果执⾏⼀个UPDATE语句影响了多⾏数据,那么⾏级触发器会对每⼀⾏都触发⼀ 次。⾏级触发器可以访问受影响⾏的旧值和新值,常⽤于实现复杂的业务逻辑时对新旧值的访 问。
**• 语句级触发器:整个语句只执行一次,不管影响几行。**在整个INSERT、UPDATE或DELETE语句执⾏时只触发⼀次。⽆论该语句影响了 多少⾏数据,语句级触发器都只在语句开始或结束时触发⼀次。语句级触发器主要⽤于实现⼀些 全局性的操作,⽐如数据同步、数据清理等。
• MySQL只⽀持⾏级触器,不⽀持语句级触发器。
触发器语法
sql
create trigger trigger_name
trigger_time trigger_event
on tbl_name for each row
begin
trigger_stmt;
end;
其中:
trigger_time:before 或 after
trigger_event:insert / update / delete
查看:
show triggers;
删除:
drop trigger [if exists] [schema_name.]trigger_name;注意:for each row 就说明它是行级触发器。
触发器的典型场景:记录日志
触发器最经典的用途之一:审计日志 / 变更日志。
先建立日志表
sql
create table student_log (
id bigint primary key auto_increment,
operation_type varchar(10) not null,
operation_time datetime not null,
operation_id bigint not null,
operation_data varchar(500)
);插入触发器
理解
after insert:插入成功后记日志new.id等:拿到新插入那条数据的值concat(...):把整条记录拼成字符串保存
为什么用 after
因为只有插入成功后,new.id 等值才最终落库,更适合记审计日志。
sql
create trigger trg_student_insert
after insert on student
for each row
begin
insert into student_log(
operation_type,
operation_time,
operation_id,
operation_data
)
values(
'insert',
now(),
new.id,
concat(new.id, ',', new.name, ',', new.sno, ',', new.age, ',',
new.gender, ',', new.enroll_date, ',', new.class_id)
);
end;更新触发器
这段最关键的点它把:
• 修改前:old
• 修改后:new
同时记录下来了,中间用 | 分隔。这正好对应面试题:如果更新一条数据,要把更新前和更新后的值都记到日志表,怎么实现?
答案就是:使用 after update 触发器,通过 old 取旧值,通过 new 取新值,再插入日志表。
sql
create trigger trg_student_update
after update on student
for each row
begin
insert into student_log(
operation_type,
operation_time,
operation_id,
operation_data
)
values(
'update',
now(),
new.id,
concat(old.id, ',', old.name, ',', old.sno, ',', old.age, ',',
old.gender, ',', old.enroll_date, ',', old.class_id,
'|',
new.id, ',', new.name, ',', new.sno, ',', new.age, ',',
new.gender, ',', new.enroll_date, ',', new.class_id)
);
end;删除触发器
sql
create trigger trg_student_delete
after delete on student
for each row
begin
insert into student_log(
operation_type,
operation_time,
operation_id,
operation_data
)
values(
'delete',
now(),
old.id,
concat(old.id, ',', old.name, ',', old.sno, ',', old.age, ',',
old.gender, ',', old.enroll_date, ',', old.class_id)
);
end;为什么这里只有 old?因为删掉之后已经没有 new 了。能拿到的只有被删之前的那条旧记录。
总结:
"核心逻辑"要把整个链条串起来。
1)存储过程是数据库里的"方法"
它适合封装一组 sql 和业务流程。
你会:
- 创建
- 调用
- 查看
- 删除
就算入门了。
2)变量分三层
- 系统变量:数据库配置
- 用户变量:会话级临时变量,带
@ - 局部变量:过程/函数/触发器内变量,要
declare
3)sql 编程的本质就是"流程控制"
你要能用:
ifcasewhilerepeatloop
来控制 sql 执行流程。
4)游标解决"逐行处理结果集"
普通查询是一把拿完,
游标是一行一行抓 。
但游标遍历时一定要配合条件处理程序来处理结束条件。
5)存储函数一定要会和存储过程区分
这是面试必问:
- 函数必须有返回值
- 参数只能是 in
- 用
select调用 - 过程用
call - 过程可用 out / inout
6)触发器本质是"自动执行的表事件逻辑"
典型用途:
- 记录日志
- 数据校验
- 同步处理
- 审计追踪
其中最常考的是 old/new 和 mysql 只支持行级触发器。
面试题
1. 存储过程的作用是什么?
存储过程是预编译并保存在数据库中的一组 sql 语句集合,用于完成特定功能。它可以封装业务逻辑、提高代码复用性、减少应用与数据库之间的交互,并支持事务控制。
2. mysql 变量有哪几种?
三种:系统变量、用户自定义变量、局部变量。系统变量分全局和会话;用户变量以 @ 开头,不需要声明;局部变量需要在存储过程、函数或触发器中用 declare 声明。
3. 用户变量和局部变量区别?
用户变量作用域是当前会话,不需要声明,前面带 @;局部变量只在 begin...end 内有效,必须先 declare。
4. in、out、inout 有什么区别?
in 是输入参数,out 是输出参数,inout 既能输入也能输出。in 是默认类型。
5. 游标的作用是什么?
游标用于在存储过程或函数中对查询结果集进行逐行处理,适合需要一行一行加工数据的场景。mysql 游标是只读的。
6. 条件处理程序是干什么的?
用于定义程序遇到错误、警告或 not found 等情况时的处理方式,避免程序异常中断,常用于配合游标处理结果集遍历结束。
7. 存储函数和存储过程有什么区别?
存储函数必须有返回值,参数只能是 in,用 select 调用;存储过程不一定有返回值,可使用 in、out、inout,用 call 调用。
8. 触发器是什么?
触发器是与表关联的数据库对象,在表发生 insert、update、delete 时自动触发执行。
9. mysql 支持语句级触发器吗?
不支持,mysql 只支持行级触发器。
10. 如何记录更新前和更新后的值?
可以定义 after update 触发器,使用 old 获取修改前的数据,使用 new 获取修改后的数据,并写入日志表。