字符串和正则表达式
1、字符串介绍
字符串(String)是JavaScript基本数据类型之一,字符串的3种定义方式,代码如下:
js
let doubleQuoted="字符串"; //双引号
let singleQuoted= '字符串'; //单引号
let templateLiterals=`字符串`;//反引号在JavaScript中,字符串使用了UTF-16编码格式表示整个Unicode字符集,Unicode字符集包含了世界上各国语言的字符,每个字符有唯一的代码点(Code Point),相当于字符的ID,而字符串中的每个字符都是使用16位的代码单元(Code Unit)进行表示的,1个16位代码单元能表示大部分的UTF-16字符,但是超出的字符需要2个代码单元表示,即代理对(Surrogate Pair)------生僻汉字、Emoji表情等有使用2个代码单元进行表示的。字符串中有一个内置的length属性用于获取字符串长度,获取的是代码单元的个数,如果一个字符可以用一个代码单元表示,则它的长度就是1,如果一个字符需要使用2个代码单元表示,则长度为2,例如"插图".length的结果为2,这一点需要特别注意,字符串的长度与实际显示的并不一样的原因就在于此。
2、字符串遍历
字符串可以认为是由多个字符组成的数组,可以使用访问每个字符,索引也是从0开始的,直到字符串长度减1,例如访问字符串中的第2个字符,代码如下:
js
let str="hello";
str[1]; //"2"需要注意的是字符串的索引也是针对代码单元而言的,如果有字符使用2个代码单元表示,则它会占据两个索引位置。
3、字符串操作
3.1、拼接
对字符串进行拼接除了可以使用+之外,还可以使用字符串对象中的concat()方法,它接收一个变长参数,可以传递多个字符串并按顺序进行拼接,之后返回拼接后的新字符串,该方法不会修改原字符串,但对原字符串进行修改也不会影响新返回的字符串,concat()用法的代码如下:
js
"hello".concat("world","!");//"hello world!"由于使用concat()的形式比使用+更为烦琐,所以推荐使用+进行字符串拼接。
3.2、裁切
3.2.1、substring()
substring()用于截取字符串中的一部分,并把它作为新的字符串返回,不会修改原字符串。它接收两个参数,起始索引和结束索引,其中起始索引位置的字符会包含在截取的部分内,而结束索引位置的字符不会包含在内。例如"hello".substring(1,3)会返回"el"。
结束索引参数可以忽略,这样会截取从起始索引到字符串末尾的子串,例如"这是一个字符串".substring(2)会返回"一个字符串"。
上述是正常情况下substring()的作用,起始索引和结束索引还有一些特殊的情况:
- 如果结束索引大于起始索引,则substring()会在内部把它们互换位置后再进行截取。
- 如果结束索引等于起始索引,则会返回空白字符串。
- 如果索引大于字符串长度length属性,则会取字符串长度。
- 如果索引为负数或NaN,则会把它转换为0。
js
let str="这是一个字符串";
console.log(str.substring(4,1)); //结束索引大于起始索引
console.log(str.substring(2,2)); //结束索引等于起始索引
console.log(str.substring(4,12)); //索引大于length
console.log(str.substring(-2)); //索引为负数
console.log(str.substring(4,NaN));//索引为NaN 是一个
""
字符串
这是一个字符串
这是一个3.2.2、slice()
slice()与substring()的参数列表和使用方法完全相同,但是对于特殊情况下的索引值,它的处理方式与substring()有以下不同之处:
- 起始索引大于结束索引会返回空白字符串。
- 如果索引为负数,则会从字符串末尾开始算起,例如最后一个字符的索引是-1,倒数第2个为-2,以此类推。
- 如果结束索引为NaN,则会返回空白字符串。
js
let str="这是一个字符串";
console.log(str.slice(1,4)); //正常情况
console.log(str.slice(4,1)); //结束索引大于起始索引
console.log(str.slice(-2)); //索引为负数
console.log(str.slice(4,NaN));//结束索引为NaN
js
是一个
""
符串
""3.3、搜索
3.3.1、includes()
includes()用于判断一个子串是否存在于字符串中,并返回true或false。它接收两个参数,即要判断的子串和搜索起始索引。例如判断"aa"是否存在于"baab"中,可以使用下方代码:
js
console.log("baab".includes("aa"))//true如果从索引2的位置开始判断,则可以给includes()传递第2个参数:
js
console.log("baba".includes("aa", 2))//false要注意的是includes()判断子串是区分大小写的,并且当起始索引小于0时会把它转换为0,当大于字符串长度时,会取字符串的长度,即length属性的值。
3.3.2、indexOf()
indexOf()可以搜索某个子串在字符串中的索引位置,如果存在则返回第1个字符所在的索引,如果不存在则返回-1。它接收和includes()相同的参数。例如搜索"p"在"apple"中的位置,可以使用"apple".indexOf("p"),它会返回1,如果从索引2开始搜索,"apple".indexOf("p",2),则它返回的就是2,也就是"apple"中的第2个"p"。如果从索引3开始搜索,"apple".indexOf("p",3),则会返回-1,因为从索引3开始,后边的字符串并不包括字符"p"。
利用indexOf()和循环可以找出子串在字符串中所有的位置,例如搜索"o"在"hello world"中出现的所有位置,代码如下:
js
let str="hello world";
let search="o";
let result=[];
let index=str.indexOf(search);
while(index>-1){
result.push(index);
index= str.indexOf(search,index+1);
}
console.log(result);//[4,7]3.3.3、lastIndexOf()
lastIndexOf()与indexOf()的搜索方向相反,它是从字符串末尾开始搜索的,并返回搜索到的子串的第1个字符的索引位置,例如"baabaa".lastIndexOf("aa")的结果为4。
3.4、分割
字符串可以按照一定的模式分割为字符串数组,使用split()方法,它接收两个参数,分别是分割符和分割结果数量限制。
分割符可以是任意字符串,也可以是转义字符,还可以是正则表达式,而第2个参数可以限制分割后的数组的长度,超过的部分将不包括在数组中。split()用法的代码如下:
js
let tags="前端,JavaScript,React,Vue,Angular";
tags.split(","); //['前端','JavaScript','React','Vue','Angular']
tags.split(",",2); //['前端','JavaScript']
let lines="第一行\n\r第二行\n\r第三行";
lines.split("\n\r"); //['第一行','第二行','第三行']如果没有给split()传递参数,则它会返回只有1个元素的数组,这个元素是原字符串本身,而如果给split()传递了空白字符串,则会把每个字符都分割出来放到数组中,这里需要注意的是,分割结果是按16位的代码单元来展示的,如果字符使用了两个代码单元,则会分割成两个,结果数组的长度也会相应地增加,代码如下:
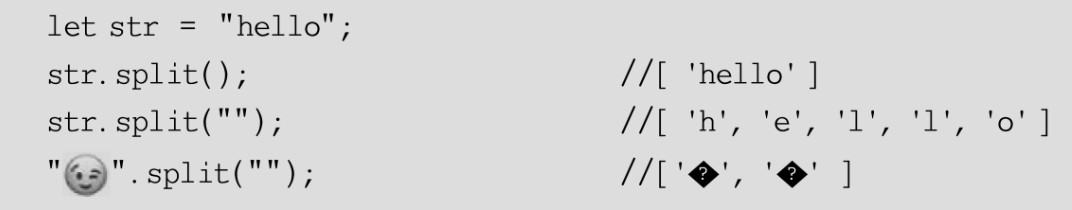
与split()相反,在数组中有一个join()方法用于按照一定模式把数组中的每个元素拼接成一个完整的字符串,它接收一个参数,即使用何种字符进行拼接。此外数组中还有reverse()方法可以把数组中的元素顺序进行反转,这两种方法结合使用可以反转一个字符串,代码如下:
js
"hello".split("").reverse().join("");//"olleh"3.5、其他操作
字符串还提供了一些其他比较简单的API,例如大小写转换和去除空格。
3.5.1、大小写转换
对字符串进行大小写转换可以使用toUpperCase()和toLowerCase(),分别可以把字符串(英文字母)变成大写和小写形式,这两种方法不接收任何参数,只需使用要转换的字符串调用,代码如下:
js
"abc".toUpperCase();//"ABC"
"ABC".toLowerCase();//"abc"3.5.2、去除空格
去除字符串空格有3种方法:trim()去除首尾空格、trimStart()去除首部空格、trimEnd()去除尾部空格,它们会去除相应位置的全部空格,代码如下:
js
" 字符串 ".trim(); //"字符串"
" 字符串 ".trimStart();//"字符串 "
" 字符串 ".trimEnd(); //" 字符串"4、模板字符串
它可以保留字符串的格式并且可以访问变量的值和表达式的结果,就像给一段文本设置占位符,然后用变量的值动态地生成字符串,所以称它为模板字符串(Template Literals)。来回顾一下它的定义方法,代码如下:
js
let isValid=true;
let str=`输入${isValid?"有效":"无效"}`;
console.log(str)//输入有效 //"输入有效"在ES6之后,JavaScript还支持了一种叫作标记化模板(TaggedTemplates)的语法形式,它是一个普通函数,但是调用的时候会有所区别,可以在它的名字之后省略小括号并直接传递模板字符串, 而这个模板字符串会按${}动态部分进行分割,把得到的静态字符串数组作为第1个参数传递给函数,动态部分则以变长参数的形式传递给第2个参数,而函数的返回值可以是任何类型。例如下方示例标记化模板函数reorder()会改变${}部分的顺序,代码如下:
js
function reorder(strings, ...exps){
console.log(strings)
console.log(exps)
return `${exps[1]}:${exps[0]}篇文章`;
}
let tag = "JS";
let res = reorder`共有${10}篇文章在${tag}标签下`;
console.log(res);
js
[ '共有', '篇文章在', '标签下' ]
[ 10, 'JS' ]
JS:10篇文章可以看到,strings参数是按${}进行分割后的数组,exps则是${}中表达式值的数组,函数里把${tag}放到了前边,把${10}放到了后边,并生成了一个全新的字符串,并且没有使用strings所包含的原始字符串的值。在调用的时候直接用函数名加``并在里边写上模板字符串就可以了。
由于标记化模板本身是普通函数,所以可以实现任何业务逻辑。例如前端React生态的styled-components库,用此语法生成了React组件,并把函数名字设置为跟HTML标签一致,作为组件底层渲染的HTML元素,然后使用传递的模板字符串生成随机的class名字,并把CSS样式设置到选择器中,代码如下:
js
const StyledDiv= styled.div`
background:${props=>props.bgColor};
`;//生成了用div渲染、可动态设置背景色的React组件另外,像gql这样的库也会接收一段用模板字符串定义的GraphQL查询语句,代码如下(代码示例来自Apollo官网):
js
//https://www.apollographql.com/docs/tutorial/queries/
export const GET_LAUNCHES=gql`
query GetLaunchList($after:String){
launches(after:$after){
cursor
hasM ore
launches{
...LaunchTile
}
}
}
${LAUNCH_TILE_DATA}
`;5、字符串中的正则
5.1、search()
字符串中提供了search()方法,用于在搜索到匹配正则表达式的字符串后,返回它的索引。该方法接收1个正则表达式作为参数,并返回第1次匹配到的字符串的起始索引,如果没有匹配到则返回-1,代码如下:
js
let str="hello world";
console.log(str.search(/e/)); //1
console.log(str.search(/z/)); //-1;5.2、match()
match()接收1个正则表达式作为参数,并返回匹配到的字符的数组,数组的内容会根据正则表达式的标志而有所不同。这里先看一下正则表达式标志的含义。
正则表达式的标志是在末尾的一些字母,例如/\w+/g,它有6种形式,分别为:
g:代表全局搜索。如果没有设置g,正则表达式会在第1次匹配到满足的字符串时就会停止;如果设置了g,则会搜索所有满足的字符串。i:是否区分大小写。不设置则区分,设置了则不区分。m:可以改变^和$界定符的行为,在没有设置多行匹配时,^和$会把起始和结束界定在整个字符串的开始和结尾,如果设置了m,则^和$会界定每行的起始和结束。s:是否允许.匹配换行符,不设置则不匹配,设置了则匹配。u:是否把正则表达式全部视为unicode代码单元。设置了u则可以使用\p Unicode属性转义和\u{hhhh}、\u{hhhhh}等形式的正则表达式,不过使用不带{}的\uhhhh形式可以不用设置u标志。y:是否启用粘滞搜索,即是否从正则对象中的lastIndex属性开始搜索。
在使用match()时,影响返回结果的标志为g。如果使用了g标志,则match()方法会返回字符串中所有满足正则表达式的字符数组,代码如下:
js
let str = "This is an apple";
let res = str.match(/is/g);
console.log(res);//[ 'is', 'is' ]这里/is/g匹配到了"This"中的"is"和单独的"is"这两个字符串,并返回了包含它们的数组。
如果没有设置g,则返回第1个匹配到的字符串,例如把上边例子中的g去掉会返回下例所示的结果,代码如下:
js
let str = "This is an apple";
let res = str.match(/is/);
console.log(res);//[ 'is' ]如果正则表达式中有分组,则会把分组记录的值按顺序返回出来,相当于\1、\2等所引用的值,例如把上例中的正则表达式改成使用小括号,代码如下:
js
let str = "This is an apple";
let res = str.match(/This (\w+) an (\w+)/);
console.log(res);
js
[
'This is an apple',
'is',
'apple',
index: 0,
input: 'This is an apple',
groups: undefined
]5.3、matchAll()
matchAll()与match()类似,接收1个正则表达式作为参数,并返回一个迭代器(Iterator),包含所有匹配的字符串,也包括分组,有关迭代器的概念将在第10章内置对象中进行介绍。与match()不同的是,参数中的正则表达式必须使用g标志进行全局匹配,而返回的迭代器转换为数组之后,每个元素是一个子数组,与不带g的match()所返回的结果数组一样,包含匹配到的字符串和分组及附加的index、input和groups信息。matchAll()用法的代码如下:
js
let res = " java and JavaScript ".matchAll(/(ja)va(\s+|\w+)/g);
//将迭代器转换为数组
let arr = [...res];
console.log(arr);
js
[
[
'java ',
'ja',
' ',
index: 1,
input: ' java and JavaScript ',
groups: undefined
]
]5.4、replace()
replace()方法用于搜索并替换字符串,第1个参数可以传递要搜索的字符串或正则表达式,第2个参数是要替换成的值,返回值为替换后的新字符串,原字符串并不会被修改。
如果第1个参数传递了字符串,则只有第1次被搜索到的字符串可以被替换,例如"aabb".replace("a","b")返回结果为"babb"。如果要全部替换,则可以使用replaceAll()方法,例如"aabb".replaceAll("a","b")会返回"bbbb"。
如果传递的是正则表达式,且没有g标志,则replace()也只会替换首次匹配到的字符串,如果有g标志,则replace()会替换所有匹配到的字符,如果使用replaceAll(),则正则表达式必须有g标志,它和replace()的作用一样。例如"aabb".replace(/a/g,"b")与"aabb".replaceAll(/a/g,"b")都会返回"bbbb"。
如果正则表达式中有分组,则可以在第2个参数中使用$引用分组中匹配到的值,代码如下:
js
let str="<div>test</div>";
let newStr= str.replace(/<div>(\w+)<\/div>/g,"$1");
newStr; //"test"replace()的第2个参数还可以是一个函数,匹配到几次字符,函数就会调用几次,函数的返回值就是要替换成的字符串。函数的参数有匹配到的字符串、分组匹配到的字符串(可能有多个,与分组数量相同)、匹配到的字符起始索引、原始字符串、命名的分组结果,代码如下:
js
function replacer(match,g1,g2,pos,str,group){
console.log(match,g1,g2,pos,str,group);
return match.toUpperCase();
}
let str="java and JavaScript".replace(/(ja)va(\s+|\w+)/g,replacer);
console.log(str);//JAVA and JAVASCRIPT代码把"java"和"JavaScript"转换成了大写形式,replacer()会针对匹配到的"java"和"JavaScript"分别执行一次,返回把匹配到的字符串大写之后的结果,replacer()函数中打印参数的结果如下:
js
java ja"" 0 java and JavaScript undefined
JavaScript ja script 9 java and JavaScript undefined5.5、split()
使用普通字符串的形式调用split()可将字符串分割为数组,现在来看一下使用正则表达式作为参数的情况,用于定义更复杂的分隔符,代码如下:
js
let str="This is a,.random?#string";
str.split(/\W+/); //["This","is","a","random","string"]示例中使用\W+用于匹配1个或多个非字母数字的字符,那么字符串中的空格和特殊符号都会计算在内,这样每个单词就都可以按这个模式分隔开来。如果想让匹配到的分隔符也包括在结果内,则可以把它放到分组中,例如使用str.split(/(\W+)/)会返回"This","","is","","a",",.","random","?#","string"。
6、RegExp对象
之前介绍的正则表达式都使用字面值进行定义,除了这种方式之外还可以使用RegExp构造函数创建正则表达式。该构造函数接收两个参数,第1个是正则表达式的字符串表示形式,第2个是标志的字符串表示形式。例如使用let re=new RegExp("abc","g")可以创建一个正则表达式对象。
在使用构造函数传递字符串构建正则表达式时,不需要使用//,另外像\w、\s中的\需要使用两个\进行转义。这种使用字符串的形式可以方便构建动态的正则表达式,例如根据变量的值确定其中的一部分。
无论是使用字面值还是使用RegExp构造函数创建的正则表达式,都包含同样的属性和方法。在本章的开始,介绍了使用正则对象中的test()方法判断正则表达式是否匹配到了字符,它还有另一个常用的方法exec(),与String中的match()类似,用于返回匹配到的字符串数组,代码如下:
js
let re=new RegExp("abc")
re.exec("abc"); //["abc",index:0,input:"abc",groups:undefined]同样地,如果正则中有分组,则分组匹配到的字符串也会加入数组中。在介绍exec()与match()的区别前,先看一下正则对象中的lastIndex属性。
lastIndex表示从字符串的哪个索引位置开始进行匹配,只有当设置了g或y标志时才会生效,它的默认值是0,即从字符串的起始索引开始匹配,在这两种标志下,lastIndex是有状态的,即在第1次匹配成功之后,会把lastIndex移动到匹配到的字符串后面索引加1的位置,下一次就在这个位置开始匹配,这种情况在调用test()或exec()的时候都会发生,代码如下:
js
let re=new RegExp("abc","g");
re.lastIndex; //0
re.test("abcabc"); //true
re.lastIndex; //3
re.test("abcabc"); //true
re.lastIndex; //6
re.test("abcabc"); //false可以看到re.lastIndex的值会被记住,所以要注意当需要复用正则表达式对象时,它的lastIndex是不是会影响最终结果,如果会,则最好重新创建一个新的正则表达式。虽然也可以直接修改lastIndex的值,但是不推荐这样做。
正常情况下,lastIndex会移动到匹配到的字符串的最后并加1,但是当lastIndex小于或等于字符串的长度且匹配到空白字符串时,就会一直停留在当时的lastIndex中,代码如下:
js
let re=new RegExp("(abc)?","g")
re.lastIndex; //0
re.test("abcabcab"); //true
re.lastIndex; //3
re.test("abcabcab"); //true
re.lastIndex; //6
re.test("abcabcab"); //true
re.lastIndex; //6
//...因为正则表达式匹配(abc)出现0次到1次,所以在lastIndex等于6时,就到了最后的"ab"这个子串了,但是由于(abc)?允许匹配空白字符串,所以按照规则,lastIndex会一直停留在6。
再有一种情况,如果lastIndex大于字符串长度,或者等于字符串长度且并没有匹配空白字符串,则会把lastIndex设置为0,例如下方的正则表达式在匹配几次超过或等于字符串长度后,就会归0,这里为了演示代码只调用了一次,可以自行测试在调用多次之后lastIndex的变化,代码如下:
js
let re=new RegExp("abc","g");
re.test("abcabc") //在调用几次后,lastIndex变为6,并在下一次匹配时重置为0现在,可以通过lastIndex属性来掌握exec()和match()的区别了,在g标志下,match()会返回全部匹配的字符串数组,并且每次都是从0开始匹配,而exec()则是每执行一次就返回当时匹配到的字符串,然后将lastIndex移动到下一个位置继续匹配,代码如下:
js
let re=new RegExp("abc","g");
"abcabc".match(re); //["abc","abc"]
re.lastIndex; //0
re.exec("abcabc"); //["abc",index:0,input:"abcabc",groups:undefined]
re.lastIndex; //3
re.exec("abcabc"); //["abc",index:3,input:"abcabc",groups:undefined]
re.lastIndex; //6再来看一下y标志的作用,它表示粘滞搜索(Sticky Search),使用它可以通过改变lastIndex来决定起始匹配索引,在匹配到字符串后也会移动lastIndex的位置(不带g或y标志的正则表达式每次匹配都是从0开始)。另外在指定lastIndex之后,正则表达式就只从lastIndex指定的位置开始搜索,如果当前位置的字符不符合规则,则它不会从后边的字符继续搜索,代码如下:
js
let re=new RegExp("abc","y");
re.lastIndex=2;
"abcabc".match(re); //null
re.lastIndex; //0示例中把re.lastIndex改为了2,那么下一步的match会从"cabc"这个位置开始匹配,由于"cabc"不满足正则表达式/abc/,所以返回了null,后边lastIndex则直接重置为0。
最后正则表达式对象中还有一个source属性,用于获取正则表达式的字符串表示。此外,上述所有正则表达式对象中的属性和方法对于用字面值创建的正则表达式同样适用。