前面我们对内存池进行了一定程度上的优化,本期我们就来学习着如何分析性能瓶颈并优化
工程代码:高并发内存池: 个人学习的项目------高并发内存池
目录
常见的性能分析工具介绍(Windows下的VS2022和Linux中)
[Windows 平台 (Visual Studio 2022 及系统工具)](#Windows 平台 (Visual Studio 2022 及系统工具))
[Linux 平台](#Linux 平台)
性能分析
常见的性能分析工具介绍(Windows下的VS2022和Linux中)
Windows 平台 (Visual Studio 2022 及系统工具)
1. Visual Studio 2022 内置工具
这是你在IDE里写代码时最顺手、最直观的分析工具。
-
性能分析器 (Debug > Performance Profiler)
-
CPU 使用量:最常用的工具。可以精准定位是哪个函数占用了大量CPU时间,通过"调用树/调用方/被调用方"视图看清函数调用关系。
-
检测 (Instrumentation) :如果你的程序在等待 (比如网络、锁、磁盘I/O)而不是计算,用这个。它能告诉你函数被调用了多少次,以及实际耗时(挂钟时间),帮你揪出那些因阻塞而慢的函数。
-
WindowsPerf 扩展 (针对 ARM 设备):如果你在 ARM 设备(如骁龙本)上开发,安装这个扩展后可以采样 CPU 事件(如缓存未命中),结果会直接关联到 VS 里的代码行。
-
-
进程浏览器 (Process Explorer)
- 这是微软官方出品的高级版"任务管理器"。它用树状视图清晰地显示进程父子关系,还能查看每个进程打开了哪些文件、注册表项,甚至可以把进程提交到 VirusTotal 检查安全性。如果你发现电脑卡顿但任务管理器看不出问题,试试这个。
2. 系统级通用工具
-
任务管理器:快速查看哪个进程占用了高的CPU、内存或磁盘。
-
资源监视器:比任务管理器更细,可以看每个进程具体的磁盘读写速度和网络连接情况。
-
性能监视器 (Perfmon):面向资深玩家。可以添加超过2000个性能计数器(比如".NET CLR Memory"下的"GC 时间"),记录成日志文件用于长期追踪内存泄漏。
-
Windows 性能记录器/分析器 (WPR/WPA) :微软官方的"核武器"。通过
wpr命令录制系统活动(如CPU采样、磁盘I/O),生成.etl文件,然后用 WPA 打开进行深度分析,适合排查间歇性卡顿。
3. 硬件与系统诊断工具
-
CrystalDiskMark / CrystalDiskInfo:前者测硬盘读写速度,后者看硬盘健康度(SMART信息)。
-
Windows 内存诊断 / MemTest86:检查内存条是否有硬件故障。
-
3DMark / Cinebench:压测显卡和CPU,看看性能是否跑满
Linux 平台
1. 系统级通用工具
这些是排查问题时第一时间想到的"瑞士军刀"。
-
top / htop :实时看进程CPU、内存占用。htop 界面更友好,支持鼠标操作。
-
vmstat / iostat :vmstat 看整体CPU、内存、系统负载;iostat 看磁盘读写速度和I/O队列长度,判断是不是磁盘太慢。
-
mpstat:查看每个CPU核心的使用率,对于诊断多线程程序在哪个核上"打架"很有用。
2. 深入分析工具
当你想知道代码内部为什么慢时,这些是主力。
-
perf (Linux 内核自带):这是 Linux 上最强大的性能分析工具,没有之一。它可以采样 CPU 周期、缓存未命中、分支预测失败等硬件事件,并精确到代码行。用它生成火焰图(Flame Graph)可以直观地看到程序的调用栈和热点路径。
-
Valgrind (Callgrind) :慢但精确 。它会在虚拟 CPU 上运行你的程序,精确记录每行代码的调用次数和消耗,适合调试逻辑复杂的程序。配合 KCachegrind 可以图形化分析。
-
gprof :GCC 编译时加上
-pg参数,程序运行结束后会生成报告。优点是简单,缺点是精确度一般,且不太适合分析多线程程序。
3. 高级追踪工具
-
bpftrace / SystemTap :内核级的动态追踪。可以写脚本实时监控内核函数调用、系统调用,非常适合排查生产环境的诡异问题(比如为什么
open系统调用这么慢)。 -
dool:整合了 vmstat、iostat、netstat 的功能,能一次性输出系统概览。
4. 综合测试与基准测试工具
-
Phoronix Test Suite:Linux 上最全面的自动化测试套件,可以一键跑分对比硬件性能。
-
fio:强大的磁盘性能测试工具,可以模拟各种读写场景(随机读写、顺序读写等),测 SSD 性能必用。
-
iperf3:测试网络带宽吞吐量,看两台机器之间的网速能跑多快。
总结与选型建议
| 你的需求 | Windows (VS2022) 首选工具 | Linux 首选工具 |
|---|---|---|
| 快速看一眼谁在占CPU | 任务管理器 / Process Explorer | htop |
| 分析代码函数级耗时 | VS 性能分析器 (CPU Usage) | perf + 火焰图 |
| 排查 I/O 或锁等待问题 | VS 性能分析器 (Instrumentation) | perf (带 -g) / bpftrace |
| 查找内存泄漏 | VS 诊断工具 / WinDbg | Valgrind (Memcheck) |
| 压测硬盘速度 | CrystalDiskMark | fio |
| 压测 CPU/GPU 极限 | 3DMark / Cinebench | stress / 7z b (跑分) |
工具性能分析
在debug条件下使用性能探查器即可
我们会发现主要的性能竞争在于锁。
基数树
基数树(Radix Tree),又称紧凑前缀树(Compact Prefix Tree)或 Patricia Trie,是一种用于存储和检索字符串键的数据结构。它通过压缩路径来优化空间------当某个节点只有一个子节点时,将该节点与其子节点合并,从而减少节点数量。这种结构特别适合存储大量共享公共前缀的键,例如路由表、自动补全、IP 路由查找等场景。
主要特性
-
空间高效:通过合并单子节点路径,显著减少了节点数量,节省内存。
-
查找快速:查找时间与键长度相关,且由于节点数少,通常比普通 Trie 更快。
-
动态操作:支持插入、查找、删除等动态操作(删除实现较复杂)。
-
前缀压缩:每个节点存储一段字符串(标签),而非单个字符,实现了路径压缩。
利用基数树优化
利用基数树,就要考虑具体的环境,对于32位系统用一层足够了,但是对于64位系统来说必须要用3层的基数树
PageMap.h
cpp
#pragma once
#include"Common.h"
#include "ConcurrentMemoryPool.h"
#include<cstring>
// Single-level array
// 单层数组映射,用于管理固定大小的内存映射
template<int BITS> // 32-13 = 19 , 32 位可以存2^19页
class TCMalloc_PageMap1 {
private:
static const int LENGTH = 1 << BITS; // 数组长度 2^19页,即页号
void **array_; // 数组指针,存储void*类型的数据
public:
typedef uintptr_t Number; // 定义Number类型为uintptr_t(无符号整数类型)
// 构造函数,初始化数组
explicit TCMalloc_PageMap1() {
size_t size = sizeof(void *) << BITS; // 计算数组所需的内存大小
size_t alignSize = Alignment::_RoundUP(size, 1 << PAGE_SHIFT); // 对齐内存大小
array_ = (void **) SystemAlloc(alignSize >> PAGE_SHIFT); // 调用SystemAlloc分配内存
memset(array_, 0, sizeof(void *) << BITS); // 初始化数组为0
}
// 获取键k对应的值,如果k超出范围或未设置,返回NULL
void *get(Number k) const {
if ((k >> BITS) > 0) { // 检查k是否超出范围
return nullptr;
}
return array_[k]; // 返回数组中k对应的值
}
// 设置键k的值为v,要求k必须在[0, 2^BITS-1]范围内
void set(Number k, void *v) {
array_[k] = v; // 将数组中k对应的值设置为v
}
};
// Two-level radix tree
// 两层基数树,用于管理更大的内存映射
template<int BITS> // 32 - 12 = 20
class TCMalloc_PageMap2 {
private:
static const int ROOT_BITS = 5; // 根节点的位数
static const int ROOT_LENGTH = 1 << ROOT_BITS; // 根节点的长度(32)
static const int LEAF_BITS = BITS - ROOT_BITS; // 叶子节点的位数 20 - 5 = 15
static const int LEAF_LENGTH = 1 << LEAF_BITS; // 叶子节点的长度 2^15
// 叶子节点结构
struct Leaf {
void *values[LEAF_LENGTH]; // 存储实际数据的数组
};
Leaf *root_[ROOT_LENGTH]; // 根节点数组,指向叶子节点
public:
typedef uintptr_t Number; // 定义Number类型为uintptr_t
// 构造函数,初始化根节点
explicit TCMalloc_PageMap2() {
memset(root_, 0, sizeof(root_)); // 初始化根节点为NULL
PreallocateMoreMemory(); // 预分配内存
}
// 获取键k对应的值,如果k超出范围或未设置,返回NULL
void *get(Number k) const {
const Number i1 = k >> LEAF_BITS; // 计算根节点索引
const Number i2 = k & (LEAF_LENGTH - 1); // 计算叶子节点索引
if ((k >> BITS) > 0 || root_[i1] == nullptr) { // 检查k是否超出范围或叶子节点未分配
return nullptr;
}
return root_[i1]->values[i2]; // 返回叶子节点中对应的值
}
// 设置键k的值为v,要求k必须在[0, 2^BITS-1]范围内
void set(Number k, void *v) {
const Number i1 = k >> LEAF_BITS; // 计算根节点索引
const Number i2 = k & (LEAF_LENGTH - 1); // 计算叶子节点索引
assert(i1 < ROOT_LENGTH); // 确保根节点索引有效
root_[i1]->values[i2] = v; // 设置叶子节点中对应的值
}
// 确保从start开始的n个键都有对应的叶子节点
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS; // 计算根节点索引
// 检查是否溢出
if (i1 >= ROOT_LENGTH)
return false;
// 如果叶子节点未分配,则分配
if (root_[i1] == nullptr) {
static ConcurrentMemoryPool<Leaf> leafPool; // 使用对象池分配叶子节点
Leaf *leaf = (Leaf *) leafPool.New(); // 从对象池中获取叶子节点
memset(leaf, 0, sizeof(*leaf)); // 初始化叶子节点
root_[i1] = leaf; // 将叶子节点挂载到根节点
}
// 跳过当前叶子节点覆盖的范围
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
// 预分配内存,确保所有可能的键都有对应的叶子节点
void PreallocateMoreMemory() {
Ensure(0, 1 << BITS); // 确保所有键都有叶子节点
}
};
// 三级基数树
template<int BITS> // 64 - 12 = 52
class TCMalloc_PageMap3 {
private:
// 在每一层内部节点消耗的位数
static const int INTERIOR_BITS = (BITS + 2) / 3; // 向上取整 (54)/3 = 18
static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS; // 内部节点的长度 2^18
// 在叶子节点消耗的位数
static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS; // 叶子节点的位数 52 - 2 * 18 = 52 - 36 = 16,就是说有两层18的
static const int LEAF_LENGTH = 1 << LEAF_BITS; // 叶子节点的长度 2^16
// 内部节点结构
struct Node {
Node* ptrs[INTERIOR_LENGTH]; // 指向子节点的指针数组
};
// 叶子节点结构
struct Leaf {
void* values[LEAF_LENGTH]; // 存储值的数组
};
Node* root_; // 基数树的根节点
// 创建一个新的内部节点
Node* NewNode()
{
static ConcurrentMemoryPool<Node> newPool;
Node *result = newPool.New();
if (result != nullptr) {
memset(result, 0, sizeof(Node)); // 初始化内存为0
}
assert(result);
return result;
}
public:
typedef uintptr_t Number; // 定义Number类型为uintptr_t
// 构造函数,初始化内存分配器和根节点
explicit TCMalloc_PageMap3()
{
root_ = NewNode();
}
// 获取键k对应的值
void* get(Number k) const {
// LEAF_BITS-->16 INTERIOR_BITS-->18
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS); // 第一层索引
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1); // 第二层索引
const Number i3 = k & (LEAF_LENGTH - 1); // 第三层索引
if ((k >> BITS) > 0 ||
root_->ptrs[i1] == nullptr || root_->ptrs[i1]->ptrs[i2] == nullptr) {
return nullptr; // 如果键超出范围或节点不存在,返回NULL
}
return reinterpret_cast<Leaf *>(root_->ptrs[i1]->ptrs[i2])->values[i3]; // 返回叶子节点中的值
}
// 设置键k对应的值
void set(Number k, void *v)
{
assert(k >> BITS == 0); // 确保键k在有效范围内
// LEAF_BITS-->16 INTERIOR_BITS-->18
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS); // 第一层索引
if (root_->ptrs[i1] == nullptr)
{
//bool Ensure(Number start, size_t n)
Ensure(k, 1);
}
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1); // 第二层索引
if (root_->ptrs[i1]->ptrs[i2] == nullptr)
{
Ensure(k, 1);
}
const Number i3 = k & (LEAF_LENGTH - 1); // 第三层索引
reinterpret_cast<Leaf *>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v; // 设置叶子节点中的值
}
// 确保从start开始的n个键对应的节点存在
bool Ensure(Number start, size_t n)
{
for (Number key = start; key <= start + n - 1;)
{
const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS); // 第一层索引
const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1); // 第二层索引
// 检查是否溢出
if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)
return false;
// 如果第二层节点不存在,则创建
if (root_->ptrs[i1] == nullptr) {
Node *node = NewNode();
if (node == nullptr) return false;
root_->ptrs[i1] = node;
}
// 如果叶子节点不存在,则创建
if (root_->ptrs[i1]->ptrs[i2] == nullptr)
{
static ConcurrentMemoryPool<Leaf> leafPool; // 使用对象池分配叶子节点
Leaf *leaf = (Leaf *) leafPool.New(); // 从对象池中获取叶子节点
if (leaf == nullptr) return false;
memset(leaf, 0, sizeof(*leaf)); // 初始化内存为0
root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node *>(leaf);
}
// 跳过当前叶子节点覆盖的键范围
// LEAF_BITS-->16 INTERIOR_BITS-->18
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
};PageCache.h
cpp
#pragma once
#include"Common.h"
#include "ConcurrentMemoryPool.h"
#include"PageMap.h"
#include<unordered_map>
class PageCache
{
private:
// 页号映射对应的centralcache的Span位置
#ifdef _WIN64
TCMalloc_PageMap3<64 - PAGE_SHIFT> IdSpanMap_;
#elif _WIN32
TCMalloc_PageMap1<32 - PAGE_SHIFT> IdSpanMap_;
#elif __linux__
TCMalloc_PageMap3<64 - PAGE_SHIFT> IdSpanMap_;
#endif
SpanList spanlist_[NFRESSLISTS];
static PageCache sInstan_;
ConcurrentMemoryPool<Span> spanPool_;
PageCache() = default;
PageCache(const PageCache&) = delete;
public:
static PageCache* Instance()
{
return &sInstan_;
}
// 获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
// 释放空闲span回到Pagecache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
std::mutex pagemtx_;
//获取K页的span
Span* GetSpan(size_t K);
};PageCache.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS
#include "PageCache.h"
PageCache PageCache::sInstan_;
// 获取一个K页的span
Span* PageCache::GetSpan(size_t k)
{
assert(k > 0);
// 大于128 page的直接向堆申请
if (k > NPAGES - 1)
{
void* ptr = SystemAlloc(k);
//Span* span = new Span;
Span* span = spanPool_.New();
span->PageNum = (PageID)ptr >> PAGE_SHIFT;
span->n_ = k;
IdSpanMap_.set(span->PageNum, span);
return span;
}
// 先检查第k个桶里面有没有span
if (!spanlist_[k].Empty())
{
Span* kSpan = spanlist_[k].PopFront();
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (size_t i = 0; i < kSpan->n_; ++i)
{
IdSpanMap_.set(kSpan->PageNum + i, kSpan);
}
return kSpan;
}
// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
for (size_t i = k + 1; i < NPAGES; ++i)
{
if (!spanlist_[i].Empty())
{
Span* nSpan = spanlist_[i].PopFront();
//Span* kSpan = new Span;
Span* kSpan = spanPool_.New();
// 在nSpan的头部切一个k页下来
// k页span返回
// nSpan再挂到对应映射的位置
kSpan->PageNum = nSpan->PageNum;
kSpan->n_ = k;
nSpan->PageNum += k;
nSpan->n_ -= k;
spanlist_[nSpan->n_].PushFront(nSpan);
// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时
// 进行的合并查找
IdSpanMap_.set(nSpan->PageNum, nSpan);
IdSpanMap_.set(nSpan->PageNum + nSpan->n_ - 1, nSpan);
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PageID i = 0; i < kSpan->n_; ++i)
{
IdSpanMap_.set(kSpan->PageNum + i, kSpan);
}
return kSpan;
}
}
// 走到这个位置就说明后面没有大页的span了
// 这时就去找堆要一个128页的span
//Span* bigSpan = new Span;
Span* bigSpan = spanPool_.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->PageNum = (PageID)ptr >> PAGE_SHIFT;
bigSpan->n_ = NPAGES - 1;
spanlist_[bigSpan->n_].PushFront(bigSpan);
return GetSpan(k);
}
Span* PageCache::MapObjectToSpan(void* obj)
{
PageID id = ((PageID)obj >> PAGE_SHIFT);
auto ret = (Span*)IdSpanMap_.get(id);
assert(ret != nullptr);
return ret;
}
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 大于128 page的直接还给堆
if (span->n_ > NPAGES - 1)
{
void* ptr = (void*)(span->PageNum << PAGE_SHIFT);
SystemFree(ptr);
//delete span;
spanPool_.Delete(span);
return;
}
// 对span前后的页,尝试进行合并,缓解内存碎片问题
while (1)
{
PageID prevId = span->PageNum - 1;
//auto ret = _idSpanMap.find(prevId);
//// 前面的页号没有,不合并了
//if (ret == _idSpanMap.end())
//{
// break;
//}
auto ret = (Span*)IdSpanMap_.get(prevId);
if (ret == nullptr)
{
break;
}
// 前面相邻页的span在使用,不合并了
Span* prevSpan = ret;
if (prevSpan->IsUse == true)
{
break;
}
// 合并出超过128页的span没办法管理,不合并了
if (prevSpan->n_ + span->n_ > NPAGES - 1)
{
break;
}
span->PageNum = prevSpan->PageNum;
span->n_ += prevSpan->n_;
spanlist_[prevSpan->n_].Erase(prevSpan);
//delete prevSpan;
spanPool_.Delete(prevSpan);
}
// 向后合并
while (1)
{
PageID nextId = span->PageNum + span->n_;
/*auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end())
{
break;
}*/
auto ret = (Span*)IdSpanMap_.get(nextId);
if (ret == nullptr)
{
break;
}
Span* nextSpan = ret;
if (nextSpan->IsUse == true)
{
break;
}
if (nextSpan->n_ + span->n_ > NPAGES - 1)
{
break;
}
span->n_ += nextSpan->n_;
spanlist_[nextSpan->n_].Erase(nextSpan);
//delete nextSpan;
spanPool_.Delete(nextSpan);
}
spanlist_[span->n_].PushFront(span);
span->IsUse = false;
IdSpanMap_.set(span->PageNum + span->n_ - 1, span);
IdSpanMap_.set(span->PageNum, span);
}性能测试
cpp
#define _CRT_SECURE_NO_WARNINGS
//多线程下与malloc的性能测试
#include"ConcurrentAlloc.h"
#include<thread>
#include<vector>
#include<atomic>
#include<ctime>
#include<cstdio>
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]()
{
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(malloc(16));
//v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(ConcurrentAlloc(16));
//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
struct Node {
Node* ptrs[262144]; // 指向子节点的指针数组
};
int main()
{
size_t n = 10000;
cout << "==========================================================" << endl;
BenchmarkConcurrentMalloc(n, 10, 10);
cout << endl << endl;
BenchmarkMalloc(n, 10, 10);
cout << "==========================================================" << endl;
return 0;
}结果为:
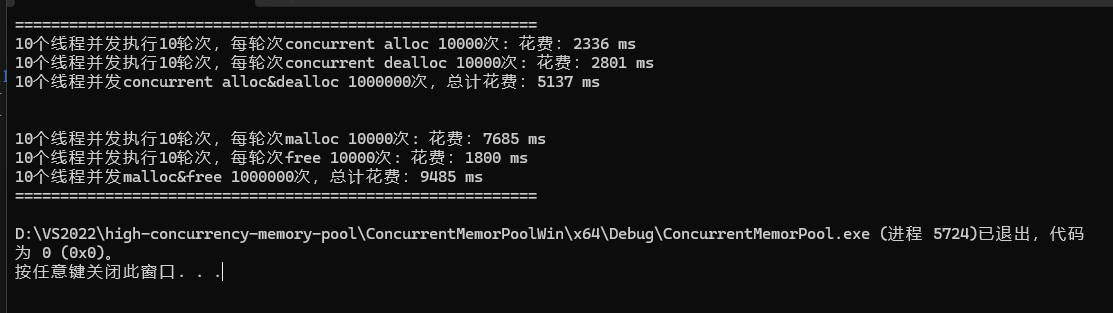
本期项目相关的博客到这里就结束了,喜欢请点个赞谢谢
封面图自取:
